Przyrostowe kopiowanie danych z usługi Azure SQL Database do usługi Blob Storage przy użyciu śledzenia zmian w witrynie Azure Portal
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
W rozwiązaniu integracji danych przyrostowe ładowanie danych po początkowych operacjach ładowania danych to powszechnie używany scenariusz. Zmienione dane w określonym okresie w Twoim źródłowym magazynie danych można łatwo podzielić (na przykład LastModifyTime, CreationTime). Jednak w niektórych przypadkach nie ma jawnego sposobu identyfikacji danych delta od czasu ostatniego przetworzenia danych. Aby zidentyfikować dane delta, można użyć technologii śledzenia zmian obsługiwanej przez magazyny danych, takie jak Azure SQL Database i SQL Server.
W tym samouczku opisano sposób używania usługi Azure Data Factory ze śledzeniem zmian w celu przyrostowego ładowania danych różnicowych z usługi Azure SQL Database do usługi Azure Blob Storage. Aby uzyskać więcej informacji na temat śledzenia zmian, zobacz Śledzenie zmian w programie SQL Server.
W tym samouczku wykonasz następujące kroki:
- Przygotuj źródłowy magazyn danych.
- Tworzenie fabryki danych.
- Tworzenie połączonych usług.
- Tworzenie zestawów danych źródła, ujścia i śledzenia zmian.
- Tworzenie, uruchamianie i monitorowanie pełnego potoku kopiowania.
- Dodawanie lub aktualizowanie danych w tabeli źródłowej.
- Utwórz, uruchom i monitoruj potok kopiowania przyrostowego.
Rozwiązanie wysokiego poziomu
W tym samouczku utworzysz dwa potoki, które wykonują następujące operacje.
Uwaga
W tym samouczku baza danych Azure SQL Database jest używana jako magazyn danych źródłowych. Można również użyć programu SQL Server.
Początkowe ładowanie danych historycznych: tworzysz potok z działaniem kopiowania, które kopiuje całe dane ze źródłowego magazynu danych (Azure SQL Database) do docelowego magazynu danych (Azure Blob Storage):
- Włącz technologię śledzenia zmian w źródłowej bazie danych w usłudze Azure SQL Database.
- Pobierz początkową wartość
SYS_CHANGE_VERSIONw bazie danych jako punkt odniesienia w celu przechwycenia zmienionych danych. - Załaduj pełne dane ze źródłowej bazy danych do usługi Azure Blob Storage.

Przyrostowe ładowanie danych różnicowych zgodnie z harmonogramem: Tworzysz ciąg składający się z następujących działań i uruchamiasz go okresowo:
Utwórz dwa zadania wyszukiwania w celu uzyskania starych i nowych
SYS_CHANGE_VERSIONwartości z bazy danych Azure SQL.Utwórz jeden proces kopiowania, aby skopiować wstawione, zaktualizowane lub usunięte dane (dane delta) pomiędzy dwiema wartościami
SYS_CHANGE_VERSIONz usługi Azure SQL Database do usługi Azure Blob Storage.Dane różnicowe ładujesz, łącząc klucze podstawowe zmienionych wierszy (między dwiema
SYS_CHANGE_VERSIONwartościami) z danymi w tabeli źródłowej, a następnie przenosisz dane różnicowe do miejsca docelowego.Utwórz jedno działanie procedury składowanej, aby zaktualizować wartość
SYS_CHANGE_VERSIONdla następnego uruchomienia potoku.

Wymagania wstępne
- Subskrypcja platformy Azure. Jeśli nie masz subskrypcji, przed rozpoczęciem utwórz bezpłatne konto.
- Azure SQL Database. Baza danych w usłudze Azure SQL Database służy jako źródłowy magazyn danych. Jeśli jej nie masz, zobacz Tworzenie bazy danych w usłudze Azure SQL Database , aby uzyskać instrukcje tworzenia bazy danych.
- Konto usługi Azure Storage. Magazyn obiektów blob jest używany jako magazyn danych ujścia. Jeśli nie masz konta usługi Azure Storage, zobacz Tworzenie konta magazynu, aby dowiedzieć się, jak je utworzyć. Utwórz kontener o nazwie adftutorial.
Uwaga
Do interakcji z platformą Azure zalecamy używanie modułu Azure Az w programie PowerShell. Zobacz Instalowanie programu Azure PowerShell, aby rozpocząć. Aby dowiedzieć się, jak przeprowadzić migrację do modułu Az PowerShell, zobacz Migracja programu Azure PowerShell z modułu AzureRM do modułu Az.
Tworzenie tabeli źródła danych w usłudze Azure SQL Database
Otwórz program SQL Server Management Studio i połącz się z usługą SQL Database.
W Eksploratorze serwera kliknij prawym przyciskiem myszy bazę danych, a następnie wybierz pozycję Nowe zapytanie.
Uruchom następujące polecenie SQL względem bazy danych, aby utworzyć tabelę o nazwie
data_source_tablejako źródłowy magazyn danych:create table data_source_table ( PersonID int NOT NULL, Name varchar(255), Age int PRIMARY KEY (PersonID) ); INSERT INTO data_source_table (PersonID, Name, Age) VALUES (1, 'aaaa', 21), (2, 'bbbb', 24), (3, 'cccc', 20), (4, 'dddd', 26), (5, 'eeee', 22);Włącz śledzenie zmian w bazie danych i tabeli źródłowej (
data_source_table), uruchamiając następujące zapytanie SQL.Uwaga
- Zastąp
<your database name>nazwą bazy danych w usłudze Azure SQL Database, która zawieradata_source_table. - W bieżącym przykładzie zmienione dane są przechowywane przez dwa dni. W przypadku ładowania zmienionych danych nie rzadziej niż co trzy dni niektóre zmienione dane nie zostaną uwzględnione. Musisz zmienić wartość
CHANGE_RETENTIONna większą liczbę lub upewnić się, że okres ładowania zmienionych danych mieści się w ciągu dwóch dni. Aby uzyskać więcej informacji, zobacz Włączanie śledzenia zmian dla bazy danych.
ALTER DATABASE <your database name> SET CHANGE_TRACKING = ON (CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON) ALTER TABLE data_source_table ENABLE CHANGE_TRACKING WITH (TRACK_COLUMNS_UPDATED = ON)- Zastąp
Utwórz nową tabelę i magazyn o nazwie
ChangeTracking_versionz wartością domyślną, uruchamiając następujące zapytanie:create table table_store_ChangeTracking_version ( TableName varchar(255), SYS_CHANGE_VERSION BIGINT, ); DECLARE @ChangeTracking_version BIGINT SET @ChangeTracking_version = CHANGE_TRACKING_CURRENT_VERSION(); INSERT INTO table_store_ChangeTracking_version VALUES ('data_source_table', @ChangeTracking_version)Uwaga
Jeśli dane nie są zmieniane po włączeniu śledzenia zmian dla usługi SQL Database, wartość wersji śledzenia zmian to
0.Uruchom następujące zapytanie, aby utworzyć procedurę składowaną w bazie danych. Potok danych wywołuje tę procedurę składowaną, aby zaktualizować wersję śledzenia zmian w tabeli, którą utworzyłeś w poprzednim kroku.
CREATE PROCEDURE Update_ChangeTracking_Version @CurrentTrackingVersion BIGINT, @TableName varchar(50) AS BEGIN UPDATE table_store_ChangeTracking_version SET [SYS_CHANGE_VERSION] = @CurrentTrackingVersion WHERE [TableName] = @TableName END
Tworzenie fabryki danych
Otwórz przeglądarkę internetową Microsoft Edge lub Google Chrome. Obecnie tylko te przeglądarki obsługują interfejs użytkownika usługi Data Factory.
W witrynie Azure Portal w menu po lewej stronie wybierz pozycję Utwórz zasób.
Wybierz Integracja>Data Factory.
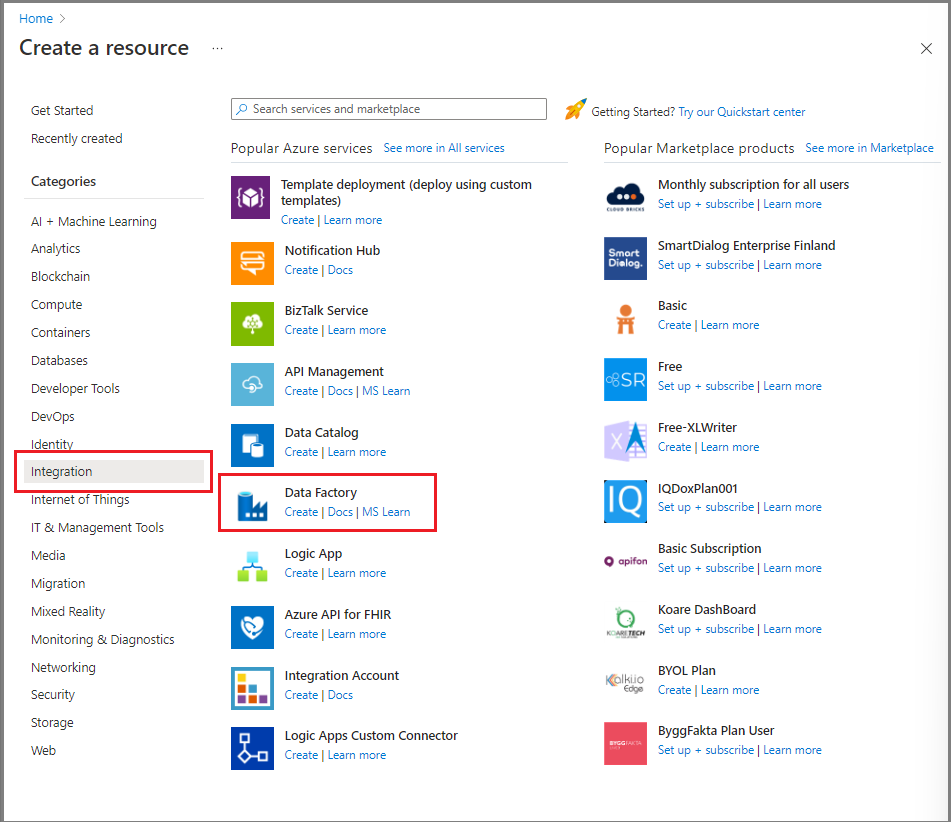
Na stronie Nowa fabryka danych wprowadź nazwę ADFTutorialDataFactory.
Nazwa fabryki danych musi być globalnie unikatowa. Jeśli wystąpi błąd informujący, że wybrana nazwa jest niedostępna, zmień nazwę (na przykład na yournameADFTutorialDataFactory) i spróbuj ponownie utworzyć fabrykę danych. Aby uzyskać więcej informacji, zobacz Reguły nazewnictwa usługi Azure Data Factory.
Wybierz subskrypcję platformy Azure, w której chcesz utworzyć fabrykę danych.
W obszarze Grupa zasobów wykonaj jedną z następujących czynności:
- Wybierz pozycję Użyj istniejącej, a następnie z listy rozwijanej wybierz istniejącą grupę zasobów.
- Wybierz pozycję Utwórz nową, a następnie wprowadź nazwę grupy zasobów.
Informacje na temat grup zasobów znajdują się w artykule Using resource groups to manage your Azure resources (Używanie grup zasobów do zarządzania zasobami platformy Azure).
W obszarze Wersja wybierz pozycję V2.
W obszarze Region wybierz region fabryki danych.
Na liście rozwijanej są wyświetlane tylko obsługiwane lokalizacje. Magazyny danych (na przykład Usługi Azure Storage i Azure SQL Database) i obliczenia (na przykład Usługa Azure HDInsight), których używa fabryka danych, może znajdować się w innych regionach.
Wybierz pozycję Dalej: Konfiguracja usługi Git. Skonfiguruj repozytorium, postępując zgodnie z instrukcjami w Konfiguracja metoda 4: Podczas tworzenia fabryki lub zaznacz pole wyboru Konfiguruj Git później.
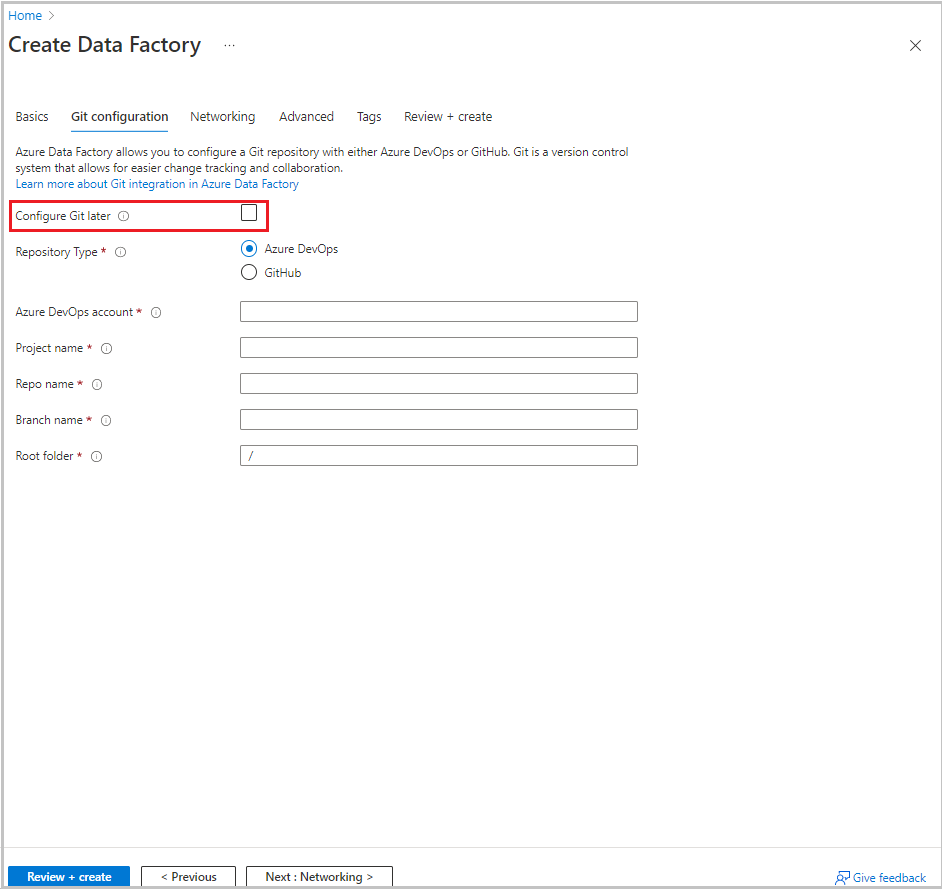
Wybierz pozycję Przejrzyj i utwórz.
Wybierz pozycję Utwórz.
Na pulpicie nawigacyjnym na kafelku Wdrażanie usługi Data Factory jest wyświetlany stan.

Po zakończeniu tworzenia zostanie wyświetlona strona Fabryka danych . Wybierz kafelek Launch Studio, aby otworzyć interfejs użytkownika usługi Azure Data Factory na osobnej karcie.
Tworzenie połączonych usług
Połączone usługi tworzy się w fabryce danych w celu połączenia magazynów danych i usług obliczeniowych z fabryką danych. W tej sekcji utworzysz połączone usługi z kontem usługi Azure Storage i bazą danych w usłudze Azure SQL Database.
Tworzenie połączonej usługi Azure Storage
Aby powiązać konto magazynowe z fabryką danych:
- W interfejsie użytkownika usługi Data Factory na karcie Zarządzanie w obszarze Połączenia wybierz pozycję Połączone usługi. Następnie wybierz pozycję + Nowy lub przycisk Utwórz połączoną usługę.
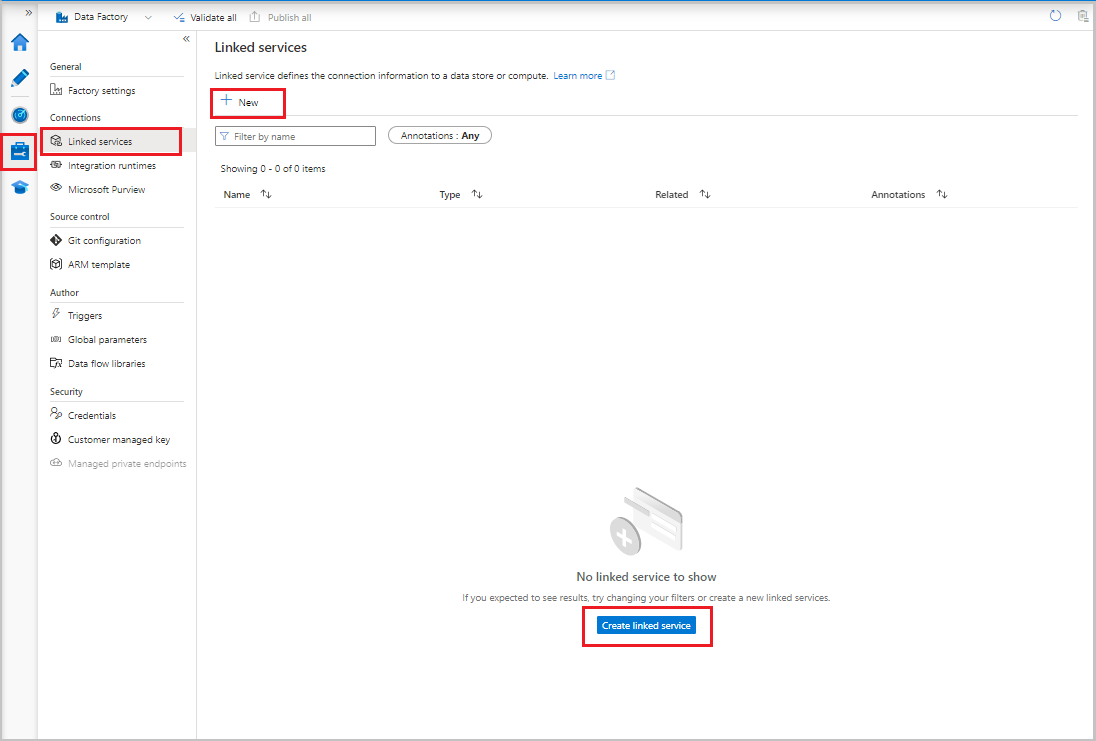
- W oknie Nowa połączona usługa wybierz pozycję Azure Blob Storage, a następnie wybierz pozycję Kontynuuj.
- Wprowadź następujące informacje:
- Wprowadź wartość AzureStorageLinkedService w polu Nazwa.
- Dla Połączenia za pośrednictwem środowiska Integration Runtime wybierz środowisko Integration Runtime.
- W polu Typ uwierzytelniania wybierz metodę uwierzytelniania.
- Dla Nazwa konta magazynu wybierz swoje konto magazynu Azure.
- Wybierz pozycję Utwórz.
Tworzenie połączonej usługi Azure SQL Database
Aby połączyć bazę danych z fabryką danych:
W interfejsie użytkownika usługi Data Factory na karcie Zarządzanie w obszarze Połączenia wybierz pozycję Połączone usługi. Następnie wybierz pozycję + Nowy.
W oknie Nowa połączona usługa wybierz pozycję Azure SQL Database, a następnie wybierz pozycję Kontynuuj.
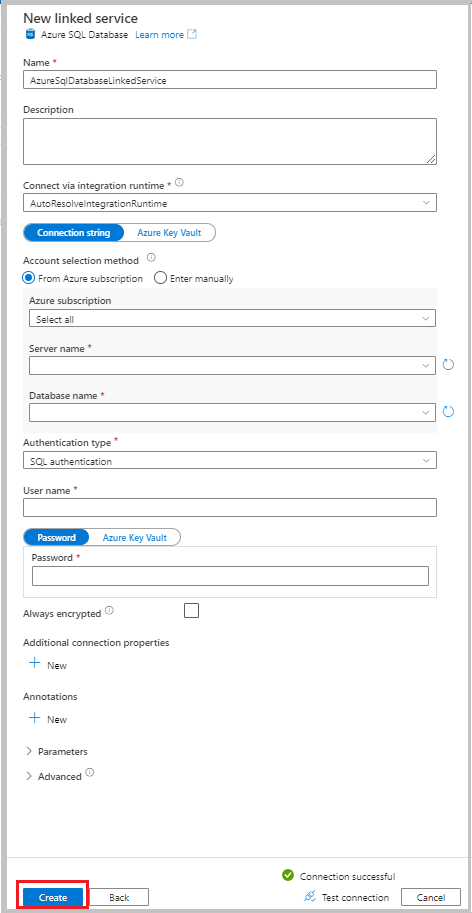
Wprowadź następujące informacje:
- W polu Nazwa wprowadź wartość AzureSqlDatabaseLinkedService.
- W polu Nazwa serwera wybierz serwer.
- W polu Nazwa bazy danych wybierz bazę danych.
- W polu Typ uwierzytelniania wybierz metodę uwierzytelniania. W tym samouczku używane jest uwierzytelnianie SQL w celach demonstracyjnych.
- W polu Nazwa użytkownika wprowadź nazwę użytkownika.
- W polu Hasło wprowadź hasło użytkownika. Możesz też podać informacje dotyczące połączonej usługi Azure Key Vault (AKV), nazwy sekretu i wersji sekretu.
Wybierz pozycję Testuj połączenie, aby przetestować połączenie.
Wybierz pozycję Utwórz , aby utworzyć połączoną usługę.
Tworzenie zestawów danych
W tej sekcji utworzysz zestawy danych reprezentujące źródło danych i miejsce docelowe danych wraz z miejscem przechowywania SYS_CHANGE_VERSION wartości.
Tworzenie zestawu danych reprezentującego źródło danych
W interfejsie użytkownika usługi Data Factory na karcie Autor wybierz znak plus (+). Następnie wybierz pozycję Zestaw danych lub wybierz wielokropek dla akcji zestawu danych.
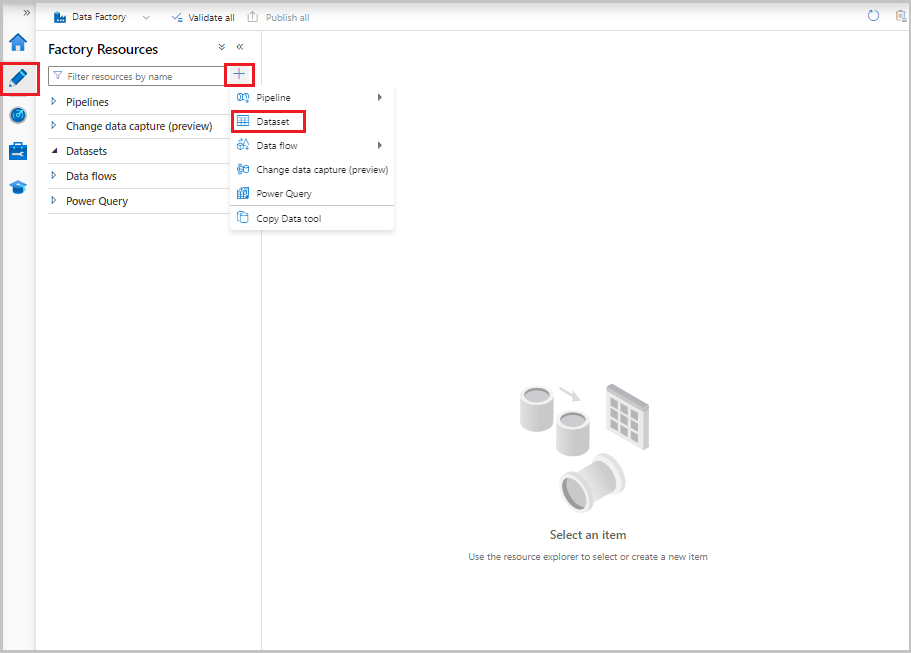
Wybierz pozycję Azure SQL Database, a następnie wybierz pozycję Kontynuuj.
W oknie Ustawianie właściwości wykonaj następujące czynności:
- Wprowadź SourceDataset w polu Nazwa.
- W polu Połączona usługa wybierz pozycję AzureSqlDatabaseLinkedService.
- W polu Nazwa tabeli wybierz pozycję dbo.data_source_table.
- Dla Importuj schemat wybierz opcję Z połączenia/magazynu.
- Wybierz przycisk OK.

Utwórz zestaw danych, aby odzwierciedlić dane skopiowane do docelowego magazynu danych
W poniższej procedurze utworzysz zestaw danych reprezentujący dane skopiowane z źródłowego magazynu danych. Utworzyłeś kontener adftutorial w usłudze Azure Blob Storage w ramach wymagań wstępnych. Utwórz ten kontener, jeśli nie istnieje, lub zastąp go nazwą istniejącego kontenera. W tym samouczku nazwa pliku wyjściowego jest generowana dynamicznie na podstawie wyrażenia @CONCAT('Incremental-', pipeline().RunId, '.txt').
W interfejsie użytkownika usługi Data Factory na karcie Autor wybierz pozycję +. Następnie wybierz pozycję Zestaw danych lub wybierz wielokropek, aby wybrać akcje dla zestawu danych.
Wybierz pozycję Azure Blob Storage, a następnie wybierz pozycję Kontynuuj.
Wybierz format typu danych jako RozdzielanyTekst, a następnie wybierz pozycję Kontynuuj.
W oknie Ustawianie właściwości wykonaj następujące czynności:
- W polu Nazwa wprowadź SinkDataset.
- W polu Połączona usługa wybierz pozycję AzureBlobStorageLinkedService.
- W polu Ścieżka pliku wprowadź adftutorial/incchgtracking.
- Wybierz przycisk OK.
Po wyświetleniu zestawu danych w widoku drzewa przejdź do karty Połączenie i wybierz pole tekstowe Nazwa pliku. Po wyświetleniu opcji Dodaj zawartość dynamiczną wybierz ją.
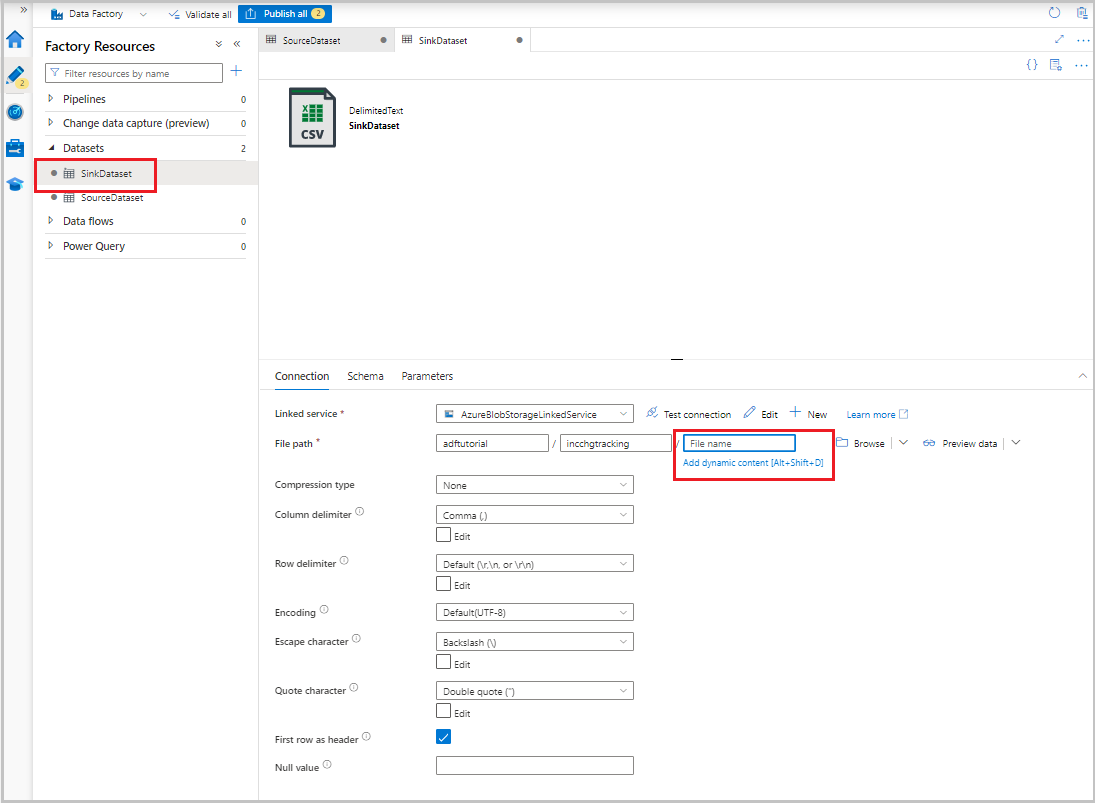
Okno Konstruktora wyrażeń potoku zostanie wyświetlone. Wklej
@concat('Incremental-',pipeline().RunId,'.csv')do pola tekstowego.Wybierz przycisk OK.
Stwórz zestaw danych do reprezentacji danych śledzenia zmian
W poniższej procedurze utworzysz zestaw danych do przechowywania wersji śledzenia zmian. Utworzyłeś tabelę table_store_ChangeTracking_version jako część wymagań wstępnych.
- W interfejsie użytkownika usługi Data Factory na karcie Autor wybierz pozycję +, a następnie wybierz pozycję Zestaw danych.
- Wybierz pozycję Azure SQL Database, a następnie wybierz pozycję Kontynuuj.
-
W oknie Ustawianie właściwości wykonaj następujące czynności:
- Dla Nazwa, wprowadź ChangeTrackingDataset.
- W polu Połączona usługa wybierz pozycję AzureSqlDatabaseLinkedService.
- Dla nazwy tabeli wybierz dbo.table_store_ChangeTracking_version.
- Dla Importuj schemat wybierz opcję Z połączenia/magazynu.
- Wybierz przycisk OK.
Tworzenie potoku danych dla pełnej kopii
W poniższej procedurze utworzysz potok z działaniem kopiowania, które kopiuje całe dane ze źródłowego magazynu danych (Azure SQL Database) do docelowego magazynu danych (Azure Blob Storage):
W interfejsie użytkownika usługi Data Factory na karcie Tworzenie wybierz pozycję +, a następnie wybierz pozycję Potok danych>Potok danych.
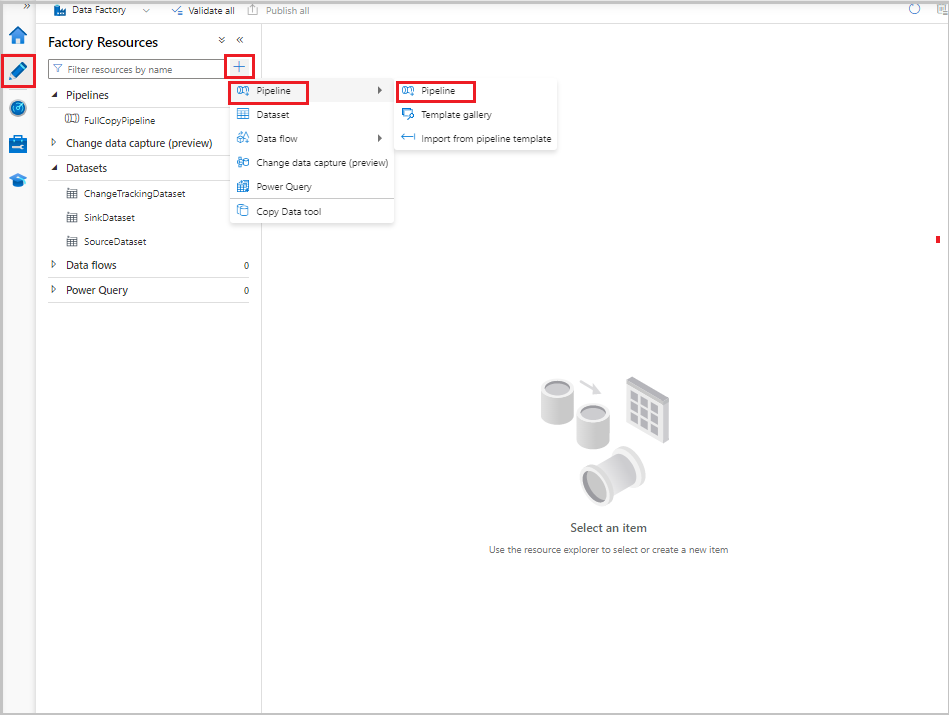
Zostanie wyświetlona nowa karta konfigurowania potoku. Potok jest również wyświetlany w widoku drzewa. W oknie Właściwości zmień nazwę pipeline'u na FullCopyPipeline.
W przyborniku Działania rozwiń pozycję Przenieś i przekształć. Wykonaj jedną z następujących czynności:
- Przeciągnij zadanie kopiowania na powierzchnię projektanta pipeline'u.
- Na pasku wyszukiwania w obszarze Działania wyszukaj działanie kopiowania danych, a następnie ustaw nazwę na FullCopyActivity.
Przejdź do zakładki Źródło. Dla Zestawu danych źródłowych wybierz pozycję SourceDataset.
Przejdź do karty Ujście. W obszarze Zestaw danych Ujścia wybierz pozycję SinkDataset.
Aby zweryfikować definicję potoku, wybierz pozycję Weryfikuj na pasku narzędzi. Potwierdź, że nie ma błędu walidacji. Zamknij wyniki weryfikacji przetwarzania.
Aby opublikować jednostki (połączone usługi, zestawy danych i potoki), wybierz Publikuj wszystko. Poczekaj na wyświetlenie komunikatu Pomyślnie opublikowano.
Aby wyświetlić powiadomienia, wybierz przycisk Pokaż powiadomienia .
Uruchom pełną kopię łańcucha przetwarzania
W interfejsie użytkownika usługi Data Factory na pasku narzędzi potoku wybierz pozycję Dodaj wyzwalacz, a następnie wybierz pozycję Wyzwól teraz.
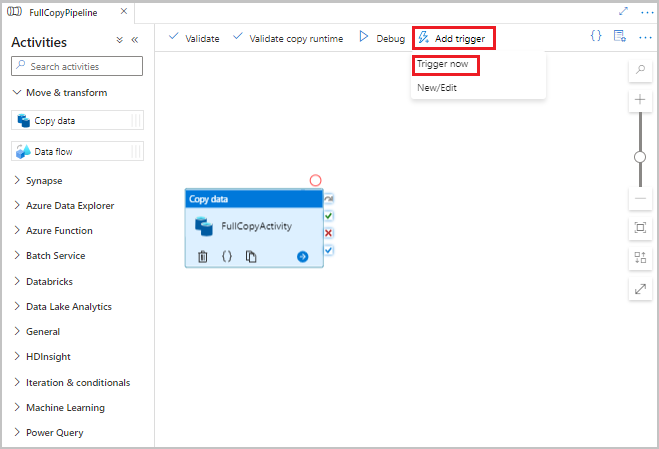
W oknie Uruchomienie potoku wybierz OK.

Monitoruj pełny proces kopiowania
W UI Data Factory wybierz kartę Monitor. Uruchomienie potoku i jego stan są wyświetlane na liście. Aby odświeżyć listę, wybierz pozycję Odśwież. Umieść kursor nad przebiegiem potoku, aby uzyskać Uruchom ponownie lub Zużycie.
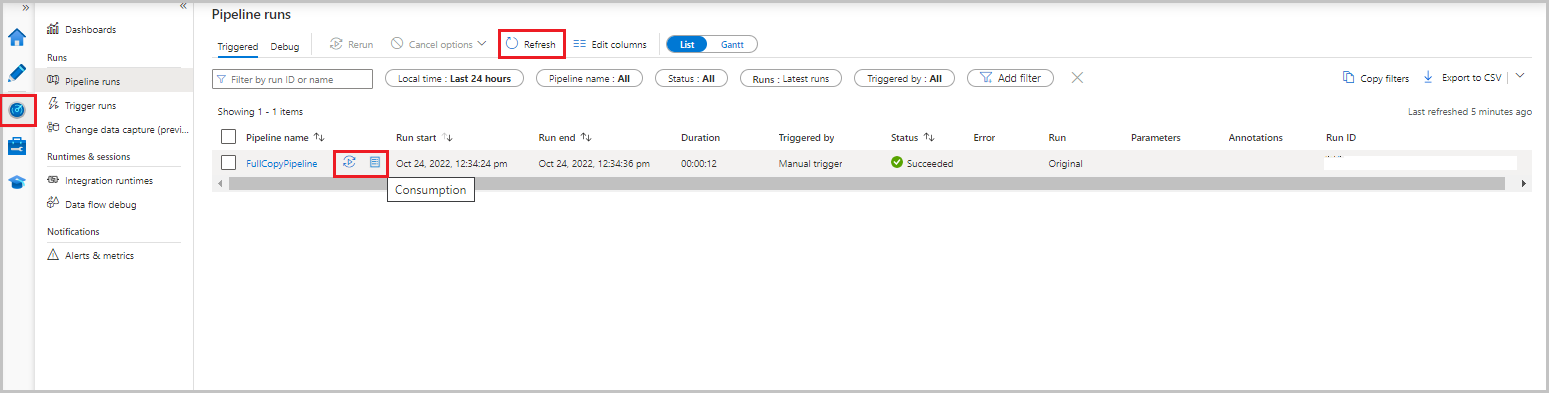
Aby wyświetlić uruchomienia aktywności skojarzone z uruchomieniem potoku, wybierz nazwę potoku z kolumny Nazwa potoku. W harmonogramie istnieje tylko jedno działanie, więc na liście znajduje się tylko jeden wpis. Aby wrócić do widoku uruchomień potoków, wybierz link Wszystkie uruchomienia potoku na górze.
Sprawdzanie wyników
Folder incchgtracking kontenera adftutorial zawiera plik o nazwie incremental-<GUID>.csv.
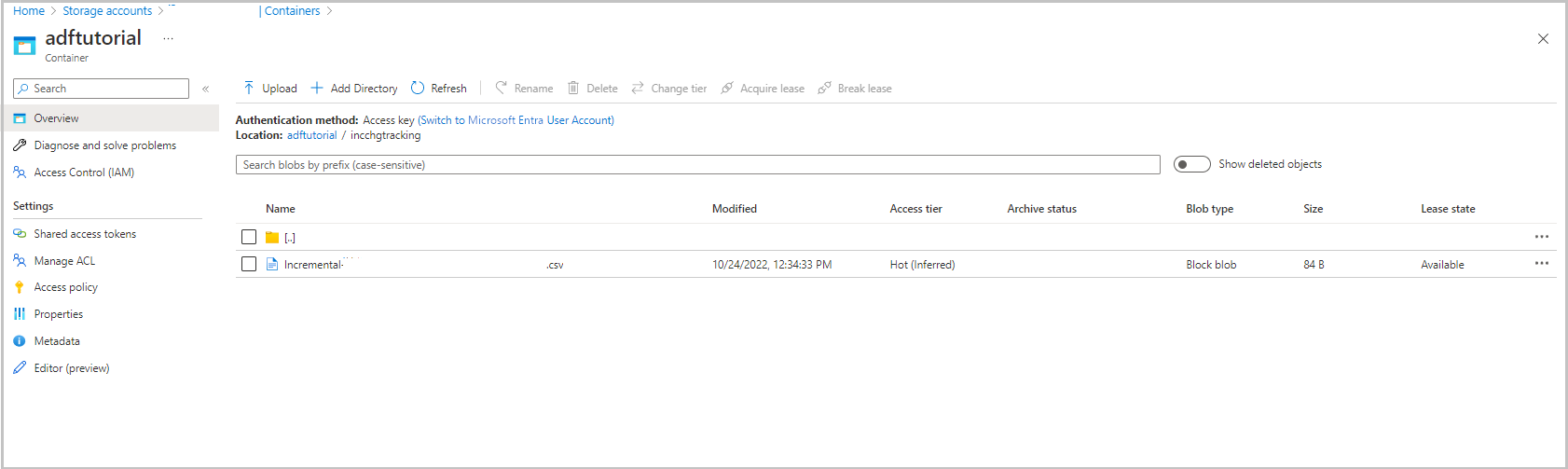
Plik powinien mieć dane z bazy danych:
PersonID,Name,Age
1,"aaaa",21
2,"bbbb",24
3,"cccc",20
4,"dddd",26
5,"eeee",22
5,eeee,PersonID,Name,Age
1,"aaaa",21
2,"bbbb",24
3,"cccc",20
4,"dddd",26
5,"eeee",22
Dodawanie większej ilości danych do tabeli źródłowej
Uruchom następujące zapytanie względem bazy danych, aby dodać wiersz i zaktualizować wiersz:
INSERT INTO data_source_table
(PersonID, Name, Age)
VALUES
(6, 'new','50');
UPDATE data_source_table
SET [Age] = '10', [name]='update' where [PersonID] = 1
Tworzenie potoku na potrzeby kopii przyrostowej
W poniższej procedurze utworzysz pipeline z czynnościami i uruchomisz go cyklicznie. Kiedy uruchamiasz potok:
- Działania wyszukiwania pobierają stare i nowe wartości z usługi Azure SQL Database i przekazują je do aktywności kopiowania.
- Działanie kopiowania kopiuje wstawione, zaktualizowane lub usunięte dane między dwiema
SYS_CHANGE_VERSIONwartościami z usługi Azure SQL Database do usługi Azure Blob Storage. - Działanie procedury składowanej aktualizuje wartość
SYS_CHANGE_VERSIONdla następnego uruchomienia potoku.
pl-PL: W interfejsie użytkownika usługi Data Factory przejdź do karty Author. Wybierz pozycję +, a następnie wybierz Pipeline>Pipeline.
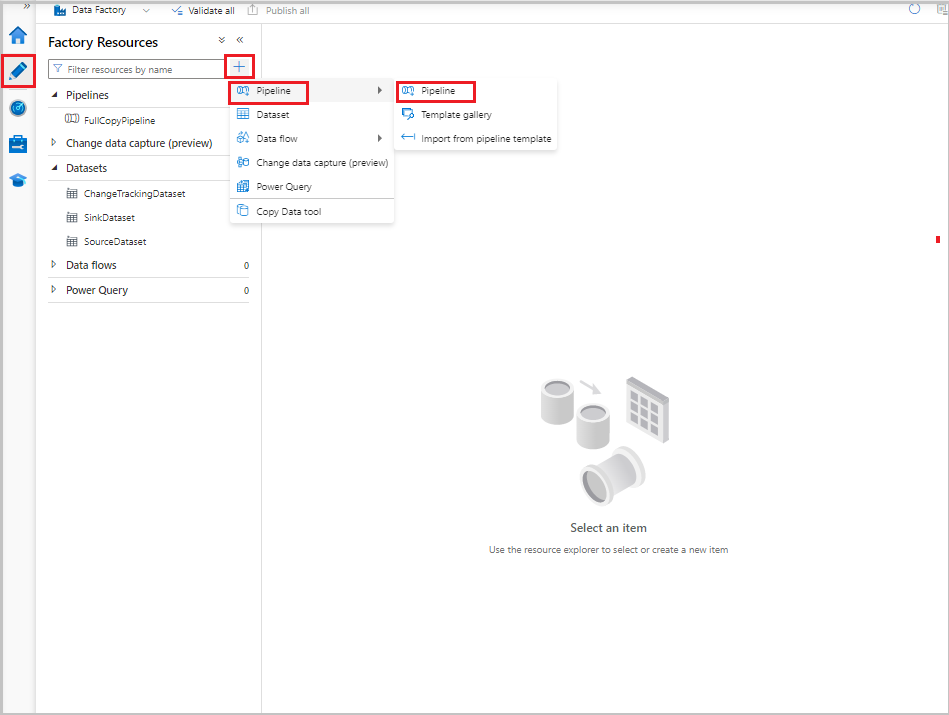
Zostanie wyświetlona nowa karta konfigurowania potoku. Potok jest również wyświetlany w widoku drzewa. W oknie Właściwości zmień nazwę potoku na IncrementalCopyPipeline.
Rozwiń sekcję Ogólne w przyborniku Działania. Przeciągnij działanie wyszukiwania na powierzchnię projektanta przepływu lub wyszukaj w polu Wyszukaj Działania. Ustaw nazwę działania na LookupLastChangeTrackingVersionActivity. To działanie pobiera wersję śledzenia zmian używaną w ostatniej operacji kopiowania, która jest przechowywana w tabeli
table_store_ChangeTracking_version.Przejdź do karty Ustawienia w oknie Właściwości . W polu Źródłowy zestaw danych wybierz pozycję ChangeTrackingDataset.
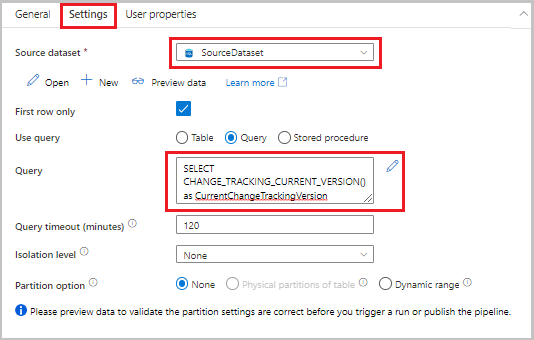
Przeciągnij czynność wyszukiwania z przybornika Działania do powierzchni projektanta rurociągu. Ustaw nazwę działania na LookupCurrentChangeTrackingVersionActivity. To działanie pobiera bieżącą wersję rozwiązania Change Tracking.
Przejdź do karty Ustawienia w oknie Właściwości , a następnie wykonaj następujące czynności:
W polu Źródłowy zestaw danych wybierz pozycję SourceDataset.
W obszarze Użyj zapytania wybierz pozycję Zapytanie.
W polu Zapytanie wprowadź następujące zapytanie SQL:
SELECT CHANGE_TRACKING_CURRENT_VERSION() as CurrentChangeTrackingVersion
W przyborniku Działania rozwiń pozycję Przenieś i przekształć. Przeciągnij działanie kopiowania danych na powierzchnię projektanta potoku. Ustaw nazwę działania na IncrementalCopyActivity. To działanie kopiuje dane między ostatnią wersją śledzenia zmian a bieżącą wersją śledzenia zmian do docelowego magazynu danych.
Przejdź do karty Źródło w oknie Właściwości , a następnie wykonaj następujące czynności:
W polu Źródłowy zestaw danych wybierz pozycję SourceDataset.
W obszarze Użyj zapytania wybierz pozycję Zapytanie.
W polu Zapytanie wprowadź następujące zapytanie SQL:
SELECT data_source_table.PersonID,data_source_table.Name,data_source_table.Age, CT.SYS_CHANGE_VERSION, SYS_CHANGE_OPERATION from data_source_table RIGHT OUTER JOIN CHANGETABLE(CHANGES data_source_table, @{activity('LookupLastChangeTrackingVersionActivity').output.firstRow.SYS_CHANGE_VERSION}) AS CT ON data_source_table.PersonID = CT.PersonID where CT.SYS_CHANGE_VERSION <= @{activity('LookupCurrentChangeTrackingVersionActivity').output.firstRow.CurrentChangeTrackingVersion}
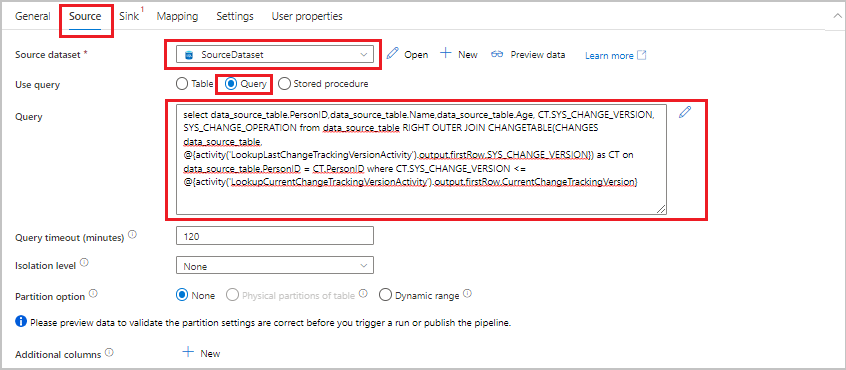
Przejdź do karty Sink. W sekcji Sink Dataset wybierz pozycję SinkDataset.
Połącz oba działania wyszukiwania jedno po drugim z działaniem kopiowania. Przeciągnij zielony przycisk dołączony do działania wyszukiwania do działania kopiowania.
Przeciągnij działanie procedury składowanej z przybornika Działania do powierzchni projektanta potoku. Ustaw nazwę działania na StoredProceduretoUpdateChangeTrackingActivity. To działanie aktualizuje wersję śledzenia zmian w tabeli
table_store_ChangeTracking_version.Przejdź do karty Ustawienia , a następnie wykonaj następujące czynności:
- W polu Połączona usługa wybierz pozycję AzureSqlDatabaseLinkedService.
- W polu Nazwa procedury składowanej wybierz wartość Update_ChangeTracking_Version.
- Wybierz Importuj.
- W sekcji Parametry procedury składowanej określ następujące wartości parametrów:
Nazwisko Typ Wartość CurrentTrackingVersionInt64 @{activity('LookupCurrentChangeTrackingVersionActivity').output.firstRow.CurrentChangeTrackingVersion}TableNameString @{activity('LookupLastChangeTrackingVersionActivity').output.firstRow.TableName}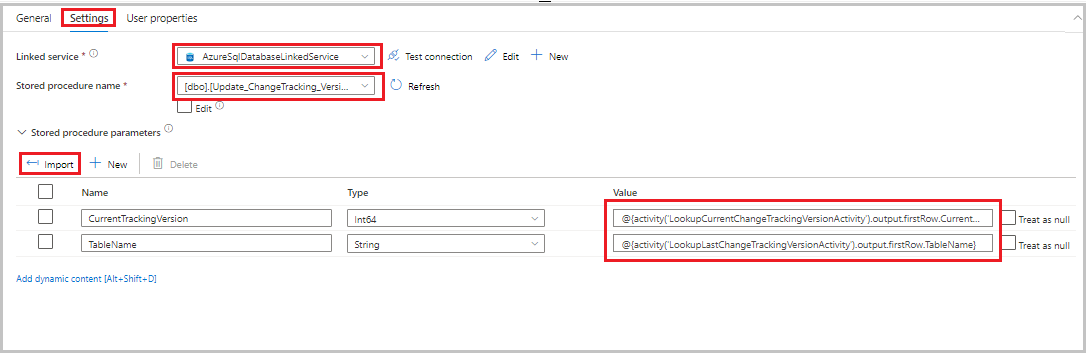
Połącz działanie kopiowania z działaniem procedury składowanej. Przeciągnij zielony przycisk dołączony do działania kopiowania do działania procedury składowanej.
Wybierz pozycję Weryfikuj na pasku narzędzi. Potwierdź, że nie wystąpiły błędy walidacji. Zamknij okno Raport walidacji procesu.
Opublikuj elementy (połączone usługi, zestawy danych i potoki) w usłudze Data Factory, wybierając przycisk Opublikuj wszystko. Poczekaj na wyświetlenie komunikatu Publikowanie zakończyło się pomyślnie .
Uruchom potok kopiowania przyrostowego
Wybierz Dodaj wyzwalacz na pasku narzędzi potoku, a następnie wybierz Wyzwól teraz.
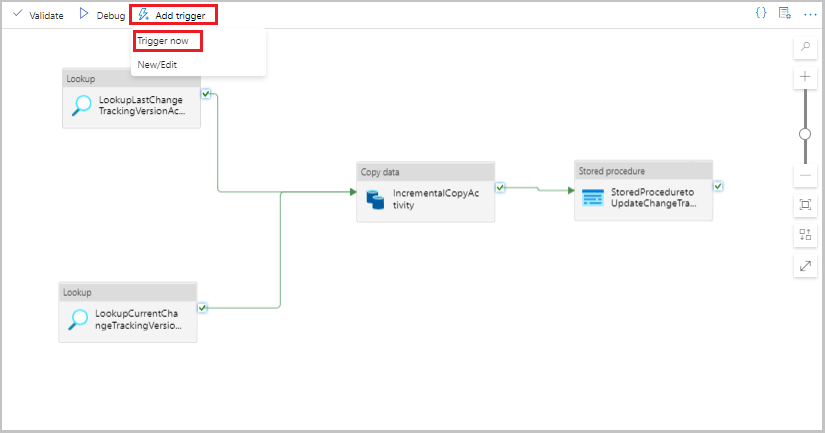
W oknie Uruchomienie potoku wybierz OK.
Monitoruj potok kopiowania przyrostowego
Wybierz kartę Monitor . Uruchomienie potoku i jego stan są wyświetlane na liście. Aby odświeżyć listę, wybierz pozycję Odśwież.
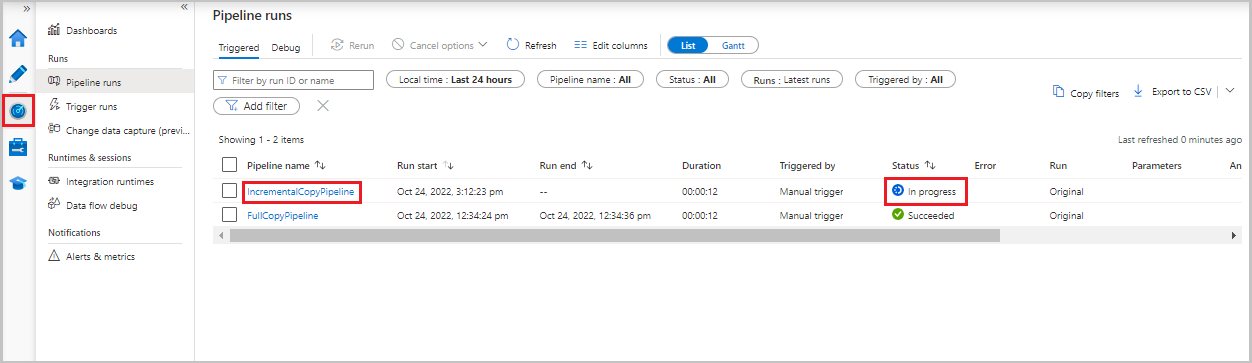
Aby wyświetlić uruchomienia aktywności skojarzone z uruchomieniem potoku, wybierz łącze IncrementalCopyPipeline w kolumnie Nazwa potoku. Serie działań są wyświetlane na liście.
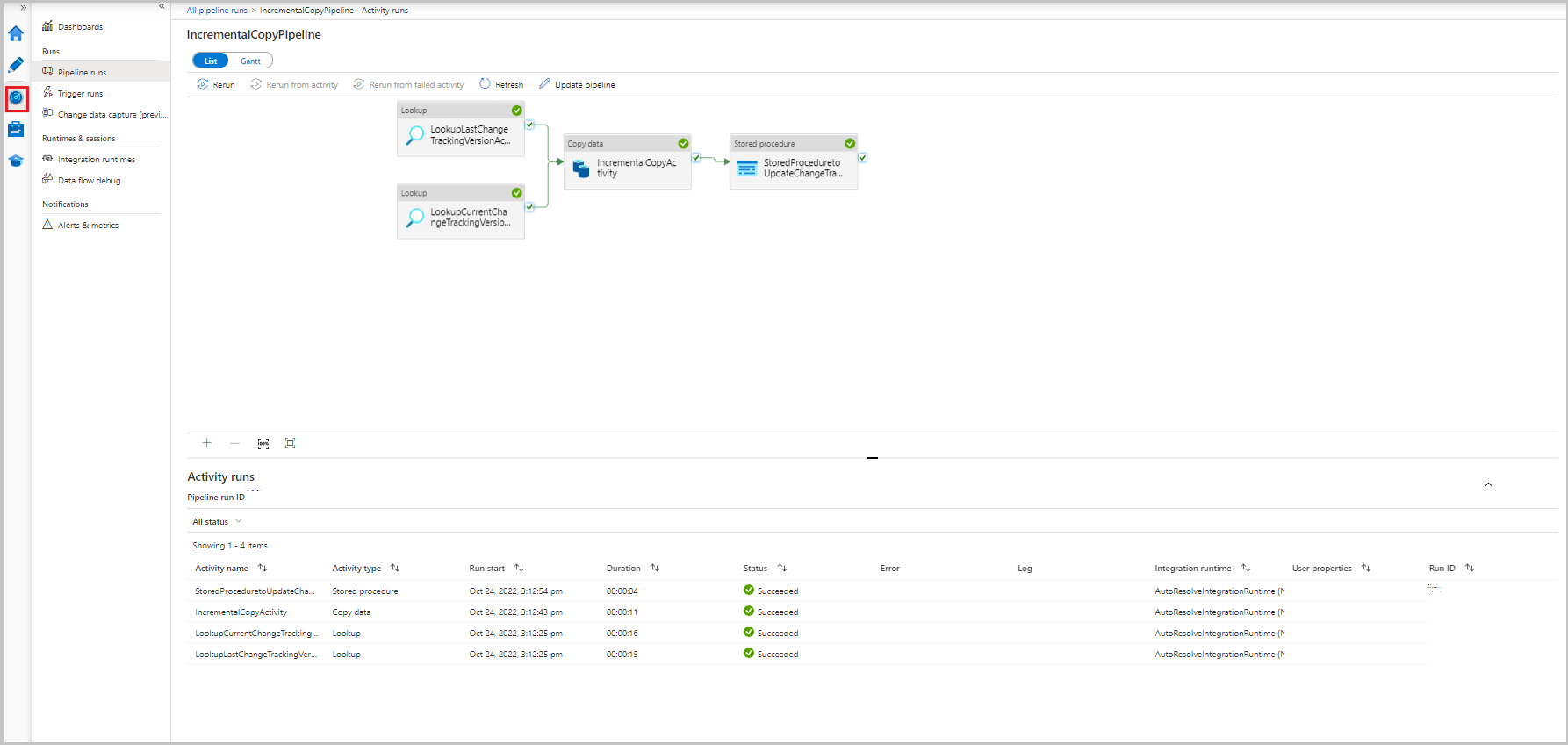
Sprawdzanie wyników
Drugi plik pojawia się w folderze incchgtracking kontenera adftutorial .
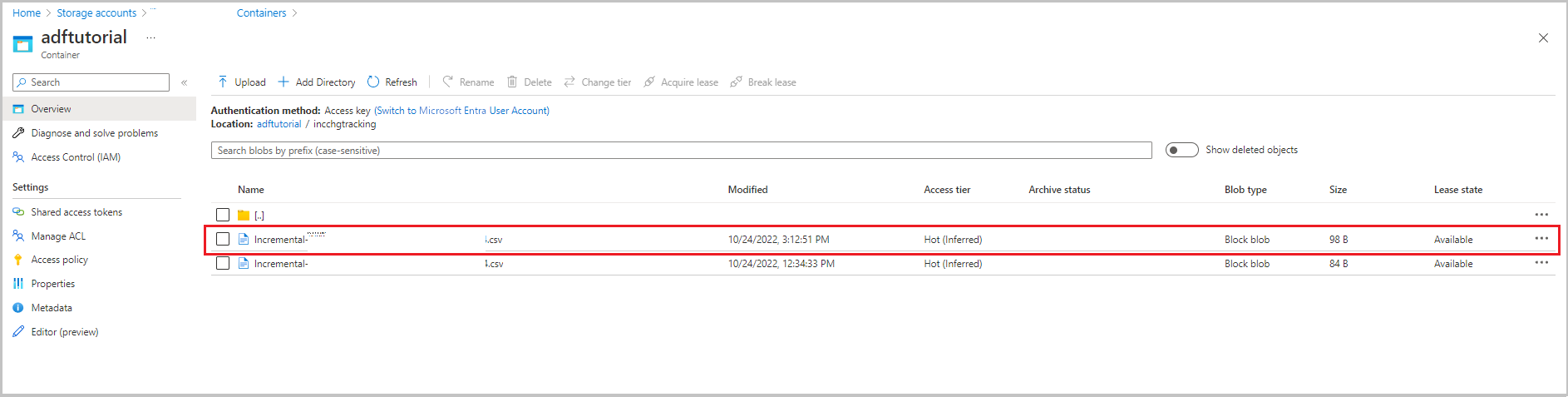
Plik powinien zawierać tylko dane różnicowe z bazy danych. Rekord z U jest zaktualizowanym wierszem w bazie danych i I jest jednym dodanym wierszem.
PersonID,Name,Age,SYS_CHANGE_VERSION,SYS_CHANGE_OPERATION
1,update,10,2,U
6,new,50,1,I
Pierwsze trzy kolumny to zmienione dane z data_source_table. Dwie ostatnie kolumny to metadane z tabeli dla systemu śledzenia zmian. Czwarta kolumna to wartość dla każdego zmienionego SYS_CHANGE_VERSION wiersza. Piąta kolumna to operacja: U = update, I = insert. Aby uzyskać szczegółowe informacje o śledzeniu zmian, zobacz CHANGETABLE.
==================================================================
PersonID Name Age SYS_CHANGE_VERSION SYS_CHANGE_OPERATION
==================================================================
1 update 10 2 U
6 new 50 1 I
Powiązana zawartość
Przejdź do następującego samouczka, aby dowiedzieć się więcej o kopiowaniu tylko nowych i zmienionych plików na podstawie polecenia LastModifiedDate: