Kopiowanie danych z bazy danych programu SQL Server do usługi Azure Blob Storage przy użyciu narzędzia do kopiowania danych
DOTYCZY:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
W tym samouczku utworzysz fabrykę danych za pomocą witryny Azure Portal. Następnie użyj narzędzia do kopiowania danych, aby utworzyć potok, który kopiuje dane z bazy danych programu SQL Server do usługi Azure Blob Storage.
Uwaga
- Jeśli jesteś nowym użytkownikiem usługi Azure Data Factory, zobacz Wprowadzenie do usługi Data Factory.
Ten samouczek obejmuje wykonanie następujących kroków:
- Tworzenie fabryki danych.
- Tworzenie potoku za pomocą narzędzia do kopiowania danych.
- Monitorowanie uruchomień potoku i działań.
Wymagania wstępne
Subskrypcja platformy Azure
Jeśli nie masz jeszcze subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto.
Role na platformie Azure
Aby utworzyć wystąpienia usługi Data Factory, konto użytkownika używane do logowania się na platformie Azure musi mieć przypisaną rolę współautora lub właściciela albo być administratorem subskrypcji platformy Azure.
Aby wyświetlić swoje uprawnienia do subskrypcji, przejdź do witryny Azure Portal. W prawym górnym rogu wybierz swoją nazwę użytkownika, a następnie wybierz pozycję Uprawnienia. Jeśli masz dostęp do wielu subskrypcji, wybierz odpowiednią subskrypcję. Aby uzyskać przykładowe instrukcje dotyczące dodawania użytkownika do roli, zobacz Przypisywanie ról platformy Azure przy użyciu witryny Azure Portal.
Program SQL Server 2014, 2016 oraz 2017
W tym samouczku użyjesz bazy danych programu SQL Server jako źródłowego magazynu danych. Potok w fabryce danych utworzony w tym samouczku kopiuje dane z tej bazy danych programu SQL Server (źródła) do magazynu obiektów blob (ujścia). Następnie utworzysz tabelę o nazwie emp w bazie danych programu SQL Server i wstawisz kilka przykładowych wpisów do tabeli.
Uruchom program SQL Server Management Studio. Jeśli program nie jest jeszcze zainstalowany na używanej maszynie, przejdź do strony pobierania programu SQL Server Management Studio.
Połącz się z wystąpieniem programu SQL Server przy użyciu swoich poświadczeń.
Utwórz przykładową bazę danych. W widoku drzewa kliknij prawym przyciskiem myszy pozycję Bazy danych, a następnie wybierz pozycję Nowa baza danych.
W oknie Nowa baza danych wprowadź nazwę bazy danych, a następnie wybierz przycisk OK.
Aby utworzyć tabelę emp i wstawić do niej przykładowe dane, uruchom następujący skrypt zapytania w bazie danych. W widoku drzewa kliknij prawym przyciskiem myszy utworzoną bazę danych, a następnie wybierz pozycję Nowe zapytanie.
CREATE TABLE dbo.emp ( ID int IDENTITY(1,1) NOT NULL, FirstName varchar(50), LastName varchar(50) ) GO INSERT INTO emp (FirstName, LastName) VALUES ('John', 'Doe') INSERT INTO emp (FirstName, LastName) VALUES ('Jane', 'Doe') GO
Konto magazynu Azure
W tym samouczku używasz konta usługi Azure Storage ogólnego przeznaczenia (konkretnie usługi Blob Storage) jako magazynu danych: docelowego/ujścia. Jeśli nie masz konta magazynu ogólnego przeznaczenia, zobacz Tworzenie konta magazynu, aby dowiedzieć się, jak je utworzyć. Potok w fabryce danych utworzony w tym samouczku kopiuje dane z bazy danych programu SQL Server (źródła) do tego magazynu obiektów blob (ujścia).
Pobieranie nazwy konta i klucza konta magazynu
W tym samouczku używasz nazwy i klucza swojego konta magazynu. Pobierz nazwę i klucz konta magazynu, wykonując następujące kroki:
Zaloguj się do witryny Azure Portal przy użyciu nazwy użytkownika i hasła do konta platformy Azure.
W lewym okienku wybierz pozycję Wszystkie usługi. Zastosuj filtrowanie według słowa kluczowego Magazyn, a następnie wybierz pozycję Konta magazynu.
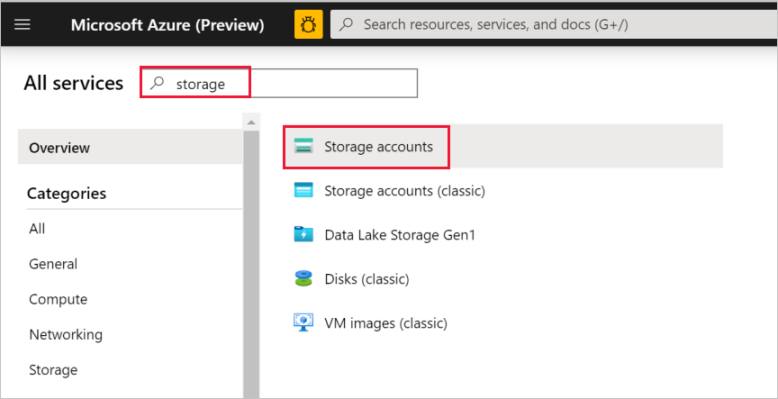
Na liście kont magazynu odfiltruj swoje konto magazynu, jeśli to konieczne. Następnie wybierz swoje konto magazynu.
W oknie Konto magazynu wybierz pozycję Klucze dostępu.
Skopiuj wartości z pól Nazwa konta magazynu i klucz1 i wklej je do Notatnika lub innego edytora do późniejszego użycia z tym samouczkiem.
Tworzenie fabryki danych
W menu po lewej stronie wybierz pozycję Utwórz zasób>Integration>Data Factory.
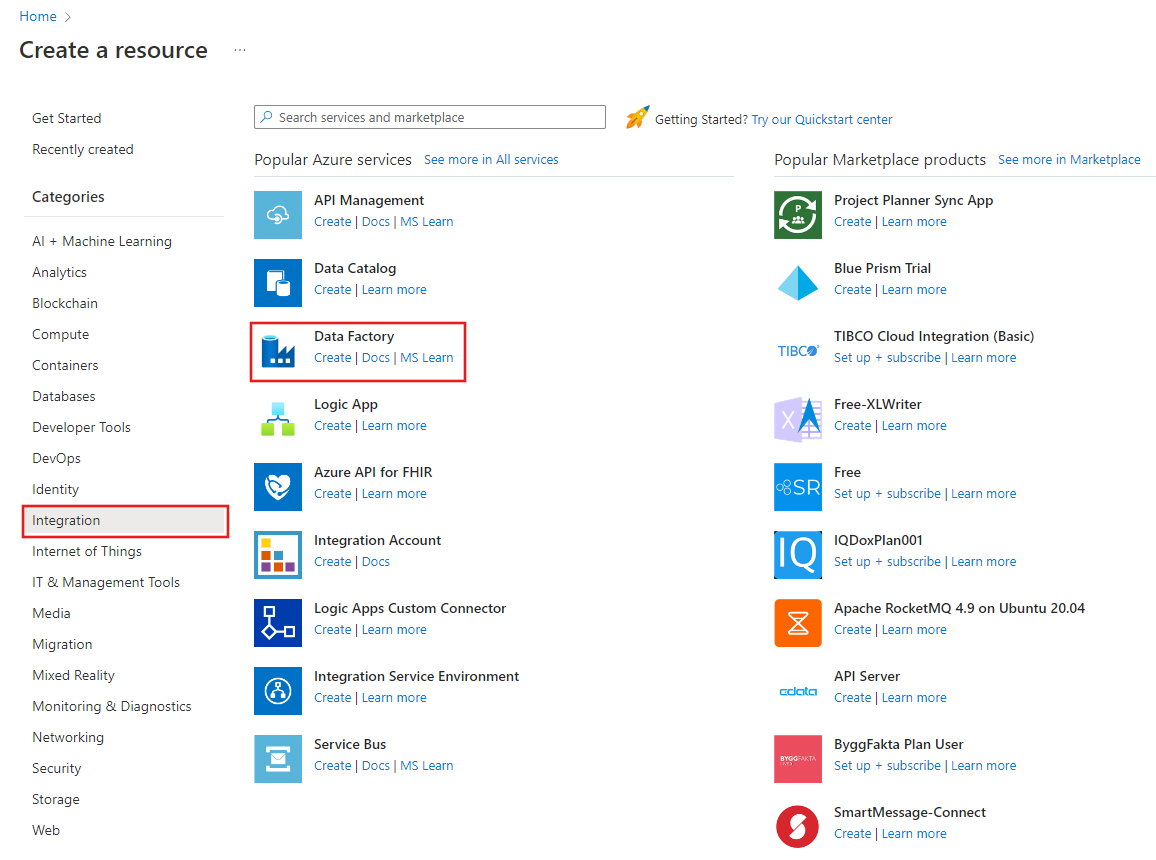
Na stronie Nowa fabryka danych w polu Nazwa wprowadź wartość ADFTutorialDataFactory.
Nazwa fabryki danych musi być globalnie unikatowa. Jeśli dla pola nazwy zobaczysz poniższy komunikat o błędzie, zmień nazwę fabryki danych (np. twojanazwaADFTutorialDataFactory). Reguły nazewnictwa dla artefaktów usługi Data Factory można znaleźć w artykule Data Factory — reguły nazewnictwa.
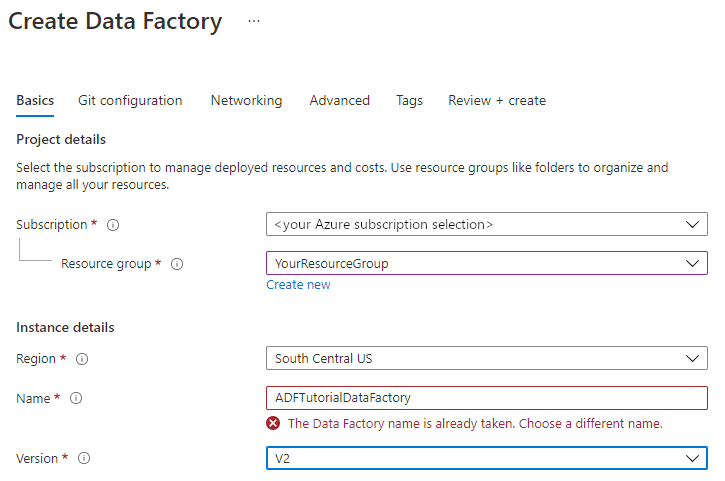
Wybierz subskrypcję platformy Azure, w której chcesz utworzyć fabrykę danych.
W obszarze Grupa zasobów wykonaj jedną z następujących czynności:
Wybierz pozycję Użyj istniejącej, a następnie wybierz istniejącą grupę zasobów z listy rozwijanej.
Wybierz pozycję Utwórz nową, a następnie wprowadź nazwę grupy zasobów.
Informacje na temat grup zasobów znajdują się w artykule Using resource groups to manage your Azure resources (Używanie grup zasobów do zarządzania zasobami platformy Azure).
W obszarze Wersja wybierz pozycję V2.
W obszarze Lokalizacja wybierz lokalizację fabryki danych. Na liście rozwijanej są wyświetlane tylko obsługiwane lokalizacje. Magazyny danych (np. usługi Azure Storage i SQL Database) oraz jednostki obliczeniowe (np. usługa Azure HDInsight) używane przez usługę Data Factory mogą mieścić się w innych lokalizacjach/regionach.
Wybierz pozycję Utwórz.
Po zakończeniu tworzenia zostanie wyświetlona strona Fabryka danych, jak pokazano na poniższej ilustracji.

Wybierz pozycję Otwórz na kafelku Otwórz usługę Azure Data Factory Studio , aby uruchomić interfejs użytkownika usługi Data Factory na osobnej karcie.
Tworzenie potoku za pomocą narzędzia do kopiowania danych
Na stronie głównej usługi Azure Data Factory wybierz pozycję Pozyskiwanie , aby uruchomić narzędzie do kopiowania danych.
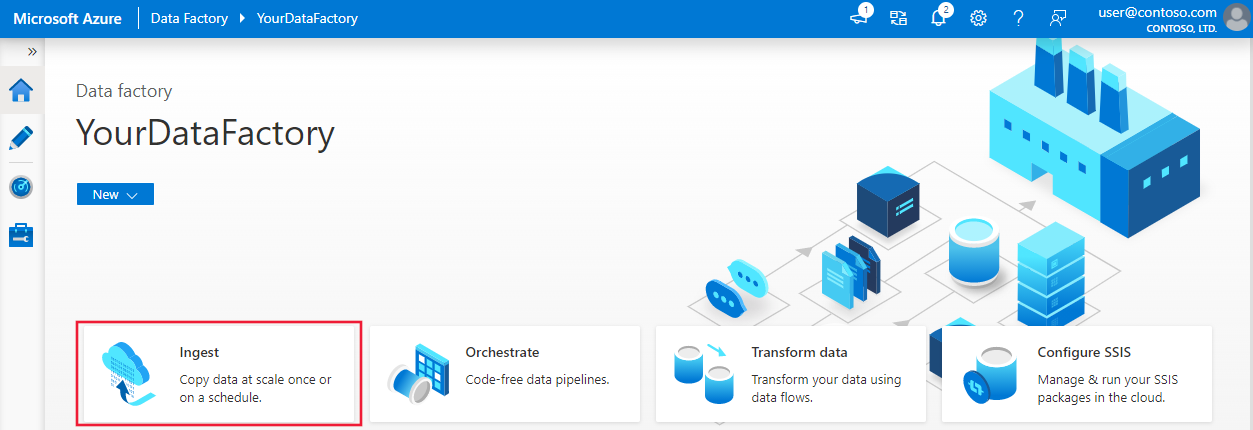
Na stronie Właściwości narzędzia do kopiowania danych wybierz pozycję Wbudowane zadanie kopiowania w obszarze Typ zadania, a następnie wybierz pozycję Uruchom raz w obszarze Cykl zadań lub harmonogram zadań, a następnie wybierz przycisk Dalej.
Na stronie Źródłowy magazyn danych wybierz pozycję + Utwórz nowe połączenie.
W obszarze Nowe połączenie wyszukaj pozycję SQL Server, a następnie wybierz pozycję Kontynuuj.
W oknie dialogowym Nowe połączenie (serwer SQL) w obszarze Nazwa wprowadź wartość SqlServerLinkedService. Wybierz pozycję +Nowy w polu Połącz za pośrednictwem środowiska Integration Runtime. Należy utworzyć środowisko Integration Runtime (Self-hosted), pobrać je na komputer i zarejestrować w usłudze Data Factory. Środowisko Integration Runtime (Self-hosted) kopiuje dane między środowiskiem lokalnym a chmurą.
W oknie dialogowym Konfiguracja środowiska Integration Runtime wybierz pozycję Self-Hosted. Następnie wybierz pozycję Kontynuuj.
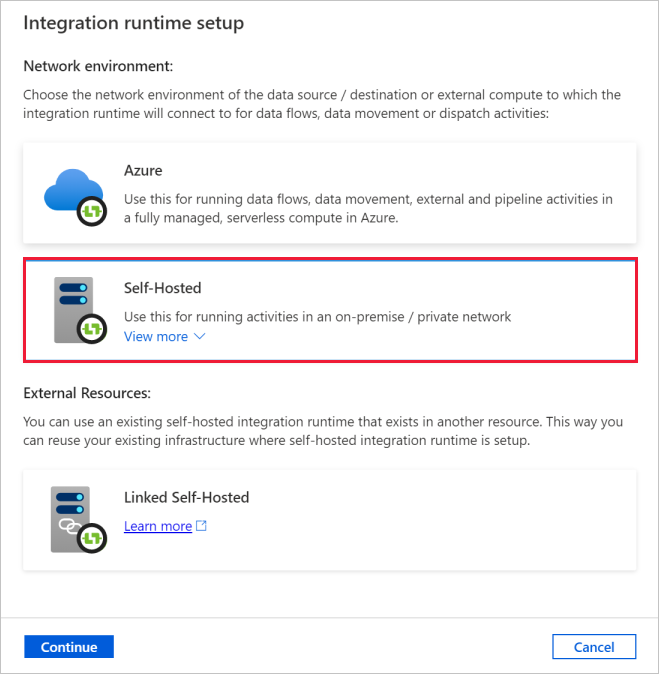
W oknie dialogowym Konfiguracja środowiska Integration Runtime w obszarze Nazwa wprowadź tutorialIntegrationRuntime. Następnie wybierz Utwórz.
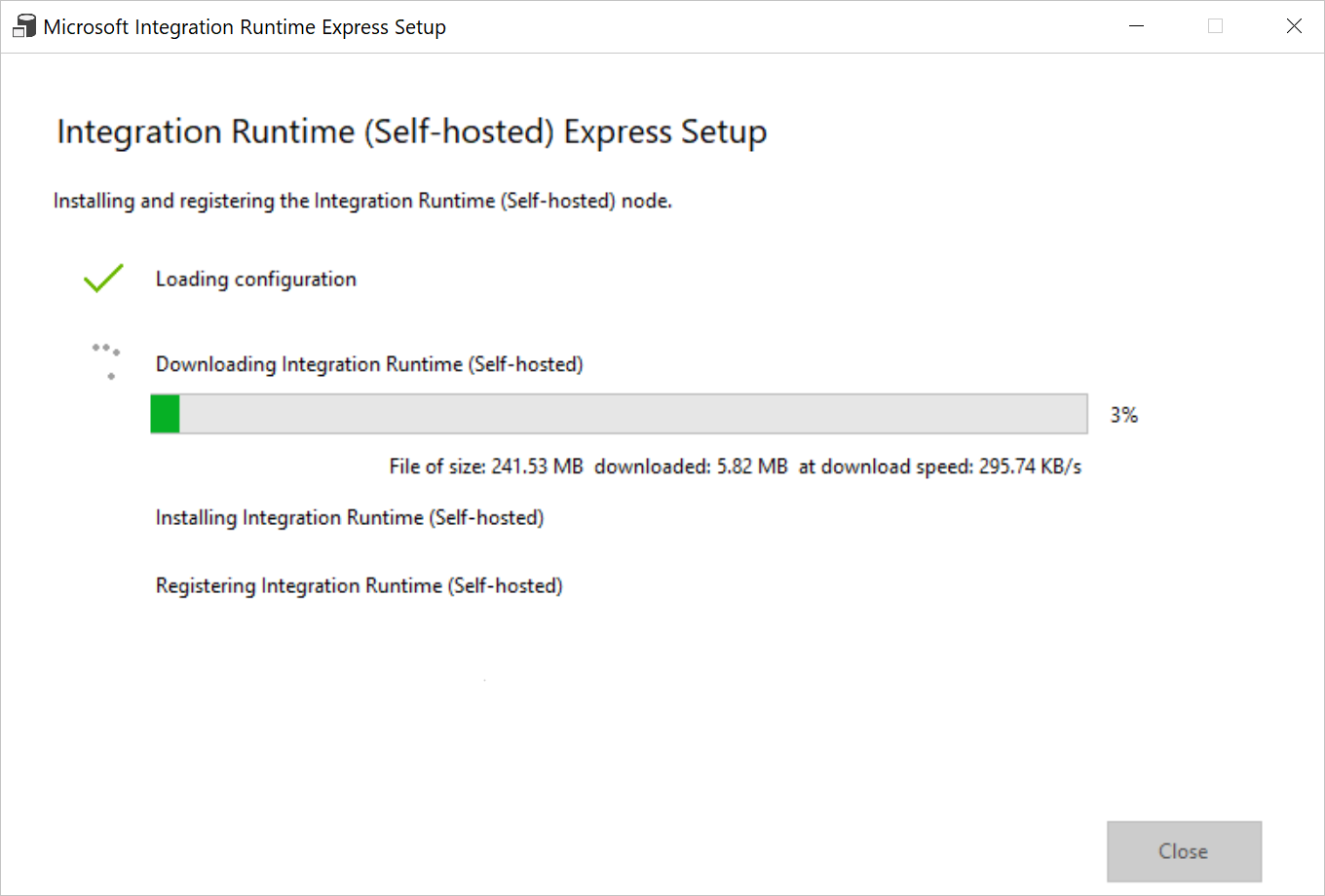
W oknie dialogowym Konfiguracja środowiska Integration Runtime wybierz pozycję Kliknij tutaj, aby uruchomić instalację ekspresową dla tego komputera. Ta akcja instaluje na komputerze środowisko Integration Runtime i rejestruje je w usłudze Data Factory. Ewentualnie można użyć opcji instalacji ręcznej w celu pobrania pliku instalacyjnego, uruchomienia go i zarejestrowania środowiska Integration Runtime za pomocą klucza.
Uruchom pobraną aplikację. W oknie zostanie wyświetlony stan instalacji ekspresowej.
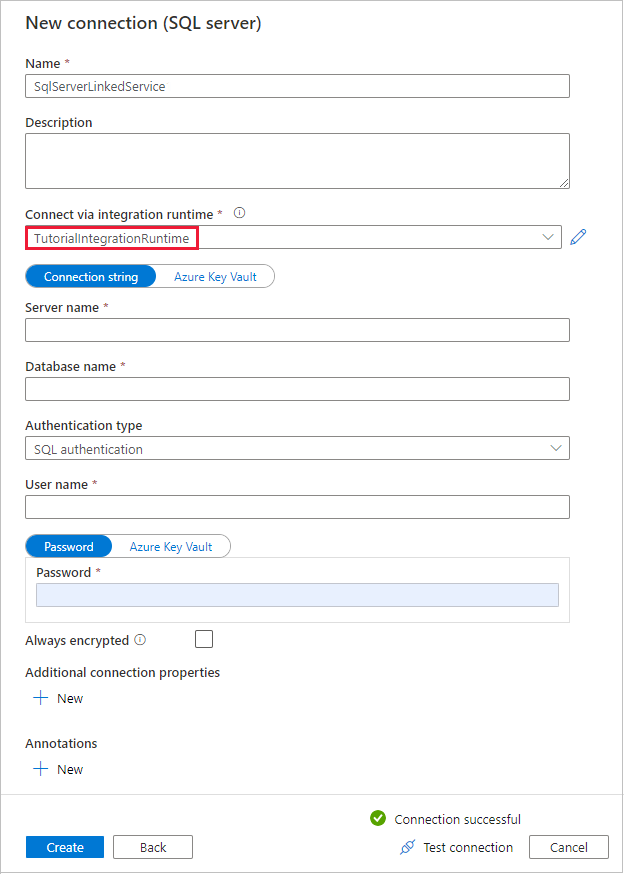
W oknie dialogowym Nowe połączenie (SQL Server) upewnij się, że w obszarze Połącz za pośrednictwem środowiska Integration Runtime wybrano pozycję TutorialIntegrationRuntime. Następnie wykonaj następujące czynności:
a. W polu Nazwa wprowadź wartość SqlServerLinkedService.
b. W polu Nazwa serwera wprowadź nazwę lokalnego wystąpienia programu SQL Server.
c. Wprowadź nazwę swojej lokalnej bazy danych w polu Nazwa bazy danych.
d. Wybierz odpowiedni typ uwierzytelniania w polu Typ uwierzytelniania.
e. W obszarze Nazwa użytkownika wprowadź nazwę użytkownika z dostępem do programu SQL Server.
f. Wprowadź hasło użytkownika.
g. Przetestuj połączenie i wybierz pozycję Utwórz.
Na stronie Źródłowy magazyn danych upewnij się, że nowo utworzone połączenie programu SQL Server zostało wybrane w bloku Połączenie. Następnie w sekcji Tabele źródłowe wybierz pozycję ISTNIEJĄCE TABELE i wybierz tabelę dbo.emp na liście, a następnie wybierz przycisk Dalej. Możesz wybrać dowolną inną tabelę, odpowiednio do bazy danych.
Na stronie Zastosuj filtr możesz wyświetlić podgląd danych i wyświetlić schemat danych wejściowych, wybierając przycisk Podgląd danych. Następnie kliknij przycisk Dalej.
Na stronie Docelowy magazyn danych wybierz pozycję + Utwórz nowe połączenie
W obszarze Nowe połączenie wyszukaj i wybierz pozycję Azure Blob Storage, a następnie wybierz pozycję Kontynuuj.

W oknie dialogowym Nowe połączenie (Azure Blob Storage) wykonaj następujące czynności:
a. W polu Nazwa wprowadź wartość AzureStorageLinkedService.
b. W obszarze Połącz za pośrednictwem środowiska Integration Runtime wybierz pozycję TutorialIntegrationRuntime i wybierz pozycję Klucz konta w obszarze Metoda uwierzytelniania.
c. W obszarze Subskrypcja platformy Azure wybierz subskrypcję platformy Azure z listy rozwijanej.
d. W polu Nazwa konta magazynu wybierz z listy rozwijanej swoje konto magazynu.
e. Przetestuj połączenie i wybierz pozycję Utwórz.
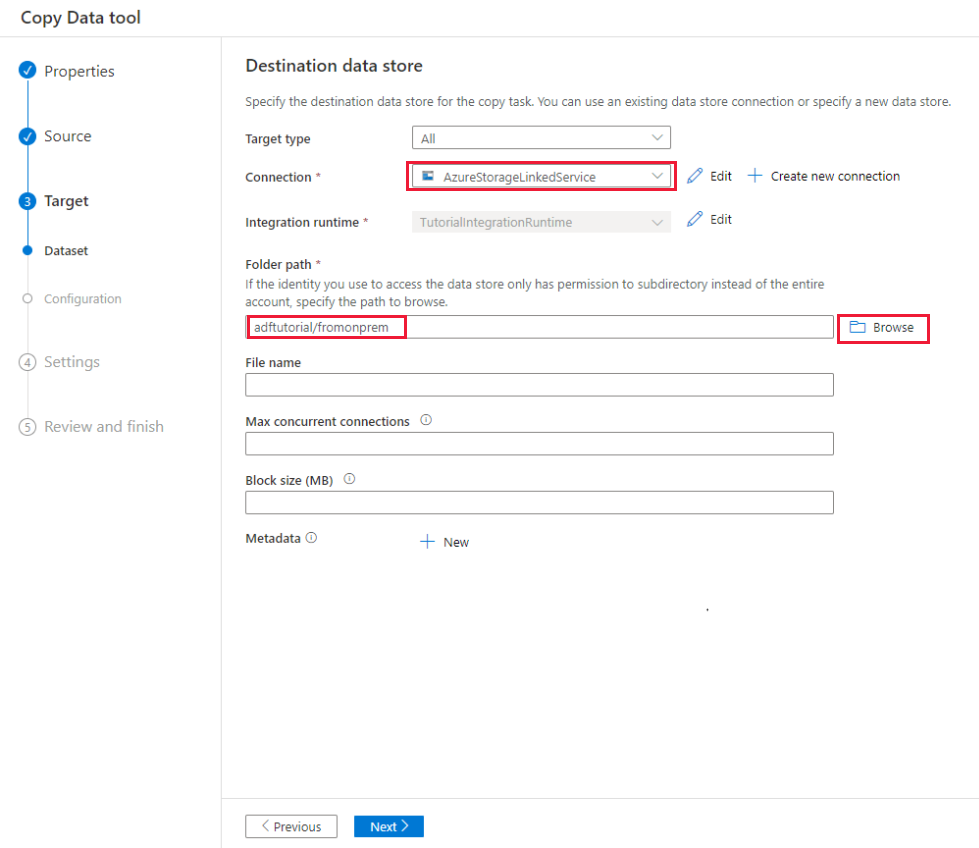
W oknie dialogowym Docelowy magazyn danych upewnij się, że nowo utworzone połączenie usługi Azure Blob Storage zostało wybrane w bloku Połączenie. Następnie w obszarze Ścieżka folderu wprowadź wartość adftutorial/fromonprem. Jako jedno z wymagań wstępnych został utworzony kontener adftutorial. Jeśli folder wyjściowy (w tym przykładzie fromonprem) nie istnieje, usługa Data Factory utworzy go automatycznie. Możesz również użyć przycisku Przeglądaj , aby przeglądać magazyn obiektów blob i jego kontenery/foldery. Jeśli nie wprowadzisz żadnej wartości w polu Nazwa pliku, domyślnie zostanie użyta nazwa źródła (w tym przykładzie dbo.emp).
W oknie dialogowym Ustawienia formatu pliku wybierz przycisk Dalej.
W oknie dialogowym Ustawienia w obszarze Nazwa zadania wprowadź wartość CopyFromOnPremSqlToAzureBlobPipeline, a następnie wybierz przycisk Dalej. Narzędzie do kopiowania danych tworzy potok o nazwie określonej w tym polu.
W oknie dialogowym Podsumowanie sprawdź wartości wszystkich ustawień, a następnie wybierz pozycję Dalej.
Na stronie Wdrażanie wybierz pozycję Monitorowanie, aby monitorować potok (zadanie).
Po zakończeniu przebiegu potoku można wyświetlić stan utworzonego potoku.
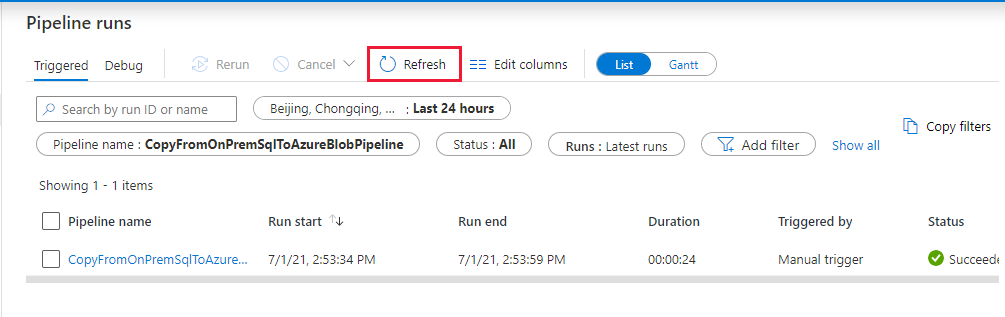
Na stronie "Uruchomienia potoku" wybierz pozycję Odśwież , aby odświeżyć listę. Wybierz link w obszarze Nazwa potoku, aby wyświetlić szczegóły przebiegu działania lub ponownie uruchomić potok.
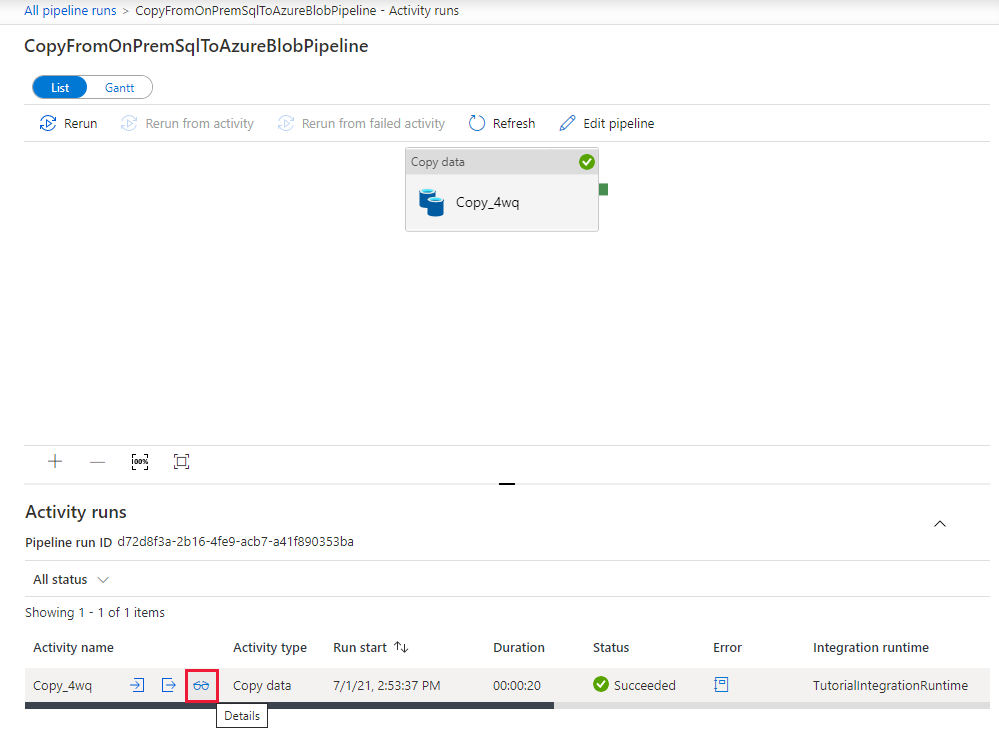
Na stronie "Uruchomienia działania" wybierz link Szczegóły (ikona okularów) w kolumnie Nazwa działania, aby uzyskać więcej informacji na temat operacji kopiowania. Aby wrócić do strony "Uruchomienia potoku", wybierz link Wszystkie uruchomienia potoku w menu stron nadrzędnych. Aby odświeżyć widok, wybierz pozycję Odśwież.
Upewnij się, że w folderze fromonprem kontenera adftutorial znajduje się plik wyjściowy.
Wybierz kartę Autor po lewej stronie, aby przełączyć się w tryb edytora. Za pomocą edytora można zaktualizować usługi połączone, zestawy danych i potoki utworzone przez narzędzie. Wybierz pozycję Kod, aby wyświetlić kod JSON skojarzony z jednostką otwartą w edytorze. Aby uzyskać szczegółowe informacje dotyczące sposobu edytowania tych jednostek w interfejsie użytkownika usługi Data Factory, zobacz wersję witryny Azure Portal używaną w tym samouczku.
Powiązana zawartość
Potok w tym przykładzie kopiuje dane z bazy danych programu SQL Server do usługi Blob Storage. W tym samouczku omówiono:
- Tworzenie fabryki danych.
- Tworzenie potoku za pomocą narzędzia do kopiowania danych.
- Monitorowanie uruchomień potoku i działań.
Lista magazynów danych obsługiwanych przez usługę Data Factory znajduje się w artykule Obsługiwane magazyny danych.
Aby dowiedzieć się, jak zbiorczo kopiować dane z lokalizacji źródłowej do docelowej, przejdź do następującego samouczka: