Przekształcanie agregacji w przepływie danych mapowania
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
Przepływy danych są dostępne zarówno w usłudze Azure Data Factory, jak i w potokach usługi Azure Synapse. Ten artykuł dotyczy przepływów danych mapowania. Jeśli dopiero zaczynasz transformacje, zapoznaj się z artykułem wprowadzającym Przekształcanie danych przy użyciu przepływu danych mapowania.
Przekształcenie agregacji definiuje agregacje kolumn w strumieniach danych. Za pomocą konstruktora wyrażeń można zdefiniować różne typy agregacji, takie jak SUM, MIN, MAX i COUNT pogrupowane według istniejących lub obliczonych kolumn.
Grupuj według
Wybierz istniejącą kolumnę lub utwórz nową obliczoną kolumnę do użycia jako klauzulę grupowania dla agregacji. Aby użyć istniejącej kolumny, wybierz ją z listy rozwijanej. Aby utworzyć nową kolumnę obliczeniową, umieść kursor nad klauzulą i kliknij pozycję Obliczona kolumna. Spowoduje to otwarcie konstruktora wyrażeń przepływu danych. Po utworzeniu obliczonej kolumny wprowadź nazwę kolumny wyjściowej w polu Nazwa jako . Jeśli chcesz dodać dodatkową klauzulę group by, umieść kursor nad istniejącą klauzulą i kliknij ikonę znaku plus.
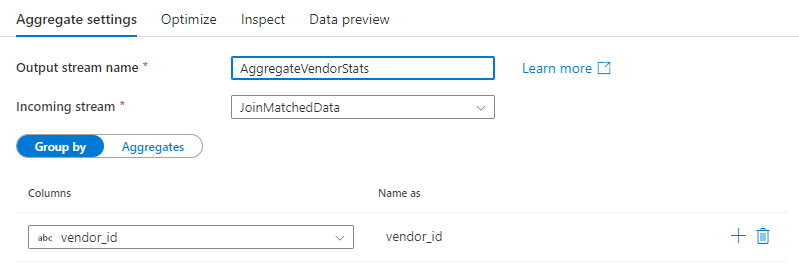
Klauzula Grupuj według jest opcjonalna w przekształceń agregacji.
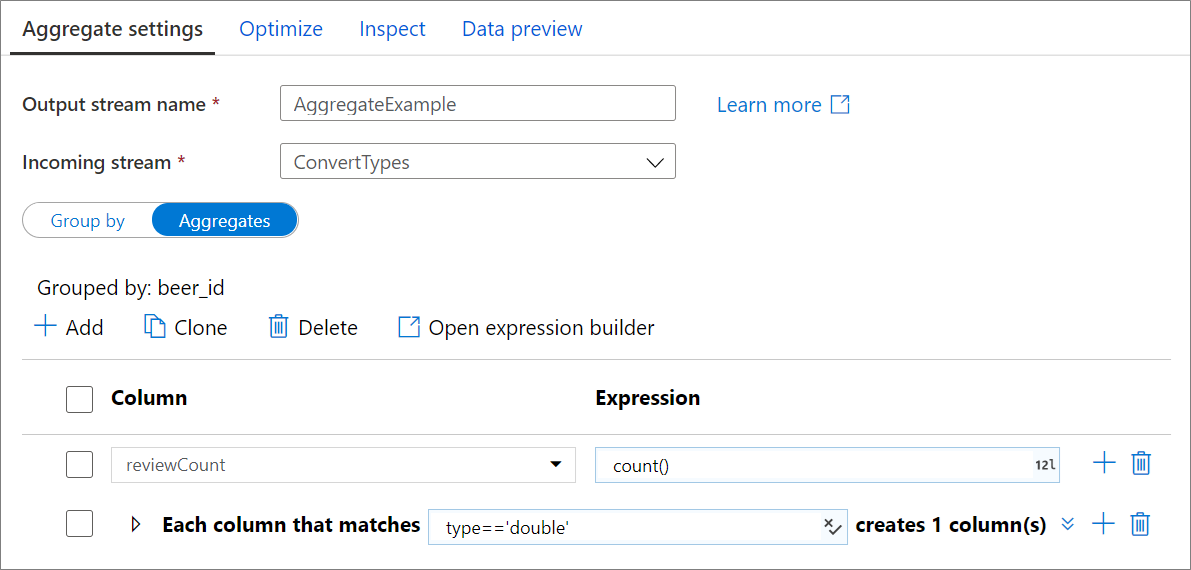
Agregowanie kolumn
Przejdź do karty Agregacje , aby utworzyć wyrażenia agregacji. Możesz zastąpić istniejącą kolumnę agregacją lub utworzyć nowe pole o nowej nazwie. Wyrażenie agregacji zostanie wprowadzone w polu po prawej stronie obok selektora nazwy kolumny. Aby edytować wyrażenie, kliknij pole tekstowe i otwórz konstruktora wyrażeń. Aby dodać więcej kolumn agregacji, kliknij pozycję Dodaj nad listą kolumn lub ikoną znaku plus obok istniejącej kolumny agregującej. Wybierz pozycję Dodaj kolumnę lub Dodaj wzorzec kolumny. Każde wyrażenie agregacji musi zawierać co najmniej jedną funkcję agregacji.
Uwaga
W trybie debugowania konstruktor wyrażeń nie może tworzyć podglądów danych za pomocą funkcji agregujących. Aby wyświetlić podglądy danych dla przekształceń zagregowanych, zamknij konstruktora wyrażeń i wyświetl dane za pomocą karty Podgląd danych.
Wzorce kolumn
Użyj wzorców kolumn, aby zastosować tę samą agregację do zestawu kolumn. Jest to przydatne, jeśli chcesz zachować wiele kolumn ze schematu wejściowego, ponieważ są one domyślnie porzucane. Użyj metody heurystycznej, takiej jak first() utrwalanie kolumn wejściowych za pośrednictwem agregacji.
Ponowne łączenie wierszy i kolumn
Przekształcenia agregacji są podobne do zapytań agregacji SQL. Kolumny, które nie są uwzględnione w grupie według klauzuli lub funkcje agregujące, nie będą przepływać do danych wyjściowych transformacji agregującej. Jeśli chcesz dołączyć inne kolumny do zagregowanych danych wyjściowych, wykonaj jedną z następujących metod:
- Użyj funkcji agregującej, takiej jak
last()lubfirst(), aby uwzględnić tę dodatkową kolumnę. - Ponownie dołącz kolumny do strumienia wyjściowego przy użyciu wzorca sprzężenia samodzielnego.
Usuwanie zduplikowanych wierszy
Typowym zastosowaniem przekształcenia agregacji jest usuwanie lub identyfikowanie zduplikowanych wpisów w danych źródłowych. Ten proces jest nazywany deduplikacją. Na podstawie zestawu grupowania według kluczy użyj heurystyki wybranej metody, aby określić, który zduplikowany wiersz ma być zachowany. Typowe heurystyki to first(), last(), max()i min(). Użyj wzorców kolumn, aby zastosować regułę do każdej kolumny z wyjątkiem grupowania według kolumn.
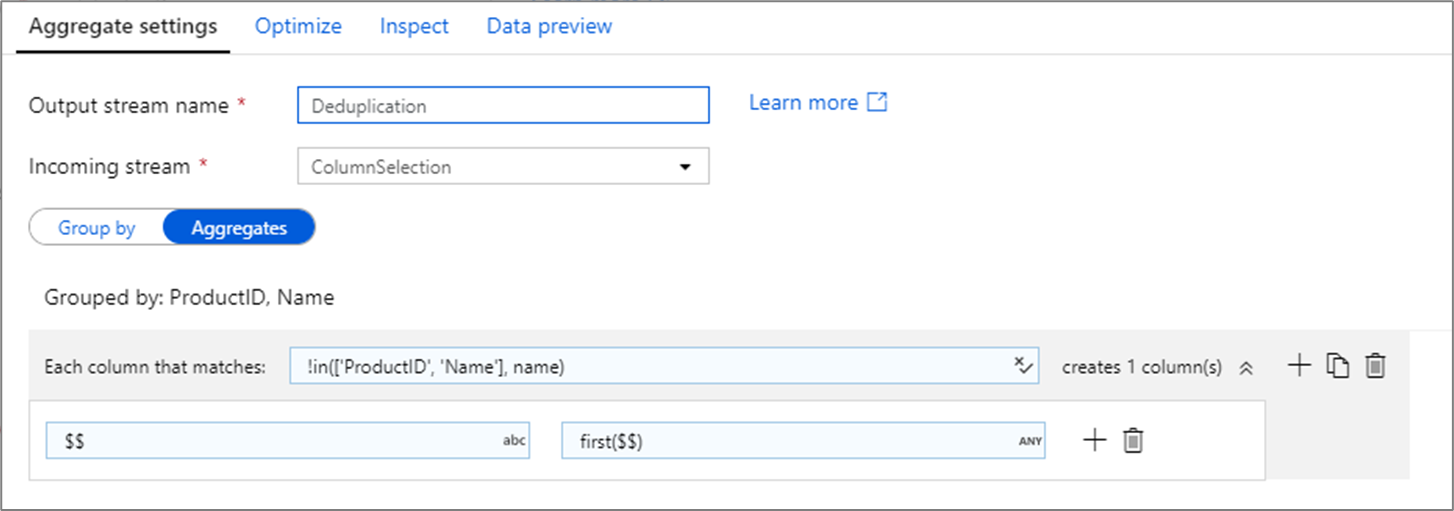
W powyższym przykładzie kolumny ProductID i Name są używane do grupowania. Jeśli dwa wiersze mają te same wartości dla tych dwóch kolumn, są traktowane jako duplikaty. W tej zagregowanej transformacji wartości pierwszego wiersza dopasowane zostaną zachowane, a wszystkie inne zostaną porzucone. Korzystając ze składni wzorca kolumny, wszystkie kolumny, których nazwy nie ProductID są i Name są mapowane na ich istniejącą nazwę kolumny i przy użyciu wartości pierwszych pasowanych wierszy. Schemat wyjściowy jest taki sam jak schemat wejściowy.
W przypadku scenariuszy count() weryfikacji danych funkcja może służyć do zliczenia liczby duplikatów.
Skrypt przepływu danych
Składnia
<incomingStream>
aggregate(
groupBy(
<groupByColumnName> = <groupByExpression1>,
<groupByExpression2>
),
<aggregateColumn1> = <aggregateExpression1>,
<aggregateColumn2> = <aggregateExpression2>,
each(
match(matchExpression),
<metadataColumn1> = <metadataExpression1>,
<metadataColumn2> = <metadataExpression2>
)
) ~> <aggregateTransformationName>
Przykład
W poniższym przykładzie strumień MoviesYear przychodzący i grupuje wiersze według kolumny year. Przekształcenie tworzy kolumnę avgrating agregacji, która daje w ocenie średnią kolumny Rating. Ta transformacja agregacji nosi nazwę AvgComedyRatingsByYear.
W interfejsie użytkownika ta transformacja wygląda jak na poniższej ilustracji:
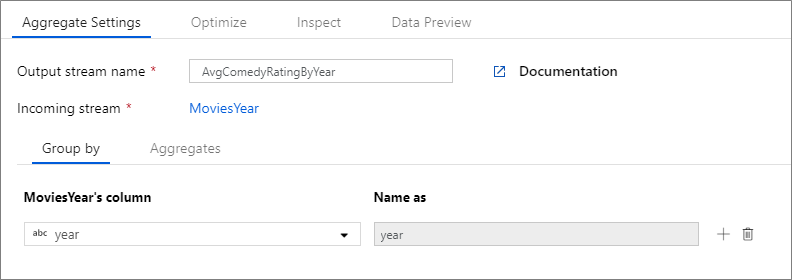
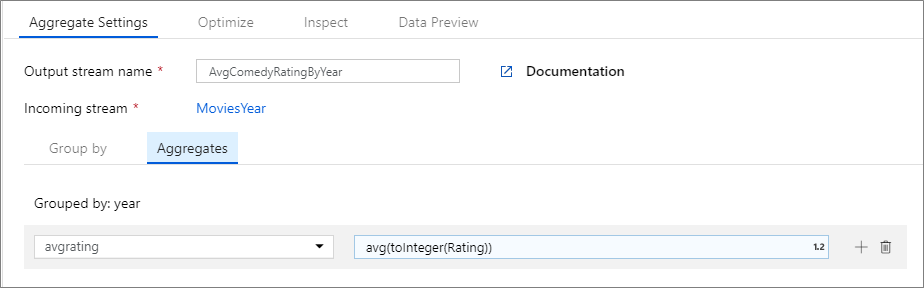
Skrypt przepływu danych dla tej transformacji znajduje się w poniższym fragmencie kodu.
MoviesYear aggregate(
groupBy(year),
avgrating = avg(toInteger(Rating))
) ~> AvgComedyRatingByYear
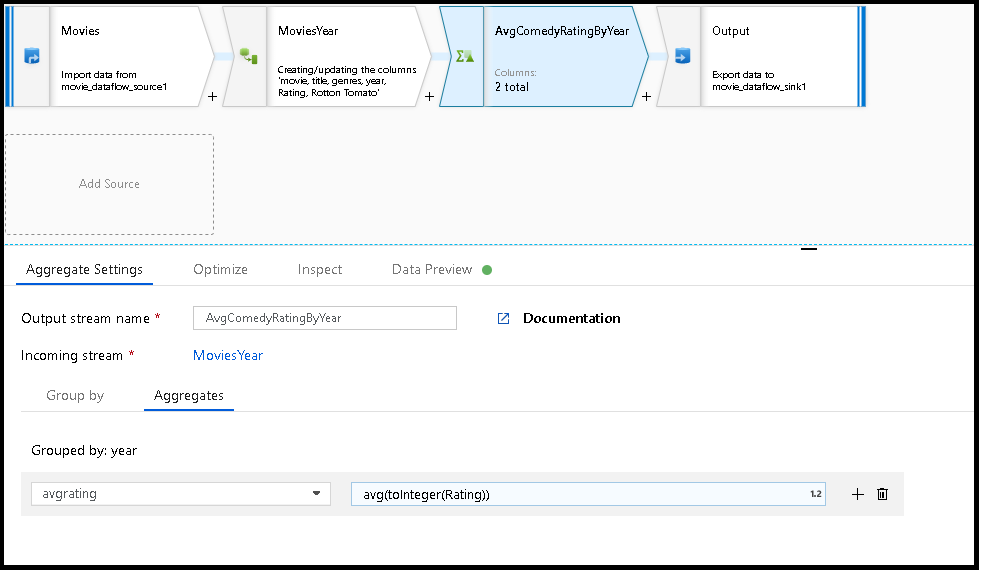
MoviesYear: Kolumna pochodna definiująca rok i kolumny AvgComedyRatingByYeartytułu: Przekształcenie agregacji dla średniej klasyfikacji komedii pogrupowanych według roku avgrating: Nazwa nowej kolumny tworzonej w celu przechowywania zagregowanej wartości
MoviesYear aggregate(groupBy(year),
avgrating = avg(toInteger(Rating))) ~> AvgComedyRatingByYear
Powiązana zawartość
- Definiowanie agregacji opartej na oknach przy użyciu przekształcenia okna