Kompilowanie wyrażeń w przepływie danych mapowania
DOTYCZY:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
W przepływie danych mapowania wiele właściwości przekształcania jest wprowadzanych jako wyrażenia. Te wyrażenia składają się z wartości kolumn, parametrów, funkcji, operatorów i literałów, które oceniają typ danych platformy Spark w czasie wykonywania. Przepływy danych mapowania mają dedykowane środowisko ułatwiające tworzenie tych wyrażeń nazywanych konstruktorem wyrażeń. Korzystając z uzupełniania kodu IntelliSense w celu wyróżniania, sprawdzania składni i autouzupełniania, konstruktor wyrażeń został zaprojektowany w celu ułatwienia tworzenia przepływów danych. W tym artykule wyjaśniono, jak efektywnie tworzyć logikę biznesową za pomocą konstruktora wyrażeń.
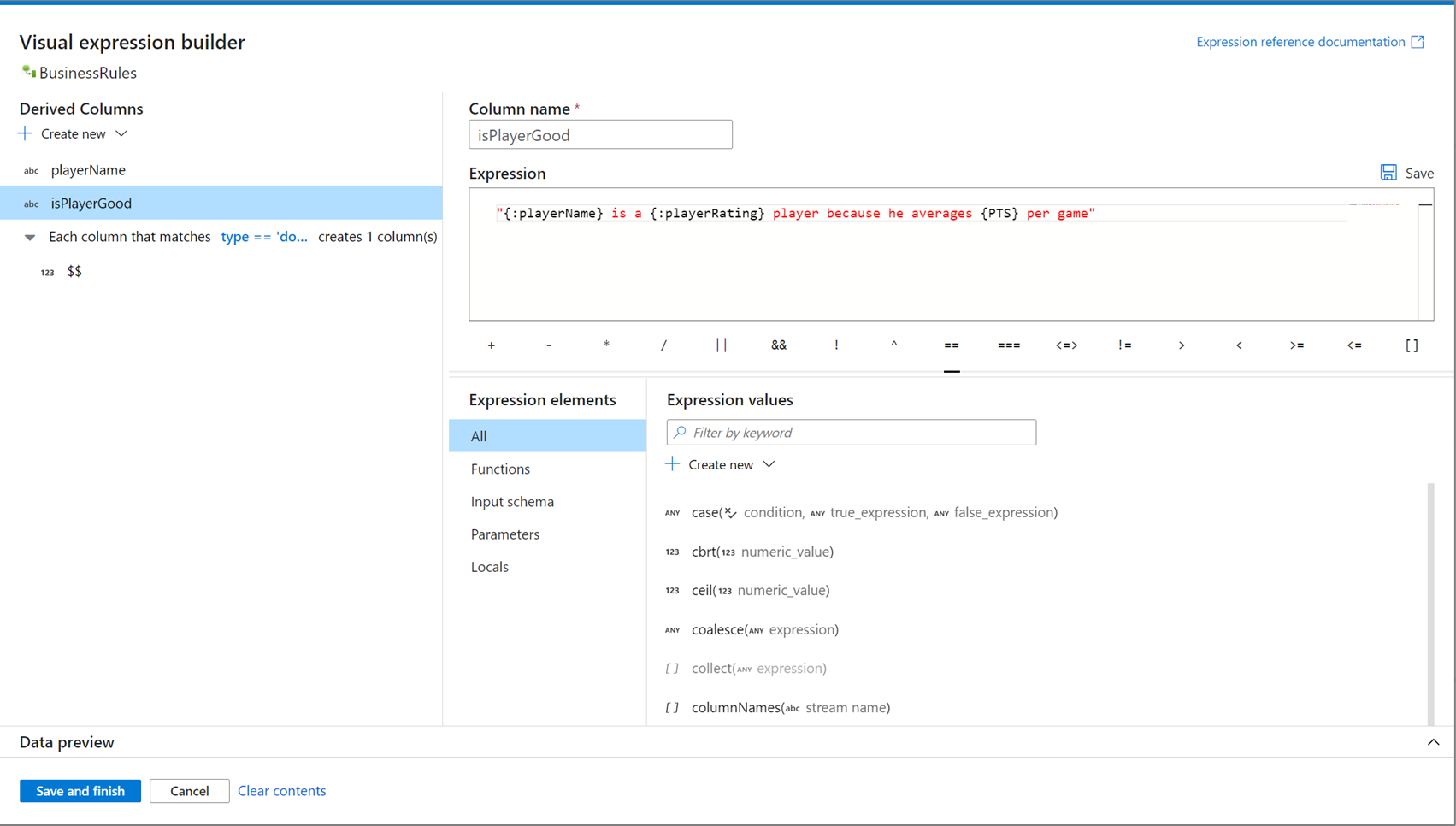
Otwórz konstruktor wyrażeń
Istnieje wiele punktów wejścia do otwarcia konstruktora wyrażeń. Są one zależne od konkretnego kontekstu transformacji przepływu danych. Najczęstszym przypadkiem użycia są przekształcenia, takie jak kolumna pochodna i agregacja , w których użytkownicy tworzą lub aktualizują kolumny przy użyciu języka wyrażeń przepływu danych. Konstruktor wyrażeń można otworzyć, wybierając pozycję Otwórz konstruktor wyrażeń nad listą kolumn. Możesz również wybrać kontekst kolumny i otworzyć konstruktora wyrażeń bezpośrednio do tego wyrażenia.
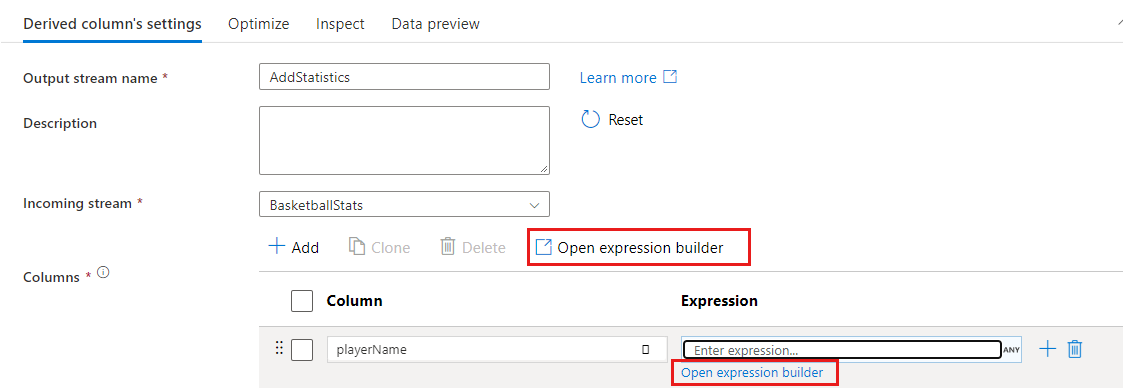
W niektórych przekształceniach, takich jak filtr, kliknięcie niebieskiego pola tekstowego wyrażenia powoduje otwarcie konstruktora wyrażeń.
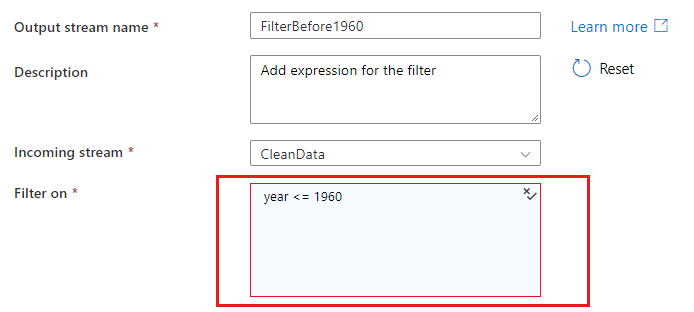
Jeśli odwołujesz się do kolumn w warunku dopasowania lub grupowania, wyrażenie może wyodrębnić wartości z kolumn. Aby utworzyć wyrażenie, wybierz pozycję Obliczona kolumna.

W przypadkach, gdy wyrażenie lub wartość literału są prawidłowymi danymi wejściowymi, wybierz pozycję Dodaj zawartość dynamiczną, aby utworzyć wyrażenie, które daje w wyniku wartość literału.

Elementy wyrażeń
W przepływach danych mapowania wyrażenia mogą składać się z wartości kolumn, parametrów, funkcji, zmiennych lokalnych, operatorów i literałów. Te wyrażenia muszą mieć wartość typu danych platformy Spark, takiego jak ciąg, wartość logiczna lub liczba całkowita.
Funkcje
Przepływy danych mapowania mają wbudowane funkcje i operatory, których można używać w wyrażeniach. Aby uzyskać listę dostępnych funkcji, zobacz dokumentację języka przepływu mapowania danych.
Funkcje zdefiniowane przez użytkownika (wersja zapoznawcza)
Przepływy mapowania danych obsługują tworzenie i używanie funkcji zdefiniowanych przez użytkownika. Aby zobaczyć, jak tworzyć funkcje zdefiniowane przez użytkownika i korzystać z nich, zobacz funkcje zdefiniowane przez użytkownika.
Indeksy tablicy adresów
Gdy masz do czynienia z kolumnami lub funkcjami, które zwracają typy tablic, użyj nawiasów kwadratowych ([]), aby uzyskać dostęp do określonego elementu. Jeśli indeks nie istnieje, wyrażenie oblicza wartość null.
Ważne
W przepływach danych mapowania tablice są oparte na jednym znaczeniu, że pierwszy element jest przywołyyny przez indeks jeden. Na przykład myArray[1] będzie uzyskiwać dostęp do pierwszego elementu tablicy o nazwie "myArray".
Schemat wejściowy
Jeśli przepływ danych używa zdefiniowanego schematu w dowolnym z jego źródeł, możesz odwołać się do kolumny według nazwy w wielu wyrażeniach. Jeśli używasz dryfu schematu, możesz odwoływać się do kolumn jawnie przy użyciu funkcji lub byNames() lub dopasować przy użyciu byName() wzorców kolumn.
Nazwy kolumn ze znakami specjalnymi
Jeśli masz nazwy kolumn, które zawierają znaki specjalne lub spacje, umieść nazwę nawiasami klamrowymi, aby odwoływać się do nich w wyrażeniu.
{[dbo].this_is my complex name$$$}
Parametry
Parametry to wartości przekazywane do przepływu danych w czasie wykonywania z potoku. Aby odwołać się do parametru, wybierz parametr z widoku Elementy wyrażenia lub odwołaj się do niego za pomocą znaku dolara przed jego nazwą. Na przykład parametr o nazwie parameter1 jest przywołyny przez $parameter1polecenie . Aby dowiedzieć się więcej, zobacz parametryzowanie przepływów danych mapowania.
Buforowane wyszukiwanie
Buforowane wyszukiwanie umożliwia wykonywanie wbudowanego wyszukiwania danych wyjściowych buforowanego ujścia. Dla każdego ujścia dostępne są dwie funkcje i lookup() outputs(). Składnią odwołującą się do tych funkcji jest cacheSinkName#functionName(). Aby uzyskać więcej informacji, zobacz ujścia pamięci podręcznej.
lookup() przyjmuje pasujące kolumny w bieżącej transformacji jako parametry i zwraca złożoną kolumnę równą wierszowi odpowiadającemu kolumnom klucza w ujściu pamięci podręcznej. Zwracana kolumna złożona zawiera kolumnę podrzędną dla każdej kolumny zamapowanej w ujściu pamięci podręcznej. Jeśli na przykład ujście errorCodeCache pamięci podręcznej kodu błędu zawiera kolumnę klucza pasującą do kodu i kolumnę o nazwie Message. Wywołanie errorCodeCache#lookup(errorCode).Message spowoduje zwrócenie komunikatu odpowiadającego kodowi przekazanemu.
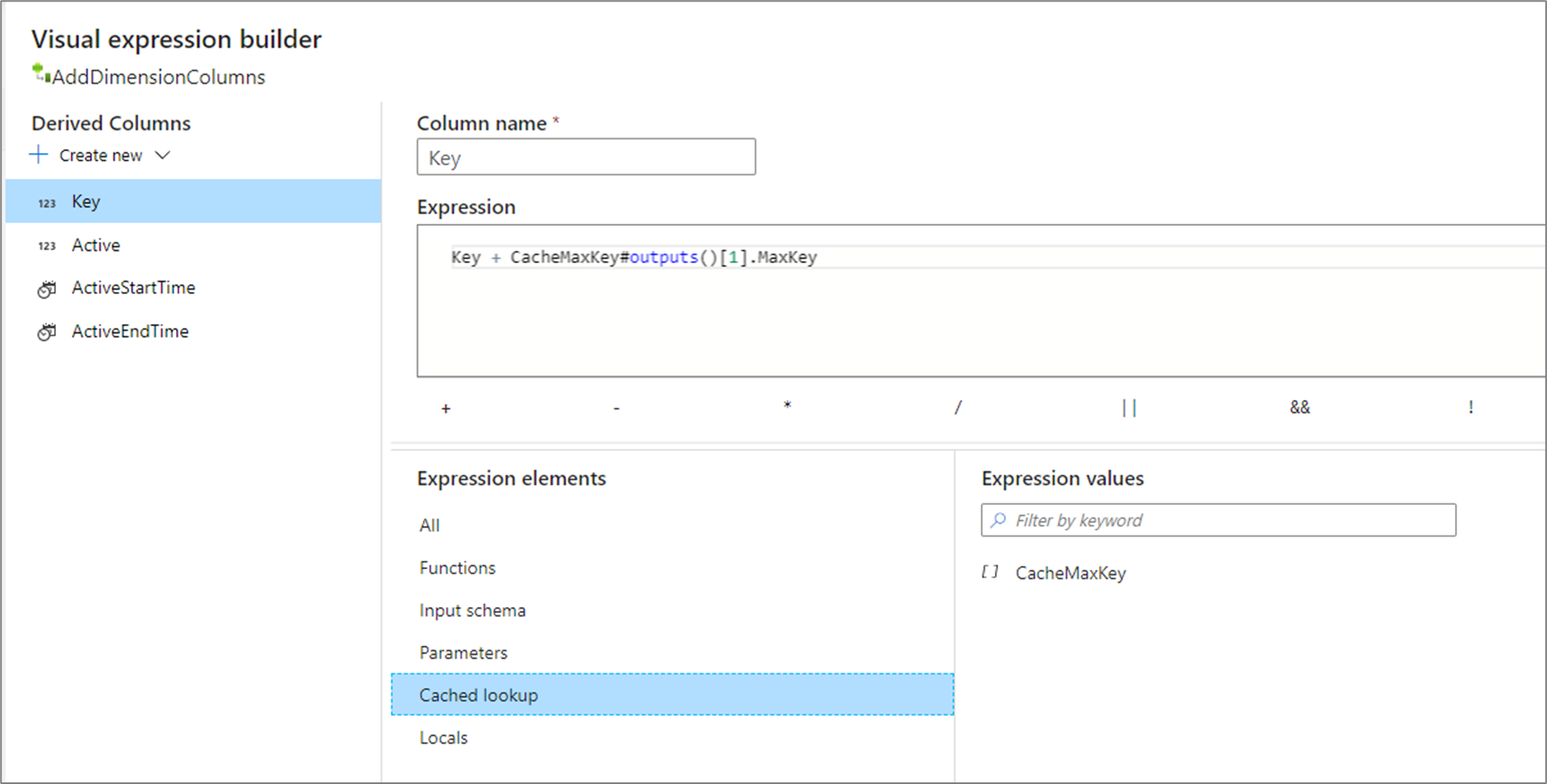
outputs() nie przyjmuje parametrów i zwraca cały ujście pamięci podręcznej jako tablicę złożonych kolumn. Nie można tego wywołać, jeśli kolumny kluczy są określone w ujściu i powinny być używane tylko w przypadku kilku wierszy w ujściu pamięci podręcznej. Typowy przypadek użycia dołącza maksymalną wartość klucza przyrostowego. Jeśli buforowany pojedynczy zagregowany wiersz CacheMaxKey zawiera kolumnę MaxKey, możesz odwołać się do pierwszej wartości, wywołując metodę CacheMaxKey#outputs()[1].MaxKey.
Zmienne lokalne
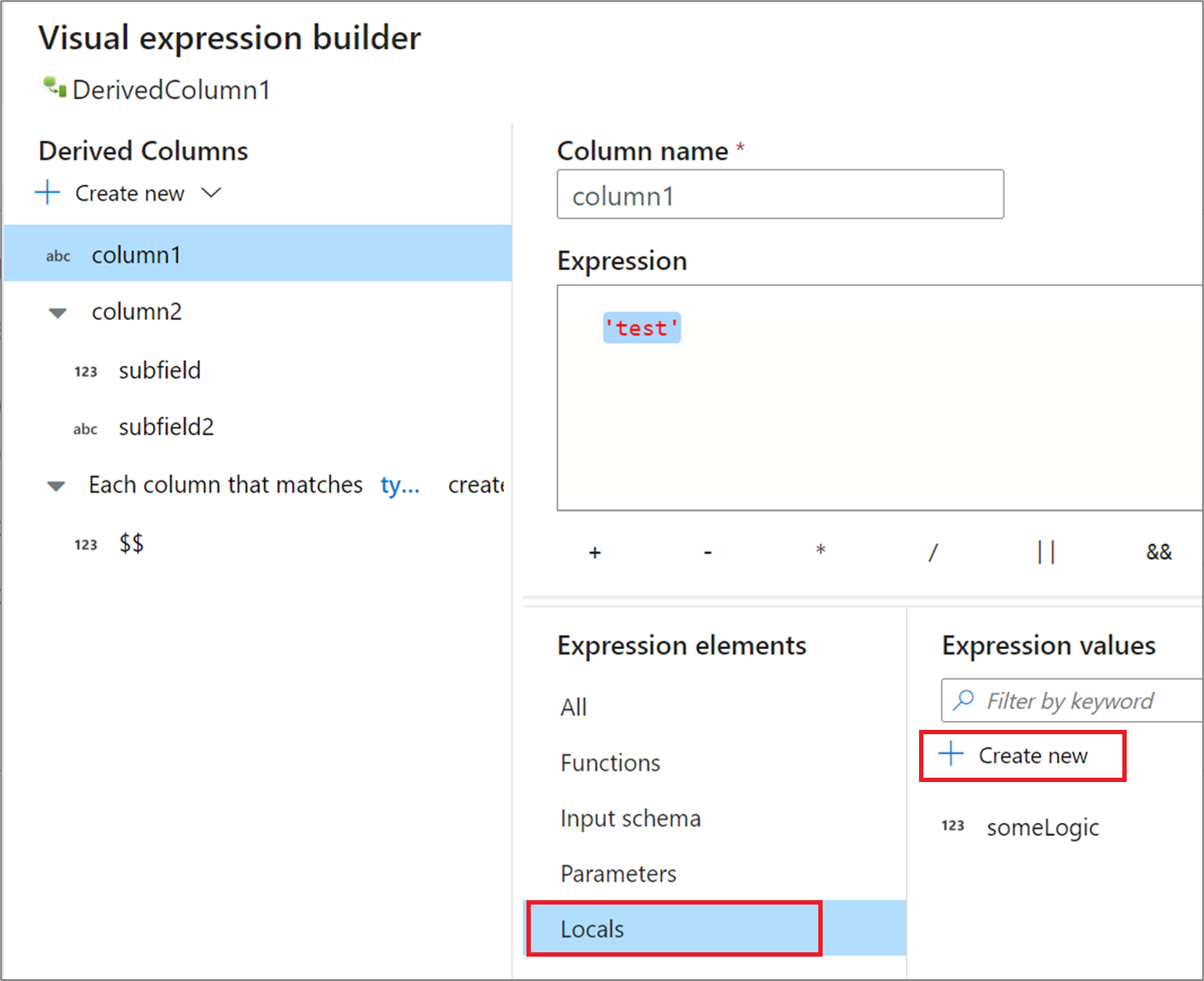
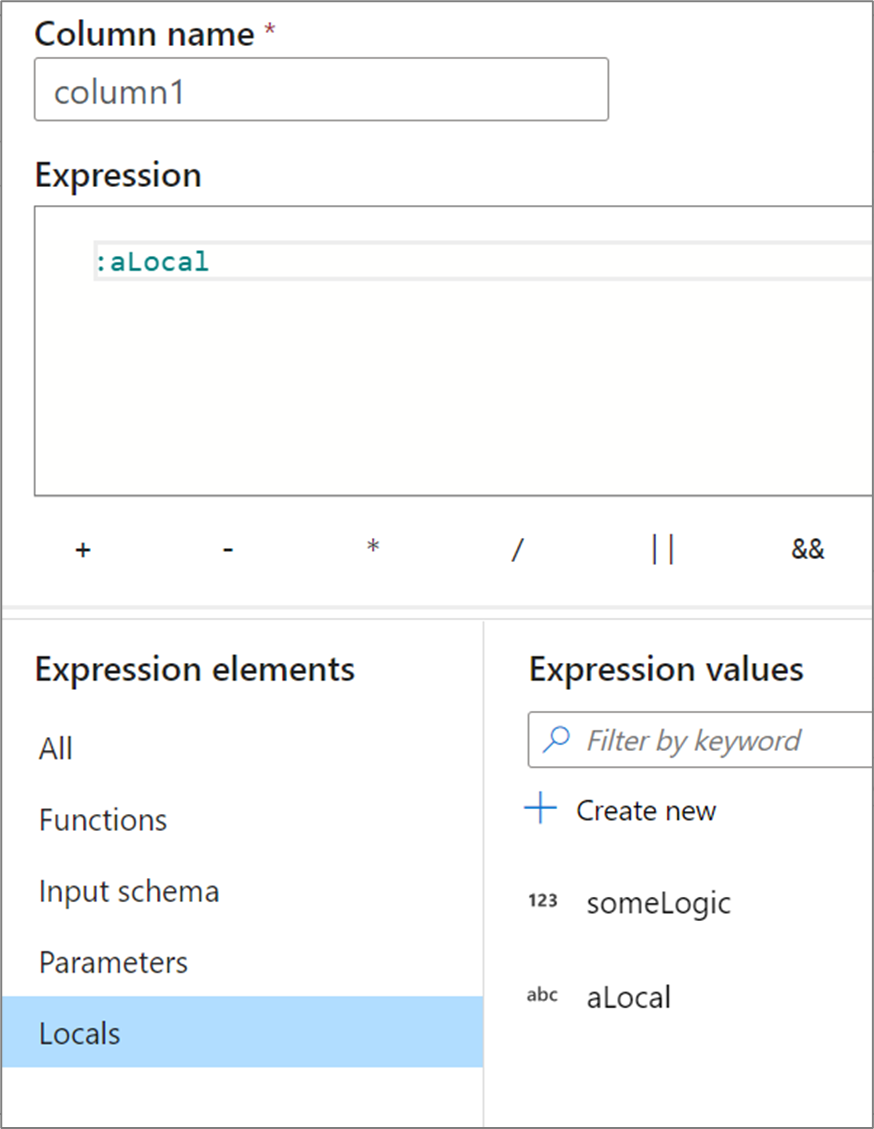
Jeśli udostępniasz logikę w wielu kolumnach lub chcesz podzielić logikę na podział, możesz utworzyć zmienną lokalną. Lokalny jest zestawem logiki, która nie jest propagowana podrzędnie do następującej transformacji. Ustawienia lokalne można utworzyć w konstruktorze wyrażeń, przechodząc do pozycji Elementy wyrażeń i wybierając pozycję Ustawienia lokalne. Utwórz nowy, wybierając pozycję Utwórz nową.
Ustawienia lokalne mogą odwoływać się do dowolnego elementu wyrażenia, w tym funkcji, schematu wejściowego, parametrów i innych ustawień lokalnych. W przypadku odwoływania się do innych ustawień lokalnych kolejność ma znaczenie, ponieważ przywołyną lokalną wartość musi być "powyżej" bieżącej.
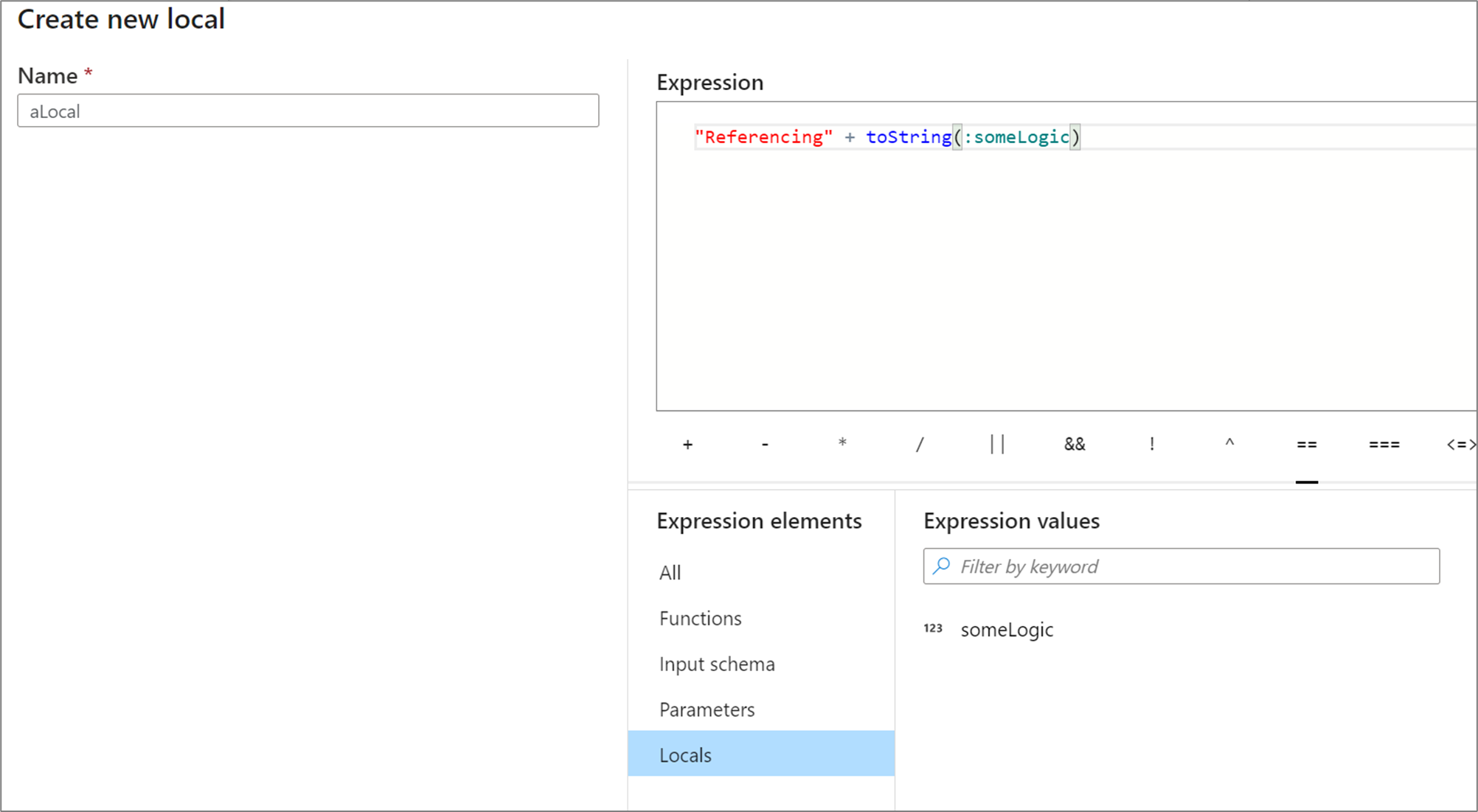
Aby odwołać się do lokalnego w transformacji, wybierz lokalny z widoku elementy wyrażenia lub odwołaj się do niego dwukropkiem przed jego nazwą. Na przykład lokalny o nazwie local1 będzie odwoływał się do elementu :local1. Aby edytować definicję lokalną, umieść kursor na niej w widoku elementów wyrażeń i wybierz ikonę ołówka.
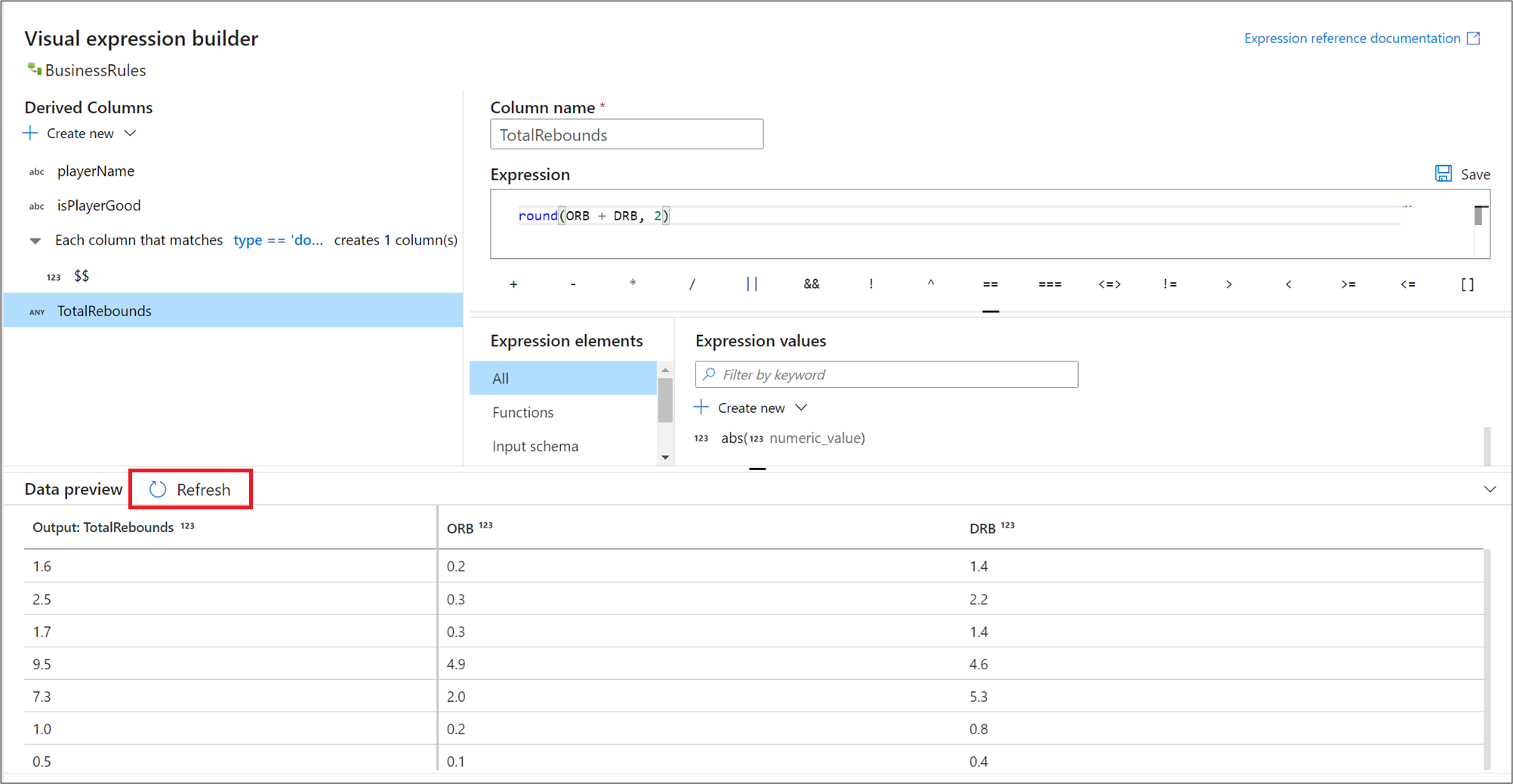
Podgląd wyników wyrażeń
Jeśli tryb debugowania jest włączony, możesz interaktywnie użyć klastra debugowania, aby wyświetlić podgląd wartości wyrażenia. Wybierz pozycję Odśwież obok podglądu danych, aby zaktualizować wyniki podglądu danych. Dane wyjściowe poszczególnych wierszy można wyświetlić, biorąc pod uwagę kolumny wejściowe.
Interpolacja ciągów
Podczas tworzenia długich ciągów, które używają elementów wyrażeń, użyj interpolacji ciągów, aby łatwo utworzyć złożoną logikę ciągów. Interpolacja ciągów pozwala uniknąć szerokiego użycia łączenia ciągów, gdy parametry są uwzględniane w ciągach zapytania. Użyj podwójnych cudzysłowów, aby ująć tekst ciągu literału razem z wyrażeniami. Możesz uwzględnić funkcje wyrażeń, kolumny i parametry. Aby użyć składni wyrażeń, należy ująć ją w nawiasy klamrowe,
Kilka przykładów interpolacji ciągów:
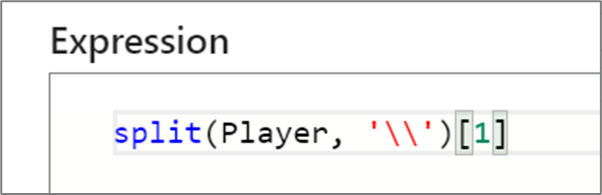
"My favorite movie is {iif(instr(title,', The')>0,"The {split(title,', The')[1]}",title)}""select * from {$tablename} where orderyear > {$year}""Total cost with sales tax is {round(totalcost * 1.08,2)}""{:playerName} is a {:playerRating} player"
Uwaga
W przypadku używania składni interpolacji ciągów w zapytaniach źródłowych SQL ciąg zapytania musi znajdować się w jednym wierszu bez ciągu "/n".
Komentowanie wyrażeń
Dodaj komentarze do wyrażeń przy użyciu składni komentarza jednowierszowego i wielowierszowego.
Następujące przykłady są prawidłowymi komentarzami:
/* This is my comment *//* This is amulti-line comment */
Jeśli umieścisz komentarz w górnej części wyrażenia, pojawi się on w polu tekstowym przekształcenia, aby udokumentować wyrażenia przekształcenia.

Wyrażenia regularne
Wiele funkcji języka wyrażeń używa składni wyrażeń regularnych. Gdy używasz funkcji wyrażeń regularnych, konstruktor wyrażeń próbuje interpretować ukośnik odwrotny (\) jako sekwencję znaków ucieczki. W przypadku używania ukośników odwrotnych w wyrażeniu regularnym należy ująć cały regex w backticks (') lub użyć podwójnego ukośnika odwrotnego.
Przykład, który używa zaplecza:
regex_replace('100 and 200', `(\d+)`, 'digits')
Przykład, który używa podwójnych ukośników:
regex_replace('100 and 200', '(\\d+)', 'digits')
Skróty klawiaturowe
Poniżej znajduje się lista skrótów dostępnych w konstruktorze wyrażeń. Większość skrótów intellisense jest dostępna podczas tworzenia wyrażeń.
- Ctrl+K Ctrl+C: Komentowanie całego wiersza.
- Ctrl+K Ctrl+U: Usuń komentarz.
- F1: podaj polecenia pomocy edytora.
- Alt+Strzałka w dół: Przenieś w dół bieżącą linię.
- Alt+Strzałka w górę: Przenieś w górę bieżącą linię.
- Ctrl+Spacja: Pokaż pomoc kontekstową.
Często używane wyrażenia
Konwertowanie na daty lub znaczniki czasu
Aby uwzględnić literały ciągu w danych wyjściowych znacznika czasu, opakuj konwersję w pliku toString().
toString(toTimestamp('12/31/2016T00:12:00', 'MM/dd/yyyy\'T\'HH:mm:ss'), 'MM/dd /yyyy\'T\'HH:mm:ss')
Aby przekonwertować milisekundy z epoki na datę lub znacznik czasu, użyj polecenia toTimestamp(<number of milliseconds>). Jeśli czas zbliża się w sekundach, pomnóż przez 1000.
toTimestamp(1574127407*1000l)
Końcowy znak "l" na końcu poprzedniego wyrażenia oznacza konwersję na długi typ jako składnia śródliniowa.
Znajdowanie czasu z epoki lub czasu systemu Unix
toLong( currentTimestamp() — toTimestamp('1970-01-01 00:00:00.000', 'rrrr-MM-dd HH:mm:ss. SSS) ) * 1000l
Ocena czasu przepływu danych
Przepływ danych przetwarza do milisekund. W przypadku 2018-07-31T20:00:00.2170000 zobaczysz dane wyjściowe 2018-07-31T20:00:00.217. W portalu dla usługi znacznik czasu jest wyświetlany w bieżącym ustawieniu przeglądarki, co może wyeliminować 217, ale po zakończeniu przepływu danych zostanie zakończone, 217 (część milisekund jest również przetwarzana). Możesz użyć funkcji toString(myDateTimeColumn) jako wyrażenia i wyświetlić pełnej precyzji danych w wersji zapoznawczej. Przetwarzanie daty/godziny jako daty/godziny, a nie ciągu dla wszystkich celów praktycznych.