Zarządzanie skalowaniem w pionie klastra (skalowanie w górę) w usłudze Azure Data Explorer w celu uwzględnienia zmieniających się wymagań
Odpowiednie określanie rozmiaru klastra ma kluczowe znaczenie dla wydajności usługi Azure Data Explorer. Statyczny rozmiar klastra może prowadzić do niedostatecznego wykorzystania lub nadmiernego wykorzystania i żaden z tych przypadków nie jest idealny.
Ponieważ zapotrzebowanie na klaster nie może być przewidywane z bezwzględną dokładnością, lepszym rozwiązaniem jest skalowanie klastra, dodawanie i usuwanie pojemności oraz zasobów procesora CPU ze zmieniającym się zapotrzebowaniem.
Istnieją dwa przepływy pracy do skalowania klastra usługi Azure Data Explorer:
- Skalowanie w poziomie, nazywane również skalowaniem w poziomie i na poziomie.
- Skalowanie w pionie, nazywane również skalowaniem w górę i w dół.
W tym artykule wyjaśniono przepływ pracy skalowania w pionie:
Konfigurowanie skalowania w pionie
W Azure Portal przejdź do zasobu klastra usługi Azure Data Explorer. W obszarze Ustawienia wybierz pozycję Skaluj w górę.
W oknie Skalowanie w górę zobaczysz dostępne jednostki SKU dla klastra. Na przykład na poniższej ilustracji dostępnych jest osiem zalecanych jednostek SKU. Rozwiń listę rozwijaną Zoptymalizowane pod kątem magazynu, Zoptymalizowane pod kątem obliczeń i Tworzenie/testowanie , aby wyświetlić więcej opcji.
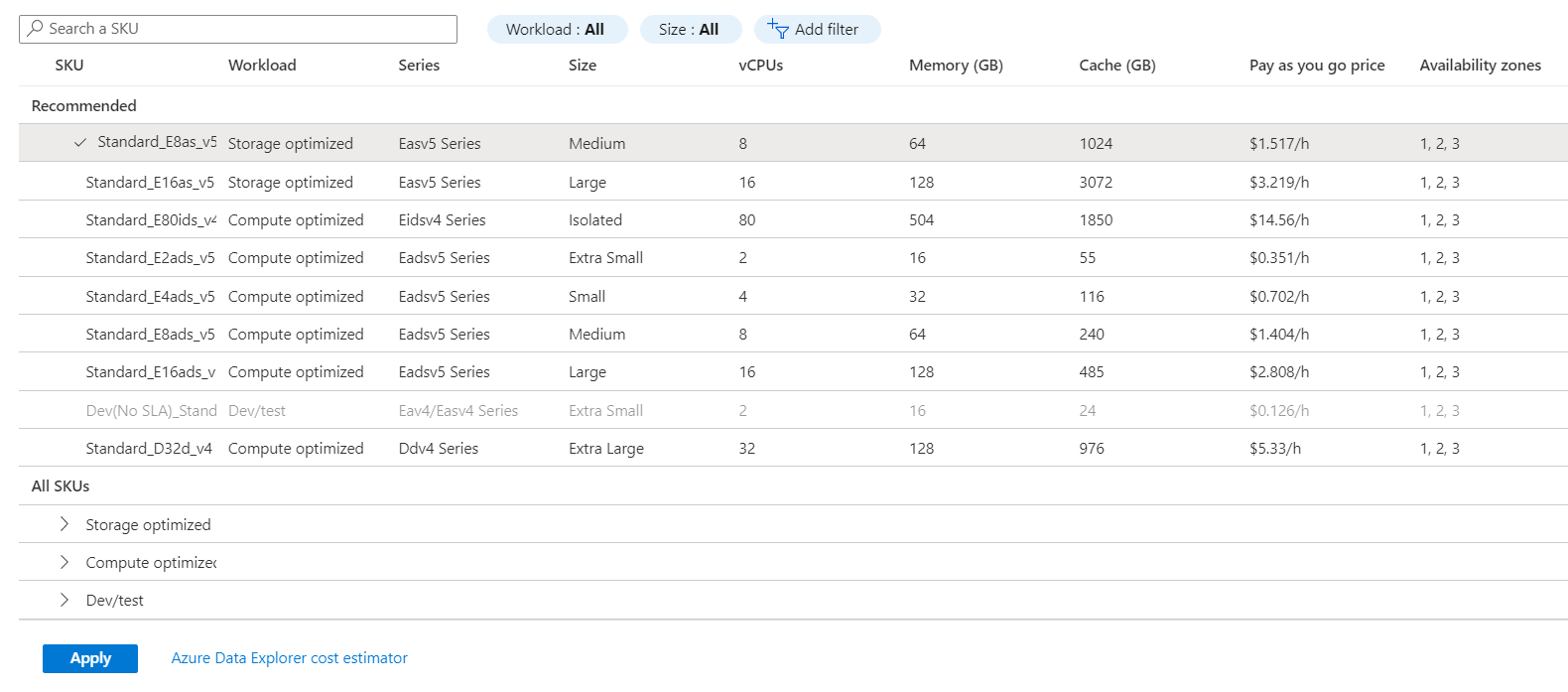
Jednostki SKU są wyłączone, ponieważ są one bieżącą jednostkę SKU lub nie są dostępne w regionie, w którym znajduje się klaster.
Aby zmienić jednostkę SKU, wybierz nową jednostkę SKU, a następnie wybierz pozycję Zastosuj.
Uwaga
- Podczas procesu skalowania w pionie, podczas gdy zasoby nowego klastra są przygotowane do ciągłego świadczenia usługi przez stary klaster. Ten proces może potrwać dziesiątki minut. Przełączenie do nowego klastra jest wykonywane tylko wtedy, gdy zasoby nowego klastra są gotowe. Proces równoległy sprawia, że środowisko migracji jednostki SKU jest stosunkowo bezproblemowe, przy minimalnych zakłóceniach usługi podczas procesu przełączania, który trwa około jednej do trzech minut. Wydajność zapytań może mieć wpływ na migrację jednostki SKU. Wpływ może się różnić ze względu na wzorce użycia.
- Zalecamy włączenie zoptymalizowanego autoskalowania , aby umożliwić klastrowi skalowanie w poziomie po migracji. Aby uzyskać rekomendację dotyczącą migracji jednostek SKU, zobacz Zmienianie klastrów Data Explorer na bardziej opłacalną i wydajną jednostkę SKU.
- Klastry z konfiguracją Virtual Network mogą mieć dłuższe przerwy w działaniu usługi.
- Cena jest oszacowaniem kosztów maszyn wirtualnych klastra i usługi Azure Data Explorer. Inne koszty nie są uwzględniane. Aby uzyskać oszacowanie, zobacz narzędzie do szacowania kosztów platformy Azure Data Explorer. Aby uzyskać pełną cenę, zobacz stronę cennika usługi Azure Data Explorer.
Skonfigurowano skalowanie w pionie dla klastra usługi Azure Data Explorer. Dodaj kolejną regułę skalowania w poziomie. Jeśli potrzebujesz pomocy dotyczącej problemów ze skalowaniem klastra, otwórz wniosek o pomoc techniczną w Azure Portal.
Zawartość pokrewna
- Zarządzanie skalowaniem w poziomie klastra w celu dynamicznego skalowania liczby wystąpień na podstawie określonych metryk.
- Monitorowanie wydajności, kondycji i użycia usługi Azure Data Explorer za pomocą metryk.