Ciągłość działania i odzyskiwanie po awarii - informacje ogólne
Ciągłość działalności biznesowej i odzyskiwanie po awarii w usłudze Azure Data Explorer umożliwia firmie kontynuowanie działania w obliczu zakłóceń. W tym artykule omówiono dostępność (wewnątrz regionów) i odzyskiwanie po awarii. Szczegóły natywnych możliwości i zagadnień dotyczących architektury dla odpornego wdrożenia usługi Azure Data Explorer. Szczegóły odzyskiwania po błędach ludzkich, wysoka dostępność, a następnie wiele konfiguracji odzyskiwania po awarii. Te konfiguracje zależą od wymagań dotyczących odporności, takich jak cel punktu odzyskiwania (RPO) i cel czasu odzyskiwania (RTO), wymagane nakłady pracy i koszty.
Eliminowanie zdarzeń zakłócających działanie
- Błąd ludzki
- Wysoka dostępność usługi Azure Data Explorer
- Awaria strefy dostępności platformy Azure
- Awaria centrum danych platformy Azure
- Awaria regionu świadczenia usługi Azure
Błąd ludzki
Błędy ludzkie są nieuniknione. Użytkownicy mogą przypadkowo usunąć klaster, bazę danych lub tabelę.
Przypadkowe usunięcie klastra lub bazy danych
Przypadkowe usunięcie klastra lub bazy danych jest akcją nieodwracalną. Jako właściciel zasobu usługi Azure Data Explorer możesz zapobiec utracie danych, włączając funkcję blokowania usuwania dostępną na poziomie zasobu platformy Azure.
Przypadkowe usunięcie tabeli
Użytkownicy z uprawnieniami administratora tabeli lub wyższymi mogą usuwać tabele. Jeśli jeden z tych użytkowników przypadkowo popadnie w tabelę, możesz ją odzyskać przy użyciu .undo drop table polecenia . Aby to polecenie powiodło się, należy najpierw włączyć właściwość możliwości odzyskiwania w zasadach przechowywania.
Przypadkowe usunięcie tabeli zewnętrznej
Tabele zewnętrzne to jednostki schematu zapytań Kusto odwołujące się do danych przechowywanych poza bazą danych. Usunięcie tabeli zewnętrznej powoduje usunięcie tylko metadanych tabeli. Możesz go odzyskać, ponownie wykonując polecenie tworzenia tabeli. Użyj funkcji usuwania nietrwałego, aby chronić przed przypadkowym usunięciem lub zastąpieniem pliku/obiektu blob przez czas skonfigurowany przez użytkownika.
Wysoka dostępność usługi Azure Data Explorer
Wysoka dostępność odnosi się do odporności na uszkodzenia usługi Azure Data Explorer, jej składników i podstawowych zależności w regionie świadczenia usługi Azure. Ta odporność na uszkodzenia pozwala uniknąć pojedynczych punktów awarii (SPOF) w implementacji. W usłudze Azure Data Explorer wysoka dostępność obejmuje warstwę trwałości, warstwę obliczeniową i konfigurację lidera.
Warstwa trwałości
Usługa Azure Data Explorer korzysta z usługi Azure Storage jako trwałej warstwy trwałości. Usługa Azure Storage automatycznie zapewnia odporność na uszkodzenia, a ustawienie domyślne oferuje magazyn lokalnie nadmiarowy (LRS) w centrum danych. Trzy repliki są utrwalane. Jeśli replika zostanie utracona podczas używania, zostanie wdrożona bez zakłóceń. Dodatkowa odporność jest możliwa w przypadku magazynu strefowo nadmiarowego (ZRS), który umieszcza repliki inteligentnie w regionalnych strefach dostępności platformy Azure w celu zapewnienia maksymalnej odporności na uszkodzenia przy dodatkowych kosztach. Magazyn z włączonym magazynem ZRS jest automatycznie konfigurowany po wdrożeniu klastra usługi Azure Data Explorer w Strefy dostępności.
Warstwa obliczeniowa
Usługa Azure Data Explorer jest rozproszoną platformą obliczeniową i może mieć dwa do wielu węzłów w zależności od typu roli skalowania i węzła. W czasie aprowizacji wybierz strefy dostępności, aby dystrybuować wdrożenie węzła w różnych strefach w celu uzyskania maksymalnej odporności wewnątrz regionu. Awaria strefy dostępności nie spowoduje całkowitej awarii, ale zamiast tego obniżenie wydajności do czasu odzyskania strefy.
Konfiguracja klastra obserwowanego przez lidera
Usługa Azure Data Explorer udostępnia opcjonalną możliwość obserwowanego klastra lidera, który ma być obserwowany przez inne klastry obserwowane w celu uzyskania dostępu tylko do odczytu do danych i metadanych lidera. Zmiany lidera, takie jak create, appendi drop są automatycznie synchronizowane z obserwowanym elementem. Chociaż liderzy mogą obejmować regiony platformy Azure, klastry obserwowanych powinny być hostowane w tych samych regionach co lider. Jeśli klaster liderów nie działa lub bazy danych lub tabele zostaną przypadkowo porzucone, klastry obserwowane utracą dostęp do momentu odzyskania dostępu do lidera.
Awaria strefy dostępności platformy Azure
Strefy dostępności platformy Azure to unikatowe lokalizacje fizyczne w tym samym regionie świadczenia usługi Azure. Mogą chronić zasoby obliczeniowe i dane klastra usługi Azure Data Explorer przed awarią częściowego regionu. Awaria strefy jest scenariuszem dostępności, ponieważ jest w regionie.
Przypnij klaster usługi Azure Data Explorer do tej samej strefy co inne połączone zasoby platformy Azure. Aby uzyskać więcej informacji na temat włączania stref dostępności, zobacz tworzenie klastra.
Uwaga
Wdrożenie w strefach dostępności jest możliwe podczas tworzenia klastra lub można przeprowadzić migrację później.
Awaria centrum danych platformy Azure
Strefy dostępności platformy Azure są dostarczane z kosztami, a niektórzy klienci decydują się wdrażać bez nadmiarowości strefowej. W przypadku takiego wdrożenia usługi Azure Data Explorer awaria centrum danych platformy Azure spowoduje awarię klastra. Obsługa awarii centrum danych platformy Azure jest zatem identyczna z awarią w regionie świadczenia usługi Azure.
Awaria regionu świadczenia usługi Azure
Usługa Azure Data Explorer nie zapewnia automatycznej ochrony przed awarią całego regionu świadczenia usługi Azure. Aby zminimalizować wpływ na działalność biznesową, jeśli wystąpi taka awaria, wiele klastrów usługi Azure Data Explorer w sparowanych regionach platformy Azure. W oparciu o cel czasu odzyskiwania (RTO), cel punktu odzyskiwania (RPO), a także nakład pracy i zagadnienia dotyczące kosztów, istnieje wiele konfiguracji odzyskiwania po awarii. Optymalizacje kosztów i wydajności są możliwe dzięki rekomendacjom usługi Azure Advisor i konfiguracji skalowania automatycznego.
Konfiguracje odzyskiwania po awarii
Ta sekcja zawiera szczegółowe informacje o wielu konfiguracjach odzyskiwania po awarii w zależności od wymagań dotyczących odporności (RPO i RTO), wymaganych wysiłków i kosztów.
Cel czasu odzyskiwania (RTO) odnosi się do czasu odzyskiwania po przerwie. Na przykład cel czasu odzyskiwania z 2 godzin oznacza, że aplikacja musi być uruchomiona w ciągu dwóch godzin od wystąpienia zakłóceń. Cel punktu odzyskiwania (RPO) odnosi się do interwału czasu, który może upłynąć podczas zakłóceń, zanim ilość utraconych danych w tym okresie jest większa niż dozwolony próg. Jeśli na przykład cel punktu odzyskiwania wynosi 24 godziny, a aplikacja ma dane począwszy od 15 lat temu, nadal mieści się w parametrach uzgodnionego celu punktu odzyskiwania.
Procesy pozyskiwania, przetwarzania i curation wymagają starannego projektu z góry podczas planowania odzyskiwania po awarii. Pozyskiwanie odnosi się do danych zintegrowanych z usługą Azure Data Explorer z różnych źródeł; przetwarzanie odnosi się do przekształceń i podobnych działań; Curation odnosi się do zmaterializowanych widoków, eksportów do magazynu data lake itd.
Poniżej przedstawiono popularne konfiguracje odzyskiwania po awarii, a każda z nich została szczegółowo opisana poniżej.
- Konfiguracja Active-Active-Active (always-on)
- Konfiguracja Active-Active
- Konfiguracja rezerwy aktywnej na gorąco
- Konfiguracja klastra odzyskiwania danych na żądanie
Konfiguracja aktywne-aktywne-aktywne
Ta konfiguracja jest również nazywana "always-on". W przypadku krytycznych wdrożeń aplikacji bez tolerancji dla awarii należy użyć wielu klastrów usługi Azure Data Explorer w sparowanych regionach platformy Azure. Skonfiguruj pozyskiwanie, przetwarzanie i curation równolegle do wszystkich klastrów. Jednostka SKU klastra musi być taka sama w różnych regionach. Platforma Azure zapewni, że aktualizacje są wdrażane i rozłożone w sparowanych regionach platformy Azure. Awaria regionu świadczenia usługi Azure nie spowoduje awarii aplikacji. Może wystąpić pewne opóźnienie lub obniżenie wydajności.
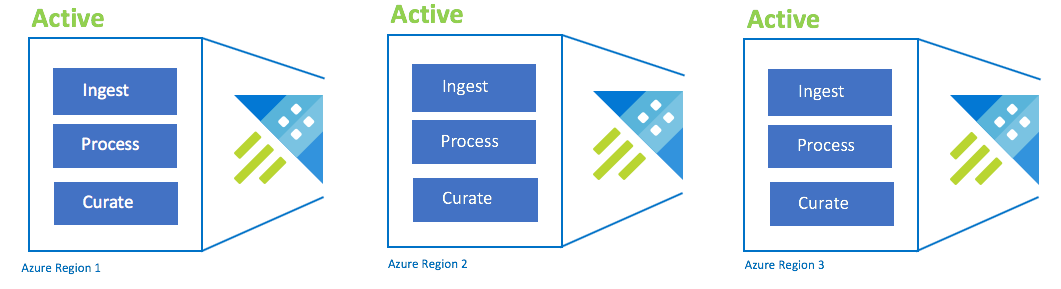
| Konfiguracja | RPO | Cel czasu odzyskiwania | Wysiłek | Koszty |
|---|---|---|---|---|
| Active-Active-Active-n | 0 godzin | 0 godzin | Lower | Najwyższa |
Konfiguracja Active-Active
Ta konfiguracja jest identyczna z konfiguracją active-active-active,ale obejmuje tylko dwa sparowane regiony platformy Azure. Skonfiguruj podwójne pozyskiwanie, przetwarzanie i curation. Użytkownicy są kierowani do najbliższego regionu. Jednostka SKU klastra musi być taka sama w różnych regionach.
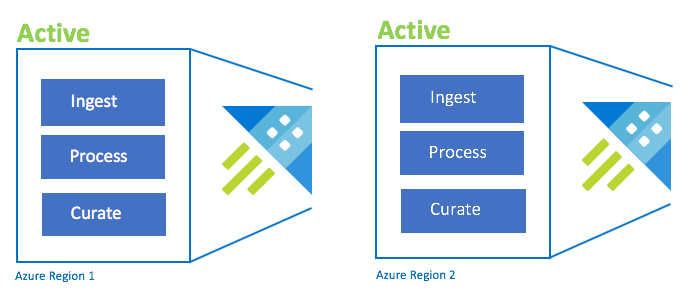
| Konfiguracja | RPO | Cel czasu odzyskiwania | Wysiłek | Koszty |
|---|---|---|---|---|
| Aktywne-aktywne | 0 godzin | 0 godzin | Lower | Wys. |
Konfiguracja rezerwy aktywnej na gorąco
Konfiguracja Active-Hot jest podobna do konfiguracji Active-Active w podwójnej pozyskiwaniu, przetwarzaniu i curation. Klaster rezerwowy jest w trybie online na potrzeby pozyskiwania, przetwarzania i curation, ale nie jest dostępny do wykonywania zapytań. Klaster rezerwowy nie musi znajdować się w tej samej jednostce SKU co klaster podstawowy. Może to być mniejsza jednostka SKU i skala, co może spowodować, że będzie mniej wydajne. W scenariuszu awarii użytkownicy są przekierowywani do klastra rezerwowego, co można opcjonalnie skalować w górę, aby zwiększyć wydajność.
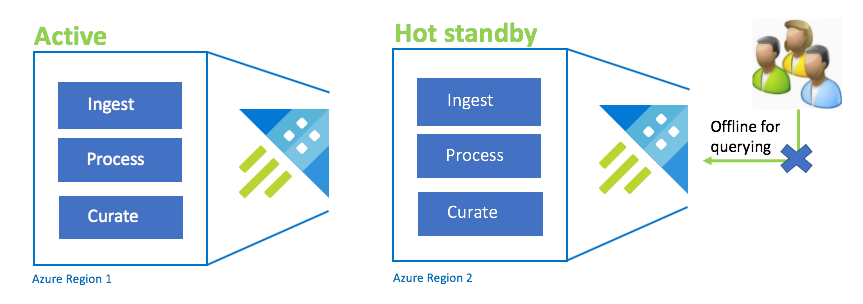
| Konfiguracja | RPO | Cel czasu odzyskiwania | Wysiłek | Koszty |
|---|---|---|---|---|
| Rezerwa aktywna-gorąca | 0 godzin | Niski | Śred. | Śred. |
Konfiguracja odzyskiwania danych na żądanie
To rozwiązanie zapewnia najmniejszą odporność (najwyższy cel punktu odzyskiwania i cel punktu odzyskiwania), jest najniższym kosztem i najwyższym nakładem pracy. W tej konfiguracji nie ma klastra odzyskiwania danych. Skonfiguruj ciągły eksport danych nadzorowanych (chyba że wymagane są również nieprzetworzone i pośrednie dane) na koncie magazynu skonfigurowanym magazynem GRS (magazyn geograficznie nadmiarowy). Klaster odzyskiwania danych jest rozwijany w przypadku scenariusza odzyskiwania po awarii. W tym czasie są stosowane listy DDLs, konfiguracja, zasady i procesy. Dane są pozyskiwane z magazynu z właściwością pozyskiwania kustoCreationTime , aby przejeżdżać czas pozyskiwania, który domyślnie jest czasem systemowym.
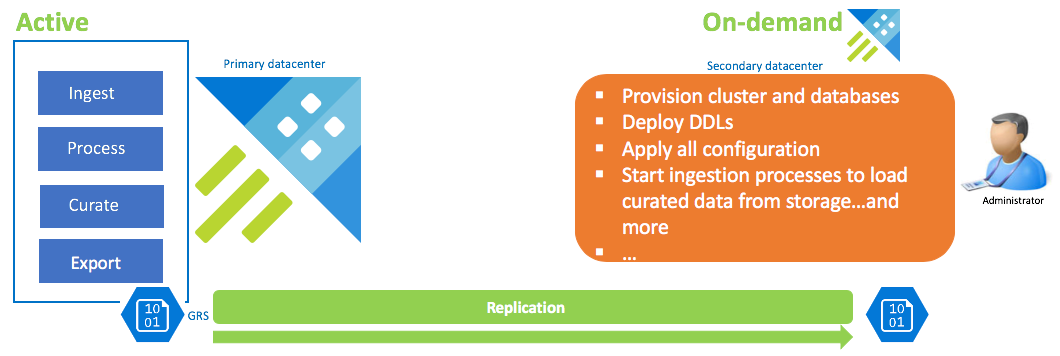
| Konfiguracja | RPO | Cel czasu odzyskiwania | Wysiłek | Koszty |
|---|---|---|---|---|
| Klaster odzyskiwania danych na żądanie | Najwyższa | Najwyższa | Najwyższa | Najniższe |
Podsumowanie opcji konfiguracji odzyskiwania po awarii
| Konfiguracja | Odporność | RPO | Cel czasu odzyskiwania | Wysiłek | Koszty |
|---|---|---|---|---|---|
| Active-Active-Active-n | Najwyższa | 0 godzin | 0 godzin | Lower | Najwyższa |
| Aktywne-aktywne | Wys. | 0 godzin | 0 godzin | Lower | Wys. |
| Rezerwa aktywna-gorąca | Śred. | 0 godzin | Niski | Śred. | Śred. |
| Klaster odzyskiwania danych na żądanie | Najniższe | Najwyższa | Najwyższa | Najwyższa | Najniższe |
Najlepsze rozwiązania
Niezależnie od wybranej konfiguracji odzyskiwania po awarii wykonaj następujące najlepsze rozwiązania:
- Wszystkie obiekty, zasady i konfiguracje bazy danych powinny być utrwalane w kontroli źródła, aby można je było zwolnić do klastra z narzędzia automatyzacji wydania. Aby uzyskać więcej informacji, zobacz Obsługa usługi Azure DevOps dla usługi Azure Data Explorer.
- Projektowanie, opracowywanie i implementowanie procedur walidacji w celu zapewnienia synchronizacji wszystkich klastrów z perspektywy danych. Usługa Azure Data Explorer obsługuje sprzężenia między klastrami. Prosta liczba lub wiersze między tabelami mogą pomóc w zweryfikowaniu.
- Procedury wydania powinny obejmować kontrole ładu i równoważenie, które zapewniają dublowanie klastrów.
- Bądź w pełni świadomy tego, co potrzeba do utworzenia klastra od podstaw.
- Utwórz listę kontrolną jednostek wdrażania. Lista będzie unikatowa dla Twoich potrzeb, ale powinna zawierać: skrypty wdrażania, połączenia pozyskiwania, narzędzia analizy biznesowej i inne ważne konfiguracje.