Tworzenie rozwiązań do zapewniania ciągłości działania i odzyskiwania po awarii za pomocą usługi Azure Data Explorer
W tym artykule opisano sposób przygotowania się do awarii regionalnej platformy Azure przez replikowanie zasobów, zarządzania i pozyskiwania danych usługi Azure Data Explorer w różnych regionach świadczenia usługi Azure. Podano przykład pozyskiwania danych za pomocą usługi Azure Event Hubs. Optymalizacja kosztów jest również omawiana dla różnych konfiguracji architektury. Aby uzyskać bardziej szczegółowe informacje na temat zagadnień dotyczących architektury i rozwiązań odzyskiwania, zobacz omówienie ciągłości działania.
Przygotowanie do regionalnej awarii platformy Azure w celu ochrony danych
Usługa Azure Data Explorer nie obsługuje automatycznej ochrony przed awarią całego regionu świadczenia usługi Azure. Takie zakłócenia mogą wystąpić podczas klęski żywiołowej, takiej jak trzęsienie ziemi. Jeśli potrzebujesz rozwiązania w sytuacji odzyskiwania po awarii, wykonaj następujące kroki, aby zapewnić ciągłość działania. W tych krokach zreplikujesz klastry, zarządzanie i pozyskiwanie danych w dwóch sparowanych regionach platformy Azure.
- Utwórz co najmniej dwa niezależne klastry w dwóch sparowanych regionach platformy Azure.
- Replikuj wszystkie działania zarządzania, takie jak tworzenie nowych tabel lub zarządzanie rolami użytkowników w każdym klastrze.
- Pozyskiwanie danych do każdego klastra równolegle.
Tworzenie wielu niezależnych klastrów
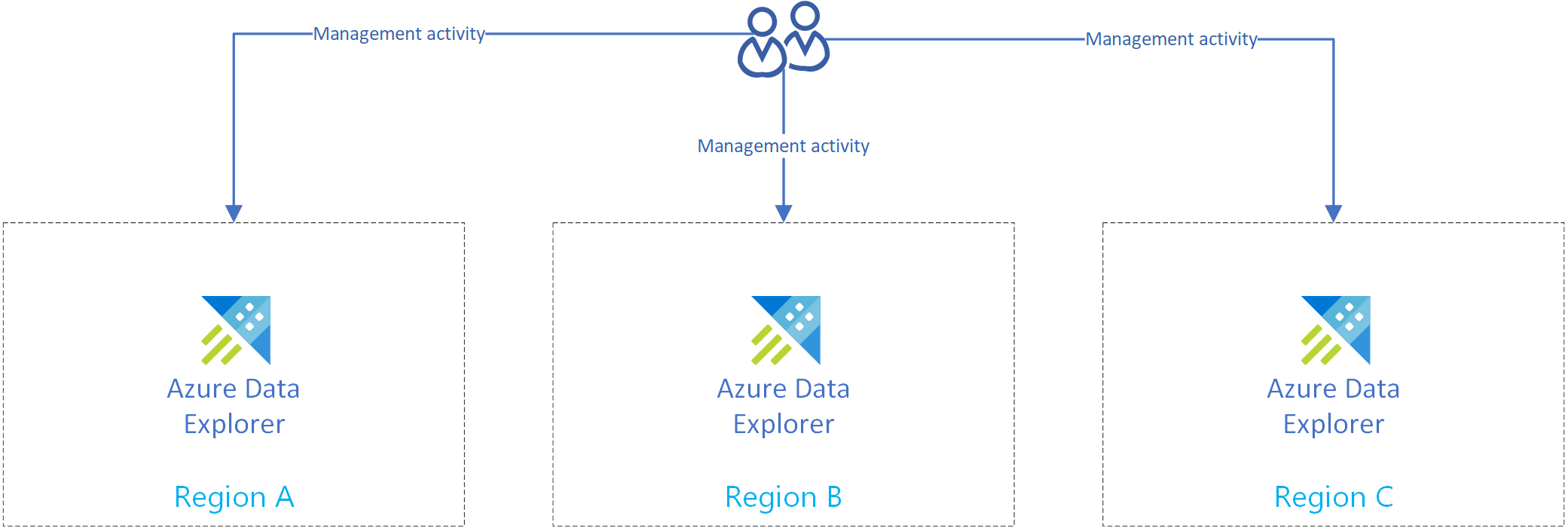
Utwórz więcej niż jeden klaster usługi Azure Data Explorer w więcej niż jednym regionie. Upewnij się, że co najmniej dwa z tych klastrów są tworzone w sparowanych regionach platformy Azure.
Na poniższej ilustracji przedstawiono repliki, trzy klastry w trzech różnych regionach.

Replikowanie działań zarządzania
Replikuj działania zarządzania, aby mieć tę samą konfigurację klastra w każdej repliki.
Utwórz w każdej repliki to samo:
- Bazy danych: możesz utworzyć nową bazę danych przy użyciu witryny Azure Portal lub jednego z naszych zestawów SDK .
- Tabele
- Mapowania
- Zasady
Zarządzanie uwierzytelnianiem i autoryzacją w każdej repliki.
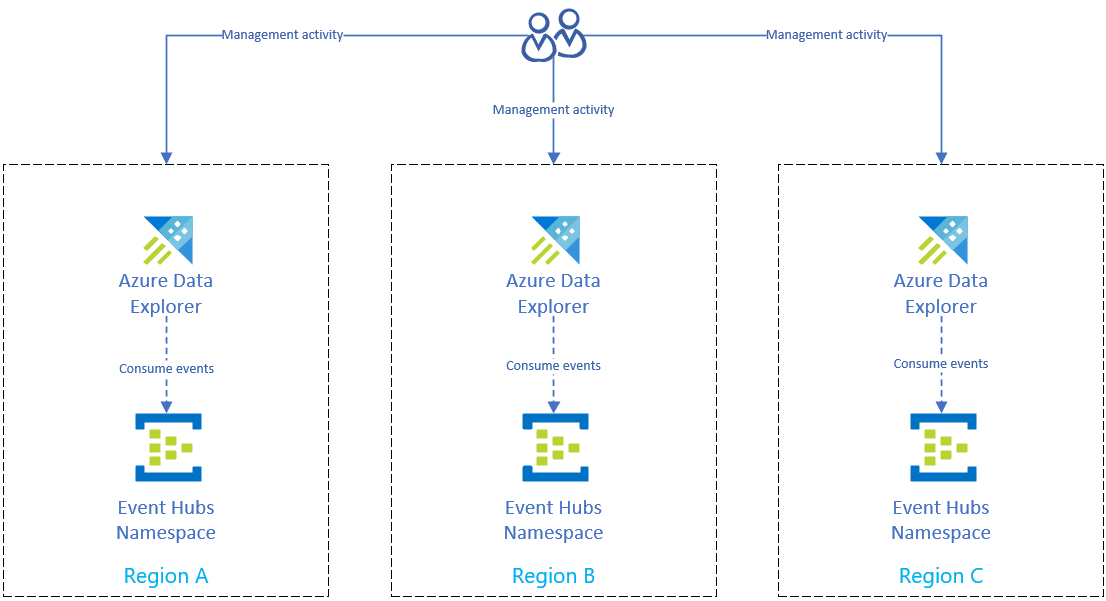
Rozwiązanie odzyskiwania po awarii przy użyciu pozyskiwania centrum zdarzeń
Po zakończeniu przygotowywania do regionalnej awarii platformy Azure w celu ochrony danych dane i zarządzanie są dystrybuowane do wielu regionów. Jeśli wystąpi awaria w jednym regionie, usługa Azure Data Explorer będzie mogła używać innych replik.
Konfigurowanie pozyskiwania przy użyciu centrum zdarzeń
Aby pozyskać dane z usługi Azure Event Hubs do klastra usługi Azure Data Explorer w każdym regionie, najpierw zreplikuj konfigurację usługi Azure Event Hubs w każdym regionie. Następnie skonfiguruj replikę usługi Azure Data Explorer w każdym regionie w celu pozyskiwania danych z odpowiednich centrów zdarzeń.
Uwaga
Pozyskiwanie za pośrednictwem usługi Azure Event Hubs/IoT Hub/Storage jest niezawodne. Jeśli klaster nie jest dostępny przez pewien czas, nadrobi zaległości w późniejszym czasie i wstawi wszystkie oczekujące komunikaty lub obiekty blob. Ten proces opiera się na punktach kontrolnych.
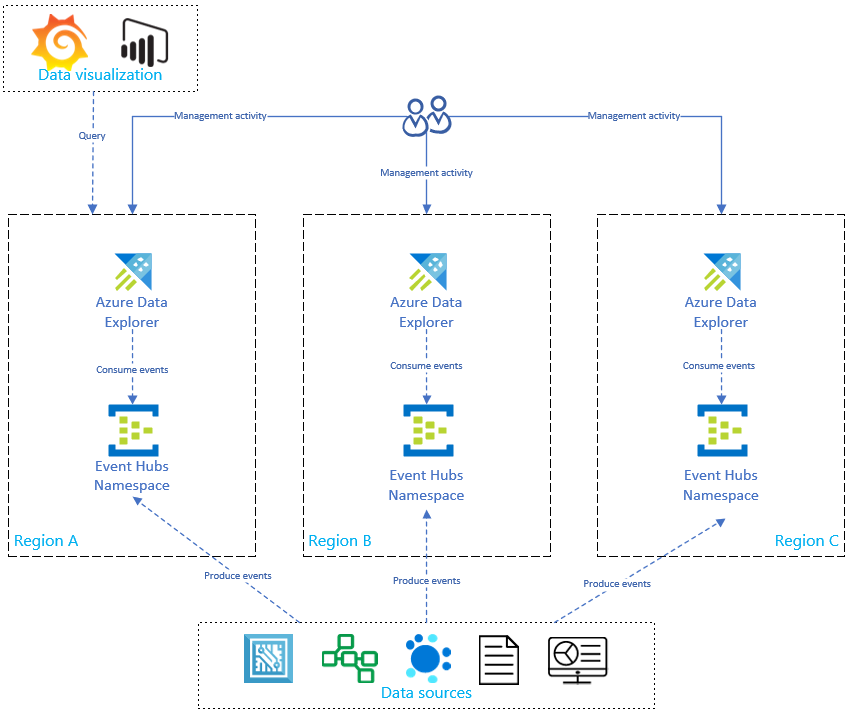
Jak pokazano na poniższym diagramie, źródła danych generują zdarzenia do centrów zdarzeń we wszystkich regionach, a każda replika usługi Azure Data Explorer zużywa zdarzenia. Składniki wizualizacji danych, takie jak Power BI, Grafana lub SDK, mogą wysyłać zapytania do jednej z replik.
Optymalizacja kosztów
Teraz możesz zoptymalizować repliki przy użyciu niektórych z następujących metod:
- Tworzenie konfiguracji odzyskiwania danych na żądanie
- Uruchamianie i zatrzymywanie replik
- Implementowanie usługi aplikacji o wysokiej dostępności
- Optymalizowanie kosztów w konfiguracji aktywne-aktywne
Tworzenie konfiguracji odzyskiwania danych na żądanie
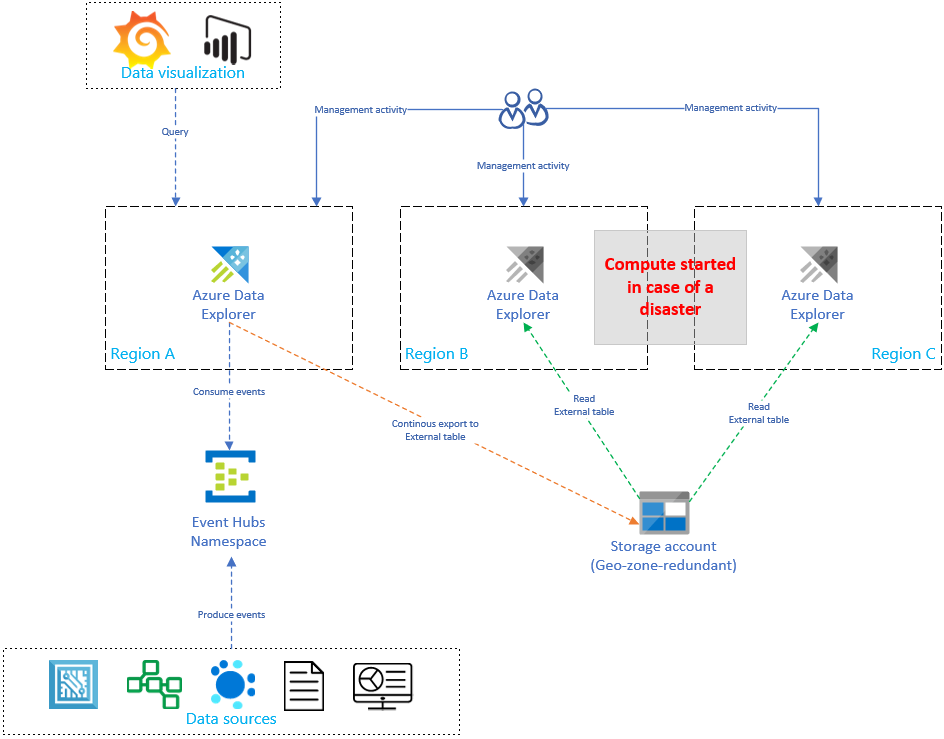
Replikowanie i aktualizowanie konfiguracji usługi Azure Data Explorer spowoduje liniowy wzrost kosztów przy użyciu liczby replik. Aby zoptymalizować koszt, możesz zaimplementować wariant architektury w celu zrównoważenia czasu, przejścia w tryb failover i kosztów. W konfiguracji odzyskiwania danych na żądanie optymalizacja kosztów została zaimplementowana przez wprowadzenie pasywnych replik usługi Azure Data Explorer. Te repliki są włączone tylko wtedy, gdy wystąpi awaria w regionie podstawowym (na przykład region A). Repliki w regionach B i C nie muszą być aktywne 24/7, co znacznie zmniejsza koszt. Jednak w większości przypadków wydajność tych replik nie będzie tak dobra, jak klaster podstawowy. Aby uzyskać więcej informacji, zobacz Konfiguracja odzyskiwania danych na żądanie.
Na poniższej ilustracji tylko jeden klaster pozyskuje dane z centrum zdarzeń. Klaster podstawowy w regionie A wykonuje ciągły eksport danych do konta magazynu. Repliki pomocnicze mają dostęp do danych przy użyciu tabel zewnętrznych.
Uruchamianie i zatrzymywanie replik
Repliki pomocnicze można uruchomić i zatrzymać przy użyciu jednej z następujących metod:
Łącznik usługi Azure Data Explorer do usługi Power Automate (wersja zapoznawcza)
Przycisk Zatrzymaj na karcie Przegląd w witrynie Azure Portal. Aby uzyskać więcej informacji, zobacz Zatrzymywanie i ponowne uruchamianie klastra.
Interfejs wiersza polecenia platformy Azure:
az kusto cluster stop --name=<clusterName> --resource-group=<rgName> --subscription=<subscriptionId>"
Implementowanie usługi aplikacji o wysokiej dostępności
Tworzenie klienta BCDR usługi aplikacja systemu Azure
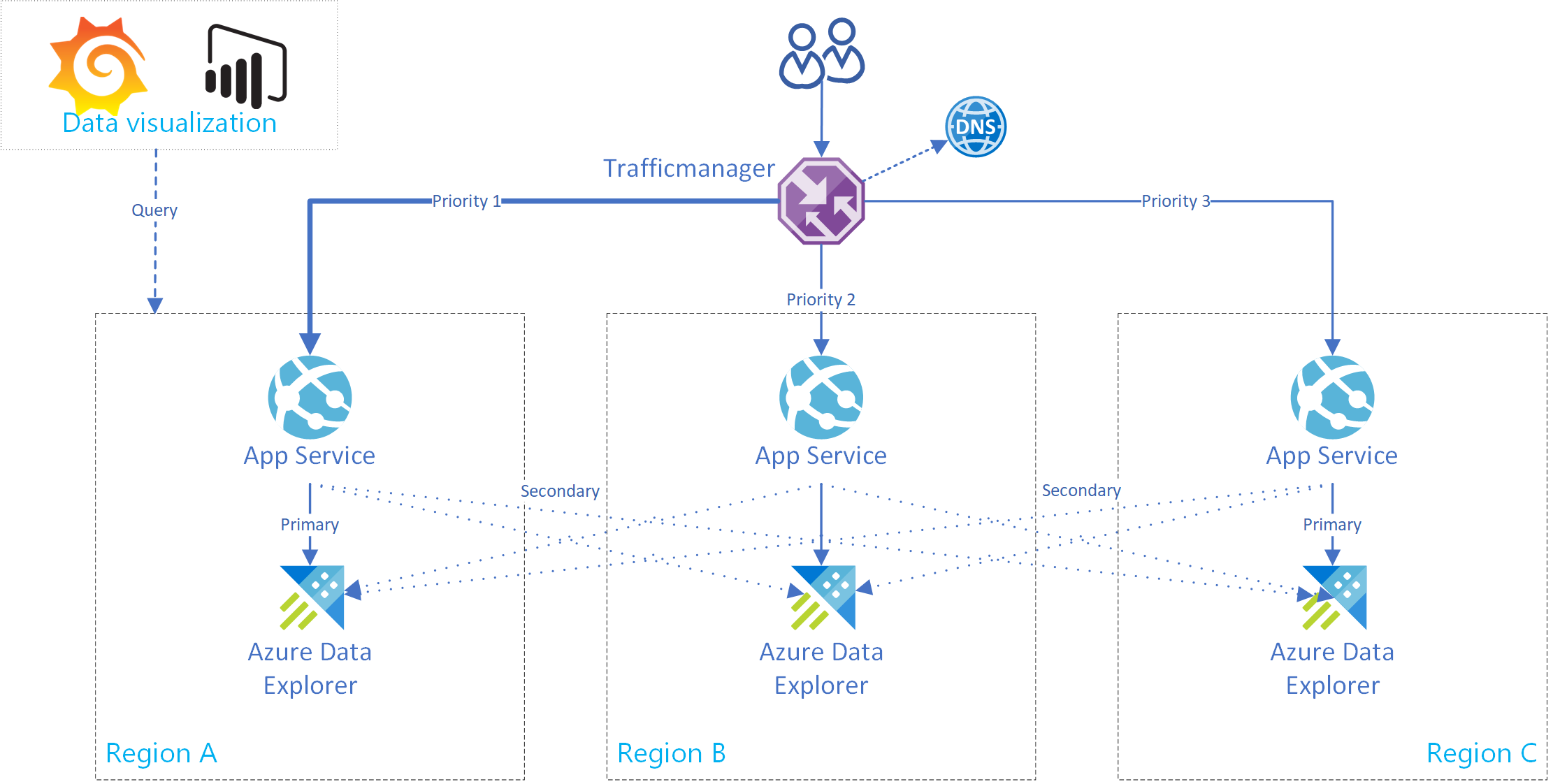
W tej sekcji pokazano, jak utworzyć usługę aplikacja systemu Azure, która obsługuje połączenie z jednym podstawowym i wieloma pomocniczymi klastrami usługi Azure Data Explorer. Na poniższej ilustracji przedstawiono konfigurację usługi aplikacja systemu Azure Service.
Napiwek
Posiadanie wielu połączeń między replikami w tej samej usłudze zapewnia zwiększoną dostępność. Ta konfiguracja nie jest przydatna tylko w przypadku wystąpień awarii regionalnych.
Użyj tego standardowego kodu dla usługi App Service. Aby zaimplementować klienta z wieloma klastrami, utworzono klasę AdxBcdrClient . Każde zapytanie wykonywane przy użyciu tego klienta zostanie wysłane najpierw do klastra podstawowego. Jeśli wystąpi błąd, zapytanie zostanie wysłane do replik pomocniczych.
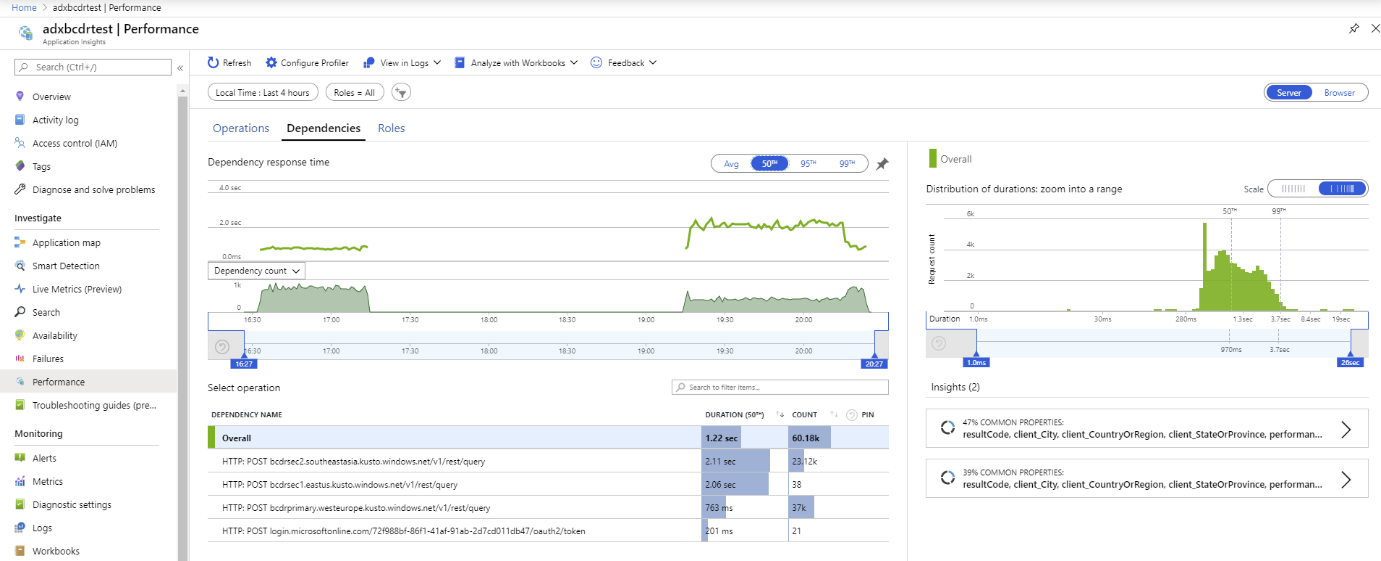
Użyj niestandardowych metryk usługi Application Insights, aby zmierzyć wydajność i dystrybucję żądań do klastrów podstawowych i pomocniczych.
Testowanie klienta BCDR usługi aplikacja systemu Azure
Przeprowadziliśmy test przy użyciu wielu replik usługi Azure Data Explorer. Po symulowanej awarii klastrów podstawowych i pomocniczych można zobaczyć, że klient BCDR usługi App Service działa zgodnie z oczekiwaniami.
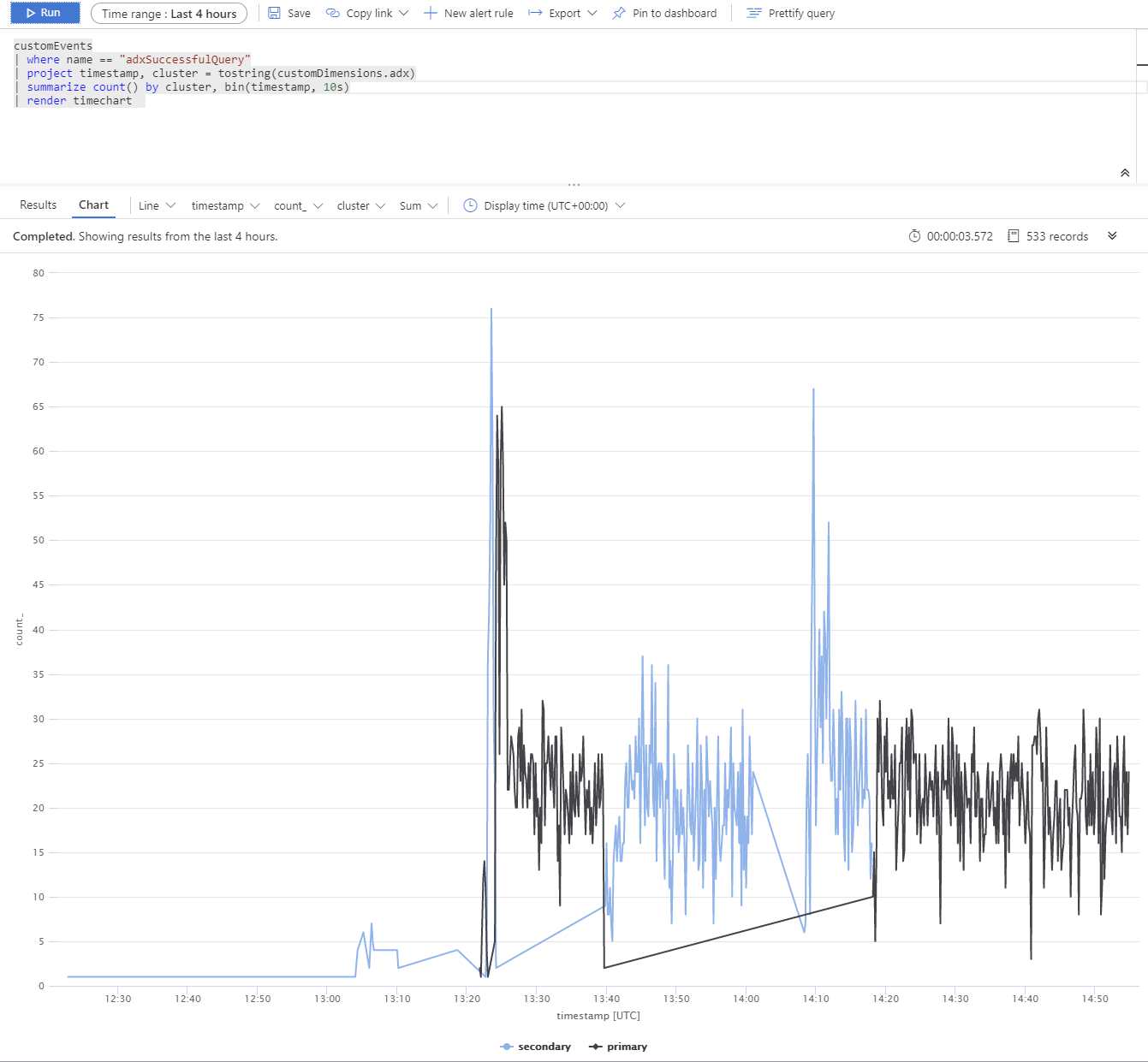
Klastry usługi Azure Data Explorer są dystrybuowane w regionie Europa Zachodnia (podstawowa 2xD14v2), Azja Południowo-Wschodnia i Wschodnie stany USA (2xD11v2).
Uwaga
Wolniejsze czasy odpowiedzi są spowodowane różnymi jednostkami SKU i zapytaniami między planetami.
Wykonywanie routingu dynamicznego lub statycznego
Użyj metod routingu usługi Azure Traffic Manager na potrzeby dynamicznego lub statycznego routingu żądań. Usługa Azure Traffic Manager to oparty na systemie DNS moduł równoważenia obciążenia ruchu, który umożliwia dystrybucję ruchu usługi App Service. Ten ruch jest zoptymalizowany pod kątem usług w globalnych regionach świadczenia usługi Azure, zapewniając jednocześnie wysoką dostępność i czas odpowiedzi.
Możesz również użyć routingu opartego na usłudze Azure Front Door. Aby porównać te dwie metody, zobacz Load-balancing with Azure application delivery suite (Równoważenie obciążenia przy użyciu pakietu dostarczania aplikacji platformy Azure).
Optymalizowanie kosztów w konfiguracji aktywne-aktywne
Użycie konfiguracji aktywne-aktywne na potrzeby odzyskiwania po awarii zwiększa koszt liniowo. Koszt obejmuje węzły, magazyn, adiustację i zwiększony koszt sieci dla przepustowości.
Optymalizowanie kosztów przy użyciu zoptymalizowanego autoskalowania
Użyj zoptymalizowanej funkcji automatycznego skalowania , aby skonfigurować skalowanie w poziomie dla klastrów pomocniczych. Powinny one być wymiarowane, aby mogły obsługiwać obciążenie pozyskiwania. Gdy klaster podstawowy nie jest osiągalny, klastry pomocnicze będą otrzymywać więcej ruchu i skalować zgodnie z konfiguracją.
Użycie zoptymalizowanego skalowania automatycznego w tym przykładzie zaoszczędziło około 50% kosztów w porównaniu z tym samym skalowaniem w poziomie i w pionie na wszystkich replikach.