Wybieranie kolumn dystrybucji w usłudze Azure Cosmos DB for PostgreSQL
DOTYCZY: ![]() Usługa Azure Cosmos DB for PostgreSQL (obsługiwana przez rozszerzenie bazy danych Citus do bazy danych PostgreSQL)
Usługa Azure Cosmos DB for PostgreSQL (obsługiwana przez rozszerzenie bazy danych Citus do bazy danych PostgreSQL)
Wybór kolumny dystrybucji w poszczególnych tabelach jest jedną z najważniejszych decyzji, jakie podejmujesz podczas modelowania. Usługa Azure Cosmos DB for PostgreSQL przechowuje wiersze w fragmentach na podstawie wartości kolumny dystrybucji wierszy.
Poprawne wybór grupuje powiązane dane razem w tych samych węzłach fizycznych, co sprawia, że zapytania są szybkie i dodaje obsługę wszystkich funkcji SQL. Nieprawidłowy wybór sprawia, że system działa powoli.
Ogólne porady
Poniżej przedstawiono cztery kryteria wyboru idealnej kolumny dystrybucji dla tabel rozproszonych.
Wybierz kolumnę centralną w obciążeniu aplikacji.
Możesz traktować tę kolumnę jako "serce", "centralny kawałek" lub "wymiar naturalny" na potrzeby partycjonowania danych.
Przykłady:
device_idw obciążeniu IoTsecurity_iddla aplikacji finansowej, która śledzi papiery wartościoweuser_idw analizie użytkownikówtenant_iddla aplikacji SaaS z wieloma dzierżawami
Wybierz kolumnę z przyzwoitą kardynalnością, a nawet rozkład statystyczny.
Kolumna powinna zawierać wiele wartości i dokładnie rozłożyć i równomiernie między wszystkimi fragmentami.
Przykłady:
- Kardynalność ponad 1000
- Nie wybieraj kolumny, która ma tę samą wartość dla dużej wartości wierszy (niesymetryczność danych)
- W obciążeniu SaaS posiadanie jednej dzierżawy znacznie większej niż reszta może spowodować niesymetryczność danych. W takiej sytuacji można użyć izolacji dzierżawy, aby utworzyć dedykowany fragment do obsługi dzierżawy.
Wybierz kolumnę, która przynosi korzyści z istniejących zapytań.
W przypadku obciążenia transakcyjnego lub operacyjnego (w przypadku którego większość zapytań zajmuje tylko kilka milisekund), wybierz kolumnę, która jest wyświetlana jako filtr w
WHEREklauzulach dla co najmniej 80% zapytań. Na przykład kolumnadevice_idw plikuSELECT * FROM events WHERE device_id=1.W przypadku obciążenia analitycznego (w przypadku którego większość zapytań trwa od 1 do 2 sekund), wybierz kolumnę, która umożliwia równoległe wykonywanie zapytań w węzłach roboczych. Na przykład kolumna często występująca w klauzulach GROUP BY lub odpytywane o wiele wartości jednocześnie.
Wybierz kolumnę, która znajduje się w większości dużych tabel.
Tabele powyżej 50 GB powinny być dystrybuowane. Wybranie tej samej kolumny dystrybucji dla wszystkich z nich umożliwia współlokowanie danych dla tej kolumny w węzłach roboczych. Współlokacja sprawia, że wydajne jest uruchamianie numerów JOIN i zestawień oraz wymuszanie kluczy obcych.
Pozostałe (mniejsze) tabele mogą być tabelami lokalnymi lub referencyjnymi. Jeśli mniejsza tabela musi dołączyć do tabel rozproszonych, utwórz tabelę referencyjną.
Przykłady przypadków użycia
Widzieliśmy ogólne kryteria wybierania kolumny dystrybucji. Teraz zobaczmy, jak mają zastosowanie do typowych przypadków użycia.
Aplikacje z wieloma dzierżawami
Architektura wielodostępna używa formy modelowania hierarchicznej bazy danych do dystrybuowania zapytań między węzłami w klastrze. Górna część hierarchii danych jest znana jako identyfikator dzierżawy i musi być przechowywana w kolumnie w każdej tabeli.
Usługa Azure Cosmos DB for PostgreSQL sprawdza zapytania, aby zobaczyć, którego identyfikatora dzierżawy dotyczą i znaleźć pasujący fragment tabeli. Kieruje zapytanie do jednego węzła roboczego, który zawiera fragment. Uruchomienie zapytania ze wszystkimi odpowiednimi danymi umieszczonymi w tym samym węźle jest nazywane kolokacją.
Na poniższym diagramie przedstawiono kolokację w modelu danych z wieloma dzierżawami. Zawiera dwie tabele, Konta i Kampanie, z których każda jest dystrybuowana przez account_idprogram . Zacienione pola reprezentują fragmenty. Zielone fragmenty są przechowywane razem w jednym węźle roboczym, a niebieskie fragmenty są przechowywane w innym węźle roboczym. Zwróć uwagę, że zapytanie sprzężenia między kontami i kampaniami zawiera wszystkie niezbędne dane w jednym węźle, gdy obie tabele są ograniczone do tych samych account_id.
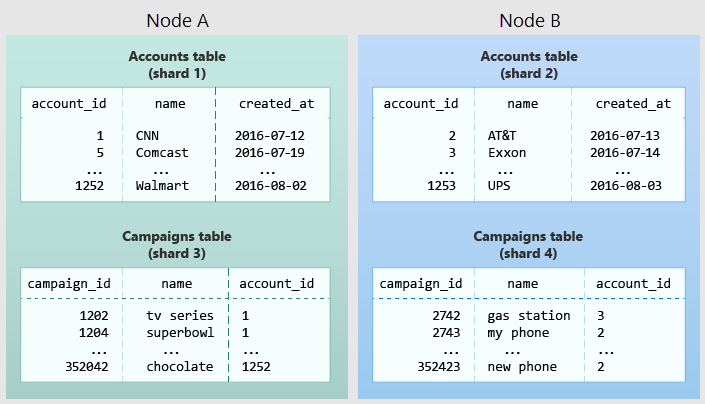
Aby zastosować ten projekt we własnym schemacie, zidentyfikuj, co stanowi dzierżawę w aplikacji. Typowe przykłady to firma, konto, organizacja lub klient. Nazwa kolumny będzie podobna company_id do lub customer_id. Zbadaj każde z zapytań i zadaj sobie pytanie, czy miałoby to więcej klauzul WHERE, aby ograniczyć wszystkie tabele związane z wierszami o tym samym identyfikatorze dzierżawy? Zapytania w modelu wielodostępnym są ograniczone do dzierżawy. Na przykład zapytania dotyczące sprzedaży lub spisu są ograniczone do określonego sklepu.
Najlepsze rozwiązania
- Dystrybuuj tabele według wspólnej kolumny tenant_id. Na przykład w aplikacji SaaS, w której dzierżawy są firmami, tenant_id prawdopodobnie będzie company_id.
- Konwertowanie małych tabel między dzierżawami na tabele referencyjne. Gdy wiele dzierżaw współużytkuje małą tabelę informacji, rozłóż ją jako tabelę referencyjną.
- Ogranicz filtrowanie wszystkich zapytań aplikacji według tenant_id. Każde zapytanie powinno żądać informacji dla jednej dzierżawy jednocześnie.
Zapoznaj się z samouczkiem dotyczącym wielu dzierżaw, aby zapoznać się z przykładem tworzenia tego rodzaju aplikacji.
Aplikacje w czasie rzeczywistym
Architektura wielodostępna wprowadza hierarchiczną strukturę i używa kolokacji danych do kierowania zapytań na dzierżawę. Natomiast architektury w czasie rzeczywistym zależą od określonych właściwości dystrybucji danych w celu osiągnięcia wysoce równoległego przetwarzania.
Używamy "identyfikatora jednostki" jako terminu dla kolumn dystrybucji w modelu czasu rzeczywistego. Typowe jednostki to użytkownicy, hosty lub urządzenia.
Zapytania w czasie rzeczywistym zwykle pytają o agregacje liczbowe pogrupowane według daty lub kategorii. Usługa Azure Cosmos DB for PostgreSQL wysyła te zapytania do każdego fragmentu w celu uzyskania wyników częściowych i tworzy ostateczną odpowiedź w węźle koordynatora. Zapytania są uruchamiane najszybciej, gdy jak najwięcej węzłów współtworzy, a gdy żaden pojedynczy węzeł nie musi wykonywać nieproporcjonalnej ilości pracy.
Najlepsze rozwiązania
- Wybierz kolumnę o wysokiej kardynalności jako kolumnę rozkładu. Dla porównania pole Stan w tabeli zamówień z wartościami Nowe, Płatne i Wysłane jest złym wyborem kolumny dystrybucji. Przyjęto założenie, że tylko te kilka wartości ogranicza liczbę fragmentów, które mogą przechowywać dane, oraz liczbę węzłów, które mogą je przetwarzać. Wśród kolumn o wysokiej kardynalności warto również wybrać te kolumny, które są często używane w klauzulach grupowania lub jako klucze sprzężenia.
- Wybierz kolumnę z równomiernym rozkładem. Jeśli dystrybuujesz tabelę w kolumnie niesymetrycznej do niektórych typowych wartości, dane w tabeli zwykle gromadzą się w niektórych fragmentach. Węzły, które przechowują te fragmenty, wykonują większą pracę niż inne węzły.
- Dystrybuuj tabele faktów i wymiarów na wspólnych kolumnach. Tabela faktów może mieć tylko jeden klucz dystrybucji. Tabele, które łączą się w innym kluczu, nie zostaną przeniesione do tabeli faktów. Wybierz jeden wymiar, który ma być kolokowany na podstawie tego, jak często jest on przyłączony i rozmiar wierszy łączących.
- Zmień niektóre tabele wymiarów na tabele referencyjne. Jeśli nie można przenieść tabeli wymiarów z tabelą faktów, możesz zwiększyć wydajność zapytań, dystrybuując kopie tabeli wymiarów do wszystkich węzłów w postaci tabeli odwołań.
Przeczytaj samouczek pulpitu nawigacyjnego w czasie rzeczywistym, aby zapoznać się z przykładem tworzenia tego rodzaju aplikacji.
Dane szeregów czasowych
W obciążeniu szeregów czasowych aplikacje wysyłają zapytania o najnowsze informacje podczas archiwizowania starych informacji.
Najczęstszym błędem podczas modelowania informacji szeregów czasowych w usłudze Azure Cosmos DB for PostgreSQL jest użycie sygnatury czasowej jako kolumny dystrybucji. Rozkład skrótów na podstawie czasu rozkłada czas pozornie losowo na różne fragmenty, zamiast utrzymywać zakresy czasu razem w fragmentach. Zapytania, które obejmują czas, zazwyczaj odwołują się do zakresów czasu, na przykład najnowszych danych. Ten typ dystrybucji skrótów prowadzi do narzutowania sieci.
Najlepsze rozwiązania
- Nie wybieraj znacznika czasu jako kolumny dystrybucji. Wybierz inną kolumnę dystrybucji. W aplikacji wielodostępnej użyj identyfikatora dzierżawy lub w aplikacji w czasie rzeczywistym użyj identyfikatora jednostki.
- Zamiast tego użyj partycjonowania tabel PostgreSQL na czas. Partycjonowanie tabel umożliwia podzielenie dużej tabeli uporządkowanych czasowo na wiele dziedziczonych tabel z każdą tabelą zawierającą różne zakresy czasu. Dystrybucja tabeli podzielonej na partycje Postgres powoduje utworzenie fragmentów dla odziedziczonych tabel.
Następne kroki
- Dowiedz się, jak kolokacja między rozproszonymi danymi ułatwia szybkie uruchamianie zapytań.
- Odkryj kolumnę dystrybucji tabeli rozproszonej i inne przydatne zapytania diagnostyczne.