Samouczek: projektowanie pulpitu nawigacyjnego analizy w czasie rzeczywistym przy użyciu usługi Azure Cosmos DB for PostgreSQL
DOTYCZY: ![]() Usługa Azure Cosmos DB for PostgreSQL (obsługiwana przez rozszerzenie bazy danych Citus do bazy danych PostgreSQL)
Usługa Azure Cosmos DB for PostgreSQL (obsługiwana przez rozszerzenie bazy danych Citus do bazy danych PostgreSQL)
W tym samouczku użyjesz usługi Azure Cosmos DB for PostgreSQL, aby dowiedzieć się, jak wykonywać następujące czynności:
- Tworzenie klastra
- Tworzenie schematu za pomocą narzędzia psql
- Tabele fragmentów między węzłami
- Generowanie danych przykładowych
- Wykonywanie zestawień
- Wykonywanie zapytań dotyczących danych pierwotnych i zagregowanych
- Wygasanie danych
Wymagania wstępne
Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto.
Tworzenie klastra
Zaloguj się do witryny Azure Portal i wykonaj następujące kroki, aby utworzyć klaster usługi Azure Cosmos DB for PostgreSQL:
Przejdź do pozycji Utwórz klaster usługi Azure Cosmos DB for PostgreSQL w witrynie Azure Portal.
W formularzu Tworzenie klastra usługi Azure Cosmos DB for PostgreSQL:
Wypełnij informacje na karcie Podstawowe informacje.
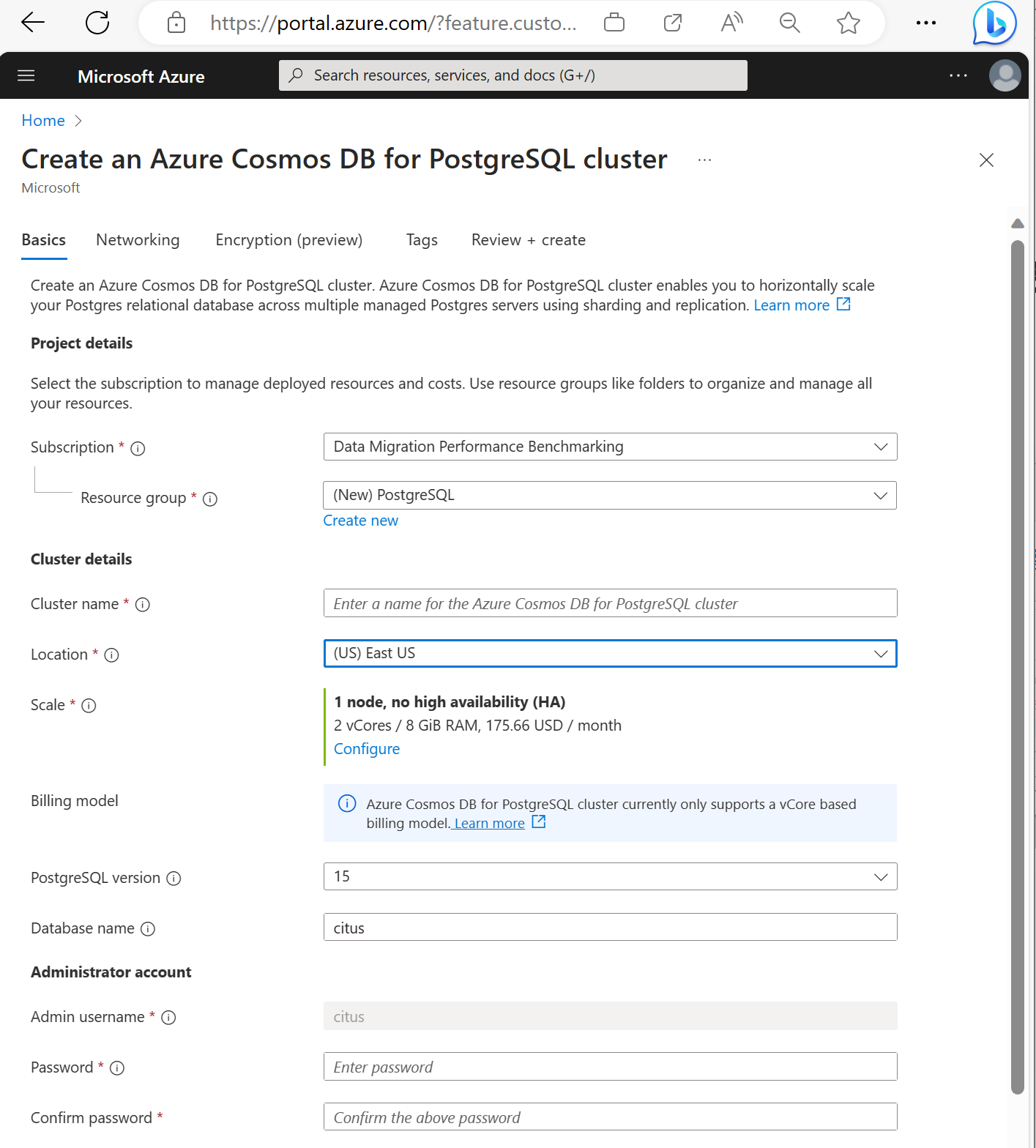
Większość opcji nie wymaga wyjaśnień, ale należy pamiętać o następujących kwestiach:
- Nazwa klastra określa nazwę DNS używaną przez aplikacje do nawiązywania połączenia w postaci
<node-qualifier>-<clustername>.<uniqueID>.postgres.cosmos.azure.com. - Możesz wybrać główną wersję bazy danych PostgreSQL, taką jak 15. Usługa Azure Cosmos DB for PostgreSQL zawsze obsługuje najnowszą wersję citus dla wybranej głównej wersji bazy danych Postgres.
- Nazwa użytkownika administratora musi być wartością
citus. - Nazwę bazy danych można pozostawić na wartości domyślnej "citus" lub zdefiniować tylko nazwę bazy danych. Nie można zmienić nazwy bazy danych po aprowizacji klastra.
- Nazwa klastra określa nazwę DNS używaną przez aplikacje do nawiązywania połączenia w postaci
Wybierz pozycję Dalej: Sieć w dolnej części ekranu.
Na ekranie Sieć wybierz pozycję Zezwalaj na dostęp publiczny z usług i zasobów platformy Azure w ramach platformy Azure do tego klastra.
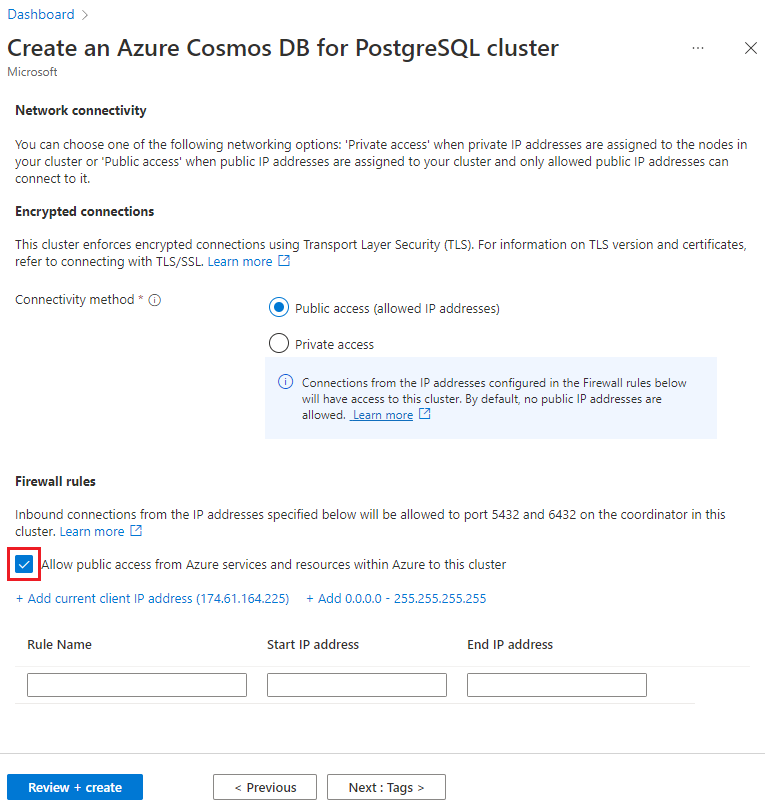
Wybierz pozycję Przeglądanie i tworzenie, a po zakończeniu walidacji wybierz pozycję Utwórz, aby utworzyć klaster.
Aprowizacja zajmuje kilka minut. Strona przekierowuje do monitorowania wdrożenia. Gdy stan zmieni się z Wdrażanie jest w toku na Wdrożenie zostało ukończone, wybierz pozycję Przejdź do zasobu.
Tworzenie schematu za pomocą narzędzia psql
Po nawiązaniu połączenia z usługą Azure Cosmos DB for PostgreSQL przy użyciu narzędzia psql możesz wykonać kilka podstawowych zadań. W tym samouczku przedstawiono proces pozyskiwania danych ruchu z analizy internetowej, a następnie zwijania danych w celu zapewnienia pulpitów nawigacyjnych w czasie rzeczywistym na podstawie tych danych.
Utwórzmy tabelę, która będzie używać wszystkich naszych nieprzetworzonych danych dotyczących ruchu internetowego. Uruchom następujące polecenia w terminalu programu psql:
CREATE TABLE http_request (
site_id INT,
ingest_time TIMESTAMPTZ DEFAULT now(),
url TEXT,
request_country TEXT,
ip_address TEXT,
status_code INT,
response_time_msec INT
);
Utworzymy również tabelę, która będzie przechowywać nasze agregacje na minutę, oraz tabelę, która utrzymuje pozycję naszego ostatniego zestawienia. Uruchom również następujące polecenia w narzędziu psql:
CREATE TABLE http_request_1min (
site_id INT,
ingest_time TIMESTAMPTZ, -- which minute this row represents
error_count INT,
success_count INT,
request_count INT,
average_response_time_msec INT,
CHECK (request_count = error_count + success_count),
CHECK (ingest_time = date_trunc('minute', ingest_time))
);
CREATE INDEX http_request_1min_idx ON http_request_1min (site_id, ingest_time);
CREATE TABLE latest_rollup (
minute timestamptz PRIMARY KEY,
CHECK (minute = date_trunc('minute', minute))
);
Nowo utworzone tabele są teraz widoczne na liście tabel za pomocą tego polecenia psql:
\dt
Tabele fragmentów między węzłami
Wdrożenie usługi Azure Cosmos DB for PostgreSQL przechowuje wiersze tabeli na różnych węzłach na podstawie wartości kolumny wyznaczonej przez użytkownika. Ten "kolumna dystrybucji" oznacza sposób dzielenia danych na fragmenty między węzłami.
Ustawmy kolumnę dystrybucji na site_id , czyli klucz fragmentu. W narzędziu psql uruchom następujące funkcje:
SELECT create_distributed_table('http_request', 'site_id');
SELECT create_distributed_table('http_request_1min', 'site_id');
Ważne
Rozpowszechnianie tabel lub używanie fragmentowania opartego na schemacie jest niezbędne do korzystania z funkcji wydajności usługi Azure Cosmos DB for PostgreSQL. Jeśli nie dystrybuujesz tabel ani schematów, węzły procesu roboczego nie mogą pomóc w uruchamianiu zapytań dotyczących ich danych.
Generowanie danych przykładowych
Teraz nasz klaster powinien być gotowy do pozyskiwania niektórych danych. Możemy uruchomić następujące polecenie lokalnie z naszego psql połączenia, aby stale wstawiać dane.
DO $$
BEGIN LOOP
INSERT INTO http_request (
site_id, ingest_time, url, request_country,
ip_address, status_code, response_time_msec
) VALUES (
trunc(random()*32), clock_timestamp(),
concat('http://example.com/', md5(random()::text)),
('{China,India,USA,Indonesia}'::text[])[ceil(random()*4)],
concat(
trunc(random()*250 + 2), '.',
trunc(random()*250 + 2), '.',
trunc(random()*250 + 2), '.',
trunc(random()*250 + 2)
)::inet,
('{200,404}'::int[])[ceil(random()*2)],
5+trunc(random()*150)
);
COMMIT;
PERFORM pg_sleep(random() * 0.25);
END LOOP;
END $$;
Zapytanie wstawia około ośmiu wierszy co sekundę. Wiersze są przechowywane w różnych węzłach procesu roboczego zgodnie z kolumną dystrybucji . site_id
Uwaga
Pozostaw uruchomione zapytanie generowania danych i otwórz drugie połączenie psql dla pozostałych poleceń w tym samouczku.
Query
Usługa Azure Cosmos DB for PostgreSQL umożliwia wielu węzłom równoległe przetwarzanie zapytań w celu uzyskania szybkości. Na przykład baza danych oblicza agregacje, takie jak SUM i COUNT w węzłach procesu roboczego, i łączy wyniki w ostateczną odpowiedź.
Oto zapytanie do zliczywania żądań internetowych na minutę wraz z kilkoma statystykami. Spróbuj uruchomić go w narzędziu psql i obserwuj wyniki.
SELECT
site_id,
date_trunc('minute', ingest_time) as minute,
COUNT(1) AS request_count,
SUM(CASE WHEN (status_code between 200 and 299) THEN 1 ELSE 0 END) as success_count,
SUM(CASE WHEN (status_code between 200 and 299) THEN 0 ELSE 1 END) as error_count,
SUM(response_time_msec) / COUNT(1) AS average_response_time_msec
FROM http_request
WHERE date_trunc('minute', ingest_time) > now() - '5 minutes'::interval
GROUP BY site_id, minute
ORDER BY minute ASC;
Zwijanie danych
Poprzednie zapytanie działa prawidłowo we wczesnych etapach, ale jego wydajność spada w miarę skalowania danych. Nawet w przypadku przetwarzania rozproszonego szybsze jest wstępne obliczenie danych niż ponowne obliczenie ich wielokrotnie.
Możemy zapewnić, że nasz pulpit nawigacyjny jest szybki, regularnie rolując nieprzetworzone dane do tabeli zagregowanej. Możesz eksperymentować z czasem trwania agregacji. Użyliśmy tabeli agregacji na minutę, ale zamiast tego można podzielić dane na 5, 15 lub 60 minut.
Aby łatwiej uruchomić ten pakiet zbiorczy, umieścimy go w funkcji plpgsql. Uruchom te polecenia w narzędziu rollup_http_request psql, aby utworzyć funkcję.
-- initialize to a time long ago
INSERT INTO latest_rollup VALUES ('10-10-1901');
-- function to do the rollup
CREATE OR REPLACE FUNCTION rollup_http_request() RETURNS void AS $$
DECLARE
curr_rollup_time timestamptz := date_trunc('minute', now());
last_rollup_time timestamptz := minute from latest_rollup;
BEGIN
INSERT INTO http_request_1min (
site_id, ingest_time, request_count,
success_count, error_count, average_response_time_msec
) SELECT
site_id,
date_trunc('minute', ingest_time),
COUNT(1) as request_count,
SUM(CASE WHEN (status_code between 200 and 299) THEN 1 ELSE 0 END) as success_count,
SUM(CASE WHEN (status_code between 200 and 299) THEN 0 ELSE 1 END) as error_count,
SUM(response_time_msec) / COUNT(1) AS average_response_time_msec
FROM http_request
-- roll up only data new since last_rollup_time
WHERE date_trunc('minute', ingest_time) <@
tstzrange(last_rollup_time, curr_rollup_time, '(]')
GROUP BY 1, 2;
-- update the value in latest_rollup so that next time we run the
-- rollup it will operate on data newer than curr_rollup_time
UPDATE latest_rollup SET minute = curr_rollup_time;
END;
$$ LANGUAGE plpgsql;
Po wdrożeniu funkcji wykonaj ją, aby zwijać dane:
SELECT rollup_http_request();
Dzięki naszym danym w formularzu wstępnie zagregowanym możemy wysłać zapytanie do tabeli zestawienia, aby uzyskać ten sam raport co wcześniej. Uruchom poniższe zapytanie:
SELECT site_id, ingest_time as minute, request_count,
success_count, error_count, average_response_time_msec
FROM http_request_1min
WHERE ingest_time > date_trunc('minute', now()) - '5 minutes'::interval;
Wygasające stare dane
Pakiety zbiorcze przyspieszają wykonywanie zapytań, ale nadal musimy wygasnąć stare dane, aby uniknąć niezwiązanych kosztów magazynowania. Zdecyduj, jak długo chcesz przechowywać dane dla każdego stopnia szczegółowości, i użyj standardowych zapytań, aby usunąć wygasłe dane. W poniższym przykładzie postanowiliśmy zachować nieprzetworzone dane przez jeden dzień i agregacje na minutę przez jeden miesiąc:
DELETE FROM http_request WHERE ingest_time < now() - interval '1 day';
DELETE FROM http_request_1min WHERE ingest_time < now() - interval '1 month';
W środowisku produkcyjnym można opakowować te zapytania w funkcji i wywoływać je co minutę w zadaniu cron.
Czyszczenie zasobów
W poprzednich krokach utworzono zasoby platformy Azure w klastrze. Jeśli nie spodziewasz się, że te zasoby będą potrzebne w przyszłości, usuń klaster. Naciśnij przycisk Usuń na stronie Przegląd klastra. Po wyświetleniu monitu na wyskakującym okienku potwierdź nazwę klastra i kliknij końcowy przycisk Usuń .
Następne kroki
W tym samouczku przedstawiono sposób aprowizacji klastra. Nawiązano z nim połączenie za pomocą narzędzia psql, utworzono schemat i rozproszone dane. Wiesz już, jak wykonywać zapytania dotyczące danych w postaci pierwotnej, regularnie agregować te dane, wykonywać zapytania względem zagregowanych tabel i wygasać stare dane.
- Dowiedz się więcej o typach węzłów klastra
- Określanie najlepszego rozmiaru początkowego klastra