Wprowadzenie do przechwytywania zmian danych w magazynie analitycznym dla usługi Azure Cosmos DB
DOTYCZY: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB
Użyj funkcji przechwytywania zmian danych (CDC) w magazynie analitycznym usługi Azure Cosmos DB jako źródła do usługi Azure Data Factory lub Azure Synapse Analytics , aby przechwycić określone zmiany danych.
Uwaga
Należy pamiętać, że połączony interfejs usługi dla interfejsu API usługi Azure Cosmos DB dla bazy danych MongoDB nie jest jeszcze dostępny w przepływie danych. Jednak możesz użyć punktu końcowego dokumentu konta z połączonym interfejsem usługi "Azure Cosmos DB for NoSQL" jako obejściem, dopóki połączona usługa Mongo nie będzie obsługiwana. W połączonej usłudze NoSQL wybierz pozycję "Wprowadź ręcznie", aby podać informacje o koncie usługi Cosmos DB i użyć punktu końcowego dokumentu konta (np. https://[your-database-account-uri].documents.azure.com:443/) zamiast punktu końcowego bazy danych MongoDB (np. mongodb://[your-database-account-uri].mongo.cosmos.azure.com:10255/)
Wymagania wstępne
- Istniejące konto usługi Azure Cosmos DB.
- Jeśli masz subskrypcję platformy Azure, utwórz nowe konto.
- Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto.
- Alternatywnie możesz wypróbować usługę Azure Cosmos DB bezpłatnie przed zatwierdzeniem.
Włączanie magazynu analitycznego
Najpierw włącz usługę Azure Synapse Link na poziomie konta, a następnie włącz magazyn analityczny dla kontenerów odpowiednich dla obciążenia.
Włączanie usługi Azure Synapse Link: włączanie usługi Azure Synapse Link dla konta usługi Azure Cosmos DB
Włącz magazyn analityczny dla kontenerów:
Opcja Przewodnik Włączanie dla określonego nowego kontenera Włączanie usługi Azure Synapse Link dla nowych kontenerów Włączanie dla określonego istniejącego kontenera Włączanie usługi Azure Synapse Link dla istniejących kontenerów
Tworzenie docelowego zasobu platformy Azure przy użyciu przepływów danych
Funkcja przechwytywania danych zmian magazynu analitycznego jest dostępna za pośrednictwem funkcji przepływu danych usługi Azure Data Factory lub Azure Synapse Analytics. W tym przewodniku użyj usługi Azure Data Factory.
Ważne
Alternatywnie możesz użyć usługi Azure Synapse Analytics. Najpierw utwórz obszar roboczy usługi Azure Synapse, jeśli jeszcze go nie masz. W nowo utworzonym obszarze roboczym wybierz kartę Programowanie , wybierz pozycję Dodaj nowy zasób, a następnie wybierz pozycję Przepływ danych.
Utwórz usługę Azure Data Factory, jeśli jeszcze jej nie masz.
Napiwek
Jeśli to możliwe, utwórz fabrykę danych w tym samym regionie, w którym znajduje się twoje konto usługi Azure Cosmos DB.
Uruchom nowo utworzoną fabrykę danych.
W fabryce danych wybierz kartę Przepływy danych, a następnie wybierz pozycję Nowy przepływ danych.
Nadaj nowo utworzonemu przepływowi danych unikatową nazwę. W tym przykładzie przepływ danych nosi nazwę
cosmoscdc.

Konfigurowanie ustawień źródła dla kontenera magazynu analitycznego
Teraz utwórz i skonfiguruj źródło do przepływu danych z magazynu analitycznego konta usługi Azure Cosmos DB.
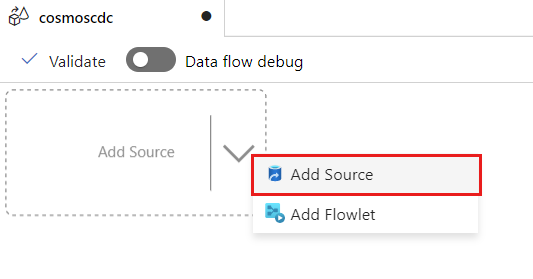
Wybierz Dodaj źródło danych.
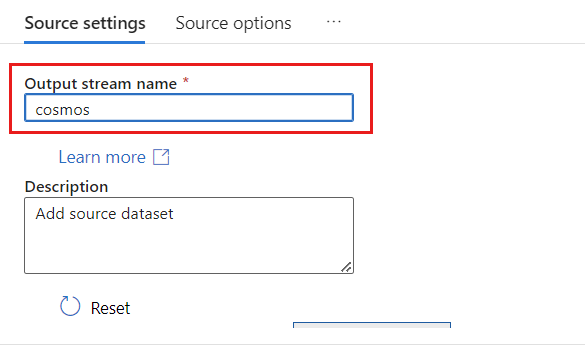
W polu Nazwa strumienia wyjściowego wprowadź cosmos.
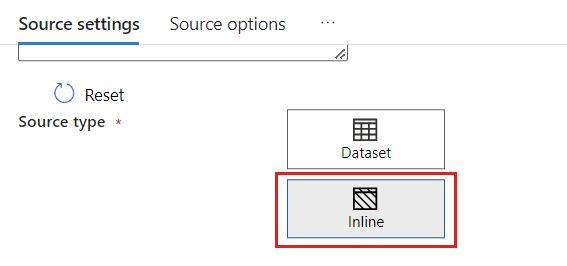
W sekcji Typ źródła wybierz pozycję Wbudowany.
W polu Zestaw danych wybierz pozycję Azure — Azure Cosmos DB for NoSQL.
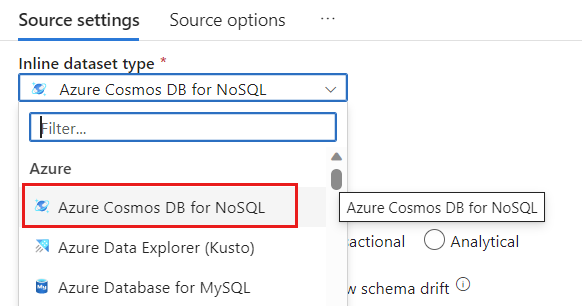
Utwórz nową połączoną usługę dla swojego konta o nazwie cosmoslinkedservice. Wybierz istniejące konto usługi Azure Cosmos DB for NoSQL w oknie podręcznym Nowa połączona usługa , a następnie wybierz przycisk OK. W tym przykładzie wybieramy istniejące konto usługi Azure Cosmos DB for NoSQL o nazwie i bazę danych o nazwie
msdocs-cosmos-sourcecosmicworks.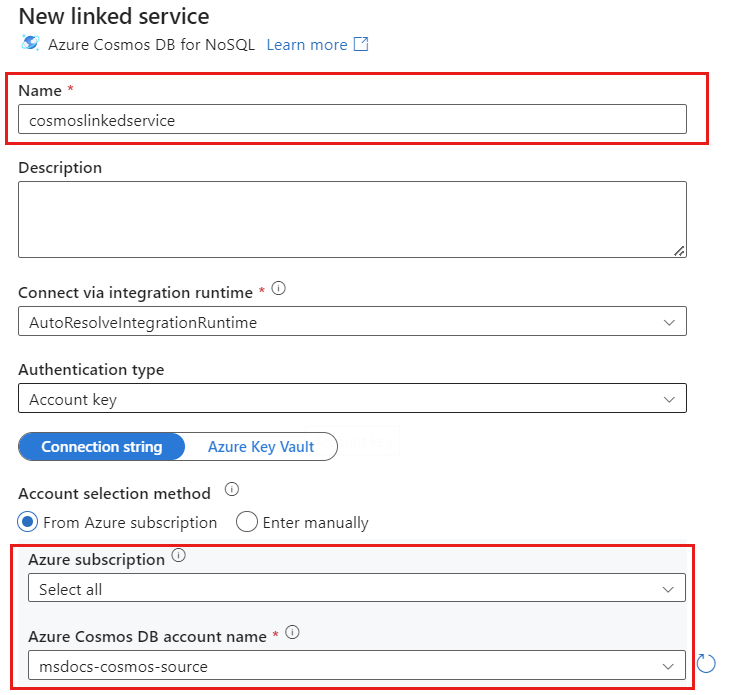
Wybierz pozycję Analiza dla typu magazynu.
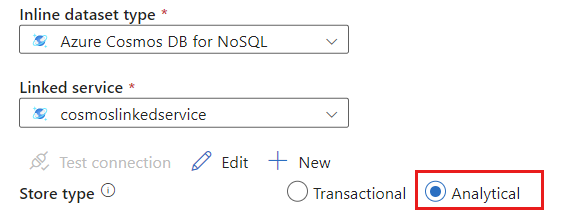
Wybierz kartę Opcje źródła.
W obszarze Opcje źródła wybierz kontener docelowy i włącz debugowanie przepływu danych. W tym przykładzie kontener ma nazwę
products.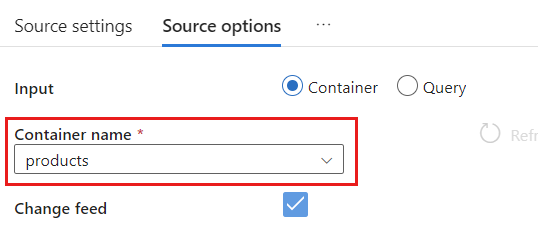
Wybierz pozycję Debugowanie przepływu danych. W oknie podręcznym Włączanie debugowania przepływu danych zachowaj opcje domyślne, a następnie wybierz przycisk OK.
Karta Opcje źródła zawiera również inne opcje, które można włączyć. W tej tabeli opisano te opcje:
| Opcja | Opis |
|---|---|
| Przechwytywanie aktualizacji pośrednich | Włącz tę opcję, jeśli chcesz przechwycić historię zmian w elementach, w tym pośrednie zmiany między odczytami przechwytywania zmian danych. |
| Przechwytywanie usuniętych | Włącz tę opcję, aby przechwycić rekordy usunięte przez użytkownika i zastosować je w ujściu. Nie można zastosować usuwania w eksploratorze danych platformy Azure i ujściach usługi Azure Cosmos DB. |
| Przechwytywanie list TTL magazynu transakcyjnego | Włącz tę opcję, aby przechwycić rekordy czasu wygaśnięcia (czas wygaśnięcia) magazynu transakcyjnego usługi Azure Cosmos DB i zastosować je w ujściu. Nie można zastosować usuwania czasu wygaśnięcia w ujściach usługi Azure Data Explorer i azure Cosmos DB. |
| Rozmiar wsadowy w bajtach | To ustawienie jest w rzeczywistości gigabajtami. Określ rozmiar w gigabajtach, jeśli chcesz wsadować zestawienia przechwytywania zmian danych |
| Dodatkowe konfiguracje | Dodatkowe konfiguracje magazynu analitycznego usługi Azure Cosmos DB i ich wartości. (np. spark.cosmos.allowWhiteSpaceInFieldNames -> true) |
Praca z opcjami źródła
Po sprawdzeniu dowolnej z opcji , Capture Deltesi Capture Transactional store TTLs proces CDC utworzy i wypełni __usr_opType pole w ujściu Capture intermediate updatesnastępującymi wartościami:
| Wartość | Opis | Opcja |
|---|---|---|
| 1 | UPDATE | Przechwyć aktualizacje pośrednie |
| 2 | INSERT | Nie ma opcji wstawiania, jest domyślnie włączona |
| 3 | USER_DELETE | Przechwytywanie usuniętych |
| 100 | TTL_DELETE | Przechwytywanie list TTL magazynu transakcyjnego |
Jeśli musisz odróżnić rekordy czasu wygaśnięcia usunięte z dokumentów usuniętych przez użytkowników lub aplikacje, sprawdź obie Capture intermediate updates opcje i Capture Transactional store TTLs . Następnie musisz dostosować procesy cdC lub aplikacje lub zapytania do użycia __usr_opType zgodnie z potrzebami biznesowymi.
Napiwek
Jeśli istnieje potrzeba, aby odbiorcy podrzędni przywrócili kolejność aktualizacji z zaznaczoną opcją "przechwyć aktualizacje pośrednie", pole sygnatury _ts czasowej systemu może być używane jako pole zamawiania.
Tworzenie i konfigurowanie ustawień ujścia dla operacji aktualizacji i usuwania
Najpierw utwórz prosty ujście usługi Azure Blob Storage , a następnie skonfiguruj ujście, aby filtrować dane tylko do określonych operacji.
Utwórz konto i kontener usługi Azure Blob Storage , jeśli jeszcze go nie masz. W następnych przykładach użyjemy konta o nazwie
msdocsblobstoragei kontenera o nazwieoutput.Napiwek
Jeśli to możliwe, utwórz konto magazynu w tym samym regionie, w którym znajduje się twoje konto usługi Azure Cosmos DB.
Wróć do usługi Azure Data Factory, utwórz nowy ujście dla danych zmian przechwyconych ze
cosmosźródła.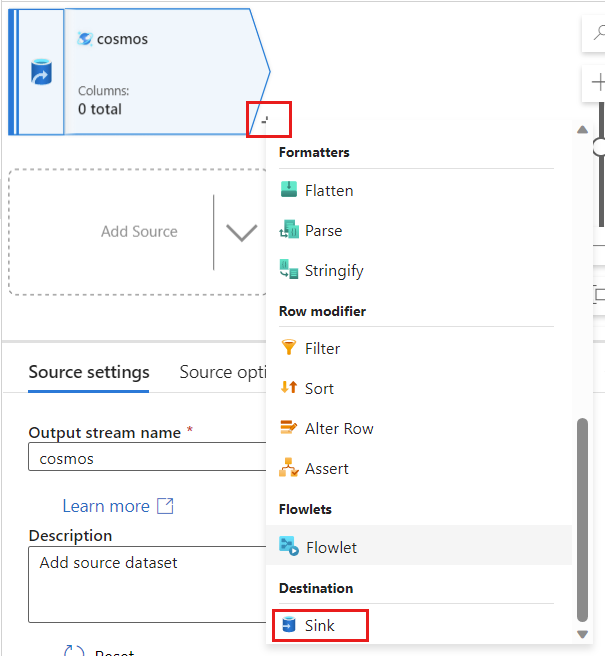
Nadaj ujściu unikatową nazwę. W tym przykładzie ujście nosi nazwę
storage.
W sekcji Typ ujścia wybierz pozycję Wbudowany. W polu Zestaw danych wybierz pozycję Delta.
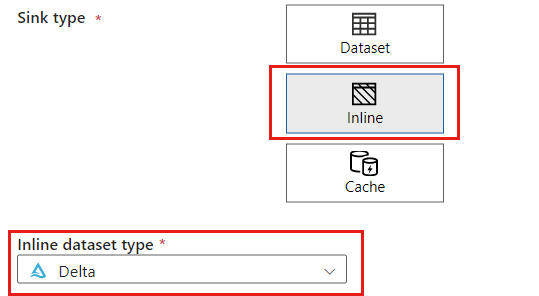
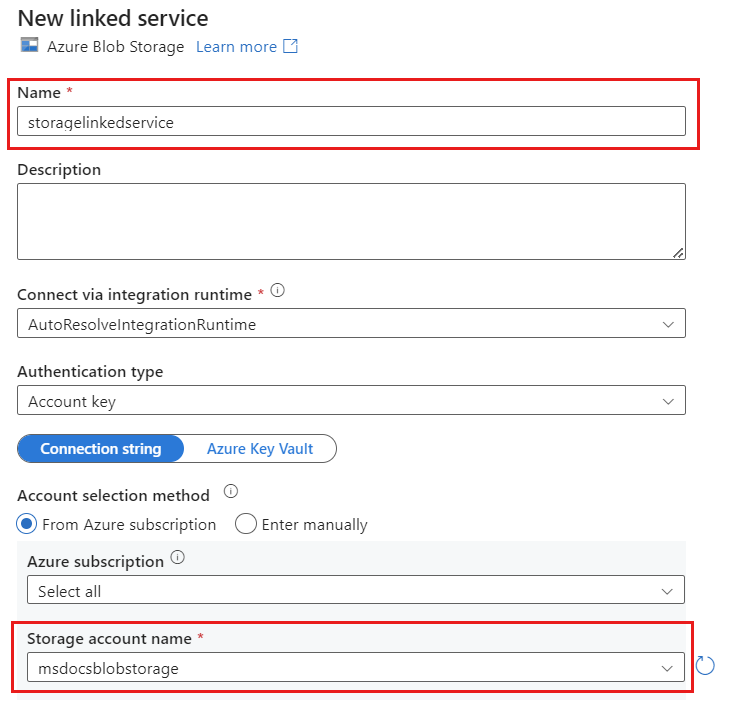
Utwórz nową połączoną usługę dla konta przy użyciu usługi Azure Blob Storage o nazwie storagelinkedservice. Wybierz istniejące konto usługi Azure Blob Storage w oknie podręcznym Nowa połączona usługa , a następnie wybierz przycisk OK. W tym przykładzie wybieramy wstępnie istniejące konto usługi Azure Blob Storage o nazwie
msdocsblobstorage.
Wybierz kartę Ustawienia.
W obszarze Ustawienia ustaw ścieżkę folderu na nazwę kontenera obiektów blob. W tym przykładzie nazwa kontenera to
output.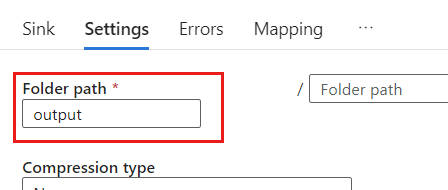
Znajdź sekcję Metoda aktualizacji i zmień wybrane opcje, aby zezwalać tylko na operacje usuwania i aktualizacji . Ponadto określ kolumny Klucz jako listę kolumn używających pola
{_rid}jako unikatowego identyfikatora.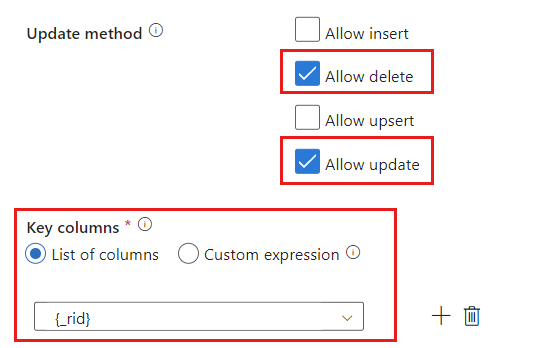
Wybierz pozycję Zweryfikuj , aby upewnić się, że nie wystąpiły żadne błędy ani pominięte. Następnie wybierz pozycję Publikuj , aby opublikować przepływ danych.
Planowanie wykonywania przechwytywania zmian danych
Po opublikowaniu przepływu danych możesz dodać nowy potok, aby przenieść i przekształcić dane.
Tworzenie nowego potoku. Nadaj potokowi unikatową nazwę. W tym przykładzie potok ma nazwę
cosmoscdcpipeline.
W sekcji Działania rozwiń opcję Przenieś i przekształć, a następnie wybierz pozycję Przepływ danych.
Nadaj działaniu przepływu danych unikatową nazwę. W tym przykładzie działanie nosi nazwę
cosmoscdcactivity.Na karcie Ustawienia wybierz przepływ danych o nazwie
cosmoscdcutworzony wcześniej w tym przewodniku. Następnie wybierz rozmiar obliczeniowy na podstawie ilości danych i wymaganego opóźnienia dla obciążenia.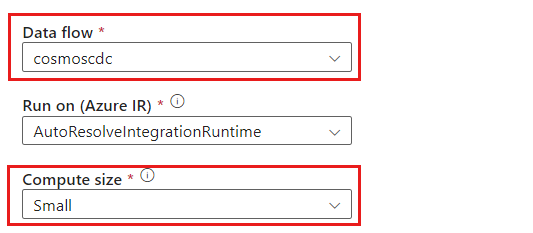
Napiwek
W przypadku przyrostowych rozmiarów danych większych niż 100 GB zalecamy rozmiar niestandardowy z liczbą rdzeni 32 (+16 rdzeni sterowników).
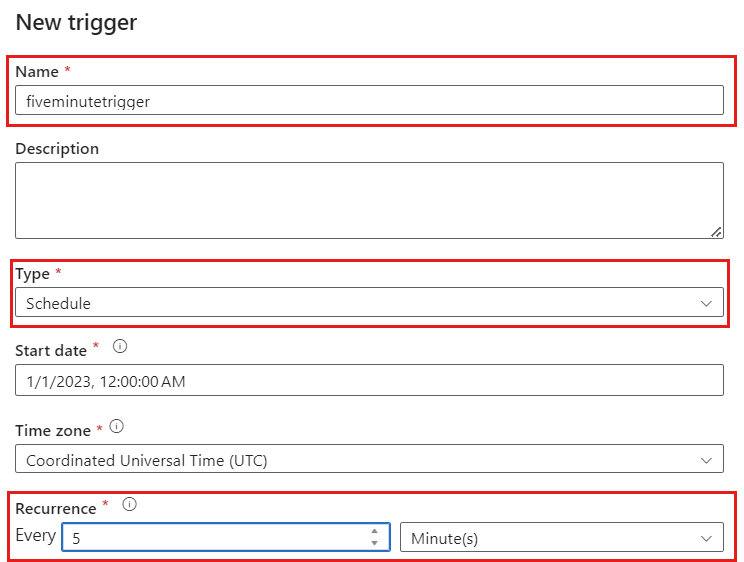
Wybierz pozycję Dodaj wyzwalacz. Zaplanuj wykonanie tego potoku w tempie, który ma sens dla obciążenia. W tym przykładzie potok jest skonfigurowany do wykonywania co pięć minut.
Uwaga
Minimalne okno cyklu dla wykonań przechwytywania danych zmian wynosi minutę.
Wybierz pozycję Zweryfikuj , aby upewnić się, że nie wystąpiły żadne błędy ani pominięte. Następnie wybierz pozycję Publikuj , aby opublikować potok.
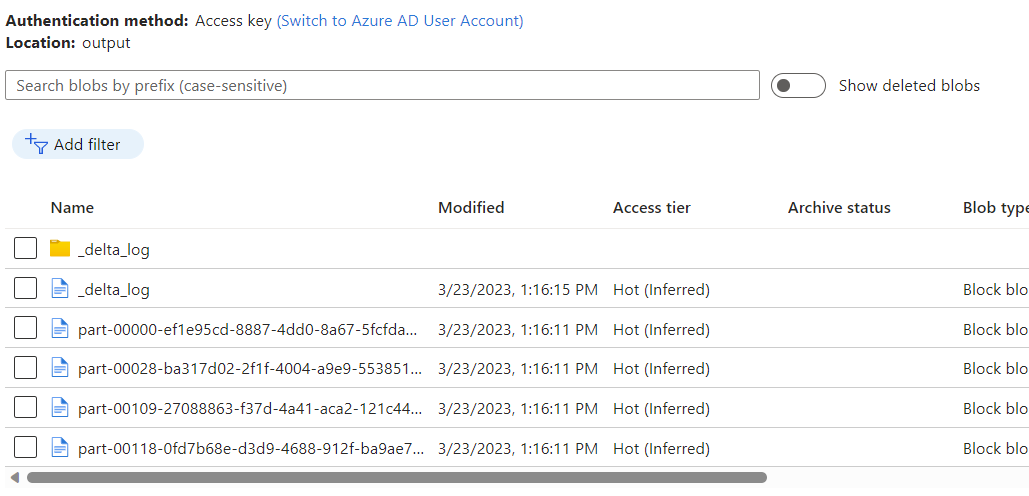
Obserwuj dane umieszczone w kontenerze usługi Azure Blob Storage jako dane wyjściowe przepływu danych przy użyciu funkcji przechwytywania zmian magazynu analitycznego usługi Azure Cosmos DB.
Uwaga
Początkowy czas uruchamiania klastra może potrwać do trzech minut. Aby uniknąć czasu uruchamiania klastra w kolejnych wykonaniach przechwytywania danych zmiany, skonfiguruj wartość Czas wygaśnięcia klastra przepływu danych. Aby uzyskać więcej informacji na temat środowiska uruchomieniowego itegration i czasu wygaśnięcia, zobacz Integration Runtime w usłudze Azure Data Factory.
Współbieżne zadania
Rozmiar partii w opcjach źródłowych lub sytuacjach, gdy ujście jest powolne pozyskiwanie strumienia zmian, może spowodować wykonanie wielu zadań w tym samym czasie. Aby uniknąć tej sytuacji, ustaw opcję współbieżności na 1 w ustawieniach potoku, aby upewnić się, że nowe wykonania nie zostaną wyzwolone do momentu zakończenia bieżącego wykonywania.
Następne kroki
- Zapoznaj się z omówieniem magazynu analitycznego usługi Azure Cosmos DB