Co to są przepływy danych w usłudze Azure Synapse Analytics?
Przepływy danych są wizualnie zaprojektowane przekształcenia danych w usłudze Azure Synapse Analytics. Przepływy danych umożliwiają inżynierom danych opracowywanie logiki przekształcania danych bez pisania kodu. Wynikowe przepływy danych są wykonywane jako działania w potokach usługi Azure Synapse Analytics, które używają skalowanych w poziomie klastrów platformy Apache Spark. Działania przepływu danych można zoperacjonalizować przy użyciu istniejących funkcji planowania, sterowania, przepływu i monitorowania usługi Azure Synapse Analytics.
Przepływy danych zapewniają całkowicie wizualne środowisko bez konieczności kodowania. Przepływy danych są uruchamiane w klastrach wykonywania zarządzanego przez usługę Synapse na potrzeby skalowalnego w poziomie przetwarzania danych. Usługa Azure Synapse Analytics obsługuje całe tłumaczenie kodu, optymalizację ścieżki i wykonywanie zadań przepływu danych.
Rozpocznij
Przepływy danych są tworzone na podstawie okienka Programowanie w programie Synapse Studio. Aby utworzyć przepływ danych, wybierz znak plus obok pozycji Programowanie, a następnie wybierz pozycję Przepływ danych.
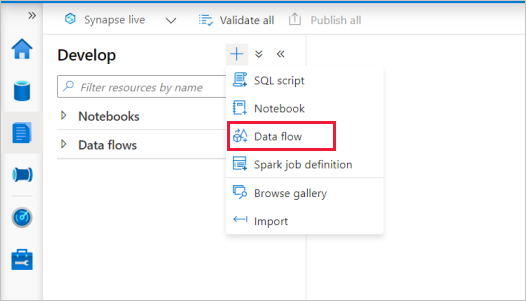
Ta akcja powoduje przejście do kanwy przepływu danych, w której można utworzyć logikę przekształcania. Wybierz pozycję Dodaj źródło , aby rozpocząć konfigurowanie transformacji źródłowej. Aby uzyskać więcej informacji, zobacz Przekształcanie źródła.
Tworzenie przepływów danych
Przepływ danych ma unikatową kanwę tworzenia, która ułatwia tworzenie logiki transformacji. Kanwa przepływu danych jest podzielona na trzy części: górny pasek, graf i panel konfiguracji.
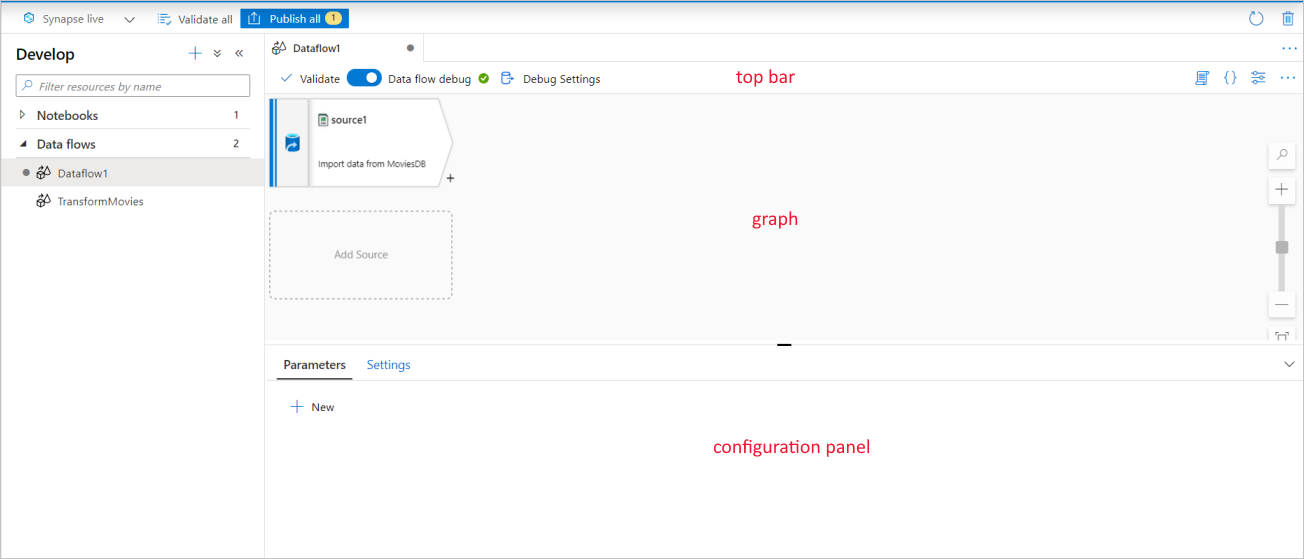
Wykres
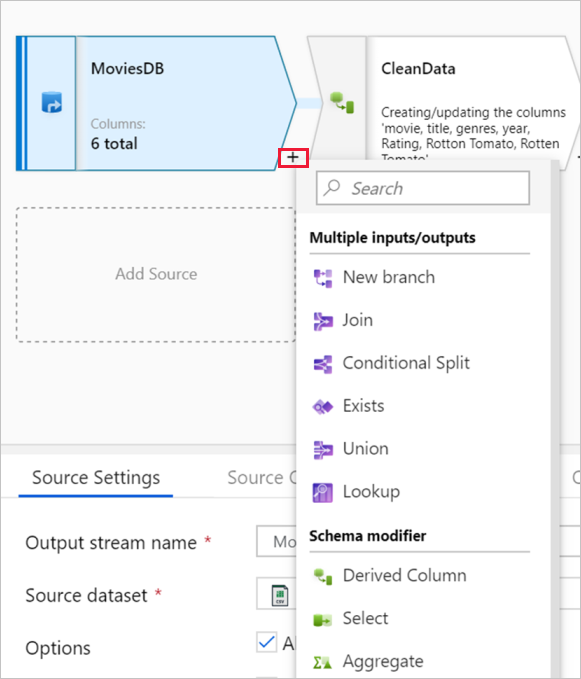
Wykres wyświetla strumień transformacji. Przedstawia pochodzenie danych źródłowych, gdy przepływa do co najmniej jednego ujścia. Aby dodać nowe źródło, wybierz pozycję Dodaj źródło. Aby dodać nową transformację, wybierz znak plus w prawym dolnym rogu istniejącej transformacji. Dowiedz się więcej na temat zarządzania wykresem przepływu danych.
Panel konfiguracji
Na panelu konfiguracji są wyświetlane ustawienia specyficzne dla aktualnie wybranej transformacji. Jeśli nie wybrano przekształcenia, zostanie wyświetlony przepływ danych. W ogólnej konfiguracji przepływu danych można dodać parametry za pomocą karty Parametry . Aby uzyskać więcej informacji, zobacz Parametry przepływu danych.
Każde przekształcenie zawiera co najmniej cztery karty konfiguracji.
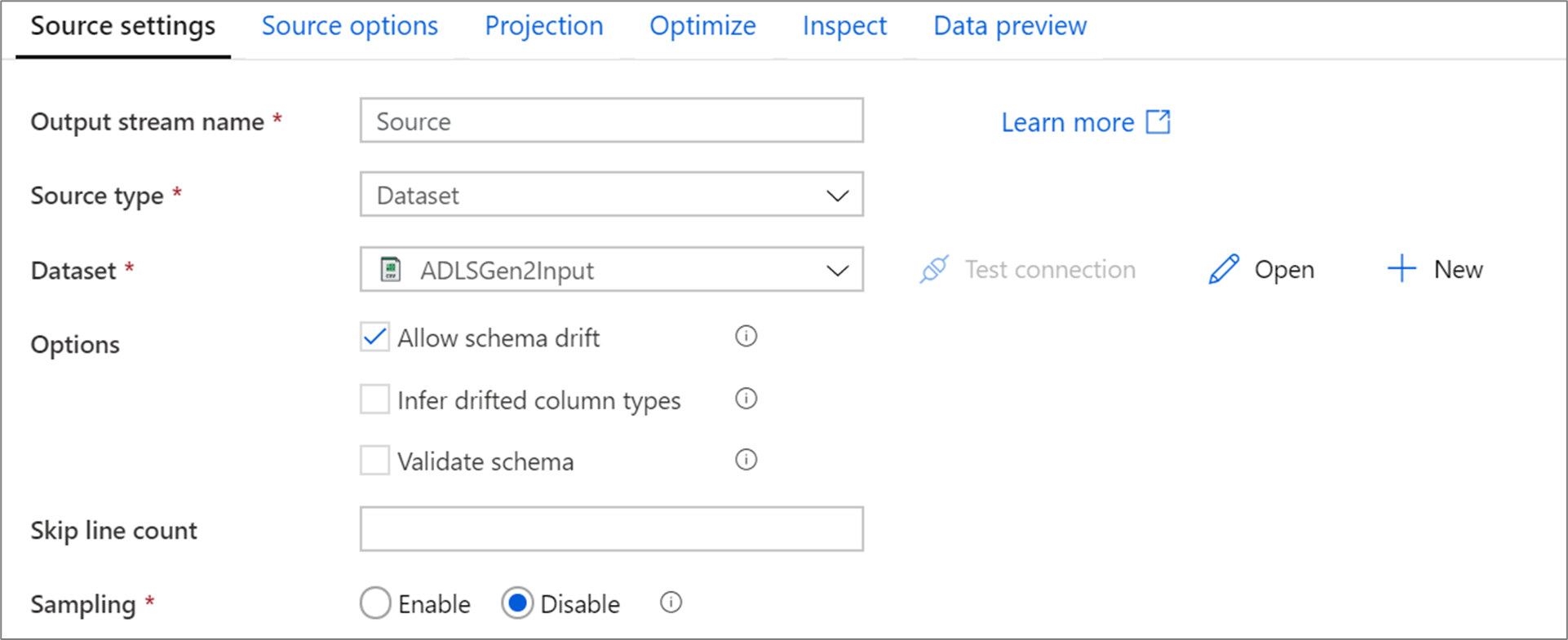
Ustawienia przekształcania
Pierwsza karta w okienku konfiguracji każdego przekształcenia zawiera ustawienia specyficzne dla tej transformacji. Aby uzyskać więcej informacji, zobacz stronę dokumentacji przekształcenia.
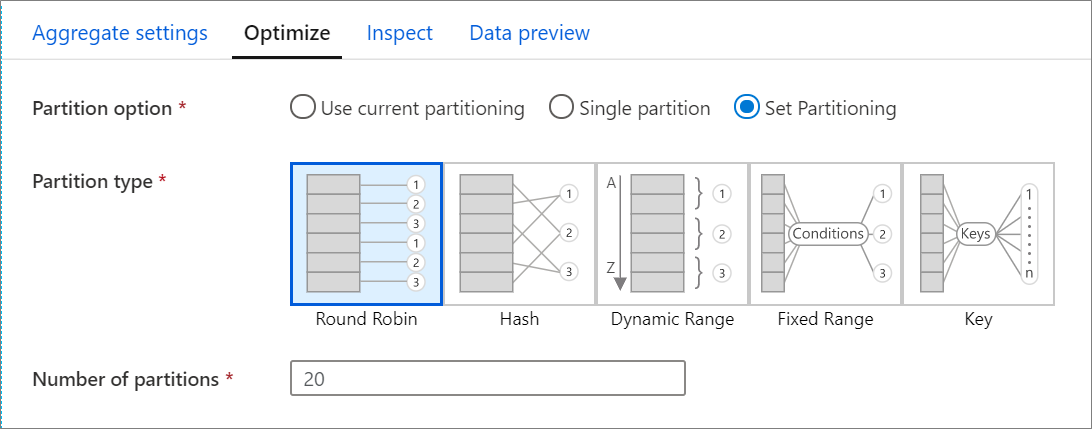
Optymalizacja
Karta Optymalizacja zawiera ustawienia służące do konfigurowania schematów partycjonowania. Aby dowiedzieć się więcej na temat optymalizowania przepływów danych, zobacz przewodnik dotyczący wydajności przepływu mapowania danych.
Kontrola
Karta Inspekcja zawiera widok metadanych strumienia danych, który jest przekształcany. Liczby kolumn, zmienione kolumny, dodane kolumny, typy danych, kolejność kolumn i odwołania do kolumn. Inspekcja to widok metadanych tylko do odczytu. Nie musisz mieć włączonego trybu debugowania, aby wyświetlić metadane w okienku Inspekcja .
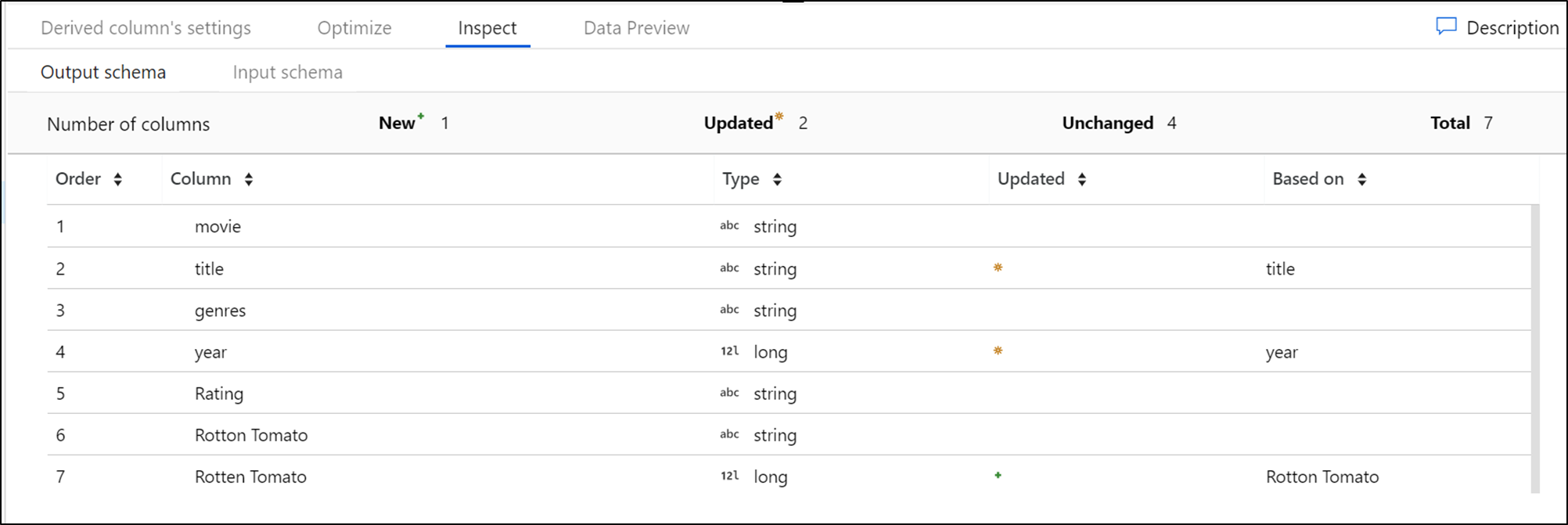
Po zmianie kształtu danych za pomocą przekształceń zobaczysz przepływ zmian metadanych w okienku Inspekcja . Jeśli w transformacji źródłowej nie ma zdefiniowanego schematu, metadane nie są widoczne w okienku Inspekcja . Brak metadanych jest typowy w scenariuszach dryfu schematu.
Podgląd danych
Jeśli tryb debugowania jest włączony, karta Podgląd danych zawiera interaktywną migawkę danych w każdej transformacji. Aby uzyskać więcej informacji, zobacz Podgląd danych w trybie debugowania.
Górny pasek
Górny pasek zawiera akcje wpływające na cały przepływ danych, takie jak ustawienia walidacji i debugowania. Możesz również wyświetlić źródłowy skrypt przepływu danych i kodu JSON logiki transformacji.
Dostępne przekształcenia
Zapoznaj się z omówieniem przekształcania przepływu mapowania danych, aby uzyskać listę dostępnych przekształceń.
Działanie przepływu danych
Przepływy danych są operacjonalizowane w potokach usługi Azure Synapse Analytics przy użyciu działania przepływu danych. Każdy użytkownik musi to zrobić, to określić, które środowisko Integration Runtime ma używać i przekazywać wartości parametrów. Aby uzyskać więcej informacji, dowiedz się więcej o środowisku Azure Integration Runtime.
Tryb debugowania
Tryb debugowania umożliwia interaktywne wyświetlanie wyników każdego kroku transformacji podczas kompilowania i debugowania przepływów danych. Sesja debugowania może być używana zarówno podczas tworzenia logiki przepływu danych, jak i uruchamiania przebiegów debugowania potoku z działaniami przepływu danych. Aby dowiedzieć się więcej, zobacz dokumentację trybu debugowania.
Monitorowanie przepływów danych
Przepływ danych integruje się z istniejącymi możliwościami monitorowania usługi Azure Synapse Analytics. Aby dowiedzieć się, jak zrozumieć dane wyjściowe monitorowania przepływu danych, zobacz Monitorowanie przepływów danych mapowania.
Zespół usługi Azure Synapse Analytics utworzył przewodnik po dostrajaniu wydajności, który pomoże ci zoptymalizować czas wykonywania przepływów danych po utworzeniu logiki biznesowej.