Wydajność i rozwiązywanie problemów z wyodrębnianiem danych SAP
Ten artykuł jest częścią serii artykułów "Sap extend and innovate data: Best practices" (Rozszerzanie i wprowadzanie innowacji w oprogramowaniu SAP: najlepsze rozwiązania).
- Identyfikowanie źródeł danych SAP
- Wybieranie najlepszego łącznika SAP
- Wydajność i rozwiązywanie problemów z wyodrębnianiem danych SAP
- Zabezpieczenia integracji danych dla oprogramowania SAP na platformie Azure
- Architektura ogólna integracji danych SAP
Istnieje wiele sposobów nawiązywania połączenia z systemem SAP na potrzeby integracji danych. W poniższych sekcjach opisano ogólne i specyficzne dla łącznika zagadnienia i zalecenia.
Wydajność
Ważne jest, aby skonfigurować optymalne ustawienia dla źródła i celu, aby można było osiągnąć najlepszą wydajność podczas wyodrębniania i przetwarzania danych.
Zagadnienia ogólne
- Upewnij się, że ustawiono prawidłowe parametry SAP dla maksymalnego połączenia współbieżnego.
- Rozważ użycie typu logowania grupy SAP w celu uzyskania lepszej wydajności i dystrybucji obciążenia.
- Upewnij się, że maszyna wirtualna własnego środowiska Integration Runtime (SHIR) ma odpowiedni rozmiar i jest wysoce dostępna.
- Podczas pracy z dużymi zestawami danych sprawdź, czy używany łącznik zapewnia możliwość partycjonowania. Wiele łączników SAP obsługuje partycjonowanie i równoległe możliwości przyspieszania ładowania danych. W przypadku użycia tej metody dane są pakowane w mniejsze fragmenty, które można załadować przy użyciu kilku procesów równoległych. Aby uzyskać więcej informacji, zobacz dokumentację specyficzną dla łącznika.
Ogólne zalecenia
Użyj transakcji SAP RZ12, aby zmodyfikować wartości maksymalnej liczby połączeń współbieżnych.
Parametry SAP dla RFC — RZ12: Następujący parametr może ograniczyć liczbę wywołań RFC dozwolonych dla jednego użytkownika lub jednej aplikacji, dlatego upewnij się, że to ograniczenie nie powoduje wąskiego gardła.
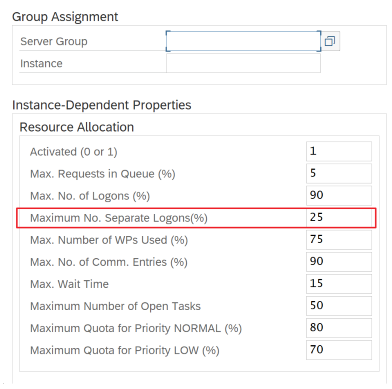
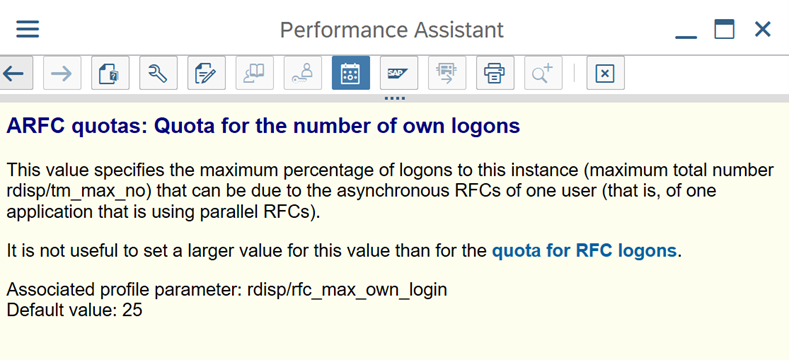
Połączenie z oprogramowaniem SAP przy użyciu grupy logowania: SHIR (self-hosted Integration Runtime) powinno łączyć się z oprogramowaniem SAP przy użyciu grupy logowania SAP (za pośrednictwem serwera komunikatów), a nie do określonego serwera aplikacji, aby zapewnić dystrybucję obciążenia na wszystkich dostępnych serwerach aplikacji.
Uwaga
Klaster Spark przepływu danych i środowisko SHIR są zaawansowane. Wiele wewnętrznych działań kopiowania SAP, na przykład 16, można wyzwolić i wykonać. Jeśli jednak numer połączenia współbieżnego serwera SAP jest mały, na przykład 8, perf odczytuje dane ze strony sap.
Zacznij od 4vCPU i 16 GB maszyn wirtualnych dla środowiska SHIR. W poniższych krokach pokazano połączenie procesu roboczego okna dialogowego w oprogramowaniu SAP z platformą SHIR.
- Sprawdź, czy klient używa słabej maszyny fizycznej do skonfigurowania i zainstalowania środowiska SHIR w celu uruchomienia wewnętrznej kopii systemu SAP.
- Przejdź do portalu Azure Data Factory i znajdź powiązaną połączoną usługę SAP CDC używaną w przepływie danych. Sprawdź przywołyną nazwę SHIR.
- Sprawdź ustawienia procesora CPU, pamięci, sieci i dysku maszyny fizycznej, na której zainstalowano środowisko SHIR.
- Sprawdź, ile
diawp.exejest uruchomionych na maszynie SHIR. Możnadiawp.exeuruchomić jedno działanie kopiowania.diawp.exeLiczba jest oparta na ustawieniach procesora CPU, pamięci, sieci i dysku maszyny.
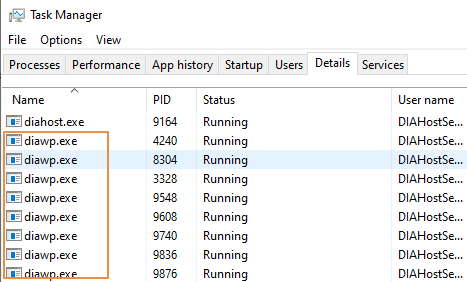
Jeśli chcesz uruchomić wiele partycji równolegle w środowisku SHIR, użyj wydajnej maszyny wirtualnej do skonfigurowania środowiska SHIR. Możesz też użyć skalowania w poziomie przy użyciu funkcji wysokiej dostępności i skalowalności SHIR, aby mieć wiele węzłów. Aby uzyskać więcej informacji, zobacz Wysoka dostępność i skalowalność.
Partycje
W poniższej sekcji opisano proces partycjonowania dla łącznika SAP CDC. Proces jest taki sam w przypadku łącznika SAP Table i SAP BW Open Hub.

Skalowanie można wykonać na własnym środowisku IR lub środowisku Azure IR w zależności od wymagań dotyczących wydajności. Zapoznaj się z użyciem procesora CPU środowiska SHIR, aby wyświetlić metryki ułatwiające podjęcie decyzji o podejściu do skalowania. Środowisko SHIR może być skalowane w pionie lub w poziomie w zależności od potrzeb. Zalecamy wdrożenie środowiska Azure IR w niższej jednostce SKU. Przeprowadź skalowanie w górę, aby spełnić wymagania dotyczące wydajności określone w ramach testowania obciążenia, zamiast niepotrzebnie rozpoczynać się od wyższego poziomu.
Uwaga
Jeśli osiągniesz 70% pojemności, przeprowadź skalowanie w górę lub w poziomie dla środowiska SHIR.

Partycjonowanie jest przydatne w przypadku początkowych lub dużych pełnych obciążeń i zwykle nie jest wymagane w przypadku obciążeń różnicowych. Jeśli partycja nie zostanie określona, domyślnie 1 "producent" w systemie SAP (zazwyczaj jeden proces wsadowy) pobiera dane źródłowe do operacyjnej kolejki danych (ODQ), a środowisko SHIR pobiera dane z funkcji ODQ. Domyślnie środowisko SHIR używa czterech wątków do pobierania danych z funkcji ODQ, więc potencjalnie cztery procesy okien dialogowych są zajęte w systemie SAP w tym czasie.
Ideą partycjonowania jest podzielenie dużego początkowego zestawu danych na wiele mniejszych rozłącznych podzestawów, które są idealnie równe rozmiarowi i które mogą być przetwarzane równolegle. Ta metoda skraca czas potrzebny na utworzenie danych z tabeli źródłowej do funkcji ODQ w sposób liniowy. W tej metodzie przyjęto założenie, że po stronie sap są wystarczające zasoby do obsługi obciążenia.
Uwaga
- Liczba partycji wykonywanych równolegle jest ograniczona przez liczbę rdzeni sterowników w środowisku Azure IR. Rozwiązanie tego ograniczenia jest obecnie w toku.
- Każda jednostka lub pakiet w transakcji SAP ODQMON jest pojedynczym plikiem w folderze przejściowym.
Zagadnienia dotyczące projektowania podczas uruchamiania potoków przy użyciu usługi CDC
Sprawdź czas trwania etapu oprogramowania SAP.
Sprawdź wydajność środowiska uruchomieniowego w ujściu.
Rozważ użycie funkcji partycjonowania, aby zwiększyć wydajność w celu uzyskania lepszej przepływności.
Jeśli czas trwania etapu sap do etapu jest powolny, rozważ zmianę rozmiaru środowiska SHIR na wyższe specyfikacje.
Sprawdź, czy czas przetwarzania ujścia jest zbyt wolny.
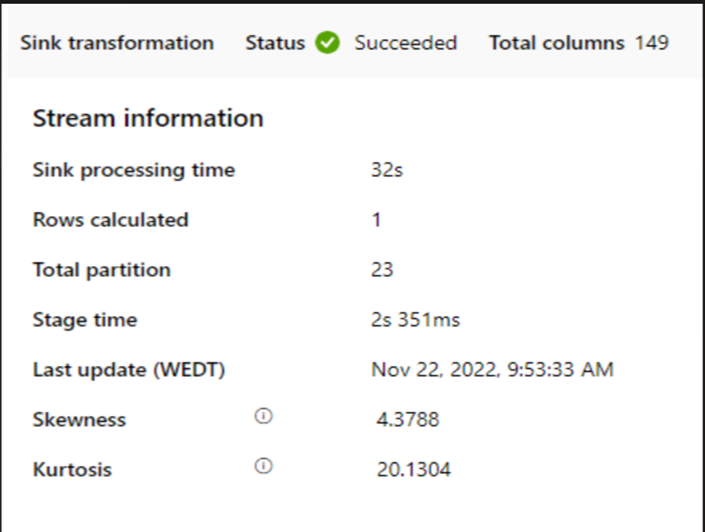
Jeśli mały klaster jest używany do uruchamiania przepływu danych mapowania, może to mieć wpływ na wydajność ujścia. Użyj dużego klastra, na przykład 16 + 256 rdzeni, więc perf odczytuje dane z etapu i zapisuje je w ujściu.
W przypadku dużych ilości danych zalecamy partycjonowanie obciążenia w celu uruchamiania zadań równoległych, ale liczba partycji jest mniejsza niż lub równa rdzeniu środowiska Azure IR, nazywana również rdzeniem klastra Spark.
Użyj karty Optymalizacja , aby zdefiniować partycje. Partycjonowania źródłowego można używać w łączniku cdC.
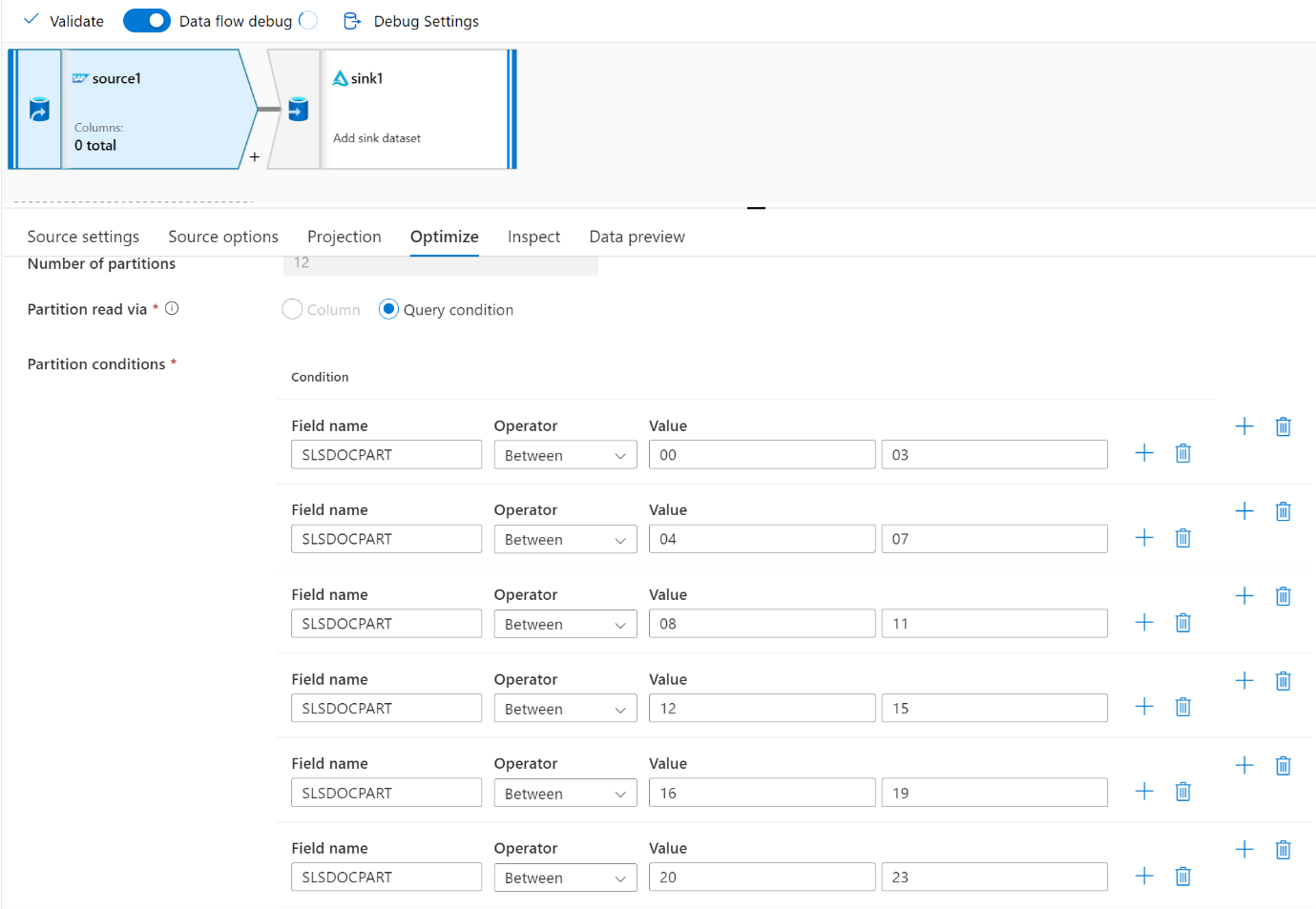
Uwaga
- Istnieje bezpośrednia korelacja między liczbą partycji z rdzeniami SHIR i węzłami środowiska Azure IR.
- Łącznik SAP CDC jest wymieniony jako typ subskrybenta Odata "Odata access for Operational Data Provisioning" w obszarze ODQMON w systemie SAP.
Zagadnienia dotyczące projektowania podczas korzystania z łącznika tabel
- Zoptymalizuj partycjonowanie, aby uzyskać lepszą wydajność.
- Rozważ stopień równoległości z tabeli SAP.
- Rozważ projekt pojedynczego pliku dla ujścia docelowego.
- Przeprowadź test porównawczy przepływności w przypadku używania dużych woluminów danych.
Zalecenia dotyczące projektowania w przypadku korzystania z łącznika tabel
Partycji: Podczas partycjonowania w łączniku tabel SAP dzieli jedną podstawową instrukcję select na kilka, używając klauzul where w odpowiednim polu, na przykład pola o wysokiej kardynalności. Jeśli tabela SAP zawiera dużą ilość danych, włącz partycjonowanie, aby podzielić dane na mniejsze partycje. Spróbuj zoptymalizować liczbę partycji (parametr
maxPartitionsNumber) tak, aby partycje są wystarczająco małe, aby uniknąć zrzutów pamięci w systemie SAP, ale wystarczająco duże, aby przyspieszyć wyodrębnianie.Równoległości prostych: Stopień równoległości kopiowania (parametr
parallelCopies) działa w parze z partycjonowaniem i instruuje SHIR, aby równoległe wywołania RFC do systemu SAP. Jeśli na przykład ustawisz ten parametr na 4, usługa jednocześnie generuje i uruchamia cztery zapytania na podstawie określonej opcji partycji i ustawień. Każde zapytanie pobiera część danych z tabeli SAP.Aby uzyskać optymalne wyniki, liczba partycji powinna być wielokrotnością liczby stopni równoległości kopiowania.
Podczas kopiowania danych z tabeli SAP do ujść binarnych rzeczywista liczba równoległych jest automatycznie dostosowywana na podstawie ilości pamięci dostępnej w środowisku SHIR. Zarejestruj rozmiar maszyny wirtualnej SHIR dla każdego cyklu testowego, stopień równoległości kopiowania i liczbę partycji. Obserwuj wydajność maszyny wirtualnej SHIR, wydajność źródłowego systemu SAP oraz żądany i rzeczywisty stopień równoległości. Użyj iteracyjnego procesu, aby zidentyfikować optymalne ustawienia i idealny rozmiar maszyny wirtualnej SHIR. Rozważ wszystkie potoki pozyskiwania, które jednocześnie ładują dane z jednego lub wielu systemów SAP.
Zwróć uwagę na zaobserwowaną liczbę wywołań RFC do systemu SAP w skonfigurowanym stopniu równoległości. Jeśli liczba wywołań RFC do systemu SAP jest mniejsza niż stopień równoległości, sprawdź, czy maszyna wirtualna SHIR ma wystarczającą ilość dostępnej pamięci i zasobów procesora CPU. W razie potrzeby wybierz większą maszynę wirtualną. Źródłowy system SAP jest skonfigurowany do ograniczania liczby połączeń równoległych. Aby uzyskać więcej informacji, zobacz sekcję Ogólne zalecenia w tym artykule.
Liczba plików: Gdy dane są kopiowane do magazynu danych opartego na plikach, a docelowy ujście jest skonfigurowany jako folder, domyślnie generowanych jest wiele plików. Jeśli ustawisz właściwość ujścia
fileName, dane są zapisywane w jednym pliku. Zaleca się zapisanie w folderze jako wielu plików, ponieważ uzyskuje większą przepływność zapisu w porównaniu z zapisem w jednym pliku.Test porównawczy wydajności: Zalecamy użycie ćwiczenia w zakresie testów porównawczych wydajności w celu pozyskiwania dużych ilości danych. Ta metoda różni parametry, takie jak partycjonowanie, stopień równoległości i liczba plików w celu określenia optymalnego ustawienia dla danej architektury, woluminu i typu danych. Zbierz dane z testów w następującym formacie.


Rozwiązywanie problemów
W przypadku powolnego lub kończącego się niepowodzeniem wyodrębniania z systemu SAP użyj dzienników SAP z programu SM37 i dopasuj je do odczytów w usłudze Data Factory.
Jeśli wyzwalane jest tylko jedno zadanie wsadowe, ustaw partycje źródłowe SAP, aby poprawić wydajność przepływu danych mapowania w usłudze Data Factory. Aby uzyskać więcej informacji, zobacz krok 6 we właściwościach przepływu danych mapy.
Jeśli w systemie SAP jest wyzwalanych wiele zadań wsadowych i istnieje znacząca różnica między czasem rozpoczęcia każdego zadania wsadowego, zmień rozmiar środowiska Azure IR. Zwiększenie liczby węzłów sterowników w środowisku Azure IR zwiększa równoległość zadań wsadowych po stronie sap.
Uwaga
Maksymalna liczba węzłów sterowników dla środowiska Azure IR wynosi 16. Każdy węzeł sterownika może wyzwalać tylko jeden proces wsadowy.
Sprawdź dzienniki w środowisku SHIR. Aby wyświetlić dzienniki, przejdź do maszyny wirtualnej SHIR. Otwórz aplikację Podgląd > zdarzeń i dzienniki łączników >> Środowiska Integration Runtime.
Aby wysłać dzienniki do obsługi, przejdź do maszyny wirtualnej SHIR. Otwórz dzienniki wysyłania diagnostycznego > menedżera > konfiguracji Integration Runtime. Ta akcja wysyła dzienniki z ostatnich siedmiu dni i udostępnia identyfikator raportu. Potrzebujesz tego identyfikatora raportu i identyfikatora RunId przebiegu. Dokumentowanie identyfikatora raportu w celu uzyskania informacji w przyszłości.
W przypadku korzystania z łącznika SAP CDC w scenariuszu SLT:
Upewnij się, że zostały spełnione wymagania wstępne. Role są wymagane dla użytkownika transformacji poziomej SAP (SLT), na przykład ADFSLTUSER w systemach OLTP lub ECC, aby replikacja SLT działała. Aby uzyskać więcej informacji, zobacz Jakie autoryzacje i role są potrzebne.
Jeśli w scenariuszu SLT wystąpią błędy, zapoznaj się z zaleceniami dotyczącymi analizy. Najpierw izoluj i przetestuj scenariusz w ramach rozwiązania SAP. Na przykład przetestuj ją poza usługą Data Factory, uruchamiając program testowy dostarczony przez oprogramowanie SAP
RODPS_REPL_TESTw programie SE38. Jeśli problem występuje po stronie oprogramowania SAP, ten sam błąd występuje podczas korzystania z raportu. Wyodrębnianie danych w oprogramowaniu SAP można analizować przy użyciu koduODQMONtransakcji .Jeśli replikacja działa w przypadku korzystania z tego raportu testowego, ale nie z usługą Data Factory, skontaktuj się z pomocą techniczną platformy Azure lub usługi Data Factory.
W poniższym przykładzie pokazano raport dla elementu
RODPS_REPL_TESTw se38: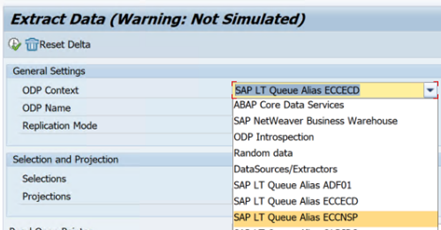
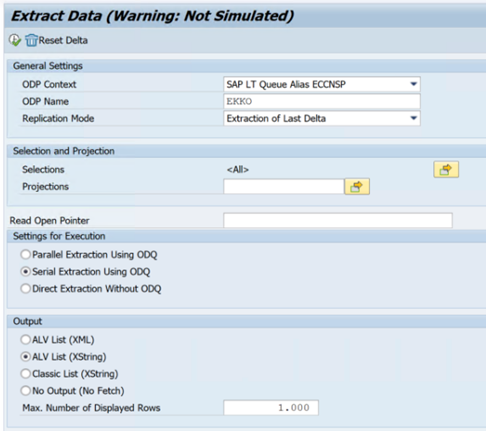

W poniższym przykładzie pokazano kod
ODQMONtransakcji :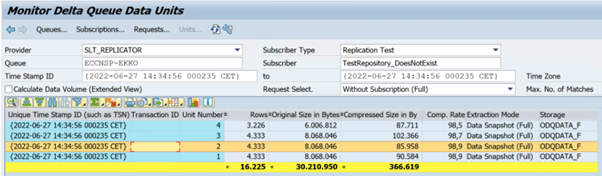
Gdy połączona usługa Data Factory łączy się z systemem SLT, nie wyświetla identyfikatorów transferu masowego SLT podczas odświeżania pola Kontekst .
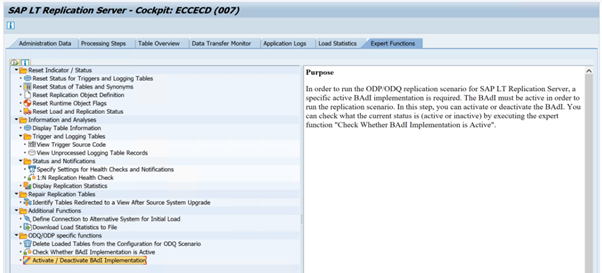
Aby uruchomić scenariusz replikacji ODP/ODQ dla serwera replikacji SAP LT, aktywuj następującą implementację dodatku biznesowego (BAdI).
Badi:
BADI_ODQ_QUEUE_MODELImplementacja rozszerzenia:
ODQ_ENH_SLT_REPLICATIONW transakcji LTRC przejdź do karty Funkcja ekspertów i wybierz pozycję Aktywuj/Dezaktywuj implementację BAdI , aby aktywować implementację.
Wybierz pozycję Tak.
W folderze funkcji specyficznych dla funkcji ODQ/ODP wybierz pozycję Sprawdź, czy implementacja BAdI jest aktywna.

W oknie dialogowym zostanie wyświetlone działanie programu.
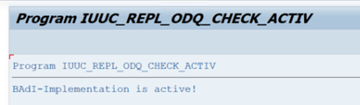
Resetowanie subskrypcji. Aby rozpocząć od nowego wyodrębniania lub zatrzymywania danych replikacji, usuń subskrypcję w pliku ODQMON. Ta akcja powoduje również usunięcie wpisów z LTRC. Po zresetowaniu subskrypcji może upłynąć kilka minut, zanim zobaczysz efekt w wersji LTRC. Planowanie zadań aprowizacji danych operacyjnych (ODP) w celu zachowania czystości kolejek różnicowych, na przykład
ODQ_CLEANUP_CLIENT_004CDS_VIEW (transakcja DHCDCMON). Od wersji S/4HANA 1909 system SAP replikuje dane z widoków usługi CDS, które używają wyzwalaczy opartych na danych zamiast kolumn dat. Koncepcja jest podobna do SLT, ale zamiast używać transakcji LTRC do jej monitorowania, należy użyć transakcji DHCDCMON.
Rozwiązywanie problemów z protokołem SLT
Serwer replikacji SLT zapewnia replikację danych w czasie rzeczywistym ze źródeł SAP i/lub źródeł innych niż SAP do obiektów docelowych SAP i/lub obiektów docelowych innych niż SAP. Istnieją trzy typy zestawów narzędzi do monitorowania wyodrębniania z SLT na platformę Azure.
- ODQMON to ogólne narzędzie do monitorowania wyodrębniania danych. Rozpocznij analizę za pomocą funkcji ODQMON, aby śledzić niespójności danych, początkową analizę wydajności oraz otwierać subskrypcje i żądania wyodrębniania.
- LTRC to transakcja używana do sprawdzania analizy wydajności. Jest to przydatne, jeśli masz problemy z replikacją danych z systemu źródłowego do odp, ponieważ możesz monitorować przepływ danych i znajdować niespójności.
- Sm37 zapewnia szczegółowe monitorowanie każdego kroku wyodrębniania SLT.
Normalne sprzątanie powinno odbywać się przy użyciu funkcji ODQMON, w której można zarządzać subskrypcją bezpośrednio i nie należy używać ltRC w tym samym celu.
Podczas wyodrębniania danych z SLT mogą wystąpić problemy, takie jak:
Wyodrębnianie nie jest uruchamiane. Sprawdź, czy połączenie SAP CDC utworzyło połączenie w narzędziu ODQMON i sprawdź, czy subskrypcja istnieje.
Niespójności danych. Sprawdź PLIK ODQMON, aby zobaczyć pojedyncze żądanie danych i potwierdzić, że można tam zobaczyć dane. Jeśli dane są widoczne w pliku ODQMON, ale nie w Azure Synapse lub w usłudze Data Factory, badanie powinno nastąpić po stronie platformy Azure. Jeśli nie widzisz danych w funkcji ODQMON, przeprowadź analizę struktury SLT przy użyciu technologii LTRC.
Problemy z wydajnością. Wyodrębnianie danych to podejście dwuetapowe. Najpierw funkcja SLT odczytuje dane z systemu źródłowego i przesyła je do odp. Po drugie, łącznik SAP CDC pobiera dane z odp i przesyła je do wybranego magazynu danych. Transakcja LTRC umożliwia analizowanie pierwszej części procesu wyodrębniania. Aby analizować wyodrębnianie danych z odp do platformy Azure, użyj narzędzi do monitorowania ODQMON i Data Factory lub Synapse.
Uwaga
Aby uzyskać więcej informacji, zobacz następujące zasoby:
Wydajność SLT
W początkowym trybie ładowania (ODPSLT) istnieją trzy kroki wyodrębniania danych z SLT do odp:
- Tworzenie obiektów migracji. Ten proces trwa tylko kilka sekund.
- Uzyskaj dostęp do obliczeń planu, które dzieli tabelę źródłową na mniejsze fragmenty. Ten krok zależy od początkowego trybu ładowania wybranego podczas konfiguracji SLT i rozmiaru tabeli. Zalecana jest opcja zoptymalizowana pod kątem zasobów.
- Obciążenie danych przesyła dane z systemu źródłowego do odp.
Każdy krok jest kontrolowany przez zadania w tle. Do monitorowania czasu trwania można użyć transakcji SM37 i LTRC. Jeśli system jest nadmiernie obciążany, zadania w tle mogą zostać uruchomione później, ponieważ nie ma wystarczającej liczby bezpłatnych procesów roboczych wsadowych. Gdy zadania są w stanie bezczynności, wydajność występuje.
Jeśli obliczenie planu dostępu trwa długo, a początkowy tryb ładowania jest ustawiony na "zoptymalizowany pod kątem wydajności", zmień go na "zoptymalizowane pod kątem zasobów" i uruchom ponownie wyodrębnianie. Jeśli ładowanie danych trwa długo, zwiększ liczbę równoległych wątków w konfiguracji.
Jeśli używasz architektury autonomicznej na potrzeby replikacji SLT (dedykowany serwer replikacji SLT), przepływność sieci między systemem źródłowym a serwerem replikacji może mieć wpływ na wydajność wyodrębniania.
W przypadku replikacji:
- Upewnij się, że masz wystarczającą liczbę zadań transferu danych, które nie są zarezerwowane dla początkowego obciążenia.
- Sprawdź, czy w statystykach obciążenia nie ma nieprzetworzonego rekordu tabeli rejestrowania.
- Upewnij się, że opcja replikacji jest ustawiona na wartość w czasie rzeczywistym.
Zaawansowane ustawienia replikacji są dostępne w wersji LTRS. Aby uzyskać więcej informacji, zobacz przewodnik rozwiązywania problemów z protokołem SLT.
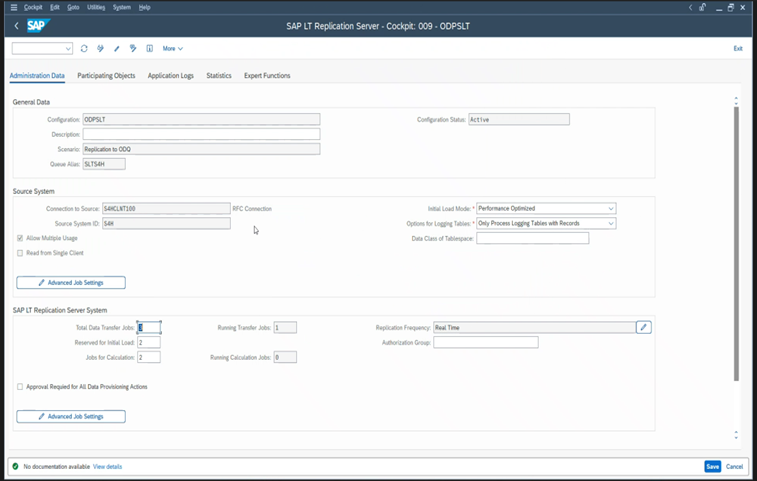
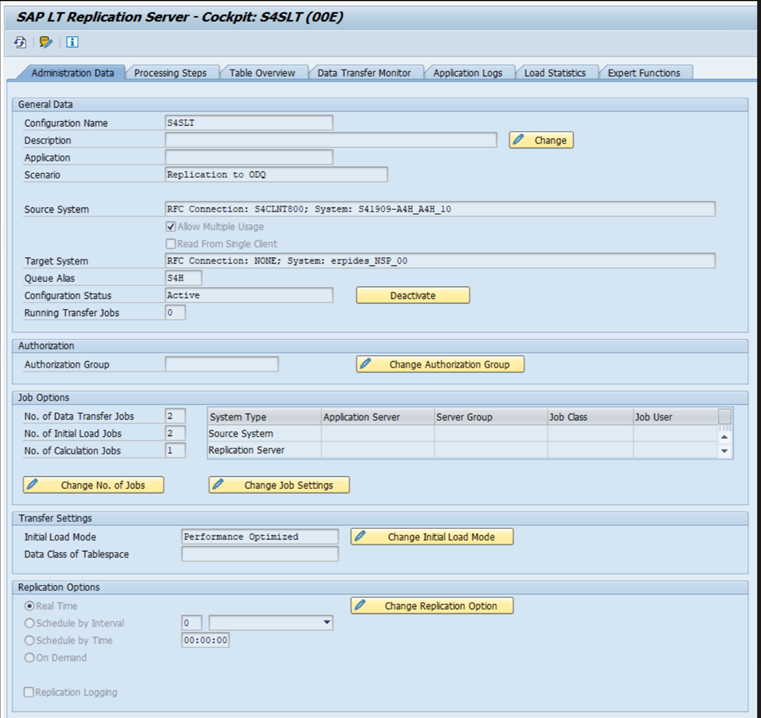
Różne wersje sap mają różne interfejsy użytkownika LTRC. Na poniższych zrzutach ekranu przedstawiono tę samą stronę dla dwóch różnych wersji.
SAP S/4HANA:
SAP ECC:


Monitor
Aby uzyskać informacje na temat monitorowania wyodrębniania danych SAP, zobacz następujące zasoby: