Samouczek: uruchamianie zadania usługi Batch za pomocą usługi Data Factory za pomocą programu Batch Explorer, Eksplorator usługi Storage i języka Python
Ten samouczek przeprowadzi Cię przez proces tworzenia i uruchamiania potoku usługi Azure Data Factory, który uruchamia obciążenie usługi Azure Batch. Skrypt języka Python jest uruchamiany w węzłach usługi Batch w celu pobrania danych wejściowych wartości rozdzielanych przecinkami (CSV) z kontenera usługi Azure Blob Storage, manipulowania danymi i zapisywania danych wyjściowych w innym kontenerze magazynu. Za pomocą programu Batch Explorer można utworzyć pulę i węzły usługi Batch oraz Eksplorator usługi Azure Storage pracować z kontenerami i plikami magazynu.
Z tego samouczka dowiesz się, jak wykonywać następujące czynności:
- Użyj programu Batch Explorer, aby utworzyć pulę i węzły usługi Batch.
- Użyj Eksplorator usługi Storage, aby utworzyć kontenery magazynu i przekazać pliki wejściowe.
- Tworzenie skryptu języka Python w celu manipulowania danymi wejściowymi i generowania danych wyjściowych.
- Utwórz potok usługi Data Factory, który uruchamia obciążenie usługi Batch.
- Użyj programu Batch Explorer, aby przyjrzeć się plikom dziennika danych wyjściowych.
Wymagania wstępne
- Konto platformy Azure z aktywną subskrypcją. Jeśli jej nie masz, utwórz bezpłatne konto.
- Konto usługi Batch z połączonym kontem usługi Azure Storage. Konta można utworzyć przy użyciu dowolnej z następujących metod: Terraform w | interfejsie wiersza polecenia | platformy Azure w witrynie Azure | Bicep | ARM.
- Wystąpienie usługi Data Factory. Aby utworzyć fabrykę danych, postępuj zgodnie z instrukcjami w temacie Tworzenie fabryki danych.
- Program Batch Explorer został pobrany i zainstalowany.
- Eksplorator usługi Storage pobrane i zainstalowane.
-
Środowisko Python w wersji 3.8 lub nowszej z zainstalowanym pakietem azure-storage-blob przy użyciu polecenia
pip. - Wejściowy zestaw danych iris.csv pobrany z usługi GitHub.
Tworzenie puli i węzłów usługi Batch za pomocą programu Batch Explorer
Użyj programu Batch Explorer, aby utworzyć pulę węzłów obliczeniowych w celu uruchomienia obciążenia.
Zaloguj się do usługi Batch Explorer przy użyciu poświadczeń platformy Azure.
Wybierz konto usługi Batch.
Wybierz pozycję Pule na lewym pasku bocznym, a następnie wybierz ikonę + , aby dodać pulę.
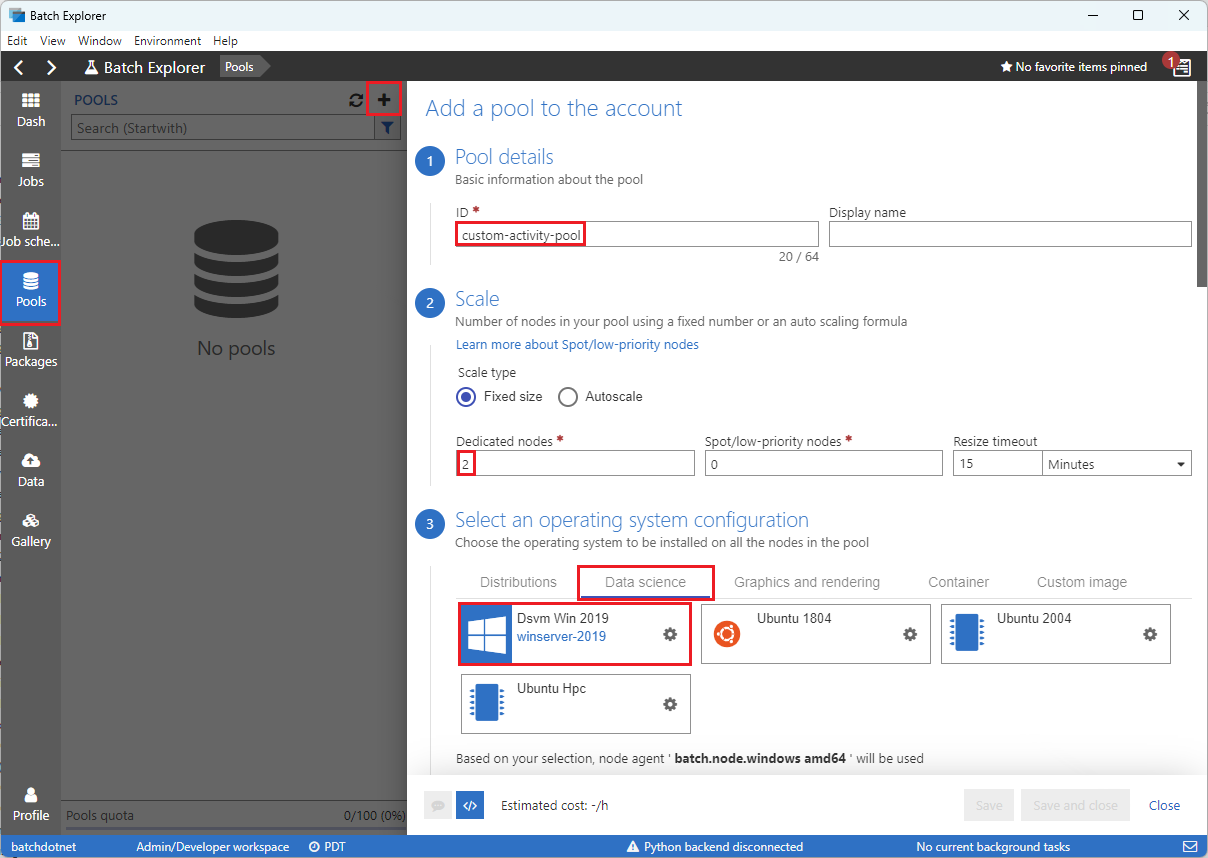
Wypełnij formularz Dodawanie puli do konta w następujący sposób:
- W obszarze Identyfikator wprowadź wartość custom-activity-pool.
- W obszarze Węzły dedykowane wprowadź wartość 2.
- W obszarze Wybierz konfigurację systemu operacyjnego wybierz kartę Nauka o danych, a następnie wybierz pozycję Dsvm Win 2019.
- W obszarze Wybierz rozmiar maszyny wirtualnej wybierz pozycję Standard_F2s_v2.
- W obszarze Rozpocznij zadanie wybierz pozycję Dodaj zadanie uruchamiania.
Na ekranie zadania uruchamiania w obszarze Wiersz polecenia wprowadź ,
cmd /c "pip install azure-storage-blob pandas"a następnie wybierz pozycję Wybierz. To polecenie instalujeazure-storage-blobpakiet w każdym węźle podczas uruchamiania.
Wybierz pozycję Zapisz i zamknij.

Tworzenie kontenerów obiektów blob za pomocą Eksplorator usługi Storage
Użyj Eksplorator usługi Storage, aby utworzyć kontenery obiektów blob do przechowywania plików wejściowych i wyjściowych, a następnie przekazać pliki wejściowe.
- Zaloguj się do Eksplorator usługi Storage przy użyciu poświadczeń platformy Azure.
- Na pasku bocznym po lewej stronie znajdź i rozwiń konto magazynu połączone z kontem usługi Batch.
- Kliknij prawym przyciskiem myszy pozycję Kontenery obiektów blob i wybierz pozycję Utwórz kontener obiektów blob lub wybierz pozycję Utwórz kontener obiektów blob z akcji w dolnej części paska bocznego.
- Wprowadź dane wejściowe w polu wprowadzania.
- Utwórz inny kontener obiektów blob o nazwie output.
- Wybierz kontener wejściowy, a następnie wybierz pozycję Przekaż>pliki w okienku po prawej stronie.
- Na ekranie Przekazywanie plików w obszarze Wybrane pliki wybierz wielokropek ... obok pola wprowadzania.
- Przejdź do lokalizacji pobranego pliku iris.csv , wybierz pozycję Otwórz, a następnie wybierz pozycję Przekaż.

Tworzenie skryptu języka Python
Poniższy skrypt języka Python ładuje plik zestawu danych iris.csv z kontenera wejściowego Eksplorator usługi Storage, manipuluje danymi i zapisuje wyniki w kontenerze wyjściowym.
Skrypt musi używać parametry połączenia dla konta usługi Azure Storage połączonego z kontem usługi Batch. Aby uzyskać parametry połączenia:
- W witrynie Azure Portal wyszukaj i wybierz nazwę konta magazynu połączonego z kontem usługi Batch.
- Na stronie konta magazynu wybierz pozycję Klucze dostępu z lewej nawigacji w obszarze Zabezpieczenia i sieć.
- W obszarze key1 wybierz pozycję Pokaż obok pozycji Parametry połączenia, a następnie wybierz ikonę Kopiuj, aby skopiować parametry połączenia.
Wklej parametry połączenia do następującego skryptu<storage-account-connection-string>, zastępując symbol zastępczy. Zapisz skrypt jako plik o nazwie main.py.
Ważne
Udostępnianie kluczy kont w źródle aplikacji nie jest zalecane w przypadku użycia produkcyjnego. Należy ograniczyć dostęp do poświadczeń i odwołać się do nich w kodzie przy użyciu zmiennych lub pliku konfiguracji. Najlepiej przechowywać klucze kont usługi Batch i magazynu w usłudze Azure Key Vault.
# Load libraries
# from azure.storage.blob import BlobClient
from azure.storage.blob import BlobServiceClient
import pandas as pd
import io
# Define parameters
connectionString = "<storage-account-connection-string>"
containerName = "output"
outputBlobName = "iris_setosa.csv"
# Establish connection with the blob storage account
blob = BlobClient.from_connection_string(conn_str=connectionString, container_name=containerName, blob_name=outputBlobName)
# Initialize the BlobServiceClient (This initializes a connection to the Azure Blob Storage, downloads the content of the 'iris.csv' file, and then loads it into a Pandas DataFrame for further processing.)
blob_service_client = BlobServiceClient.from_connection_string(conn_str=connectionString)
blob_client = blob_service_client.get_blob_client(container_name=containerName, blob_name=outputBlobName)
# Download the blob content
blob_data = blob_client.download_blob().readall()
# Load iris dataset from the task node
# df = pd.read_csv("iris.csv")
df = pd.read_csv(io.BytesIO(blob_data))
# Take a subset of the records
df = df[df['Species'] == "setosa"]
# Save the subset of the iris dataframe locally in the task node
df.to_csv(outputBlobName, index = False)
with open(outputBlobName, "rb") as data:
blob.upload_blob(data, overwrite=True)
Aby uzyskać więcej informacji na temat pracy z usługą Azure Blob Storage, zapoznaj się z dokumentacją usługi Azure Blob Storage.
Uruchom skrypt lokalnie, aby przetestować i zweryfikować funkcjonalność.
python main.py
Skrypt powinien utworzyć plik wyjściowy o nazwie iris_setosa.csv zawierający tylko rekordy danych, które mają gatunek = setosa. Po sprawdzeniu, czy działa prawidłowo, przekaż plik skryptu main.py do kontenera wejściowego Eksplorator usługi Storage.
Konfigurowanie potoku usługi Data Factory
Utwórz i zweryfikuj potok usługi Data Factory, który używa skryptu języka Python.
Pobieranie informacji o koncie
Potok usługi Data Factory używa nazw kont usługi Batch i magazynu, wartości kluczy konta i punktu końcowego konta usługi Batch. Aby uzyskać te informacje z witryny Azure Portal:
Na pasku usługi Azure Search wyszukaj i wybierz nazwę konta usługi Batch.
Na stronie Konto usługi Batch wybierz pozycję Klucze w obszarze nawigacji po lewej stronie.
Na stronie Klucze skopiuj następujące wartości:
- Konto usługi Batch
- Punkt końcowy konta
- Podstawowy klucz dostępu
- Nazwa konta magazynu
- Klucz1
Tworzenie i uruchamianie potoku
Jeśli program Azure Data Factory Studio nie jest jeszcze uruchomiony, wybierz pozycję Uruchom studio na stronie usługi Data Factory w witrynie Azure Portal.
W narzędziu Data Factory Studio wybierz ikonę ołówka Author (Autor ) w obszarze nawigacji po lewej stronie.
W obszarze Zasoby fabryki wybierz ikonę + , a następnie wybierz pozycję Potok.
W okienku Właściwości po prawej stronie zmień nazwę potoku na Uruchom język Python.
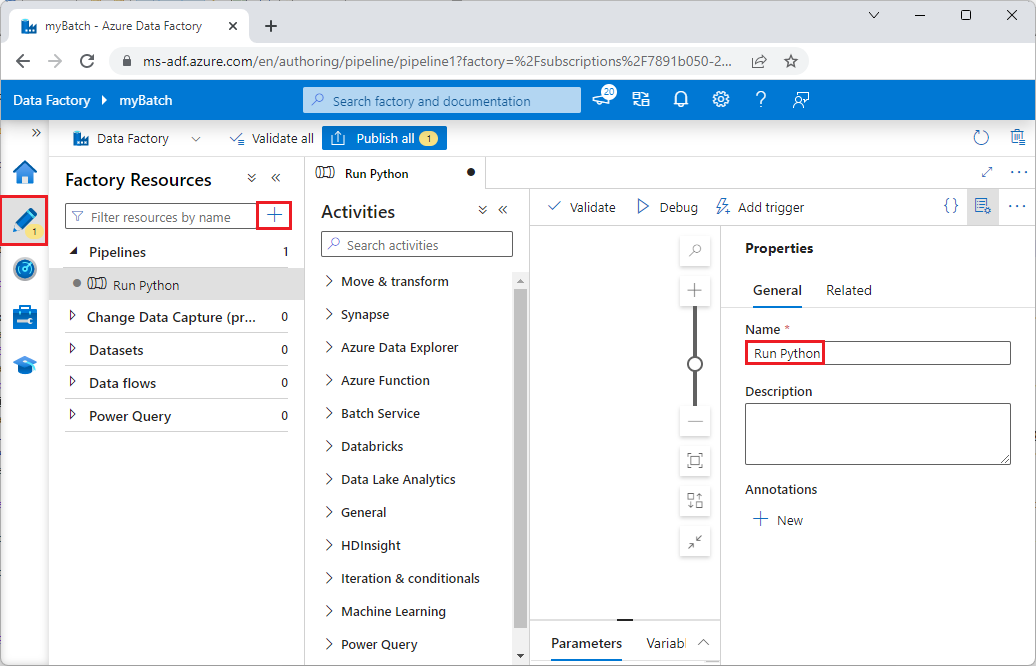
W okienku Działania rozwiń węzeł Usługa Batch i przeciągnij działanie Niestandardowe na powierzchnię projektanta potoku.
Poniżej kanwy projektanta na karcie Ogólne wprowadź ciąg testPipeline w obszarze Nazwa.
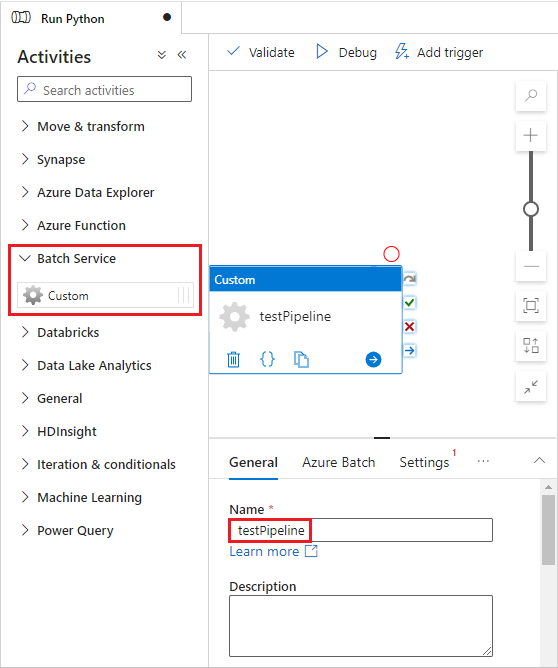
Wybierz kartę Azure Batch , a następnie wybierz pozycję Nowy.
Wypełnij formularz Nowa połączona usługa w następujący sposób:
- Nazwa: wprowadź nazwę połączonej usługi, na przykład AzureBatch1.
- Klucz dostępu: wprowadź podstawowy klucz dostępu skopiowany z konta usługi Batch.
- Nazwa konta: wprowadź nazwę konta usługi Batch.
-
Adres URL usługi Batch: wprowadź punkt końcowy konta skopiowany z konta usługi Batch, na przykład
https://batchdotnet.eastus.batch.azure.com. - Nazwa puli: wprowadź wartość custom-activity-pool , pulę utworzoną w programie Batch Explorer.
- Nazwa połączonej usługi konta magazynu: wybierz pozycję Nowy. Na następnym ekranie wprowadź nazwę połączonej usługi magazynu, taką jak AzureBlobStorage1, wybierz subskrypcję platformy Azure i połączone konto magazynu, a następnie wybierz pozycję Utwórz.
W dolnej części ekranu nowa połączona usługa Batch wybierz pozycję Testuj połączenie. Po pomyślnym nawiązaniu połączenia wybierz pozycję Utwórz.
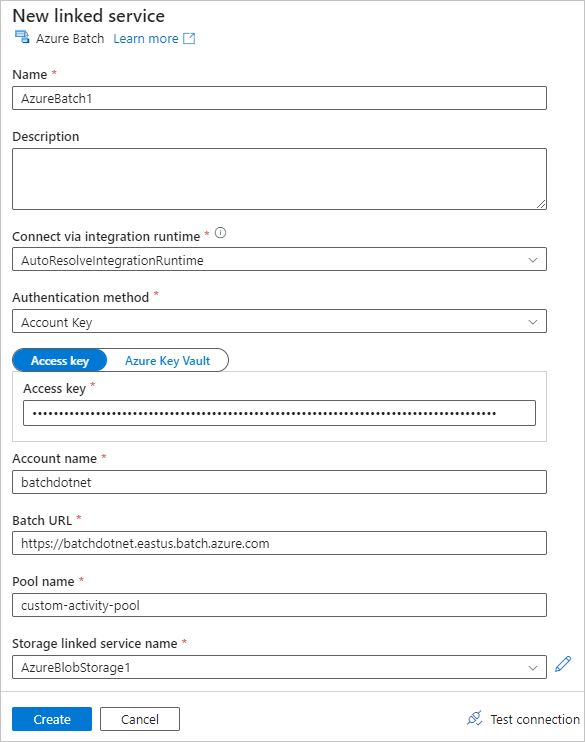
Wybierz kartę Ustawienia , a następnie wprowadź lub wybierz następujące ustawienia:
-
Polecenie: wprowadź .
cmd /C python main.py - Połączona usługa zasobów: wybierz utworzoną połączoną usługę magazynu, taką jak AzureBlobStorage1, i przetestuj połączenie, aby upewnić się, że działa pomyślnie.
- Ścieżka folderu: wybierz ikonę folderu, a następnie wybierz kontener wejściowy i wybierz przycisk OK. Pliki z tego folderu są pobierane z kontenera do węzłów puli przed uruchomieniem skryptu języka Python.
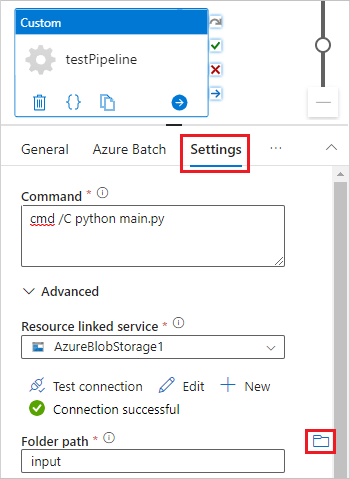
-
Polecenie: wprowadź .
Wybierz pozycję Weryfikuj na pasku narzędzi potoku, aby zweryfikować potok.
Wybierz pozycję Debuguj , aby przetestować potok i upewnić się, że działa prawidłowo.
Wybierz pozycję Opublikuj wszystko , aby opublikować potok.
Wybierz pozycję Dodaj wyzwalacz, a następnie wybierz pozycję Wyzwól teraz , aby uruchomić potok, lub Pozycję Nowy/Edytuj , aby go zaplanować.
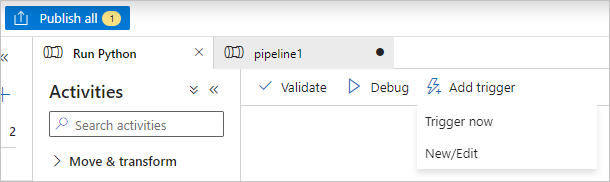

Wyświetlanie plików dziennika za pomocą programu Batch Explorer
Jeśli uruchomienie potoku generuje ostrzeżenia lub błędy, możesz użyć programu Batch Explorer, aby zapoznać się z stdout.txt i stderr.txt plikami wyjściowymi, aby uzyskać więcej informacji.
- W programie Batch Explorer wybierz pozycję Zadania na lewym pasku bocznym.
- Wybierz zadanie adfv2-custom-activity-pool.
- Wybierz zadanie, które miało kod zakończenia błędu.
- Wyświetl pliki stdout.txt i stderr.txt, aby zbadać i zdiagnozować problem.
Czyszczenie zasobów
Konta, zadania i zadania usługi Batch są bezpłatne, ale węzły obliczeniowe generują opłaty nawet wtedy, gdy nie są uruchomione zadania. Najlepiej przydzielić pule węzłów tylko w razie potrzeby i usunąć pule po zakończeniu pracy z nimi. Usunięcie pul powoduje usunięcie wszystkich danych wyjściowych zadania w węzłach i samych węzłów.
Pliki wejściowe i wyjściowe pozostają na koncie magazynu i mogą naliczać opłaty. Gdy pliki nie są już potrzebne, możesz usunąć pliki lub kontenery. Jeśli nie potrzebujesz już konta usługi Batch ani połączonego konta magazynu, możesz je usunąć.
Następne kroki
W tym samouczku przedstawiono sposób używania skryptu języka Python z usługą Batch Explorer, Eksplorator usługi Storage i usługą Data Factory do uruchamiania obciążenia usługi Batch. Aby uzyskać więcej informacji na temat usługi Data Factory, zobacz Co to jest usługa Azure Data Factory?