Najlepsze praktyki konfiguracji HADR (SQL Server na maszynach wirtualnych Azure)
Dotyczy:![]() program SQL Server na maszynie wirtualnej platformy Azure
program SQL Server na maszynie wirtualnej platformy Azure
Klaster Windows Server Failover Cluster jest używany do zapewnienia wysokiej dostępności i odzyskiwania po awarii (HADR, ODR) razem z SQL Server na platformie Azure Virtual Machines.
Ten artykuł zawiera najlepsze praktyki dotyczące konfiguracji klastra dla instancji klastra trybu przełączenia awaryjnego (FCI) i grup dostępności przy użyciu SQL Server na maszynach wirtualnych platformy Azure.
Aby dowiedzieć się więcej, zobacz inne artykuły z tej serii: Lista kontrolna, Rozmiar maszyny wirtualnej, Przechowywanie, Zabezpieczenia, Konfiguracja HADR, Zbieranie danych bazowych.
Lista kontrolna
Zapoznaj się z poniższą listą kontrolną, aby zapoznać się z krótkim omówieniem najlepszych rozwiązań dotyczących usługi HADR, które opisano w pozostałej części artykułu.
Funkcje wysokiej dostępności i odzyskiwania po awarii (HADR), takie jak grupa dostępności Always On i instancja klastra w trybie failover, opierają się na technologii klastrowania przełączania awaryjnego Windows Server. Zapoznaj się z najlepszymi rozwiązaniami dotyczącymi modyfikowania ustawień usługi HADR, aby lepiej obsługiwać środowisko chmury.
W przypadku klastra systemu Windows należy wziąć pod uwagę następujące najlepsze rozwiązania:
- Wdróż maszyny wirtualne SQL Server do wielu podsieci, jeśli to możliwe, aby uniknąć zależności od Azure Load Balancer lub rozproszonej nazwy sieciowej (DNN) przy kierowaniu ruchu do rozwiązania HADR.
- Zmień klaster na mniej agresywne parametry, aby uniknąć nieoczekiwanych awarii sieci przejściowych lub konserwacji platformy Azure. Aby dowiedzieć się więcej, zobacz ustawienia pulsu i progu. W przypadku systemu Windows Server 2012 i nowszych użyj następujących zalecanych wartości:
- SameSubnetDelay: 1 sekunda
- SameSubnetThreshold: 40 pulsów
- CrossSubnetDelay: 1 sekunda
- CrossSubnetThreshold: 40 pulsów
- Umieść maszyny wirtualne w zestawie dostępności lub w różnych strefach dostępności. Aby dowiedzieć się więcej, zobacz Ustawienia dostępności maszyn wirtualnych.
- Użyj jednej karty sieciowej na węzeł klastra.
- Skonfiguruj głosowanie kworum klastra, aby używać 3 lub więcej nieparzystych głosów. Nie przypisuj głosów do regionów DR.
- Uważnie monitoruj limity zasobów, aby uniknąć nieoczekiwanych ponownych uruchomień lub trybu failover z powodu ograniczeń zasobów.
- Upewnij się, że system operacyjny, sterowniki i program SQL Server mają najnowsze kompilacje.
- Optymalizowanie wydajności programu SQL Server na maszynach wirtualnych platformy Azure. Zapoznaj się z innymi sekcjami w tym artykule, aby dowiedzieć się więcej.
- Zmniejsz lub rozłóż obciążenie, aby uniknąć limitów zasobów.
- Przejdź do maszyny wirtualnej lub dysku o wyższych limitach, aby uniknąć ograniczeń.
W przypadku grupy dostępności programu SQL Server lub wystąpienia klastra trybu failover należy wziąć pod uwagę następujące najlepsze rozwiązania:
- Jeśli występują częste nieoczekiwane błędy, postępuj zgodnie z najlepszymi rozwiązaniami dotyczącymi wydajności opisanymi w pozostałej części tego artykułu.
- Jeśli optymalizacja wydajności maszyny wirtualnej z programem SQL Server nie rozwiąże problemów z nieoczekiwanymi przełączeniami awaryjnymi, rozważ złagodzenie monitorowania dla grupy dostępności lub instancji klastra failover. Jednak może to nie rozwiązać problemu źródłowego źródła problemu i może maskować objawy, zmniejszając prawdopodobieństwo awarii. Nadal może być konieczne zbadanie i rozwiązanie źródłowej głównej przyczyny. W przypadku systemu Windows Server 2012 lub nowszego użyj następujących zalecanych wartości:
-
Limit czasu dzierżawy: użyj tego równania, aby obliczyć maksymalną wartość limitu czasu dzierżawy:
Lease timeout < (2 * SameSubnetThreshold * SameSubnetDelay).
Zacznij od 40 sekund. Jeśli używasz wcześniej zalecanych rozluźnionychSameSubnetThresholdwartościSameSubnetDelay, nie przekraczaj 80 sekund dla wartości czasu wygaśnięcia dzierżawy. - Maksymalna liczba niepowodzeń w określonym przedziale czasu: ustaw tę wartość na 6.
-
Limit czasu dzierżawy: użyj tego równania, aby obliczyć maksymalną wartość limitu czasu dzierżawy:
- W przypadku używania nazwy sieci wirtualnej (VNN) i usługi Azure Load Balancer do łączenia się z rozwiązaniem HADR określ
MultiSubnetFailover = truew parametry połączenia, nawet jeśli klaster obejmuje tylko jedną podsieć.- Jeśli klient nie obsługuje
MultiSubnetFailover = True, może być konieczne ustawienieRegisterAllProvidersIP = 0iHostRecordTTL = 300na buforowanie poświadczeń klienta na krótszy czas. Jednak może to spowodować dodatkowe zapytania do serwera DNS.
- Jeśli klient nie obsługuje
- Aby nawiązać połączenie z rozwiązaniem HADR przy użyciu nazwy sieci rozproszonej (DNN), rozważ następujące kwestie:
- Należy użyć sterownika klienta obsługującego
MultiSubnetFailover = True, a ten parametr musi znajdować się w łańcuchu połączenia. - Użyj unikatowego portu DNN w ciągu połączenia podczas łączenia z odbiornikiem DNN dla grupy dostępności.
- Należy użyć sterownika klienta obsługującego
- Użyj ciągu połączenia z mirroringiem bazy danych dla podstawowej grupy dostępności, aby pominąć potrzebę modułu równoważenia obciążenia lub DNN.
- Przed wdrożeniem rozwiązania o wysokiej dostępności zweryfikuj rozmiar sektora dysków VHD, aby uniknąć nieprawidłowego dopasowywania operacji we/wy. Aby dowiedzieć się więcej, zobacz KB3009974 .
- Jeśli aparat bazy danych programu SQL Server, odbiornik grupy dostępności Always On lub sonda kondycji wystąpienia klastra trybu przełączania awaryjnego są skonfigurowane do używania portu z zakresu od 49 152 do 65 536 (domyślny zakres portów dynamicznych dla protokołu TCP/IP), dodaj wykluczenie dla każdego z tych portów. Dzięki temu inne systemy nie będą dynamicznie przypisywane tego samego portu. Poniższy przykład tworzy wykluczenie dla portu 59999:
netsh int ipv4 add excludedportrange tcp startport=59999 numberofports=1 store=persistent
Aby porównać listę kontrolną usługi HADR z innymi najlepszymi rozwiązaniami, zobacz kompleksową listę kontrolną najlepszych rozwiązań dotyczących wydajności.
Ustawienia dostępności maszyny wirtualnej
Aby zmniejszyć efekt przestoju, rozważ następujące ustawienia dostępności maszyn wirtualnych:
- Używaj grup umieszczania w pobliżu razem z przyspieszoną siecią w celu zapewnienia najniższych opóźnień.
- Umieść węzły klastra maszyn wirtualnych w oddzielnych strefach dostępności, aby chronić przed awariami na poziomie centrum danych lub w jednym zestawie dostępności w celu zapewnienia nadmiarowości o małych opóźnieniach w tym samym centrum danych.
- W zestawie dostępności użyj dysków systemu operacyjnego i danych zarządzanych w warstwie Premium dla maszyn wirtualnych.
- Skonfiguruj każdą warstwę aplikacji na oddzielne zestawy dostępności.
Kworum
Mimo że klaster z dwoma węzłami działa bez zasobu kworum, klienci są ściśle zobowiązani do korzystania z zasobu kworum, aby uzyskać wsparcie produkcyjne. Walidacja klastrów nie przepuszcza żadnego klastra bez zasobu kworum.
Technicznie rzecz biorąc, klaster z trzema węzłami może przetrwać utratę jednego węzła (zredukowany do dwóch węzłów) bez zasobu kworum, ale gdy klaster zostanie zredukowany do dwóch węzłów, istnieje ryzyko, że jeśli nastąpi kolejna utrata węzła lub awaria komunikacji, zasoby klastrowane przejdą w tryb offline, aby zapobiec sytuacji podziału klastra. Skonfigurowanie zasobu kworum umożliwia klastrowi kontynuowanie pracy tylko z jednym węzłem w trybie online.
Świadek dysku jest najbardziej odporną opcją kworum, ale aby użyć świadka dysku w SQL Server na maszynie wirtualnej platformy Azure, musisz użyć udostępnionego dysku platformy Azure, co wprowadza pewne ograniczenia dla rozwiązania wysokiej dostępności. W związku z tym należy użyć dysku świadka przy konfigurowaniu wystąpienia klastra trybu awaryjnego z użyciem udostępnionych dysków Azure, w przeciwnym wypadku korzystaj ze świadka w chmurze, jeśli to możliwe.
W poniższej tabeli wymieniono opcje kworum dostępne dla programu SQL Server na maszynach wirtualnych platformy Azure:
| Świadek chmury | Świadek dysku | Świadek udziału plików | |
|---|---|---|---|
| Obsługiwany system operacyjny | Windows Server 2016+ | wszystkie | wszystkie |
- Świadek w chmurze jest idealny do wdrożeń w wielu lokalizacjach, strefach i regionach. Jeśli to możliwe, użyj świadka w chmurze, chyba że korzystasz z rozwiązania klastra z współużytkowanym magazynem.
- Świadek dysku jest najbardziej odporną opcją kworum i jest preferowany dla każdego klastra korzystającego z dysków udostępnionych na platformie Azure (lub dowolnego rozwiązania udostępnionego dysku, takiego jak współużytkowany interfejs SCSI, iSCSI lub sieć SAN Fibre Channel). Klastrowany udostępniony wolumin nie może być używany jako świadek dyskowy.
- Świadek współdzielenia plików jest odpowiedni, gdy świadek dyskowy i świadek w chmurze są niedostępne.
Aby rozpocząć, zobacz Konfigurowanie kworum klastra.
Głosowanie kworum
Istnieje możliwość zmiany głosowania kworum węzła uczestniczącego w klastrze w trybie awaryjnym systemu Windows Server.
Podczas modyfikowania ustawień głosowania węzła postępuj zgodnie z następującymi wytycznymi:
| Wytyczne dotyczące głosowania kworum |
|---|
| Zaczynaj od tego, że każdy węzeł nie ma głosu domyślnie. Każdy węzeł powinien głosować tylko z wyraźnym uzasadnieniem. |
| Włącz głosy dla węzłów klastra hostujących replikę podstawową grupy dostępności lub preferowanych właścicieli wystąpienia klastra trybu failover. |
| Włącz głosowanie dla właścicieli automatycznego przełączenia awaryjnego. Każdy węzeł, który może hostować replikę podstawową lub awaryjne przełączenie klastra na skutek automatycznego awaryjnego przełączenia, powinien mieć głos. |
| Jeśli grupa dostępności ma więcej niż jedną replikę pomocniczą, włączaj głosy tylko dla tych replik, które działają w automatycznym trybie przełączenia awaryjnego. |
| Wyłącz głosy dla węzłów znajdujących się w zapasowych lokacjach odzyskiwania po awarii. Węzły w lokalizacjach pomocniczych nie powinny wpływać na decyzję o zmniejszeniu dostępności klastra, jeśli lokalizacja główna działa poprawnie. |
| Mają nieparzystą liczbę głosów, przy czym minimum trzy to głosy kworum. Dodaj świadka kworum do dodatkowego głosowania, jeśli jest to konieczne w klastrze dwuwęzłowym. |
| Ponownie oceń przydziały głosów po awarii systemu. Nie chcesz przełączać się na konfigurację awaryjną klastra, która nie obsługuje poprawnego kworum. |
Łączność
Aby dopasować doświadczenie użytkownika w środowisku lokalnym przy nawiązywaniu połączenia z listenerem grupy dostępności lub wystąpieniem klastra przełączania awaryjnego, wdróż maszyny wirtualne SQL Server w wielu podsieciach w tej samej sieci wirtualnej. Posiadanie wielu podsieci neguje potrzebę dodatkowej zależności od usługi Azure Load Balancer lub nazwy sieci rozproszonej w celu kierowania ruchu do odbiornika.
Aby uprościć rozwiązanie HADR, wdróż maszyny wirtualne z programem SQL Server w wielu podsieciach, jeśli to możliwe. Aby dowiedzieć się więcej, zobacz Wielopodsieciowe grupy dostępności i Wielopodsieciowe wystąpienia klastrowe trybu failover.
Jeśli maszyny wirtualne programu SQL Server znajdują się w jednej podsieci, można skonfigurować nazwę sieci wirtualnej (VNN) lub nazwę sieci rozproszonej (DNN) wraz z usługą Azure Load Balancer dla zarówno instancji klastra w trybie failover, jak i listenerów grupy dostępności.
Nazwa sieci rozproszonej jest zalecaną opcją łączności, jeśli jest dostępna:
- Kompleksowe rozwiązanie jest bardziej niezawodne, ponieważ nie trzeba już utrzymywać zasobu modułu równoważenia obciążenia.
- Wyeliminowanie sond modułu równoważenia obciążenia minimalizuje czas trwania trybu failover.
- DNN upraszcza konfigurowanie i zarządzanie wystąpieniem klastra trybu failover lub odbiornikiem grupy dostępności za pomocą programu SQL Server na maszynach wirtualnych platformy Azure.
Rozważ następujące ograniczenia:
- Sterownik klienta musi obsługiwać
MultiSubnetFailover=Trueparametr . - Funkcja DNN jest dostępna od programu SQL Server 2016 SP3, programu SQL Server 2017 CU25 i programu SQL Server 2019 CU8 w systemie Windows Server 2016 lub nowszym.
Aby dowiedzieć się więcej, zobacz Omówienie klastra trybu przełączania awaryjnego systemu Windows Server.
Aby skonfigurować łączność, zobacz następujące artykuły:
- Grupa dostępności: Konfiguracja DNN, Konfiguracja VNN
- Wystąpienie klastra trybu failover: Konfigurowanie DNN, Konfigurowanie VNN.
Większość funkcji SQL Server działa przejrzyście z klastrami trybu przełączenia awaryjnego i grupami dostępności podczas korzystania z nazwy sieci rozproszonej, ale niektóre funkcje mogą wymagać specjalnej uwagi. Aby dowiedzieć się więcej, zobacz interoperacyjność FCI i DNN oraz interoperacyjność AG i DNN.
Napiwek
Ustaw parametr MultiSubnetFailover = true w łańcuchu połączenia, nawet dla rozwiązań HADR obejmujących jedną podsieć, aby umożliwić przyszłe łączenie podsieci bez konieczności aktualizacji łańcucha połączenia.
Puls i próg
Zmień ustawienia pulsu i progu klastra na złagodzone. Domyślne ustawienia pulsu i progu klastra są przeznaczone dla wysoce dostosowanych sieci lokalnych i nie uwzględniają możliwości zwiększonego opóźnienia w środowisku chmury. Sieć pulsu jest utrzymywana przy użyciu protokołu UDP 3343, który jest tradycyjnie znacznie mniej niezawodny niż TCP i bardziej podatny na niekompletne konwersacje.
W związku z tym podczas uruchamiania węzłów klastra dla programu SQL Server na maszynie wirtualnej platformy Azure wysokiej dostępności zmień ustawienia klastra na bardziej zrelaksowany stan monitorowania, aby uniknąć przejściowych awarii z powodu zwiększonego opóźnienia sieci lub awarii, konserwacji platformy Azure lub osiągnięcia wąskich gardeł zasobów.
Ustawienia opóźnienia i progu mają skumulowany wpływ na całkowite wykrywanie stanu zdrowia. Na przykład ustawienie parametru CrossSubnetDelay w celu wysyłania pulsu co 2 sekundy i ustawienie wartości CrossSubnetThreshold na 10 nieodebranych pulsów przed podjęciem odzyskiwania oznacza, że klaster może mieć całkowitą tolerancję sieci wynoszącą 20 sekund przed podjęciem akcji odzyskiwania. Ogólnie rzecz biorąc, nadal wysyłać częste pulsy, ale preferowane są większe progi.
Aby zapewnić odzyskiwanie podczas uzasadnionych awarii przy jednoczesnym zapewnieniu większej tolerancji dla przejściowych problemów, zrelaksuj ustawienia opóźnień i progów do zalecanych wartości opisanych w poniższej tabeli:
| Ustawienie | Windows Server 2012 lub nowszym | Windows Server 2008 R2 |
|---|---|---|
| SameSubnetDelay | 1 sekunda | 2 sekundy |
| SameSubnetThreshold | 40 pulsów | 10 uderzeń serca (maks.) |
| Opóźnienie między podsieciami | 1 sekunda | 2 sekundy |
| Próg przekroczenia podsieci | 40 pulsów | 20 pulsów (maks.) |
Użyj programu PowerShell, aby zmienić parametry klastra:
(get-cluster).SameSubnetThreshold = 40
(get-cluster).CrossSubnetThreshold = 40
Użyj programu PowerShell, aby zweryfikować zmiany:
get-cluster | fl *subnet*
Rozważ następujące.
- Ta zmiana jest natychmiastowa, ponowne uruchomienie klastra lub żadnych zasobów nie jest wymagane.
- Te same wartości podsieci nie powinny być większe niż wartości między podsieciami.
- SameSubnetThreshold <= CrossSubnetThreshold
- SameSubnetDelay = CrossSubnetDelay <
Wybierz dopasowane wartości na podstawie tego, jak dużo czasu przestoju jest akceptowalne i jak długo powinno trwać przed podjęciem akcji naprawczej, w zależności od aplikacji, potrzeb biznesowych i środowiska. Jeśli nie możesz przekroczyć domyślnych wartości systemu Windows Server 2019, spróbuj je dopasować, jeśli to możliwe:
Na potrzeby dokumentacji w poniższej tabeli przedstawiono wartości domyślne:
| Ustawienie | Windows Server 2019 | Windows Server 2016 | Windows Server 2008 – 2012 R2 |
|---|---|---|---|
| OpóźnienieTegoSamegoPodsieci | 1 sekunda | 1 sekunda | 1 sekunda |
| PrógDlaTejSamejPodsieci | 20 pulsów | 10 pulsów | 5 pulsów |
| Opóźnienie międzypodsieciowe | 1 sekunda | 1 sekunda | 1 sekunda |
| Próg między podsieciami | 20 pulsów | 10 pulsów | 5 pulsów |
Aby dowiedzieć się więcej, zobacz "Dostrajanie progów sieci klastra trybu awaryjnego przełączania".
Złagodzone monitorowanie
Jeśli dostrajanie ustawień pulsu i progu klastra zgodnie z zaleceniami nie zapewnia wystarczającej tolerancji i nadal występują przełączenia awaryjne z powodu przejściowych problemów, a nie rzeczywistych awarii, możesz skonfigurować monitorowanie grupy dostępności lub klastra awaryjnego, aby było mniej rygorystyczne. W niektórych scenariuszach korzystne może być tymczasowe złagodzenie monitorowania przez pewien czas, biorąc pod uwagę poziom aktywności. Na przykład możesz rozluźnić monitorowanie podczas wykonywania intensywnych operacji wejścia/wyjścia, takich jak kopie zapasowe bazy danych, konserwacja indeksu, DBCC CHECKDB itp. Po zakończeniu działania ustaw monitorowanie na bardziej rygorystyczne wartości.
Ostrzeżenie
Zmiana tych ustawień może maskować podstawowy problem i powinna być używana jako tymczasowe rozwiązanie w celu zmniejszenia, a nie wyeliminowania prawdopodobieństwa awarii. Podstawowe problemy należy nadal badać i rozwiązywać.
Zacznij od zwiększenia następujących parametrów z domyślnych wartości w celu złagodzenia monitorowania i dostosuj je w razie potrzeby:
| Parametr | Domyślna wartość | Wartość zrelaksowana | opis |
|---|---|---|---|
| Limit czasu kontroli kondycji | 30000 | 60000 | Określa kondycję repliki podstawowej lub węzła. Biblioteka DLL sp_server_diagnostics zasobu klastra zwraca wyniki w odstępie czasu równym 1/3 progu limitowego czasu sprawdzania kondycji. Jeśli sp_server_diagnostics działa wolno lub nie zwraca informacji, biblioteka DLL zasobu czeka przez pełny czas oczekiwania limitu sprawdzania kondycji, zanim ustali, że zasób nie odpowiada, i rozpocznie przełączenie awaryjne, jeśli zostało to skonfigurowane. |
| Poziom warunku awarii | 3 | 2 | Warunki wyzwalające automatyczne przejście w tryb failover. Istnieją pięć poziomów warunków awarii, które wahają się od najmniej restrykcyjnych (poziom jeden) do najbardziej restrykcyjnych (poziom pięć) |
Użyj języka Transact-SQL (T-SQL), aby zmodyfikować warunki sprawdzania kondycji i niepowodzenia zarówno dla grup AG, jak i wystąpień klastra trybu failover.
W przypadku grup dostępności:
ALTER AVAILABILITY GROUP AG1 SET (HEALTH_CHECK_TIMEOUT =60000);
ALTER AVAILABILITY GROUP AG1 SET (FAILURE_CONDITION_LEVEL = 2);
W przypadku instancji klastra przełączania awaryjnego:
ALTER SERVER CONFIGURATION SET FAILOVER CLUSTER PROPERTY HealthCheckTimeout = 60000;
ALTER SERVER CONFIGURATION SET FAILOVER CLUSTER PROPERTY FailureConditionLevel = 2;
Grupy dostępności: rozpocznij od następujących zalecanych parametrów i dostosuj je w razie potrzeby.
| Parametr | Domyślna wartość | Wartość zrelaksowana | opis |
|---|---|---|---|
| Limit czasu dzierżawy | 20000 | 40000 | Zapobiega podziałowi mózgu. |
| Limit czasu sesji | 10 000 | 20000 | Sprawdza problemy z komunikacją między replikami. Czas limitu sesji to właściwość repliki, która kontroluje, jak długo (w sekundach) replika dostępności czeka na odpowiedź ping z połączonej repliki, zanim uzna połączenie za nieudane. Domyślnie replika czeka 10 sekund na odpowiedź ping. Ta właściwość repliki ma zastosowanie tylko do połączenia między daną repliką pomocniczą a repliką podstawową grupy dostępności. |
| Maksymalna liczba niepowodzeń w określonym przedziale czasu | 2 | 6 | Służy do unikania niekontrolowanego przenoszenia zasobu klastrowanego podczas wielokrotnych awarii węzłów. Zbyt mała wartość może prowadzić do tego, że grupa dostępności jest w stanie niepowodzenia. Zwiększ wartość, aby zapobiec krótkim przerywaniom spowodowanym problemami wydajnościowymi, ponieważ zbyt niska wartość może prowadzić do awarii grupy dostępności. |
Przed wprowadzeniem jakichkolwiek zmian należy wziąć pod uwagę następujące kwestie:
- Nie obniżaj wartości limitu czasu poniżej wartości domyślnych.
- Użyj tego równania, aby obliczyć maksymalną wartość limitu czasu dzierżawy:
Lease timeout < (2 * SameSubnetThreshold * SameSubnetDelay).
Zacznij od 40 sekund. Jeśli używasz wcześniej zalecanych wartościSameSubnetThresholdiSameSubnetDelay, nie przekraczaj 80 sekund dla limitu czasu dzierżawy. - W przypadku replik z zatwierdzaniem synchronicznym zmiana czasu oczekiwania sesji na wartość wysokiej wartości może zwiększyć oczekiwania HADR_sync_commit.
Limit czasu dzierżawy
Użyj Menedżera klastra trybu failover, aby zmodyfikować ustawienia limitu czasu dzierżawy dla grupy dostępności. Szczegółowe kroki można znaleźć w dokumentacji sprawdzania kondycji dzierżawy grupy dostępności programu SQL Server.
Limit czasu sesji
Użyj języka Transact-SQL (T-SQL), aby zmodyfikować limit czasu sesji dla grupy dostępności:
ALTER AVAILABILITY GROUP AG1
MODIFY REPLICA ON 'INSTANCE01' WITH (SESSION_TIMEOUT = 20);
Maksymalna liczba niepowodzeń w określonym przedziale czasu
Użyj Menedżera Klastra Przełączania Awaryjnego, aby zmodyfikować wartość Maksymalne błędy w określonym przedziale czasu.
- Wybierz pozycję Role w okienku nawigacji.
- W obszarze Role kliknij prawym przyciskiem myszy zasób klastrowany i wybierz polecenie Właściwości.
- Wybierz kartę Failover i zwiększ maksymalną liczbę niepowodzeń w określonym przedziale czasu zgodnie z potrzebami.
Limity zasobów
Limity maszyn wirtualnych lub dysków mogą spowodować wąskie gardło zasobów, które wpływa negatywnie na kondycję klastra i utrudnia kontrolę kondycji. Jeśli występują problemy z limitami zasobów, rozważ następujące kwestie:
- Użyj analizy I/O (wersja zapoznawcza) w portalu Azure, aby zidentyfikować problemy z wydajnością dysku, które mogą powodować przełączenie awaryjne.
- Upewnij się, że system operacyjny, sterowniki i program SQL Server mają najnowsze kompilacje.
- Optymalizowanie programu SQL Server w środowisku maszyny wirtualnej platformy Azure zgodnie z opisem w wytycznych dotyczących wydajności programu SQL Server na maszynach wirtualnych platformy Azure
- Użyj
- Zmniejsz lub rozłóż obciążenie, aby ograniczyć wykorzystanie bez przekraczania limitów zasobów.
- Optymalizacja obciążenia serwera SQL Server, jeśli istnieje taka możliwość, na przykład
- dodanie/optymalizacja indeksów;
- aktualizacja statystyk w razie potrzeby, a jeśli to możliwe, przy użyciu pełnego skanowania;
- użycie funkcji, takich jak zarządca zasobów (począwszy od programu SQL Server 2014, tylko w wersji Enterprise), aby ograniczyć wykorzystanie zasobów podczas określonych obciążeń, takich jak tworzenie kopii zapasowych lub konserwacja indeksu.
- Przejdź do maszyny wirtualnej lub dysku, który ma wyższe limity, aby spełnić lub przekroczyć wymagania obciążenia.
Nawiązywanie kontaktów
Wdróż maszyny wirtualne programu SQL Server w wielu podsieciach, jeśli to możliwe, aby uniknąć zależności od usługi Azure Load Balancer lub rozproszonej nazwy sieci (DNN), aby kierować ruch do rozwiązania HADR.
Użyj pojedynczej karty sieciowej na każdą serwerową jednostkę (węzeł klastra). Sieć platformy Azure ma nadmiarowość fizyczną, co sprawia, że dodatkowe karty sieciowe są niepotrzebne w klastrze maszyn wirtualnych gościa na platformie Azure. Raport weryfikacji klastra ostrzega, że węzły są dostępne tylko w jednej sieci. To ostrzeżenie można zignorować w klastrach nadmiarowych gości maszyn wirtualnych na platformie Azure.
Limity przepustowości dla określonej maszyny wirtualnej są współużytkowane przez karty sieciowe i dodanie dodatkowej karty sieciowej nie zwiększa wydajności grupy dostępności dla programu SQL Server na maszynach wirtualnych platformy Azure. W związku z tym nie ma potrzeby dodawania drugiej karty sieciowej.
Niezgodna z RFC usługa DHCP na platformie Azure może powodować niepowodzenia przy tworzeniu niektórych konfiguracji klastra przełączania awaryjnego. Ten błąd występuje, ponieważ nazwa sieci klastra jest przypisana zduplikowany adres IP, taki jak ten sam adres IP co jeden z węzłów klastra. Jest to problem podczas korzystania z grup dostępności, które zależą od funkcji klastra trybu failover systemu Windows.
Rozważmy scenariusz utworzenia klastra z dwoma węzłami i włączenia go do trybu online:
- Klaster wchodzi do trybu online, a następnie węzeł NODE1 żąda dynamicznie przypisanego adresu IP dla nazwy sieci klastra.
- Usługa DHCP nie podaje żadnego adresu IP innego niż własny adres IP węzła1, ponieważ usługa DHCP rozpoznaje, że żądanie pochodzi z samego węzła NODE1.
- System Windows wykrywa, że zduplikowany adres jest przypisany zarówno do węzła NODE1, jak i do nazwy sieciowej klastra z funkcją przełączania awaryjnego, a domyślna grupa klastra nie może być dostępna.
- Domyślna grupa klastrów zostanie przeniesiona do węzła NODE2. Węzeł NODE2 traktuje adres IP węzła1 jako adres IP klastra i przenosi domyślną grupę klastra do trybu online.
- Gdy węzeł NODE2 próbuje nawiązać łączność z węzłem NODE1, pakiety kierowane do węzła NODE1 nigdy nie opuszczają NODE2, ponieważ rozpoznaje adres IP węzła NODE1 jako swój. Węzeł NODE2 nie może nawiązać łączności z węzłem NODE1, a następnie traci kworum i zamyka klaster.
- Węzeł NODE1 może wysyłać pakiety do węzła NODE2, ale węzeł NODE2 nie może odpowiedzieć. Węzeł NODE1 traci kworum i zamyka cały klaster.
Ten scenariusz można uniknąć, przypisując nieużywany statyczny adres IP do nazwy sieciowej klastra w celu przełączenia nazwy sieciowej klastra do trybu online i dodania adresu IP do usługi Azure Load Balancer.
Jeśli aparat bazy danych programu SQL Server, odbiornik zawsze włączonej grupy dostępności, sonda kondycji wystąpienia klastra trybu failover, punkt końcowy dublowania bazy danych, zasób podstawowego adresu IP klastra lub dowolny inny zasób SQL jest skonfigurowany do używania portu z zakresu od 49 152 do 65 536 ( domyślny zakres portów dynamicznych dla protokołu TCP/IP), dodaj wykluczenie dla każdego portu. Zapobiega to dynamicznemu przypisywaniu tego samego portu przez inne procesy systemowe. Poniższy przykład tworzy wykluczenie dla portu 59999:
netsh int ipv4 add excludedportrange tcp startport=59999 numberofports=1 store=persistent
Ważne jest skonfigurowanie wykluczenia portu, gdy port nie jest używany, w przeciwnym razie polecenie kończy się niepowodzeniem z komunikatem, na przykład "Proces nie może uzyskać dostępu do pliku, ponieważ jest używany przez inny proces".
Aby upewnić się, że wykluczenia zostały poprawnie skonfigurowane, użyj następującego polecenia: netsh int ipv4 show excludedportrange tcp.
Ustawienie tego wykluczenia dla portu sondy IP roli grupy dostępności powinno uniemożliwić zdarzenia, takie jak identyfikator zdarzenia: 1069 ze stanem 10048. To zdarzenie można zobaczyć w zdarzeniach klastra trybu failover systemu Windows z następującym komunikatem:
Cluster resource '<IP name in AG role>' of type 'IP Address' in cluster role '<AG Name>' failed.
An Event ID: 1069 with status 10048 can be identified from cluster logs with events like:
Resource IP Address 10.0.1.0 called SetResourceStatusEx: checkpoint 5. Old state OnlinePending, new state OnlinePending, AppSpErrorCode 0, Flags 0, nores=false
IP Address <IP Address 10.0.1.0>: IpaOnlineThread: **Listening on probe port 59999** failed with status **10048**
Status [**10048**](/windows/win32/winsock/windows-sockets-error-codes-2) refers to: **This error occurs** if an application attempts to bind a socket to an **IP address/port that has already been used** for an existing socket.
Może to być spowodowane przez proces wewnętrzny, który przyjmuje ten sam port zdefiniowany jako port sondy. Pamiętaj, że port sondowania służy do sprawdzania statusu instancji puli zaplecza w usłudze Azure Load Balancer.
Jeśli sondzie zdrowotnej nie uda się otrzymać odpowiedzi z wystąpienia zaplecza, żadne nowe połączenia nie będą wysyłane do tego wystąpienia aż do momentu, gdy sonda zdrowotna znowu się powiedzie.
Znane problemy
Zapoznaj się z rozwiązaniami niektórych często znanych problemów i błędów.
Rywalizacja o zasoby (w szczególności wejścia/wyjścia) powoduje przełączenie awaryjne.
Wyczerpanie wydajności wejścia/wyjścia lub procesora dla twojej maszyny wirtualnej może spowodować przełączenie awaryjne twojej grupy dostępności. Identyfikowanie rywalizacji, która odbywa się bezpośrednio przed przejściem w tryb failover, jest najbardziej niezawodnym sposobem identyfikowania przyczyn automatycznego przejścia w tryb failover.
Korzystanie z analizy we/wy
Użyj analizy we/wy (wersja zapoznawcza) w portalu Azure, aby zidentyfikować problemy z wydajnością dysku, które mogą powodować przejście na tryb failover.
Monitorowanie za pomocą metryk we/wy magazynu maszyn wirtualnych
Monitoruj maszyny wirtualne platformy Azure, aby spojrzeć na metryki użycia operacji we/wy magazynu, aby zrozumieć opóźnienie na poziomie maszyny wirtualnej lub dysku.
Wykonaj następujące kroki, aby przejrzeć ogólne wyczerpanie operacji wejścia/wyjścia maszyny wirtualnej platformy Azure:
Przejdź do Maszyny wirtualnej w portalu Azure — a nie do maszyn wirtualnych SQL.
Wybierz pozycję Metryki w obszarze Monitorowanie , aby otworzyć stronę Metryki .
Wybierz Czas lokalny aby określić zakres czasowy, który Cię interesuje, oraz strefę czasową, lokalną dla maszyny wirtualnej lub UTC/GMT.
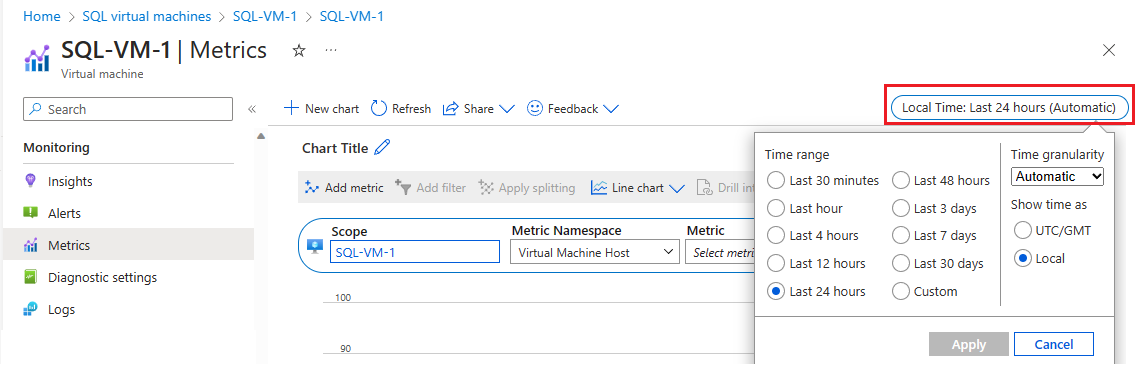
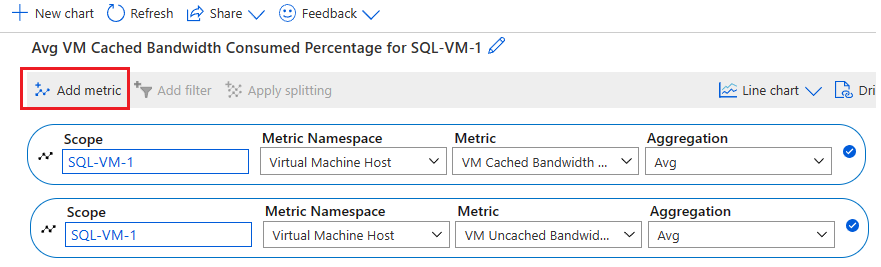
Wybierz pozycję Dodaj metrykę , aby dodać następujące dwie metryki, aby wyświetlić wykres:
- Procent użycia przepustowości pamięci podręcznej maszyny wirtualnej
- Procent zużycia niebuforowanej przepustowości przez maszynę wirtualną
HostEvents platformy Azure powoduje przejście maszyny wirtualnej w tryb failover.
Możliwe, że element HostEvent maszyny wirtualnej platformy Azure powoduje przełączenie grupy dostępności w tryb failover. Jeśli uważasz, że zdarzenie HostEvent maszyny wirtualnej platformy Azure spowodowało awarię powodującą przełączenie, możesz sprawdzić dziennik aktywności usługi Azure Monitor i widok stanu zasobów maszyn wirtualnych Azure.
Dziennik aktywności usługi Azure Monitor to dziennik platformy na platformie Azure, który zapewnia wgląd w zdarzenia na poziomie subskrypcji. Dziennik aktywności zawiera informacje, takie jak czas modyfikacji zasobu lub uruchomienie maszyny wirtualnej. Dziennik aktywności można wyświetlić w witrynie Azure Portal lub pobrać wpisy za pomocą programu PowerShell i interfejsu wiersza polecenia platformy Azure.
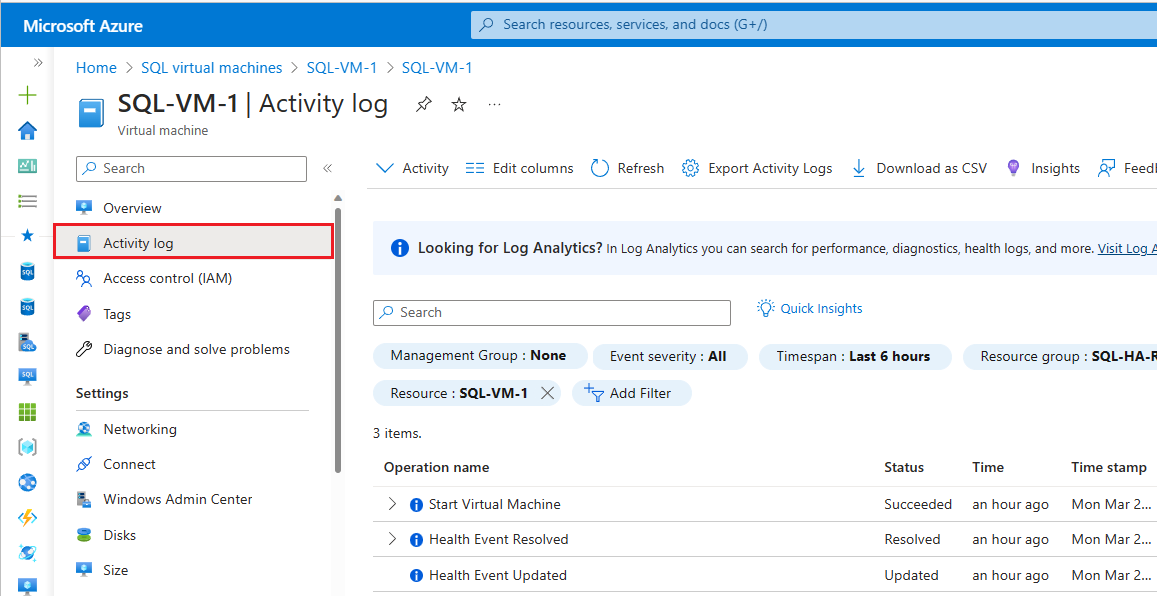
Aby sprawdzić dziennik aktywności usługi Azure Monitor, wykonaj następujące kroki:
Przejdź do maszyny wirtualnej w witrynie Azure Portal
Wybierz pozycję Dziennik aktywności w okienku Maszyna wirtualna
Wybierz pozycję Przedział czasu , a następnie wybierz przedział czasu po przejściu grupy dostępności w tryb failover. Wybierz Zastosuj.
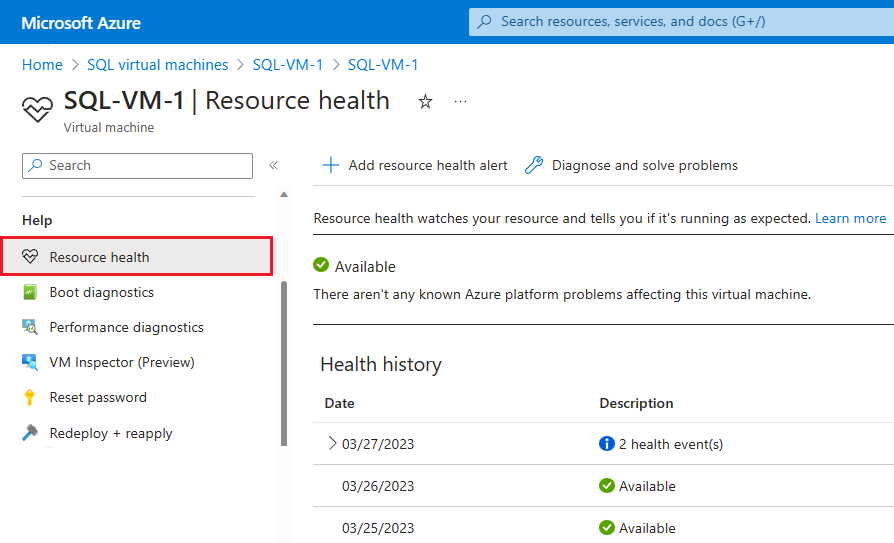
Jeśli platforma Azure zawiera dodatkowe informacje o głównej przyczynie niedostępności zainicjowanej przez platformę, te informacje mogą być publikowane na stronie przeglądu usługi Azure VM — Resource Health do 72 godzin po początkowej niedostępności. Te informacje są obecnie dostępne tylko dla maszyn wirtualnych.
- Przejdź do maszyny wirtualnej w witrynie Azure Portal
- Wybierz Resource Health w panelu Kondycja zdrowotna.
Możesz również skonfigurować na tej stronie alerty na podstawie zdarzeń związanych ze stanem zdrowia.
Węzeł klastra został usunięty z członkostwa
Jeśli ustawienia pulsu i progu klastra systemu Windows są zbyt agresywne dla danego środowiska, często w dzienniku zdarzeń systemu może zostać wyświetlony następujący komunikat.
Error 1135
Cluster node 'Node1' was removed from the active failover cluster membership.
The Cluster service on this node may have stopped. This could also be due to the node having
lost communication with other active nodes in the failover cluster. Run the Validate a
Configuration Wizard to check your network configuration. If the condition persists, check
for hardware or software errors related to the network adapters on this node. Also check for
failures in any other network components to which the node is connected such as hubs, switches, or bridges.
Aby uzyskać więcej informacji, zobacz Rozwiązywanie problemów z klastrem o identyfikatorze zdarzenia 1135.
Dzierżawa wygasła/ Dzierżawa nie jest już prawidłowa
Jeśli monitorowanie jest zbyt agresywne dla danego środowiska, może być widoczne częste ponowne uruchamianie grupy dostępności lub ponowne uruchamianie trybu failover klastra, awarie lub przełączanie trybu pracy. Ponadto w przypadku grup dostępności mogą zostać wyświetlone następujące komunikaty w dzienniku błędów programu SQL Server:
Error 19407: The lease between availability group 'PRODAG' and the Windows Server Failover Cluster has expired.
A connectivity issue occurred between the instance of SQL Server and the Windows Server Failover Cluster.
To determine whether the availability group is failing over correctly, check the corresponding availability group
resource in the Windows Server Failover Cluster
Error 19419: The renewal of the lease between availability group '%.*ls' and the Windows Server Failover Cluster
failed because the existing lease is no longer valid.
Przekroczenie limitu czasu połączenia
Jeśli limit czasu sesji jest zbyt agresywny dla środowiska grupy dostępności, często mogą być wyświetlane następujące komunikaty:
Error 35201: A connection timeout has occurred while attempting to establish a connection to availability
replica 'replicaname' with ID [availability_group_id]. Either a networking or firewall issue exists,
or the endpoint address provided for the replica is not the database mirroring endpoint of the host server instance.
Error 35206
A connection timeout has occurred on a previously established connection to availability
replica 'replicaname' with ID [availability_group_id]. Either a networking or a firewall issue
exists, or the availability replica has transitioned to the resolving role.
Grupa nie przełącza się na tryb awaryjny
Jeśli wartość Maksymalna liczba niepowodzeń w określonym okresie jest zbyt niska i doświadczasz sporadycznych niepowodzeń z powodu przejściowych problemów, grupa dostępności może zakończyć w stanie awarii. Zwiększ tę wartość, aby tolerować więcej błędów przejściowych.
Not failing over group <Resource name>, failoverCount 3, failoverThresholdSetting <Number>, computedFailoverThreshold 2.
Zdarzenie 1196 — Rejestracja skojarzonej nazwy DNS zasobu sieciowego nie powiodła się
- Sprawdź ustawienia karty sieciowej dla wszystkich węzłów klastra i upewnij się, że nie ma żadnych zewnętrznych rekordów DNS
- Upewnij się, że na wewnętrznych serwerach DNS istnieje rekord A dla klastra. Jeśli tak nie jest, utwórz ręcznie nowy rekord A na serwerze DNS dla obiektu kontroli dostępu do klastra i zaznacz ustawienie Zezwalaj wszystkim uwierzytelnionym użytkownikom na aktualizowanie rekordów DNS z tą samą nazwą właściciela.
- Przełącz zasób „Nazwa klastra” razem z zasobem IP do trybu offline i napraw go.
Zdarzenie 157 — dysk został usunięty z zaskoczeniem.
Może się tak zdarzyć, jeśli właściwość Storage Spaces AutomaticClusteringEnabled jest ustawiona na True dla środowiska AG. Zmień ją na False. Uruchomienie raportu walidacji z opcją magazynu może także spowodować zresetowanie dysku lub zdarzenie nieoczekiwanego usunięcia. Przyczyną zdarzenia nieoczekiwanego usunięcia dysku może być także ograniczanie przepustowości w systemie pamięci masowej.
Zdarzenie 1206 — nie można udostępnić zasobu nazwy sieciowej klastra online.
Nie można zaktualizować obiektu komputera skojarzonego z zasobem w domenie. Upewnij się, że masz odpowiednie uprawnienia do domeny
Błędy klastrowania systemu Windows
Jeśli nie masz otwartych portów usługi klastra do komunikacji, mogą wystąpić problemy podczas konfigurowania klastra awaryjnego przełączania systemu Windows lub jego łączności.
Jeśli korzystasz z systemu Windows Server 2019 i nie widzisz adresu IP klastra systemu Windows, skonfigurowano nazwę sieci rozproszonej, która jest obsługiwana tylko w programie SQL Server 2019. Jeśli masz starszą wersję programu SQL Server, możesz usunąć klaster i utworzyć go ponownie przy użyciu nazwy sieciowej.
Przejrzyj inne błędy zdarzeń klastra trybu failover systemu Windows i ich rozwiązania tutaj
Następne kroki
Aby dowiedzieć się więcej, zobacz:
- Ustawienia usługi HADR dla programu SQL Server na maszynach wirtualnych platformy Azure
- Klaster trybu failover systemu Windows Server z programem SQL Server na maszynach wirtualnych platformy Azure
- Grupy dostępności Always On z SQL Server na maszynach wirtualnych Azure
- Klaster awaryjny Windows Server z SQL Server na maszynach wirtualnych Azure
- Instancje klastra przełączania awaryjnego z programem SQL Server na maszynach wirtualnych platformy Azure
- Omówienie wystąpienia klastra failover