Rozwiązywanie problemów z łącznością z usługą Azure SQL Managed Instance przy użyciu usługi Resource Health
Dotyczy: ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
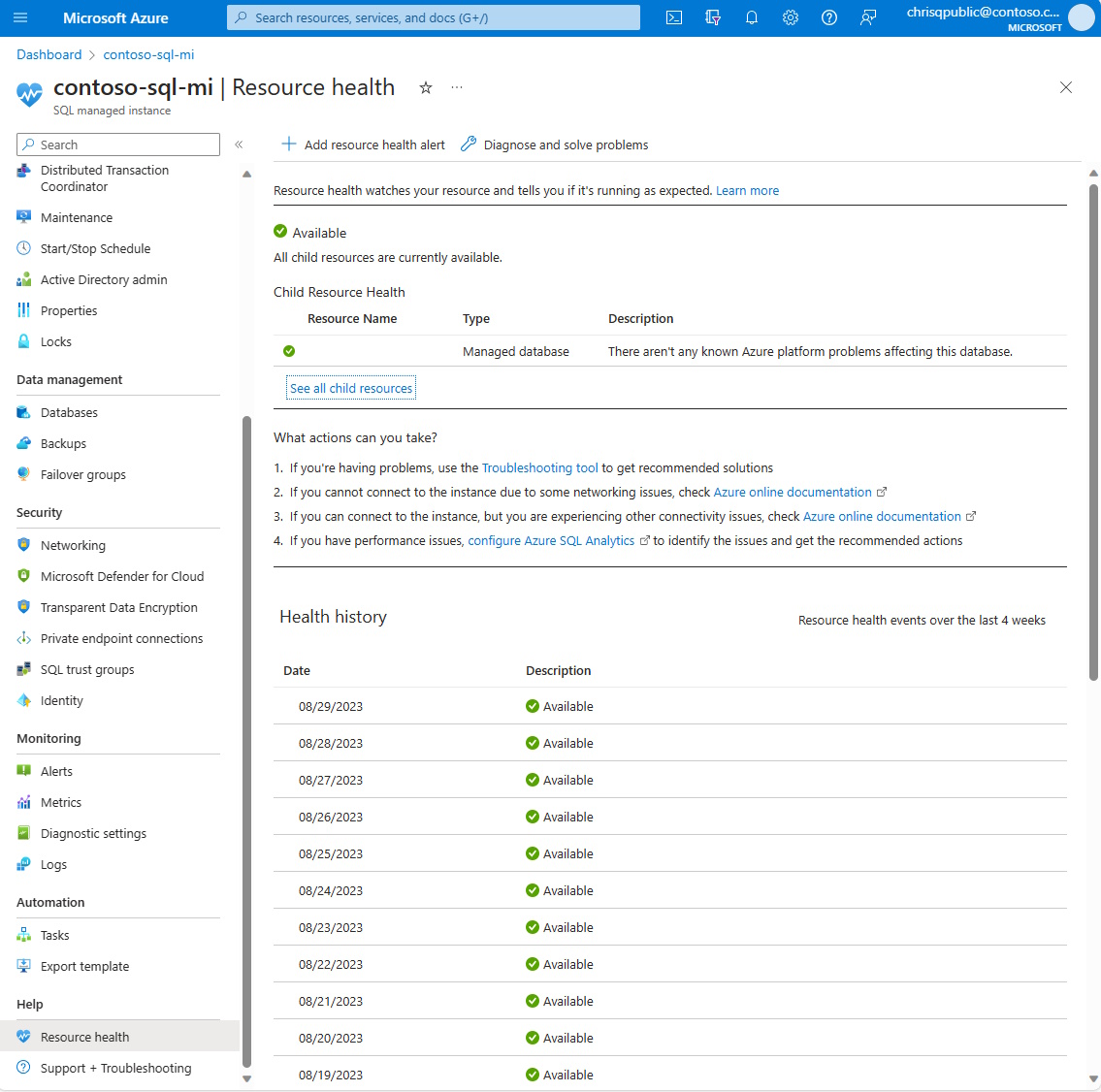
Usługa Resource Health dla usługi Azure SQL Managed Instance ułatwia diagnozowanie i uzyskiwanie pomocy technicznej, gdy problem z platformą Azure ma wpływ na zasoby. Informuje o bieżącej i wcześniejszej kondycji zasobów oraz pomaga uniknąć problemów. Strona Kondycja zasobu zapewnia pomoc techniczną, gdy potrzebujesz pomocy dotyczącej problemów z usługą platformy Azure.
Kontrole kondycji
Kondycja zasobu określa kondycję wystąpienia zarządzanego SQL, sprawdzając powodzenie i niepowodzenie logowania do zasobu. Obecnie kondycja zasobu dla wystąpienia zarządzanego SQL sprawdza tylko błędy logowania z powodu błędu systemu, a nie błędu użytkownika. Stan kondycji jest aktualizowany co 1 do 2 minut.
Stany kondycji
Dostępny
Stan Dostępne oznacza, że usługa Resource Health nie wykryła błędów logowania z powodu błędów systemowych w wystąpieniu zarządzanym SQL.
Obniżona wydajność
Stan Obniżona wydajność oznacza, że kondycja zasobu wykryła większość pomyślnych logowań, ale także niektóre błędy. Są to najprawdopodobniej przejściowe błędy logowania. Aby zmniejszyć wpływ problemów z połączeniem spowodowanych przejściowymi błędami logowania, zaimplementuj logikę ponawiania prób w kodzie.
Niedostępny
Stan Niedostępny oznacza, że usługa Resource Health wykryła spójne błędy logowania do wystąpienia zarządzanego SQL. Jeśli zasób pozostaje w tym stanie przez dłuższy czas, skontaktuj się z pomocą techniczną.
Nieznane
Stan kondycji Nieznany wskazuje, że usługa Resource Health nie otrzymała informacji o tym zasobie przez ponad 10 minut. Chociaż ten stan nie jest ostatecznym wskazaniem stanu zasobu, jest to ważny punkt danych w procesie rozwiązywania problemów. Jeśli zasób jest uruchomiony zgodnie z oczekiwaniami, stan zasobu zmieni się na Dostępny po kilku minutach. Jeśli występują problemy z zasobem, nieznany stan kondycji może sugerować, że zdarzenie na platformie ma wpływ na zasób.
Informacje historyczne
Dostęp do historii kondycji można uzyskać do 30 dni w sekcji Historia kondycji usługi Resource Health. Sekcja będzie również zawierać przyczynę (jeśli jest dostępna) dla przestojów. Obecnie platforma Azure pokazuje przestój zasobu w dwuminutowym poziomie szczegółowości. W rzeczywistości przestój trwa prawdopodobnie mniej niż minutę. Średnia wynosi 8 sekund.
Przyczyny przestojów
Gdy wystąpi przestój wystąpienia zarządzanego SQL, analiza jest wykonywana w celu określenia przyczyny. Jeśli jest dostępna, przyczyna przestoju jest zgłaszana w sekcji Historia kondycji usługi Resource Health. Przyczyny przestojów są zwykle publikowane w ciągu 45 minut po zdarzeniu.
Wybieranie okna obsługi
Okno obsługi można skonfigurować tak, aby miało to wpływ na zdarzenia konserwacji przewidywalne i mniej zakłócające obciążenie. Funkcja okna obsługi ułatwia planowanie przewidywalnych uaktualnień lub zaplanowanej konserwacji. Powiadomienia z wyprzedzeniem są dostępne dla wszystkich wystąpień zarządzanych SQL. Powiadomienia z wyprzedzeniem umożliwiają klientom skonfigurowanie powiadomień wysyłanych z wyprzedzeniem do 24 godzin przed każdym zaplanowanym zdarzeniem.
Planowana konserwacja
Infrastruktura platformy Azure okresowo wykonuje planowaną konserwację — uaktualnianie sprzętu lub składników oprogramowania w centrum danych. Podczas gdy baza danych jest w trakcie konserwacji, usługa Azure SQL może zakończyć niektóre istniejące połączenia i odrzucać nowe. Błędy logowania występujące podczas planowanej konserwacji są zwykle przejściowe, a logika ponawiania prób w przypadku sporadycznych błędów sieci pomaga zmniejszyć wpływ. Jeśli nadal występują błędy logowania, skontaktuj się z pomocą techniczną.
Ponowne konfigurowanie
Ponowne konfiguracje są uznawane za przejściowe warunki i są oczekiwane od czasu do czasu. Te zdarzenia mogą być wyzwalane przez równoważenie obciążenia lub awarie oprogramowania/sprzętu. Każda aplikacja produkcyjna klienta, która łączy się z bazą danych w chmurze, powinna zaimplementować niezawodną logikę ponawiania prób połączenia w przypadku błędów przejściowych, ponieważ pomoże to ograniczyć te sytuacje i zwykle powinno spowodować, że błędy będą niewidoczne dla użytkownika końcowego.
Następne kroki
- Dowiedz się więcej na temat logiki ponawiania prób dla błędów przejściowych.
- Rozwiązywanie problemów, diagnozowanie i zapobieganie błędom połączenia SQL.
- Dowiedz się więcej o konfigurowaniu alertów usługi Resource Health.
- Zapoznaj się z omówieniem usługi Resource Health.
- Zapoznaj się z często zadawanymi pytaniami dotyczącymi usługi Resource Health.
- Skonfiguruj okno obsługi i powiadomienia z wyprzedzeniem.