Tworzenie woluminów w klastrach azure Stack HCI i Windows Server
Dotyczy: Azure Stack HCI, wersje 22H2 i 21H2; Windows Server 2022, Windows Server 2019, Windows Server 2016
Ważne
Usługa Azure Stack HCI jest teraz częścią usługi Azure Local. Trwa zmiana nazwy dokumentacji produktu. Jednak starsze wersje rozwiązania Azure Stack HCI, na przykład 22H2 będą nadal odwoływać się do rozwiązania Azure Stack HCI i nie będą odzwierciedlać zmiany nazwy. Dowiedz się więcej.
W tym artykule opisano sposób tworzenia woluminów w klastrze przy użyciu centrum administracyjnego systemu Windows i programu Windows PowerShell, sposobu pracy z plikami na woluminach oraz sposobu włączania deduplikacji i kompresji, sum kontrolnych integralności lub szyfrowania funkcją BitLocker na woluminach. Aby dowiedzieć się, jak tworzyć woluminy i konfigurować replikację dla klastrów rozproszony, zobacz Tworzenie woluminów rozproszony.
Napiwek
Jeśli jeszcze tego nie zrobiono, najpierw zapoznaj się z planowaniem woluminów .
Podczas tworzenia woluminów w klastrze z jednym węzłem należy użyć programu PowerShell. Zobacz Tworzenie woluminów przy użyciu programu PowerShell.
Tworzenie woluminu dublowanego dwustopniowego lub trójstopniowego
Aby utworzyć wolumin dublowania dwukierunkowego lub trójstopniowego przy użyciu centrum administracyjnego systemu Windows:
W centrum administracyjnym systemu Windows połącz się z klastrem, a następnie wybierz pozycję Woluminy w okienku Narzędzia .
Na stronie Woluminy wybierz kartę Spis , a następnie wybierz pozycję Utwórz.
W okienku Tworzenie woluminu wprowadź nazwę woluminu.
W obszarze Odporność wybierz opcję Dublowanie dwukierunkowe lub Dublowanie trzystopniowe w zależności od liczby serwerów w klastrze.
W obszarze Rozmiar na dysku TWARDYM określ rozmiar woluminu. Na przykład 5 TB (terabajty).
W obszarze Więcej opcji można użyć pól wyboru, aby włączyć deduplikację i kompresję, sumy kontrolne integralności lub szyfrowanie funkcji BitLocker.
Wybierz pozycję Utwórz.
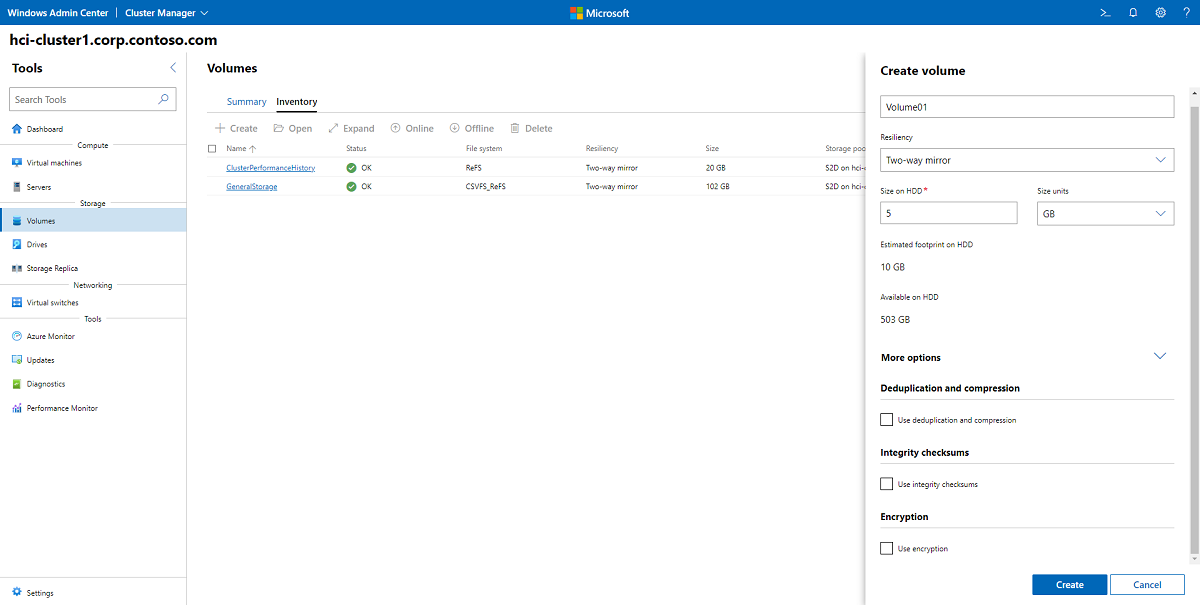

W zależności od rozmiaru tworzenie woluminu może potrwać kilka minut. Powiadomienia w prawym górnym rogu będą otrzymywać informacje o utworzeniu woluminu. Nowy wolumin pojawi się na liście Spis.
Tworzenie woluminu parzystości przyspieszanej przez dublowanie
Parzystość przyspieszana przez dublowanie (MAP) zmniejsza zużycie woluminu na dysku TWARDYM. Na przykład wolumin dublowania trzystopniowego oznacza, że dla każdego 10 terabajtów rozmiaru będzie potrzebnych 30 terabajtów jako ślad. Aby zmniejszyć obciążenie związane z zużyciem, utwórz wolumin z parzystością przyspieszaną przez dublowanie. Zmniejsza to zużycie danych z 30 terabajtów do zaledwie 22 terabajtów, nawet w przypadku tylko 4 serwerów, dublując najbardziej aktywne 20 procent danych i używając parzystości, która jest wydajniejsza w celu przechowywania reszty. Możesz dostosować ten współczynnik parzystości i dublowania, aby wydajność w porównaniu z kompromisem wydajności, który jest odpowiedni dla obciążenia. Na przykład 90 procent parzystości i 10 procent dublowania daje mniejszą wydajność, ale usprawnia jeszcze więcej śladu.
Uwaga
Woluminy parzystości przyspieszanej przez dublowanie wymagają systemu plików ReFS (Resilient File System).
Aby utworzyć wolumin z parzystością przyspieszaną przez dublowanie w Centrum administracyjnym systemu Windows:
- W centrum administracyjnym systemu Windows połącz się z klastrem, a następnie wybierz pozycję Woluminy w okienku Narzędzia .
- Na stronie Woluminy wybierz kartę Spis , a następnie wybierz pozycję Utwórz.
- W okienku Tworzenie woluminu wprowadź nazwę woluminu.
- W obszarze Odporność wybierz pozycję Parzystość przyspieszana przez dublowanie.
- W obszarze Procent parzystości wybierz wartość procentową parzystości.
- W obszarze Więcej opcji można użyć pól wyboru, aby włączyć deduplikację i kompresję, sumy kontrolne integralności lub szyfrowanie funkcji BitLocker.
- Wybierz pozycję Utwórz.
Otwieranie woluminu i dodawanie plików
Aby otworzyć wolumin i dodać pliki do woluminu w centrum administracyjnym systemu Windows:
W centrum administracyjnym systemu Windows połącz się z klastrem, a następnie wybierz pozycję Woluminy w okienku Narzędzia .
Na stronie Woluminy wybierz kartę Spis .
Na liście woluminów wybierz nazwę woluminu, który chcesz otworzyć.
Na stronie szczegółów woluminu można zobaczyć ścieżkę do woluminu.
W górnej części strony wybierz pozycję Otwórz. Spowoduje to uruchomienie narzędzia Pliki w centrum administracyjnym systemu Windows.
Przejdź do ścieżki woluminu. W tym miejscu możesz przeglądać pliki w woluminie.
Wybierz pozycję Przekaż, a następnie wybierz plik do przekazania.
Użyj przycisku Wstecz przeglądarki, aby wrócić do okienka Narzędzia w Centrum administracyjnym systemu Windows.
Włączanie deduplikacji i kompresji
Deduplikacja i kompresja są zarządzane na wolumin. Deduplikacja i kompresja korzystają z modelu przetwarzania końcowego, co oznacza, że nie zobaczysz oszczędności, dopóki nie zostanie uruchomiona. Gdy tak, będzie działać nad wszystkimi plikami, nawet tymi, które były tam wcześniej.
Aby dowiedzieć się więcej, zobacz Włączanie szyfrowania woluminów, deduplikacji i kompresji
Tworzenie woluminów przy użyciu programu Windows PowerShell
Najpierw uruchom program Windows PowerShell z menu Start systemu Windows. Zalecamy użycie polecenia cmdlet New-Volume do utworzenia woluminów dla rozwiązania Azure Stack HCI. Zapewnia najszybsze i najprostsze środowisko. To pojedyncze polecenie cmdlet automatycznie tworzy dysk wirtualny, partycje i formatuje go, tworzy wolumin o pasującej nazwie i dodaje go do udostępnionych woluminów klastra — wszystko w jednym prostym kroku.
Polecenie cmdlet New-Volume ma cztery parametry, które zawsze trzeba podać:
FriendlyName: dowolny ciąg, na przykład "Volume1"
System plików: CSVFS_ReFS (zalecane dla wszystkich woluminów; wymagane dla woluminów parzystości przyspieszanej przez dublowanie) lub CSVFS_NTFS
StoragePoolFriendlyName: nazwa puli magazynów, na przykład "S2D on ClusterName"
Rozmiar: rozmiar woluminu, na przykład "10 TB"
Uwaga
System Windows, w tym program PowerShell, liczy się przy użyciu liczb binarnych (base-2), natomiast dyski są często oznaczane przy użyciu liczb dziesiętnych (base-10). Wyjaśnia to, dlaczego dysk "jeden terabajt", zdefiniowany jako 1000 000 000 000 000 bajtów, pojawia się w systemie Windows jako około "909 GB". Jest to oczekiwane. Podczas tworzenia woluminów przy użyciu polecenia New-Volume należy określić parametr Rozmiar w liczbach binarnych (base-2). Na przykład określenie wartości "909 GB" lub "0,909495 TB" spowoduje utworzenie woluminu o rozmiarze około 1 000 000 000 000 bajtów.
Przykład: z 1 do 3 serwerów
Aby ułatwić sobie sprawę, jeśli wdrożenie ma tylko jeden lub dwa serwery, usługa Miejsca do magazynowania Direct automatycznie użyje dublowania dwukierunkowego w celu zapewnienia odporności. Jeśli wdrożenie ma tylko trzy serwery, automatycznie użyje dublowania trójstopniowego.
New-Volume -FriendlyName "Volume1" -FileSystem CSVFS_ReFS -StoragePoolFriendlyName S2D* -Size 1TB
Przykład: z 4 lub nowszymi serwerami
Jeśli masz co najmniej cztery serwery, możesz użyć opcjonalnego parametru ResiliencySettingName , aby wybrać typ odporności.
- ResiliencySettingName: Dublowanie lub Parzystość.
W poniższym przykładzie funkcja "Volume2" używa dublowania trzystopniowego, a funkcja "Volume3" używa parzystości podwójnej (często nazywanej "kodowaniem wymazywania").
New-Volume -FriendlyName "Volume2" -FileSystem CSVFS_ReFS -StoragePoolFriendlyName S2D* -Size 1TB -ResiliencySettingName Mirror
New-Volume -FriendlyName "Volume3" -FileSystem CSVFS_ReFS -StoragePoolFriendlyName S2D* -Size 1TB -ResiliencySettingName Parity
Korzystanie z warstw magazynowania
We wdrożeniach z trzema typami dysków jeden wolumin może obejmować warstwy SSD i HDD, aby częściowo znajdować się na każdym z nich. Podobnie w przypadku wdrożeń z czterema lub większą liczbą serwerów jeden wolumin może mieszać dublowanie i parzystość podwójną, aby częściowo znajdować się na każdym z nich.
Aby ułatwić tworzenie takich woluminów, usługa Azure Stack HCI udostępnia domyślne szablony warstw o nazwie MirrorOnMediaType i NestedMirrorOn MediaType (na potrzeby wydajności) oraz ParityOnMediaType i NestedParityOnMediaType (w przypadku pojemności), gdzie typ MediaType to HDD lub SSD. Szablony reprezentują warstwy magazynowania oparte na typach multimediów i hermetyzują definicje dublowania trzystopniowego na szybszych dyskach pojemności (jeśli dotyczy) i parzystości podwójnej na wolniejszych dyskach pojemności (jeśli ma to zastosowanie).
Uwaga
Pamięć podręczna warstwy magistrali magazynu (SBL) nie jest obsługiwana w konfiguracji pojedynczego serwera. Wszystkie płaskie konfiguracje typu pojedynczego magazynu (na przykład all-NVMe lub all-SSD) są jedynym obsługiwanym typem magazynu dla pojedynczego serwera.
Uwaga
W klastrach Miejsca do magazynowania Direct działających we wcześniejszych wersjach systemu Windows Server 2016 szablony warstw domyślnych były po prostu nazywane wydajnością i pojemnością.
Warstwy magazynowania można wyświetlić, uruchamiając polecenie cmdlet Get-StorageTier na dowolnym serwerze w klastrze.
Get-StorageTier | Select FriendlyName, ResiliencySettingName, PhysicalDiskRedundancy
Jeśli na przykład masz klaster z dwoma węzłami z tylko dyskiem TWARDYM, dane wyjściowe mogą wyglądać mniej więcej tak:
FriendlyName ResiliencySettingName PhysicalDiskRedundancy
------------ --------------------- ----------------------
NestedParityOnHDD Parity 1
Capacity Mirror 1
NestedMirrorOnHDD Mirror 3
MirrorOnHDD Mirror 1
Aby utworzyć woluminy warstwowe, należy odwołać się do tych szablonów warstw przy użyciu parametrów StorageTierFriendlyNames i StorageTierSizes polecenia cmdlet New-Volume. Na przykład następujące polecenie cmdlet tworzy jeden wolumin, który miesza dublowanie trójstopniowe i podwójną parzystość w proporcjach 30:70.
New-Volume -FriendlyName "Volume1" -FileSystem CSVFS_ReFS -StoragePoolFriendlyName S2D* -StorageTierFriendlyNames MirrorOnHDD, Capacity -StorageTierSizes 300GB, 700GB
Powtórz w razie potrzeby, aby utworzyć więcej niż jeden wolumin.
Tabela podsumowania warstwy magazynowania
W poniższych tabelach podsumowano warstwy magazynowania, które można utworzyć w usługach Azure Stack HCI i Windows Server.
NumberOfNodes: 1
| FriendlyName | Typ nośnika | ResiliencySettingName | NumberOfDataCopies | PhysicalDiskRedundancy | NumberOfGroups | FaultDomainAwareness | KolumnaSolacja | Uwaga |
|---|---|---|---|---|---|---|---|---|
| MirrorOnHDD | HDD | Dublowany | 2 | 1 | 1 | Dysk fizyczny | Dysk fizyczny | automatycznie utworzony |
| MirrorOnSSD | SSD | Dublowany | 2 | 1 | 1 | Dysk fizyczny | Dysk fizyczny | automatycznie utworzony |
| MirrorOnSCM | SCM | Dublowany | 2 | 1 | 1 | Dysk fizyczny | Dysk fizyczny | automatycznie utworzony |
| ParityOnHDD | HDD | Parzystość | 1 | 1 | 1 | Dysk fizyczny | Dysk fizyczny | automatycznie utworzony |
| ParityOnSSD | SSD | Parzystość | 1 | 1 | 1 | Dysk fizyczny | Dysk fizyczny | automatycznie utworzony |
| ParityOnSCM | SCM | Parzystość | 1 | 1 | 1 | Dysk fizyczny | Dysk fizyczny | automatycznie utworzony |
NumberOfNodes: 2
| FriendlyName | Typ nośnika | ResiliencySettingName | NumberOfDataCopies | PhysicalDiskRedundancy | NumberOfGroups | FaultDomainAwareness | KolumnaSolacja | Uwaga |
|---|---|---|---|---|---|---|---|---|
| MirrorOnHDD | HDD | Dublowany | 2 | 1 | 1 | StorageScaleUnit | Dysk fizyczny | automatycznie utworzony |
| MirrorOnSSD | SSD | Dublowany | 2 | 1 | 1 | StorageScaleUnit | Dysk fizyczny | automatycznie utworzony |
| MirrorOnSCM | SCM | Dublowany | 2 | 1 | 1 | StorageScaleUnit | Dysk fizyczny | automatycznie utworzony |
| ZagnieżdżoneMirrorOnHDD | HDD | Dublowany | 100 | 3 | 1 | StorageScaleUnit | Dysk fizyczny | ręczne |
| ZagnieżdżoneMirrorOnSSD | SSD | Dublowany | 100 | 3 | 1 | StorageScaleUnit | Dysk fizyczny | ręczne |
| ZagnieżdżoneMirrorOnSCM | SCM | Dublowany | 100 | 3 | 1 | StorageScaleUnit | Dysk fizyczny | ręczne |
| ZagnieżdżoneParityOnHDD | HDD | Parzystość | 2 | 1 | 1 | StorageScaleUnit | Dysk fizyczny | ręczne |
| ZagnieżdżoneparityOnSSD | SSD | Parzystość | 2 | 1 | 1 | StorageScaleUnit | Dysk fizyczny | ręczne |
| ZagnieżdżoneparityOnSCM | SCM | Parzystość | 2 | 1 | 1 | StorageScaleUnit | Dysk fizyczny | ręczne |
NumberOfNodes: 3
| FriendlyName | Typ nośnika | ResiliencySettingName | NumberOfDataCopies | PhysicalDiskRedundancy | NumberOfGroups | FaultDomainAwareness | KolumnaSolacja | Uwaga |
|---|---|---|---|---|---|---|---|---|
| MirrorOnHDD | HDD | Dublowany | 3 | 2 | 1 | StorageScaleUnit | Dysk fizyczny | automatycznie utworzony |
| MirrorOnSSD | SSD | Dublowany | 3 | 2 | 1 | StorageScaleUnit | Dysk fizyczny | automatycznie utworzony |
| MirrorOnSCM | SCM | Dublowany | 3 | 2 | 1 | StorageScaleUnit | Dysk fizyczny | automatycznie utworzony |
NumberOfNodes: 4+
| FriendlyName | Typ nośnika | ResiliencySettingName | NumberOfDataCopies | PhysicalDiskRedundancy | NumberOfGroups | FaultDomainAwareness | KolumnaSolacja | Uwaga |
|---|---|---|---|---|---|---|---|---|
| MirrorOnHDD | HDD | Dublowany | 3 | 2 | 1 | StorageScaleUnit | Dysk fizyczny | automatycznie utworzony |
| MirrorOnSSD | SSD | Dublowany | 3 | 2 | 1 | StorageScaleUnit | Dysk fizyczny | automatycznie utworzony |
| MirrorOnSCM | SCM | Dublowany | 3 | 2 | 1 | StorageScaleUnit | Dysk fizyczny | automatycznie utworzony |
| ParityOnHDD | HDD | Parzystość | 1 | 2 | Automatycznie | StorageScaleUnit | StorageScaleUnit | automatycznie utworzony |
| ParityOnSSD | SSD | Parzystość | 1 | 2 | Automatycznie | StorageScaleUnit | StorageScaleUnit | automatycznie utworzony |
| ParityOnSCM | SCM | Parzystość | 1 | 2 | Automatycznie | StorageScaleUnit | StorageScaleUnit | automatycznie utworzony |
Zagnieżdżone woluminy odporności
Odporność zagnieżdżona dotyczy tylko dwóch klastrów serwerów z systemem Azure Stack HCI lub Windows Server 2022 lub Windows Server 2019; Nie można użyć odporności zagnieżdżonej, jeśli klaster ma co najmniej trzy serwery lub jeśli klaster działa w systemie Windows Server 2016. Zagnieżdżone odporność umożliwia klastrowi dwóch serwerów wytrzymanie wielu awarii sprzętowych w tym samym czasie bez utraty dostępności magazynu, dzięki czemu użytkownicy, aplikacje i maszyny wirtualne będą nadal działać bez zakłóceń. Aby uzyskać więcej informacji, zobacz Zagnieżdżone odporność dla woluminów Miejsca do magazynowania Direct i Plan: wybieranie typu odporności.
Znane polecenia cmdlet magazynu w programie PowerShell umożliwiają tworzenie woluminów z zagnieżdżonymi odpornościami, zgodnie z opisem w poniższej sekcji.
Krok 1. Tworzenie szablonów warstw magazynowania (tylko system Windows Server 2019)
System Windows Server 2019 wymaga utworzenia nowych szablonów warstw magazynowania przy użyciu polecenia cmdlet przed utworzeniem New-StorageTier woluminów. Należy to zrobić tylko raz, a następnie każdy utworzony wolumin może odwoływać się do tych szablonów.
Uwaga
Jeśli korzystasz z systemu Windows Server 2022, Azure Stack HCI 21H2 lub Azure Stack HCI 20H2, możesz pominąć ten krok.
-MediaType Określ dyski pojemności i, opcjonalnie, -FriendlyName wybrane przez Ciebie. Nie modyfikuj innych parametrów.
Jeśli na przykład dyski pojemności są dyskami twardymi (HDD), uruchom program PowerShell jako administrator i uruchom następujące polecenia cmdlet.
Aby utworzyć warstwę NestedMirror:
New-StorageTier -StoragePoolFriendlyName S2D* -FriendlyName NestedMirrorOnHDD -ResiliencySettingName Mirror -MediaType HDD -NumberOfDataCopies 4
Aby utworzyć warstwę NestedParity:
New-StorageTier -StoragePoolFriendlyName S2D* -FriendlyName NestedParityOnHDD -ResiliencySettingName Parity -MediaType HDD -NumberOfDataCopies 2 -PhysicalDiskRedundancy 1 -NumberOfGroups 1 -FaultDomainAwareness StorageScaleUnit -ColumnIsolation PhysicalDisk
Jeśli dyski pojemności są dyskami półprzewodnikowymi (SSD), ustaw wartość -MediaType SSD zamiast i zmień wartość na -FriendlyName *OnSSD. Nie modyfikuj innych parametrów.
Napiwek
Sprawdź, czy Get-StorageTier pomyślnie utworzono warstwy.
Krok 2. Tworzenie zagnieżdżonych woluminów
Utwórz nowe woluminy przy użyciu New-Volume polecenia cmdlet .
Dublowanie dwukierunkowe zagnieżdżone
Aby użyć dublowania dwukierunkowego, odwołaj się do szablonu
NestedMirrorwarstwy i określ rozmiar. Na przykład:New-Volume -StoragePoolFriendlyName S2D* -FriendlyName Volume01 -StorageTierFriendlyNames NestedMirrorOnHDD -StorageTierSizes 500GBJeśli dyski pojemności są dyskami półprzewodnikowymi (SSD), zmień wartość
-StorageTierFriendlyNamesna*OnSSD.Parzystość przyspieszana przez dublowanie zagnieżdżone
Aby użyć parzystości przyspieszonej przez dublowanie, należy odwołać się zarówno do
NestedMirrorszablonów warstwy, jak iNestedParityokreślić dwa rozmiary, po jednym dla każdej części woluminu (najpierw dublowanie, sekunda parzystości). Aby na przykład utworzyć jeden wolumin 500 GB, który jest 20% zagnieżdżonym dublowaniem dwukierunkowym i 80% zagnieżdżonym parzystością, uruchom polecenie:New-Volume -StoragePoolFriendlyName S2D* -FriendlyName Volume02 -StorageTierFriendlyNames NestedMirrorOnHDD, NestedParityOnHDD -StorageTierSizes 100GB, 400GBJeśli dyski pojemności są dyskami półprzewodnikowymi (SSD), zmień wartość
-StorageTierFriendlyNamesna*OnSSD.
Krok 3. Kontynuuj w Centrum administracyjnym systemu Windows
Woluminy korzystające z odporności zagnieżdżonej są wyświetlane w Centrum administracyjnym systemu Windows z przezroczystym etykietowaniem, jak na poniższym zrzucie ekranu. Po ich utworzeniu możesz zarządzać nimi i monitorować je za pomocą centrum administracyjnego systemu Windows, podobnie jak w przypadku dowolnego innego woluminu w usłudze Miejsca do magazynowania Direct.

Opcjonalnie: Rozszerzanie na dyski pamięci podręcznej
W przypadku ustawień domyślnych zagnieżdżone odporność chroni przed utratą wielu dysków pojemności w tym samym czasie lub jednym serwerem i jednym dyskiem pojemności w tym samym czasie. Aby rozszerzyć tę ochronę na dyski pamięci podręcznej, należy wziąć pod uwagę inne kwestie: ponieważ dyski pamięci podręcznej często zapewniają buforowanie odczytu i zapisu dla wielu dysków pojemności, jedynym sposobem zapewnienia, że można tolerować utratę dysku pamięci podręcznej, gdy drugi serwer nie działa, to nie buforowanie zapisów, ale ma to wpływ na wydajność.
Aby rozwiązać ten scenariusz, Miejsca do magazynowania Direct oferuje opcję automatycznego wyłączania buforowania zapisu, gdy jeden serwer w klastrze dwóch serwerów nie działa, a następnie ponownie włącz buforowanie zapisu po utworzeniu kopii zapasowej serwera. Aby umożliwić rutynowe ponowne uruchamianie bez wpływu na wydajność, buforowanie zapisu nie jest wyłączone, dopóki serwer nie zostanie wyłączony przez 30 minut. Po wyłączeniu buforowania zapisu zawartość pamięci podręcznej zapisu jest zapisywana na urządzeniach pojemnościowych. Po tym serwer może tolerować nieudane urządzenie pamięci podręcznej na serwerze online, choć odczyty z pamięci podręcznej mogą być opóźnione lub kończą się niepowodzeniem, jeśli urządzenie pamięci podręcznej ulegnie awarii.
Uwaga
W przypadku całego systemu fizycznego pamięci podręcznej (pojedynczego typu nośnika) nie trzeba uwzględniać automatycznego wyłączania buforowania zapisu, gdy jeden serwer w klastrze z dwoma serwerami nie działa. Należy wziąć pod uwagę tylko pamięć podręczną warstwy magistrali magazynu (SBL), która jest wymagana tylko w przypadku korzystania z dysków HDD.
(Opcjonalnie) Aby automatycznie wyłączyć buforowanie zapisu, gdy jeden serwer w klastrze dwóch serwerów nie działa, uruchom program PowerShell jako administrator i uruchom polecenie:
Get-StorageSubSystem Cluster* | Set-StorageHealthSetting -Name "System.Storage.NestedResiliency.DisableWriteCacheOnNodeDown.Enabled" -Value "True"
Po ustawieniu wartości True zachowanie pamięci podręcznej jest następujące:
| Sytuacja | Zachowanie pamięci podręcznej | Czy można tolerować utratę dysku pamięci podręcznej? |
|---|---|---|
| Oba serwery są w górę | Operacje odczytu i zapisu w pamięci podręcznej, pełna wydajność | Tak |
| Serwer w dół, pierwsze 30 minut | Operacje odczytu i zapisu w pamięci podręcznej, pełna wydajność | Nie (tymczasowo) |
| Po pierwszych 30 minutach | Tylko odczyty pamięci podręcznej, wydajność, której dotyczy problem | Tak (po zapisaniu pamięci podręcznej na dyskach pojemności) |
Następne kroki
Aby zapoznać się z powiązanymi tematami i innymi zadaniami zarządzania magazynem, zobacz również: