Samouczek: używanie usługi Azure Cache for Redis jako pamięci podręcznej semantycznej
W tym samouczku użyjesz usługi Azure Cache for Redis jako semantycznej pamięci podręcznej z opartym na sztucznej inteligencji modelem dużego języka (LLM). Usługa Azure OpenAI Service służy do generowania odpowiedzi LLM na zapytania i buforowania tych odpowiedzi przy użyciu usługi Azure Cache for Redis, zapewniając szybsze odpowiedzi i obniżając koszty.
Ponieważ usługa Azure Cache for Redis oferuje wbudowaną funkcję wyszukiwania wektorowego, można również wykonywać buforowanie semantyczne. Możesz zwrócić buforowane odpowiedzi dla identycznych zapytań, a także zapytań, które są podobne, nawet jeśli tekst nie jest taki sam.
Z tego samouczka dowiesz się, jak wykonywać następujące czynności:
- Tworzenie wystąpienia usługi Azure Cache for Redis skonfigurowanego na potrzeby buforowania semantycznego
- Użyj innych popularnych bibliotek języka Python w języku LangChain.
- Użyj usługi Azure OpenAI, aby wygenerować tekst z modeli sztucznej inteligencji i buforować wyniki.
- Zapoznaj się z korzyściami z używania buforowania w usłudze LLMs.
Ważne
Ten samouczek przeprowadzi Cię przez proces tworzenia notesu Jupyter Notebook. Możesz skorzystać z tego samouczka z plikiem kodu języka Python (.py) i uzyskać podobne wyniki, ale musisz dodać wszystkie bloki kodu w tym samouczku do .py pliku i wykonać je raz, aby wyświetlić wyniki. Innymi słowy, notesy Jupyter Notebook zapewniają wyniki pośrednie podczas wykonywania komórek, ale nie jest to zachowanie, którego należy oczekiwać podczas pracy w pliku kodu języka Python.
Ważne
Jeśli zamiast tego chcesz kontynuować pracę w ukończonym notesie Jupyter, pobierz plik notesu Jupyter o nazwie semanticcache.ipynb i zapisz go w nowym folderze semanticcache .
Wymagania wstępne
Subskrypcja platformy Azure — utwórz bezpłatnie
Dostęp udzielony usłudze Azure OpenAI w żądanej subskrypcji platformy Azure Obecnie musisz ubiegać się o dostęp do usługi Azure OpenAI. Możesz ubiegać się o dostęp do usługi Azure OpenAI, wypełniając formularz pod adresem https://aka.ms/oai/access.
Notesy Jupyter (opcjonalnie)
Zasób usługi Azure OpenAI z wdrożonym modelem ada-002 (wersja 2) i gpt-35-turbo-instruct . Te modele są obecnie dostępne tylko w niektórych regionach. Zapoznaj się z przewodnikiem wdrażania zasobów, aby uzyskać instrukcje dotyczące wdrażania modeli.
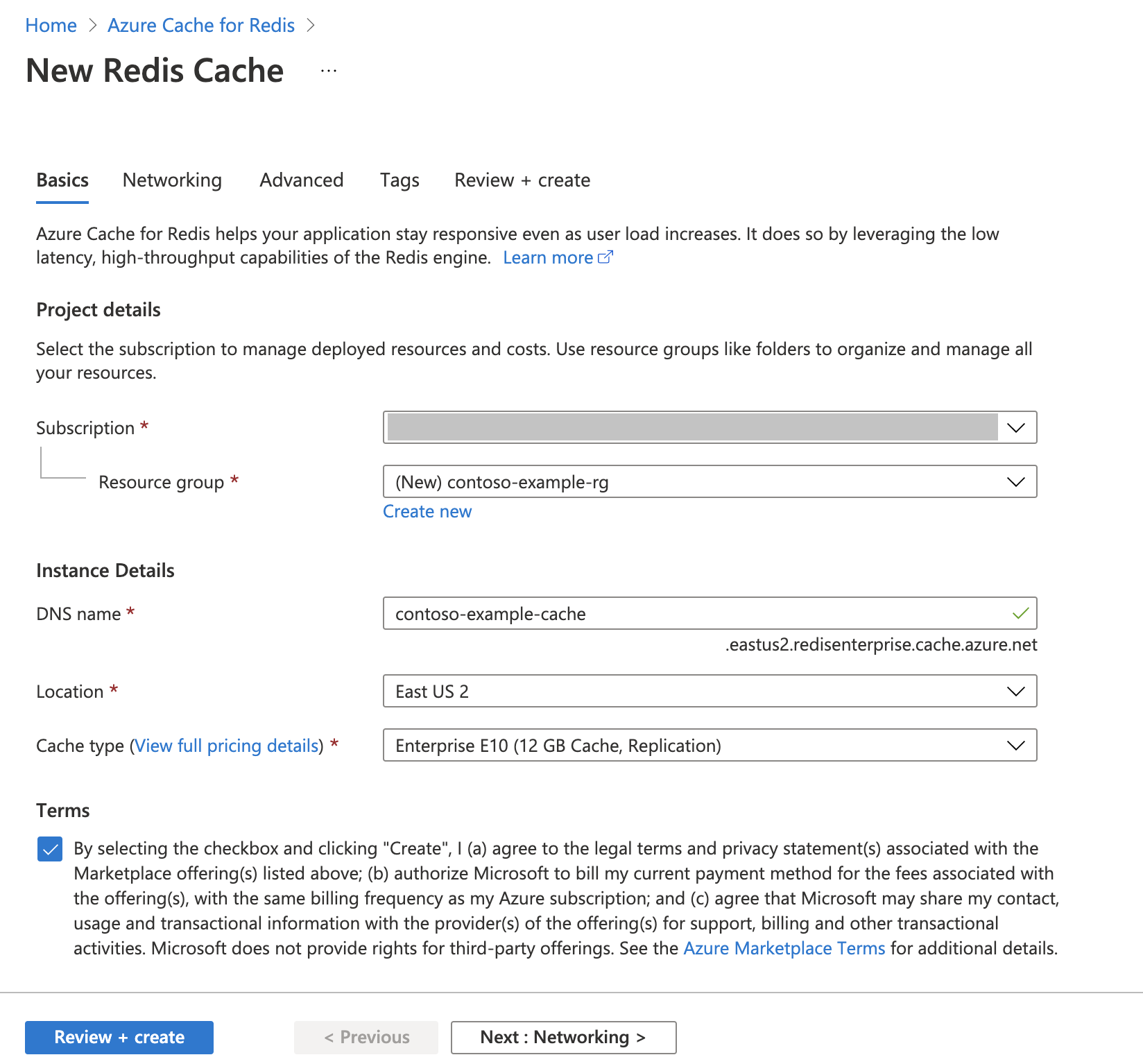
Tworzenie wystąpienia pamięci podręcznej Azure Cache for Redis
Postępuj zgodnie z przewodnikiem Szybki start: tworzenie pamięci podręcznej Redis Enterprise Cache . Na stronie Zaawansowane upewnij się, że dodano moduł RediSearch i wybrano zasady klastra przedsiębiorstwa. Wszystkie inne ustawienia mogą być zgodne z wartością domyślną opisaną w przewodniku Szybki start.
Utworzenie pamięci podręcznej zajmuje kilka minut. Możesz przejść do następnego kroku w międzyczasie.
Konfigurowanie środowiska projektowego
Utwórz folder na komputerze lokalnym o nazwie semanticcache w lokalizacji, w której zwykle zapisujesz projekty.
Utwórz nowy plik języka Python (tutorial.py) lub notes Jupyter (tutorial.ipynb) w folderze.
Zainstaluj wymagane pakiety języka Python:
pip install openai langchain redis tiktoken
Tworzenie modeli usługi Azure OpenAI
Upewnij się, że masz dwa modele wdrożone w zasobie usługi Azure OpenAI:
LlM, który udostępnia odpowiedzi tekstowe. Na potrzeby tego samouczka używamy modelu GPT-3.5-turbo-instruct .
Model osadzania, który konwertuje zapytania na wektory, aby umożliwić ich porównywanie z poprzednimi zapytaniami. Na potrzeby tego samouczka używamy modelu osadzania tekstu ada-002 (wersja 2 ).
Aby uzyskać bardziej szczegółowe instrukcje, zobacz Wdrażanie modelu . Zarejestruj nazwę wybraną dla każdego wdrożenia modelu.
Importowanie bibliotek i konfigurowanie informacji o połączeniu
Aby pomyślnie wykonać wywołanie usługi Azure OpenAI, potrzebujesz punktu końcowego i klucza. Potrzebujesz również punktu końcowego i klucza do nawiązania połączenia z usługą Azure Cache for Redis.
Przejdź do zasobu azure OpenAI w witrynie Azure Portal.
Znajdź punkt końcowy i klucze w sekcji Zarządzanie zasobami zasobu usługi Azure OpenAI. Skopiuj punkt końcowy i klucz dostępu, ponieważ potrzebujesz zarówno do uwierzytelniania wywołań interfejsu API. Przykładowy punkt końcowy to:
https://docs-test-001.openai.azure.com. Możesz użyć wartościKEY1lubKEY2.Przejdź do strony Przegląd zasobu usługi Azure Cache for Redis w witrynie Azure Portal. Skopiuj punkt końcowy.
Znajdź klucze dostępu w sekcji Ustawienia. Skopiuj klucz dostępu. Możesz użyć wartości
PrimarylubSecondary.Dodaj następujący kod do nowej komórki kodu:
# Code cell 2 import openai import redis import os import langchain from langchain.llms import AzureOpenAI from langchain.embeddings import AzureOpenAIEmbeddings from langchain.globals import set_llm_cache from langchain.cache import RedisSemanticCache import time AZURE_ENDPOINT=<your-openai-endpoint> API_KEY=<your-openai-key> API_VERSION="2023-05-15" LLM_DEPLOYMENT_NAME=<your-llm-model-name> LLM_MODEL_NAME="gpt-35-turbo-instruct" EMBEDDINGS_DEPLOYMENT_NAME=<your-embeddings-model-name> EMBEDDINGS_MODEL_NAME="text-embedding-ada-002" REDIS_ENDPOINT = <your-redis-endpoint> REDIS_PASSWORD = <your-redis-password>Zaktualizuj wartość
API_KEYiRESOURCE_ENDPOINTprzy użyciu wartości klucza i punktu końcowego z wdrożenia usługi Azure OpenAI.Ustaw
LLM_DEPLOYMENT_NAMEiEMBEDDINGS_DEPLOYMENT_NAMEna nazwę dwóch modeli wdrożonych w usłudze Azure OpenAI Service.Zaktualizuj
REDIS_ENDPOINTelement iREDIS_PASSWORDza pomocą wartości punktu końcowego i klucza z wystąpienia usługi Azure Cache for Redis.Ważne
Zdecydowanie zalecamy używanie zmiennych środowiskowych lub menedżera wpisów tajnych, takich jak usługa Azure Key Vault , aby przekazać informacje o kluczu interfejsu API, punkcie końcowym i nazwie wdrożenia. Te zmienne są ustawiane w postaci zwykłego tekstu dla uproszczenia.
Wykonaj komórkę kodu 2.
Inicjowanie modeli sztucznej inteligencji
Następnie zainicjujesz modele LLM i osadzasz modele
Dodaj następujący kod do nowej komórki kodu:
# Code cell 3 llm = AzureOpenAI( deployment_name=LLM_DEPLOYMENT_NAME, model_name="gpt-35-turbo-instruct", openai_api_key=API_KEY, azure_endpoint=AZURE_ENDPOINT, openai_api_version=API_VERSION, ) embeddings = AzureOpenAIEmbeddings( azure_deployment=EMBEDDINGS_DEPLOYMENT_NAME, model="text-embedding-ada-002", openai_api_key=API_KEY, azure_endpoint=AZURE_ENDPOINT, openai_api_version=API_VERSION )Wykonaj komórkę kodu 3.
Konfigurowanie usługi Redis jako semantycznej pamięci podręcznej
Następnie określ usługę Redis jako semantyczną pamięć podręczną dla usługi LLM.
Dodaj następujący kod do nowej komórki kodu:
# Code cell 4 redis_url = "rediss://:" + REDIS_PASSWORD + "@"+ REDIS_ENDPOINT set_llm_cache(RedisSemanticCache(redis_url = redis_url, embedding=embeddings, score_threshold=0.05))Ważne
Wartość parametru
score_thresholdokreśla, jak podobne dwa zapytania muszą być zwracane w pamięci podręcznej wyniku. Im mniejsza liczba, tym bardziej podobne są zapytania. Możesz obejść tę wartość, aby dostosować ją do aplikacji.Wykonaj komórkę kodu 4.
Wykonywanie zapytań i uzyskiwanie odpowiedzi z usługi LLM
Na koniec wykonaj zapytanie dotyczące usługi LLM, aby uzyskać odpowiedź wygenerowaną przez sztuczną inteligencję. Jeśli używasz notesu Jupyter, możesz dodać %%time w górnej części komórki, aby wyświetlić ilość czasu potrzebnego do wykonania kodu.
Dodaj następujący kod do nowej komórki kodu i wykonaj go:
# Code cell 5 %%time response = llm("Please write a poem about cute kittens.") print(response)Powinny zostać wyświetlone dane wyjściowe i wyjściowe podobne do następujących:
Fluffy balls of fur, With eyes so bright and pure, Kittens are a true delight, Bringing joy into our sight. With tiny paws and playful hearts, They chase and pounce, a work of art, Their innocence and curiosity, Fills our hearts with such serenity. Their soft meows and gentle purrs, Are like music to our ears, They curl up in our laps, And take the stress away in a snap. Their whiskers twitch, they're always ready, To explore and be adventurous and steady, With their tails held high, They're a sight to make us sigh. Their tiny faces, oh so sweet, With button noses and paw-sized feet, They're the epitome of cuteness, ... Cute kittens, a true blessing, In our hearts, they'll always be reigning. CPU times: total: 0 ns Wall time: 2.67 sW obiekcie
Wall timejest wyświetlana wartość 2,67 sekund. To, ile czasu rzeczywistego zajęło wysłanie zapytania do usługi LLM i w celu wygenerowania odpowiedzi przez moduł LLM.Wykonaj ponownie komórkę 5. Powinny zostać wyświetlone dokładnie te same dane wyjściowe, ale z mniejszym czasem ściany:
Fluffy balls of fur, With eyes so bright and pure, Kittens are a true delight, Bringing joy into our sight. With tiny paws and playful hearts, They chase and pounce, a work of art, Their innocence and curiosity, Fills our hearts with such serenity. Their soft meows and gentle purrs, Are like music to our ears, They curl up in our laps, And take the stress away in a snap. Their whiskers twitch, they're always ready, To explore and be adventurous and steady, With their tails held high, They're a sight to make us sigh. Their tiny faces, oh so sweet, With button noses and paw-sized feet, They're the epitome of cuteness, ... Cute kittens, a true blessing, In our hearts, they'll always be reigning. CPU times: total: 0 ns Wall time: 575 msCzas ściany wydaje się skrócić o współczynnik pięciu- aż do 575 milisekund.
Zmień zapytanie z
Please write a poem about cute kittensnaWrite a poem about cute kittensi ponownie uruchom komórkę 5. Powinny zostać wyświetlone dokładnie te same dane wyjściowe i krótszy czas ściany niż oryginalne zapytanie. Mimo że zapytanie uległo zmianie, semantyczne znaczenie zapytania pozostało takie samo, więc zwracane były te same buforowane dane wyjściowe. Jest to zaleta buforowania semantycznego!
Zmienianie progu podobieństwa
Spróbuj uruchomić podobne zapytanie o innym znaczeniu, na przykład
Please write a poem about cute puppies. Zwróć uwagę, że buforowany wynik jest również zwracany tutaj. Semantyczne znaczenie słowa jest wystarczająco blisko słowapuppieskittens, że zwracany jest buforowany wynik.Próg podobieństwa można zmodyfikować, aby określić, kiedy semantyczna pamięć podręczna powinna zwrócić buforowany wynik i kiedy powinna zwrócić nowe dane wyjściowe z usługi LLM. W komórce kodu 4 zmień wartość
score_thresholdz0.05na0.01:# Code cell 4 redis_url = "rediss://:" + REDIS_PASSWORD + "@"+ REDIS_ENDPOINT set_llm_cache(RedisSemanticCache(redis_url = redis_url, embedding=embeddings, score_threshold=0.01))Spróbuj ponownie wykonać zapytanie
Please write a poem about cute puppies. Powinny zostać wyświetlone nowe dane wyjściowe specyficzne dla szczeniąt:Oh, little balls of fluff and fur With wagging tails and tiny paws Puppies, oh puppies, so pure The epitome of cuteness, no flaws With big round eyes that melt our hearts And floppy ears that bounce with glee Their playful antics, like works of art They bring joy to all they see Their soft, warm bodies, so cuddly As they curl up in our laps Their gentle kisses, so lovingly Like tiny, wet, puppy taps Their clumsy steps and wobbly walks As they explore the world anew Their curiosity, like a ticking clock Always eager to learn and pursue Their little barks and yips so sweet Fill our days with endless delight Their unconditional love, so complete ... For they bring us love and laughter, year after year Our cute little pups, in every way. CPU times: total: 15.6 ms Wall time: 4.3 sPrawdopodobnie trzeba dostosować próg podobieństwa na podstawie aplikacji, aby upewnić się, że podczas określania zapytań do pamięci podręcznej jest używana właściwa czułość.
Czyszczenie zasobów
Jeśli chcesz nadal korzystać z zasobów utworzonych w tym artykule, zachowaj grupę zasobów.
W przeciwnym razie, jeśli skończysz z zasobami, możesz usunąć utworzoną grupę zasobów platformy Azure, aby uniknąć naliczania opłat.
Ważne
Usunięcie grupy zasobów jest nieodwracalne. Jeśli usuniesz grupę zasobów, wszystkie zawarte w niej zasoby zostaną trwale usunięte. Uważaj, aby nie usunąć przypadkowo niewłaściwych zasobów lub grupy zasobów. Jeśli zasoby zostały utworzone w istniejącej grupie zasobów zawierającej zasoby, które chcesz zachować, możesz usunąć każdy zasób indywidualnie zamiast usuwać grupę zasobów.
Aby usunąć grupę zasobów
Zaloguj się do witryny Azure Portal, a następnie wybierz pozycję Grupy zasobów.
Wybierz grupę zasobów, którą chcesz usunąć.
Jeśli istnieje wiele grup zasobów, użyj pola Filtruj dla dowolnego pola... wpisz nazwę grupy zasobów utworzonej dla tego artykułu. Wybierz grupę zasobów na liście wyników.
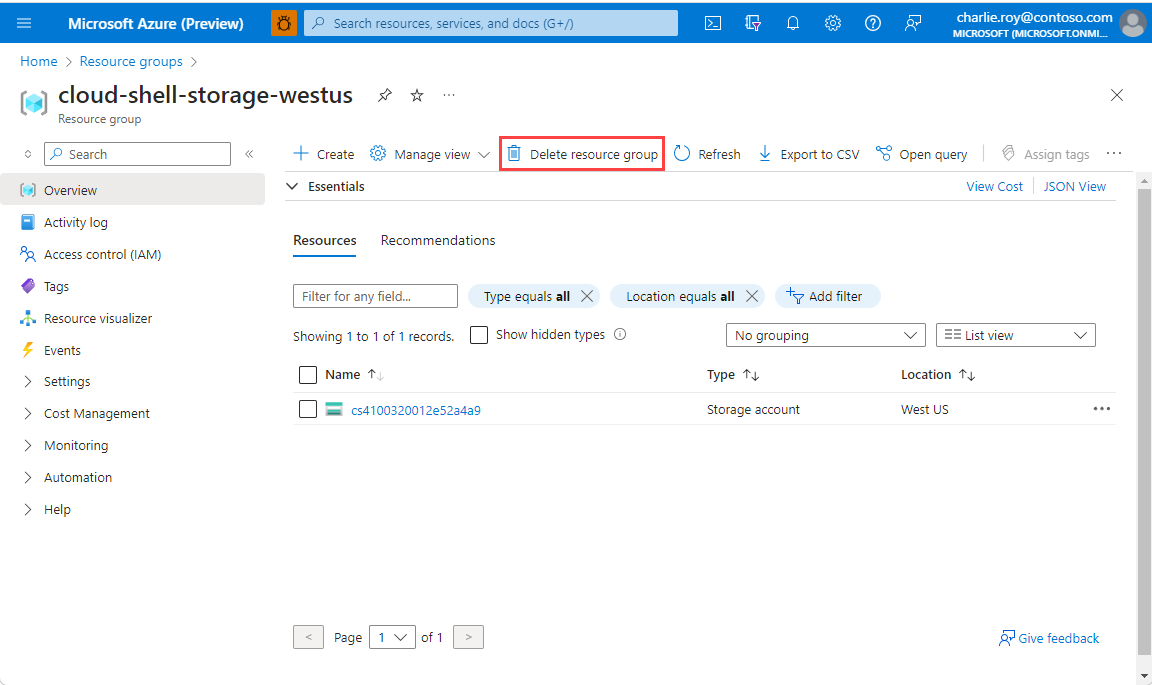
Wybierz pozycję Usuń grupę zasobów.
Zobaczysz prośbę o potwierdzenie usunięcia grupy zasobów. Wpisz nazwę grupy zasobów w celu potwierdzenia, a następnie wybierz pozycję Usuń.
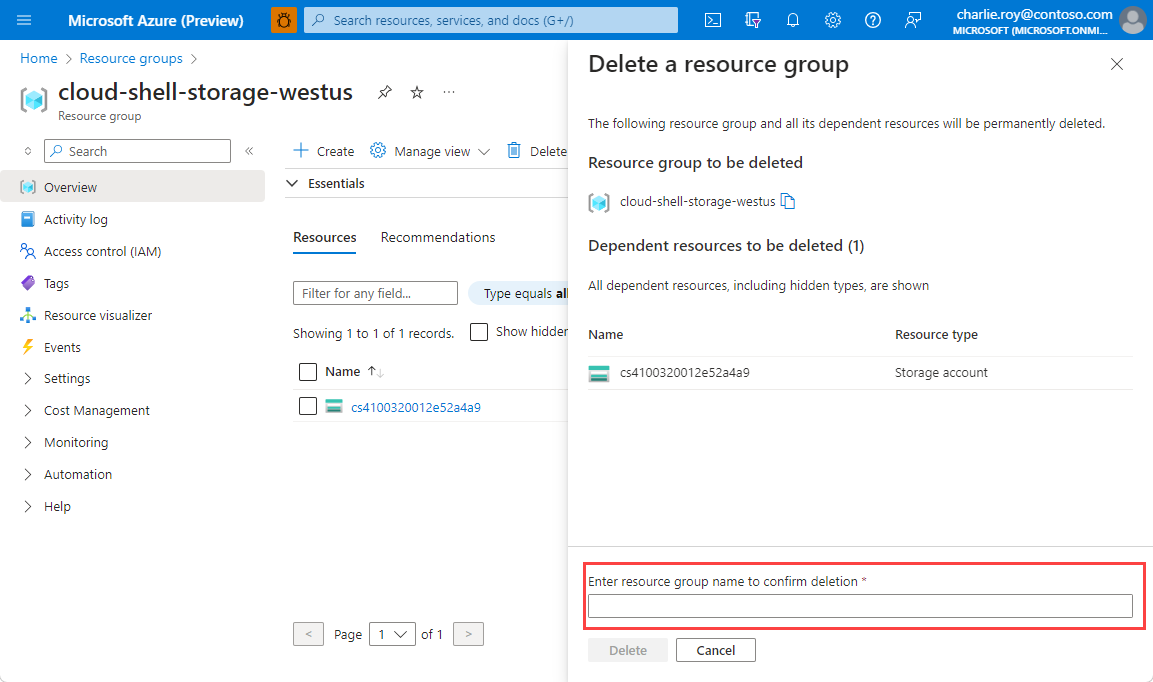
Po krótkim czasie grupa zasobów i wszystkie jej zasoby zostaną usunięte.
Powiązana zawartość
- Dowiedz się więcej o usłudze Azure Cache for Redis
- Dowiedz się więcej o możliwościach wyszukiwania wektorów usługi Azure Cache for Redis
- Samouczek: korzystanie z wyszukiwania podobieństwa wektorów w usłudze Azure Cache for Redis
- Przeczytaj, jak utworzyć aplikację obsługiwaną przez sztuczną inteligencję przy użyciu interfejsu OpenAI i usługi Redis
- Tworzenie aplikacji pytań i odpowiedzi za pomocą semantycznych odpowiedzi