Samouczek: przeprowadzanie wyszukiwania podobieństwa wektorów na potrzeby osadzania w usłudze Azure OpenAI przy użyciu usługi Azure Cache for Redis
W tym samouczku omówisz podstawowy przypadek użycia wyszukiwania wektorów podobnych. Użyjesz osadzeń generowanych przez usługę Azure OpenAI Service i wbudowanych funkcji wyszukiwania wektorowego w warstwie Enterprise usługi Azure Cache for Redis, aby wykonać zapytanie o zestaw danych filmów w celu znalezienia najbardziej odpowiedniego dopasowania.
Samouczek używa zestawu danych Wikipedia Movie Plots, który zawiera opisy fabuły ponad 35.000 filmów z Wikipedii obejmujące lata 1901-2017. Zestaw danych zawiera podsumowanie fabuły dla każdego filmu oraz metadane, takie jak rok, w jakim film został wydany, reżyserzy, główna obsada i gatunek. Wykonasz kroki samouczka, aby wygenerować osadzanie na podstawie podsumowania wykresu i użyć innych metadanych do uruchamiania zapytań hybrydowych.
Z tego samouczka dowiesz się, jak wykonywać następujące czynności:
- Tworzenie wystąpienia usługi Azure Cache for Redis skonfigurowanego do wyszukiwania wektorowego
- Zainstaluj usługę Azure OpenAI i inne wymagane biblioteki języka Python.
- Pobierz zestaw danych filmu i przygotuj go do analizy.
- Użyj modelu osadzania tekstu-ada-002 (wersja 2), aby wygenerować osadzanie.
- Tworzenie indeksu wektorowego w usłudze Azure Cache for Redis
- Użyj podobieństwa cosinus, aby sklasyfikować wyniki wyszukiwania.
- Użyj funkcji zapytań hybrydowych za pośrednictwem narzędzia RediSearch , aby wstępnie przefiltrować dane i zwiększyć możliwości wyszukiwania wektorów.
Ważne
Ten samouczek przeprowadzi Cię przez proces tworzenia notesu Jupyter Notebook. Możesz skorzystać z tego samouczka z plikiem kodu języka Python (.py) i uzyskać podobne wyniki, ale musisz dodać wszystkie bloki kodu w tym samouczku do .py pliku i wykonać je raz, aby wyświetlić wyniki. Innymi słowy, notesy Jupyter Notebook zapewniają wyniki pośrednie podczas wykonywania komórek, ale nie jest to zachowanie, którego należy oczekiwać podczas pracy w pliku kodu języka Python.
Ważne
Jeśli zamiast tego chcesz kontynuować pracę w ukończonym notesie Jupyter, pobierz plik notesu Jupyter o nazwie tutorial.ipynb i zapisz go w nowym folderze redis-vector .
Wymagania wstępne
- Subskrypcja platformy Azure — utwórz bezpłatnie
- Dostęp udzielony usłudze Azure OpenAI w żądanej subskrypcji platformy Azure Obecnie musisz ubiegać się o dostęp do usługi Azure OpenAI. Możesz ubiegać się o dostęp do usługi Azure OpenAI, wypełniając formularz pod adresem https://aka.ms/oai/access.
- Środowisko Python w wersji 3.7.1 lub nowszej
- Notesy Jupyter (opcjonalnie)
- Zasób usługi Azure OpenAI z wdrożonym modelem osadzania tekstu ada-002 (wersja 2). Ten model jest obecnie dostępny tylko w niektórych regionach. Zapoznaj się z przewodnikiem wdrażania zasobów, aby uzyskać instrukcje dotyczące wdrażania modelu.
Tworzenie wystąpienia usługi Azure Cache for Redis
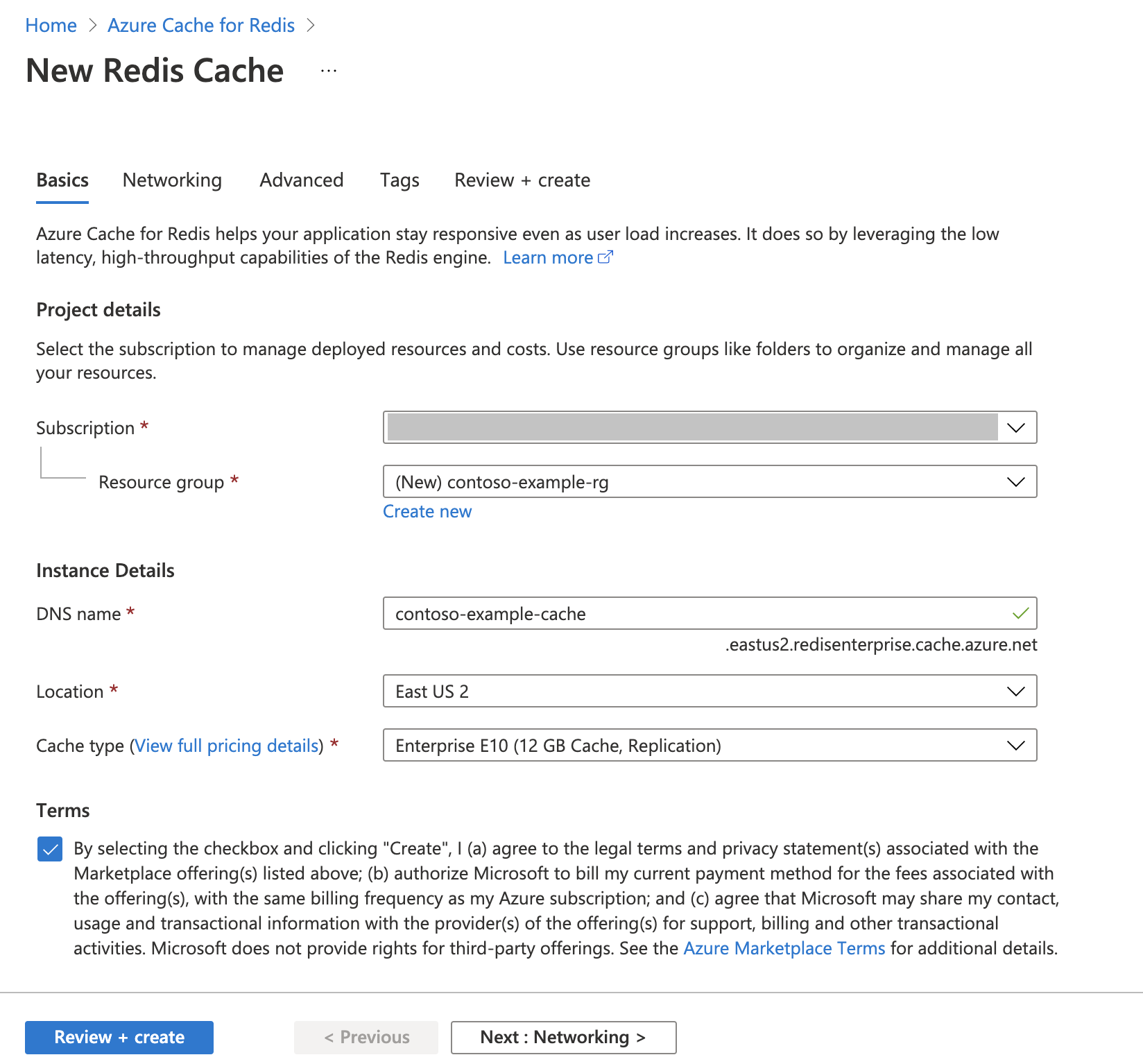
Postępuj zgodnie z przewodnikiem Szybki start: tworzenie pamięci podręcznej Redis Enterprise Cache . Na stronie Zaawansowane upewnij się, że dodano moduł RediSearch i wybrano zasady klastra przedsiębiorstwa. Wszystkie inne ustawienia mogą być zgodne z wartością domyślną opisaną w przewodniku Szybki start.
Utworzenie pamięci podręcznej zajmuje kilka minut. Możesz przejść do następnego kroku w międzyczasie.
Konfigurowanie środowiska projektowego
Utwórz folder na komputerze lokalnym o nazwie redis-vector w lokalizacji, w której zazwyczaj zapisujesz projekty.
Utwórz nowy plik języka Python (tutorial.py) lub notes Jupyter (tutorial.ipynb) w folderze.
Zainstaluj wymagane pakiety języka Python:
pip install "openai==1.6.1" num2words matplotlib plotly scipy scikit-learn pandas tiktoken redis langchain
Pobieranie zestawu danych
W przeglądarce internetowej przejdź do https://www.kaggle.com/datasets/jrobischon/wikipedia-movie-plotsadresu .
Zaloguj się lub zarejestruj się przy użyciu narzędzia Kaggle. Rejestracja jest wymagana do pobrania pliku.
Wybierz link Pobierz w witrynie Kaggle, aby pobrać plik archive.zip.
Wyodrębnij plik archive.zip i przenieś wiki_movie_plots_deduped.csv do folderu redis-vector .
Importowanie bibliotek i konfigurowanie informacji o połączeniu
Aby pomyślnie wykonać wywołanie usługi Azure OpenAI, potrzebujesz punktu końcowego i klucza. Potrzebujesz również punktu końcowego i klucza do nawiązania połączenia z usługą Azure Cache for Redis.
Przejdź do zasobu azure OpenAI w witrynie Azure Portal.
Znajdź punkt końcowy i klucze w sekcji Zarządzanie zasobami. Skopiuj punkt końcowy i klucz dostępu, ponieważ będzie potrzebny zarówno do uwierzytelniania wywołań interfejsu API. Przykładowy punkt końcowy to:
https://docs-test-001.openai.azure.com. Możesz użyć wartościKEY1lubKEY2.Przejdź do strony Przegląd zasobu usługi Azure Cache for Redis w witrynie Azure Portal. Skopiuj punkt końcowy.
Znajdź klucze dostępu w sekcji Ustawienia. Skopiuj klucz dostępu. Możesz użyć wartości
PrimarylubSecondary.Dodaj następujący kod do nowej komórki kodu:
# Code cell 2 import re from num2words import num2words import os import pandas as pd import tiktoken from typing import List from langchain.embeddings import AzureOpenAIEmbeddings from langchain.vectorstores.redis import Redis as RedisVectorStore from langchain.document_loaders import DataFrameLoader API_KEY = "<your-azure-openai-key>" RESOURCE_ENDPOINT = "<your-azure-openai-endpoint>" DEPLOYMENT_NAME = "<name-of-your-model-deployment>" MODEL_NAME = "text-embedding-ada-002" REDIS_ENDPOINT = "<your-azure-redis-endpoint>" REDIS_PASSWORD = "<your-azure-redis-password>"Zaktualizuj wartość
API_KEYiRESOURCE_ENDPOINTprzy użyciu wartości klucza i punktu końcowego z wdrożenia usługi Azure OpenAI.DEPLOYMENT_NAMEpowinna być ustawiona na nazwę wdrożenia przy użyciutext-embedding-ada-002 (Version 2)modelu osadzania iMODEL_NAMEpowinna być używanym konkretnym modelem osadzania.Zaktualizuj
REDIS_ENDPOINTelement iREDIS_PASSWORDza pomocą wartości punktu końcowego i klucza z wystąpienia usługi Azure Cache for Redis.Ważne
Zdecydowanie zalecamy używanie zmiennych środowiskowych lub menedżera wpisów tajnych, takich jak usługa Azure Key Vault , aby przekazać informacje o kluczu interfejsu API, punkcie końcowym i nazwie wdrożenia. Te zmienne są ustawiane w postaci zwykłego tekstu dla uproszczenia.
Wykonaj komórkę kodu 2.
Importowanie zestawu danych do biblioteki pandas i przetwarzanie danych
Następnie odczytasz plik csv do ramki danych biblioteki pandas.
Dodaj następujący kod do nowej komórki kodu:
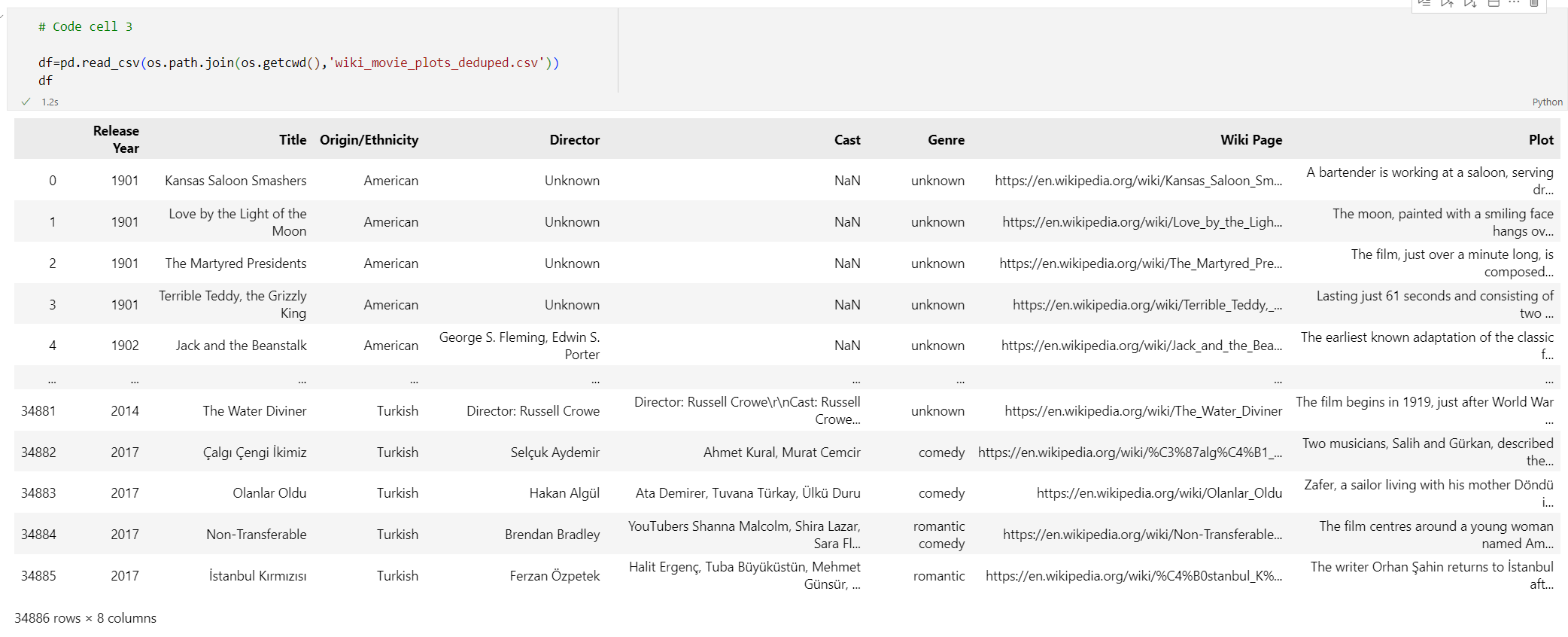
# Code cell 3 df=pd.read_csv(os.path.join(os.getcwd(),'wiki_movie_plots_deduped.csv')) dfWykonaj komórkę kodu 3. Powinny zostać wyświetlone następujące dane wyjściowe:
Następnie przetwórz dane, dodając
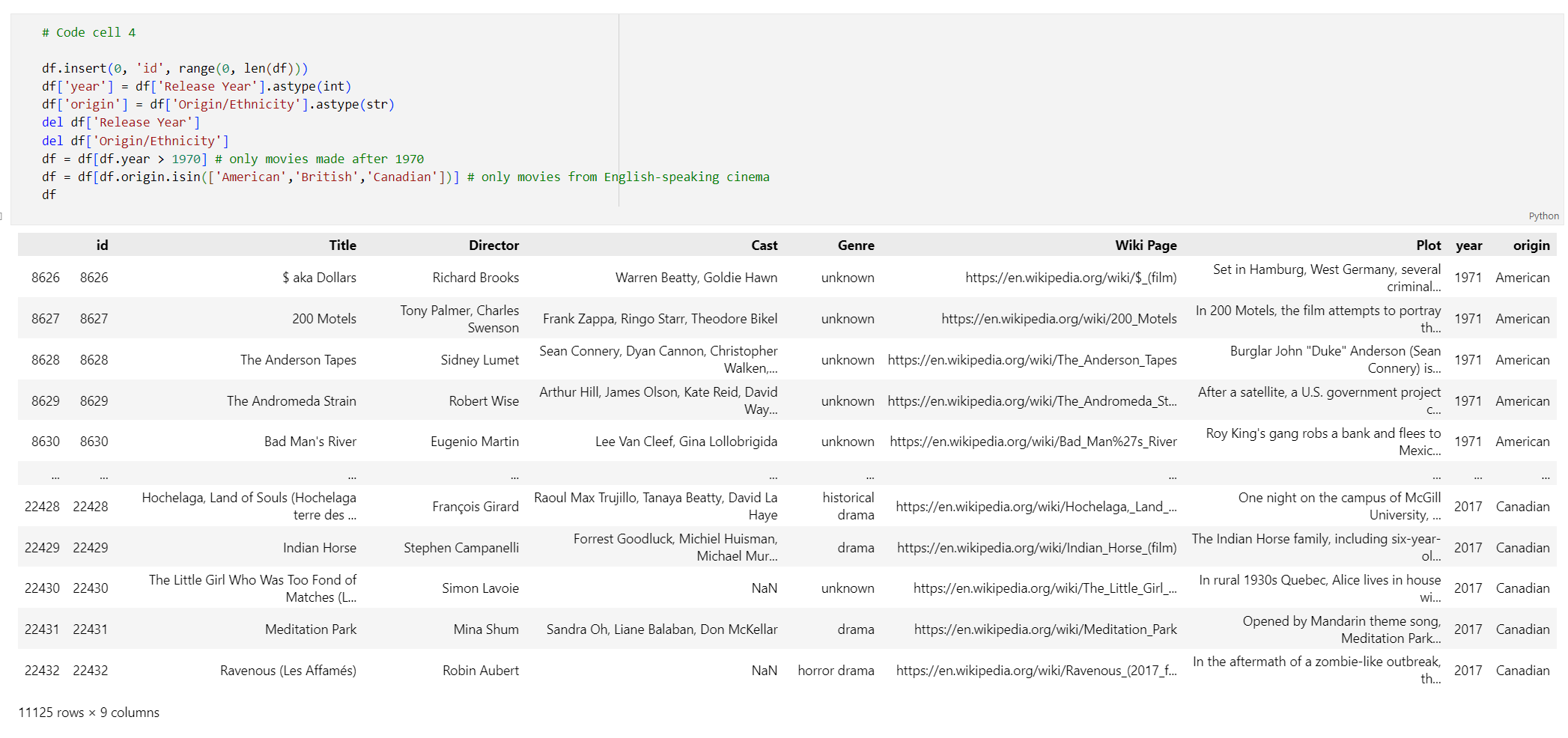
idindeks, usuwając spacje z tytułów kolumn i filtrując filmy, aby robić tylko filmy wykonane po 1970 roku i z krajów lub regionów języka angielskiego. Ten krok filtrowania zmniejsza liczbę filmów w zestawie danych, co zmniejsza koszt i czas wymagany do wygenerowania osadzania. Możesz zmienić lub usunąć parametry filtru na podstawie preferencji.Aby przefiltrować dane, dodaj następujący kod do nowej komórki kodu:
# Code cell 4 df.insert(0, 'id', range(0, len(df))) df['year'] = df['Release Year'].astype(int) df['origin'] = df['Origin/Ethnicity'].astype(str) del df['Release Year'] del df['Origin/Ethnicity'] df = df[df.year > 1970] # only movies made after 1970 df = df[df.origin.isin(['American','British','Canadian'])] # only movies from English-speaking cinema dfWykonaj komórkę kodu 4. Powinny zostać wyświetlone następujące wyniki:
Utwórz funkcję w celu oczyszczenia danych przez usunięcie białych znaków i znaków interpunkcyjnych, a następnie użyj jej względem ramki danych zawierającej wykres.
Dodaj następujący kod do nowej komórki kodu i wykonaj go:
# Code cell 5 pd.options.mode.chained_assignment = None # s is input text def normalize_text(s, sep_token = " \n "): s = re.sub(r'\s+', ' ', s).strip() s = re.sub(r". ,","",s) # remove all instances of multiple spaces s = s.replace("..",".") s = s.replace(". .",".") s = s.replace("\n", "") s = s.strip() return s df['Plot']= df['Plot'].apply(lambda x : normalize_text(x))Na koniec usuń wszystkie wpisy zawierające opisy wykresów, które są zbyt długie dla modelu osadzania. (Innymi słowy, wymagają one więcej tokenów niż limit tokenu 8192). a następnie oblicz liczbę tokenów wymaganych do wygenerowania osadzania. Ma to również wpływ na ceny generacji osadzania.
Dodaj następujący kod do nowej komórki kodu:
# Code cell 6 tokenizer = tiktoken.get_encoding("cl100k_base") df['n_tokens'] = df["Plot"].apply(lambda x: len(tokenizer.encode(x))) df = df[df.n_tokens<8192] print('Number of movies: ' + str(len(df))) print('Number of tokens required:' + str(df['n_tokens'].sum()))Wykonaj komórkę kodu 6. Powinny być widoczne następujące dane wyjściowe:
Number of movies: 11125 Number of tokens required:7044844Ważne
Zapoznaj się z cennikiem usługi Azure OpenAI Service, aby obliczyć koszt generowania osadzonych elementów na podstawie wymaganej liczby tokenów.


Ładowanie ramki danych do biblioteki LangChain
Załaduj ramkę danych do biblioteki LangChain przy użyciu DataFrameLoader klasy . Gdy dane są w dokumentach LangChain, znacznie łatwiej jest używać bibliotek LangChain do generowania osadzonych i przeprowadzania wyszukiwań podobieństw. Ustaw wartość Wykres jako page_content_column wartość , aby osadzanie było generowane w tej kolumnie.
Dodaj następujący kod do nowej komórki kodu i wykonaj go:
# Code cell 7 loader = DataFrameLoader(df, page_content_column="Plot" ) movie_list = loader.load()
Generowanie osadzania i ładowanie ich do usługi Redis
Teraz, gdy dane zostały przefiltrowane i załadowane do aplikacji LangChain, utworzysz osadzanie, aby można było wykonywać zapytania dotyczące wykresu dla każdego filmu. Poniższy kod konfiguruje usługę Azure OpenAI, generuje osadzanie i ładuje wektory osadzania do usługi Azure Cache for Redis.
Dodaj następujący kod nowej komórki kodu:
# Code cell 8 embedding = AzureOpenAIEmbeddings( deployment=DEPLOYMENT_NAME, model=MODEL_NAME, azure_endpoint=RESOURCE_ENDPOINT, openai_api_type="azure", openai_api_key=API_KEY, openai_api_version="2023-05-15", show_progress_bar=True, chunk_size=16 # current limit with Azure OpenAI service. This will likely increase in the future. ) # name of the Redis search index to create index_name = "movieindex" # create a connection string for the Redis Vector Store. Uses Redis-py format: https://redis-py.readthedocs.io/en/stable/connections.html#redis.Redis.from_url # This example assumes TLS is enabled. If not, use "redis://" instead of "rediss:// redis_url = "rediss://:" + REDIS_PASSWORD + "@"+ REDIS_ENDPOINT # create and load redis with documents vectorstore = RedisVectorStore.from_documents( documents=movie_list, embedding=embedding, index_name=index_name, redis_url=redis_url ) # save index schema so you can reload in the future without re-generating embeddings vectorstore.write_schema("redis_schema.yaml")Wykonaj komórkę kodu 8. Może to potrwać ponad 30 minut. Zostanie
redis_schema.yamlrównież wygenerowany plik. Ten plik jest przydatny, jeśli chcesz nawiązać połączenie z indeksem w wystąpieniu usługi Azure Cache for Redis bez ponownego generowania osadzania.
Ważne
Szybkość generowania osadzania zależy od limitu przydziału dostępnego dla modelu Azure OpenAI. W przypadku limitu przydziału 240 000 tokenów na minutę przetwarzanie tokenów 7M w zestawie danych potrwa około 30 minut.
Uruchamianie zapytań wyszukiwania wektorowego
Teraz, gdy zestaw danych, interfejs API usługi Azure OpenAI i wystąpienie usługi Redis zostały skonfigurowane, możesz wyszukiwać przy użyciu wektorów. W tym przykładzie zwracane są 10 pierwszych wyników dla danego zapytania.
Dodaj następujący kod do pliku kodu w języku Python:
# Code cell 9 query = "Spaceships, aliens, and heroes saving America" results = vectorstore.similarity_search_with_score(query, k=10) for i, j in enumerate(results): movie_title = str(results[i][0].metadata['Title']) similarity_score = str(round((1 - results[i][1]),4)) print(movie_title + ' (Score: ' + similarity_score + ')')Wykonaj komórkę kodu 9. Powinny zostać wyświetlone następujące dane wyjściowe:
Independence Day (Score: 0.8348) The Flying Machine (Score: 0.8332) Remote Control (Score: 0.8301) Bravestarr: The Legend (Score: 0.83) Xenogenesis (Score: 0.8291) Invaders from Mars (Score: 0.8291) Apocalypse Earth (Score: 0.8287) Invasion from Inner Earth (Score: 0.8287) Thru the Moebius Strip (Score: 0.8283) Solar Crisis (Score: 0.828)Wynik podobieństwa jest zwracany wraz z porządkowym rankingiem filmów według podobieństwa. Zwróć uwagę, że bardziej szczegółowe zapytania mają wyniki podobieństwa zmniejszają się szybciej na liście.
Wyszukiwanie hybrydowe
Ponieważ usługa RediSearch oferuje również rozbudowane funkcje wyszukiwania na podstawie wyszukiwania wektorowego, można filtrować wyniki według metadanych w zestawie danych, takich jak gatunek filmowy, obsada, rok wydania lub reżyser. W tym przypadku filtruj na podstawie gatunku
comedy.Dodaj następujący kod do nowej komórki kodu:
# Code cell 10 from langchain.vectorstores.redis import RedisText query = "Spaceships, aliens, and heroes saving America" genre_filter = RedisText("Genre") == "comedy" results = vectorstore.similarity_search_with_score(query, filter=genre_filter, k=10) for i, j in enumerate(results): movie_title = str(results[i][0].metadata['Title']) similarity_score = str(round((1 - results[i][1]),4)) print(movie_title + ' (Score: ' + similarity_score + ')')Wykonaj komórkę kodu 10. Powinny zostać wyświetlone następujące dane wyjściowe:
Remote Control (Score: 0.8301) Meet Dave (Score: 0.8236) Elf-Man (Score: 0.8208) Fifty/Fifty (Score: 0.8167) Mars Attacks! (Score: 0.8165) Strange Invaders (Score: 0.8143) Amanda and the Alien (Score: 0.8136) Suburban Commando (Score: 0.8129) Coneheads (Score: 0.8129) Morons from Outer Space (Score: 0.8121)
Dzięki usłudze Azure Cache for Redis i usłudze Azure OpenAI Service możesz użyć osadzania i wyszukiwania wektorowego, aby dodać zaawansowane możliwości wyszukiwania do aplikacji.
Czyszczenie zasobów
Jeśli chcesz nadal korzystać z zasobów utworzonych w tym artykule, zachowaj grupę zasobów.
W przeciwnym razie, jeśli skończysz z zasobami, możesz usunąć utworzoną grupę zasobów platformy Azure, aby uniknąć naliczania opłat.
Ważne
Usunięcie grupy zasobów jest nieodwracalne. Jeśli usuniesz grupę zasobów, wszystkie zawarte w niej zasoby zostaną trwale usunięte. Uważaj, aby nie usunąć przypadkowo niewłaściwych zasobów lub grupy zasobów. Jeśli zasoby zostały utworzone w istniejącej grupie zasobów zawierającej zasoby, które chcesz zachować, możesz usunąć każdy zasób indywidualnie zamiast usuwać grupę zasobów.
Aby usunąć grupę zasobów
Zaloguj się do witryny Azure Portal, a następnie wybierz pozycję Grupy zasobów.
Wybierz grupę zasobów, którą chcesz usunąć.
Jeśli istnieje wiele grup zasobów, użyj pola Filtruj dla dowolnego pola... wpisz nazwę grupy zasobów utworzonej dla tego artykułu. Wybierz grupę zasobów na liście wyników.
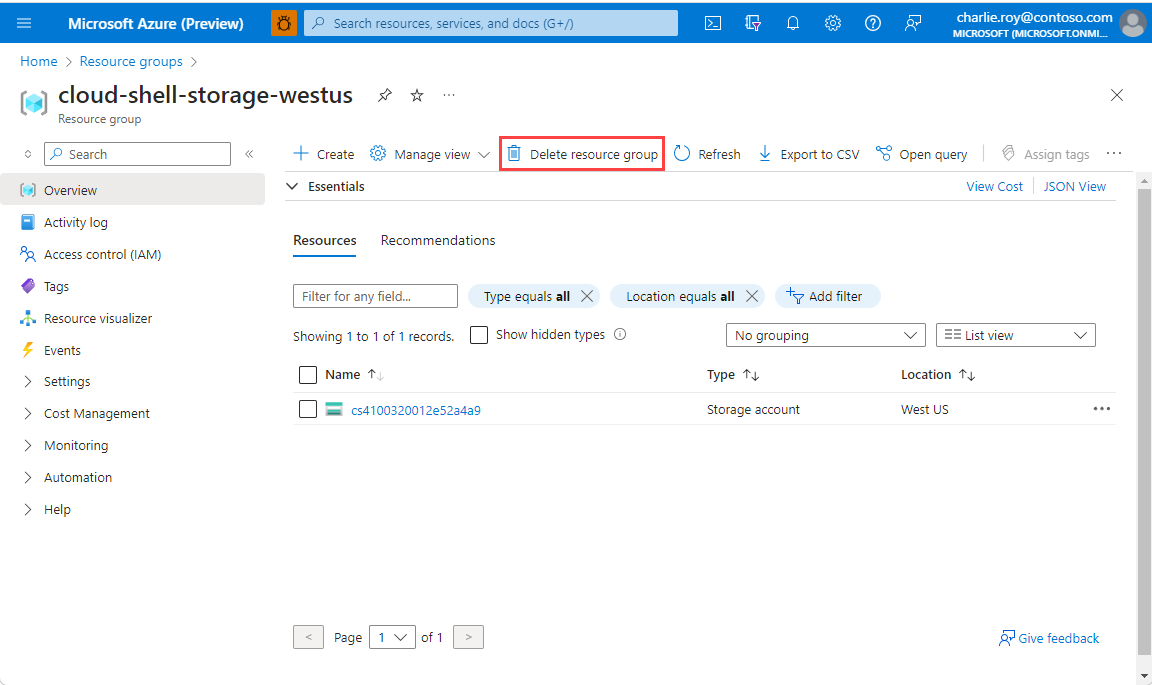
Wybierz pozycję Usuń grupę zasobów.
Zobaczysz prośbę o potwierdzenie usunięcia grupy zasobów. Wpisz nazwę grupy zasobów w celu potwierdzenia, a następnie wybierz pozycję Usuń.
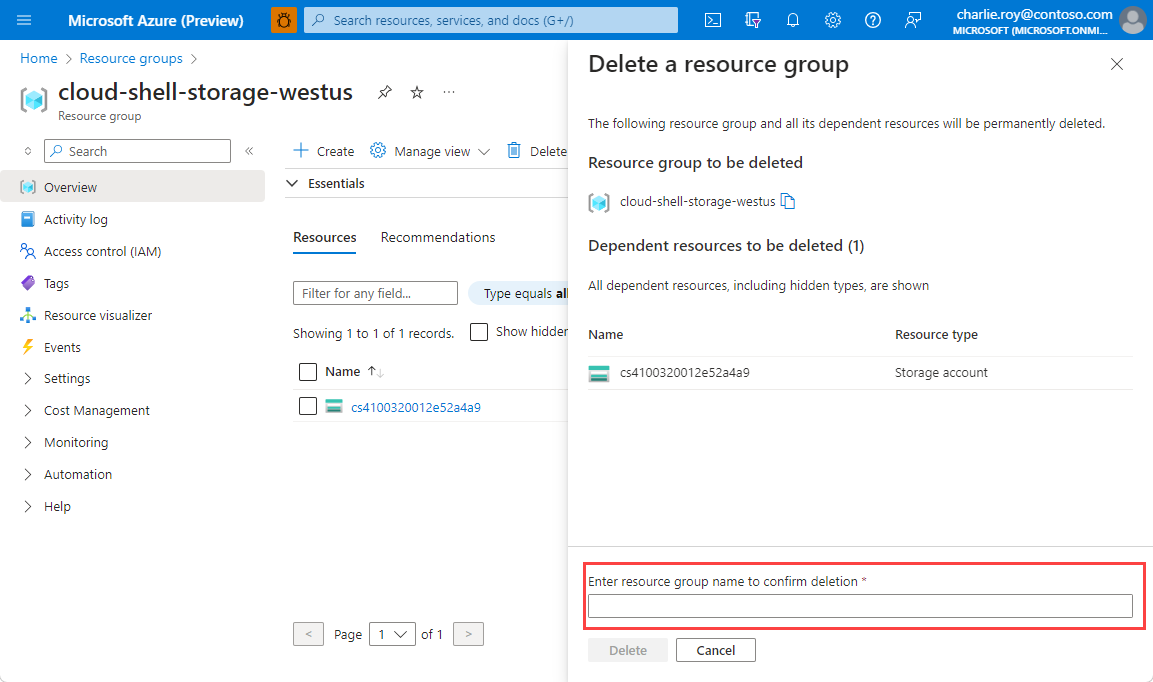
Po krótkim czasie grupa zasobów i wszystkie jej zasoby zostaną usunięte.
Powiązana zawartość
- Dowiedz się więcej o usłudze Azure Cache for Redis
- Dowiedz się więcej o możliwościach wyszukiwania wektorów usługi Azure Cache for Redis
- Dowiedz się więcej o osadzaniu generowanych przez usługę Azure OpenAI Service
- Dowiedz się więcej o podobieństwie cosinus
- Przeczytaj, jak utworzyć aplikację obsługiwaną przez sztuczną inteligencję przy użyciu interfejsu OpenAI i usługi Redis
- Tworzenie aplikacji pytań i odpowiedzi za pomocą semantycznych odpowiedzi