Wdrażanie i testowanie obciążeń o znaczeniu krytycznym na platformie Azure
Wdrażanie i testowanie środowiska o krytycznym znaczeniu jest kluczowym elementem ogólnej architektury referencyjnej. Poszczególne sygnatury aplikacji są wdrażane przy użyciu infrastruktury jako kodu z repozytorium kodu źródłowego. Aktualizacje infrastruktury i aplikacji na górze powinny być wdrażane z zerowym przestojem w aplikacji. Zaleca się użycie ciągłego procesu integracji DevOps do pobierania kodu źródłowego z repozytorium i wdrażania poszczególnych etapów na platformie Azure.
Wdrażanie i aktualizacje to centralny proces w architekturze. Aktualizacje związane z infrastrukturą i aplikacjami powinny być wdrażane w całkowicie niezależnych instancjach. Tylko globalne składniki infrastruktury w architekturze są współużytkowane przez znaczniki. Istniejące stemple w infrastrukturze nie są naruszane. Aktualizacje infrastruktury są wdrażane w tych nowych sygnaturach. Podobnie nowe wersje aplikacji są wdrażane w tych nowych sygnaturach.
Nowe znaczki zostały dodane do usługi Azure Front Door. Ruch jest stopniowo przenoszony do nowych sygnatur. Gdy ruch jest obsługiwany z nowych sygnatur bez problemów, poprzednie sygnatury są usuwane.
Testy penetracyjne, chaosu i stresu są zalecane dla wdrożonego środowiska. Proaktywne testowanie infrastruktury wykrywa słabe strony i sposób działania wdrożonej aplikacji w przypadku wystąpienia awarii.
Wdrażania
Wdrożenie infrastruktury w architekturze referencyjnej zależy od następujących procesów i składników:
DevOps — kod źródłowy z serwisu GitHub i pipeline'y dla infrastruktury.
aktualizacje bez przestojów — aktualizacje i uaktualnienia są wdrażane w środowisku z zerowym przestojem w wdrożonej aplikacji.
Environments — środowiska krótkotrwałe i trwałe stosowane w architekturze.
Udostępnione i dedykowane zasoby — zasoby platformy Azure, które są dedykowane i udostępnione centrom danych oraz ogólnej infrastrukturze.
Aby uzyskać więcej informacji, zobacz Wdrażanie i testowanie obciążeń o znaczeniu krytycznym na platformie Azure: Zagadnienia dotyczące projektowania
Wdrażanie: DevOps
Składniki DevOps udostępniają repozytorium kodu źródłowego i kanały ciągłej integracji/ciągłego wdrażania do wdrażania infrastruktury i aktualizacji. Usługi GitHub i Azure Pipelines zostały wybrane jako składniki.
GitHub — zawiera repozytoria kodu źródłowego dla aplikacji i infrastruktury.
Azure Pipelines — Potoki używane przez architekturę do zadań budowania, testowania i wydawania.
Dodatkowym składnikiem w projektowaniu używanym do wdrożenia są agenty kompilacji. Agenci kompilacji hostowanej przez firmę Microsoft są używane w ramach usługi Azure Pipelines do wdrażania infrastruktury i aktualizacji. Korzystanie z agentów kompilacji hostowanych przez firmę Microsoft eliminuje obciążenie związane z zarządzaniem dla deweloperów w celu obsługi i aktualizowania agenta kompilacji.
Aby uzyskać więcej informacji na temat usługi Azure Pipelines, zobacz Co to jest usługa Azure Pipelines?.

Aby uzyskać więcej informacji, zobacz Wdrażanie i testowanie obciążeń o znaczeniu krytycznym na platformie Azure: wdrożenia infrastruktury jako kodu
Wdrożenie: aktualizacje bez przestojów
Strategia aktualizacji bez przestojów w architekturze referencyjnej jest kluczowa dla ogólnej aplikacji o znaczeniu krytycznym. Metodologia wymiany zamiast uaktualnienia znaczków zapewnia pełną nową instalację aplikacji w jednostce infrastruktury. Architektura referencyjna wykorzystuje podejście niebieskie/zielone i umożliwia oddzielne środowiska testowe i programistyczne.
Istnieją dwa główne składniki architektury referencyjnej:
Infrastructure — usługi i zasoby platformy Azure. Wdrożono przy użyciu programu Terraform i skojarzonej z nią konfiguracji.
Application — hostowana usługa lub aplikacja, która obsługuje użytkowników. Na podstawie kontenerów Docker oraz artefaktów zbudowanych przy użyciu npm w językach HTML i JavaScript dla interfejsu użytkownika aplikacji jednostronicowej (SPA).
W wielu systemach zakłada się, że aktualizacje aplikacji są częstsze niż aktualizacje infrastruktury. W rezultacie dla każdego z nich opracowywane są różne procedury aktualizacji. Dzięki infrastrukturze chmury publicznej zmiany mogą nastąpić w szybszym tempie. Wybrano jeden proces wdrażania aktualizacji aplikacji i aktualizacji infrastruktury. Jedno podejście zapewnia, że aktualizacje infrastruktury i aplikacji są zawsze zsynchronizowane. Takie podejście umożliwia:
Jeden spójny proces — mniejsze ryzyko błędów, jeśli uaktualnienia infrastruktury i aplikacji są mieszane razem w wydaniu, celowo lub nie.
Włącza wdrożenia Blue/Green — każda aktualizacja jest wdrażana przy użyciu stopniowej migracji ruchu do nowej wersji.
Łatwiejsze wdrażanie i debugowanie aplikacji — cała sygnatura nigdy nie obsługuje wielu wersji aplikacji obok siebie.
Prosty rollback — ruch można przełączyć z powrotem do znaczników, które obsługują poprzednią wersję, jeśli wystąpią błędy lub problemy.
Eliminacja ręcznych zmian i dryfu konfiguracji – Każde środowisko to nowe wdrożenie.
Aby uzyskać więcej informacji, zobacz Wdrożenia i testowanie obciążeń o kluczowym znaczeniu dla misji na platformie Azure: Efemeryczne wdrożenia blue/green
Strategia rozgałęziania
Podstawą strategii aktualizacji jest użycie gałęzi w repozytorium Git. Architektura referencyjna używa trzech typów gałęzi:
| Gałąź | Opis |
|---|---|
feature/* i fix/* |
Punkty wejścia dla każdej zmiany. Deweloperzy tworzą te gałęzie i powinni mieć opisową nazwę, taką jak feature/catalog-update lub fix/worker-timeout-bug. Gdy zmiany są gotowe do scalenia, zostanie utworzona prośba o scalenie względem gałęzi main. Co najmniej jeden recenzent musi zatwierdzić wszystkie pull requesty. Z nielicznymi wyjątkami każda zmiana proponowana w PR musi przejść przez kompleksowy proces walidacji (E2E). Deweloperzy powinni używać pipeline'u E2E do testowania i debugowania zmian w pełnym środowisku. |
main |
Ciągle posuwająca się naprzód i stabilna gałąź. Najczęściej używane do testowania integracji. Zmiany main są wprowadzane tylko za pośrednictwem żądań ciągnięcia. Polityka gałęzi zabrania bezpośrednich zapisów. Nocne wydania dla stałego środowiska integration (int) są automatycznie wykonywane z gałęzi main. Gałąź main jest uważana za stabilną. Należy bezpiecznie założyć, że w danym momencie można utworzyć na jego podstawie wydanie. |
release/* |
Gałęzie wydania są tworzone tylko z gałęzi main. Gałęzie są zgodne z formatem release/2021.7.X. Polityki gałęzi są używane, aby tylko administratorzy repo mogli tworzyć gałęzie release/*. Tylko te gałęzie są używane do wdrażania w środowisku prod. |
Aby uzyskać więcej informacji, zobacz Wdrażanie i testowanie obciążeń o znaczeniu krytycznym na platformie Azure: strategia rozgałęziania
Szybkie poprawki
Jeśli poprawka jest wymagana pilnie z powodu usterki lub innego problemu i nie można przejść przez zwykły proces wydania, dostępna jest ścieżka poprawki. Krytyczne aktualizacje zabezpieczeń i poprawki środowiska użytkownika, które nie zostały odnalezione podczas testowania początkowego, są uznawane za prawidłowe przykłady poprawek.
Poprawka musi zostać utworzona w nowej gałęzi fix, a następnie scalona do main przy użyciu zwykłego pull requesta. Zamiast tworzyć nową gałąź wersji, hotfix jest włączany do istniejącej gałęzi wersji. Ta gałąź jest już wdrożona w środowisku prod. Potok CI/CD, który pierwotnie wdrożył gałąź typu release ze wszystkimi testami, zostaje uruchomiony ponownie i wdraża hotfix w ramach potoku.
Aby uniknąć poważnych problemów, ważne jest, aby poprawka zawierała kilka izolowanych commitów, które można łatwo wybrać i zintegrować z gałęzią wydania. Jeśli nie można zintegrować z gałęzią wydania izolowanych zatwierdzeń, oznacza to, że zmiana nie kwalifikuje się jako poprawka. Wdróż zmianę jako pełną nową wersję. Połącz je z wycofaniem do poprzedniej stabilnej wersji do momentu wdrożenia nowej wersji.
Wdrażanie: środowiska
Architektura referencyjna używa dwóch typów środowisk dla infrastruktury:
Krótkotrwałe — potok weryfikacji E2E służy do wdrażania tymczasowych środowisk. Środowiska krótkotrwałe są używane do czystej weryfikacji lub debugowania środowisk dla deweloperów. Środowiska weryfikacji można utworzyć na podstawie gałęzi
feature/*, poddane testom, a następnie zniszczyć, jeśli wszystkie testy zakończyły się pomyślnie. Środowiska debugowania są wdrażane w taki sam sposób jak walidacja, ale nie są natychmiast niszczone. Te środowiska nie powinny istnieć dłużej niż kilka dni i powinny zostać usunięte po scaleniu odpowiedniego pull requesta dla gałęzi funkcji.Stałe — w środowiskach stałych dostępne są wersje
integration (int)iproduction (prod). Te środowiska działają w sposób ciągły i nie są niszczone. Środowiska używają stałych nazw domen, takich jakint.mission-critical.app. W rzeczywistej implementacji architektury referencyjnej należy dodać środowiskostaging(wstępnieprod). Środowiskostagingsłuży do wdrażania i weryfikowania gałęzireleaseprzy użyciu tego samego procesu aktualizacji coprod(wdrożenie Blue/Green).Integration (int) — wersja
intjest wdrażana każdej nocy z gałęzimainprzy użyciu tego samego procesu coprod. Zmiana ruchu jest szybsza niż w poprzedniej wersji. Zamiast stopniowego przełączania ruchu na przestrzeni wielu dni, tak jak ma to miejsce wprod, procesintkończy się w ciągu kilku minut lub nawet godzin. Ta szybsza zmiana zapewnia gotowość zaktualizowanego środowiska do następnego ranka. Stare sygnatury są automatycznie usuwane, jeśli wszystkie testy w ciągu zakończyły się pomyślnie.Production (prod) — Wersja
prodjest wdrażana tylko z gałęzirelease/*. Przełączanie ruchu korzysta z bardziej szczegółowych kroków. Brama ręcznego zatwierdzania znajduje się między każdym krokiem. Każda wersja tworzy nowe pieczęcie regionalne i wdraża nową wersję aplikacji do pieczęci. Istniejące znaczki nie są dotykane w tym procesie. Najważniejszą kwestią dlaprodjest to, że powinno być "zawsze włączone". Nigdy nie powinny wystąpić żadne zaplanowane lub nieplanowane przestoje. Jedynym wyjątkiem są podstawowe zmiany w warstwie bazy danych. Może być potrzebne planowane okno konserwacji.
Wdrażanie: udostępnione i dedykowane zasoby
Środowiska trwałe (int i prod) w architekturze referencyjnej mają różne typy zasobów w zależności od tego, czy są one współużytkowane z całą infrastrukturą lub przeznaczone dla pojedynczej sygnatury. Zasoby mogą być przeznaczone dla określonej wersji i istnieją tylko do momentu przejęcia następnej jednostki wydania.
Jednostki wydania
Jednostka wydania to kilka regionalnych znaczków dla specyficznej wersji wydania. Znaczki zawierają wszystkie zasoby, które nie są udostępniane innym znaczkom. Te zasoby to sieci wirtualne, klaster usługi Azure Kubernetes Service, usługa Event Hubs i usługa Azure Key Vault. Usługi Azure Cosmos DB i ACR są konfigurowane przy użyciu źródeł danych programu Terraform.
Zasoby współużytkowane globalnie
Wszystkie zasoby współużytkowane między jednostkami wydania są definiowane w niezależnym szablonie programu Terraform. Te zasoby to usługi Front Door, Azure Cosmos DB, Container Registry (ACR) oraz obszary robocze usługi Log Analytics i inne zasoby związane z monitorowaniem. Te zasoby są wdrażane przed wdrożeniem pierwszej regionalnej pieczęci jednostki wydania. Zasoby są przywoływane w szablonach programu Terraform dla znaczników.
Drzwi frontowe
Choć usługa Front Door jest globalnym zasobem współużytkowanym w różnych centrach danych, jej konfiguracja różni się nieco od innych zasobów globalnych. Usługa Front Door musi zostać ponownie skonfigurowana po wdrożeniu nowej pieczęci. Usługa Front Door musi zostać ponownie skonfigurowana, aby stopniowo przełączać ruch do nowych sygnatur.
Nie można bezpośrednio zdefiniować konfiguracji zaplecza usługi Front Door w szablonie programu Terraform. Konfiguracja jest wstawiana ze zmiennymi programu Terraform. Wartości zmiennych są tworzone przed rozpoczęciem wdrażania programu Terraform.
Konfiguracja poszczególnych składników wdrożenia usługi Front Door jest zdefiniowana jako:
frontonu — koligacja sesji jest skonfigurowana w celu zapewnienia, że użytkownicy nie przełączają się między różnymi wersjami interfejsu użytkownika podczas jednej sesji.
Origins — usługa Front Door jest skonfigurowana z dwoma typami grup pochodzenia:
Grupa źródeł dla magazynu statycznego, która obsługuje interfejs użytkownika. Grupa zawiera konta magazynowe witryny internetowej z wszystkich obecnie aktywnych jednostek wydawniczych. Różne wagi można przypisać źródłom z różnych jednostek wydaniowych, aby stopniowo przekierowywać ruch sieciowy do nowszej jednostki. Każde źródło pochodzące z jednostki wydania powinno mieć przypisaną taką samą wagę.
Grupa źródeł dla interfejsu API, która jest hostowana w usłudze Azure Kubernetes Service. Jeśli istnieją jednostki wydania z różnymi wersjami interfejsu API, dla każdej jednostki wydania istnieje grupa źródłowa interfejsu API. Jeśli wszystkie jednostki wydania oferują ten sam zgodny interfejs API, wszystkie źródła są dodawane do tej samej grupy i przypisuje się im różne wagi.
reguły routingu — istnieją dwa typy reguł routingu:
Reguła routingu dla interfejsu użytkownika powiązana z grupą źródłową magazynu interfejsu użytkownika.
Reguła routingu dotycząca każdego interfejsu API obecnie obsługiwanego przez źródła. Na przykład:
/api/1.0/*i/api/2.0/*.
Jeśli wydanie wprowadza nową wersję interfejsów API zaplecza, zmiany odzwierciedlają interfejs użytkownika wdrożony w ramach wydania. Określona wersja interfejsu użytkownika zawsze wywołuje określoną wersję adresu URL interfejsu API. Użytkownicy, którzy korzystają z wersji interfejsu użytkownika, automatycznie używają odpowiedniego zapleczowego API. Dla różnych wystąpień wersji interfejsu API potrzebne są określone reguły routingu. Te reguły są połączone z odpowiednimi grupami pochodzenia. Jeśli nie wprowadzono nowego interfejsu API, wszystkie reguły routingu powiązane z interfejsem API odnoszą się do jednej grupy źródłowej. W takim przypadku nie ma znaczenia, czy użytkownik jest obsługiwany przez interfejs użytkownika z innej wersji niż interfejs API.
Wdrażanie: proces wdrażania
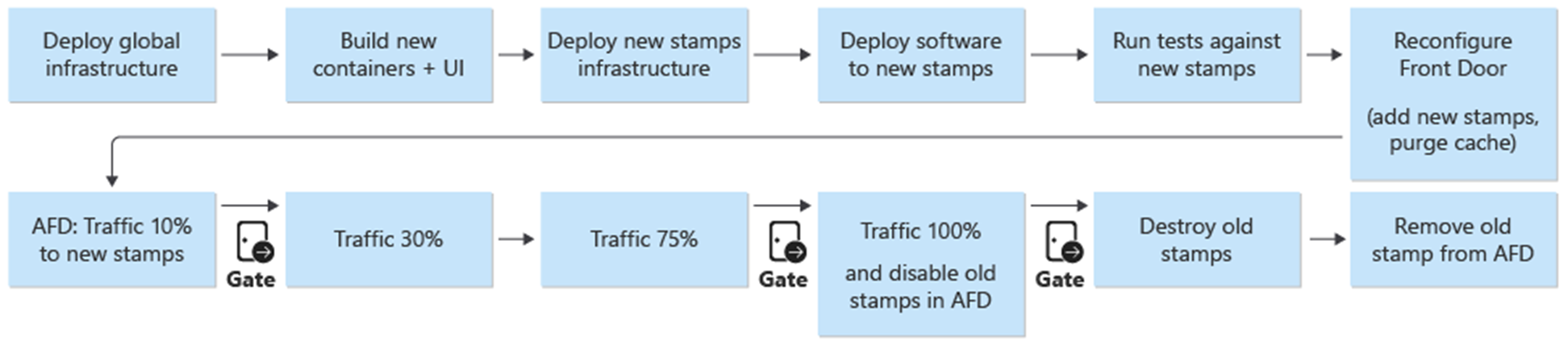
Niebieskie/zielone wdrożenie jest celem procesu wdrażania. Nowe wydanie z gałęzi release/* jest wdrażane w środowisku prod. Ruch użytkowników jest stopniowo przesuwany na aktualizacje nowej wersji.
W pierwszym kroku procesu wdrażania nowej wersji infrastruktura nowej jednostki wydania jest wdrażana za pomocą narzędzia Terraform. Wykonanie potoku wdrażania infrastruktury umożliwia wdrożenie nowej infrastruktury z wybranej gałęzi wydania. Równolegle do aprowizacji infrastruktury obrazy kontenerów są kompilowane lub importowane i wypychane do globalnie udostępnionego rejestru kontenerów (ACR). Po zakończeniu poprzednich procesów aplikacja zostanie wdrożona na serwerach. Z punktu widzenia implementacji jest to jeden potok z wieloma etapami zależnymi. Ten sam ciąg można ponownie wykonać dla wdrożeń poprawek.
Po wdrożeniu i zweryfikowaniu nowej jednostki wydania, nowa jednostka zostanie dodana do Front Door, aby odbierać ruch użytkowników.
Przełącznik/parametr, który rozróżnia wersje wprowadzające i niewprowadzające nową wersję interfejsu API, powinien być planowany. Na podstawie tego, czy wydanie wprowadza nową wersję API, należy utworzyć nową grupę źródłową z zapleczem API. Alternatywnie można dodać nowe zaplecza API do istniejącej grupy początkowej. Nowe konta magazynu interfejsu użytkownika są dodawane do odpowiedniej istniejącej grupy pochodzenia. Wagi dla nowych źródeł powinny być ustawione zgodnie z żądanym podziałem ruchu. Należy utworzyć nową regułę trasy zgodnie z wcześniejszym opisem, która będzie odpowiadać odpowiedniej grupie pochodzenia.
W ramach dodawania nowej jednostki wydania wagi nowych źródeł powinny być ustawione na pożądany minimalny poziom ruchu użytkowników. Jeśli nie zostaną wykryte żadne problemy, ilość ruchu użytkowników powinna zostać zwiększona do nowej grupy pochodzenia w danym okresie. Aby dostosować parametry wagi, te same kroki wdrażania powinny zostać wykonane ponownie z żądanymi wartościami.
Demontaż jednostki wydania
W ramach ciągu wdrażania dla jednostki wydania istnieje etap niszczenia, który usuwa wszystkie artefakty, gdy jednostka wydania nie jest już potrzebna. Cały ruch jest przenoszony do nowej wersji wydaniowej. Ten etap obejmuje usunięcie odwołań do jednostek dystrybucji z Front Door. To usunięcie ma kluczowe znaczenie dla umożliwienia wydania nowej wersji w późniejszym czasie. Usługa Front Door musi wskazywać pojedynczą jednostkę wydania, aby przygotować się do następnej wersji w przyszłości.
Listy kontrolne
W ramach harmonogramu wydań należy użyć listy kontrolnej przed i po wydaniu. Poniższy przykład dotyczy elementów, które powinny znajdować się na dowolnej liście kontrolnej co najmniej.
lista kontrolna wersji wstępnej — przed rozpoczęciem wydania sprawdź następujące kwestie:
Upewnij się, że najnowszy stan gałęzi
mainzostał pomyślnie wdrożony i przetestowany w środowiskuint.Zaktualizuj plik dziennika zmian za pomocą pull request do gałęzi
main.Utwórz gałąź
release/z gałęzimain.
lista kontrolna po publikacji — przed zniszczeniem starych znaczków oraz usunięciem ich odwołań z Front Door, sprawdź, czy:
Klastry nie odbierają już ruchu przychodzącego.
Usługa Event Hubs i inne kolejki komunikatów nie zawierają żadnych nieprzetworzonych komunikatów.
Wdrożenie: ograniczenia i zagrożenia strategii aktualizacji
Strategia aktualizacji opisana w tej architekturze referencyjnej ma pewne ograniczenia i zagrożenia, które należy wspomnieć:
Wyższy koszt — podczas wydawania aktualizacji wiele składników infrastruktury jest aktywnych dwa razy w okresie wydania.
Złożoność usługi Front Door — proces aktualizacji w usłudze Front Door jest złożony w celu zaimplementowania i obsługi. Możliwość wykonywania efektywnych wdrożeń niebiesko-zielonych z zerowym przestojem zależy od tego, czy działa prawidłowo.
Małe zmiany czasochłonne — proces aktualizacji powoduje dłuższy proces wydawania małych zmian. To ograniczenie można częściowo ograniczyć za pomocą procesu poprawek opisanego w poprzedniej sekcji.
Wdrażanie: Zagadnienia dotyczące zgodności przekazywania danych aplikacji
Strategia aktualizacji może obsługiwać wiele wersji interfejsu API i składników roboczych wykonywanych jednocześnie. Ponieważ usługa Azure Cosmos DB jest współdzielona między co najmniej dwiema wersjami, istnieje możliwość, że elementy danych zmienione przez jedną wersję mogą nie zawsze być zgodne z wersją interfejsu API lub procesami roboczymi korzystającymi z niego. Warstwy interfejsu API i procesy robocze muszą implementować projekt kompatybilności wstecznej. Wcześniejsze wersje interfejsu API lub składników procesu roboczego przetwarzają dane wstawione przez nowszy interfejs API lub wersję składnika procesu roboczego. Ignoruje części, których nie rozumie.
Testowanie
Architektura referencyjna zawiera różne testy używane na różnych etapach w ramach implementacji testowania.
Te testy obejmują:
testy jednostkowe — te testy sprawdzają, czy logika biznesowa aplikacji działa zgodnie z oczekiwaniami. Architektura referencyjna zawiera przykładowy zestaw testów jednostkowych wykonywanych automatycznie przed każdą kompilacją kontenera przez usługę Azure Pipelines. Jeśli jakikolwiek test zakończy się niepowodzeniem, potok zostanie zatrzymany. Kompilowanie i wdrażanie zostaje zatrzymane. Deweloper musi rozwiązać ten problem przed ponownym wykonaniem pipeline'u.
testy obciążeniowe — te testy pomagają ocenić pojemność, skalowalność i potencjalne wąskie gardła dla danego obciążenia lub sprzężenia. Implementacja referencyjna zawiera generator obciążenia użytkownika w celu utworzenia syntetycznych wzorców obciążenia, których można użyć do symulowania rzeczywistego ruchu. Generator obciążenia może być również używany niezależnie od implementacji referencyjnej.
Testy dymne — te testy określają, czy infrastruktura i obciążenie są dostępne i działają zgodnie z oczekiwaniami. Testy dymne są wykonywane w ramach każdego wdrożenia.
testy interfejsu użytkownika — te testy sprawdzają, czy interfejs użytkownika został wdrożony i działa zgodnie z oczekiwaniami. Bieżąca implementacja przechwytuje zrzuty ekranu kilku stron po wdrożeniu bez faktycznego testowania.
Testy iniekcji błędów — można je zautomatyzować lub wykonać ręcznie. Zautomatyzowane testowanie w architekturze integruje Azure Chaos Studio jako część ścieżek wdrożeniowych.
Aby uzyskać więcej informacji, zobacz Wdrażanie i testowanie obciążeń o znaczeniu krytycznym na platformie Azure: ciągła walidacja i testowanie
Testowanie: struktury
W miarę możliwości należy używać istniejących możliwości testowania i struktur implementacji referencyjnej online.
| Szkielet | Test | Opis |
|---|---|---|
| NUnit | Jednostka | Ta struktura jest używana do testowania jednostkowego części implementacji platformy .NET Core. Usługa Azure Pipelines automatycznie wykonuje testy jednostkowe przed kompilacjami kontenerów. |
| JMeter za pomocą usługi Azure Load Testing | Ładowanie | Azure Load Testing jest zarządzaną usługą używaną do przeprowadzania definicji testów obciążeniowych Apache JMeter. |
| szarańcza | Ładowanie | Locust to platforma testowania obciążenia typu open source napisana w języku Python. |
| dramaturg | Interfejs użytkownika i dym | Playwright to biblioteka Node.js typu open source do automatyzowania chromium, Firefox i WebKit przy użyciu jednego interfejsu API. Definicja testu Playwright może być również używana niezależnie od referencyjnej implementacji. |
| Azure Chaos Studio | Iniekcja błędu | Implementacja referencyjna używa narzędzia Azure Chaos Studio jako opcjonalnego kroku w potoku weryfikacji E2E w celu wstrzyknięcia błędów na potrzeby walidacji odporności. |
Testowanie: testowanie iniekcji błędów i inżynieria chaosu
Aplikacje rozproszone powinny być odporne na awarie usług i składników. Testowanie poprzez iniekcję błędów (znane również jako wstrzykiwanie błędów lub inżynieria chaosu) to praktyka wystawiania aplikacji i usług na rzeczywiste stresy i awarie.
Odporność jest właściwością całego systemu i wprowadzanie błędów pomaga znaleźć problemy w aplikacji. Rozwiązanie tych problemów pomaga zweryfikować odporność aplikacji na zawodne warunki, brakujące zależności i inne błędy.
Testy ręczne i automatyczne można wykonywać względem infrastruktury w celu znalezienia błędów i problemów w implementacji.
Automatyczne
Architektura referencyjna integruje azure Chaos Studio do wdrażania i uruchamiania zestawu eksperymentów usługi Azure Chaos Studio w celu wstrzyknięcia różnych błędów na poziomie sygnatury. Eksperymenty chaosu można wykonać jako opcjonalną część potoku wdrażania E2E. Po wykonaniu testów opcjonalny test obciążeniowy jest zawsze wykonywany równolegle. Test obciążeniowy służy do tworzenia obciążenia klastra w celu zweryfikowania wpływu wstrzykniętych błędów.
Instrukcja
Ręczne testowanie iniekcji błędów powinno się przeprowadzać w środowisku walidacji E2E. To środowisko zapewnia pełne reprezentatywne testy bez ryzyka ingerencji w inne środowiska. Większość błędów generowanych przy użyciu testów można zaobserwować bezpośrednio w widoku metryk usługi Application Insights Live. Pozostałe błędy są dostępne w widoku Błędy i odpowiadające im tabele dziennika. Inne błędy wymagają dokładniejszego debugowania, takiego jak użycie kubectl do obserwowania zachowania w usłudze Azure Kubernetes Service.
Dwa przykłady testów iniekcji niepowodzeń przeprowadzonych na architekturze referencyjnej to:
Wstrzykiwanie błędów oparte na DNS (usługa nazw domen) — przypadek testowy, który może symulować wiele problemów. Błędy rozpoznawania nazw domeny (DNS) z powodu awarii serwera DNS lub usługi Azure DNS. Testowanie oparte na systemie DNS może pomóc w symulowaniu ogólnych problemów z połączeniami między klientem a usługą, na przykład gdy BackgroundProcessor nie może nawiązać połączenia z usługą Event Hubs.
W scenariuszach z jednym hostem można zmodyfikować lokalny plik
hosts, aby nadpisać rozpoznawanie nazw DNS. W większym środowisku z wieloma serwerami dynamicznymi, takimi jak AKS, plikhostsnie jest wykonalny. prywatnych stref DNS platformy Azure można użyć jako alternatywy do testowania scenariuszy awarii.Usługi Azure Event Hubs i Azure Cosmos DB to dwie usługi platformy Azure używane w implementacji referencyjnej, których można użyć do wstrzykiwania błędów opartych na systemie DNS. Sterowanie rozpoznawaniem nazw DNS usługi Event Hubs może być realizowane za pomocą prywatnej strefy DNS platformy Azure związanej z siecią wirtualną jednej z instancji. Azure Cosmos DB to globalnie replikowana usługa z określonymi regionalnymi punktami końcowymi. Zmiana rekordów DNS dla tych punktów końcowych może symulować błąd dla określonego regionu i przetestować przełączenie awaryjne klientów.
Blokada zapory — większość usług platformy Azure obsługuje ograniczenia dostępu zapory na podstawie sieci wirtualnych i/lub adresów IP. W infrastrukturze referencyjnej te ograniczenia są używane do ograniczania dostępu do usługi Azure Cosmos DB lub Event Hubs. Prostą procedurą jest usunięcie istniejących reguł Zezwalaj na lub dodawanie nowych reguł Blokuj. Ta procedura może symulować błędy konfiguracji zapory lub awarie usługi.
Następujące przykładowe usługi w implementacji referencyjnej można przetestować przy użyciu testu zapory:
Usługa Wynik Key Vault Gdy dostęp do Key Vault jest zablokowany, najbardziej bezpośrednim skutkiem było niepowodzenie w uruchomieniu nowych zasobników. Sterownik CSI usługi Key Vault, który pobiera sekrety podczas uruchamiania zasobnika, nie może wykonywać swoich zadań i uniemożliwia jego uruchomienie. Odpowiednie komunikaty o błędach można zaobserwować za pomocą kubectl describe po CatalogService-deploy-my-new-pod -n workload. Istniejące zasobniki nadal działają, chociaż zaobserwowano ten sam komunikat o błędzie. Wyniki okresowego sprawdzania tajnych danych powodują wygenerowanie komunikatu o błędzie. Chociaż nie przetestowano, wykonywanie wdrożenia nie działa, gdy usługa Key Vault jest niedostępna. Zadania Terraform i CLI platformy Azure w ramach działania potoku wysyłają żądania do usługi Key Vault.Centra Wydarzeń Po zablokowaniu dostępu do usługi Event Hubs nowe komunikaty wysyłane przez usługę CatalogService i HealthService kończą się niepowodzeniem. Pobieranie komunikatów przez proces w tle powoli zaczyna kończyć się niepowodzeniem, aż całkowicie przestaje działać w ciągu kilku minut. Azure Cosmos DB Usunięcie istniejącej polityki zapory dla sieci wirtualnej powoduje, że usługa stanu zdrowia zacznie ulegać awarii z minimalnym opóźnieniem. Ta procedura symuluje tylko konkretny przypadek, całą awarię usługi Azure Cosmos DB. Większość przypadków awarii występujących na poziomie regionalnym jest łagodzona automatycznie dzięki przezroczystej zmianie klienta do innego regionu usługi Azure Cosmos DB. Opisane wcześniej testy iniekcji błędów oparte na systemie DNS są bardziej znaczącym testem dla usługi Azure Cosmos DB. Rejestr kontenerów (ACR) Nawet po zablokowaniu dostępu do usługi ACR, tworzenie nowych zasobników, które zostały wcześniej ściągnięte i zbuforowane na węźle usługi AKS, nadal jest możliwe. Tworzenie nadal działa dzięki fladze wdrożeniowej K8s pullPolicy=IfNotPresent. Węzły nie mogą utworzyć nowego podu i natychmiast kończą się błędem z powodu błędówErrImagePull, jeśli węzeł nie ściągnie i nie zbuforuje obrazu zanim napotka blokadę.kubectl describe podwyświetla odpowiedni komunikat403 Forbidden.program równoważenia obciążenia wejściowy AKS Zmiana reguł ruchu przychodzącego dla protokołu HTTP(S) (portów 80 i 443) w zarządzanej grupie zabezpieczeń sieci (NSG) usługi AKS na Odmowa powoduje, że ruch użytkowników lub sondy zdrowotnej nie dociera do klastra. Test tego błędu jest trudny do zidentyfikowania głównej przyczyny, która została symulowana jako blokada między ścieżką sieciową usługi Front Door a sygnaturą regionalną. Front Door natychmiast wykrywa tę awarię i usuwa znacznik z obiegu.