Dzielenie magazynu danych na zestaw poziomych partycji lub fragmentów. Może to poprawić skalowalność podczas przechowywania dużych woluminów danych i uzyskiwania do nich dostępu.
Kontekst i problem
Magazyn danych obsługiwany przez jeden serwer może podlegać następującym ograniczeniom:
Ilość miejsca w magazynie. Oczekuje się, że magazyn danych na potrzeby aplikacji chmurowych dostępnych na dużą skalę będzie zawierał bardzo dużą ilość danych, która może znacznie wzrosnąć wraz z upływem czasu. Serwer zazwyczaj udostępnia ograniczoną ilość miejsca do przechowywania na dysku, ale można zastąpić istniejące dyski większymi lub dodać więcej dysków do maszyny, kiedy ilości danych rosną. Jednak system ostatecznie osiągnie limit, kiedy nie będzie już można łatwo zwiększyć pojemności magazynu na danym serwerze.
Zasoby obliczeniowe. Aplikacja w chmurze musi obsługiwać dużą liczbę równoczesnych użytkowników, z których każdy uruchamia zapytania pobierające informacje z magazynu danych. Pojedynczy serwer hostujący magazyn danych może nie być w stanie zapewnić niezbędnej mocy obliczeniowej do obsługi tego obciążenia, co powoduje wydłużenie czasu odpowiedzi dla użytkowników i częste błędy podczas próby przechowywania i pobierania limitu czasu danych. Może być możliwe dodanie pamięci lub uaktualnienia procesorów, ale system osiągnie limit, gdy nie będzie możliwe dalsze zwiększenie zasobów obliczeniowych.
Przepustowość sieci. Ostatecznie o wydajności magazynu danych działającego na jednym serwerze decyduje szybkość, z jaką serwer może odbierać żądania i wysyłać odpowiedzi. Istnieje możliwość, że ilość ruchu sieciowego może przekraczać pojemność sieci używanej do łączenia się z serwerem, co skutkuje żądaniami zakończonymi niepowodzeniem.
Lokalizacja geograficzna. Może być konieczne przechowywanie danych wygenerowanych przez określonych użytkowników w tym samym regionie, w którym się oni znajdują, ze względu na przepisy, zgodność lub wydajność, albo w celu zmniejszenia opóźnienia dostępu do danych. Jeśli użytkownicy są rozproszeni między różnymi krajami lub regionami, przechowywanie danych całej aplikacji w jednym magazynie danych może nie być możliwe.
Skalowanie w pionie przez dodanie pojemności dysku, mocy obliczeniowej, pamięci i połączeń sieciowych może odroczyć skutki niektórych z tych ograniczeń, ale jest to prawdopodobnie tylko rozwiązanie tymczasowe. Komercyjna aplikacja w chmurze zdolna obsługiwać dużą liczbę użytkowników i duże ilości danych musi mieć możliwość niemal nieskończonego skalowania, a więc skalowanie w pionie niekoniecznie jest najlepszym rozwiązaniem.
Rozwiązanie
Dzielenie magazynu danych na poziome partycje lub fragmenty. Każdy fragment ma ten sam schemat, ale przechowuje własny unikatowy podzestaw danych. Fragment jest niezależnym magazynem danych (może zawierać dane dla wielu jednostek o różnych typach), uruchomionym na serwerze działającym jako węzeł magazynu.
Ten wzorzec ma następujące korzyści:
Można skalować system przez dodawanie kolejnych fragmentów uruchomionych na dodatkowych węzłach magazynu.
Dla każdego węzła magazynu system może korzystać ze standardowego sprzętu zamiast wyspecjalizowanych i drogich komputerów.
Można zmniejszyć rywalizację i zwiększyć wydajność przez równoważenie obciążenia między fragmentami.
W chmurze fragmenty mogą być fizycznie zlokalizowane blisko użytkowników, którzy będą uzyskiwali dostęp do danych.
Podczas dzielenia magazynu danych na fragmenty należy zdecydować, które dane powinny być umieszczone w poszczególnych fragmentach. Fragment zwykle zawiera elementy, które mieszczą się w określonym zakresie wyznaczanym przez jeden lub więcej atrybutów danych. Te atrybuty tworzą klucz fragmentu (czasem określany jako klucz partycji). Klucz fragmentu powinien być statyczny. Nie powinien on być oparty na danych, które mogą się zmieniać.
Fragmentowanie powoduje fizyczne organizowanie danych. Jeśli aplikacja przechowuje oraz pobiera dane, logika fragmentowania kieruje aplikację do odpowiedniego fragmentu. Tę logikę fragmentowania można zaimplementować jako część kodu dostępu do danych w aplikacji lub może ona zostać zaimplementowana przez system magazynu danych, jeśli w sposób przezroczysty obsługuje on fragmentowanie.
Abstrakcja fizycznej lokalizacji danych w logice fragmentowania zapewnia wysoki poziom kontroli nad tym, które fragmenty zawierają określone dane. Umożliwia również migrację między fragmentami bez konieczności wprowadzania zmian logiki biznesowej aplikacji, jeśli dane we fragmentach wymagają ponownej dystrybucji (na przykład jeśli fragmenty stają się niezrównoważone). Kosztem jest dodatkowy nakład pracy przy dostępie do danych wymagany przy określaniu lokalizacji każdego elementu danych podczas jego pobierana.
Aby zapewnić optymalną wydajność i skalowalność, ważne jest podzielenie danych w sposób odpowiedni dla typów zapytań wykonywanych przez aplikację. W wielu przypadkach jest mało prawdopodobne, że schemat fragmentowania będzie dokładnie odpowiadał wymaganiom każdego zapytania. Na przykład w systemie wielodostępnym aplikacja może wymagać pobrania danych dzierżawy przy użyciu identyfikatora dzierżawy, ale może być również konieczne wyszukanie tych danych na podstawie innego atrybutu, takiego jak nazwa lub lokalizacja dzierżawy. Na potrzeby obsługi tych sytuacji zaimplementuj strategię fragmentowania za pomocą klucza fragmentu, który obsługuje najczęściej wykonywane zapytania.
Jeśli zapytania regularnie pobierają dane przy użyciu kombinacji wartości atrybutów, prawdopodobnie można zdefiniować złożony klucz fragmentu przez łączenie atrybutów. Można również użyć wzorca takiego jak Indeksowanie tabeli, aby zapewnić szybkie wyszukiwanie danych na podstawie atrybutów, które nie są objęte kluczem fragmentu.
Strategie fragmentowania
W przypadku wybierania klucza fragmentu i podejmowania decyzji o sposobie rozproszenia danych między fragmentami powszechnie używane są trzy strategie. Należy pamiętać, że między fragmentami a serwerami hostowanymi nie musi istnieć żadna korespondencja jeden do jednego — pojedynczy serwer może hostować wiele fragmentów. Strategie są następujące:
Strategia Wyszukiwanie. W tej strategii logika fragmentowania implementuje mapę, która kieruje żądanie dotyczące danych do fragmentu zawierającego dane, używając klucza fragmentu. W aplikacji wielodostępnej wszystkie dane dzierżawy mogą być przechowywane razem w fragmentach przy użyciu identyfikatora dzierżawy jako klucza fragmentu. Wiele dzierżaw może współużytkować ten sam fragment, ale dane dla jednej dzierżawy nie będą rozdzielane na wiele fragmentów. Na rysunku przedstawiono fragmentowanie danych dzierżawy na podstawie identyfikatorów dzierżawy.
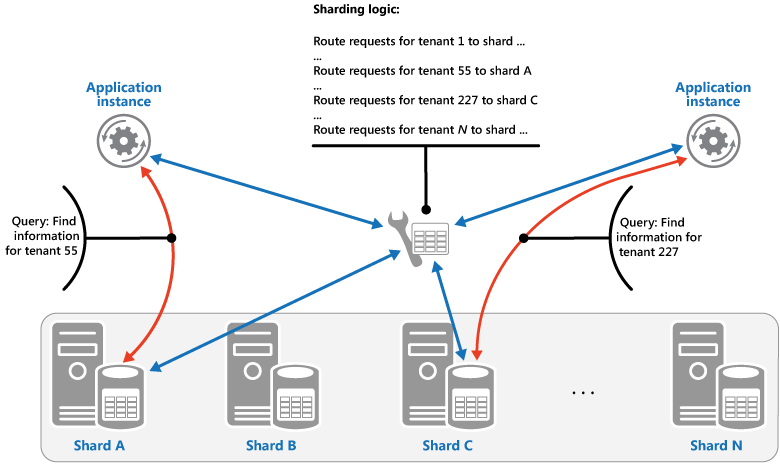
Mapowanie między wartością klucza fragmentu a magazynem fizycznym, na którym istnieją dane, może być oparte na fizycznych fragmentach, w których każda wartość klucza fragmentu jest mapowania na partycję fizyczną. Alternatywnie bardziej elastyczną techniką ponownego równoważenia fragmentów jest partycjonowanie wirtualne, gdzie wartości kluczy fragmentów są mapowanie na tę samą liczbę fragmentów wirtualnych, które z kolei mapuje na mniejszą liczbę partycji fizycznych. W tym podejściu aplikacja lokalizuje dane przy użyciu wartości klucza fragmentu, która odwołuje się do wirtualnego fragmentu, a system w sposób przezroczysty mapuje wirtualne fragmenty na partycje fizyczne. Mapowanie między wirtualnym fragmentem a partycją fizyczną może ulec zmianie bez konieczności modyfikowania kodu aplikacji w celu użycia innego zestawu wartości klucza fragmentu.
Strategia Zakres. Ta strategia grupuje elementy powiązane razem w tym samym fragmentzie i porządkuje je według klucza fragmentu — klucze fragmentów są sekwencyjne. Jest to przydatne w przypadku aplikacji, które często pobierają zestawy elementów za pomocą zapytań o zakres (zapytań, które zwracają zestaw elementów danych dla klucza fragmentu mieszczącego się w danym zakresie). Na przykład jeśli aplikacja regularnie musi znajdować zamówienia złożone w danym miesiącu, dane te mogą być pobierane szybciej, jeżeli wszystkie zamówienia dla danego miesiąca są przechowywane w kolejności daty i godziny w tym samym fragmencie. Gdyby każde zamówienie było przechowywane w innym fragmencie, musiałyby być one pobierane pojedynczo przez wykonywanie dużej liczby zapytań o punkt (zapytań, które zwracają jeden element danych). Następny rysunek przedstawia przechowywanie sekwencyjnych zestawów (zakresów) danych we fragmencie.
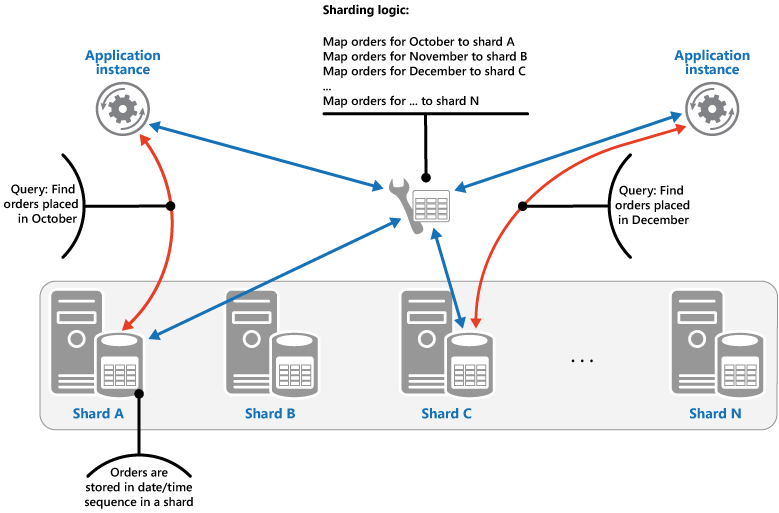
W tym przykładzie klucz fragmentu jest kluczem złożonym zawierającym miesiąc zamówienia jako najważniejszy element, po którym następuje dzień i godzina zamówienia. Dane dotyczące zamówień są w naturalny sposób sortowane, kiedy nowe zamówienia są tworzone i dodawane do fragmentu. Niektóre magazyny danych obsługują dwuczęściowe klucze fragmentów, zawierające element klucza partycji, który identyfikuje fragment, oraz klucz wiersza, który jednoznacznie identyfikuje element we fragmencie. Dane są zwykle przechowywane przy pomocy kolejności klucza wiersza we fragmencie. Elementy, które podlegają zapytaniom o zakres i muszą być zgrupowane razem, mogą korzystać z klucza fragmentu, który ma taką samą wartość klucza partycji, ale unikatową wartość dla klucza wiersza.
Strategia Skrót. Celem tej strategii jest zmniejszenie prawdopodobieństwa pojawienia się obszarów nadmiernej aktywności (fragmentów, które mają nieproporcjonalnie duże obciążenie). Rozkłada ona dane między fragmenty w sposób, który zapewnia osiągniecie równowagi między rozmiarem każdego fragmentu i średnim obciążeniem nakładanym na poszczególne fragmenty. Logika fragmentowania oblicza fragment do przechowywania elementu na podstawie skrótu jednego lub wielu atrybutów danych. Wybrane funkcje wyznaczania wartości skrótu powinny rozkładać dane równomiernie między fragmentami (można tu wprowadzić pewien element losowy do obliczeń). Na następnym rysunku przedstawiono fragmentowanie danych dzierżawy na podstawie wartości skrótu identyfikatora dzierżawy.
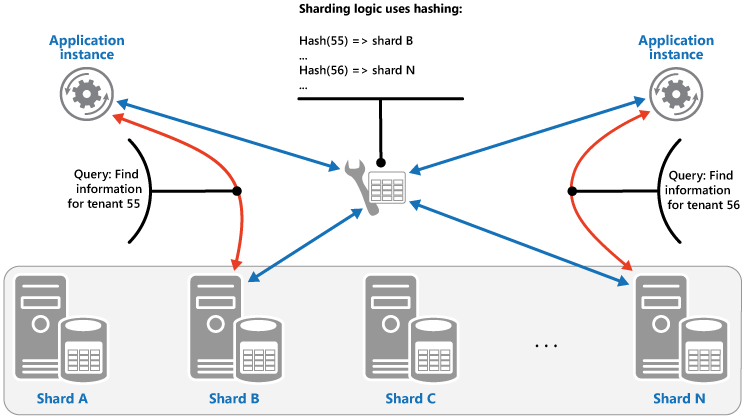
Aby zrozumieć zaletę strategii wyznaczania wartości skrótu w innych strategiach fragmentowania, rozważ, w jaki sposób aplikacja wielodostępna rejestrująca nowe dzierżawy sekwencyjnie może przypisać dzierżawy do fragmentów w magazynie danych. W przypadku używania strategii Zakres dane dla dzierżaw od 1 do n będą przechowywane we fragmencie A, dane dla dzierżaw od n + 1 do m będą przechowywane we fragmencie B i tak dalej. Jeśli ostatnio zarejestrowane dzierżawy są również najbardziej aktywne, większość działań dotyczących danych będzie występowała w niewielkiej liczbie fragmentów, co może spowodować powstanie obszarów nadmiernej aktywności. Z kolei strategia Skrót przydziela dzierżawy do fragmentów na podstawie skrótu ich identyfikatora dzierżawy. Oznacza to, że sekwencyjne dzierżawy będą najprawdopodobniej przydzielane do różnych fragmentów, które będą rozkładać obciążenie między nimi. Na poprzedniej ilustracji przedstawiono to dla dzierżaw 55 i 56.
Trzy strategie fragmentowania mają następujące zalety i wady:
Wyszukiwanie. Oferuje większą kontrolę nad sposobem, w jaki fragmenty są konfigurowane i używane. Korzystanie z fragmentów wirtualnych zmniejsza wpływ podczas ponownego równoważenia danych, ponieważ można dodać nowe partycje fizyczne w celu wyrównania obciążenia. Mapowanie między fragmentem wirtualnym i partycjami fizycznymi, które implementują fragment, można zmodyfikować bez wpływu na kod aplikacji, który używa klucza fragmentu do przechowywania i pobierania danych. Wyszukiwanie lokalizacji fragmentów może narzucać dodatkowe obciążenie.
Zakres. Ta strategia jest łatwa w implementacji i dobrze się sprawdza w przypadku zapytań o zakres, ponieważ mogą one często pobierać wiele elementów danych z jednego fragmentu w ramach pojedynczej operacji. Ta strategia umożliwia łatwiejsze zarządzanie danymi. Na przykład jeśli użytkownicy w tym samym regionie są przechowywani w tym samym fragmencie, można zaplanować aktualizacje w poszczególnych strefach czasowych na podstawie wzorca lokalnego obciążenia i zapotrzebowania. Jednak ta strategia nie zapewnia optymalnego równoważenia między fragmentami. Ponowne równoważenie fragmentów jest trudne i może nie rozwiązać problemu nierównomiernego obciążenia, jeśli większość działań dotyczy sąsiadujących kluczy fragmentów.
Skrót. Ta strategia oferuje lepsze możliwości bardziej równomiernego rozkładu danych i obciążenia. Routing żądań możne być wykonywany bezpośrednio przy użyciu funkcji skrótu. Nie ma potrzeby obsługi mapowania. Należy pamiętać, że wyznaczanie wartości skrótu może nakładać dodatkowe obciążenie. Ponadto ponowne równoważenie fragmentów jest trudne.
Najbardziej typowe systemy fragmentowania implementują jedno z podejść opisanych powyżej, ale należy również uwzględnić wymagania biznesowe aplikacji i ich wzorce użycia danych. Na przykład w aplikacji wielodostępnej:
Można fragmentować dane na podstawie obciążenia. Można segregować dane dla wysoce zmiennych dzierżaw w osobnych fragmentach. W związku z tym można zwiększyć szybkość dostępu do danych w przypadku pozostałych dzierżaw.
Można fragmentować dane na podstawie lokalizacji dzierżawy. Można przełączyć w tryb offline dane dla dzierżaw w określonym regionie geograficznym na potrzeby kopii zapasowej i konserwacji poza godzinami szczytu w danym regionie, podczas gdy dane dla dzierżaw w innych regionach są w trybie online i dostępne w ich godzinach pracy.
Dzierżawy o wysokiej wartości mogą być przypisane do własnych prywatnych, wysoko wydajnych, lekko załadowanych fragmentów, podczas gdy dzierżawy o niższej wartości mogą być współużytkowane bardziej gęsto zapakowane, zajęte fragmenty.
Dane dla dzierżawy, które wymagają wysokiego stopnia izolacji i prywatności danych, mogą być przechowywane na osobnym serwerze.
Operacje skalowania i przenoszenia danych
Każda ze strategii fragmentowania oznacza różne możliwości i poziomy złożoności dla zarządzania skalowaniem w poziomie (do wewnątrz i na zewnątrz), przenoszeniem danych i zachowaniem stanu.
Strategia Wyszukiwanie pozwala na przeprowadzanie operacji skalowania i przenoszenia danych na poziomie użytkownika, w trybie online lub offline. Technika polega na wstrzymaniu niektórych lub wszystkich działań użytkownika (być może w okresach poza szczytem), przeniesieniu danych do nowej partycji wirtualnej lub fizycznego fragmentu, zmianie mapowań, unieważnieniu lub odświeżeniu pamięci podręcznych przechowujących te dane, a następnie pozwoleniu na wznowienie aktywności użytkownika. Często ten typ operacji może być zarządzany centralnie. Strategia Wyszukiwanie wymaga, aby stan zdecydowanie podlegał buforowaniu i był przyjazny dla repliki.
Strategia Zakres nakłada pewne ograniczenia na operacje skalowania i przenoszenia danych, które zwykle muszą być przeprowadzane, gdy niektóre lub wszystkie źródła danych są w trybie offline, ponieważ dane muszą zostać podzielone i scalone między fragmentami. Przenoszenie danych w celu ponownego zrównoważenia fragmentów może nie rozwiązać problemu nierównego obciążenia, jeśli większość działań dotyczy sąsiadujących kluczy fragmentów lub identyfikatorów danych znajdujących się w tym samym zakresie. Strategia Zakres może wymagać utrzymania pewnego stanu w celu mapowania zakresów na partycje fizyczne.
W przypadku strategii Skrót operacje skalowania i przenoszenia danych stają się bardziej złożone, ponieważ klucze partycji są skrótami kluczy fragmentów lub identyfikatorów danych. Nowa lokalizacja każdego fragmentu musi być określona za pomocą funkcji skrótu lub funkcji zmodyfikowanej w celu zapewnienia poprawnego mapowania. Jednak strategia skrótu nie wymaga obsługi stanu.
Problemy i kwestie do rozważenia
Podczas podejmowania decyzji o sposobie wdrożenia tego wzorca należy rozważyć następujące punkty:
Fragmentowanie uzupełnia inne formy partycjonowania, takie jak partycjonowanie pionowe i partycjonowanie funkcjonalne. Na przykład pojedynczy fragment może zawierać jednostki partycjonowane w pionie, a partycja funkcjonalna może być implementowana jako wiele fragmentów. Aby uzyskać więcej informacji na temat partycjonowania, zobacz Data Partitioning Guidance (Wskazówki dotyczące partycjonowania danych).
Należy zachować zrównoważenie fragmentów, aby każdy z nich obsługiwał podobny wolumen operacji we/wy. Ponieważ dane są wstawiane i usuwane, należy okresowo ponownie równoważyć fragmenty, aby zagwarantować równy rozkład i zmniejszyć prawdopodobieństwo pojawienia się obszarów nadmiernej aktywności. Ponowne równoważenie może być kosztowną operacją. W celu zmniejszenia konieczności ponownego równoważenia należy zaplanować wzrost przez zapewnienie, że każdy fragment zawiera wystarczająco dużo wolnego miejsca do obsługi oczekiwanej liczby zmian. Należy również opracować strategie i skrypty umożliwiające szybkie ponowne zrównoważenie fragmentów, jeśli jest to niezbędne.
Dla klucza fragmentu należy użyć stabilnych danych. Jeśli klucz fragmentu zmieni się, może być konieczne przeniesienie odpowiadającego mu elementu danych między fragmentami, co zwiększa ilość pracy wykonywanej przez operacje aktualizacji. Z tego powodu należy unikać tworzenia klucza fragmentu na podstawie potencjalnie nietrwałych informacji. Zamiast tego należy wyszukać atrybuty, które są niezmienne lub w sposób naturalny tworzą klucz.
Upewnij się, że klucze fragmentów są unikatowe. Na przykład należy unikać używania pól typu autoincrement jako klucza fragmentu. W niektórych systemach pola autoinkrementowane nie mogą być koordynowane między fragmentami, co może skutkować tym, że elementy w różnych fragmentach mają ten sam klucz fragmentu.
Wartości typu autoincrement w innych polach, które nie są kluczami fragmentów, również mogą powodować problemy. Na przykład jeśli pola typu autoincrement są używane do generowania unikatowych identyfikatorów, wówczas dwa różne elementy znajdujące się w różnych fragmentach mogą mieć przypisany ten sam identyfikator.
Może nie być możliwe zaprojektowanie klucza fragmentu, który spełni wymagania każdego możliwego zapytania dotyczącego danych. Pofragmentuj dane w celu obsługi najczęściej wykonywanych zapytań, a w razie potrzeby utwórz tabele indeksów pomocniczych do obsługi zapytań, które pobierają dane przy użyciu kryteriów opartych na atrybutach niebędących częścią klucza fragmentu. Aby uzyskać więcej informacji, zobacz wzorzec indeksowania tabeli.
Zapytania, które uzyskują dostęp tylko do jednego fragmentu, są bardziej wydajne niż te, które pobierają dane z wielu fragmentów, dlatego należy unikać implementowania systemu fragmentowania, jeśli skutkuje to wykonywaniem przez aplikacje wielu zapytań, które łączą dane przechowywane w różnych fragmentach. Należy pamiętać, że jeden fragment może zawierać dane dla wielu typów jednostek. Rozważ denormalizację danych w celu przechowywania pokrewnych jednostek, które są często razem wyszukiwane w zapytaniach (na przykład szczegóły klientów i złożone przez nich zamówienia) w jednym fragmencie, aby ograniczyć liczbę oddzielnych odczytów, które wykonuje aplikacja.
Jeśli jednostka w jednym fragmencie odwołuje się do jednostki przechowywanej w innym fragmencie,uwzględnij klucz fragmentu dla drugiej jednostki jako część schematu dla pierwszej jednostki. Może to pomóc w zwiększeniu wydajności zapytań odwołujących się do powiązanych danych w tych fragmentach.
Jeśli aplikacja musi wykonywać zapytania, które pobierają dane z wielu fragmentów, istnieje możliwość pobierania tych danych przy użyciu zadań równoległych. Przykładem są zapytania wielokierunkowe, w których dane z wielu fragmentów są pobierane równolegle, a następnie agregowane w jeden wynik. Jednak to podejście nieuchronnie zwiększa złożoność logiki dostępu do danych rozwiązania.
W przypadku wielu aplikacji utworzenie większej liczby małych fragmentów może być bardziej efektywne niż posiadanie niewielkiej liczby dużych fragmentów, ponieważ może zaoferować większe możliwości równoważenia obciążenia. Może to być również przydatne, jeśli przewidujesz potrzebę migracji fragmentów z jednej lokalizacji fizycznej do innej. Przenoszenie małych fragmentów jest szybsze niż przenoszenie jednego dużego.
Upewnij się, że dla każdego węzła magazynu fragmentów dostępne są zasoby wystarczające do obsługi wymaganej skalowalności, zarówno pod względem rozmiaru danych, jak i przepływności. Aby uzyskać więcej informacji, zobacz sekcję "Projektowanie partycji pod kątem skalowalności" w wskazówki dotyczące partycjonowania danych.
Należy rozważyć replikację danych referencyjnych do wszystkich fragmentów. Jeśli operacja, która pobiera dane z fragmentu, odwołuje się w ramach tego samego zapytania również do danych statycznych lub powoli przenoszonych, należy dodać te dane do fragmentu. Aplikacja może wtedy łatwo pobrać wszystkie dane dla zapytania bez konieczności wykonywania dodatkowej komunikacji dwustronnej z oddzielnym magazynem danych.
Jeśli dane referencyjne przechowywane w wielu fragmentach zmienią się, system musi zsynchronizować te zmiany między wszystkimi fragmentami. System może doświadczyć pewnej niespójności w czasie, kiedy ta synchronizacja jest wykonywana. Jeśli to robisz, musisz zaprojektować aplikacje tak, aby były w stanie sobie z tym radzić.
Utrzymanie integralności referencyjnej i spójności między fragmentami może być trudne, dlatego należy zminimalizować operacje, które wpływają na dane w wielu fragmentach. Jeśli aplikacja musi modyfikować dane w wielu fragmentach, należy ocenić, czy pełna spójność danych jest faktycznie wymagana. Typowym alternatywnym rozwiązaniem w chmurze jest spójność ostateczna. Dane w każdej partycji są aktualizowane oddzielnie i logika aplikacji musi odpowiadać za zapewnianie pomyślnego ukończenia wszystkich aktualizacji, a także obsługę niespójności, które mogą powstać w wyniku wykonywania zapytań na danych w czasie, kiedy ostatecznie spójna operacja jest uruchomiona. Aby uzyskać więcej informacji na temat wdrażania spójności ostatecznej, zobacz Data consistency primer (Podstawy spójności danych).
Konfigurowanie dużej liczby fragmentów i zarządzanie nimi może być wyzwaniem. Zadania, takie jak monitorowanie, tworzenie kopii zapasowej, sprawdzanie spójności i rejestrowanie lub inspekcja, muszą być wykonywane na wielu fragmentach i serwerach, prawdopodobnie przechowywanych w wielu lokalizacjach. Te zadania mogą być implementowane za pomocą skryptów lub innych rozwiązań automatyzacji, ale może to nie wyeliminować całkowicie dodatkowych wymagań administracyjnych.
Fragmenty mogą mieć określoną lokalizację geograficzną, tak aby zawarte w nich dane znajdowały się blisko wystąpień aplikacji, która z nich korzysta. Takie podejście może znacznie poprawić wydajność, ale wymaga dodatkowego rozważenia zadań, które muszą uzyskać dostęp do wielu fragmentów w różnych lokalizacjach.
Kiedy używać tego wzorca
Użyj tego wzorca, gdy magazyn danych prawdopodobnie będzie potrzebował skalowania poza zasoby dostępne dla pojedynczego węzła magazynu, lub aby zwiększyć wydajność przez zmniejszenie rywalizacji w magazynie danych.
Uwaga
Głównym celem fragmentowania jest zwiększenie wydajności i skalowalności systemu, ale przy okazji może ono również zwiększyć dostępność ze względu na sposób podziału danych na oddzielne partycje. Błąd w jednej partycji nie musi uniemożliwiać aplikacji dostępu do danych przechowywanych w innych partycjach, a operator może wykonywać konserwację lub odzyskiwanie jednej lub kilku partycji bez zabierania dostępu do danych całej aplikacji. Aby uzyskać więcej informacji, zobacz Data Partitioning Guidance (Wskazówki dotyczące partycjonowania danych).
Projekt obciążenia
Architekt powinien ocenić, w jaki sposób wzorzec fragmentowania może być używany w projekcie obciążenia, aby sprostać celom i zasadom opisanym w filarach platformy Azure Well-Architected Framework. Na przykład:
| Filar | Jak ten wzorzec obsługuje cele filaru |
|---|---|
| Decyzje projektowe dotyczące niezawodności pomagają obciążeniu stać się odporne na awarię i zapewnić, że zostanie przywrócony do w pełni funkcjonalnego stanu po wystąpieniu awarii. | Ponieważ dane lub przetwarzanie są odizolowane od fragmentu, awaria jednego fragmentu pozostaje odizolowana od tego fragmentu. - PARTYcjonowanie danych RE:06 - RE:07 Self-preservation |
| Optymalizacja kosztów koncentruje się na utrzymaniu i poprawie zwrotu obciążenia z inwestycji. | System, który implementuje fragmenty, często korzysta z wielu wystąpień mniej kosztownych zasobów obliczeniowych lub magazynowych, a nie jednego droższego zasobu. W wielu przypadkach ta konfiguracja może zaoszczędzić pieniądze. - KOSZT SKŁADNIKA CO:07 |
| Wydajność pomaga wydajnie sprostać zapotrzebowaniu dzięki optymalizacjom skalowania, danych, kodu. | W przypadku używania fragmentowania w strategii skalowania dane lub przetwarzanie są izolowane do fragmentu, więc rywalizują o zasoby tylko z innymi żądaniami kierowanymi do tego fragmentu. Fragmentowanie można również użyć do optymalizacji na podstawie lokalizacji geograficznej. - PE:05 Skalowanie i partycjonowanie - PE:08 Wydajność danych |
Podobnie jak w przypadku każdej decyzji projektowej, należy rozważyć wszelkie kompromisy w stosunku do celów innych filarów, które mogą zostać wprowadzone przy użyciu tego wzorca.
Przykład
Rozważmy witrynę internetową, która przedstawia ekspansywną kolekcję informacji na temat opublikowanych książek na całym świecie. Liczba możliwych książek w katalogu w tym obciążeniu oraz typowe wzorce zapytań/użycia oznaczają użycie pojedynczej relacyjnej bazy danych do przechowywania informacji o książce. Architekt obciążenia decyduje się na fragmentowanie danych w wielu wystąpieniach bazy danych przy użyciu statycznego numeru isBN (International Standard Book Number) książek dla klucza fragmentu. W szczególności używają cyfry kontrolnej (0–10) ISBN, ponieważ daje 11 możliwych fragmentów logicznych, a dane będą dość zrównoważone w każdym fragmentie. Na początek decydują się na przeniesienie 11 logicznych fragmentów do trzech fizycznych baz danych fragmentów. Używają podejścia do fragmentowania odnośników i przechowują informacje mapowania klucz-serwer w bazie danych mapy fragmentów.
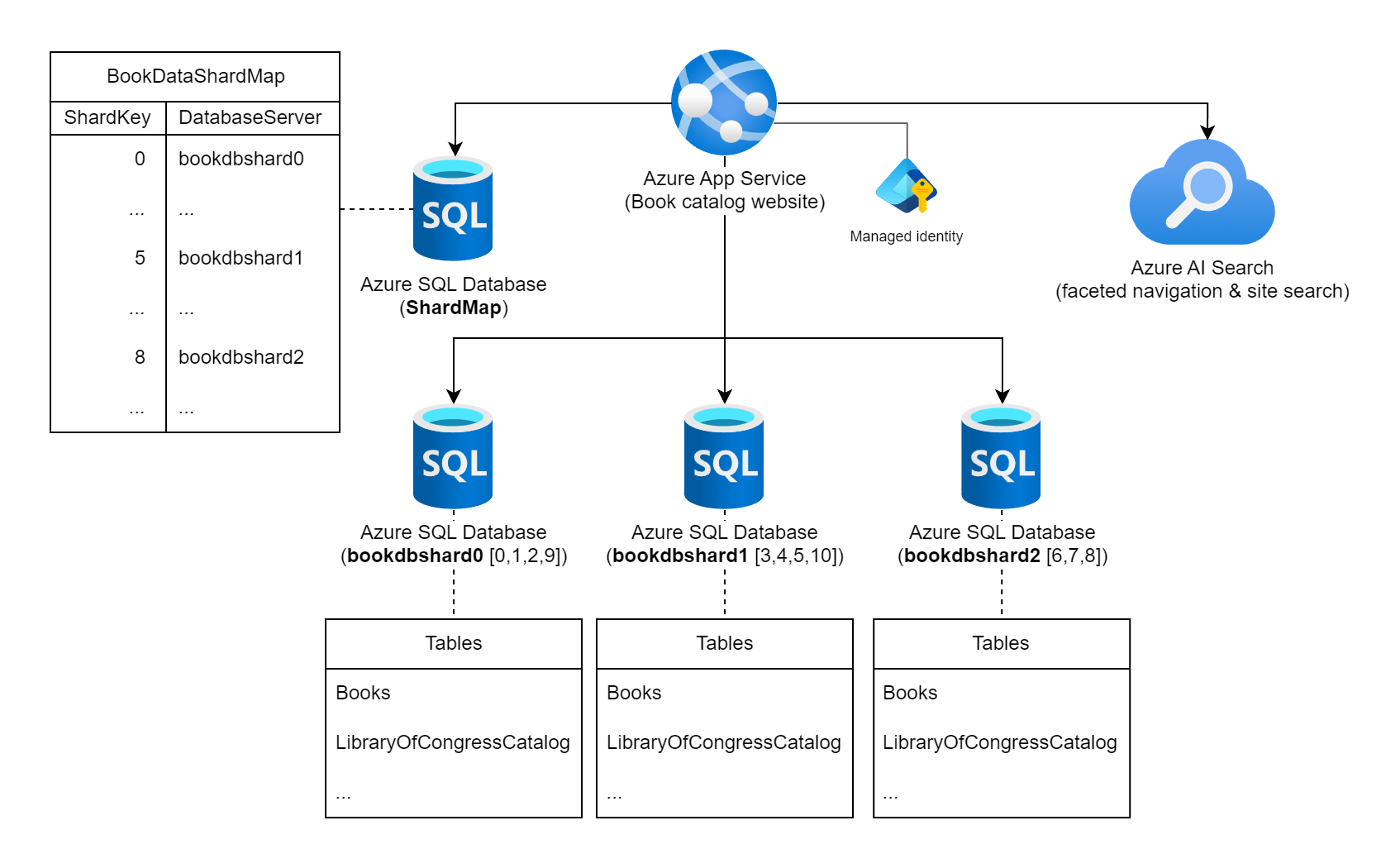
Diagram przedstawiający usługę aplikacja systemu Azure o nazwie "Witryna internetowa wykazu książek", która jest połączona z wieloma wystąpieniami usługi Azure SQL Database i wystąpieniem usługi Azure AI Search. Jedna z baz danych jest oznaczona jako baza danych ShardMap i zawiera przykładową tabelę, która odzwierciedla część tabeli mapowania, która jest również wymieniona w dalszej części tego dokumentu. Istnieją również trzy wystąpienia baz danych fragmentów: bookdbshard0, bookdbshard1 i bookdbshard2. Każda z baz danych zawiera przykładową listę tabel pod nimi. Wszystkie trzy przykłady są identyczne, wymieniając tabele "Books" i "LibraryOfCongressCatalog" oraz wskaźnik większej liczby tabel. Ikona azure AI Search wskazuje, że jest używana do nawigacji aspektowej i wyszukiwania w witrynie. Tożsamość zarządzana jest wyświetlana z usługą aplikacja systemu Azure Service.
Mapa fragmentów odnośników
Baza danych mapy fragmentów zawiera następującą tabelę mapowania fragmentów i dane.
SELECT ShardKey, DatabaseServer
FROM BookDataShardMap
| ShardKey | DatabaseServer |
|----------|----------------|
| 0 | bookdbshard0 |
| 1 | bookdbshard0 |
| 2 | bookdbshard0 |
| 3 | bookdbshard1 |
| 4 | bookdbshard1 |
| 5 | bookdbshard1 |
| 6 | bookdbshard2 |
| 7 | bookdbshard2 |
| 8 | bookdbshard2 |
| 9 | bookdbshard0 |
| 10 | bookdbshard1 |
Przykładowy kod witryny internetowej — dostęp do pojedynczego fragmentu
Witryna internetowa nie zna liczby fizycznych baz danych fragmentów (trzy w tym przypadku) ani logiki, która mapuje klucz fragmentu na wystąpienie bazy danych, ale witryna internetowa nie wie, że cyfra kontrolna ISBN książki powinna być traktowana jako klucz fragmentu. Witryna internetowa ma dostęp tylko do odczytu do bazy danych mapy fragmentów i dostępu do odczytu i zapisu we wszystkich bazach danych fragmentów. W tym przykładzie witryna internetowa korzysta z tożsamości zarządzanej systemu usługi aplikacja systemu Azure Service, która hostuje witrynę internetową do autoryzacji w celu zachowania wpisów tajnych poza parametry połączenia.
Witryna internetowa jest skonfigurowana przy użyciu następujących parametry połączenia w appsettings.json pliku, na przykład w tym przykładzie lub za pomocą ustawień aplikacji usługi App Service.
{
...
"ConnectionStrings": {
"ShardMapDb": "Data Source=tcp:<database-server-name>.database.windows.net,1433;Initial Catalog=ShardMap;Authentication=Active Directory Default;App=Book Site v1.5a",
"BookDbFragment": "Data Source=tcp:SHARD.database.windows.net,1433;Initial Catalog=Books;Authentication=Active Directory Default;App=Book Site v1.5a"
},
...
}
Gdy dostępne są informacje o połączeniu z bazą danych mapy fragmentów, przykład zapytania aktualizacji wykonywanego przez witrynę internetową do puli fragmentów bazy danych obciążenia będzie wyglądać podobnie do poniższego kodu.
...
// All data for this book is stored in a shard based on the book's ISBN check digit,
// which is converted to an integer 0 - 10 (special value 'X' becomes 10).
int isbnCheckDigit = book.Isbn.CheckDigitAsInt;
// Establish a pooled connection to the database shard for this specific book.
using (SqlConnection sqlConn = await shardedDatabaseConnections.OpenShardConnectionForKeyAsync(key: isbnCheckDigit, cancellationToken))
{
// Update the book's Library of Congress catalog information
SqlCommand cmd = sqlConn.CreateCommand();
cmd.CommandText = @"UPDATE LibraryOfCongressCatalog
SET ControlNumber = @lccn,
...
Classification = @lcc
WHERE BookID = @bookId";
cmd.Parameters.AddWithValue("@lccn", book.LibraryOfCongress.Lccn);
...
cmd.Parameters.AddWithValue("@lcc", book.LibraryOfCongress.Lcc);
cmd.Parameters.AddWithValue("@bookId", book.Id);
await cmd.ExecuteNonQueryAsync(cancellationToken);
}
...
W poprzednim przykładowym kodzie, jeśli book.Isbn wartość to 978-8-1130-1024-6, isbnCheckDigit powinna to być wartość 6. Wywołanie metody do OpenShardConnectionForKeyAsync(6) jest zwykle implementowane przy użyciu podejścia z odkładaniem do pamięci podręcznej. Wysyła zapytanie do bazy danych mapy fragmentów zidentyfikowanych z parametry połączeniaShardMapDb, jeśli nie ma buforowanych informacji o fragmentach dla klucza fragmentu 6. Z pamięci podręcznej aplikacji lub z bazy danych fragmentów wartość bookdbshard2 ma miejsce SHARD w BookDbFragment parametry połączenia. Połączenie w puli jest (ponownie) ustanowione w celu bookdbshard2.database.windows.net, otwarcia i zwrócenia do kodu wywołującego. Następnie kod aktualizuje istniejący rekord w tym wystąpieniu bazy danych.
Przykładowy kod witryny internetowej — dostęp do wielu fragmentów
W rzadkich przypadkach zapytanie obejmujące wiele fragmentów jest wymagane przez witrynę internetową, aplikacja wykonuje równoległe zapytanie fan-out we wszystkich fragmentach.
...
// Retrieve all shard keys
var shardKeys = shardedDatabaseConnections.GetAllShardKeys();
// Execute the query, in a fan-out style, against each shard in the shard list.
Parallel.ForEachAsync(shardKeys, async (shardKey, cancellationToken) =>
{
using (SqlConnection sqlConn = await shardedDatabaseConnections.OpenShardConnectionForKeyAsync(key: shardKey, cancellationToken))
{
SqlCommand cmd = sqlConn.CreateCommand();
cmd.CommandText = @"SELECT ...
FROM ...
WHERE ...";
SqlDataReader reader = await cmd.ExecuteReaderAsync(cancellationToken);
while (await reader.ReadAsync(cancellationToken))
{
// Read the results in to a thread-safe data structure.
}
reader.Close();
}
});
...
Alternatywą dla zapytań obejmujących wiele fragmentów w tym obciążeniu może być użycie zewnętrznego indeksu w usłudze Azure AI Search, takiego jak wyszukiwanie witryn lub funkcje nawigacji aspektowej.
Dodawanie wystąpień fragmentów
Zespół ds. obciążeń zdaje sobie sprawę, że jeśli katalog danych lub jego współbieżne użycie znacznie wzrośnie znacznie więcej niż trzy wystąpienia bazy danych, może być wymagane. Zespół ds. obciążeń nie spodziewa się dynamicznego dodawania serwerów baz danych i będzie znosić przestoje obciążeń, jeśli nowy fragment musi być w trybie online. Przeniesienie nowego wystąpienia fragmentu w tryb online wymaga przeniesienia danych z istniejących fragmentów do nowego fragmentu wraz z aktualizacją tabeli mapy fragmentów. To dość statyczne podejście umożliwia obciążeniu pewnie buforowanie mapowania bazy danych klucza fragmentu w kodzie witryny internetowej.
Logika klucza fragmentu w tym przykładzie ma górny górny limit wynoszący 11 maksymalnych fragmentów fizycznych. Jeśli zespół obciążeń wykonuje testy szacowania obciążenia i ocenia, że w końcu będzie potrzebnych więcej niż 11 wystąpień baz danych, należy wprowadzić inwazyjną zmianę logiki klucza fragmentu. Ta zmiana obejmuje staranne planowanie modyfikacji kodu i migracji danych do nowej logiki klucza.
Funkcje zestawu SDK
Zamiast pisać kod niestandardowy na potrzeby zarządzania fragmentami i routingu zapytań do wystąpień usługi Azure SQL Database, oceń bibliotekę klienta elastic database. Ta biblioteka obsługuje zarządzanie mapami fragmentów, routing zapytań zależnych od danych i zapytania krzyżowe w języku C# i Java.
Następne kroki
Podczas implementowania tego wzorca mogą być istotne następujące wskazówki:
- Podstawy spójności danych. Może być konieczne utrzymanie spójności danych rozproszonych między różne fragmenty. Podsumowuje zagadnienia związane z utrzymywaniem zgodności danych rozproszonych i opisuje korzyści i kompromisy dla różnych modeli spójności.
- Data Partitioning Guidance (Wskazówki dotyczące partycjonowania danych). Fragmentowanie magazynu może wprowadzić szereg dodatkowych problemów. W tym artykule opisano te problemy w odniesieniu do partycjonowania magazynu danych w chmurze, aby poprawić skalowalność, zmniejszyć rywalizację i zoptymalizować wydajność.
Powiązane zasoby
Podczas implementowania tego wzorca mogą być również istotne następujące wzorce:
- Wzorzec indeksowania tabeli. Czasami niemożliwe jest pełne obsługiwanie zapytań tylko przy użyciu projektu klucza fragmentu. Umożliwia aplikacji szybkie pobieranie danych z dużego magazynu danych, określając klucz inny niż klucz fragmentu.
- Materialized View pattern (Wzorzec zmaterializowanego widoku). Aby zachować wydajność niektórych operacji zapytań, warto utworzyć zmaterializowane widoki, które agregują i podsumowują dane, zwłaszcza jeśli te dane podsumowania są oparte na informacjach rozproszonych między fragmentami. Opisuje sposób generowania i wypełniania tych widoków.