Koordynuj zestaw rozproszonych działań jako jedną operację. Jeśli jakakolwiek z akcji zakończy się niepowodzeniem, spróbuj obsłużyć awarie w sposób niewidoczny dla użytkownika, ewentualnie cofnij już wykonaną pracę tak, aby w efekcie cała operacja zakończyła się pomyślnie lub niepowodzeniem jako całość. Może to zapewnić dodatkową odporność rozproszonego systemu, umożliwiając mu powrót do prawidłowego działania i ponawianie akcji, które kończą się niepowodzeniem z powodu przejściowych wyjątków, długotrwałych błędów i awarii procesów.
Kontekst i problem
Aplikacja wykonuje zadania złożone z wielu kroków, w tym kroków wywołujących zdalne usługi lub uzyskujących dostęp do zdalnych zasobów. Poszczególne kroki mogą być od siebie niezależne, ale są koordynowane przez logikę aplikacji, która implementuje zadanie.
Jeśli to możliwe, aplikacja powinna upewniać się, że uruchamiane zadanie zostaje ukończone, i rozwiązywać błędy, które mogą wystąpić podczas uzyskiwania dostępu do zdalnych usług lub zasobów. Przyczyny występowania błędów mogą być różne. Może to być na przykład niedziałająca sieć, przerwana komunikacja, brak odpowiedzi lub niestabilny stan zdalnej usługi lub tymczasowy brak dostępu do zdalnego zasobu na skutek ograniczeń zasobów. W wielu przypadkach będą to błędy przejściowe i mogą być obsługiwane za pomocą Wzorca ponawiania.
Jeśli aplikacja wykryje trwalszy błąd uniemożliwiający łatwe odzyskanie sprawności, musi być w stanie przywrócić system do spójnego stanu i zapewnić integralność całej operacji.
Rozwiązanie
Wzorzec nadzorcy agenta harmonogramu definiuje następujących aktorów. Aktorzy ci organizują kroki, które mają być wykonane w ramach całego zadania.
Harmonogram odpowiada za wykonanie kroków składających się na zadanie i organizuje ich działanie. Kroki te można połączyć w potok lub przepływ pracy. Harmonogram odpowiada za to, aby kroki zawarte w tym przepływie pracy były wykonywane w odpowiedniej kolejności. W miarę wykonywania każdego kroku harmonogram rejestruje stan przepływu pracy, taki jak "krok jeszcze nie został uruchomiony", "krok uruchomiony" lub "krok ukończony". Informacje o stanie powinny również zawierać górny limit czasu dozwolonego na zakończenie kroku, nazywany czasem ukończenia. Jeśli krok wymaga dostępu do zdalnej usługi lub zasobu, harmonogram wywołuje odpowiedniego agenta, przekazując mu szczegóły pracy do wykonania. Harmonogram zwykle komunikuje się z agentem przy użyciu asynchronicznych komunikatów żądania/odpowiedzi. Można to zaimplementować przy użyciu kolejek, choć można także użyć innych technologii obsługi komunikatów rozproszonych.
Harmonogram pełni funkcję podobną do menedżera procesów we wzorcu menedżera procesów. Faktyczny przepływ pracy jest zwykle definiowany i implementowany przez aparat przepływu pracy kontrolowany przez harmonogram. To podejście pozwala oddzielić logikę biznesową przepływu pracy od harmonogramu.
Agent zawiera logikę, która hermetyzuje wywołanie usługi zdalnej lub dostęp do zdalnego zasobu, do których odwołuje się krok zadania. Każdy agent opakowuje zwykle wywołania jednej usługi lub zasobu, implementując odpowiednią logikę ponawiania prób i obsługi błędów (podlegającą ograniczeniom związanym z limitem czasu opisanym w dalszej części). Podczas implementowania logiki ponawiania należy przekazać stabilny identyfikator we wszystkich próbach ponawiania prób, aby usługa zdalna mogła jej używać dla dowolnej logiki deduplikacji. Jeśli kroki wykonywanego przez harmonogram przepływu pracy korzystają z kilku usług i zasobów w ramach różnych kroków, każdy krok może odwoływać się do innego agenta (stanowi to szczegół implementacji wzorca).
Nadzorca monitoruje stan kroków zadania wykonywanego przez harmonogram. Jest uruchamiany okresowo (częstotliwość będzie specyficzna dla systemu) i sprawdza stan kroków obsługiwanych przez harmonogram. W przypadku stwierdzenia przekroczenia limitu czasu lub niepowodzenia któregoś z kroków organizuje odpowiedniego agenta w celu odzyskania sprawności tego kroku lub przeprowadza odpowiednie działania naprawcze (co może się wiązać ze zmianą stanu kroku). Należy pamiętać, że odzyskiwanie sprawności lub działania naprawcze są wykonywane za pomocą harmonogramu i agentów. Nadzorca powinien po prostu zażądać wykonania tych czynności.
Harmonogram, agent i nadzorca są składnikami logicznymi, a ich fizyczna implementacja zależy od używanej technologii. Można na przykład zaimplementować kilka agentów logicznych jako część pojedynczej usługi internetowej.
Harmonogram przechowuje informacje dotyczące postępu zadania i stanu każdego kroku w trwałym magazynie danych, nazywanym magazynem stanów. Nadzorca można użyć tych informacji w celu określenia, czy krok zakończył się niepowodzeniem. Na rysunku przedstawiono relację między harmonogramem, agentami, nadzorcą i magazynem stanów.
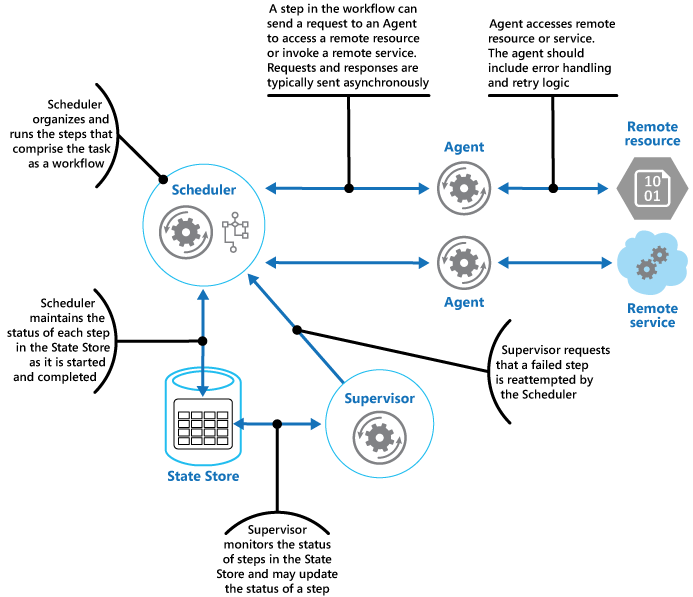
Uwaga
Ten diagram przedstawia uproszczoną wersję wzorca. W rzeczywistej implementacji może istnieć wiele wystąpień harmonogramu działających jednocześnie, z których każde wykonuje podzbiór zadań. System może także uruchomić wiele wystąpień każdego agenta lub nawet kilku nadzorców. W takim przypadku nadzorcy muszą starannie koordynować swoją pracę ze sobą, aby upewnić się, że nie konkurują o odzyskanie tych samych nieudanych kroków i zadań. Wzorzec wyboru lidera zapewnia jedno z możliwych rozwiązań tego problemu.
Gdy aplikacja jest gotowa do uruchomienia zadania, przesyła żądanie do harmonogramu. Harmonogram rejestruje informacje na temat początkowego stanu zadania i jego kroków (np. krok jeszcze nie rozpoczęty) w magazynie stanów, a następnie rozpoczyna wykonywanie operacji określonych przez przepływ pracy. Przy każdym uruchamianym przez harmonogram kroku aktualizuje on informacje o stanie tego kroku w magazynie stanów (np. krok uruchomiony).
Jeśli krok odwołuje się do zdalnej usługi lub zasobu, harmonogram wysyła komunikat do odpowiedniego agenta. Komunikat zawiera informacje o tym, że agent musi przekazać informacje do usługi lub uzyskać dostęp do zasobu, a także czas ukończenia dla operacji. Jeśli agent pomyślnie zakończy operację, zwraca odpowiedź do harmonogramu. Harmonogram może wtedy zaktualizować informacje o stanie w magazynie stanów (np. krok ukończony) i wykonać kolejny krok. Ten proces jest kontynuowany do momentu wykonania całego zadania.
Agent może implementować dowolną logikę ponowień, która jest niezbędna do wykonania pracy. Jeśli jednak agent nie wykona pracy przed upływem okresu ukończenia, harmonogram przyjmie, że operacja zakończyła się niepowodzeniem. W takim przypadku agent powinien przerwać pracę i nie podejmować próby zwracania czegokolwiek do harmonogramu (nawet komunikatu o błędzie) ani jakichkolwiek prób odzyskiwania sprawności. Przyczyną tego ograniczenia jest to, że jeśli upłynie limit czasu kroku lub krok zakończy się niepowodzeniem, uruchomienie takiego nieudanego kroku może być zaplanowane w innym wystąpieniu agenta (ten proces jest opisany w dalszej części).
W przypadku niepowodzenia agenta harmonogram nie otrzyma odpowiedzi. Wzorzec nie dokonuje rozróżnienia między krokiem, w przypadku którego upłynął limit czasu, i tym, który faktycznie zakończył się niepowodzeniem.
Jeśli krok zakończy się niepowodzeniem lub upłynie limit czasu, magazyn stanów będzie zawierać rekord wskazujący na to, że krok został uruchomiony, ale upłynął jego czas ukończenia. Nadzorca szuka tego typu kroków i próbuje odzyskać ich sprawność. Jedną z możliwych strategii jest zaktualizowanie wartości complete-by przez nadzorcę w celu wydłużenia czasu dostępnego do ukończenia kroku, a następnie wysłanie komunikatu do harmonogramu identyfikującego przekroczony limit czasu. Harmonogram może następnie spróbować powtórzyć ten krok. Jednak ten projekt wymaga, aby zadania są idempotentne. System powinien zawierać infrastrukturę w celu zachowania spójności. Aby uzyskać więcej informacji, zobacz Repeatable Infrastructure (Powtarzalna infrastruktura), Architect Azure applications for resiliency and availability (Powtarzalna infrastruktura), Architect Azure applications for resiliency and availability (Architektura aplikacji platformy Azure pod kątem odporności i dostępności) oraz Resource consistency decision guide (Przewodnik po decyzjach dotyczących spójności zasobów).
W przypadku ciągłego niepowodzenia lub limitu czasu nadzorca może być konieczne uniemożliwienie ponownego wykonania tego samego kroku. W tym celu nadzorca może zachować liczbę ponownych prób dla każdego kroku wraz z informacjami o stanie w magazynie stanów. Jeśli liczba ta przekroczy wstępnie zdefiniowany próg, nadzorca może podjąć strategię oczekiwania przez dłuższy czas, zanim powiadomi harmonogram, że krok powinien zostać ponowiony, w oczekiwaniu, że w tym czasie błąd zostanie usunięty. Nadzorca może także wysłać komunikat do harmonogramu z żądaniem cofnięcia całego zadania przez zaimplementowanie wzorca transakcji wyrównującej. Ta metoda będzie zależeć od udostępniania przez harmonogram i agentów informacji niezbędnych do zaimplementowania operacji wyrównującej dla każdego kroku, który został ukończony pomyślnie.
Celem nadzorcy nie jest monitorowanie harmonogramu i agentów ani ich ponowne uruchamianie w razie awarii. Ten aspekt systemu powinien być obsługiwany przez infrastrukturę, w ramach której te składniki działają. Analogicznie nadzorca nie powinien mieć wiedzy na temat rzeczywistych operacji biznesowych uruchamianych przez zadania wykonywane przez harmonogram (w tym sposobu wyrównywania w przypadku niepowodzenia tych zadań). Odpowiada za to logika przepływu pracy implementowana przez harmonogram. Wyłączna odpowiedzialność nadzorcy polega na określeniu, czy krok zakończył się niepowodzeniem, i zadbaniu o powtórzenie tego kroku lub cofnięcie całego zadania zawierającego krok zakończony niepowodzeniem.
Jeśli harmonogram został ponownie uruchomiony po awarii lub nastąpiło nieoczekiwane zakończenie wykonywanego przez harmonogram przepływu pracy, harmonogram powinien móc ustalić stan każdego zadania wykonywanego w czasie, gdy doszło do awarii, oraz być przygotowany do wznowienia tego zadania od tego momentu. Szczegóły implementacji tego procesu prawdopodobnie będą specyficzne dla systemu. Jeśli zadanie nie może zostać odzyskane, może być konieczne cofnięcie pracy wykonanej już przez to zadanie. Może to również wymagać zaimplementowania transakcji wyrównującej.
Główną zaletą tego wzorca jest odporność systemu w przypadku nieoczekiwanych tymczasowych lub nieodwracalnych awarii. System można skonstruować tak, aby był samonaprawiony. Jeśli na przykład ulegnie awarii agent lub harmonogram, może zostać uruchomiony nowy, a nadzorca może zadbać o wznowienie zadania. W przypadku awarii nadzorcy może zostać uruchomione inne wystąpienie i przejąć zadania od miejsca, gdzie wystąpił błąd. Jeśli zaplanowano okresowe uruchamianie nadzorcy, nowe wystąpienie może być automatycznie uruchamiane po upływie wstępnie zdefiniowanego przedziału czasu. Magazyn stanów może być replikowany w celu zapewnienia jeszcze większego stopnia odporności.
Problemy i kwestie do rozważenia
Podczas podejmowania decyzji o sposobie wdrażania tego wzorca należy rozważyć następujące kwestie:
Ten wzorzec może być trudny do zaimplementowania i wymaga dokładnego przetestowania każdego trybu awaryjnego systemu.
Logika odzyskiwania/ponawiania zaimplementowana przez harmonogram jest złożona i zależna od informacji o stanie przechowywanych w magazynie stanów. Konieczne może być również rejestrowanie w trwałym magazynie danych informacji wymaganych do zaimplementowania transakcji wyrównującej. Transakcja wyrównywająca również może zakończyć się niepowodzeniem.
Ważne będzie to, jak często nadzorca jest uruchamiany. Powinien być uruchamiany wystarczająco często, aby zapobiegać blokowaniu przez dłuższy czas aplikacji przez kroki, które zakończyły się niepowodzeniem, ale nie na tyle często, aby stanowić obciążenie.
Kroki wykonywane przez agenta mogą być uruchamiane więcej niż jednokrotnie. Logika odpowiadająca za implementację tych kroków powinna być idempotentna.
Kiedy używać tego wzorca
Użyj tego wzorca, jeśli proces uruchamiany w środowisku rozproszonym, takim jak chmura, musi być odporny na błędy komunikacji i/lub błędy operacyjne.
Ten wzorzec może nie być odpowiedni w przypadku zadań, które nie wywołują usług zdalnych lub uzyskują dostępu do zdalnych zasobów.
Projekt obciążenia
Architekt powinien ocenić, w jaki sposób wzorzec nadzorcy agenta harmonogramu może być używany w projekcie obciążenia, aby sprostać celom i zasadom opisanym w filarach platformy Azure Well-Architected Framework. Na przykład:
| Filar | Jak ten wzorzec obsługuje cele filaru |
|---|---|
| Decyzje projektowe dotyczące niezawodności pomagają obciążeniu stać się odporne na awarię i zapewnić, że zostanie przywrócony do w pełni funkcjonalnego stanu po wystąpieniu awarii. | Ten wzorzec używa metryk kondycji do wykrywania błędów i przekierowywania zadań do agenta w dobrej kondycji w celu ograniczenia skutków awarii. - Nadmiarowość RE:05 - RE:07 Samonaprawiania |
| Wydajność pomaga wydajnie sprostać zapotrzebowaniu dzięki optymalizacjom skalowania, danych, kodu. | Ten wzorzec używa metryk wydajności i pojemności do wykrywania bieżącego użycia i kierowania zadań do agenta, który ma pojemność. Można go również użyć do nadania priorytetowi wykonywania pracy o wyższym priorytcie nad pracą o niższym priorytcie. - PE:05 Skalowanie i partycjonowanie - PE:09 Przepływy krytyczne |
Podobnie jak w przypadku każdej decyzji projektowej, należy rozważyć wszelkie kompromisy w stosunku do celów innych filarów, które mogą zostać wprowadzone przy użyciu tego wzorca.
Przykład
Na platformie Microsoft Azure wdrożona została aplikacja internetowa, która implementuje system do obsługi handlu elektronicznego. Użytkownicy mogą uruchamiać tę aplikację, aby przeglądać dostępne produkty i składać zamówienia. Interfejs użytkownika działa jako rola internetowa, a elementy aplikacji odpowiedzialne za przetwarzanie zamówień są zaimplementowane jako zestaw ról procesów roboczych. Część logiki przetwarzania zamówień polega na uzyskiwaniu dostępu do zdalnej usługi i ten aspekt systemu może być podatny na przejściowe lub długotrwałe błędy. Z tego powodu projektanci użyli wzorca nadzorcy agenta harmonogramu do zaimplementowania elementów systemu odpowiedzialnych za przetwarzanie zamówień.
Gdy klient składa zamówienie, aplikacja tworzy komunikat opisujący zamówienie i zapisuje ten komunikat do kolejki. Osobny proces przesyłania, uruchomiony w roli procesu roboczego, pobiera komunikat, wstawia szczegóły zamówienia do bazy danych zamówień i tworzy rekord dla procesu zamówień w magazynie stanów. Należy pamiętać, że operacje wstawiania do bazy danych zamówień i magazynu stanów są wykonywane w ramach tej samej operacji. Proces przesyłania ma zapewnić, że obie operacje wstawiania zakończą się powodzeniem.
Informacje o stanie tworzone przez proces przesyłania dla zamówienia obejmują:
OrderID. Identyfikator zamówienia w bazie danych zamówień.
LockedBy. Identyfikator wystąpienia roli procesu roboczego obsługującego zamówienie. Może istnieć wiele bieżących wystąpień roli procesu roboczego obsługujących harmonogram, ale każde zamówienie powinno być obsługiwane tylko przez jedno wystąpienie.
CompleteBy. Czas, w jakim zamówienie powinno zostać przetworzone.
ProcessState. Bieżący stan zadania obsługującego zamówienie. Możliwe stany to:
- Oczekujące. Zamówienie zostało utworzone, ale przetwarzanie nie zostało jeszcze rozpoczęte.
- Przetwarzanie. Zamówienie jest obecnie przetwarzane.
- Przetworzone. Zamówienie zostało przetworzone pomyślnie.
- Błąd. Przetwarzanie zamówienia zakończyło się niepowodzeniem.
FailureCount. Liczba ponowień próby przetwarzania zamówienia.
W ramach tych informacji o stanie pole OrderID jest kopiowane z identyfikatora zamówienia nowego zamówienia. Wartości pól LockedBy i CompleteBy są ustawione na null, wartość pola ProcessState jest ustawiona na Pending, a pola FailureCount na 0.
Uwaga
W tym przykładzie logika obsługi zamówień jest stosunkowo prosta i zawiera tylko jeden krok, który wywołuje usługę zdalną. W bardziej złożonym scenariuszu wieloetapowym proces przesyłania prawdopodobnie obejmuje kilka kroków, dlatego w magazynie stanów zostanie utworzonych kilka rekordów — każdy z nich opisuje stan pojedynczego kroku.
Harmonogram jest także uruchamiany jako część roli procesu roboczego i implementuje logikę biznesową obsługującą zamówienie. Wystąpienie harmonogramu sondujące pod kątem nowych zamówień sprawdza magazyn stanów, szukając rekordów, w których pole LockedBy ma wartość null i pole ProcessState oznaczone jest jako oczekujące. Gdy harmonogram wykryje nowe zamówienie, natychmiast wypełnia pole LockedBy własnym identyfikatorem wystąpienia, ustawia odpowiedni czas w polu CompleteBy i ustawia pole ProcessState na przetwarzanie. Kod został zaprojektowany jako wyłączny i niepodzielny, co ma zagwarantować, że dwa równoczesne wystąpienia harmonogramu nie mogą próbować obsłużyć jednocześnie tego samego zamówienia.
Harmonogram uruchamia następnie biznesowy przepływ pracy w celu asynchronicznego przetworzenia zamówienia, przekazując wartość w polu OrderID z magazynu stanów. Przepływ pracy obsługujący zamówienie pobiera szczegóły zamówienia z bazy danych zamówień i wykonuje swoją pracę. Jeśli krok przepływu pracy przetwarzania zamówień musi wywołać usługę zdalną, używa agenta. Krok przepływu pracy komunikuje się z agentem przy użyciu pary kolejek komunikatów usługi Azure Service Bus działających jako kanał żądań/odpowiedzi. Na rysunku przedstawiono ogólny widok rozwiązania.
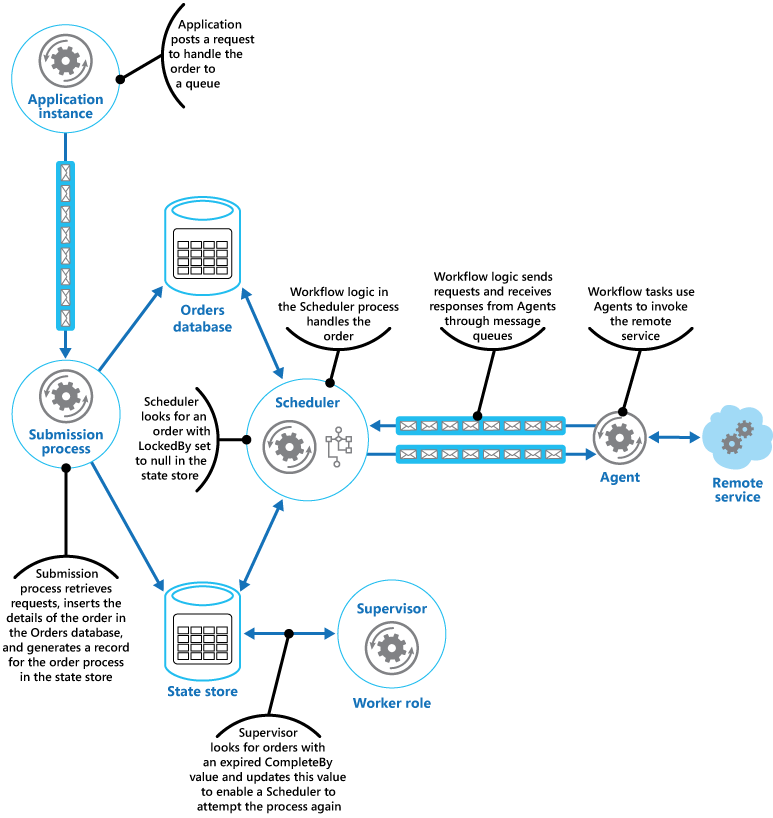
Komunikat wysyłany do agenta z kroku przepływu pracy zawiera opis zamówienia i czas ukończenia. Jeśli agent otrzyma odpowiedź z usługi zdalnej przed upływem czasu ukończenia, zamieszcza komunikat odpowiedzi w kolejce usługi Service Bus, którą przepływ pracy nasłuchuje. Gdy krok przepływu pracy odbiera prawidłowy komunikat odpowiedzi, kończy przetwarzanie, a harmonogram ustawia ProcessState pole stanu zamówienia na przetworzone. W tym momencie przetwarzanie zamówienia zostaje pomyślnie ukończone.
Jeśli czas ukończenia upłynie zanim agent otrzyma odpowiedź ze zdalnej usługi, agent zatrzymuje po prostu przetwarzanie i kończy obsługę zamówienia. Podobnie jeśli przepływ pracy obsługujący zamówienie przekroczy czas ukończenia, także ulega zakończeniu. W obu przypadkach stan zamówienia w magazynie stanów zostanie ustawiony na przetwarzanie, jednak czas ukończenia wskazuje, że czas przetwarzania zamówienia minął i proces zostanie uznany za zakończony niepowodzeniem. Należy pamiętać, że w przypadku nieoczekiwanego zakończenia działania agenta uzyskującego dostęp do zdalnej usługi lub przepływu pracy obsługującego zamówienie (lub obu) wartość informacji w magazynie stanów zostanie ponownie ustawiona na przetwarzanie i po pewnym czasie jej wartość czasu ukończenia wygaśnie.
Jeśli agent wykryje nieodwracalny, nieprzejściowy błąd podczas próby nawiązania kontaktu ze zdalną usługą, może wysłać odpowiedź z informacją o błędzie z powrotem do przepływu pracy. Harmonogram może ustawić stan zamówienia na błąd i wywołać zdarzenie, które powiadomi operatora. Operator może następnie spróbować ręcznie usunąć przyczynę błędu i ponownie przesłać krok, którego przetwarzanie się nie powiodło.
Nadzorca okresowo sprawdza magazyn stanów pod kątem zamówień, których wartość czasu ukończenia wygasła. Jeśli nadzorca znajdzie taki rekord, zwiększa wartość pola FailureCount. Jeśli wartość licznika awarii jest niższa od określonej wartości progowej, nadzorca resetuje pole LockedBy do wartości null, aktualizuje pole CompleteBy z użyciem nowego czasu wygaśnięcia i ustawia pole ProcessState jako oczekujące. Wystąpienie harmonogramu może podjąć to zamówienie i przetworzyć je jak wcześniej. Jeśli wartość licznika awarii przekroczy określoną wartość progową, przyjmuje się, że powód awarii nie jest przejściowy. Harmonogram ustawia stan zamówienia na błąd i wywołuje zdarzenie, które powiadomi operatora.
W tym przykładzie nadzorca jest zaimplementowany w odrębnej roli procesu roboczego. Można użyć różnych strategii przeznaczonych do uruchamiania zadania nadzorcy, w tym usługi Azure Scheduler (nie należy mylić ze składnikiem harmonogramu w tym wzorcu). Aby uzyskać więcej informacji na temat usługi Azure Scheduler, odwiedź stronę usługi Scheduler.
Choć nie pokazano tego w tym przykładzie, konieczne może być, aby harmonogram informował o postępie i stanie zamówienia aplikację, która przesłała zamówienie. Aplikacja i harmonogram są od siebie odizolowane, aby wyeliminować wszelkie zależności między nimi. Aplikacja nie wie, które wystąpienie harmonogramu obsługuje zamówienie, zaś harmonogram nie ma informacji, które konkretnie wystąpienie aplikacji odpowiada za złożenie zamówienia.
Aby umożliwić raportowanie stanu zamówienia, aplikacja może używać własnej prywatnej kolejki odpowiedzi. Szczegóły tej kolejki odpowiedzi będą dołączane jako część żądania wysyłanego do procesu przesyłania, który zamieści te informacje w magazynie stanów. Harmonogram może następnie publikować w tej kolejce komunikaty określające stan zamówienia (odebrano żądanie, zamówienie ukończone, zamówienie zakończone niepowodzeniem itp.). Powinien on uwzględniać w tych komunikatach identyfikator zamówienia, tak aby możliwe było skorelowanie ich z oryginalnym żądaniem aplikacji.
Następne kroki
Podczas implementowania tego wzorca mogą być istotne następujące wskazówki:
Asynchronous Messaging Primer (Podstawy asynchronicznej obsługi komunikatów). Składniki we wzorcu nadzorcy agenta harmonogramu są zazwyczaj uruchamiane niezależnie od siebie i komunikują się asynchronicznie. Opisuje niektóre z metod, które mogą być użyte do zaimplementowania komunikacji asynchronicznej w oparciu o kolejki komunikatów.
Odwołanie 6. Saga o sagach. Przykład przedstawiający sposób wykorzystania przez wzorzec CQRS menedżera procesów (część przewodnika Podróż CQRS).
Powiązane zasoby
Podczas implementowania tego wzorca mogą być również istotne następujące wzorce:
Wzorzec ponawiania. Agent może używać tego wzorca do ponawiania, w sposób niewidoczny dla użytkownika, operacji uzyskującej dostęp do zdalnej usługi lub zasobu, która wcześniej zakończyła się niepowodzeniem. Należy go używać, gdy oczekuje się, że przyczyna błędu ma charakter przejściowy i może zostać usunięta.
Wzorzec wyłącznika. Agent może używać tego wzorca do obsługi błędów, których naprawienie może potrwać zmienną ilość czasu podczas nawiązywania połączenia ze zdalną usługą lub zasobem.
Wzorzec transakcji wyrównującej. Jeśli nie można pomyślnie ukończyć wykonywanego przez harmonogram przepływu pracy, konieczne może być cofnięcie wykonanej wcześniej pracy. Wzorzec transakcji wyrównującej opisuje, jak można to osiągnąć w odniesieniu do operacji, które implementują model spójności ostatecznej. Tego typu operacje są często implementowane przez harmonogram, który wykonuje złożone biznesowe procesy i przepływy pracy.
Wzorzec wyboru lidera. Konieczne może być koordynowanie działań wielu wystąpień nadzorcy, aby zapobiec próbom odzyskiwania przez nie tego samego zakończonego niepowodzeniem procesu. Wzorzec wyboru lidera opisuje, jak to zrobić.
Architektura chmury: wzorzec Scheduler-Agent-Supervisor na blogu Clemens Vasters