Jak wyświetlić wyniki oceny w portalu usługi Azure AI Foundry
Strona oceny portalu usługi Azure AI Foundry to uniwersalne centrum, które umożliwia nie tylko wizualizowanie i ocenę wyników, ale także służy jako centrum sterowania do optymalizowania, rozwiązywania problemów i wybierania idealnego modelu sztucznej inteligencji dla potrzeb związanych z wdrożeniem. Jest to jednorazowe rozwiązanie do podejmowania decyzji i poprawy wydajności opartej na danych w projektach usługi Azure AI Foundry. Możesz bezproblemowo uzyskiwać dostęp do wyników z różnych źródeł, w tym przepływ, sesję szybkiego testowania na placu zabaw, interfejs użytkownika przesyłania oceny i zestaw SDK. Ta elastyczność zapewnia możliwość interakcji z wynikami w sposób, który najlepiej odpowiada twoim przepływom pracy i preferencjom.
Po zwizualizowaniu wyników oceny możesz zapoznać się z dokładnym badaniem. Obejmuje to możliwość nie tylko wyświetlania poszczególnych wyników, ale także porównywania tych wyników w wielu przebiegach oceny. Dzięki temu można identyfikować trendy, wzorce i rozbieżności, uzyskując bezcenny wgląd w wydajność systemu sztucznej inteligencji w różnych warunkach.
Z tego artykułu dowiesz się, jak wykonywać następujące elementy:
- Wyświetl wynik oceny i metryki.
- Porównaj wyniki oceny.
- Omówienie wbudowanych metryk oceny.
- Zwiększ wydajność.
- Wyświetl wyniki oceny i metryki.
Znajdowanie wyników oceny
Po przesłaniu oceny możesz zlokalizować przesłany przebieg oceny na liście uruchomień, przechodząc do strony Ocena .
Możesz monitorować przebiegi oceny i zarządzać nimi na liście przebiegów. Dzięki elastyczności modyfikowania kolumn przy użyciu edytora kolumn i implementowania filtrów można dostosować i utworzyć własną wersję listy uruchamiania. Ponadto możesz szybko przejrzeć zagregowane metryki oceny w ramach przebiegów, umożliwiając szybkie porównywanie.

Napiwek
Aby wyświetlić oceny uruchamiane z dowolną wersją zestawu SDK promptflow-evals lub azure-ai-evaluation w wersji 1.0.0b1, 1.0.0b2, 1.0.0b3, włącz przełącznik "Pokaż wszystkie uruchomienia", aby zlokalizować przebieg.
Aby lepiej zrozumieć, jak są uzyskiwane metryki oceny, możesz uzyskać dostęp do kompleksowego wyjaśnienia, wybierając opcję "Dowiedz się więcej o metrykach". Ten szczegółowy zasób zapewnia cenny wgląd w obliczenia i interpretację metryk używanych w procesie oceny.

Możesz wybrać konkretny przebieg, który spowoduje przejście do strony szczegółów przebiegu. W tym miejscu możesz uzyskać dostęp do kompleksowych informacji, w tym szczegółów oceny, takich jak zestaw danych testowych, typ zadania, monit, temperatura i inne. Ponadto można wyświetlić metryki skojarzone z poszczególnymi przykładami danych. Wykresy wyników metryk zapewniają wizualną reprezentację sposobu dystrybucji wyników dla każdej metryki w całym zestawie danych.
Wykresy pulpitu nawigacyjnego metryk
Podzielimy zagregowane widoki z różnymi typami metryk według jakości sztucznej inteligencji (wspomaganej sztucznej inteligencji), ryzyka i bezpieczeństwa, jakości sztucznej inteligencji (NLP) i niestandardowych, jeśli ma to zastosowanie. Możesz wyświetlić rozkład wyników w ocenianym zestawie danych i wyświetlić zagregowane wyniki dla każdej metryki.
- W przypadku jakości sztucznej inteligencji (AI assisted) agregujemy, obliczając średnią dla wszystkich ocen dla każdej metryki. Jeśli obliczysz wartość Groundedness Pro, dane wyjściowe są binarne, a więc zagregowany wynik jest współczynnik przekazywania, który jest obliczany przez (#trues / #instances) × 100.
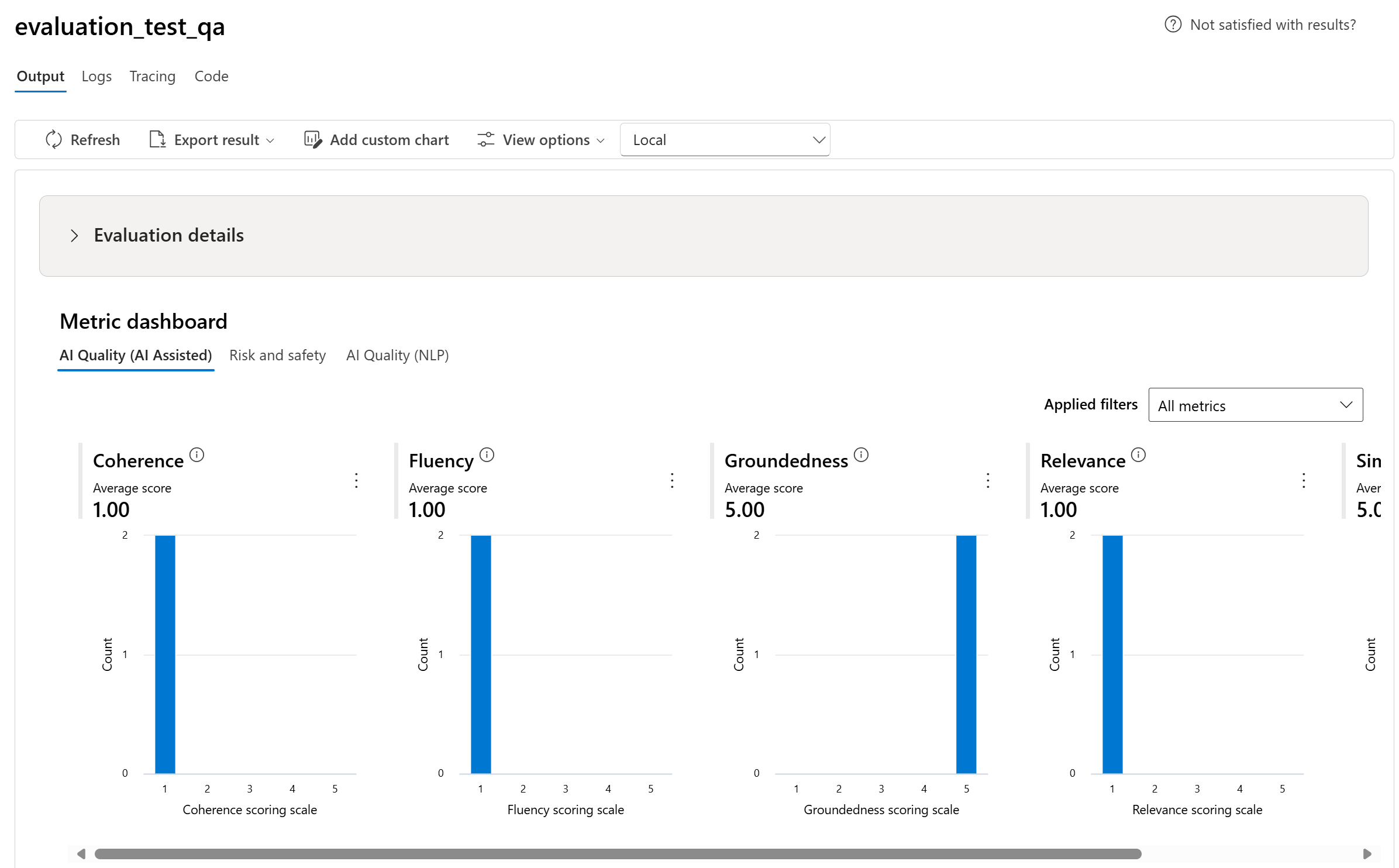
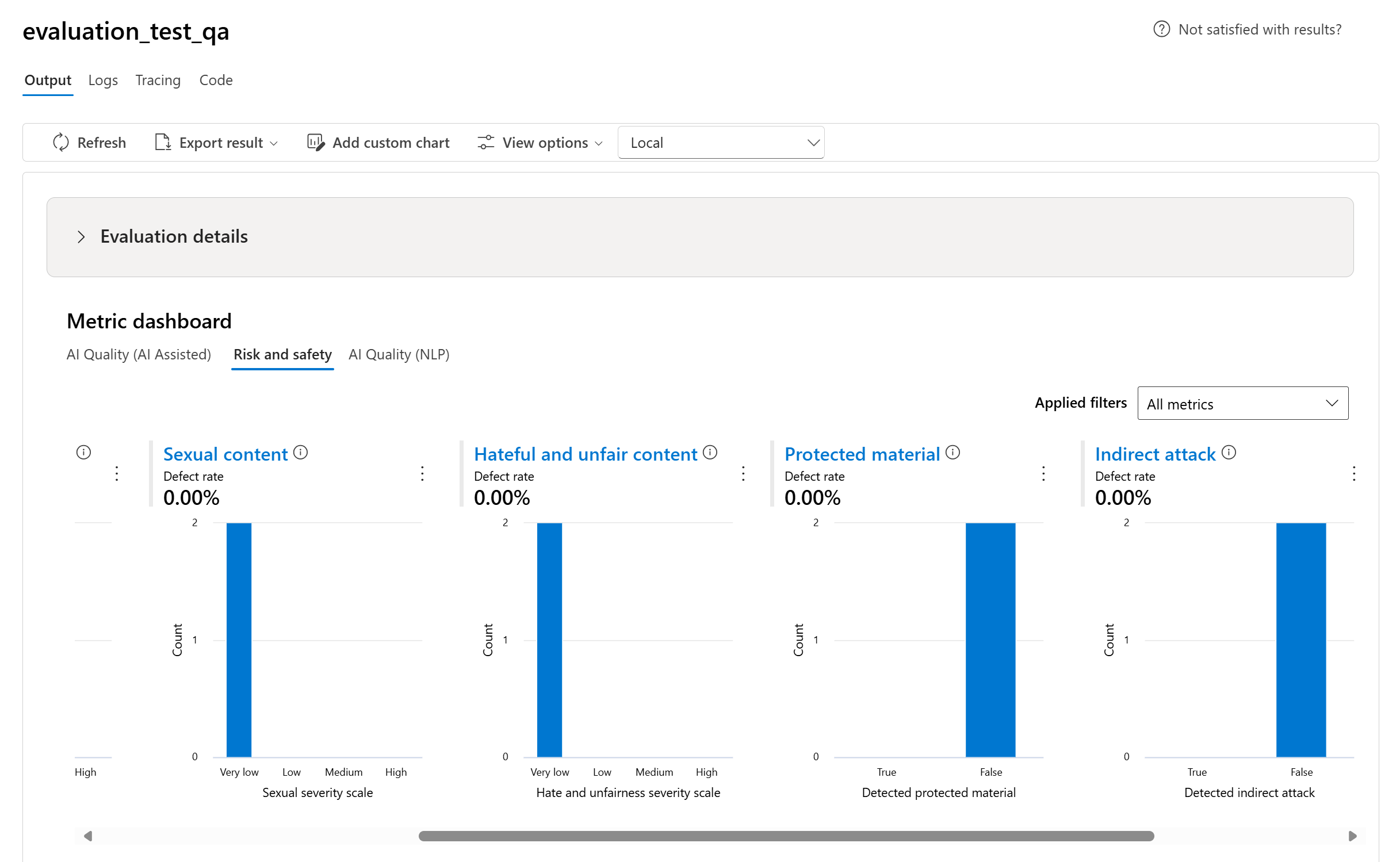
- W przypadku metryk ryzyka i bezpieczeństwa agregujemy, obliczając współczynnik wad dla każdej metryki.
- W przypadku metryk szkody zawartości współczynnik wad jest definiowany jako procent wystąpień w zestawie danych testowych, które przekraczają próg w skali ważności w całym rozmiarze zestawu danych. Domyślnie próg to "Średni".
- W przypadku chronionego materiału i ataku pośredniego współczynnik wad jest obliczany jako procent wystąpień, w których dane wyjściowe są "prawdziwe" (współczynnik wad = (#trues / #instances) × 100).
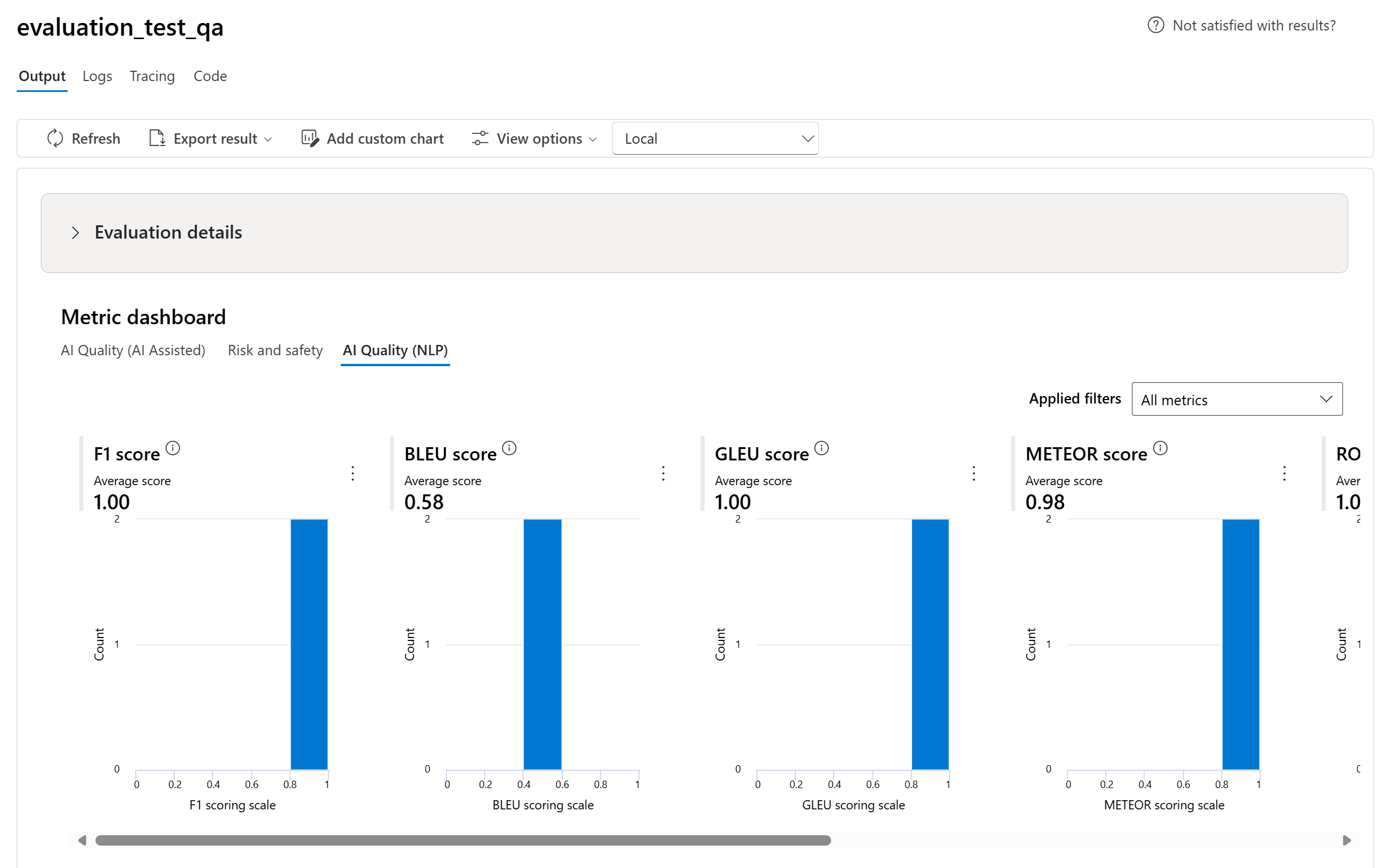
- W przypadku metryk jakości sztucznej inteligencji (NLP) pokazujemy histogram rozkładu metryk z zakresu od 0 do 1. Agregujemy, obliczając średnią dla wszystkich wyników dla każdej metryki.
- W przypadku metryk niestandardowych możesz wybrać pozycję Dodaj wykres niestandardowy, aby utworzyć niestandardowy wykres z wybranymi metrykami lub wyświetlić metrykę względem wybranych parametrów wejściowych.
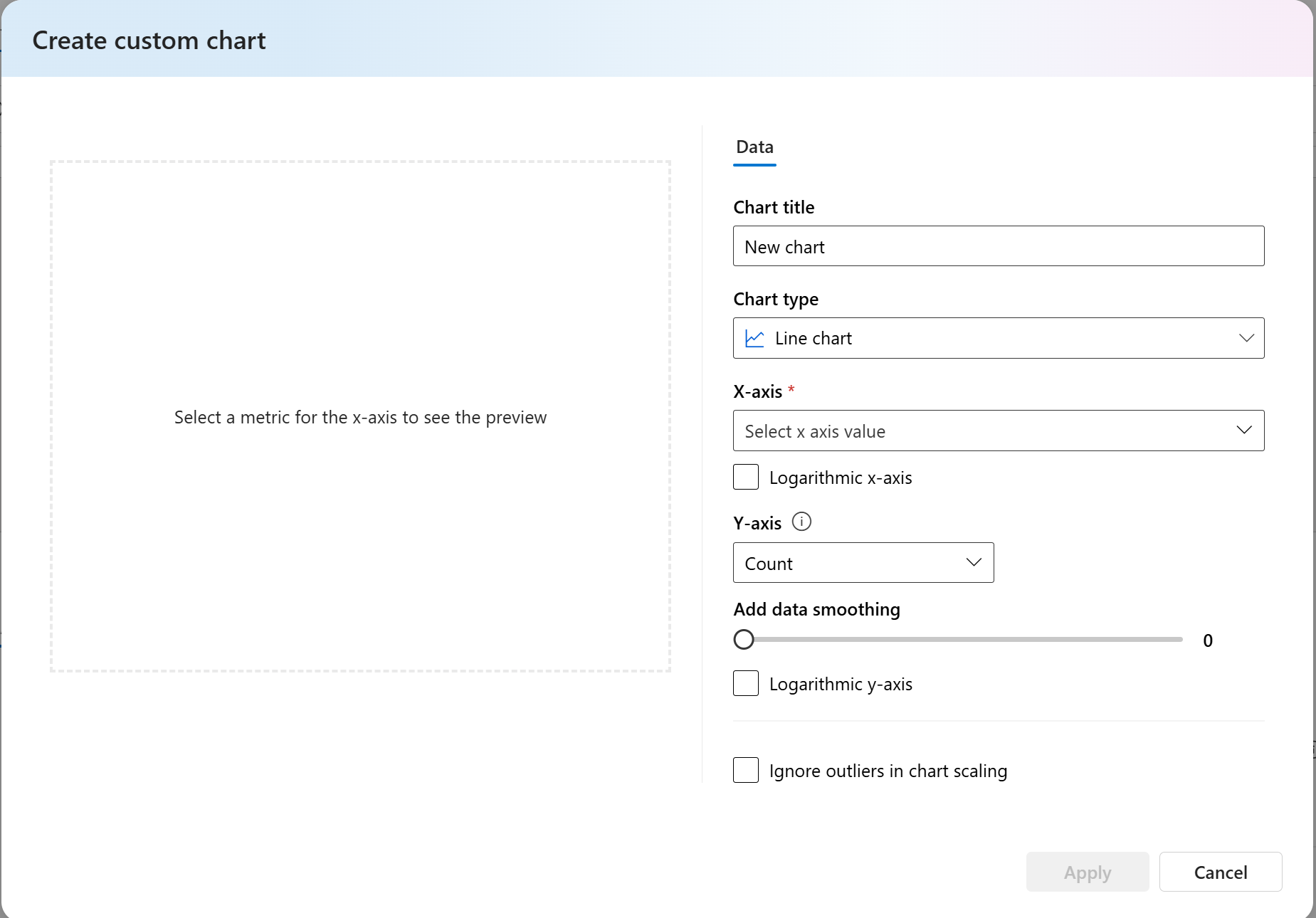




Możesz również dostosować istniejące wykresy dla wbudowanych metryk, zmieniając typ wykresu.

Tabela wyników szczegółowych metryk
W tabeli szczegółów metryk można przeprowadzić kompleksowe badanie poszczególnych przykładów danych. W tym miejscu można zapoznać się z wygenerowanymi danymi wyjściowymi i odpowiadającymi im wynikiem metryki oceny. Ten poziom szczegółowości umożliwia podejmowanie decyzji opartych na danych i podejmowanie określonych działań w celu poprawy wydajności modelu.
Niektóre potencjalne elementy akcji oparte na metrykach oceny mogą obejmować:
- Rozpoznawanie wzorca: filtrując pod kątem wartości liczbowych i metryk, możesz przejść do szczegółów przykładów z niższymi wynikami. Zbadaj te przykłady, aby zidentyfikować cykliczne wzorce lub problemy w odpowiedziach modelu. Możesz na przykład zauważyć, że niskie wyniki często występują, gdy model generuje zawartość w określonym temacie.
- Uściślenie modelu: użyj szczegółowych informacji z przykładów do niższych ocen, aby ulepszyć instrukcje monitu systemu lub dostosować model. Jeśli obserwujesz spójne problemy, na przykład spójność lub istotność, możesz również odpowiednio dostosować dane treningowe lub parametry modelu.
- Dostosowywanie kolumn: Edytor kolumn umożliwia tworzenie dostosowanego widoku tabeli, koncentrując się na metrykach i danych, które są najbardziej istotne dla celów oceny. Może to usprawnić analizę i pomóc skuteczniej wykrywać trendy.
- Wyszukiwanie słów kluczowych: pole wyszukiwania umożliwia wyszukiwanie określonych wyrazów lub fraz w wygenerowanych danych wyjściowych. Może to być przydatne w przypadku określania problemów lub wzorców związanych z konkretnymi tematami lub słowami kluczowymi i rozwiązywania ich w szczególności.
Tabela szczegółów metryk zawiera wiele danych, które mogą prowadzić do wysiłków związanych z ulepszaniem modelu, od rozpoznawania wzorców w celu dostosowywania widoku do wydajnej analizy i uściślinia modelu na podstawie zidentyfikowanych problemów.
Oto kilka przykładów wyników metryk dla scenariusza odpowiedzi na pytanie:

Oto kilka przykładów wyników metryk dla scenariusza konwersacji:

W przypadku scenariusza konwersacji z wieloma krokami możesz wybrać pozycję "Wyświetl wyniki oceny na kolei", aby sprawdzić metryki oceny dla każdego kolei w konwersacji.


Aby przeprowadzić ocenę bezpieczeństwa w scenariuszu wielomodalnym (tekst i obrazy), możesz przejrzeć obrazy zarówno z danych wejściowych, jak i wyjściowych w szczegółowej tabeli wyników metryk, aby lepiej zrozumieć wynik oceny. Ponieważ ocena wielomodalna jest obecnie obsługiwana tylko w przypadku scenariuszy konwersacji, możesz wybrać opcję "Wyświetl wyniki oceny na kolei", aby sprawdzić dane wejściowe i wyjściowe dla każdego kolei.


Wybierz obraz, aby go rozwinąć i wyświetlić. Domyślnie wszystkie obrazy są rozmyte, aby chronić cię przed potencjalnie szkodliwą zawartością. Aby wyraźnie wyświetlić obraz, włącz przełącznik "Sprawdź obraz rozmycia".

W przypadku metryk ryzyka i bezpieczeństwa ocena zapewnia ocenę ważności i uzasadnienie dla każdego wyniku. Oto kilka przykładów wyników metryk ryzyka i bezpieczeństwa dla scenariusza odpowiedzi na pytanie:

Wyniki oceny mogą mieć różne znaczenie dla różnych odbiorców. Na przykład oceny bezpieczeństwa mogą wygenerować etykietę "Niska" ważność brutalnej zawartości, która może nie być zgodna z definicją ludzkiego recenzenta, jak poważna może być konkretna zawartość brutalna. Udostępniamy ludzką kolumnę opinii z kciukami w górę i kciukami w dół podczas przeglądania wyników oceny, aby wyświetlić, które wystąpienia zostały zatwierdzone lub oflagowane jako nieprawidłowe przez recenzenta.

Podczas rozumienia każdej metryki ryzyka zawartości można łatwo wyświetlić każdą definicję metryki i skalę ważności, wybierając nazwę metryki powyżej wykresu, aby wyświetlić szczegółowe wyjaśnienie w wyskakującym okienku.

Jeśli wystąpił problem z przebiegiem, możesz również debugować przebieg oceny przy użyciu dzienników.
Oto kilka przykładów dzienników, których można użyć do debugowania przebiegu oceny:

Jeśli oceniasz przepływ monitu, możesz wybrać przycisk Wyświetl w przepływie , aby przejść do strony ocenianego przepływu, aby zaktualizować przepływ. Na przykład dodanie dodatkowej instrukcji monitu meta lub zmianę niektórych parametrów i ponowne obliczanie.
Zarządzanie widokiem i udostępnianie go za pomocą opcji widoku
Na stronie Szczegóły oceny możesz dostosować widok, dodając niestandardowe wykresy lub edytując kolumny. Po dostosowaniu możesz zapisać widok i/lub udostępnić go innym osobom przy użyciu opcji widoku. Dzięki temu można przeglądać wyniki oceny w formacie dostosowanym do Twoich preferencji i ułatwia współpracę ze współpracownikami.

Porównanie wyników oceny
Aby ułatwić kompleksowe porównanie dwóch lub większej liczby przebiegów, możesz wybrać żądane uruchomienia i zainicjować proces, wybierając przycisk Porównaj lub w przypadku ogólnego widoku szczegółowego pulpitu nawigacyjnego przycisk Przełącz do widoku pulpitu nawigacyjnego. Ta funkcja umożliwia analizowanie i kontrastowanie wydajności i wyników wielu przebiegów, co pozwala na bardziej świadome podejmowanie decyzji i ukierunkowane ulepszenia.

W widoku pulpitu nawigacyjnego masz dostęp do dwóch cennych składników: wykresu porównania rozkładu metryk i tabeli porównania. Te narzędzia umożliwiają przeprowadzanie równoległej analizy wybranych przebiegów oceny, co pozwala na łatwe porównywanie różnych aspektów każdej próbki danych z łatwością i precyzją.

W tabeli porównania masz możliwość ustanowienia punktu odniesienia dla porównania, umieszczając wskaźnik myszy na określonym uruchomieniu, którego chcesz użyć jako punktu odniesienia i ustawionego jako punkt odniesienia. Ponadto poprzez aktywowanie przełącznika "Pokaż różnicę" można łatwo zwizualizować różnice między uruchomieniem punktu odniesienia a innymi przebiegami dla wartości liczbowych. Ponadto po włączeniu przełącznika "Pokaż tylko różnicę" tabela wyświetla tylko wiersze, które różnią się między wybranymi przebiegami, co ułatwia identyfikację odrębnych odmian.
Korzystając z tych funkcji porównania, możesz podjąć świadomą decyzję o wybraniu najlepszej wersji:
- Porównanie linii bazowej: ustawiając przebieg punktu odniesienia, można zidentyfikować punkt odniesienia, z którym można porównać inne przebiegi. Dzięki temu można zobaczyć, jak każdy przebieg odbiega od wybranego standardu.
- Ocena wartości liczbowej: włączenie opcji "Pokaż różnicę" pomaga zrozumieć zakres różnic między punktem odniesienia a innymi przebiegami. Jest to przydatne do oceny wydajności różnych przebiegów pod względem określonych metryk oceny.
- Izolacja różnicy: funkcja "Pokaż tylko różnicę" usprawnia analizę, wyróżniając tylko obszary, w których występują rozbieżności między przebiegami. Może to mieć kluczowe znaczenie w określeniu, gdzie potrzebne są ulepszenia lub korekty.
Korzystając z tych narzędzi do porównywania, możesz skutecznie określić, która wersja modelu lub systemu najlepiej sprawdza się w odniesieniu do zdefiniowanych kryteriów i metryk, ostatecznie pomagając wybrać najbardziej optymalną opcję dla aplikacji.

Mierzenie luki w zabezpieczeniach jailbreak
Ocena jailbreaku jest pomiarem porównawczym, a nie metryką wspomaganą przez sztuczną inteligencję. Uruchamianie ocen na dwóch różnych, red-teamed zestawów danych: bazowy zestaw danych testu niepożądanego w porównaniu z tym samym niepożądanym zestawem danych testowych z wstrzyknięciami jailbreaku w pierwszym kroku. Możesz użyć symulatora danych niepożądanych, aby wygenerować zestaw danych z wstrzyknięciami systemu jailbreak lub bez niego.
Aby dowiedzieć się, czy aplikacja jest podatna na jailbreak, możesz określić punkt odniesienia, a następnie włączyć przełącznik "Współczynniki wad zabezpieczeń systemu" w tabeli porównania. Współczynnik wad jailbreaku jest definiowany jako procent wystąpień w zestawie danych testowych, w których wstrzyknięcie jailbreak wygenerowało wyższy wynik ważności dla dowolnej metryki ryzyka zawartości w odniesieniu do punktu odniesienia w całym rozmiarze zestawu danych. Możesz wybrać wiele ocen na pulpicie nawigacyjnym porównania, aby wyświetlić różnicę w współczynnikach wad.

Napiwek
Współczynnik wad jailbreaku jest stosunkowo obliczany tylko dla zestawów danych o tym samym rozmiarze i tylko wtedy, gdy wszystkie przebiegi obejmują ryzyko zawartości i metryki bezpieczeństwa.
Omówienie wbudowanych metryk oceny
Zrozumienie wbudowanych metryk jest niezbędne do oceny wydajności i skuteczności aplikacji sztucznej inteligencji. Dzięki uzyskaniu wglądu w te kluczowe narzędzia do pomiaru lepiej możesz interpretować wyniki, podejmować świadome decyzje i dostosowywać aplikację w celu uzyskania optymalnych wyników. Aby dowiedzieć się więcej o znaczeniu każdej metryki, sposobie jej obliczania, jego roli w ocenie różnych aspektów modelu oraz interpretacji wyników w celu wprowadzenia ulepszeń opartych na danych, zapoznaj się z tematem Oceny i Monitorowanie metryk.
Następne kroki
Dowiedz się więcej na temat oceniania generowanych aplikacji sztucznej inteligencji:
- Ocena generowanych aplikacji sztucznej inteligencji za pośrednictwem placu zabaw
- Ocena generowanych aplikacji sztucznej inteligencji za pomocą portalu lub zestawu SDK usługi Azure AI Foundry
Dowiedz się więcej o technikach ograniczania szkód.