Trenowanie profesjonalnego modelu głosu
Z tego artykułu dowiesz się, jak wytrenować niestandardowy neuronowy głos za pośrednictwem portalu usługi Speech Studio.
Ważne
Niestandardowe trenowanie neuronowego głosu jest obecnie dostępne tylko w niektórych regionach. Po wytrenowanym modelu głosowym w obsługiwanym regionie możesz skopiować go do zasobu usługi Mowa w innym regionie zgodnie z potrzebami. Aby uzyskać więcej informacji, zobacz przypisy dolne w tabeli usługi Mowa.
Czas trwania szkolenia różni się w zależności od ilości używanych danych. Trenowanie niestandardowego neuronowego głosu trwa średnio około 40 godzin obliczeniowych. Użytkownicy subskrypcji standardowej (S0) mogą trenować cztery głosy jednocześnie. Jeśli osiągniesz limit, poczekaj, aż co najmniej jeden z modeli głosowych zakończy trenowanie, a następnie spróbuj ponownie.
Uwaga
Chociaż łączna liczba godzin wymaganych przez metodę trenowania jest różna, ta sama cena jednostkowa ma zastosowanie do każdej z nich. Aby uzyskać więcej informacji, zobacz niestandardowe szczegóły cennika trenowania neuronowego.
Wybieranie metody trenowania
Po zweryfikowaniu plików danych użyj ich do utworzenia niestandardowego modelu neuronowego głosu. Podczas tworzenia niestandardowego neuronowego głosu można go wytrenować przy użyciu jednej z następujących metod:
Neuronowe: utwórz głos w tym samym języku danych treningowych.
Neuronowe — krzyżowe: utwórz głos, który mówi innym językiem od danych treningowych. Na przykład przy użyciu danych treningowych
zh-CNmożna utworzyć głos, który mówien-US.Język danych szkoleniowych i język docelowy muszą być jednym z języków obsługiwanych na potrzeby trenowania głosu krzyżowego. Nie musisz przygotowywać danych treningowych w języku docelowym, ale skrypt testowy musi być w języku docelowym.
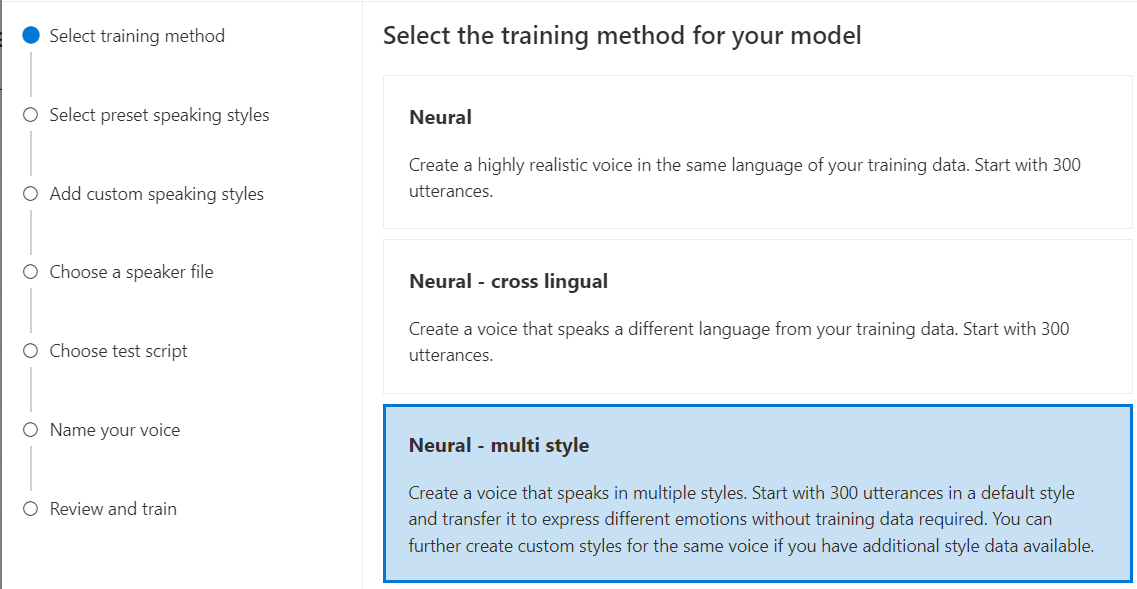
Neuronowy — wiele stylów: utwórz niestandardowy neuronowy głos, który mówi w wielu stylach i emocjach bez dodawania nowych danych treningowych. Wiele głosów w stylu jest przydatnych w przypadku znaków gier wideo, czatbotów konwersacyjnych, audiobooków, czytników zawartości i nie tylko.
Aby utworzyć głos w wielu stylach, należy przygotować zestaw ogólnych danych treningowych, co najmniej 300 wypowiedzi. Wybierz co najmniej jeden z wstępnie ustawionych stylów mówienia docelowego. Można również utworzyć wiele stylów niestandardowych, udostępniając przykłady stylów, co najmniej 100 wypowiedzi na styl, jako dodatkowe dane treningowe dla tego samego głosu. Obsługiwane style ustawień wstępnych różnią się w zależności od różnych języków. Zobacz dostępne style ustawień wstępnych w różnych językach.
Język danych treningowych musi być jednym z języków, które są obsługiwane w przypadku niestandardowego neuronowego głosu, międzylingualnego lub wielu uczenia w stylu.
Trenowanie niestandardowego neuronowego modelu głosu
Aby utworzyć niestandardowy neuronowy głos w usłudze Speech Studio, wykonaj następujące kroki dla jednej z następujących metod:
Zaloguj się do programu Speech Studio.
Wybierz pozycję Niestandardowy głos><Nazwa>>projektu Train model>Train a new model (Uczenie nowego modelu).
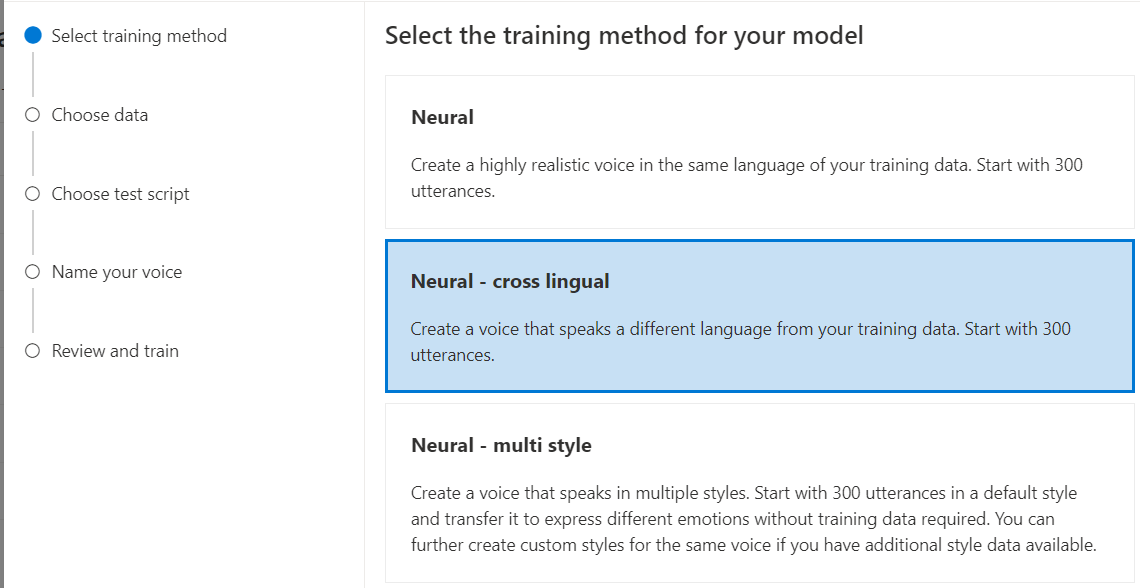
Wybierz pozycję Neuronowe jako metodę trenowania modelu, a następnie wybierz pozycję Dalej. Aby użyć innej metody trenowania, zobacz Neuronowe — krzyżowe lub Neuronowe — wiele stylów.
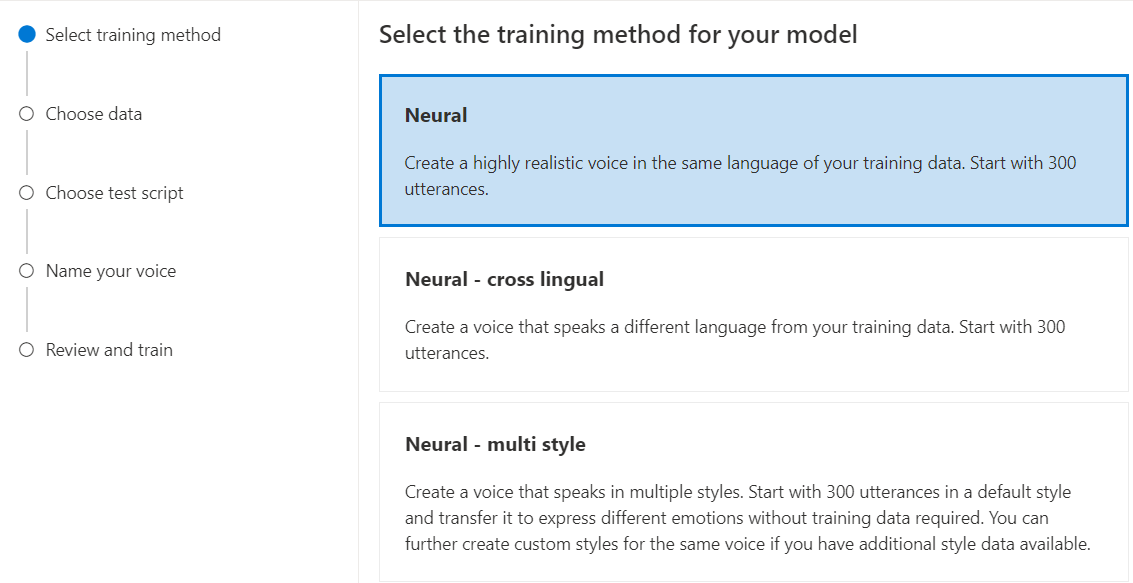
Wybierz wersję przepisu szkoleniowego dla modelu. Domyślnie jest wybierana najnowsza wersja. Obsługiwane funkcje i czas trenowania mogą się różnić w zależności od wersji. Zwykle zalecamy najnowszą wersję. W niektórych przypadkach możesz wybrać wcześniejszą wersję, aby skrócić czas trenowania. Aby uzyskać więcej informacji na temat trenowania dwujęzycznego i różnic między ustawieniami regionalnymi, zobacz Szkolenie dwujęzyczne .
Uwaga
Wersje
V2.2021.07modelu , ,V4.2021.10V5.2022.05,V6.2022.11iV9.2023.10zostaną wycofane do 1 października 2024 r. Modele głosowe utworzone już w tych wycofanych wersjach nie będą miały wpływu.Wybierz dane, których chcesz użyć do trenowania. Z trenowania są usuwane zduplikowane nazwy audio. Upewnij się, że wybrane dane nie zawierają tych samych nazw audio w wielu plikach .zip .
Do trenowania można wybrać tylko pomyślnie przetworzone zestawy danych. Jeśli na liście nie widzisz zestawu szkoleniowego, sprawdź stan przetwarzania danych.
Wybierz plik osoby mówiącej z instrukcją talentu głosowego odpowiadającą głośnikowi w danych treningowych.
Wybierz Dalej.
Każde trenowanie automatycznie generuje 100 przykładowych plików audio, aby ułatwić przetestowanie modelu za pomocą skryptu domyślnego.
Opcjonalnie możesz również wybrać pozycję Dodaj własny skrypt testowy i podać własny skrypt testowy z maksymalnie 100 wypowiedziami, aby przetestować model bez dodatkowych kosztów. Wygenerowane pliki dźwiękowe są kombinacją skryptów testów automatycznych i niestandardowych skryptów testowych. Aby uzyskać więcej informacji, zobacz wymagania dotyczące skryptu testowego.
Wprowadź nazwę, aby ułatwić identyfikację modelu. Starannie wybierz nazwę. Nazwa modelu jest używana jako nazwa głosu w żądaniu syntezy mowy przez zestaw SDK i dane wejściowe SSML. Dozwolone są tylko litery, cyfry i kilka znaków interpunkcyjnych. Użyj różnych nazw dla różnych modeli neuronowych głosów.
Opcjonalnie wprowadź opis , aby ułatwić zidentyfikowanie modelu. Typowym zastosowaniem opisu jest zarejestrowanie nazw danych użytych do utworzenia modelu.
Wybierz Dalej.
Przejrzyj ustawienia i zaznacz pole, aby zaakceptować warunki użytkowania.
Wybierz pozycję Prześlij , aby rozpocząć trenowanie modelu.
Trenowanie dwujęzyczne
Jeśli wybierzesz typ trenowania neuronowego , możesz wytrenować głos, aby mówić w wielu językach. Ustawienia zh-CNregionalne , i zh-TW obsługują szkolenia dwujęzyczne dla głosu, aby mówić zarówno w języku chińskim, jak i zh-HKangielskim. W zależności od danych treningowych syntetyzowany głos może mówić po angielsku z akcentem natywnym w języku angielskim lub angielskim z tym samym akcentem co dane szkoleniowe.
Uwaga
Aby włączyć głos w ustawieniach regionalnych, aby mówić po angielsku zh-CN z tym samym akcentem co przykładowe dane, należy wybrać Chinese (Mandarin, Simplified), English bilingual podczas tworzenia projektu lub określić zh-CN (English bilingual) ustawienia regionalne dla danych zestawu treningowego za pośrednictwem interfejsu API REST.
W poniższej tabeli przedstawiono różnice między ustawieniami regionalnymi:
| Ustawienia regionalne programu Speech Studio | Ustawienia regionalne interfejsu API REST | Obsługa dwujęzyczna |
|---|---|---|
Chinese (Mandarin, Simplified) |
zh-CN |
Jeśli przykładowe dane zawierają język angielski, syntetyzowany głos mówi po angielsku z akcentem natywnym w języku angielskim, zamiast tego samego akcentu co przykładowe dane, niezależnie od ilości danych w języku angielskim. |
Chinese (Mandarin, Simplified), English bilingual |
zh-CN (English bilingual) |
Jeśli chcesz, aby syntetyzowany głos mówił po angielsku z tym samym akcentem co przykładowe dane, zalecamy uwzględnienie ponad 10% danych języka angielskiego w zestawie treningowym. W przeciwnym razie akcent angielski może nie być idealny. |
Chinese (Cantonese, Simplified) |
zh-HK |
Jeśli chcesz wytrenować syntetyzowany głos zdolny do mówienia po angielsku z tym samym akcentem co przykładowe dane, upewnij się, że w zestawie treningowym udostępniasz ponad 10% danych angielskich. W przeciwnym razie domyślnie jest to akcent natywny w języku angielskim. Próg 10% jest obliczany na podstawie danych zaakceptowanych po pomyślnym przekazaniu, a nie na danych przed przekazaniem. Jeśli niektóre przekazane dane w języku angielskim zostaną odrzucone z powodu wad i nie spełniają progu 10%, syntetyzowany głos domyślnie jest akcentem natywnym w języku angielskim. |
Chinese (Taiwanese Mandarin, Traditional) |
zh-TW |
Jeśli chcesz wytrenować syntetyzowany głos zdolny do mówienia po angielsku z tym samym akcentem co przykładowe dane, upewnij się, że w zestawie treningowym udostępniasz ponad 10% danych angielskich. W przeciwnym razie domyślnie jest to akcent natywny w języku angielskim. Próg 10% jest obliczany na podstawie danych zaakceptowanych po pomyślnym przekazaniu, a nie na danych przed przekazaniem. Jeśli niektóre przekazane dane w języku angielskim zostaną odrzucone z powodu wad i nie spełniają progu 10%, syntetyzowany głos domyślnie jest akcentem natywnym w języku angielskim. |
Dostępne style ustawień wstępnych w różnych językach
Poniższa tabela zawiera podsumowanie różnych wstępnie ustawionych stylów zgodnie z różnymi językami.
| Styl mówienia | Język (ustawienia regionalne) |
|---|---|
| zły | Angielski (Stany Zjednoczone) (en-US)Japoński (Japonia) ( ja-JP) 1Chiński (mandaryński, uproszczony) ( zh-CN) 1 |
| spokój | Chiński (mandaryński, uproszczony) (zh-CN) 1 |
| czat | Chiński (mandaryński, uproszczony) (zh-CN) 1 |
| radosny | Angielski (Stany Zjednoczone) (en-US)Japoński (Japonia) ( ja-JP) 1Chiński (mandaryński, uproszczony) ( zh-CN) 1 |
| Niezadowolonych | Chiński (mandaryński, uproszczony) (zh-CN) 1 |
| podekscytowany | Angielski (Stany Zjednoczone) (en-US) |
| bojaźliwy | Chiński (mandaryński, uproszczony) (zh-CN) 1 |
| przyjacielski | Angielski (Stany Zjednoczone) (en-US) |
| Nadzieję | Angielski (Stany Zjednoczone) (en-US) |
| smutny | Angielski (Stany Zjednoczone) (en-US)Japoński (Japonia) ( ja-JP) 1Chiński (mandaryński, uproszczony) ( zh-CN) 1 |
| Krzycząc | Angielski (Stany Zjednoczone) (en-US) |
| poważny | Chiński (mandaryński, uproszczony) (zh-CN) 1 |
| Przerażony | Angielski (Stany Zjednoczone) (en-US) |
| nieprzyjazny | Angielski (Stany Zjednoczone) (en-US) |
| Whispering | Angielski (Stany Zjednoczone) (en-US) |
1 Styl neuronowego głosu jest dostępny w publicznej wersji zapoznawczej. Style w publicznej wersji zapoznawczej są dostępne tylko w następujących regionach usługi : Wschodnie stany USA, Europa Zachodnia i Azja Południowo-Wschodnia.
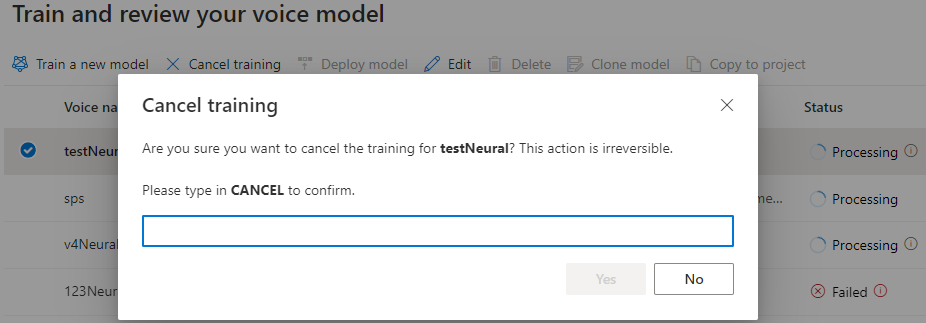
W tabeli Train model (Trenowanie modelu ) zostanie wyświetlony nowy wpis odpowiadający nowo utworzonemu modelowi. Stan odzwierciedla proces konwertowania danych na model głosowy, zgodnie z opisem w tej tabeli:
| Stan | Znaczenie |
|---|---|
| Przetwarzanie | Tworzony jest model głosowy. |
| Powodzenie | Model głosowy został utworzony i można go wdrożyć. |
| Niepowodzenie | Model głosowy nie powiódł się podczas trenowania. Przyczyną awarii mogą być na przykład problemy z danymi lub problemy z siecią. |
| Anulowany | Szkolenie dla modelu głosowego zostało anulowane. |
Gdy stan modelu to Przetwarzanie, możesz wybrać pozycję Anuluj trenowanie , aby anulować model głosowy. Nie są naliczane opłaty za anulowane szkolenie.
Po pomyślnym zakończeniu trenowania modelu możesz przejrzeć szczegóły modelu i przetestować model głosowy.
Możesz użyć narzędzia do tworzenia zawartości audio w usłudze Speech Studio, aby utworzyć dźwięk i dostosować wdrożony głos. Jeśli ma zastosowanie do głosu, możesz wybrać jeden z wielu stylów.
Zmienianie nazwy modelu
Jeśli chcesz zmienić nazwę utworzonego modelu, wybierz pozycję Klonuj model , aby utworzyć klon modelu o nowej nazwie w bieżącym projekcie.
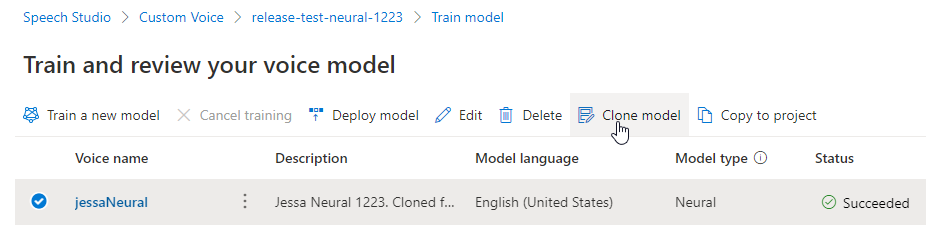
Wprowadź nową nazwę w oknie Klonowanie modelu głosowego , a następnie wybierz pozycję Prześlij. Tekst Neuronowy jest automatycznie dodawany jako sufiks do nowej nazwy modelu.
Testowanie modelu głosu
Po pomyślnym skompilowania modelu głosowego można użyć wygenerowanych przykładowych plików audio, aby przetestować go przed wdrożeniem.
Jakość głosu zależy od wielu czynników, takich jak:
- Rozmiar danych treningowych.
- Jakość nagrania.
- Dokładność pliku transkrypcji.
- Jak dobrze zarejestrowany głos w danych treningowych pasuje do osobowości zaprojektowanego głosu dla zamierzonego przypadku użycia.
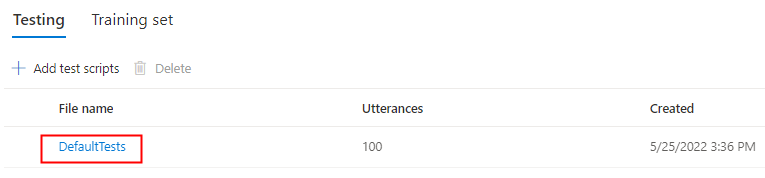
Wybierz pozycję DomyślneTesty w obszarze Testowanie , aby nasłuchiwać przykładowych plików audio. Domyślne przykłady testów obejmują 100 przykładowych plików audio generowanych automatycznie podczas trenowania, co ułatwia przetestowanie modelu. Oprócz tych 100 plików audio dostarczanych domyślnie własne wypowiedzi skryptu testowego są również dodawane do zestawu DefaultTests . Ten dodatek jest w większości 100 wypowiedzi. Nie są naliczane opłaty za testowanie za pomocą opcji DefaultTests.
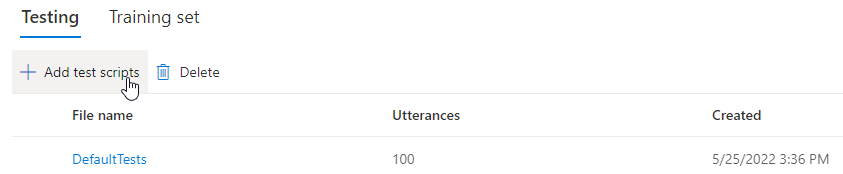
Jeśli chcesz przekazać własne skrypty testowe w celu dalszego testowania modelu, wybierz pozycję Dodaj skrypty testowe , aby przekazać własny skrypt testowy.
Przed przekazaniem skryptu testowego sprawdź wymagania skryptu testowego. Opłata jest naliczana za dodatkowe testowanie za syntezę wsadową na podstawie liczby znaków podlegających rozliczaniu. Zobacz Cennik usługi Azure AI Speech.
W obszarze Dodaj skrypty testowe wybierz pozycję Przeglądaj, aby wybrać własny skrypt, a następnie wybierz pozycję Dodaj , aby go przekazać.
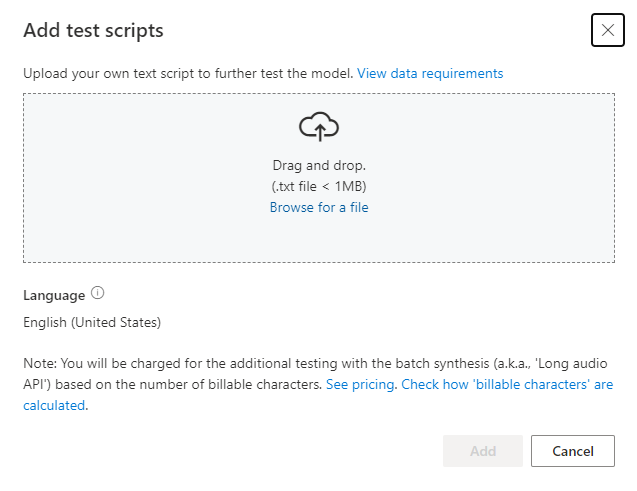
Wymagania testów skryptowych
Skrypt testowy musi być plikiem .txt , który jest mniejszy niż 1 MB. Obsługiwane formaty kodowania obejmują ANSI/ASCII, UTF-8, UTF-8-BOM, UTF-16-LE lub UTF-16-BE.
W przeciwieństwie do plików transkrypcji trenowania skrypt testowy powinien wykluczyć identyfikator wypowiedzi, który jest nazwą pliku każdej wypowiedzi. W przeciwnym razie te identyfikatory są mówione.
Oto przykładowy zestaw wypowiedzi w jednym pliku .txt :
This is the waistline, and it's falling.
We have trouble scoring.
It was Janet Maslin.
Każdy akapit wypowiedzi powoduje utworzenie oddzielnego dźwięku. Jeśli chcesz połączyć wszystkie zdania w jeden dźwięk, utwórz je w jednym akapicie.
Uwaga
Wygenerowane pliki dźwiękowe są kombinacją skryptów testów automatycznych i niestandardowych skryptów testowych.
Aktualizowanie wersji aparatu dla modelu głosowego
Aparaty zamiany tekstu na mowę na platformę Azure są aktualizowane od czasu do czasu w celu przechwycenia najnowszego modelu językowego definiującego wymowę języka. Po wytrenowania głosu możesz zastosować głos do nowego modelu językowego, aktualizując go do najnowszej wersji aparatu.
Po udostępnieniu nowego aparatu zostanie wyświetlony monit o zaktualizowanie modelu neuronowego głosu.

Przejdź do strony szczegółów modelu i postępuj zgodnie z instrukcjami wyświetlanymi na ekranie, aby zainstalować najnowszy aparat.
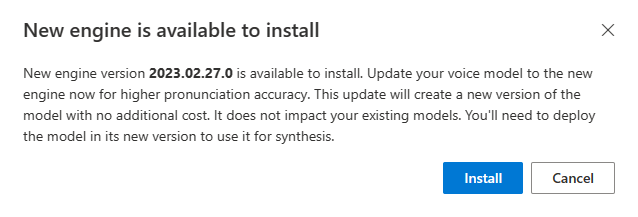
Alternatywnie wybierz pozycję Zainstaluj najnowszy aparat później, aby zaktualizować model do najnowszej wersji aparatu.
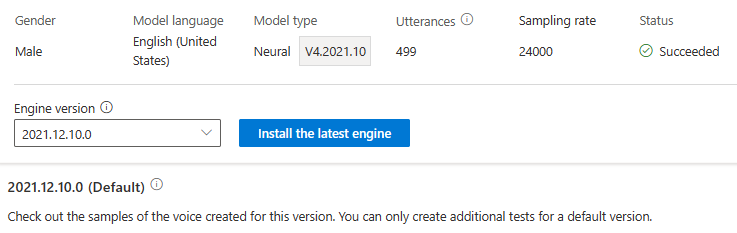
Nie są naliczane opłaty za aktualizację aparatu. Poprzednie wersje są nadal przechowywane.
Możesz sprawdzić wszystkie wersje aparatu dla modelu z listy Wersji aparatu lub usunąć je, jeśli nie są już potrzebne.
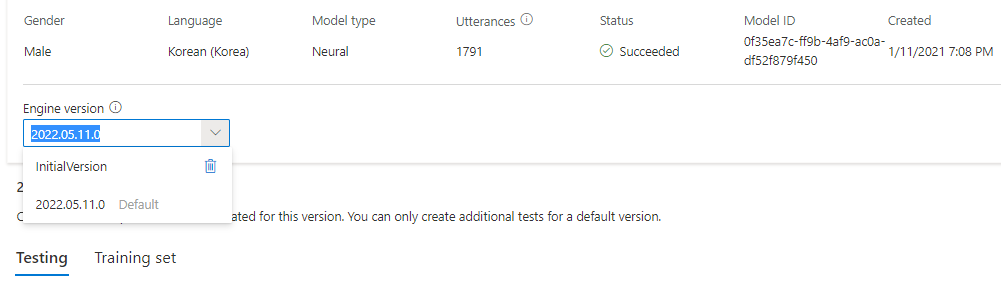
Zaktualizowana wersja jest automatycznie ustawiana jako domyślna. Możesz jednak zmienić domyślną wersję, wybierając wersję z listy rozwijanej i wybierając pozycję Ustaw jako domyślną.
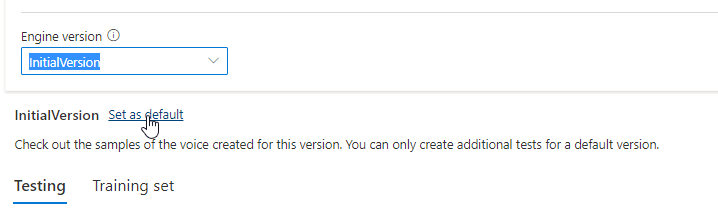

Jeśli chcesz przetestować każdą wersję aparatu modelu głosowego, możesz wybrać wersję z listy, a następnie wybrać pozycję DefaultTests w obszarze Testowanie , aby nasłuchiwać przykładowych plików audio. Jeśli chcesz przekazać własne skrypty testowe, aby dokładniej przetestować bieżącą wersję aparatu, najpierw upewnij się, że wersja jest ustawiona jako domyślna, a następnie wykonaj kroki opisane w temacie Testowanie modelu głosu.
Aktualizowanie aparatu powoduje utworzenie nowej wersji modelu bez dodatkowych kosztów. Po zaktualizowaniu wersji aparatu dla modelu głosowego należy wdrożyć nową wersję, aby utworzyć nowy punkt końcowy. Można wdrożyć tylko wersję domyślną.
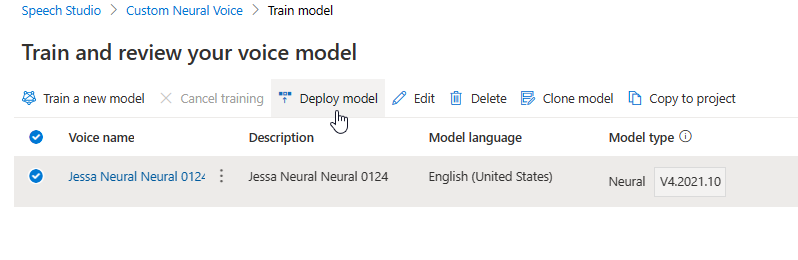
Po utworzeniu nowego punktu końcowego należy przenieść ruch do nowego punktu końcowego w produkcie.
Aby dowiedzieć się więcej na temat możliwości i limitów tej funkcji oraz najlepszych rozwiązań w celu poprawy jakości modelu, zobacz Charakterystykę i ograniczenia dotyczące używania niestandardowego neuronowego głosu.
Kopiowanie modelu głosu do innego projektu
Model głosowy można skopiować do innego projektu dla tego samego regionu lub innego regionu. Można na przykład skopiować model neuronowego głosu, który został wytrenowany w jednym regionie, do projektu dla innego regionu.
Uwaga
Niestandardowe trenowanie neuronowego głosu jest obecnie dostępne tylko w niektórych regionach. Możesz skopiować model neuronowego głosu z tych regionów do innych regionów. Aby uzyskać więcej informacji, zobacz regiony niestandardowego neuronowego głosu.
Aby skopiować niestandardowy model neuronowego głosu do innego projektu:
Na karcie Trenowanie modelu wybierz model głosowy, który chcesz skopiować, a następnie wybierz pozycję Kopiuj do projektu.
Wybierz pozycję Subskrypcja, Region, Zasób mowy i Projekt, w którym chcesz skopiować model. Musisz mieć zasób mowy i projekt w regionie docelowym, w przeciwnym razie musisz je najpierw utworzyć.
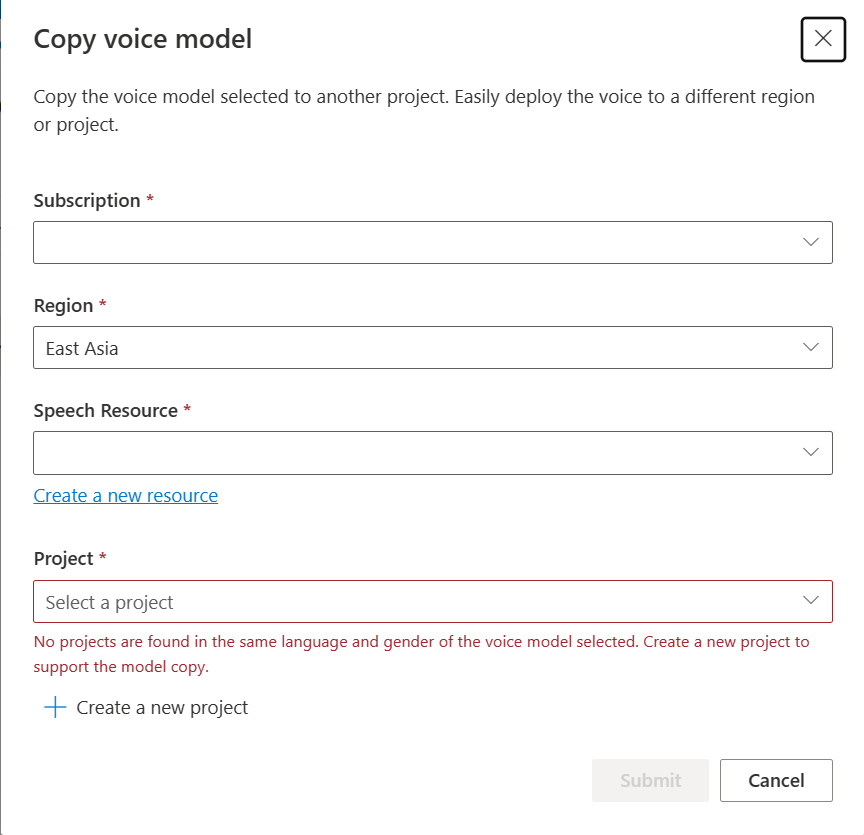
Wybierz pozycję Prześlij , aby skopiować model.
Wybierz pozycję Wyświetl model w obszarze komunikatu powiadomienia o pomyślnym skopiowaniu.
Przejdź do projektu, w którym skopiowano model, aby wdrożyć kopię modelu.
Następne kroki
Z tego artykułu dowiesz się, jak wytrenować niestandardowy neuronowy głos za pomocą niestandardowego interfejsu API głosu.
Ważne
Niestandardowe trenowanie neuronowego głosu jest obecnie dostępne tylko w niektórych regionach. Po wytrenowanym modelu głosowym w obsługiwanym regionie możesz skopiować go do zasobu usługi Mowa w innym regionie zgodnie z potrzebami. Aby uzyskać więcej informacji, zobacz przypisy dolne w tabeli usługi Mowa.
Czas trwania szkolenia różni się w zależności od ilości używanych danych. Trenowanie niestandardowego neuronowego głosu trwa średnio około 40 godzin obliczeniowych. Użytkownicy subskrypcji standardowej (S0) mogą trenować cztery głosy jednocześnie. Jeśli osiągniesz limit, poczekaj, aż co najmniej jeden z modeli głosowych zakończy trenowanie, a następnie spróbuj ponownie.
Uwaga
Chociaż łączna liczba godzin wymaganych przez metodę trenowania jest różna, ta sama cena jednostkowa ma zastosowanie do każdej z nich. Aby uzyskać więcej informacji, zobacz niestandardowe szczegóły cennika trenowania neuronowego.
Wybieranie metody trenowania
Po zweryfikowaniu plików danych użyj ich do utworzenia niestandardowego modelu neuronowego głosu. Podczas tworzenia niestandardowego neuronowego głosu można go wytrenować przy użyciu jednej z następujących metod:
Neuronowe: utwórz głos w tym samym języku danych treningowych.
Neuronowe — krzyżowe: utwórz głos, który mówi innym językiem od danych treningowych. Na przykład przy użyciu danych treningowych
fr-FRmożna utworzyć głos, który mówien-US.Język danych szkoleniowych i język docelowy muszą być jednym z języków obsługiwanych na potrzeby trenowania głosu krzyżowego. Nie musisz przygotowywać danych treningowych w języku docelowym, ale skrypt testowy musi być w języku docelowym.
Neuronowy — wiele stylów: utwórz niestandardowy neuronowy głos, który mówi w wielu stylach i emocjach bez dodawania nowych danych treningowych. Wiele głosów w stylu jest przydatnych w przypadku znaków gier wideo, czatbotów konwersacyjnych, audiobooków, czytników zawartości i nie tylko.
Aby utworzyć głos w wielu stylach, należy przygotować zestaw ogólnych danych treningowych, co najmniej 300 wypowiedzi. Wybierz co najmniej jeden z wstępnie ustawionych stylów mówienia docelowego. Można również utworzyć wiele stylów niestandardowych, udostępniając przykłady stylów, co najmniej 100 wypowiedzi na styl, jako dodatkowe dane treningowe dla tego samego głosu. Obsługiwane style ustawień wstępnych różnią się w zależności od różnych języków. Zobacz dostępne style ustawień wstępnych w różnych językach.
Język danych treningowych musi być jednym z języków, które są obsługiwane w przypadku niestandardowego neuronowego głosu, lingualistów lub trenowania w wielu stylach.
Tworzenie modelu głosu
Aby utworzyć głos neuronowy, użyj Models_Create operacji niestandardowego interfejsu API głosu. Skonstruuj treść żądania zgodnie z następującymi instrukcjami:
- Ustaw wymaganą
projectIdwłaściwość. Zobacz Tworzenie projektu. - Ustaw wymaganą
consentIdwłaściwość. Zobacz dodawanie zgody na talent głosowy. - Ustaw wymaganą
trainingSetIdwłaściwość. Zobacz tworzenie zestawu treningowego. - Ustaw wymaganą właściwość przepis
kindna wartośćDefaultna potrzeby trenowania neuronowego głosu. Rodzaj przepisu wskazuje metodę trenowania i nie można jej później zmienić. Aby użyć innej metody trenowania, zobacz Neuronowe — krzyżowe lub Neuronowe — wiele stylów. Aby uzyskać więcej informacji na temat trenowania dwujęzycznego i różnic między ustawieniami regionalnymi, zobacz Szkolenie dwujęzyczne . - Ustaw wymaganą
voiceNamewłaściwość. Nazwa głosu musi kończyć się ciągiem "Neuronowe" i nie można jej później zmienić. Starannie wybierz nazwę. Nazwa głosu jest używana w żądaniu syntezy mowy przez zestaw SDK i dane wejściowe SSML. Dozwolone są tylko litery, cyfry i kilka znaków interpunkcyjnych. Użyj różnych nazw dla różnych modeli neuronowych głosów. - Opcjonalnie ustaw
descriptionwłaściwość opisu głosu. Opis głosu można zmienić później.
Utwórz żądanie HTTP PUT przy użyciu identyfikatora URI, jak pokazano w poniższym przykładzie Models_Create .
- Zastąp
YourResourceKeyciąg kluczem zasobu usługi Mowa. - Zastąp
YourResourceRegionelement regionem zasobu usługi Mowa. - Zastąp
JessicaModelIdelement wybranym identyfikatorem modelu. Identyfikator uwzględniający wielkość liter będzie używany w identyfikatorze URI modelu i nie można go później zmienić.
curl -v -X PUT -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId"
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/models/JessicaModelId?api-version=2024-02-01-preview"
Treść odpowiedzi powinna zostać wyświetlona w następującym formacie:
{
"id": "JessicaModelId",
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default",
"version": "V7.2023.03"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId",
"locale": "en-US",
"engineVersion": "2023.07.04.0",
"status": "NotStarted",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
Trenowanie dwujęzyczne
Jeśli wybierzesz typ trenowania neuronowego , możesz wytrenować głos, aby mówić w wielu językach. Ustawienia zh-CNregionalne , i zh-TW obsługują szkolenia dwujęzyczne dla głosu, aby mówić zarówno w języku chińskim, jak i zh-HKangielskim. W zależności od danych treningowych syntetyzowany głos może mówić po angielsku z akcentem natywnym w języku angielskim lub angielskim z tym samym akcentem co dane szkoleniowe.
Uwaga
Aby włączyć głos w ustawieniach regionalnych, aby mówić po angielsku zh-CN z tym samym akcentem co przykładowe dane, należy wybrać Chinese (Mandarin, Simplified), English bilingual podczas tworzenia projektu lub określić zh-CN (English bilingual) ustawienia regionalne dla danych zestawu treningowego za pośrednictwem interfejsu API REST.
W poniższej tabeli przedstawiono różnice między ustawieniami regionalnymi:
| Ustawienia regionalne programu Speech Studio | Ustawienia regionalne interfejsu API REST | Obsługa dwujęzyczna |
|---|---|---|
Chinese (Mandarin, Simplified) |
zh-CN |
Jeśli przykładowe dane zawierają język angielski, syntetyzowany głos mówi po angielsku z akcentem natywnym w języku angielskim, zamiast tego samego akcentu co przykładowe dane, niezależnie od ilości danych w języku angielskim. |
Chinese (Mandarin, Simplified), English bilingual |
zh-CN (English bilingual) |
Jeśli chcesz, aby syntetyzowany głos mówił po angielsku z tym samym akcentem co przykładowe dane, zalecamy uwzględnienie ponad 10% danych języka angielskiego w zestawie treningowym. W przeciwnym razie akcent angielski może nie być idealny. |
Chinese (Cantonese, Simplified) |
zh-HK |
Jeśli chcesz wytrenować syntetyzowany głos zdolny do mówienia po angielsku z tym samym akcentem co przykładowe dane, upewnij się, że w zestawie treningowym udostępniasz ponad 10% danych angielskich. W przeciwnym razie domyślnie jest to akcent natywny w języku angielskim. Próg 10% jest obliczany na podstawie danych zaakceptowanych po pomyślnym przekazaniu, a nie na danych przed przekazaniem. Jeśli niektóre przekazane dane w języku angielskim zostaną odrzucone z powodu wad i nie spełniają progu 10%, syntetyzowany głos domyślnie jest akcentem natywnym w języku angielskim. |
Chinese (Taiwanese Mandarin, Traditional) |
zh-TW |
Jeśli chcesz wytrenować syntetyzowany głos zdolny do mówienia po angielsku z tym samym akcentem co przykładowe dane, upewnij się, że w zestawie treningowym udostępniasz ponad 10% danych angielskich. W przeciwnym razie domyślnie jest to akcent natywny w języku angielskim. Próg 10% jest obliczany na podstawie danych zaakceptowanych po pomyślnym przekazaniu, a nie na danych przed przekazaniem. Jeśli niektóre przekazane dane w języku angielskim zostaną odrzucone z powodu wad i nie spełniają progu 10%, syntetyzowany głos domyślnie jest akcentem natywnym w języku angielskim. |
Dostępne style ustawień wstępnych w różnych językach
Poniższa tabela zawiera podsumowanie różnych wstępnie ustawionych stylów zgodnie z różnymi językami.
| Styl mówienia | Język (ustawienia regionalne) |
|---|---|
| zły | Angielski (Stany Zjednoczone) (en-US)Japoński (Japonia) ( ja-JP) 1Chiński (mandaryński, uproszczony) ( zh-CN) 1 |
| spokój | Chiński (mandaryński, uproszczony) (zh-CN) 1 |
| czat | Chiński (mandaryński, uproszczony) (zh-CN) 1 |
| radosny | Angielski (Stany Zjednoczone) (en-US)Japoński (Japonia) ( ja-JP) 1Chiński (mandaryński, uproszczony) ( zh-CN) 1 |
| Niezadowolonych | Chiński (mandaryński, uproszczony) (zh-CN) 1 |
| podekscytowany | Angielski (Stany Zjednoczone) (en-US) |
| bojaźliwy | Chiński (mandaryński, uproszczony) (zh-CN) 1 |
| przyjacielski | Angielski (Stany Zjednoczone) (en-US) |
| Nadzieję | Angielski (Stany Zjednoczone) (en-US) |
| smutny | Angielski (Stany Zjednoczone) (en-US)Japoński (Japonia) ( ja-JP) 1Chiński (mandaryński, uproszczony) ( zh-CN) 1 |
| Krzycząc | Angielski (Stany Zjednoczone) (en-US) |
| poważny | Chiński (mandaryński, uproszczony) (zh-CN) 1 |
| Przerażony | Angielski (Stany Zjednoczone) (en-US) |
| nieprzyjazny | Angielski (Stany Zjednoczone) (en-US) |
| Whispering | Angielski (Stany Zjednoczone) (en-US) |
1 Styl neuronowego głosu jest dostępny w publicznej wersji zapoznawczej. Style w publicznej wersji zapoznawczej są dostępne tylko w następujących regionach usługi : Wschodnie stany USA, Europa Zachodnia i Azja Południowo-Wschodnia.
Uzyskiwanie stanu szkolenia
Aby uzyskać stan trenowania modelu głosu, użyj Models_Get operacji niestandardowego interfejsu API głosu. Skonstruuj identyfikator URI żądania zgodnie z następującymi instrukcjami:
Utwórz żądanie HTTP GET przy użyciu identyfikatora URI, jak pokazano w poniższym przykładzie Models_Get .
- Zastąp
YourResourceKeyciąg kluczem zasobu usługi Mowa. - Zastąp
YourResourceRegionelement regionem zasobu usługi Mowa. - Zastąp wartość
JessicaModelId, jeśli w poprzednim kroku określono inny identyfikator modelu.
curl -v -X GET "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/models/JessicaModelId?api-version=2024-02-01-preview" -H "Ocp-Apim-Subscription-Key: YourResourceKey"
Treść odpowiedzi powinna zostać wyświetlona w następującym formacie.
Uwaga
Przepis kind i inne właściwości zależą od sposobu trenowania głosu. W tym przykładzie przepis jest Default przeznaczony do trenowania głosu neuronowego.
{
"id": "JessicaModelId",
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default",
"version": "V7.2023.03"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId",
"locale": "en-US",
"engineVersion": "2023.07.04.0",
"status": "Succeeded",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
Może być konieczne odczekenie kilku minut przed ukończeniem trenowania. W końcu stan zmieni się na Succeeded lub Failed.