Czym jest usługa rozpoznawania mowy?
Usługa rozpoznawania mowy udostępnia funkcję zamiany mowy na tekst i tekst na mowę za pomocą zasobu usługi Mowa. Możesz transkrybować mowę do tekstu z wysoką dokładnością, tworzyć naturalnie brzmiący tekst na głosy mowy, tłumaczyć dźwięk mówiony i używać rozpoznawania osoby mówiącej podczas konwersacji.

Twórz niestandardowe głosy, dodawaj określone słowa do podstawowego słownika lub twórz własne modele. Uruchamiaj usługę Mowa w dowolnym miejscu, w chmurze lub na urządzeniach brzegowych w kontenerach. Rozpoznawanie mowy umożliwia aplikacjom, narzędziom i urządzeniom korzystanie z interfejsu wiersza polecenia usługi Mowa, zestawu SDK usługi Mowa i interfejsów API REST.
Mowa jest dostępna dla wielu języków, regionów i punktów cenowych.
Scenariusze z zastosowaniem mowy
Typowe scenariusze dotyczące mowy obejmują:
- Podpisy: dowiedz się, jak synchronizować podpisy z danymi wejściowymi audio, stosować filtry wulgaryzmów, uzyskiwać częściowe wyniki, stosować dostosowania i identyfikować języki mówione w scenariuszach wielojęzycznych.
- Tworzenie zawartości audio: możesz używać neuronowych głosów do interakcji z czatbotami i asystentami głosowymi bardziej naturalnymi i angażującymi, konwertując teksty cyfrowe, takie jak książki elektroniczne na audiobooki i ulepszać systemy nawigacji samochodowej.
- Call Center: Transkrybuj wywołania w czasie rzeczywistym lub przetwarzaj partię połączeń, redaguj dane osobowe i wyodrębnij szczegółowe informacje, takie jak tonacja, aby pomóc w przypadku użycia centrum telefonicznego.
- Uczenie językowe: udostępniaj opinie na temat oceny wymowy uczniom języka, obsługują transkrypcję w czasie rzeczywistym na potrzeby rozmów zdalnego uczenia się i czytają na głos materiały dydaktyczne z głosami neuronowymi.
- Asystentzy głosowi: twórz naturalne, ludzkie interfejsy, takie jak interfejsy konwersacyjne dla swoich aplikacji i środowisk. Funkcja asystenta głosowego zapewnia szybką, niezawodną interakcję między urządzeniem a implementacją asystenta.
Firma Microsoft używa usługi Mowa w wielu scenariuszach, takich jak podpisy w aplikacji Teams, dyktowanie w usłudze Office 365 i Odczytywanie na głos w przeglądarce Microsoft Edge.
Możliwości mowy
Te sekcje zawierają podsumowanie funkcji mowy z linkami, aby uzyskać więcej informacji.
Zamiana mowy na tekst
Zamiana mowy na tekst umożliwia transkrypcję dźwięku na tekst w czasie rzeczywistym lub asynchronicznie przy użyciu transkrypcji wsadowej.
Napiwek
Możesz wypróbować zamianę mowy w czasie rzeczywistym na tekst w programie Speech Studio bez rejestracji ani pisania kodu.
Konwertuj dźwięk na tekst z różnych źródeł, w tym mikrofonów, plików audio i magazynu obiektów blob. Użyj diaryzacji osoby mówiącej, aby określić, kto powiedział, co i kiedy. Uzyskaj czytelne transkrypcje z automatycznym formatowaniem i interpunkcją.
Model podstawowy może nie być wystarczający, jeśli dźwięk zawiera hałas otoczenia lub zawiera wiele żargonów branżowych i specyficznych dla domeny. W takich przypadkach można tworzyć i trenować niestandardowe modele mowy przy użyciu danych akustycznych, językowych i wymowy. Niestandardowe modele mowy są prywatne i mogą oferować przewagę konkurencyjną.
Zamiana mowy w czasie rzeczywistym na tekst
W przypadku zamiany mowy w czasie rzeczywistym na tekst dźwięk jest transkrypowany w miarę rozpoznawania mowy z mikrofonu lub pliku. Zamiana mowy w czasie rzeczywistym na tekst dla aplikacji, które muszą transkrybować dźwięk w czasie rzeczywistym, na przykład:
- Transkrypcje, transkrypcje lub napisy na potrzeby spotkań na żywo
- Diarization (Diarization)
- Ocena wymowy
- Pomoc dla agentów centrum kontaktowego
- Dyktowanie
- Agenci głosowi
Szybki interfejs API transkrypcji
Interfejs API szybkiej transkrypcji służy do transkrypcji plików audio z synchronicznym i znacznie szybszym zwracaniem wyników niż dźwięk w czasie rzeczywistym. Użyj szybkiej transkrypcji w scenariuszach, w których potrzebujesz transkrypcji nagrania audio tak szybko, jak to możliwe z przewidywalnym opóźnieniem, na przykład:
- Szybka transkrypcja audio lub wideo, napisy i edycja.
- Tłumaczenie wideo
Aby rozpocząć pracę z szybką transkrypcją, zobacz używanie szybkiego interfejsu API transkrypcji.
Transkrypcja wsadowa
Transkrypcja wsadowa służy do transkrypcji dużej ilości dźwięku w magazynie. Możesz wskazać pliki audio z identyfikatorem URI sygnatury dostępu współdzielonego (SAS) i asynchronicznie odbierać wyniki transkrypcji. Użyj transkrypcji wsadowej dla aplikacji, które muszą zbiorczo transkrybować dźwięk, na przykład:
- Transkrypcje, transkrypcje lub napisy dla wstępnie rozpoznanego dźwięku
- Analiza po wywołaniu centrum kontaktów
- Diarization (Diarization)
Zamiana tekstu na mowę
Dzięki zamianie tekstu na mowę możesz przekonwertować tekst wejściowy na człowieka, na przykład syntetyzowany mowę. Używaj głosów neuronowych, które są głosami ludzkimi, takimi jak głosy obsługiwane przez głębokie sieci neuronowe. Użyj języka znaczników syntezy mowy (SSML), aby dostosować wysokość, wymowę, szybkość mówienia, głośność i nie tylko.
- Wstępnie utworzony głos neuronowy: wysoce naturalne głosy gotowe do użycia. Sprawdź wstępnie utworzone przykłady neuronowych głosów w galerii głosów i określ odpowiedni głos dla Twoich potrzeb biznesowych.
- Niestandardowy neuronowy głos: oprócz wstępnie utworzonych głosów neuronowych, które wychodzą z pudełka, możesz również utworzyć niestandardowy głos neuronowy , który jest rozpoznawalny i unikatowy dla marki lub produktu. Niestandardowe neuronowe głosy są prywatne i mogą oferować przewagę konkurencyjną. Zapoznaj się z niestandardowymi przykładami neuronowych głosów tutaj.
Tłumaczenie mowy
Tłumaczenie mowy umożliwia tłumaczenie mowy w czasie rzeczywistym, wielojęzyczne tłumaczenie mowy na aplikacje, narzędzia i urządzenia. Ta funkcja umożliwia zamianę mowy na mowę i mowę na tłumaczenie tekstu.
Identyfikacja języka
Identyfikacja języka służy do identyfikowania języków mówionych w dźwiękach w porównaniu z listą obsługiwanych języków. Użyj samej identyfikacji języka z rozpoznawaniem mowy do rozpoznawania tekstu lub tłumaczenia mowy.
Rozpoznawanie osoby mówiącej
Rozpoznawanie osoby mówiącej udostępnia algorytmy weryfikujące i identyfikujące osoby mówiące o ich unikatowych cechach głosowych. Rozpoznawanie osoby mówiącej służy do odpowiadania na pytanie "Kto mówi?".
Ocena wymowy
Ocena wymowy ocenia wymowę mowy i przekazuje głośnikom opinie na temat dokładności i biegłości dźwięku mówionego. Dzięki ocenie wymowy osoby uczące się języka mogą ćwiczyć, uzyskiwać natychmiastowe opinie i poprawiać swoją wymowę, tak aby potrafiły mówić i przekazywać informacje z pewnością siebie.
Rozpoznawanie intencji
Rozpoznawanie intencji: używaj mowy do tekstu z interpretacją języka konwersacyjnego, aby uzyskać intencje użytkownika na podstawie transkrypcji mowy i wykonywać działania na poleceniach głosowych.
Dostarczanie i obecność
Funkcje usługi Azure AI Speech można wdrożyć w chmurze lub lokalnie.
Dzięki kontenerom możesz przybliżyć usługę do danych ze względów zgodności, zabezpieczeń lub innych powodów operacyjnych.
Wdrożenie usługi Mowa w suwerennych chmurach jest dostępne dla niektórych jednostek rządowych i ich partnerów. Na przykład chmura Azure Government jest dostępna dla jednostek rządowych USA i ich partnerów. Platforma Microsoft Azure obsługiwana przez chmurę 21Vianet jest dostępna dla organizacji z obecnością biznesową w Chinach. Aby uzyskać więcej informacji, zobacz suwerenne chmury.
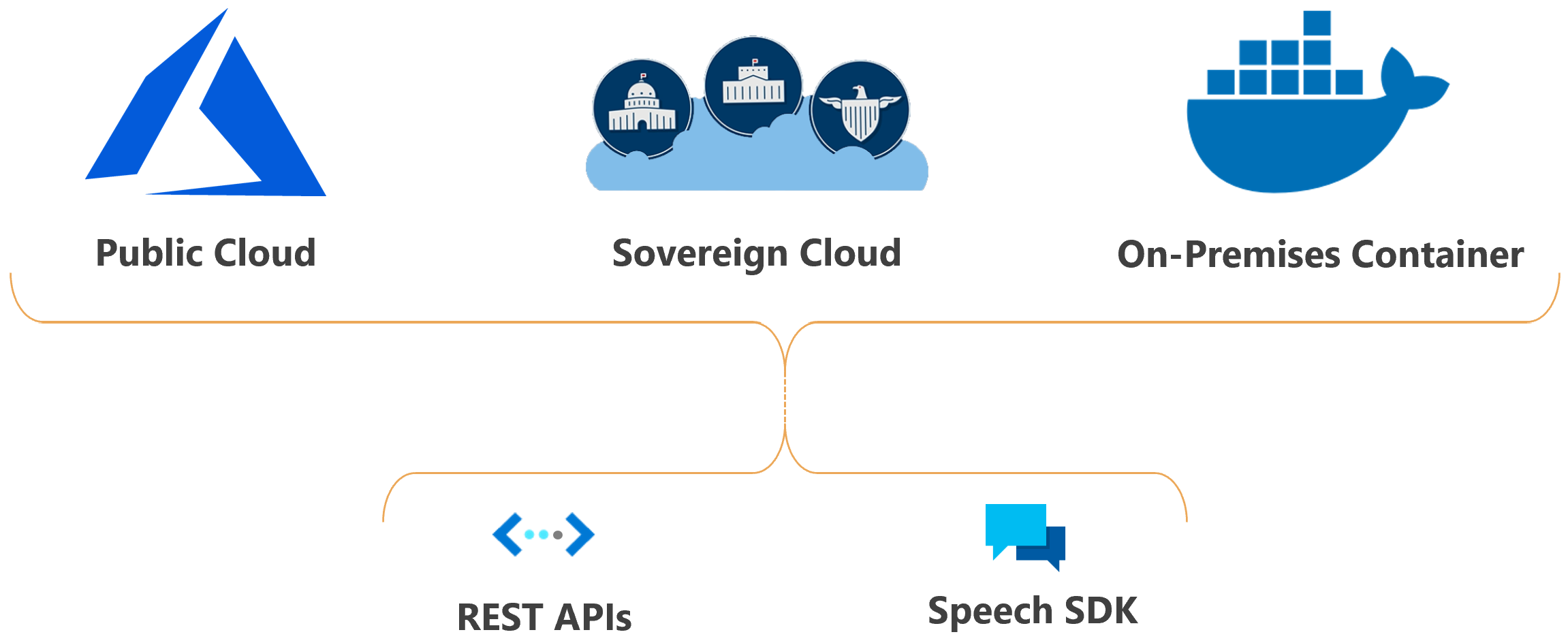
Używanie mowy w aplikacji
Usługa Speech Studio to zestaw narzędzi opartych na interfejsie użytkownika do tworzenia i integrowania funkcji z usługi Mowa azure AI w aplikacjach. Projekty można tworzyć w programie Speech Studio przy użyciu podejścia bez kodu, a następnie odwoływać się do tych zasobów w aplikacjach przy użyciu zestawu Speech SDK, interfejsu wiersza polecenia usługi Mowa lub interfejsów API REST.
Interfejs wiersza polecenia usługi Mowa to narzędzie wiersza polecenia do korzystania z usługi Mowa bez konieczności pisania kodu. Większość funkcji zestawu SDK usługi Mowa jest dostępnych w interfejsie wiersza polecenia usługi Mowa, a niektóre zaawansowane funkcje i dostosowania zostały uproszczone w interfejsie wiersza polecenia usługi Mowa.
Zestaw SPEECH SDK uwidacznia wiele funkcji usługi Mowa, których można użyć do tworzenia aplikacji z obsługą mowy. Zestaw SPEECH SDK jest dostępny w wielu językach programowania i na wszystkich platformach.
W niektórych przypadkach nie można używać zestawu SDK usługi Mowa lub nie należy ich używać. W takich przypadkach możesz użyć interfejsów API REST, aby uzyskać dostęp do usługi Mowa. Na przykład użyj interfejsów API REST do transkrypcji wsadowej i interfejsów API REST rozpoznawania osoby mówiącej.
Rozpocznij
Oferujemy przewodniki Szybki start w wielu popularnych językach programowania. Każdy przewodnik Szybki start jest przeznaczony do uczenia podstawowych wzorców projektowania i uruchamiania kodu w czasie krótszym niż 10 minut. Zapoznaj się z następującą listą przewodników Szybki start dla każdej funkcji:
- Przewodnik Szybki start dotyczący zamiany mowy na tekst
- Przewodnik Szybki start dotyczący zamiany tekstu na mowę
- Przewodnik Szybki start dotyczący tłumaczenia mowy
Przykłady kodu
Przykładowy kod usługi Mowa jest dostępny w witrynie GitHub. Te przykłady obejmują typowe scenariusze, takie jak odczytywanie dźwięku z pliku lub strumienia, ciągłe i jednosstrzałowe rozpoznawanie oraz praca z modelami niestandardowymi. Użyj tych linków, aby wyświetlić przykłady zestawu SDK i interfejsu REST:
- Przykłady zamiany mowy na tekst, zamiany tekstu na mowę i tłumaczenia mowy (SDK)
- Przykłady transkrypcji wsadowej (REST)
- Przykłady zamiany tekstu na mowę (REST)
- Przykłady asystenta głosowego (SDK)
Odpowiedzialne AI
System sztucznej inteligencji obejmuje nie tylko technologię, ale także osoby, które go używają, osoby, których to dotyczy, oraz środowisko, w którym jest wdrażane. Zapoznaj się z uwagami dotyczącymi przejrzystości, aby dowiedzieć się więcej na temat odpowiedzialnego używania sztucznej inteligencji i wdrażania w systemach.
Zamiana mowy na tekst
- Notatka dotycząca przezroczystości i przypadki użycia
- Cechy i ograniczenia
- Integracja i odpowiedzialne użycie
- Dane, prywatność i bezpieczeństwo
Ocena wymowy
Niestandardowy neuronowy głos
- Notatka dotycząca przezroczystości i przypadki użycia
- Cechy i ograniczenia
- Ograniczony dostęp
- Odpowiedzialne wdrażanie mowy syntetycznej
- Ujawnianie talentów głosowych
- Ujawnianie wytycznych dotyczących projektowania
- Ujawnianie wzorców projektowych
- Kodeks postępowania
- Dane, prywatność i bezpieczeństwo
Rozpoznawanie osoby mówiącej
- Notatka dotycząca przezroczystości i przypadki użycia
- Cechy i ograniczenia
- Ograniczony dostęp
- Ogólne wytyczne
- Dane, prywatność i bezpieczeństwo