Uzupełnianie przechowywane w usłudze Azure OpenAI i destylowanie (wersja zapoznawcza)
Zapisane uzupełnienia umożliwiają przechwytywanie historii konwersacji z sesji ukończenia czatu do użycia jako zestawy danych na potrzeby ocen i dostrajania.
Obsługa przechowywanych uzupełnień
Obsługa interfejsu API
2024-10-01-preview
Obsługa modelu
gpt-4o-2024-08-06
Dostępność w regionach
- Szwecja Środkowa
- Północno-środkowe stany USA
- Wschodnie stany USA 2
Konfigurowanie przechowywanych uzupełnień
Aby włączyć przechowywane uzupełnienia dla wdrożenia usługi Azure OpenAI, ustaw store parametr na Truewartość . Użyj parametru metadata , aby wzbogacić przechowywany zestaw danych uzupełniania o dodatkowe informacje.
import os
from openai import AzureOpenAI
from azure.identity import DefaultAzureCredential, get_bearer_token_provider
token_provider = get_bearer_token_provider(
DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default"
)
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
azure_ad_token_provider=token_provider,
api_version="2024-10-01-preview"
)
completion = client.chat.completions.create(
model="gpt-4o", # replace with model deployment name
store= True,
metadata = {
"user": "admin",
"category": "docs-test",
},
messages=[
{"role": "system", "content": "Provide a clear and concise summary of the technical content, highlighting key concepts and their relationships. Focus on the main ideas and practical implications."},
{"role": "user", "content": "Ensemble methods combine multiple machine learning models to create a more robust and accurate predictor. Common techniques include bagging (training models on random subsets of data), boosting (sequentially training models to correct previous errors), and stacking (using a meta-model to combine base model predictions). Random Forests, a popular bagging method, create multiple decision trees using random feature subsets. Gradient Boosting builds trees sequentially, with each tree focusing on correcting the errors of previous trees. These methods often achieve better performance than single models by reducing overfitting and variance while capturing different aspects of the data."}
]
)
print(completion.choices[0].message)
Po włączeniu przechowywanych uzupełnień dla wdrożenia usługi Azure OpenAI rozpocznie się on w portalu usługi Azure AI Foundry w okienku Przechowywane uzupełnienia .

Destylacja
Destylacja umożliwia przekształcenie przechowywanych uzupełnień w zestaw danych dostrajania. Typowym przypadkiem użycia jest użycie przechowywanych uzupełnień z większym bardziej zaawansowanym modelem dla określonego zadania, a następnie użycie przechowywanych uzupełnień w celu wytrenowania mniejszego modelu na przykładach wysokiej jakości interakcji modelu.
Destylacja wymaga co najmniej 10 przechowywanych uzupełnień, chociaż zaleca się zapewnienie setek do tysięcy przechowywanych uzupełnień w celu uzyskania najlepszych wyników.
W okienku Przechowywane uzupełnienia w portalu usługi Azure AI Foundry użyj opcji Filtr , aby wybrać uzupełnienia, za pomocą których chcesz wytrenować model.
Aby rozpocząć destylację, wybierz pozycję Destyluj
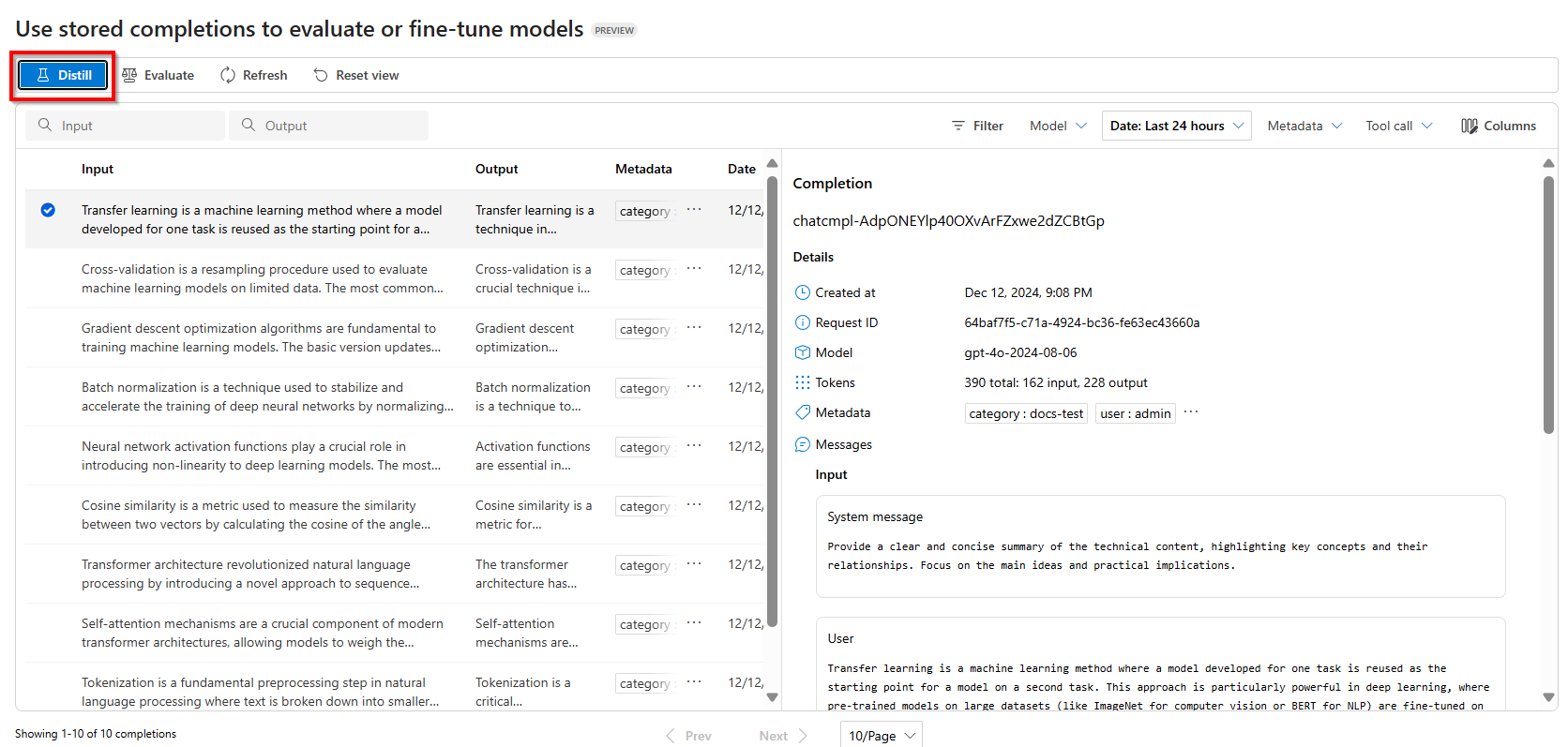
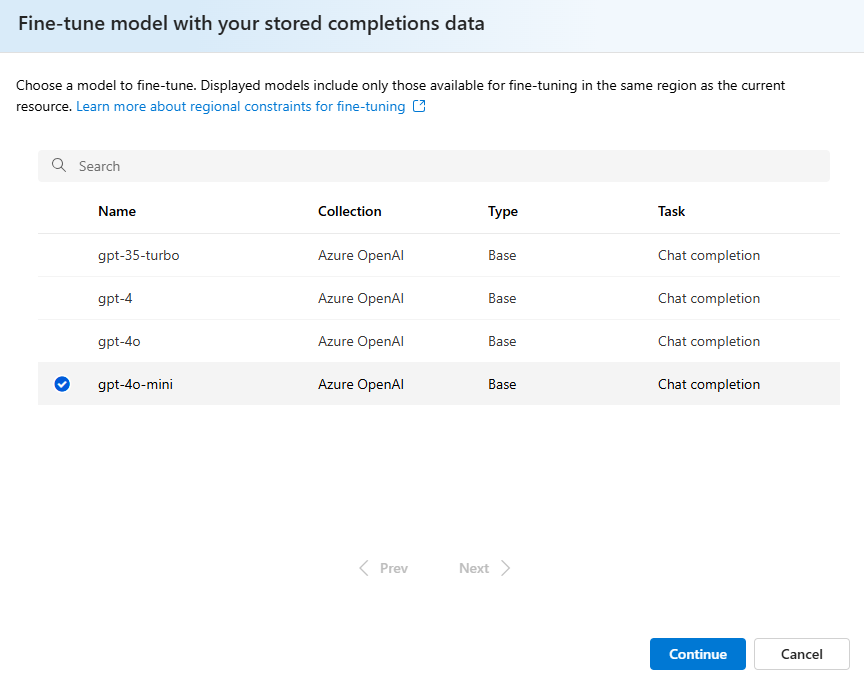
Wybierz model, który chcesz dostosować do przechowywanego zestawu danych uzupełniania.
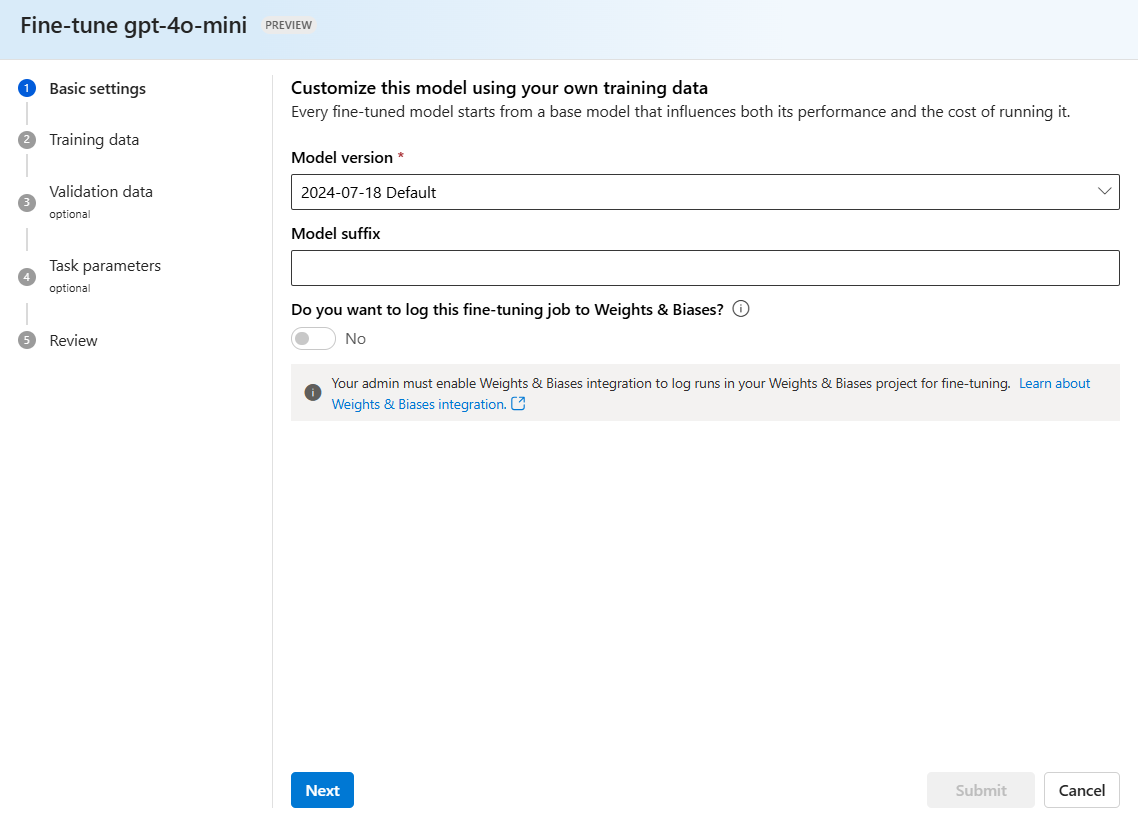
Sprawdź, która wersja modelu ma zostać dostrojona:
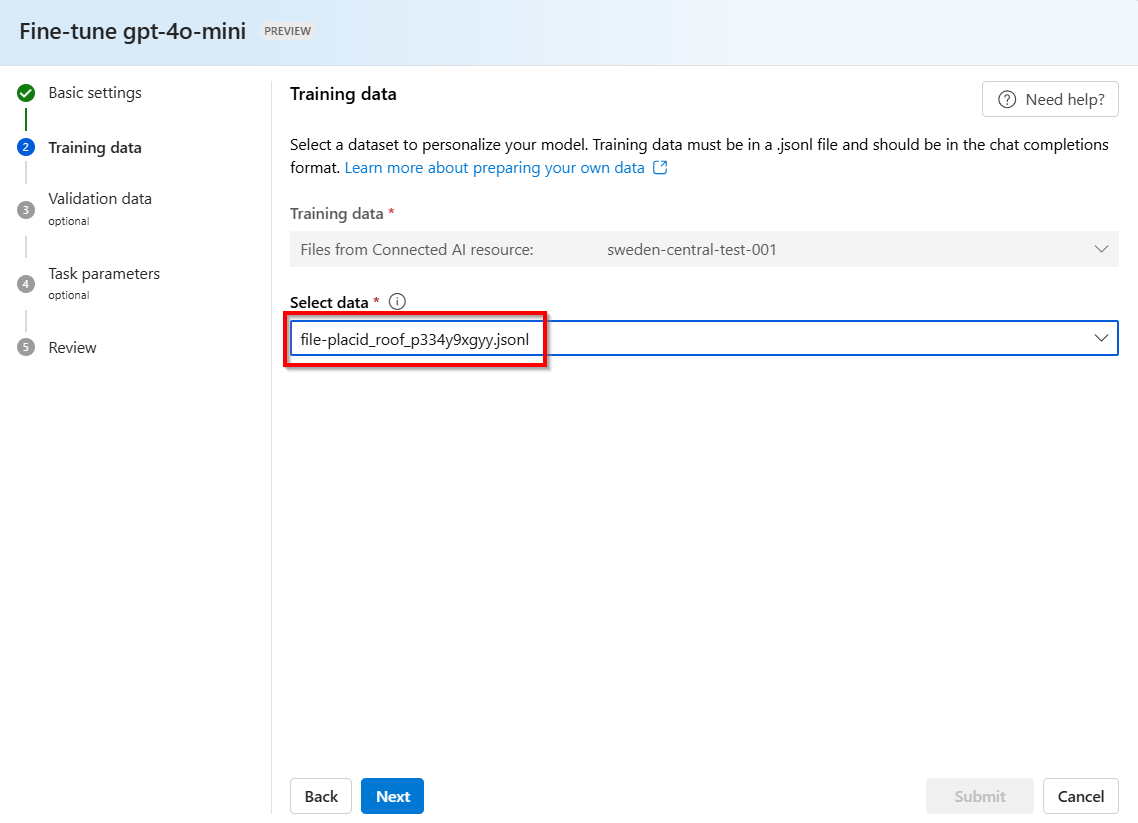
Plik
.jsonlo losowo wygenerowanej nazwie zostanie utworzony jako zestaw danych szkoleniowych z przechowywanych uzupełnień. Wybierz plik >Dalej.Uwaga
Nie można uzyskać bezpośredniego dostępu do przechowywanych plików trenowania destylowania uzupełniania i nie można ich wyeksportować zewnętrznie/pobrać.




Pozostałe kroki odpowiadają typowym krokom dostrajania interfejsu Azure OpenAI. Aby dowiedzieć się więcej, zobacz nasz przewodnik wprowadzający dostrajania.
Ocena
Ocena dużych modeli językowych jest krytycznym krokiem w mierzeniu ich wydajności w różnych zadaniach i wymiarach. Jest to szczególnie ważne w przypadku dostosowanych modeli, w których ocena zysków wydajności (lub strat) z trenowania ma kluczowe znaczenie. Dokładne oceny mogą pomóc w zrozumieniu, w jaki sposób różne wersje modelu mogą mieć wpływ na aplikację lub scenariusz.
Przechowywane uzupełnienia mogą służyć jako zestaw danych do uruchamiania ocen.
W okienku Przechowywane uzupełnienia w portalu usługi Azure AI Foundry użyj opcji Filtr , aby wybrać uzupełnienia, które mają być częścią zestawu danych oceny.
Aby skonfigurować ocenę, wybierz pozycję Oceń
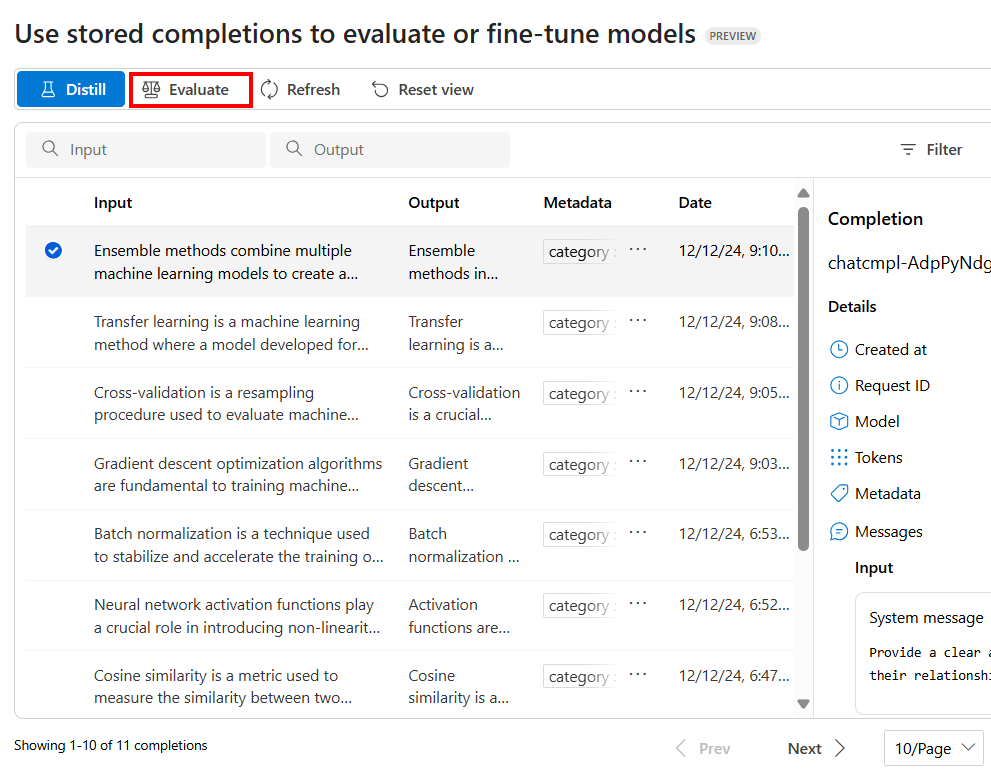
Spowoduje to uruchomienie okienka Oceny ze wstępnie wypełnionym
.jsonlplikiem z losowo wygenerowaną nazwą utworzoną jako zestaw danych oceny na podstawie przechowywanych uzupełnień.Uwaga
Nie można uzyskać bezpośredniego dostępu do przechowywanych plików danych oceny ukończenia i nie można ich wyeksportować zewnętrznie/pobrać.


Aby dowiedzieć się więcej na temat oceny, zobacz Wprowadzenie do ocen
Rozwiązywanie problemów
Czy potrzebuję specjalnych uprawnień do korzystania z przechowywanych uzupełnień?
Dostęp do przechowywanych uzupełnień jest kontrolowany za pośrednictwem dwóch funkcji DataActions:
Microsoft.CognitiveServices/accounts/OpenAI/stored-completions/readMicrosoft.CognitiveServices/accounts/OpenAI/stored-completions/action
Domyślnie Cognitive Services OpenAI Contributor ma dostęp do obu tych uprawnień:

Jak mogę usunąć przechowywane dane?
Dane można usunąć, usuwając skojarzony zasób usługi Azure OpenAI. Jeśli chcesz usunąć tylko przechowywane dane ukończenia, musisz otworzyć sprawę z pomocą techniczną klienta.
Ile przechowywanych danych ukończenia można przechowywać?
Możesz przechowywać maksymalnie 10 GB danych.
Czy mogę zapobiec włączeniu przechowywanych uzupełnień w ramach subskrypcji?
Należy otworzyć zgłoszenie z pomocą techniczną klienta, aby wyłączyć przechowywane uzupełnienia na poziomie subskrypcji.
TypeError: Completions.create() otrzymał nieoczekiwany argument "store"
Ten błąd występuje, gdy korzystasz ze starszej wersji biblioteki klienta openAI, która poprzedza wydanie funkcji uzupełniania przechowywanych. Uruchom program pip install openai --upgrade.