Ocena usługi Azure OpenAI (wersja zapoznawcza)
Ocena dużych modeli językowych jest krytycznym krokiem w mierzeniu ich wydajności w różnych zadaniach i wymiarach. Jest to szczególnie ważne w przypadku dostosowanych modeli, w których ocena zysków wydajności (lub strat) z trenowania ma kluczowe znaczenie. Dokładne oceny mogą pomóc w zrozumieniu, w jaki sposób różne wersje modelu mogą mieć wpływ na aplikację lub scenariusz.
Ocena interfejsu Azure OpenAI umożliwia deweloperom tworzenie przebiegów oceny w celu przetestowania oczekiwanych par danych wejściowych/wyjściowych, oceniając wydajność modelu między kluczowymi metrykami, takimi jak dokładność, niezawodność i ogólna wydajność.
Obsługa ocen
Dostępność w regionach
- Wschodnie stany USA 2
- Północno-środkowe stany USA
- Szwecja Środkowa
- Szwajcaria Zachodnia
Obsługiwane typy wdrożeń
- Standardowa
- Globalny standard
- Standard strefy danych
- Zarządzanie aprowizowane
- Globalna aprowizacja zarządzana
- Strefa danych zarządzana aprowizowana
Potok oceny
Dane testowe
Musisz zebrać zestaw danych podstawowej prawdy, względem którego chcesz przeprowadzić test. Tworzenie zestawu danych jest zazwyczaj procesem iteracyjnym, który gwarantuje, że oceny pozostaną istotne dla scenariuszy w czasie. Ten zestaw danych podstawowej prawdy jest zwykle ręcznie wykonany i reprezentuje oczekiwane zachowanie modelu. Zestaw danych jest również oznaczony etykietą i zawiera oczekiwane odpowiedzi.
Uwaga
Niektóre testy ewaluacyjne, takie jak Sentiment i valid JSON lub XML , nie wymagają danych podstawowych prawdy.
Źródło danych musi być w formacie JSONL. Poniżej przedstawiono dwa przykłady zestawów danych oceny JSONL:
Format oceny
{"question": "Find the degree for the given field extension Q(sqrt(2), sqrt(3), sqrt(18)) over Q.", "subject": "abstract_algebra", "A": "0", "B": "4", "C": "2", "D": "6", "answer": "B", "completion": "B"}
{"question": "Let p = (1, 2, 5, 4)(2, 3) in S_5 . Find the index of <p> in S_5.", "subject": "abstract_algebra", "A": "8", "B": "2", "C": "24", "D": "120", "answer": "C", "completion": "C"}
{"question": "Find all zeros in the indicated finite field of the given polynomial with coefficients in that field. x^5 + 3x^3 + x^2 + 2x in Z_5", "subject": "abstract_algebra", "A": "0", "B": "1", "C": "0,1", "D": "0,4", "answer": "D", "completion": "D"}
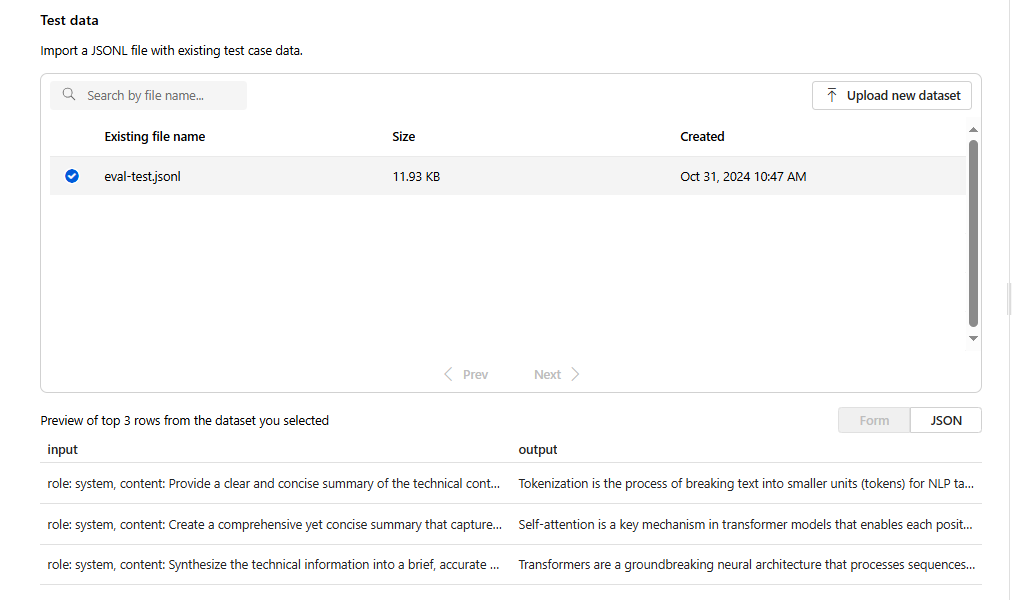
Po przekazaniu i wybraniu pliku oceny zostanie zwrócony podgląd pierwszych trzech wierszy:


Możesz wybrać wszystkie istniejące wcześniej przekazane zestawy danych lub przekazać nowy zestaw danych.
Tworzenie odpowiedzi (opcjonalnie)
Monit używany w ocenie powinien odpowiadać monitowi, który ma być używany w środowisku produkcyjnym. Te monity zawierają instrukcje dotyczące działania modelu. Podobnie jak w przypadku środowisk zabaw, możesz utworzyć wiele danych wejściowych, aby uwzględnić kilka przykładów w wierszu polecenia. Aby uzyskać więcej informacji, zobacz monituj techniki inżynieryjne, aby uzyskać szczegółowe informacje na temat niektórych zaawansowanych technik w zakresie projektowania monitów i monitowania inżynieryjnego.
Możesz odwoływać się do danych wejściowych w monitach przy użyciu {{input.column_name}} formatu, w którym column_name odpowiada nazwom kolumn w pliku wejściowym.
Dane wyjściowe wygenerowane podczas oceny zostaną przywołyzowane w kolejnych krokach przy użyciu {{sample.output_text}} formatu.
Uwaga
Należy użyć podwójnych nawiasów klamrowych, aby upewnić się, że prawidłowo odwołujesz się do danych.
Wdrożenie modelu
W ramach tworzenia ocen wybierzesz modele, które mają być używane podczas generowania odpowiedzi (opcjonalnie), a także modeli do użycia podczas klasyfikacji modeli z określonymi kryteriami testowania.
W usłudze Azure OpenAI przypiszesz konkretne wdrożenia modelu do użycia w ramach ocen. Można porównać wiele wdrożeń modelu w jednym przebiegu oceny.
Możesz ocenić wdrożenia modelu podstawowego lub precyzyjnego. Wdrożenia dostępne na liście zależą od wdrożeń utworzonych w ramach zasobu usługi Azure OpenAI. Jeśli nie możesz znaleźć żądanego wdrożenia, możesz utworzyć nowy z poziomu strony oceny usługi Azure OpenAI.
Kryteria testowania
Kryteria testowania służą do oceny skuteczności poszczególnych danych wyjściowych generowanych przez model docelowy. Te testy porównują dane wejściowe z danymi wyjściowymi, aby zapewnić spójność. Masz elastyczność konfigurowania różnych kryteriów testowania i mierzenia jakości i istotności danych wyjściowych na różnych poziomach.

Wprowadzenie
Wybierz pozycję Azure OpenAI Evaluation (WERSJA ZAPOZNAWCZA) w portalu azure AI Foundry. Aby zobaczyć ten widok jako opcję, może być konieczne najpierw wybranie istniejącego zasobu usługi Azure OpenAI w obsługiwanym regionie.
Wybierz pozycję Nowa ocena
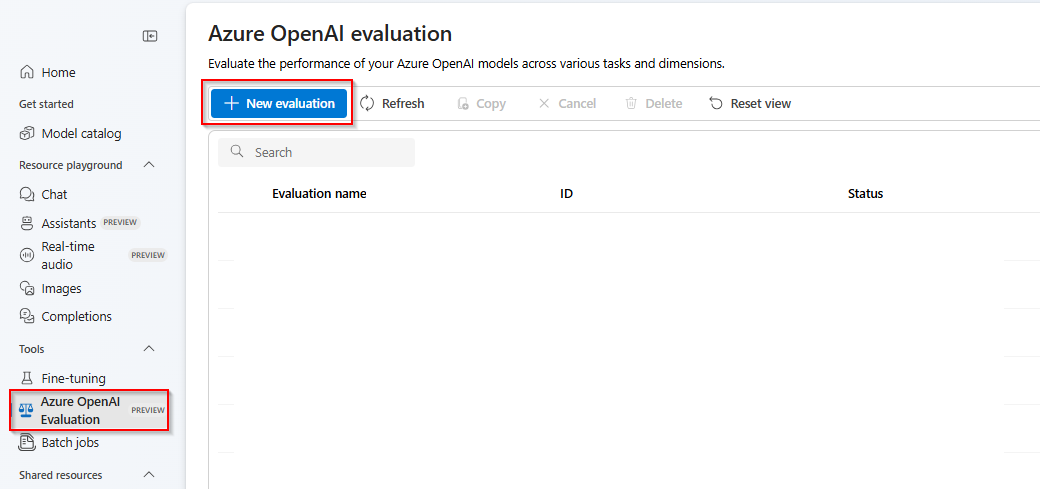
Wprowadź nazwę oceny. Domyślnie losowa nazwa jest generowana automatycznie, chyba że zostanie edytowana i zamieniona. Wybierz pozycję Przekaż nowy zestaw danych.
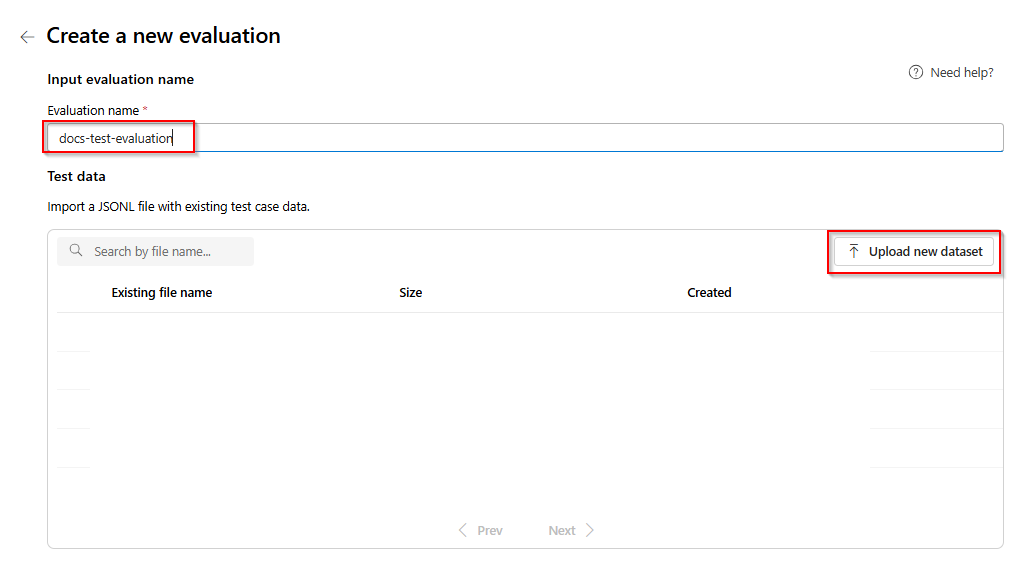
Wybierz ocenę, która będzie w
.jsonlformacie. Jeśli potrzebujesz przykładowego pliku testowego, możesz zapisać te 10 wierszy w pliku o nazwieeval-test.jsonl:{"input": [{"role": "system", "content": "Provide a clear and concise summary of the technical content, highlighting key concepts and their relationships. Focus on the main ideas and practical implications."}, {"role": "user", "content": "Tokenization is a key step in preprocessing for natural language processing, involving the division of text into smaller components called tokens. These can be words, subwords, or characters, depending on the method chosen. Word tokenization divides text at word boundaries, while subword techniques like Byte Pair Encoding (BPE) or WordPiece can manage unknown words by breaking them into subunits. Character tokenization splits text into individual characters, useful for multiple languages and misspellings. The tokenization method chosen greatly affects model performance and its capacity to handle various languages and vocabularies."}], "output": "Tokenization divides text into smaller units (tokens) for NLP applications, using word, subword (e.g., BPE), or character methods. Each has unique benefits, impacting model performance and language processing capabilities."} {"input": [{"role": "system", "content": "Create a comprehensive yet concise summary that captures the essential technical details and significance of the topic."}, {"role": "user", "content": "Self-attention mechanisms are vital in modern transformer models, allowing them to evaluate the relevance of different parts of an input sequence when processing each element. In self-attention, each position in a sequence learns to focus on all other positions, forming a weighted sum of their values. Attention weights are derived using queries, keys, and values, with compatibility between a query and key determining attention to each value. This mechanism enables capturing long-range dependencies and relationships within a sequence, making it effective for tasks needing context understanding and inter-part relationships."}], "output": "Self-attention is crucial in transformers, enabling each sequence position to evaluate and collect data from all others. It uses queries, keys, and values for attention weights, effectively capturing long-range dependencies and contextual links."} {"input": [{"role": "system", "content": "Synthesize the technical information into a brief, accurate summary that maintains the core concepts and their significance."}, {"role": "user", "content": "The transformer architecture significantly changed natural language processing by introducing a new method for sequence processing. Unlike recurrent neural networks, transformers process whole sequences at once using self-attention. The architecture consists of an encoder and decoder, each with multiple layers of multi-head attention, feed-forward networks, and normalization layers. The encoder processes the input sequence, and the decoder produces the output sequence. Positional encodings are added to retain sequence order information since the model lacks inherent sequence position awareness. This architecture underlies many leading language models like BERT and GPT."}], "output": "Transformers are a transformative neural architecture processing sequences with self-attention instead of recurrence. Their encoder-decoder design, with multi-head attention and position encodings, is fundamental to modern language models like BERT and GPT."} {"input": [{"role": "system", "content": "Distill the technical content into a clear, concise summary that preserves the most important concepts and their practical applications."}, {"role": "user", "content": "Cosine similarity is a metric for measuring similarity between vectors by calculating the cosine of the angle between them. The outcome ranges from -1 to 1, with 1 indicating identical orientation, 0 orthogonality, and -1 opposite orientation. In machine learning and NLP, cosine similarity is useful for comparing document vectors, word embeddings, or any high-dimensional representations. It's often preferred over Euclidean distance because it's invariant to vector magnitude, focusing instead on orientation. This makes it particularly useful for comparing documents or embeddings of various lengths or scales."}], "output": "Cosine similarity evaluates vector similarity by computing their angle's cosine, with values from -1 to 1. It's widely used in ML and NLP for comparing document vectors and embeddings due to its magnitude-invariant nature."} {"input": [{"role": "system", "content": "Provide a succinct summary that captures the key technical concepts and their relationships while maintaining clarity and accuracy."}, {"role": "user", "content": "Neural network activation functions are crucial for introducing non-linearity to deep learning models. Commonly used activation functions include ReLU (Rectified Linear Unit), which outputs the input directly if positive and zero otherwise, sigmoid, which compresses values between 0 and 1, and tanh, which normalizes values between -1 and 1. Each function has specific benefits and applications: ReLU avoids vanishing gradients and enables sparse activation, sigmoid is useful for binary classification, and tanh is often used in hidden layers for its zero-centered output. The activation function choice greatly affects model training dynamics and ultimate performance."}], "output": "Activation functions introduce non-linearity to neural networks, with ReLU, sigmoid, and tanh being the most common. Each serves distinct purposes: ReLU prevents vanishing gradients, sigmoid is suitable for binary classification, and tanh offers zero-centered output, all affecting model performance differently."} {"input": [{"role": "system", "content": "Create a focused summary that emphasizes the main technical concepts and their practical implications while maintaining accuracy."}, {"role": "user", "content": "Batch normalization is a technique that stabilizes and accelerates deep neural network training by normalizing each layer's inputs. It normalizes activations using the mean and variance computed over the current data batch. This normalization reduces internal covariate shift, where the input distribution changes during training. Batch normalization includes learnable parameters (gamma and beta) allowing the network to reverse normalization if necessary. Benefits include enabling higher learning rates, lessening the importance of precise parameter initialization, and serving as a regularizer, potentially removing the need for dropout."}], "output": "Batch normalization stabilizes neural network training by normalizing layer inputs using batch statistics. It addresses internal covariate shift with learnable parameters, allowing higher learning rates and improved training dynamics, while offering regularization benefits."} {"input": [{"role": "system", "content": "Summarize the technical content while preserving the essential concepts and their interconnections, ensuring clarity and precision."}, {"role": "user", "content": "Gradient descent optimization algorithms are foundational to training machine learning models. The basic version updates parameters in the steepest descent direction of the loss function. Variants like Stochastic Gradient Descent (SGD) use random samples to estimate gradients, enhancing computational efficiency. Advanced optimizers like Adam combine momentum (helping overcome local minima) and RMSprop (adapting learning rates for each parameter). These optimizers maintain running averages of gradients and their squares, enabling adaptive learning rates and more efficient training. The optimizer choice can significantly influence model convergence speed and final performance."}], "output": "Gradient descent algorithms optimize ML models by updating parameters based on loss gradients. Variants like SGD use sampling for efficiency, while advanced optimizers like Adam combine momentum with adaptive learning rates for improved training performance."} {"input": [{"role": "system", "content": "Deliver a concise yet comprehensive summary that highlights the key technical aspects and their practical significance."}, {"role": "user", "content": "Cross-validation is a resampling method used to evaluate machine learning models on limited data. The most common form, k-fold cross-validation, involves dividing the dataset into k equal parts, training the model on k-1 folds while validating on the remaining fold, and rotating through all combinations. This provides a more robust model performance assessment than a single train-test split, helping detect overfitting and estimate model generalization to unseen data. Variations include stratified k-fold (maintaining class distribution), leave-one-out (k equals dataset size), and time series cross-validation for temporal data."}], "output": "Cross-validation evaluates ML models by training and testing on different data splits, typically using k-fold methodology. This approach offers better performance assessment than single splits, with variations for different data types and requirements."} {"input": [{"role": "system", "content": "Generate a clear and focused summary that captures the essential technical details while maintaining their relationships and significance."}, {"role": "user", "content": "Transfer learning is a machine learning method where a model developed for one task is reused as the starting point for a model on a second task. This approach is powerful in deep learning, where pre-trained models on large datasets (like ImageNet for computer vision or BERT for NLP) are fine-tuned on specific downstream tasks. Transfer learning reduces the need for large amounts of task-specific training data and computational resources, as the model has already learned useful features from the source domain. Common strategies include feature extraction (freezing pre-trained layers) and fine-tuning (updating all or some pre-trained weights)."}], "output": "Transfer learning reuses models trained on one task for different tasks, particularly effective in deep learning. It leverages pre-trained models through feature extraction or fine-tuning, reducing data and computational needs for new tasks."} {"input": [{"role": "system", "content": "Provide a precise and informative summary that distills the key technical concepts while maintaining their relationships and practical importance."}, {"role": "user", "content": "Ensemble methods combine multiple machine learning models to create a more robust and accurate predictor. Common techniques include bagging (training models on random data subsets), boosting (sequentially training models to correct earlier errors), and stacking (using a meta-model to combine base model predictions). Random Forests, a popular bagging method, create multiple decision trees using random feature subsets. Gradient Boosting builds trees sequentially, with each tree correcting the errors of previous ones. These methods often outperform single models by reducing overfitting and variance while capturing different data aspects."}], "output": "Ensemble methods enhance prediction accuracy by combining multiple models through techniques like bagging, boosting, and stacking. Popular implementations include Random Forests (using multiple trees with random features) and Gradient Boosting (sequential error correction), offering better performance than single models."}Pierwsze trzy wiersze pliku będą widoczne jako wersja zapoznawcza:
W obszarze Odpowiedzi wybierz przycisk Utwórz . Wybierz
{{item.input}}z listy rozwijanej Utwórz przy użyciu szablonu . Spowoduje to wstrzyknięcie pól wejściowych z pliku oceny do poszczególnych monitów o uruchomienie nowego modelu, które chcemy porównać z naszym zestawem danych oceny. Model weźmie te dane wejściowe i wygeneruje własne unikatowe dane wyjściowe, które w tym przypadku będą przechowywane w zmiennej o nazwie{{sample.output_text}}. Następnie użyjemy tego przykładowego tekstu wyjściowego w ramach naszych kryteriów testowania. Alternatywnie możesz ręcznie podać własny niestandardowy komunikat systemowy i poszczególne przykłady komunikatów.Wybierz model, który chcesz wygenerować odpowiedzi na podstawie oceny. Jeśli nie masz modelu, możesz go utworzyć. W tym przykładzie używamy standardowego wdrożenia
gpt-4o-miniprogramu .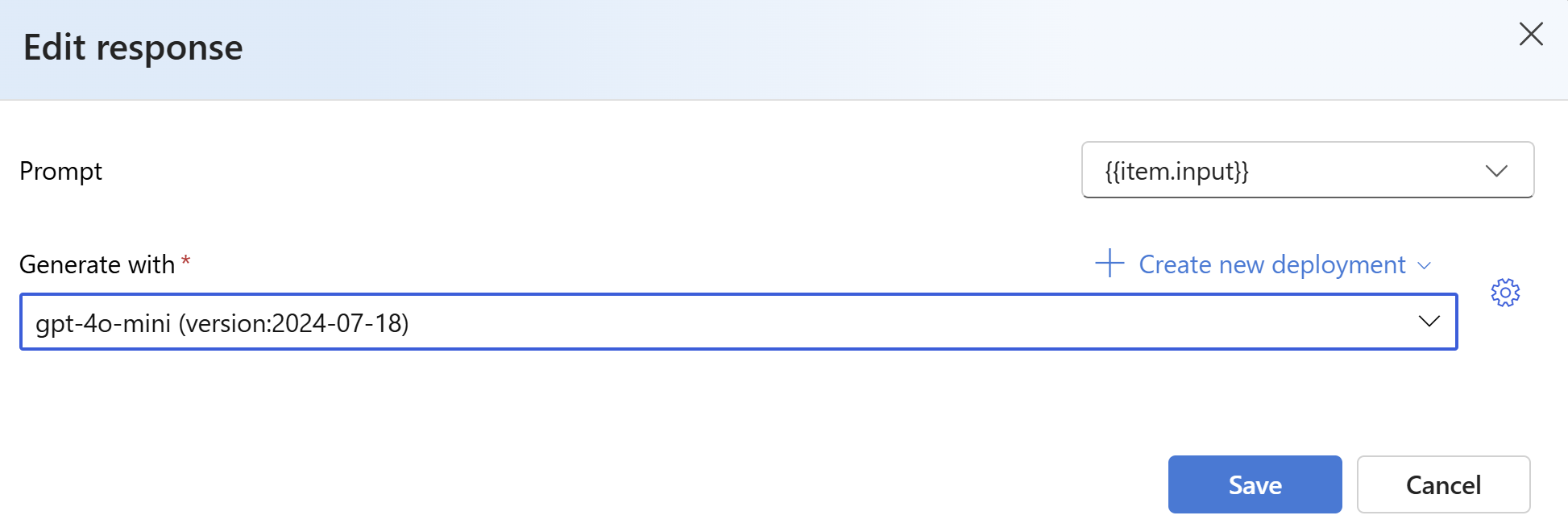
Symbol settings/sprocket steruje podstawowymi parametrami przekazywanymi do modelu. Obecnie obsługiwane są tylko następujące parametry:




- Temperatura
- Maksymalna długość
- Góra P
Maksymalna długość jest obecnie ograniczona do 2048 niezależnie od wybranego modelu.
Wybierz pozycję Dodaj kryteria testowania, wybierz pozycję Dodaj.
Wybierz pozycję Podobieństwo> semantyczne w obszarze Porównaj dodaj
{{item.output}}w obszarze Z dodaj{{sample.output_text}}. Spowoduje to utworzenie oryginalnych danych wyjściowych odwołania z pliku ewaluacyjnego.jsonli porównanie go z danymi wyjściowymi, które zostaną wygenerowane przez podanie monitów dotyczących modelu na podstawie elementu{{item.input}}.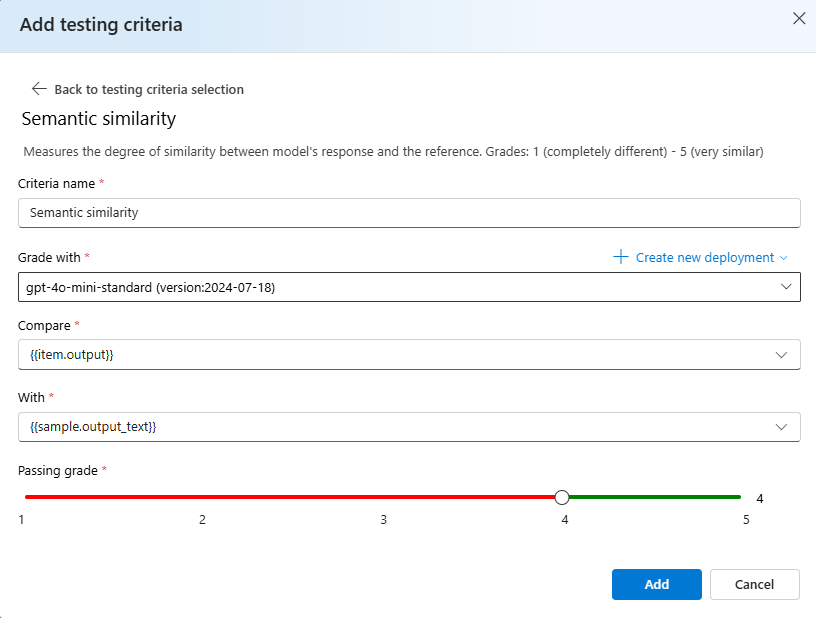
Wybierz pozycję Dodaj> w tym momencie, możesz dodać dodatkowe kryteria testowania lub wybrać pozycję Utwórz, aby zainicjować uruchomienie zadania oceny.
Po wybraniu pozycji Utwórz nastąpi przekierowanie do strony stanu zadania oceny.
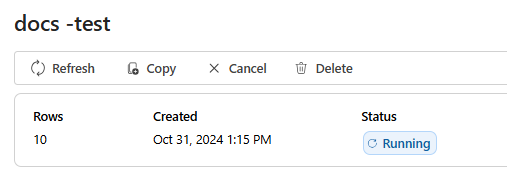
Po utworzeniu zadania oceny możesz wybrać zadanie, aby wyświetlić pełne szczegóły zadania:
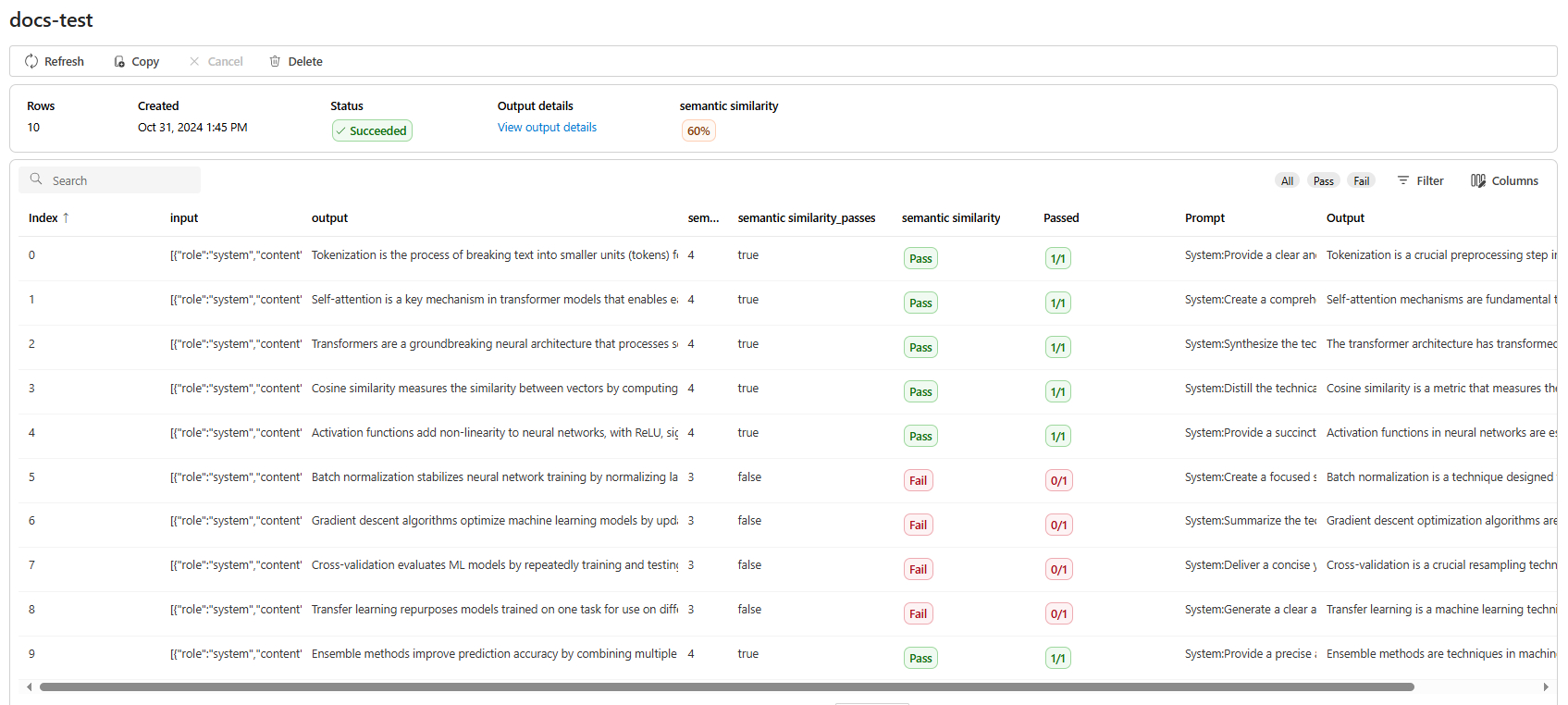
W przypadku semantycznej podobieństwa Szczegóły danych wyjściowych widoku zawierają reprezentację JSON, którą można skopiować/wkleić w testach przekazujących.
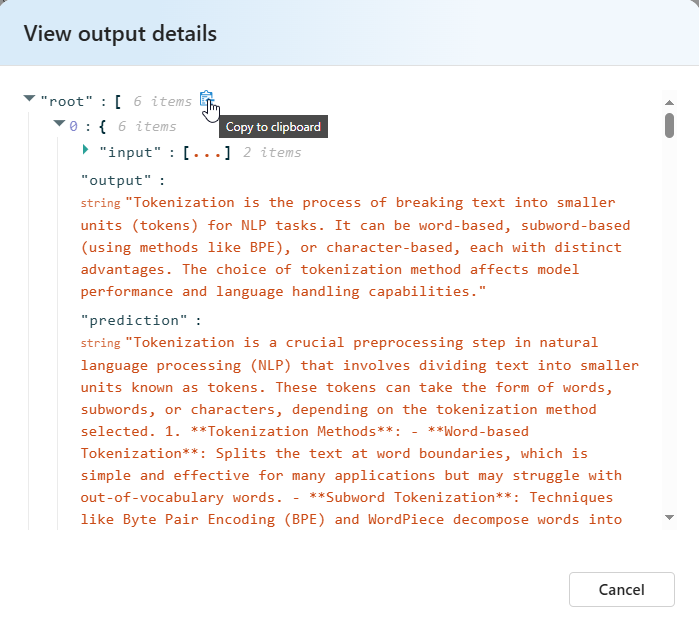




Szczegóły kryteriów testowania
Ocena usługi Azure OpenAI oferuje wiele opcji kryteriów testowania. Poniższa sekcja zawiera dodatkowe szczegóły dotyczące każdej opcji.
Rzeczowość
Ocenia dokładność faktów przesłanej odpowiedzi, porównując ją z odpowiedzią eksperta.
Rzeczowość ocenia faktyczne dokładność przesłanej odpowiedzi, porównując ją z odpowiedzią eksperta. Korzystając ze szczegółowego monitu łańcucha myśli (CoT), klasykator określa, czy przesłana odpowiedź jest zgodna z podzbiorem, nadzbiorem lub w konflikcie z odpowiedzią eksperta. Lekceważy różnice w stylu, gramatyce lub interpunkcji, koncentrując się wyłącznie na treściach faktycznych. Faktów może być przydatne w wielu scenariuszach, w tym między innymi w przypadku weryfikacji zawartości i narzędzi edukacyjnych zapewniających dokładność odpowiedzi dostarczonych przez sztuczną inteligencję.

Tekst monitu używany w ramach tych kryteriów testowania można wyświetlić, wybierając listę rozwijaną obok monitu. Bieżący tekst monitu to:
Prompt
You are comparing a submitted answer to an expert answer on a given question.
Here is the data:
[BEGIN DATA]
************
[Question]: {input}
************
[Expert]: {ideal}
************
[Submission]: {completion}
************
[END DATA]
Compare the factual content of the submitted answer with the expert answer. Ignore any differences in style, grammar, or punctuation.
The submitted answer may either be a subset or superset of the expert answer, or it may conflict with it. Determine which case applies. Answer the question by selecting one of the following options:
(A) The submitted answer is a subset of the expert answer and is fully consistent with it.
(B) The submitted answer is a superset of the expert answer and is fully consistent with it.
(C) The submitted answer contains all the same details as the expert answer.
(D) There is a disagreement between the submitted answer and the expert answer.
(E) The answers differ, but these differences don't matter from the perspective of factuality.
Podobieństwo semantyczne
Mierzy stopień podobieństwa między odpowiedzią modelu a odwołaniem.
Grades: 1 (completely different) - 5 (very similar).

Opinia
Próbuje zidentyfikować emocjonalny ton danych wyjściowych.

Tekst monitu używany w ramach tych kryteriów testowania można wyświetlić, wybierając listę rozwijaną obok monitu. Bieżący tekst monitu to:
Prompt
You will be presented with a text generated by a large language model. Your job is to rate the sentiment of the text. Your options are:
A) Positive
B) Neutral
C) Negative
D) Unsure
[BEGIN TEXT]
***
[{text}]
***
[END TEXT]
First, write out in a step by step manner your reasoning about the answer to be sure that your conclusion is correct. Avoid simply stating the correct answers at the outset. Then print only the single character (without quotes or punctuation) on its own line corresponding to the correct answer. At the end, repeat just the letter again by itself on a new line
Sprawdzanie ciągu
Sprawdza, czy dane wyjściowe są dokładnie zgodne z oczekiwanym ciągiem.

Sprawdzanie ciągu wykonuje różne operacje binarne na dwóch zmiennych ciągów, co pozwala na zastosowanie różnych kryteriów oceny. Pomaga to w weryfikowaniu różnych relacji ciągów, w tym równości, zawierania i określonych wzorców. Ten ewaluator umożliwia porównywanie bez uwzględniania wielkości liter lub wielkości liter. Udostępnia również określone oceny dla wyników true lub false, umożliwiając dostosowane wyniki oceny na podstawie wyniku porównania. Oto typ obsługiwanych operacji:
-
equals: sprawdza, czy ciąg wyjściowy jest dokładnie taki sam jak ciąg oceny. -
contains: sprawdza, czy ciąg oceny jest podciągem ciągu wyjściowego. -
starts-with: sprawdza, czy ciąg wyjściowy rozpoczyna się od ciągu oceny. -
ends-with: sprawdza, czy ciąg wyjściowy kończy się ciągiem oceny.
Uwaga
Podczas ustawiania określonych parametrów w kryteriach testowania możesz wybrać między zmienną a szablonem. Wybierz zmienną , jeśli chcesz odwołać się do kolumny w danych wejściowych. Wybierz szablon , jeśli chcesz podać stały ciąg.
Prawidłowy kod JSON lub XML
Sprawdza, czy dane wyjściowe są prawidłowe w formacie JSON lub XML.

Dopasuj schemat
Zapewnia, że dane wyjściowe są zgodne z określoną strukturą.

Kryteria są zgodne
Oceń, czy odpowiedź modelu jest zgodna z twoimi kryteriami. Ocena: powodzenie lub niepowodzenie.

Tekst monitu używany w ramach tych kryteriów testowania można wyświetlić, wybierając listę rozwijaną obok monitu. Bieżący tekst monitu to:
Prompt
Your job is to assess the final response of an assistant based on conversation history and provided criteria for what makes a good response from the assistant. Here is the data:
[BEGIN DATA]
***
[Conversation]: {conversation}
***
[Response]: {response}
***
[Criteria]: {criteria}
***
[END DATA]
Does the response meet the criteria? First, write out in a step by step manner your reasoning about the criteria to be sure that your conclusion is correct. Avoid simply stating the correct answers at the outset. Then print only the single character "Y" or "N" (without quotes or punctuation) on its own line corresponding to the correct answer. "Y" for yes if the response meets the criteria, and "N" for no if it does not. At the end, repeat just the letter again by itself on a new line.
Reasoning:
Jakość tekstu
Oceń jakość tekstu, porównując tekst referencyjny.

Podsumowanie:
- Wynik BLEU: ocenia jakość wygenerowanego tekstu, porównując go z co najmniej jednym wysokiej jakości tłumaczeniami referencyjnymi przy użyciu wyniku BLEU.
- Wynik ROUGE: ocenia jakość wygenerowanego tekstu, porównując go z podsumowaniami referencyjnymi przy użyciu wyników ROUGE.
- Cosine: Określane również jako podobieństwo cosinus mierzy, jak blisko dwa osadzanie tekstu — takie jak dane wyjściowe modelu i teksty referencyjne — wyrównywanie znaczenia, pomagając ocenić podobieństwo semantyczne między nimi. Odbywa się to przez pomiar ich odległości w przestrzeni wektorowej.
Szczegóły:
Wynik BLEU (BiLingual Evaluation Understudy) jest często używany w przetwarzaniu języka naturalnego (NLP) i tłumaczenia maszynowego. Jest on powszechnie używany w przypadku podsumowania tekstu i generowania tekstu. Ocenia, jak blisko wygenerowany tekst jest zgodny z tekstem referencyjnym. Wynik BLEU waha się od 0 do 1, z wyższymi wynikami wskazującymi lepszą jakość.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation) to zestaw metryk używanych do oceny automatycznego podsumowania i tłumaczenia maszynowego. Mierzy nakładanie się na wygenerowany tekst i podsumowania odwołań. Rouge koncentruje się na miarach zorientowanych na kompletność, aby ocenić, jak dobrze wygenerowany tekst obejmuje tekst referencyjny. Wynik ROUGE zawiera różne metryki, w tym: • ROUGE-1: Nakładanie się jednogramów (pojedynczych słów) między wygenerowanym i referencyjnym tekstem. • ROUGE-2: Nakładanie się bigramów (dwa kolejne wyrazy) między wygenerowanym i referencyjnym tekstem. • ROUGE-3: Nakładanie się trigramów (trzy kolejne wyrazy) między wygenerowanym i referencyjnym tekstem. • ROUGE-4: Nakładanie się czterech gramów (cztery kolejne wyrazy) między wygenerowanym i referencyjnym tekstem. • ROUGE-5: Nakładanie się pięciu gramów (pięć kolejnych wyrazów) między wygenerowanym i referencyjnym tekstem. • ROUGE-L: Nakładanie się gramów L (L kolejnych wyrazów) między wygenerowanym i referencyjnym tekstem. Podsumowanie tekstu i porównanie dokumentów są jednymi z optymalnych przypadków użycia dla programu ROUGE, szczególnie w scenariuszach, w których spójność tekstu i istotność są krytyczne.
Podobieństwo cosinus mierzy, jak blisko dwa osadzania tekstu — takie jak dane wyjściowe modelu i teksty referencyjne — są zgodne ze znaczeniem, pomagając ocenić podobieństwo semantyczne między nimi. Podobnie jak w przypadku innych ewaluatorów opartych na modelu, należy podać wdrożenie modelu przy użyciu funkcji oceny.
Ważne
W przypadku tego ewaluatora obsługiwane są tylko modele osadzania:
text-embedding-3-smalltext-embedding-3-largetext-embedding-ada-002
Monit niestandardowy
Używa modelu do klasyfikowania danych wyjściowych w zestawie określonych etykiet. Ten ewaluator używa niestandardowego monitu, który należy zdefiniować.
