Wydajność i opóźnienie
W tym artykule omówiono sposób działania opóźnienia i przepływności z usługą Azure OpenAI oraz sposób optymalizacji środowiska w celu zwiększenia wydajności.
Informacje o przepływności a opóźnieniach
Istnieją dwie kluczowe pojęcia, które należy wziąć pod uwagę podczas określania rozmiaru aplikacji: (1) Przepływność na poziomie systemu mierzona w tokenach na minutę (TPM) i (2) czasy odpowiedzi na wywołanie (znane również jako opóźnienie).
Przepływność na poziomie systemu
Obejmuje to ogólną pojemność wdrożenia — liczbę żądań na minutę i łączną liczbę tokenów, które można przetworzyć.
W przypadku wdrożenia standardowego przydział przypisany do wdrożenia częściowo określa ilość przepływności, którą można osiągnąć. Jednak limit przydziału określa tylko logikę przyjmowania wywołań do wdrożenia i nie wymusza bezpośrednio przepływności. Ze względu na różnice opóźnienia poszczególnych wywołań możesz nie być w stanie osiągnąć przepływności tak wysokie, jak limit przydziału. Dowiedz się więcej na temat zarządzania limitem przydziału.
W ramach aprowizowania wdrożenia do punktu końcowego jest przydzielana zestaw pojemności przetwarzania modelu. Ilość przepływności, którą można osiągnąć w punkcie końcowym, jest czynnikiem kształtu obciążenia, w tym ilości tokenu wejściowego, ilości danych wyjściowych, szybkości wywołań i współczynnika dopasowania pamięci podręcznej. Liczba współbieżnych wywołań i łączna liczba przetworzonych tokenów może się różnić w zależności od tych wartości.
W przypadku wszystkich typów wdrożeń zrozumienie przepływności na poziomie systemu jest kluczowym składnikiem optymalizacji wydajności. Ważne jest, aby wziąć pod uwagę przepływność na poziomie systemu dla danego modelu, wersji i kombinacji obciążenia, ponieważ przepływność będzie się różnić w zależności od tych czynników.
Szacowanie przepływności na poziomie systemu
Szacowanie modułu TPM za pomocą metryk usługi Azure Monitor
Jedną z metod szacowania przepływności na poziomie systemu dla danego obciążenia jest użycie historycznych danych użycia tokenu. W przypadku obciążeń usługi Azure OpenAI dostęp do wszystkich historycznych danych użycia można uzyskać i zwizualizować za pomocą natywnych funkcji monitorowania oferowanych w ramach usługi Azure OpenAI. Do oszacowania przepływności na poziomie systemu dla obciążeń usługi Azure OpenAI potrzebne są dwie metryki: (1) Przetworzone tokeny monitu i (2) Wygenerowane tokeny ukończenia.
W połączeniu metryki przetworzonego tokenu monitu (moduł TPM) i wygenerowane tokeny ukończenia (wyjściowe moduł TPM) zapewniają szacowany widok przepływności na poziomie systemu na podstawie rzeczywistego ruchu obciążenia. Takie podejście nie uwzględnia korzyści z buforowania monitów, dlatego będzie to konserwatywne oszacowanie przepływności systemu. Te metryki można analizować przy użyciu minimalnej, średniej i maksymalnej agregacji w 1-minutowych oknach w wielotygodniowym horyzoncie czasu. Zaleca się analizowanie tych danych w wielotygodniowym horyzoncie czasu w celu zapewnienia wystarczającej ilości punktów danych do oceny. Poniższy zrzut ekranu przedstawia przykład metryki Przetworzone tokeny monitu wizualizowane w usłudze Azure Monitor, która jest dostępna bezpośrednio za pośrednictwem witryny Azure Portal.
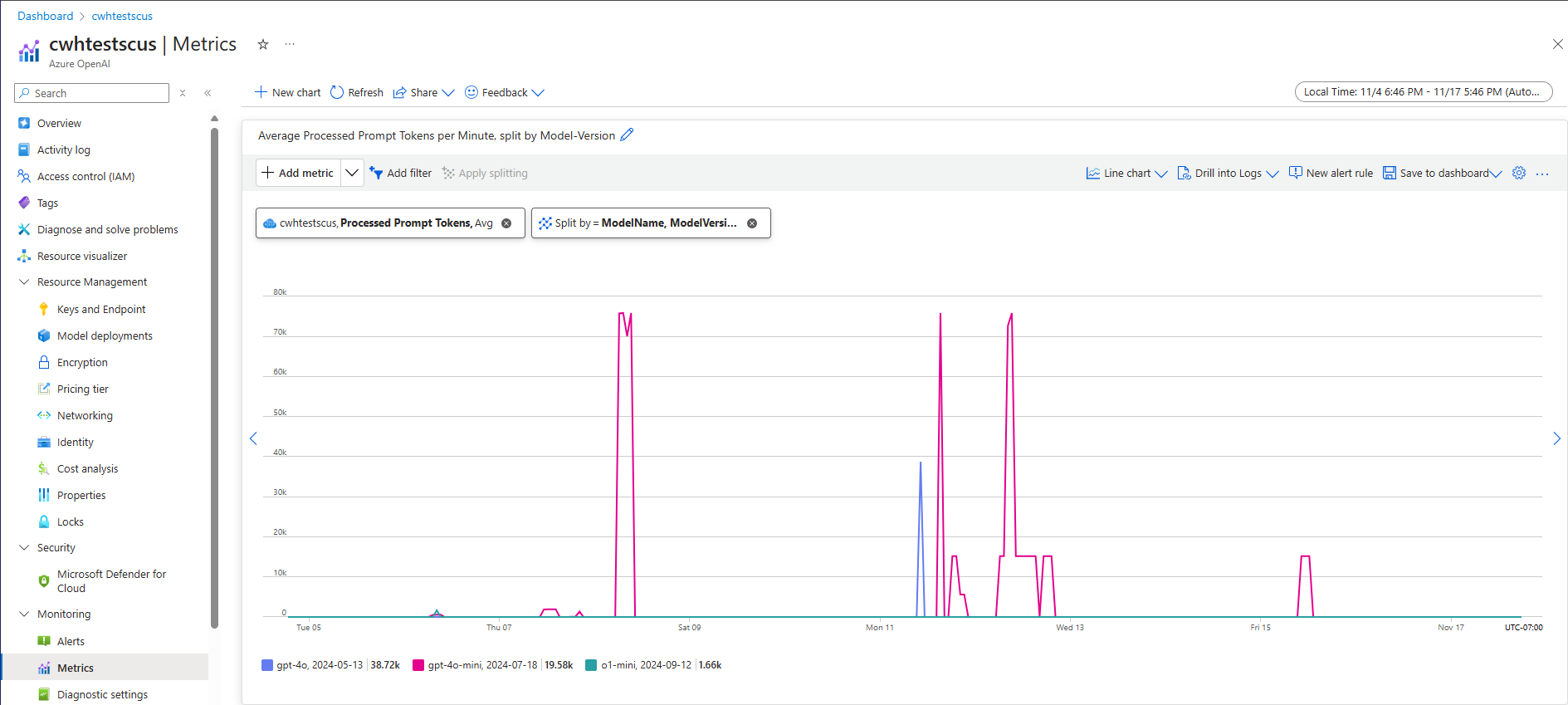
Szacowanie modułu TPM na podstawie danych żądania
Drugie podejście do szacowanej przepływności na poziomie systemu obejmuje zbieranie informacji o użyciu tokenu z danych żądania interfejsu API. Ta metoda zapewnia bardziej szczegółowe podejście do zrozumienia kształtu obciążenia na żądanie. Połączenie informacji o użyciu tokenu żądania z woluminem żądania mierzonym w żądaniach na minutę (RPM) zapewnia oszacowanie przepływności na poziomie systemu. Należy pamiętać, że wszelkie założenia dotyczące spójności informacji o użyciu tokenu w żądaniach i woluminie żądań będą mieć wpływ na szacowanie przepływności systemu. Dane wyjściowe użycia tokenu można znaleźć w szczegółach odpowiedzi interfejsu API dla danego żądania ukończenia czatu usługi Azure OpenAI Service.
{
"body": {
"id": "chatcmpl-7R1nGnsXO8n4oi9UPz2f3UHdgAYMn",
"created": 1686676106,
"choices": [...],
"usage": {
"completion_tokens": 557,
"prompt_tokens": 33,
"total_tokens": 590
}
}
}
Zakładając, że wszystkie żądania dla danego obciążenia są jednolite, tokeny monitu i tokeny uzupełniania z danych odpowiedzi interfejsu API mogą być mnożone przez szacowaną wartość RPM w celu zidentyfikowania wejściowego i wyjściowego modułu TPM dla danego obciążenia.
Jak używać oszacowań przepływności na poziomie systemu
Po oszacowaniu przepływności na poziomie systemu dla danego obciążenia te oszacowania mogą służyć do rozmiaru wdrożeń w warstwie Standardowa i Aprowizowane. W przypadku wdrożeń w warstwie Standardowa wartości wejściowe i wyjściowe modułu TPM można połączyć, aby oszacować łączną liczbę modułów TPM do przypisania do danego wdrożenia. W przypadku wdrożeń aprowizowanych dane użycia tokenu żądania lub wartości wejściowe i wyjściowe modułu TPM mogą służyć do oszacowania liczby jednostek PTU wymaganych do obsługi danego obciążenia przy użyciu środowiska kalkulatora wydajności wdrożenia.
Oto kilka przykładów minimodelki GPT-4o:
| Rozmiar monitu (tokeny) | Rozmiar generacji (tokeny) | Żądania na minutę | Wejściowy moduł TPM | Wyjściowy moduł TPM | Łączna liczba modułów TPM | Wymagane jednostki PTU |
|---|---|---|---|---|---|---|
| 800 | 150 | 30 | 24,000 | 4500 | 28,500 | 15 |
| 5,000 | 50 | 1000 | 5,000,000 | 50,000 | 5,050,000 | 140 |
| 1000 | 300 | 500 | 500,000 | 150,000 | 650,000 | 30 |
Liczba jednostek PTU jest skalowana liniowo z szybkością wywołań, gdy rozkład obciążenia pozostaje stały.
Opóźnienie: czasy odpowiedzi na wywołanie
Wysoka definicja opóźnienia w tym kontekście to czas potrzebny na odzyskanie odpowiedzi z modelu. W przypadku żądań ukończenia i ukończenia czatu opóźnienie jest w dużej mierze zależne od typu modelu, liczby tokenów w wierszu polecenia i liczby wygenerowanych tokenów. Ogólnie rzecz biorąc, każdy token monitu dodaje niewiele czasu w porównaniu do każdego wygenerowanego tokenu przyrostowego.
Szacowanie oczekiwanego opóźnienia poszczególnych wywołań może być trudne w przypadku tych modeli. Opóźnienie żądania ukończenia może się różnić w zależności od czterech podstawowych czynników: (1) model, (2) liczba tokenów w wierszu polecenia, (3) liczba wygenerowanych tokenów i (4) całkowite obciążenie wdrożenia i systemu. Jeden i trzy są często głównymi współautorami łącznego czasu. W następnej sekcji przedstawiono bardziej szczegółowe informacje na temat anatomii wywołania wnioskowania dużego modelu językowego.
Poprawa wydajności
Istnieje kilka czynników, które można kontrolować, aby zwiększyć opóźnienie poszczególnych wywołań aplikacji.
Wybieranie modelu
Opóźnienie zależy od używanego modelu. W przypadku identycznego żądania należy oczekiwać, że różne modele mają różne opóźnienia dla wywołania ukończenia czatu. Jeśli twój przypadek użycia wymaga najniższych modeli opóźnień z najszybszym czasem odpowiedzi, zalecamy najnowszy model GPT-4o mini.
Rozmiar generacji i maksymalne tokeny
Po wysłaniu żądania ukończenia do punktu końcowego usługi Azure OpenAI tekst wejściowy jest konwertowany na tokeny, które następnie są wysyłane do wdrożonego modelu. Model odbiera tokeny wejściowe, a następnie rozpoczyna generowanie odpowiedzi. Jest to iteracyjny proces sekwencyjny, jeden token naraz. Innym sposobem, aby myśleć o tym jest jak pętla for z n tokens = n iterations. W przypadku większości modeli generowanie odpowiedzi jest najwolniejszym krokiem w procesie.
W momencie żądania żądany rozmiar generacji (max_tokens parametru) jest używany jako początkowe oszacowanie rozmiaru generacji. Czas obliczeniowy generowania pełnego rozmiaru jest zarezerwowany przez model podczas przetwarzania żądania. Po zakończeniu generowania pozostały limit przydziału zostanie zwolniony. Sposoby zmniejszenia liczby tokenów:
max_tokensUstaw parametr dla każdego wywołania tak małe, jak to możliwe.- Uwzględnij sekwencje zatrzymania, aby zapobiec generowaniu dodatkowej zawartości.
- Generuj mniej odpowiedzi: parametry best_of i n mogą znacznie zwiększyć opóźnienie, ponieważ generują wiele danych wyjściowych. Aby uzyskać najszybszą odpowiedź, nie należy określać tych wartości ani ustawiać ich na 1.
Podsumowując, zmniejszenie liczby tokenów generowanych na żądanie zmniejsza opóźnienie każdego żądania.
Przesyłanie strumieniowe
Ustawienie stream: true w żądaniu sprawia, że tokeny powrotu usługi są dostępne natychmiast, zamiast czekać na wygenerowanie pełnej sekwencji tokenów. Nie zmienia czasu na pobranie wszystkich tokenów, ale skraca czas pierwszej odpowiedzi. Takie podejście zapewnia lepsze środowisko użytkownika, ponieważ użytkownicy końcowi mogą odczytywać odpowiedź podczas generowania.
Przesyłanie strumieniowe jest również przydatne w przypadku dużych wywołań, które mogą zająć dużo czasu. Wiele klientów i warstw pośredniczących ma limity czasu dla poszczególnych wywołań. Wywołania długiej generacji mogą zostać anulowane z powodu przekroczenia limitu czasu po stronie klienta. Przesyłając strumieniowo dane z powrotem, możesz upewnić się, że dane przyrostowe są odbierane.
Przykłady użycia przesyłania strumieniowego:
Czatboty i interfejsy konwersacyjne.
Przesyłanie strumieniowe ma wpływ na postrzegane opóźnienie. Po włączeniu przesyłania strumieniowego tokeny są odbierane z powrotem we fragmentach natychmiast po ich udostępniniu. W przypadku użytkowników końcowych takie podejście często wydaje się, że model odpowiada szybciej, mimo że ogólny czas ukończenia żądania pozostaje taki sam.
Przykłady, gdy przesyłanie strumieniowe jest mniej ważne:
Analiza tonacji, tłumaczenie języka, generowanie zawartości.
Istnieje wiele przypadków użycia, w których wykonujesz kilka zadań zbiorczych, w których zależy tylko na gotowym wyniku, a nie odpowiedzi w czasie rzeczywistym. Jeśli przesyłanie strumieniowe jest wyłączone, nie otrzymasz żadnych tokenów, dopóki model nie zakończy całej odpowiedzi.
Filtrowanie zawartości
Usługa Azure OpenAI zawiera system filtrowania zawartości, który działa wraz z podstawowymi modelami. Ten system działa przez uruchomienie zarówno monitu, jak i ukończenia przez zespół modeli klasyfikacji mających na celu wykrywanie i zapobieganie wyjściu szkodliwej zawartości.
System filtrowania zawartości wykrywa i podejmuje działania na określonych kategoriach potencjalnie szkodliwej zawartości w monitach wejściowych i uzupełnianiu danych wyjściowych.
Dodanie filtrowania zawartości wiąże się ze wzrostem bezpieczeństwa, ale także opóźnieniami. Istnieje wiele aplikacji, w których jest to konieczne kompromis w wydajności, jednak istnieją pewne mniejsze przypadki użycia ryzyka, w których wyłączenie filtrów zawartości w celu zwiększenia wydajności może być warte zbadania.
Dowiedz się więcej o żądaniu modyfikacji domyślnych zasad filtrowania zawartości.
Rozdzielenie obciążeń
Mieszanie różnych obciążeń w tym samym punkcie końcowym może negatywnie wpłynąć na opóźnienie. Jest to spowodowane tym, że (1) są one wsadowe razem podczas wnioskowania, a krótkie wywołania mogą czekać na dłuższe ukończenie, a (2) mieszanie wywołań może zmniejszyć szybkość trafień pamięci podręcznej, ponieważ obaj konkurują o to samo miejsce. Jeśli to możliwe, zalecane jest posiadanie oddzielnych wdrożeń dla każdego obciążenia.
Rozmiar monitu
Chociaż rozmiar monitu ma mniejszy wpływ na opóźnienie niż rozmiar generowania, ma wpływ na całkowity czas, zwłaszcza gdy rozmiar rośnie duży.
Dzielenie na partie
Jeśli wysyłasz wiele żądań do tego samego punktu końcowego, możesz podzielić żądania na pojedyncze wywołanie. Zmniejsza to liczbę żądań potrzebnych do wykonania i w zależności od scenariusza, który może poprawić ogólny czas odpowiedzi. Zalecamy przetestowanie tej metody, aby sprawdzić, czy pomaga.
Jak zmierzyć przepływność
Zalecamy pomiar ogólnej przepływności wdrożenia przy użyciu dwóch miar:
- Wywołania na minutę: liczba wywołań wnioskowania interfejsu API na minutę. Można to zmierzyć w usłudze Azure-Monitor przy użyciu metryki Żądania usługi Azure OpenAI i dzielenia według wartości ModelDeploymentName
- Łączna liczba tokenów na minutę: łączna liczba tokenów przetwarzanych na minutę przez wdrożenie. Obejmuje to tokeny monitu i wygenerowane. Często jest to bardziej podzielone na mierzenie obu w celu dokładniejszego zrozumienia wydajności wdrożenia. Można to zmierzyć w usłudze Azure-Monitor przy użyciu metryki Przetworzone tokeny wnioskowania.
Aby dowiedzieć się więcej na temat monitorowania usługi Azure OpenAI Service, możesz dowiedzieć się więcej.
Jak zmierzyć opóźnienie poszczególnych wywołań
Czas potrzebny na każde wywołanie zależy od tego, jak długo trwa odczytywanie modelu, generowanie danych wyjściowych i stosowanie filtrów zawartości. Sposób mierzenia czasu będzie się różnić, jeśli używasz przesyłania strumieniowego, czy nie. Sugerujemy inny zestaw miar dla każdego przypadku.
Aby dowiedzieć się więcej na temat monitorowania usługi Azure OpenAI Service, możesz dowiedzieć się więcej.
Bez przesyłania strumieniowego:
- Całkowity czas żądania: łączny czas potrzebny na wygenerowanie całej odpowiedzi dla żądań nieprzesyłania strumieniowego mierzony przez bramę interfejsu API. Ta liczba zwiększa się wraz ze wzrostem rozmiaru monitu i generowania.
Przesyłanie strumieniowe:
- Czas odpowiedzi: zalecana miara opóźnienia (czas odpowiedzi) dla żądań przesyłanych strumieniowo. Dotyczy wdrożeń zarządzanych przez ptU i PTU. Obliczono jako czas potrzebny na wyświetlenie pierwszej odpowiedzi po wysłaniu przez użytkownika monitu mierzonego przez bramę interfejsu API. Ta liczba zwiększa się wraz ze wzrostem rozmiaru monitu i/lub zmniejszeniem rozmiaru trafień.
- Średni czas generowania tokenu od pierwszego tokenu do ostatniego tokenu podzielony przez liczbę wygenerowanych tokenów mierzonych przez bramę interfejsu API. Mierzy to szybkość generowania odpowiedzi i zwiększa się wraz ze wzrostem obciążenia systemu. Zalecana miara opóźnienia dla żądań przesyłania strumieniowego.
Podsumowanie
Opóźnienie modelu: jeśli opóźnienie modelu jest dla Ciebie ważne, zalecamy wypróbowanie modelu mini GPT-4o.
Niższe maksymalne tokeny: interfejs OpenAI stwierdził, że nawet w przypadkach, gdy łączna liczba wygenerowanych tokenów jest podobna, żądanie o wyższej wartości ustawionej dla parametru maksymalnego tokenu będzie miało większe opóźnienie.
Mniejsza łączna liczba wygenerowanych tokenów: im mniej tokenów wygenerowało szybciej ogólną odpowiedź. Pamiętaj, że jest to tak, jakby pętla for miała wartość
n tokens = n iterations. Obniż liczbę wygenerowanych tokenów i całkowity czas odpowiedzi poprawi się odpowiednio.Przesyłanie strumieniowe: włączenie przesyłania strumieniowego może być przydatne w zarządzaniu oczekiwaniami użytkowników w niektórych sytuacjach, umożliwiając użytkownikowi wyświetlanie odpowiedzi modelu podczas generowania zamiast czekać, aż ostatni token będzie gotowy.
Filtrowanie zawartości zwiększa bezpieczeństwo, ale ma również wpływ na opóźnienie. Oceń, czy którekolwiek z obciążeń skorzystałoby ze zmodyfikowanych zasad filtrowania zawartości.