Jak wytrenować niestandardowy model klasyfikacji tekstu
Artykuł
Trenowanie to proces, w którym model uczy się na podstawie oznaczonych danych. Po zakończeniu trenowania będzie można wyświetlić wydajność modelu, aby określić, czy chcesz poprawić model.
Aby wytrenować model, uruchom zadanie szkoleniowe. Tylko pomyślnie ukończone zadania tworzą model nadający się do użycia. Zadania szkoleniowe wygasają po siedmiu dniach. Po upływie tego okresu nie będzie można pobrać szczegółów zadania. Jeśli zadanie szkoleniowe zostało ukończone pomyślnie i model został utworzony, nie będzie to miało wpływu na wygaśnięcie zadania. Jednocześnie można uruchomić tylko jedno zadanie szkoleniowe i nie można uruchomić innych zadań w tym samym projekcie.
Czas trenowania może trwać od kilku minut, gdy zajmuje się kilkoma dokumentami, do kilku godzin w zależności od rozmiaru zestawu danych i złożoności schematu.
Wymagania wstępne
Przed wytrenem modelu potrzebne są następujące elementy:
Przed rozpoczęciem procesu trenowania dokumenty oznaczone etykietą w projekcie są podzielone na zestaw szkoleniowy i zestaw testów. Każdy z nich pełni inną funkcję.
Zestaw trenowania jest używany w trenowaniu modelu. Jest to zestaw , z którego model uczy się klas/klas przypisanych do każdego dokumentu.
Zestaw testów to zestaw ślepy, który nie jest wprowadzany do modelu podczas trenowania, ale tylko podczas oceny.
Po pomyślnym wytrenowanym modelu jest on używany do przewidywania z dokumentów w zestawie testowym. Na podstawie tych przewidywań zostaną obliczone metryki oceny modelu.
Zaleca się upewnienie się, że wszystkie klasy są odpowiednio reprezentowane zarówno w zestawie treningowym, jak i testowym.
Niestandardowa klasyfikacja tekstu obsługuje dwie metody dzielenia danych:
Automatyczne dzielenie zestawu testów na podstawie danych treningowych: system podzieli dane oznaczone etykietami między zestawy treningowe i testowe, zgodnie z wybranymi wartościami procentowymi. System podejmie próbę przedstawienia wszystkich klas w zestawie treningowym. Zalecany podział procentowy wynosi 80% na potrzeby trenowania i 20% na potrzeby testowania.
Uwaga
Jeśli wybierzesz opcję Automatycznie dzieląc zestaw testów z danych treningowych, tylko dane przypisane do zestawu treningowego zostaną podzielone zgodnie z podanymi wartościami procentowymi.
Użyj ręcznego podziału danych treningowych i testowych: ta metoda umożliwia użytkownikom zdefiniowanie, które dokumenty z etykietami powinny należeć do tego zestawu. Ten krok jest włączony tylko w przypadku dodania dokumentów do zestawu testów podczas etykietowania danych.
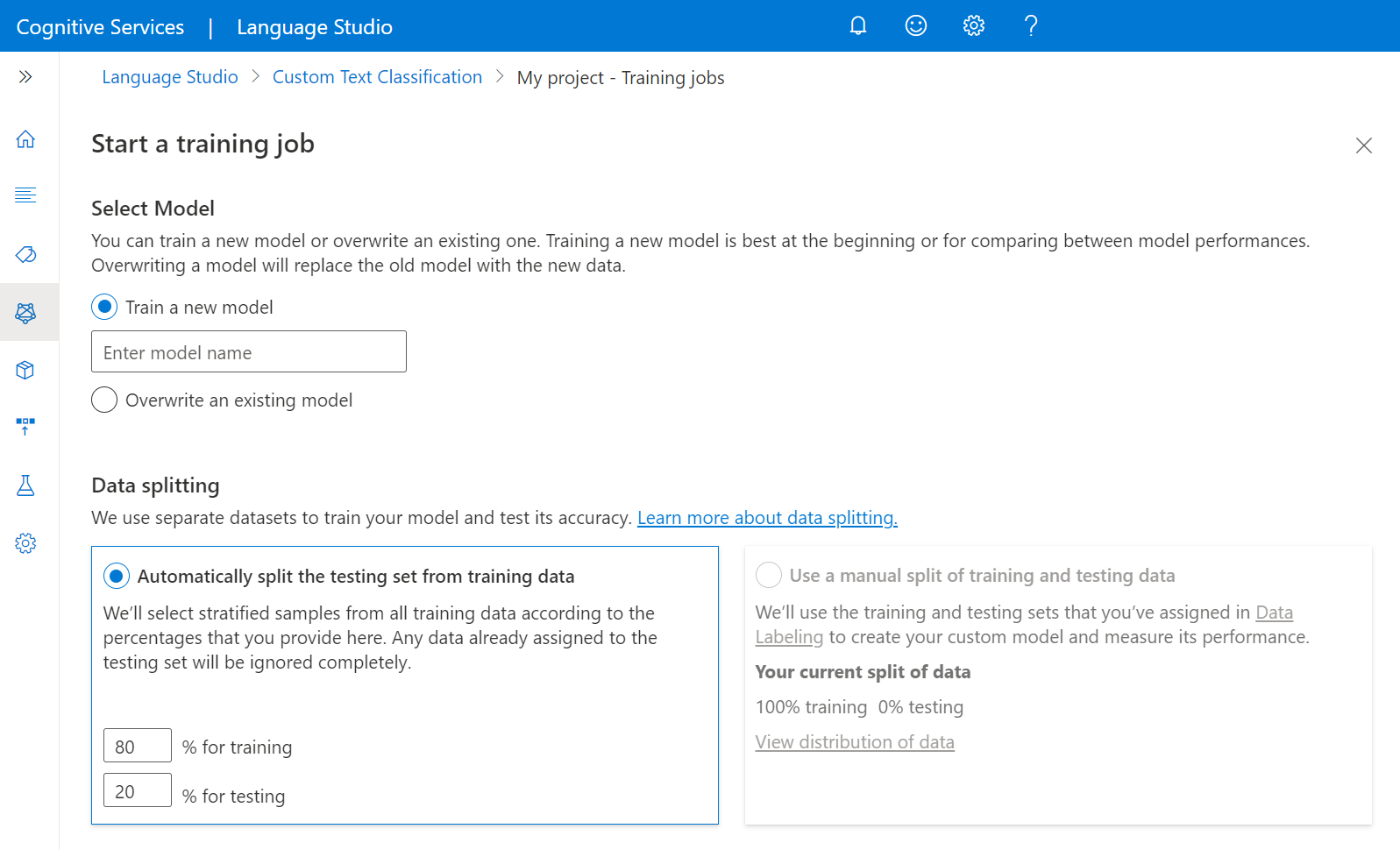
Aby rozpocząć trenowanie modelu z poziomu programu Language Studio:
Wybierz pozycję Zadania trenowania z menu po lewej stronie.
Wybierz pozycję Start a training job (Rozpocznij zadanie szkoleniowe) z górnego menu.
Wybierz pozycję Train a new model (Trenowanie nowego modelu ) i wpisz nazwę modelu w polu tekstowym. Możesz również zastąpić istniejący model , wybierając tę opcję i wybierając model, który chcesz zastąpić z menu rozwijanego. Zastępowanie wytrenowanego modelu jest nieodwracalne, ale nie wpłynie to na wdrożone modele do momentu wdrożenia nowego modelu.
Wybierz metodę dzielenia danych. Możesz wybrać opcję Automatyczne dzielenie zestawu testów z danych treningowych, w których system podzieli dane oznaczone etykietami między zestawy treningowe i testowe, zgodnie z określonymi wartościami procentowymi. Możesz też użyć ręcznego podziału danych treningowych i testowych. Ta opcja jest włączona tylko w przypadku dodania dokumentów do zestawu testów podczas etykietowania danych. Aby uzyskać więcej informacji na temat dzielenia danych, zobacz Jak wytrenować model .
Wybierz przycisk Train (Trenuj).
Jeśli wybierzesz identyfikator zadania szkoleniowego z listy, zostanie wyświetlone okienko boczne, w którym można sprawdzić postęp trenowania, stan zadania i inne szczegóły dotyczące tego zadania.
Uwaga
Tylko pomyślnie ukończone zadania szkoleniowe będą generować modele.
Czas trenowania modelu może potrwać od kilku minut do kilku godzin na podstawie rozmiaru oznaczonych danych.
Jednocześnie może być uruchomione tylko jedno zadanie trenowania. Nie można uruchomić innego zadania trenowania w tym samym projekcie, dopóki uruchomione zadanie nie zostanie ukończone.
Rozpoczynanie zadania szkoleniowego
Prześlij żądanie POST przy użyciu następującego adresu URL, nagłówków i treści JSON, aby przesłać zadanie szkoleniowe. Zastąp poniższe wartości symboli zastępczych własnymi wartościami.
Nazwa projektu. Ta wartość jest uwzględniana w wielkości liter.
myProject
{API-VERSION}
Wersja wywoływanego interfejsu API. Wartość, do których odwołuje się tutaj, dotyczy najnowszej wersji wydanej. Dowiedz się więcej o innych dostępnych wersjach interfejsu API
2022-05-01
Nagłówki
Użyj następującego nagłówka, aby uwierzytelnić żądanie.
Key
Wartość
Ocp-Apim-Subscription-Key
Klucz do zasobu. Służy do uwierzytelniania żądań interfejsu API.
Treść żądania
Użyj następującego kodu JSON w treści żądania. Model zostanie podany po zakończeniu {MODEL-NAME} trenowania. Tylko pomyślne zadania szkoleniowe będą tworzyć modele.
Nazwa modelu, która zostanie przypisana do modelu po pomyślnym wytrenowanym.
myModel
trainingConfigVersion
{CONFIG-VERSION}
Jest to wersja modelu, która będzie używana do trenowania modelu.
2022-05-01
evaluationOptions
Opcja dzielenia danych między zestawy trenowania i testowania.
{}
kind
percentage
Metody podzielone. Możliwe wartości to percentage lub manual. Aby uzyskać więcej informacji, zobacz Jak wytrenować model .
percentage
trainingSplitPercentage
80
Procent oznakowanych danych, które mają zostać uwzględnione w zestawie treningowym. Zalecana wartość to 80.
80
testingSplitPercentage
20
Procent oznakowanych danych, które mają zostać uwzględnione w zestawie testów. Zalecana wartość to 20.
20
Uwaga
Wartości trainingSplitPercentage i testingSplitPercentage są wymagane tylko wtedy, gdy Kind jest ustawiona wartość percentage , a suma obu wartości procentowych powinna być równa 100.
Po wysłaniu żądania interfejsu API otrzymasz odpowiedź wskazującą 202 , że zadanie zostało przesłane poprawnie. W nagłówkach odpowiedzi wyodrębnij location wartość. Zostanie on sformatowany w następujący sposób:
Element {JOB-ID} służy do identyfikowania żądania, ponieważ ta operacja jest asynchroniczna. Możesz użyć tego adresu URL, aby uzyskać stan trenowania.
Uzyskiwanie stanu zadania szkoleniowego
Trenowanie może trwać czasami w zależności od rozmiaru danych treningowych i złożoności schematu. Następujące żądanie umożliwia kontynuowanie sondowania stanu zadania szkoleniowego do momentu pomyślnego ukończenia zadania.
Użyj następującego żądania GET , aby uzyskać stan postępu trenowania modelu. Zastąp poniższe wartości symboli zastępczych własnymi wartościami.
Nazwa projektu. Ta wartość jest uwzględniana w wielkości liter.
myProject
{JOB-ID}
Identyfikator lokalizowania stanu trenowania modelu. Ta wartość znajduje się w wartości nagłówka location otrzymanej w poprzednim kroku.
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx
{API-VERSION}
Wersja wywoływanego interfejsu API. Wartość, do których odwołuje się tutaj, dotyczy najnowszej wersji wydanej. Zobacz cykl życia modelu, aby dowiedzieć się więcej o innych dostępnych wersjach interfejsu API.
2022-05-01
Nagłówki
Użyj następującego nagłówka, aby uwierzytelnić żądanie.
Key
Wartość
Ocp-Apim-Subscription-Key
Klucz do zasobu. Służy do uwierzytelniania żądań interfejsu API.
Treść odpowiedzi
Po wysłaniu żądania otrzymasz następującą odpowiedź.
Aby anulować zadanie szkoleniowe w programie Language Studio, przejdź do strony Zadania trenowania . Wybierz zadanie szkoleniowe, które chcesz anulować, a następnie wybierz pozycję Anuluj z górnego menu.
Utwórz żądanie POST przy użyciu następującego adresu URL, nagłówków i treści JSON, aby anulować zadanie trenowania.
Adres URL żądania
Podczas tworzenia żądania interfejsu API użyj następującego adresu URL. Zastąp poniższe wartości symboli zastępczych własnymi wartościami.