Rozwiązania wideo usługi Azure AI Content Understanding (wersja zapoznawcza)
Ważne
- Usługa Azure AI Content Understanding jest dostępna w wersji zapoznawczej. Publiczne wersje zapoznawcze zapewniają wczesny dostęp do funkcji, które są w aktywnym rozwoju.
- Funkcje, podejścia i procesy mogą ulec zmianie lub mieć ograniczone możliwości przed ogólną dostępnością.
- Aby uzyskać więcej informacji, zobacz Dodatkowe warunki użytkowania dla wersji zapoznawczych platformy Microsoft Azure.
Usługa Azure AI Content Understanding umożliwia wyodrębnianie i dostosowywanie metadanych wideo. Usługa Content Understanding pomaga efektywnie zarządzać, kategoryzować, pobierać i tworzyć przepływy pracy dla zasobów wideo. Rozszerza bibliotekę elementów zawartości multimediów, obsługuje przepływy pracy, takie jak generowanie wyróżnienia, kategoryzowanie zawartości i ułatwia aplikacje, takie jak generowanie rozszerzonej generacji (RAG).
Wiedza na temat zawartości wideo ma szerokie możliwości użycia. Można na przykład dostosować metadane, aby oznaczyć określone sceny w filmie szkoleniowym, co ułatwia pracownikom znajdowanie i ponowne wyszukiwanie ważnych sekcji. Możesz również użyć dostosowywania metadanych, aby zidentyfikować umieszczanie produktów w filmach promocyjnych, co ułatwia zespołom marketingowym analizowanie ekspozycji marki.
Przypadki użycia biznesowego
Usługa Azure AI Content Understanding udostępnia szereg przypadków użycia biznesowych, w tym:
- Emisja multimediów i rozrywki: zarządzaj dużymi bibliotekami pokazów, filmów i klipów, generując szczegółowe metadane dla każdego elementu zawartości.
- Edukacja i e*Nauka: indeksowanie i pobieranie konkretnych momentów w filmach edukacyjnych lub wykładach.
- Szkolenia firmowe: organizuj filmy szkoleniowe według kluczowych tematów, scen lub ważnych momentów.
- Marketing i reklama: Analizowanie filmów promocyjnych w celu wyodrębnienia umieszczania produktów, wyglądu marki i kluczowych wiadomości.
Możliwości rozumienia wideo
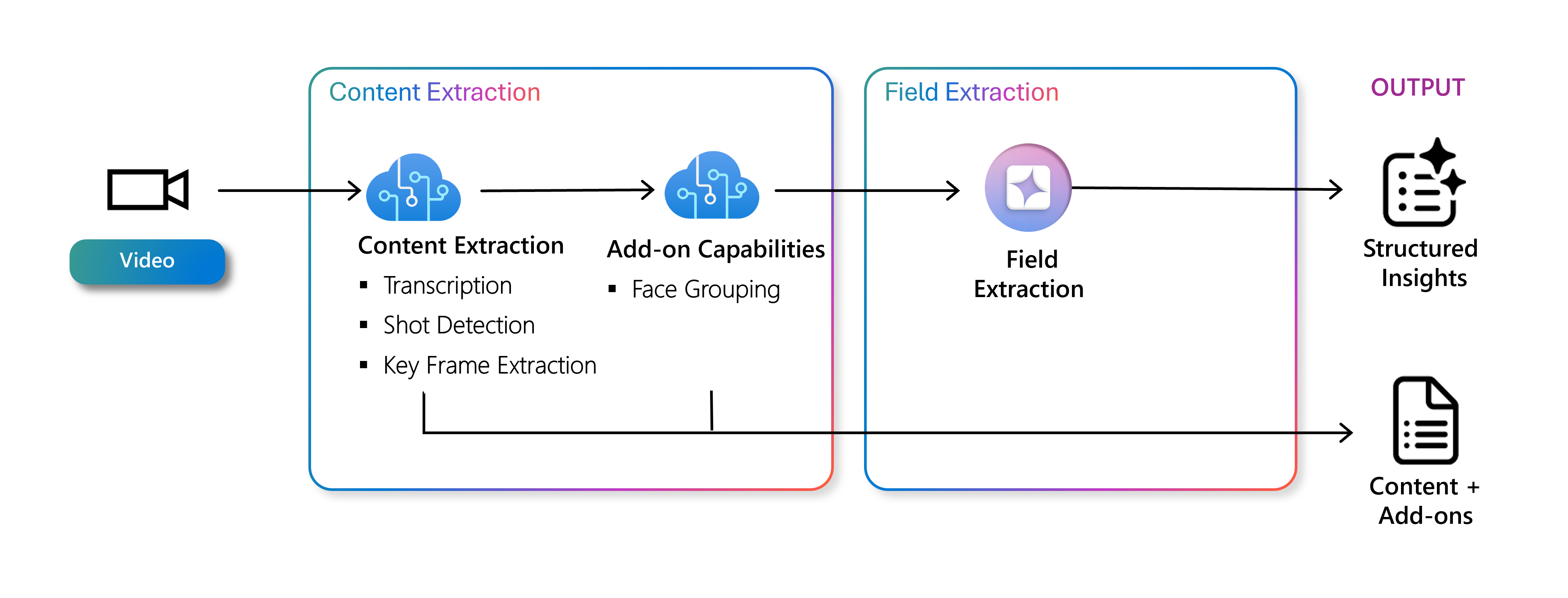
Usługa Content Understanding przetwarza pliki wideo za pomocą dostosowywalnego potoku, który może wykonywać zadania wyodrębniania zawartości i wyodrębniania pól. Wyodrębnianie zawartości koncentruje się na analizowaniu wideo w celu generowania podstawowych metadanych, podczas gdy wyodrębnianie pól używa tych metadanych do tworzenia bardziej szczegółowych, niestandardowych szczegółowych informacji dostosowanych do określonych przypadków użycia. Poniżej przedstawiono omówienie każdej możliwości.
Wyodrębnianie zawartości
Wyodrębnianie zawartości dla wideo obejmuje transkrypcję, wykrywanie zdjęć, wyodrębnianie klatek kluczowych i grupowanie twarzy. Te operacje są wykonywane na próbkowanych klatkach z całego filmu wideo i generują dane wyjściowe tekstu strukturalnego reprezentujące wideo. Wyodrębnianie zawartości służy również jako dane uziemienia do możliwości generowania wyodrębniania pól, zapewniając kontekst tego, co znajduje się w filmie wideo.
Konkretne możliwości wyodrębniania zawartości:
- Transkrypcja: konwertuje mowę na ustrukturyzowany tekst z możliwością wyszukiwania za pośrednictwem usługi Azure AI Speech, umożliwiając użytkownikom określanie języków rozpoznawania.
- Wykrywanie zdjęć: identyfikuje segmenty wideo dopasowane do granic zdjęć, jeśli to możliwe, co pozwala na precyzyjne edytowanie i ponowne pakowanie zawartości z podziałami dokładnie na granicach zdjęć.
- Wyodrębnianie klatek kluczowych: wyodrębnia klatki kluczowe z filmów, aby reprezentować wszystkie zdjęcia całkowicie, zapewniając, że każde zdjęcie ma wystarczającą liczbę klatek kluczowych, aby umożliwić efektywne działanie wyodrębniania pól.
- Grupowanie twarzy: grupowane twarze wyświetlane w filmie wideo w celu wyodrębnienia jednego reprezentatywnego obrazu twarzy dla każdej osoby i udostępnia segmenty, w których każdy z nich jest obecny. Pogrupowane dane twarzy są dostępne jako metadane i mogą służyć do generowania dostosowanych pól metadanych.
- Ta funkcja ma ograniczony dostęp i obejmuje identyfikację twarzy i grupowanie twarzy; klienci muszą zarejestrować się w celu uzyskania dostępu w funkcji rozpoznawania twarzy.
Wyodrębnianie pól
Wyodrębnianie pól umożliwia generowanie danych ustrukturyzowanych dla każdego segmentu filmu wideo, takich jak tagi, kategorie lub opisy, przy użyciu dostosowanego schematu dostosowanego do konkretnych potrzeb. Te dane ustrukturyzowane ułatwiają efektywne organizowanie, wyszukiwanie i automatyczne przetwarzanie zawartości wideo. Wyodrębnianie pól używa wielomodalnego modelu generowania do wyodrębniania określonych danych z wideo przy użyciu klatek kluczowych i danych wyjściowych tekstu z wyodrębniania zawartości jako danych wejściowych. Wyodrębnianie pól umożliwia modelowi generowania szczegółowych informacji na podstawie zawartości wizualnej przechwyconej na podstawie zdjęć, zapewniając szczegółową identyfikację.
Przykłady pól dla różnych branż:
Zarządzanie zasobami multimedialnymi:
- Typ strzału: pomaga edytorom i producentom organizować zawartość, upraszczać edytowanie i interpretować język wizualny filmu wideo. Przydatne w przypadku tagowania metadanych i szybszego pobierania sceny.
- Schemat kolorów: Przekazuje nastrój i atmosferę, niezbędne dla spójności narracji i zaangażowania widza. Identyfikowanie motywów kolorów ułatwia znajdowanie pasujących klipów do przyspieszonej edycji wideo.
Reklama:
- Marka: identyfikuje obecność marki, krytyczne znaczenie dla analizowania wpływu reklamy, widoczności marki i skojarzenia z produktami. Ta funkcja umożliwia reklamodawcom ocenę znaczenia marki i zapewnienie zgodności z wytycznymi dotyczącymi znakowania.
- Kategorie reklam: kategoryzuje typy reklam według branży, typu produktu lub segmentu odbiorców, które obsługują ukierunkowane strategie reklamowe, kategoryzacja i analizę wydajności.
Główne korzyści
Usługa Content Understanding zapewnia kilka kluczowych korzyści w porównaniu z innymi rozwiązaniami do analizy wideo:
- Analiza wieloramowa oparta na segmentach: identyfikowanie akcji, zdarzeń, tematów i motywów przez analizowanie wielu ramek z poszczególnych segmentów wideo, a nie pojedynczych ramek.
- Dostosowywanie: dostosuj wygenerowane metadane, modyfikując schemat zgodnie z konkretnym przypadkiem użycia.
- Modele generowania: opisz w języku naturalnym zawartość, którą chcesz wyodrębnić, a usługa Content Understanding używa modeli generowania w celu wyodrębnienia tych metadanych.
- Zoptymalizowane przetwarzanie wstępne: wykonaj kilka kroków przetwarzania wstępnego wyodrębniania zawartości, takich jak transkrypcja i wykrywanie scen, zoptymalizowane pod kątem udostępniania zaawansowanego kontekstu modelom generowania sztucznej inteligencji.
Wymagania dotyczące danych wejściowych
Aby uzyskać szczegółowe informacje na temat obsługiwanych formatów dokumentów wejściowych, zapoznaj się z naszą stroną Limity przydziału i limity usługi.
Obsługiwane języki i regiony
Aby uzyskać szczegółową listę obsługiwanych języków i regionów, odwiedź naszą stronę pomocy technicznej języka i regionu.
Prywatność i zabezpieczenia danych
Podobnie jak w przypadku wszystkich usług azure AI, deweloperzy korzystający z usługi Content Understanding powinni pamiętać o zasadach firmy Microsoft dotyczących danych klientów. Aby dowiedzieć się więcej, zobacz naszą stronę Dane, ochrona i prywatność .
Ważne
Użytkownicy usługi Content Understanding mogą włączać funkcje, takie jak grupowanie twarzy dla filmów wideo, które obejmowały przetwarzanie danych biometrycznych. Jeśli używasz produktów lub usług firmy Microsoft do przetwarzania danych biometrycznych, odpowiadasz za: (i) powiadamianie podmiotów danych, w tym w odniesieniu do okresów przechowywania i zniszczenia; ii) uzyskiwanie zgody od podmiotów danych; oraz (iii) usunięcie danych biometrycznych, zgodnie z potrzebami i wymaganych zgodnie z odpowiednimi wymaganiami dotyczącymi ochrony danych. "Dane biometryczne" mają znaczenie określone w art. Aby uzyskać powiązane informacje, zobacz Dane i prywatność twarzy.
Następne kroki
- Spróbuj przetwarzać zawartość wideo przy użyciu usługi Content Understanding w witrynie Azure Portal.
- Dowiedz się, jak analizować szablony analizatora zawartości wideo.
- Przejrzyj przykładowy kod: wyodrębnianie zawartości wideo.
- Przejrzyj przykładowy kod: wyszukiwanie wideo przy użyciu zapytań języka naturalnego.
- Przeglądanie przykładu kodu: szablony analizatora