Jak wygenerować uzupełnianie czatu przy użyciu wnioskowania modelu AI platformy Azure
Ważne
Elementy oznaczone (wersja zapoznawcza) w tym artykule są obecnie dostępne w publicznej wersji zapoznawczej. Ta wersja zapoznawcza jest udostępniana bez umowy dotyczącej poziomu usług i nie zalecamy korzystania z niej w przypadku obciążeń produkcyjnych. Niektóre funkcje mogą być nieobsługiwane lub ograniczone. Aby uzyskać więcej informacji, zobacz Uzupełniające warunki korzystania z wersji zapoznawczych platformy Microsoft Azure.
W tym artykule wyjaśniono, jak używać interfejsu API uzupełniania czatów z modelami wdrożonym w wnioskowaniu modelu AI platformy Azure w usługach azure AI.
Wymagania wstępne
Aby używać modeli uzupełniania czatów w aplikacji, potrzebne są następujące elementy:
Subskrypcja Azure. Jeśli używasz modeli GitHub, możesz uaktualnić środowisko i utworzyć subskrypcję platformy Azure w tym procesie. Przeczytaj artykuł Upgrade from GitHub Models to Azure AI model inference if's your case (Uaktualnianie modeli Usługi GitHub do wnioskowania modelu AI platformy Azure), jeśli tak jest.
Zasób usług AI platformy Azure. Aby uzyskać więcej informacji, zobacz Create an Azure AI Services resource (Tworzenie zasobu usług Azure AI Services).
Adres URL i klucz punktu końcowego.


Wdrożenie modelu uzupełniania czatu. Jeśli nie masz jeszcze jednego artykułu Dodawanie i konfigurowanie modeli w usługach azure AI w celu dodania modelu uzupełniania czatów do zasobu.
Zainstaluj pakiet wnioskowania usługi Azure AI dla języka Python za pomocą następującego polecenia:
pip install -U azure-ai-inference
Korzystanie z uzupełniania czatu
Najpierw utwórz klienta, aby korzystać z modelu. Poniższy kod używa adresu URL punktu końcowego i klucza przechowywanego w zmiennych środowiskowych.
import os
from azure.ai.inference import ChatCompletionsClient
from azure.core.credentials import AzureKeyCredential
client = ChatCompletionsClient(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=AzureKeyCredential(os.environ["AZURE_INFERENCE_CREDENTIAL"]),
model="mistral-large-2407"
)
Jeśli zasób został skonfigurowany do obsługi identyfikatora Entra firmy Microsoft, możesz użyć następującego fragmentu kodu, aby utworzyć klienta.
import os
from azure.ai.inference import ChatCompletionsClient
from azure.identity import DefaultAzureCredential
client = ChatCompletionsClient(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=DefaultAzureCredential(),
model="mistral-large-2407"
)
Tworzenie żądania ukończenia czatu
W poniższym przykładzie pokazano, jak utworzyć podstawowe żądanie ukończenia czatu do modelu.
from azure.ai.inference.models import SystemMessage, UserMessage
response = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant."),
UserMessage(content="How many languages are in the world?"),
],
)
Uwaga
Niektóre modele nie obsługują komunikatów systemowych (role="system"). W przypadku korzystania z interfejsu API wnioskowania modelu AI platformy Azure komunikaty systemowe są tłumaczone na komunikaty użytkowników, co jest najbliższą dostępną funkcją. To tłumaczenie jest oferowane dla wygody, ale ważne jest, aby sprawdzić, czy model jest przestrzegany instrukcji w komunikacie systemowym z odpowiednim poziomem pewności.
Odpowiedź jest następująca, gdzie można zobaczyć statystyki użycia modelu:
print("Response:", response.choices[0].message.content)
print("Model:", response.model)
print("Usage:")
print("\tPrompt tokens:", response.usage.prompt_tokens)
print("\tTotal tokens:", response.usage.total_tokens)
print("\tCompletion tokens:", response.usage.completion_tokens)
Response: As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.
Model: mistral-large-2407
Usage:
Prompt tokens: 19
Total tokens: 91
Completion tokens: 72
Sprawdź sekcję usage w odpowiedzi, aby zobaczyć liczbę tokenów używanych dla monitu, łączną liczbę wygenerowanych tokenów oraz liczbę tokenów używanych do ukończenia.
Przesyłanie strumieniowe zawartości
Domyślnie interfejs API uzupełniania zwraca całą wygenerowaną zawartość w pojedynczej odpowiedzi. Jeśli generujesz długie zakończenia, oczekiwanie na odpowiedź może potrwać wiele sekund.
Możesz przesyłać strumieniowo zawartość, aby pobrać ją podczas jego generowania. Zawartość strumieniowa umożliwia rozpoczęcie przetwarzania ukończenia w miarę dostępności zawartości. Ten tryb zwraca obiekt, który przesyła strumieniowo odpowiedź jako zdarzenia wysyłane tylko do serwera. Wyodrębnij fragmenty z pola różnicowego, a nie z pola komunikatu.
Aby przesłać strumieniowo uzupełnienia, ustaw stream=True podczas wywoływania modelu.
result = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant."),
UserMessage(content="How many languages are in the world?"),
],
temperature=0,
top_p=1,
max_tokens=2048,
stream=True,
)
Aby zwizualizować dane wyjściowe, zdefiniuj funkcję pomocnika, aby wydrukować strumień.
def print_stream(result):
"""
Prints the chat completion with streaming.
"""
import time
for update in result:
if update.choices:
print(update.choices[0].delta.content, end="")
Możesz zwizualizować sposób generowania zawartości przez przesyłanie strumieniowe:
print_stream(result)
Poznaj więcej parametrów obsługiwanych przez klienta wnioskowania
Zapoznaj się z innymi parametrami, które można określić w kliencie wnioskowania. Aby uzyskać pełną listę wszystkich obsługiwanych parametrów i odpowiedniej dokumentacji, zobacz Dokumentacja interfejsu API wnioskowania modelu AI platformy Azure.
from azure.ai.inference.models import ChatCompletionsResponseFormatText
response = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant."),
UserMessage(content="How many languages are in the world?"),
],
presence_penalty=0.1,
frequency_penalty=0.8,
max_tokens=2048,
stop=["<|endoftext|>"],
temperature=0,
top_p=1,
response_format={ "type": ChatCompletionsResponseFormatText() },
)
Niektóre modele nie obsługują formatowania danych wyjściowych JSON. Zawsze możesz monitować model o wygenerowanie danych wyjściowych JSON. Jednak takie dane wyjściowe nie mają gwarancji, że są prawidłowe dane JSON.
Jeśli chcesz przekazać parametr, który nie znajduje się na liście obsługiwanych parametrów, możesz przekazać go do modelu bazowego przy użyciu dodatkowych parametrów. Zobacz Przekazywanie dodatkowych parametrów do modelu.
Tworzenie danych wyjściowych JSON
Niektóre modele mogą tworzyć dane wyjściowe JSON. Ustaw response_format wartość na wartość , aby json_object włączyć tryb JSON i zagwarantować, że komunikat generowany przez model jest prawidłowym kodem JSON. Należy również poinstruować model, aby samodzielnie wygenerował kod JSON za pośrednictwem komunikatu systemu lub użytkownika. Ponadto zawartość wiadomości może być częściowo odcięta, jeśli finish_reason="length", co wskazuje, że generacja przekroczyła max_tokens lub że konwersacja przekroczyła maksymalną długość kontekstu.
from azure.ai.inference.models import ChatCompletionsResponseFormatJSON
response = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant that always generate responses in JSON format, using."
" the following format: { ""answer"": ""response"" }."),
UserMessage(content="How many languages are in the world?"),
],
response_format={ "type": ChatCompletionsResponseFormatJSON() }
)
Przekazywanie dodatkowych parametrów do modelu
Interfejs API wnioskowania modelu AI platformy Azure umożliwia przekazywanie dodatkowych parametrów do modelu. Poniższy przykład kodu pokazuje, jak przekazać dodatkowy parametr logprobs do modelu.
response = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant."),
UserMessage(content="How many languages are in the world?"),
],
model_extras={
"logprobs": True
}
)
Przed przekazaniem dodatkowych parametrów do interfejsu API wnioskowania modelu AI platformy Azure upewnij się, że model obsługuje te dodatkowe parametry. Po wysłaniu żądania do modelu bazowego nagłówek extra-parameters jest przekazywany do modelu z wartością pass-through. Ta wartość informuje punkt końcowy o przekazaniu dodatkowych parametrów do modelu. Użycie dodatkowych parametrów z modelem nie gwarantuje, że model może je faktycznie obsłużyć. Przeczytaj dokumentację modelu, aby dowiedzieć się, które dodatkowe parametry są obsługiwane.
Używanie narzędzi
Niektóre modele obsługują korzystanie z narzędzi, które mogą być niezwykłym zasobem, gdy trzeba odciążyć określone zadania z modelu językowego, a zamiast tego polegać na bardziej deterministycznym systemie, a nawet innym modelu językowym. Interfejs API wnioskowania modelu AI platformy Azure umożliwia definiowanie narzędzi w następujący sposób.
Poniższy przykład kodu tworzy definicję narzędzia, która umożliwia wyszukiwanie informacji o locie z dwóch różnych miast.
from azure.ai.inference.models import FunctionDefinition, ChatCompletionsFunctionToolDefinition
flight_info = ChatCompletionsFunctionToolDefinition(
function=FunctionDefinition(
name="get_flight_info",
description="Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
parameters={
"type": "object",
"properties": {
"origin_city": {
"type": "string",
"description": "The name of the city where the flight originates",
},
"destination_city": {
"type": "string",
"description": "The flight destination city",
},
},
"required": ["origin_city", "destination_city"],
},
)
)
tools = [flight_info]
W tym przykładzie dane wyjściowe funkcji to brak dostępnych lotów dla wybranej trasy, ale użytkownik powinien rozważyć pociąg.
def get_flight_info(loc_origin: str, loc_destination: str):
return {
"info": f"There are no flights available from {loc_origin} to {loc_destination}. You should take a train, specially if it helps to reduce CO2 emissions."
}
Uwaga
Modele cohere wymagają, aby odpowiedzi narzędzia było prawidłową zawartością JSON sformatowaną jako ciąg. Podczas konstruowania komunikatów typu Tool upewnij się, że odpowiedź jest prawidłowym ciągiem JSON.
Monituj model o zarezerwowanie lotów przy użyciu tej funkcji:
messages = [
SystemMessage(
content="You are a helpful assistant that help users to find information about traveling, how to get"
" to places and the different transportations options. You care about the environment and you"
" always have that in mind when answering inqueries.",
),
UserMessage(
content="When is the next flight from Miami to Seattle?",
),
]
response = client.complete(
messages=messages, tools=tools, tool_choice="auto"
)
Możesz sprawdzić odpowiedź, aby dowiedzieć się, czy należy wywołać narzędzie. Sprawdź przyczynę zakończenia, aby określić, czy narzędzie ma być wywoływane. Należy pamiętać, że można wskazać wiele typów narzędzi. W tym przykładzie pokazano narzędzie typu function.
response_message = response.choices[0].message
tool_calls = response_message.tool_calls
print("Finish reason:", response.choices[0].finish_reason)
print("Tool call:", tool_calls)
Aby kontynuować, dołącz tę wiadomość do historii czatów:
messages.append(
response_message
)
Teraz nadszedł czas, aby wywołać odpowiednią funkcję do obsługi wywołania narzędzia. Poniższy fragment kodu iteruje wszystkie wywołania narzędzia wskazane w odpowiedzi i wywołuje odpowiednią funkcję z odpowiednimi parametrami. Odpowiedź jest również dołączana do historii czatów.
import json
from azure.ai.inference.models import ToolMessage
for tool_call in tool_calls:
# Get the tool details:
function_name = tool_call.function.name
function_args = json.loads(tool_call.function.arguments.replace("\'", "\""))
tool_call_id = tool_call.id
print(f"Calling function `{function_name}` with arguments {function_args}")
# Call the function defined above using `locals()`, which returns the list of all functions
# available in the scope as a dictionary. Notice that this is just done as a simple way to get
# the function callable from its string name. Then we can call it with the corresponding
# arguments.
callable_func = locals()[function_name]
function_response = callable_func(**function_args)
print("->", function_response)
# Once we have a response from the function and its arguments, we can append a new message to the chat
# history. Notice how we are telling to the model that this chat message came from a tool:
messages.append(
ToolMessage(
tool_call_id=tool_call_id,
content=json.dumps(function_response)
)
)
Wyświetl odpowiedź z modelu:
response = client.complete(
messages=messages,
tools=tools,
)
Stosowanie bezpieczeństwa zawartości
Interfejs API wnioskowania modelu AI platformy Azure obsługuje bezpieczeństwo zawartości usługi Azure AI. W przypadku korzystania z wdrożeń z włączonym bezpieczeństwem zawartości sztucznej inteligencji platformy Azure dane wejściowe i wyjściowe przechodzą przez zespół modeli klasyfikacji mających na celu wykrywanie i zapobieganie wystąpieniu szkodliwej zawartości. System filtrowania zawartości wykrywa i podejmuje działania na określonych kategoriach potencjalnie szkodliwej zawartości w monitach wejściowych i uzupełnianiu danych wyjściowych.
W poniższym przykładzie pokazano, jak obsługiwać zdarzenia, gdy model wykryje szkodliwą zawartość w monicie wejściowym i włączono bezpieczeństwo zawartości.
from azure.ai.inference.models import AssistantMessage, UserMessage, SystemMessage
try:
response = client.complete(
messages=[
SystemMessage(content="You are an AI assistant that helps people find information."),
UserMessage(content="Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills."),
]
)
print(response.choices[0].message.content)
except HttpResponseError as ex:
if ex.status_code == 400:
response = ex.response.json()
if isinstance(response, dict) and "error" in response:
print(f"Your request triggered an {response['error']['code']} error:\n\t {response['error']['message']}")
else:
raise
raise
Napiwek
Aby dowiedzieć się więcej na temat konfigurowania i kontrolowania ustawień bezpieczeństwa zawartości usługi Azure AI, zapoznaj się z dokumentacją dotyczącą bezpieczeństwa zawartości usługi Azure AI.
Używanie uzupełniania czatu z obrazami
Niektóre modele mogą powodować między tekstem i obrazami oraz generować uzupełnienia tekstu na podstawie obu rodzajów danych wejściowych. W tej sekcji zapoznasz się z możliwościami niektórych modeli przetwarzania obrazów w sposób czatu:
Ważne
Niektóre modele obsługują tylko jeden obraz dla każdego kolei w konwersacji czatu i tylko ostatni obraz jest zachowywany w kontekście. Jeśli dodasz wiele obrazów, spowoduje to wystąpienie błędu.
Aby wyświetlić tę możliwość, pobierz obraz i zakoduj informacje jako base64 ciąg. Wynikowe dane powinny znajdować się wewnątrz adresu URL danych:
from urllib.request import urlopen, Request
import base64
image_url = "https://news.microsoft.com/source/wp-content/uploads/2024/04/The-Phi-3-small-language-models-with-big-potential-1-1900x1069.jpg"
image_format = "jpeg"
request = Request(image_url, headers={"User-Agent": "Mozilla/5.0"})
image_data = base64.b64encode(urlopen(request).read()).decode("utf-8")
data_url = f"data:image/{image_format};base64,{image_data}"
Wizualizowanie obrazu:
import requests
import IPython.display as Disp
Disp.Image(requests.get(image_url).content)

Teraz utwórz żądanie ukończenia czatu z obrazem:
from azure.ai.inference.models import TextContentItem, ImageContentItem, ImageUrl
response = client.complete(
messages=[
SystemMessage("You are a helpful assistant that can generate responses based on images."),
UserMessage(content=[
TextContentItem(text="Which conclusion can be extracted from the following chart?"),
ImageContentItem(image=ImageUrl(url=data_url))
]),
],
temperature=0,
top_p=1,
max_tokens=2048,
)
Odpowiedź jest następująca, gdzie można zobaczyć statystyki użycia modelu:
print(f"{response.choices[0].message.role}:\n\t{response.choices[0].message.content}\n")
print("Model:", response.model)
print("Usage:")
print("\tPrompt tokens:", response.usage.prompt_tokens)
print("\tCompletion tokens:", response.usage.completion_tokens)
print("\tTotal tokens:", response.usage.total_tokens)
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: mistral-large-2407
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Ważne
Elementy oznaczone (wersja zapoznawcza) w tym artykule są obecnie dostępne w publicznej wersji zapoznawczej. Ta wersja zapoznawcza jest udostępniana bez umowy dotyczącej poziomu usług i nie zalecamy korzystania z niej w przypadku obciążeń produkcyjnych. Niektóre funkcje mogą być nieobsługiwane lub ograniczone. Aby uzyskać więcej informacji, zobacz Uzupełniające warunki korzystania z wersji zapoznawczych platformy Microsoft Azure.
W tym artykule wyjaśniono, jak używać interfejsu API uzupełniania czatów z modelami wdrożonym w wnioskowaniu modelu AI platformy Azure w usługach azure AI.
Wymagania wstępne
Aby używać modeli uzupełniania czatów w aplikacji, potrzebne są następujące elementy:
Subskrypcja Azure. Jeśli używasz modeli GitHub, możesz uaktualnić środowisko i utworzyć subskrypcję platformy Azure w tym procesie. Przeczytaj artykuł Upgrade from GitHub Models to Azure AI model inference if's your case (Uaktualnianie modeli Usługi GitHub do wnioskowania modelu AI platformy Azure), jeśli tak jest.
Zasób usług AI platformy Azure. Aby uzyskać więcej informacji, zobacz Create an Azure AI Services resource (Tworzenie zasobu usług Azure AI Services).
Adres URL i klucz punktu końcowego.
Wdrożenie modelu uzupełniania czatu. Jeśli nie masz jeszcze jednego artykułu Dodawanie i konfigurowanie modeli w usługach azure AI w celu dodania modelu uzupełniania czatów do zasobu.
Zainstaluj bibliotekę wnioskowania platformy Azure dla języka JavaScript za pomocą następującego polecenia:
npm install @azure-rest/ai-inference
Korzystanie z uzupełniania czatu
Najpierw utwórz klienta, aby korzystać z modelu. Poniższy kod używa adresu URL punktu końcowego i klucza przechowywanego w zmiennych środowiskowych.
import ModelClient from "@azure-rest/ai-inference";
import { isUnexpected } from "@azure-rest/ai-inference";
import { AzureKeyCredential } from "@azure/core-auth";
const client = new ModelClient(
process.env.AZURE_INFERENCE_ENDPOINT,
new AzureKeyCredential(process.env.AZURE_INFERENCE_CREDENTIAL)
);
Jeśli zasób został skonfigurowany do obsługi identyfikatora Entra firmy Microsoft, możesz użyć następującego fragmentu kodu, aby utworzyć klienta.
import ModelClient from "@azure-rest/ai-inference";
import { isUnexpected } from "@azure-rest/ai-inference";
import { DefaultAzureCredential } from "@azure/identity";
const client = new ModelClient(
process.env.AZURE_INFERENCE_ENDPOINT,
new DefaultAzureCredential()
);
Tworzenie żądania ukończenia czatu
W poniższym przykładzie pokazano, jak utworzyć podstawowe żądanie ukończenia czatu do modelu.
var messages = [
{ role: "system", content: "You are a helpful assistant" },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
}
});
Uwaga
Niektóre modele nie obsługują komunikatów systemowych (role="system"). W przypadku korzystania z interfejsu API wnioskowania modelu AI platformy Azure komunikaty systemowe są tłumaczone na komunikaty użytkowników, co jest najbliższą dostępną funkcją. To tłumaczenie jest oferowane dla wygody, ale ważne jest, aby sprawdzić, czy model jest przestrzegany instrukcji w komunikacie systemowym z odpowiednim poziomem pewności.
Odpowiedź jest następująca, gdzie można zobaczyć statystyki użycia modelu:
if (isUnexpected(response)) {
throw response.body.error;
}
console.log("Response: ", response.body.choices[0].message.content);
console.log("Model: ", response.body.model);
console.log("Usage:");
console.log("\tPrompt tokens:", response.body.usage.prompt_tokens);
console.log("\tTotal tokens:", response.body.usage.total_tokens);
console.log("\tCompletion tokens:", response.body.usage.completion_tokens);
Response: As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.
Model: mistral-large-2407
Usage:
Prompt tokens: 19
Total tokens: 91
Completion tokens: 72
Sprawdź sekcję usage w odpowiedzi, aby zobaczyć liczbę tokenów używanych dla monitu, łączną liczbę wygenerowanych tokenów oraz liczbę tokenów używanych do ukończenia.
Przesyłanie strumieniowe zawartości
Domyślnie interfejs API uzupełniania zwraca całą wygenerowaną zawartość w pojedynczej odpowiedzi. Jeśli generujesz długie zakończenia, oczekiwanie na odpowiedź może potrwać wiele sekund.
Możesz przesyłać strumieniowo zawartość, aby pobrać ją podczas jego generowania. Zawartość strumieniowa umożliwia rozpoczęcie przetwarzania ukończenia w miarę dostępności zawartości. Ten tryb zwraca obiekt, który przesyła strumieniowo odpowiedź jako zdarzenia wysyłane tylko do serwera. Wyodrębnij fragmenty z pola różnicowego, a nie z pola komunikatu.
Aby przesłać strumieniowo uzupełnienia, użyj .asNodeStream() polecenia podczas wywoływania modelu.
var messages = [
{ role: "system", content: "You are a helpful assistant" },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
}
}).asNodeStream();
Możesz zwizualizować sposób generowania zawartości przez przesyłanie strumieniowe:
var stream = response.body;
if (!stream) {
stream.destroy();
throw new Error(`Failed to get chat completions with status: ${response.status}`);
}
if (response.status !== "200") {
throw new Error(`Failed to get chat completions: ${response.body.error}`);
}
var sses = createSseStream(stream);
for await (const event of sses) {
if (event.data === "[DONE]") {
return;
}
for (const choice of (JSON.parse(event.data)).choices) {
console.log(choice.delta?.content ?? "");
}
}
Poznaj więcej parametrów obsługiwanych przez klienta wnioskowania
Zapoznaj się z innymi parametrami, które można określić w kliencie wnioskowania. Aby uzyskać pełną listę wszystkich obsługiwanych parametrów i odpowiedniej dokumentacji, zobacz Dokumentacja interfejsu API wnioskowania modelu AI platformy Azure.
var messages = [
{ role: "system", content: "You are a helpful assistant" },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
presence_penalty: "0.1",
frequency_penalty: "0.8",
max_tokens: 2048,
stop: ["<|endoftext|>"],
temperature: 0,
top_p: 1,
response_format: { type: "text" },
}
});
Niektóre modele nie obsługują formatowania danych wyjściowych JSON. Zawsze możesz monitować model o wygenerowanie danych wyjściowych JSON. Jednak takie dane wyjściowe nie mają gwarancji, że są prawidłowe dane JSON.
Jeśli chcesz przekazać parametr, który nie znajduje się na liście obsługiwanych parametrów, możesz przekazać go do modelu bazowego przy użyciu dodatkowych parametrów. Zobacz Przekazywanie dodatkowych parametrów do modelu.
Tworzenie danych wyjściowych JSON
Niektóre modele mogą tworzyć dane wyjściowe JSON. Ustaw response_format wartość na wartość , aby json_object włączyć tryb JSON i zagwarantować, że komunikat generowany przez model jest prawidłowym kodem JSON. Należy również poinstruować model, aby samodzielnie wygenerował kod JSON za pośrednictwem komunikatu systemu lub użytkownika. Ponadto zawartość wiadomości może być częściowo odcięta, jeśli finish_reason="length", co wskazuje, że generacja przekroczyła max_tokens lub że konwersacja przekroczyła maksymalną długość kontekstu.
var messages = [
{ role: "system", content: "You are a helpful assistant that always generate responses in JSON format, using."
+ " the following format: { \"answer\": \"response\" }." },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
response_format: { type: "json_object" }
}
});
Przekazywanie dodatkowych parametrów do modelu
Interfejs API wnioskowania modelu AI platformy Azure umożliwia przekazywanie dodatkowych parametrów do modelu. Poniższy przykład kodu pokazuje, jak przekazać dodatkowy parametr logprobs do modelu.
var messages = [
{ role: "system", content: "You are a helpful assistant" },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
headers: {
"extra-params": "pass-through"
},
body: {
messages: messages,
logprobs: true
}
});
Przed przekazaniem dodatkowych parametrów do interfejsu API wnioskowania modelu AI platformy Azure upewnij się, że model obsługuje te dodatkowe parametry. Po wysłaniu żądania do modelu bazowego nagłówek extra-parameters jest przekazywany do modelu z wartością pass-through. Ta wartość informuje punkt końcowy o przekazaniu dodatkowych parametrów do modelu. Użycie dodatkowych parametrów z modelem nie gwarantuje, że model może je faktycznie obsłużyć. Przeczytaj dokumentację modelu, aby dowiedzieć się, które dodatkowe parametry są obsługiwane.
Używanie narzędzi
Niektóre modele obsługują korzystanie z narzędzi, które mogą być niezwykłym zasobem, gdy trzeba odciążyć określone zadania z modelu językowego, a zamiast tego polegać na bardziej deterministycznym systemie, a nawet innym modelu językowym. Interfejs API wnioskowania modelu AI platformy Azure umożliwia definiowanie narzędzi w następujący sposób.
Poniższy przykład kodu tworzy definicję narzędzia, która umożliwia wyszukiwanie informacji o locie z dwóch różnych miast.
const flight_info = {
name: "get_flight_info",
description: "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
parameters: {
type: "object",
properties: {
origin_city: {
type: "string",
description: "The name of the city where the flight originates",
},
destination_city: {
type: "string",
description: "The flight destination city",
},
},
required: ["origin_city", "destination_city"],
},
}
const tools = [
{
type: "function",
function: flight_info,
},
];
W tym przykładzie dane wyjściowe funkcji to brak dostępnych lotów dla wybranej trasy, ale użytkownik powinien rozważyć pociąg.
function get_flight_info(loc_origin, loc_destination) {
return {
info: "There are no flights available from " + loc_origin + " to " + loc_destination + ". You should take a train, specially if it helps to reduce CO2 emissions."
}
}
Uwaga
Modele cohere wymagają, aby odpowiedzi narzędzia było prawidłową zawartością JSON sformatowaną jako ciąg. Podczas konstruowania komunikatów typu Tool upewnij się, że odpowiedź jest prawidłowym ciągiem JSON.
Monituj model o zarezerwowanie lotów przy użyciu tej funkcji:
var result = await client.path("/chat/completions").post({
body: {
messages: messages,
tools: tools,
tool_choice: "auto"
}
});
Możesz sprawdzić odpowiedź, aby dowiedzieć się, czy należy wywołać narzędzie. Sprawdź przyczynę zakończenia, aby określić, czy narzędzie ma być wywoływane. Należy pamiętać, że można wskazać wiele typów narzędzi. W tym przykładzie pokazano narzędzie typu function.
const response_message = response.body.choices[0].message;
const tool_calls = response_message.tool_calls;
console.log("Finish reason: " + response.body.choices[0].finish_reason);
console.log("Tool call: " + tool_calls);
Aby kontynuować, dołącz tę wiadomość do historii czatów:
messages.push(response_message);
Teraz nadszedł czas, aby wywołać odpowiednią funkcję do obsługi wywołania narzędzia. Poniższy fragment kodu iteruje wszystkie wywołania narzędzia wskazane w odpowiedzi i wywołuje odpowiednią funkcję z odpowiednimi parametrami. Odpowiedź jest również dołączana do historii czatów.
function applyToolCall({ function: call, id }) {
// Get the tool details:
const tool_params = JSON.parse(call.arguments);
console.log("Calling function " + call.name + " with arguments " + tool_params);
// Call the function defined above using `window`, which returns the list of all functions
// available in the scope as a dictionary. Notice that this is just done as a simple way to get
// the function callable from its string name. Then we can call it with the corresponding
// arguments.
const function_response = tool_params.map(window[call.name]);
console.log("-> " + function_response);
return function_response
}
for (const tool_call of tool_calls) {
var tool_response = tool_call.apply(applyToolCall);
messages.push(
{
role: "tool",
tool_call_id: tool_call.id,
content: tool_response
}
);
}
Wyświetl odpowiedź z modelu:
var result = await client.path("/chat/completions").post({
body: {
messages: messages,
tools: tools,
}
});
Stosowanie bezpieczeństwa zawartości
Interfejs API wnioskowania modelu AI platformy Azure obsługuje bezpieczeństwo zawartości usługi Azure AI. W przypadku korzystania z wdrożeń z włączonym bezpieczeństwem zawartości sztucznej inteligencji platformy Azure dane wejściowe i wyjściowe przechodzą przez zespół modeli klasyfikacji mających na celu wykrywanie i zapobieganie wystąpieniu szkodliwej zawartości. System filtrowania zawartości wykrywa i podejmuje działania na określonych kategoriach potencjalnie szkodliwej zawartości w monitach wejściowych i uzupełnianiu danych wyjściowych.
W poniższym przykładzie pokazano, jak obsługiwać zdarzenia, gdy model wykryje szkodliwą zawartość w monicie wejściowym i włączono bezpieczeństwo zawartości.
try {
var messages = [
{ role: "system", content: "You are an AI assistant that helps people find information." },
{ role: "user", content: "Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills." },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
}
});
console.log(response.body.choices[0].message.content);
}
catch (error) {
if (error.status_code == 400) {
var response = JSON.parse(error.response._content);
if (response.error) {
console.log(`Your request triggered an ${response.error.code} error:\n\t ${response.error.message}`);
}
else
{
throw error;
}
}
}
Napiwek
Aby dowiedzieć się więcej na temat konfigurowania i kontrolowania ustawień bezpieczeństwa zawartości usługi Azure AI, zapoznaj się z dokumentacją dotyczącą bezpieczeństwa zawartości usługi Azure AI.
Używanie uzupełniania czatu z obrazami
Niektóre modele mogą powodować między tekstem i obrazami oraz generować uzupełnienia tekstu na podstawie obu rodzajów danych wejściowych. W tej sekcji zapoznasz się z możliwościami niektórych modeli przetwarzania obrazów w sposób czatu:
Ważne
Niektóre modele obsługują tylko jeden obraz dla każdego kolei w konwersacji czatu i tylko ostatni obraz jest zachowywany w kontekście. Jeśli dodasz wiele obrazów, spowoduje to wystąpienie błędu.
Aby wyświetlić tę możliwość, pobierz obraz i zakoduj informacje jako base64 ciąg. Wynikowe dane powinny znajdować się wewnątrz adresu URL danych:
const image_url = "https://news.microsoft.com/source/wp-content/uploads/2024/04/The-Phi-3-small-language-models-with-big-potential-1-1900x1069.jpg";
const image_format = "jpeg";
const response = await fetch(image_url, { headers: { "User-Agent": "Mozilla/5.0" } });
const image_data = await response.arrayBuffer();
const image_data_base64 = Buffer.from(image_data).toString("base64");
const data_url = `data:image/${image_format};base64,${image_data_base64}`;
Wizualizowanie obrazu:
const img = document.createElement("img");
img.src = data_url;
document.body.appendChild(img);
Teraz utwórz żądanie ukończenia czatu z obrazem:
var messages = [
{ role: "system", content: "You are a helpful assistant that can generate responses based on images." },
{ role: "user", content:
[
{ type: "text", text: "Which conclusion can be extracted from the following chart?" },
{ type: "image_url", image:
{
url: data_url
}
}
]
}
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
temperature: 0,
top_p: 1,
max_tokens: 2048,
}
});
Odpowiedź jest następująca, gdzie można zobaczyć statystyki użycia modelu:
console.log(response.body.choices[0].message.role + ": " + response.body.choices[0].message.content);
console.log("Model:", response.body.model);
console.log("Usage:");
console.log("\tPrompt tokens:", response.body.usage.prompt_tokens);
console.log("\tCompletion tokens:", response.body.usage.completion_tokens);
console.log("\tTotal tokens:", response.body.usage.total_tokens);
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: mistral-large-2407
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Ważne
Elementy oznaczone (wersja zapoznawcza) w tym artykule są obecnie dostępne w publicznej wersji zapoznawczej. Ta wersja zapoznawcza jest udostępniana bez umowy dotyczącej poziomu usług i nie zalecamy korzystania z niej w przypadku obciążeń produkcyjnych. Niektóre funkcje mogą być nieobsługiwane lub ograniczone. Aby uzyskać więcej informacji, zobacz Uzupełniające warunki korzystania z wersji zapoznawczych platformy Microsoft Azure.
W tym artykule wyjaśniono, jak używać interfejsu API uzupełniania czatów z modelami wdrożonym w wnioskowaniu modelu AI platformy Azure w usługach azure AI.
Wymagania wstępne
Aby używać modeli uzupełniania czatów w aplikacji, potrzebne są następujące elementy:
Subskrypcja Azure. Jeśli używasz modeli GitHub, możesz uaktualnić środowisko i utworzyć subskrypcję platformy Azure w tym procesie. Przeczytaj artykuł Upgrade from GitHub Models to Azure AI model inference if's your case (Uaktualnianie modeli Usługi GitHub do wnioskowania modelu AI platformy Azure), jeśli tak jest.
Zasób usług AI platformy Azure. Aby uzyskać więcej informacji, zobacz Create an Azure AI Services resource (Tworzenie zasobu usług Azure AI Services).
Adres URL i klucz punktu końcowego.
Wdrożenie modelu uzupełniania czatu. Jeśli nie masz jeszcze jednego artykułu Dodawanie i konfigurowanie modeli w usługach azure AI w celu dodania modelu uzupełniania czatów do zasobu.
Dodaj pakiet wnioskowania usługi Azure AI do projektu:
<dependency> <groupId>com.azure</groupId> <artifactId>azure-ai-inference</artifactId> <version>1.0.0-beta.1</version> </dependency>Jeśli używasz identyfikatora Entra, potrzebujesz również następującego pakietu:
<dependency> <groupId>com.azure</groupId> <artifactId>azure-identity</artifactId> <version>1.13.3</version> </dependency>Zaimportuj następującą przestrzeń nazw:
package com.azure.ai.inference.usage; import com.azure.ai.inference.EmbeddingsClient; import com.azure.ai.inference.EmbeddingsClientBuilder; import com.azure.ai.inference.models.EmbeddingsResult; import com.azure.ai.inference.models.EmbeddingItem; import com.azure.core.credential.AzureKeyCredential; import com.azure.core.util.Configuration; import java.util.ArrayList; import java.util.List;
Korzystanie z uzupełniania czatu
Najpierw utwórz klienta, aby korzystać z modelu. Poniższy kod używa adresu URL punktu końcowego i klucza przechowywanego w zmiennych środowiskowych.
Jeśli zasób został skonfigurowany do obsługi identyfikatora Entra firmy Microsoft, możesz użyć następującego fragmentu kodu, aby utworzyć klienta.
Tworzenie żądania ukończenia czatu
W poniższym przykładzie pokazano, jak utworzyć podstawowe żądanie ukończenia czatu do modelu.
Uwaga
Niektóre modele nie obsługują komunikatów systemowych (role="system"). W przypadku korzystania z interfejsu API wnioskowania modelu AI platformy Azure komunikaty systemowe są tłumaczone na komunikaty użytkowników, co jest najbliższą dostępną funkcją. To tłumaczenie jest oferowane dla wygody, ale ważne jest, aby sprawdzić, czy model jest przestrzegany instrukcji w komunikacie systemowym z odpowiednim poziomem pewności.
Odpowiedź jest następująca, gdzie można zobaczyć statystyki użycia modelu:
Response: As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.
Model: mistral-large-2407
Usage:
Prompt tokens: 19
Total tokens: 91
Completion tokens: 72
Sprawdź sekcję usage w odpowiedzi, aby zobaczyć liczbę tokenów używanych dla monitu, łączną liczbę wygenerowanych tokenów oraz liczbę tokenów używanych do ukończenia.
Przesyłanie strumieniowe zawartości
Domyślnie interfejs API uzupełniania zwraca całą wygenerowaną zawartość w pojedynczej odpowiedzi. Jeśli generujesz długie zakończenia, oczekiwanie na odpowiedź może potrwać wiele sekund.
Możesz przesyłać strumieniowo zawartość, aby pobrać ją podczas jego generowania. Zawartość strumieniowa umożliwia rozpoczęcie przetwarzania ukończenia w miarę dostępności zawartości. Ten tryb zwraca obiekt, który przesyła strumieniowo odpowiedź jako zdarzenia wysyłane tylko do serwera. Wyodrębnij fragmenty z pola różnicowego, a nie z pola komunikatu.
Możesz zwizualizować sposób generowania zawartości przez przesyłanie strumieniowe:
Poznaj więcej parametrów obsługiwanych przez klienta wnioskowania
Zapoznaj się z innymi parametrami, które można określić w kliencie wnioskowania. Aby uzyskać pełną listę wszystkich obsługiwanych parametrów i odpowiedniej dokumentacji, zobacz Dokumentacja interfejsu API wnioskowania modelu AI platformy Azure. Niektóre modele nie obsługują formatowania danych wyjściowych JSON. Zawsze możesz monitować model o wygenerowanie danych wyjściowych JSON. Jednak takie dane wyjściowe nie mają gwarancji, że są prawidłowe dane JSON.
Jeśli chcesz przekazać parametr, który nie znajduje się na liście obsługiwanych parametrów, możesz przekazać go do modelu bazowego przy użyciu dodatkowych parametrów. Zobacz Przekazywanie dodatkowych parametrów do modelu.
Tworzenie danych wyjściowych JSON
Niektóre modele mogą tworzyć dane wyjściowe JSON. Ustaw response_format wartość na wartość , aby json_object włączyć tryb JSON i zagwarantować, że komunikat generowany przez model jest prawidłowym kodem JSON. Należy również poinstruować model, aby samodzielnie wygenerował kod JSON za pośrednictwem komunikatu systemu lub użytkownika. Ponadto zawartość wiadomości może być częściowo odcięta, jeśli finish_reason="length", co wskazuje, że generacja przekroczyła max_tokens lub że konwersacja przekroczyła maksymalną długość kontekstu.
Przekazywanie dodatkowych parametrów do modelu
Interfejs API wnioskowania modelu AI platformy Azure umożliwia przekazywanie dodatkowych parametrów do modelu. Poniższy przykład kodu pokazuje, jak przekazać dodatkowy parametr logprobs do modelu.
Przed przekazaniem dodatkowych parametrów do interfejsu API wnioskowania modelu AI platformy Azure upewnij się, że model obsługuje te dodatkowe parametry. Po wysłaniu żądania do modelu bazowego nagłówek extra-parameters jest przekazywany do modelu z wartością pass-through. Ta wartość informuje punkt końcowy o przekazaniu dodatkowych parametrów do modelu. Użycie dodatkowych parametrów z modelem nie gwarantuje, że model może je faktycznie obsłużyć. Przeczytaj dokumentację modelu, aby dowiedzieć się, które dodatkowe parametry są obsługiwane.
Używanie narzędzi
Niektóre modele obsługują korzystanie z narzędzi, które mogą być niezwykłym zasobem, gdy trzeba odciążyć określone zadania z modelu językowego, a zamiast tego polegać na bardziej deterministycznym systemie, a nawet innym modelu językowym. Interfejs API wnioskowania modelu AI platformy Azure umożliwia definiowanie narzędzi w następujący sposób.
Poniższy przykład kodu tworzy definicję narzędzia, która umożliwia wyszukiwanie informacji o locie z dwóch różnych miast.
W tym przykładzie dane wyjściowe funkcji to brak dostępnych lotów dla wybranej trasy, ale użytkownik powinien rozważyć pociąg.
Uwaga
Modele cohere wymagają, aby odpowiedzi narzędzia było prawidłową zawartością JSON sformatowaną jako ciąg. Podczas konstruowania komunikatów typu Tool upewnij się, że odpowiedź jest prawidłowym ciągiem JSON.
Monituj model o zarezerwowanie lotów przy użyciu tej funkcji:
Możesz sprawdzić odpowiedź, aby dowiedzieć się, czy należy wywołać narzędzie. Sprawdź przyczynę zakończenia, aby określić, czy narzędzie ma być wywoływane. Należy pamiętać, że można wskazać wiele typów narzędzi. W tym przykładzie pokazano narzędzie typu function.
Aby kontynuować, dołącz tę wiadomość do historii czatów:
Teraz nadszedł czas, aby wywołać odpowiednią funkcję do obsługi wywołania narzędzia. Poniższy fragment kodu iteruje wszystkie wywołania narzędzia wskazane w odpowiedzi i wywołuje odpowiednią funkcję z odpowiednimi parametrami. Odpowiedź jest również dołączana do historii czatów.
Wyświetl odpowiedź z modelu:
Stosowanie bezpieczeństwa zawartości
Interfejs API wnioskowania modelu AI platformy Azure obsługuje bezpieczeństwo zawartości usługi Azure AI. W przypadku korzystania z wdrożeń z włączonym bezpieczeństwem zawartości sztucznej inteligencji platformy Azure dane wejściowe i wyjściowe przechodzą przez zespół modeli klasyfikacji mających na celu wykrywanie i zapobieganie wystąpieniu szkodliwej zawartości. System filtrowania zawartości wykrywa i podejmuje działania na określonych kategoriach potencjalnie szkodliwej zawartości w monitach wejściowych i uzupełnianiu danych wyjściowych.
W poniższym przykładzie pokazano, jak obsługiwać zdarzenia, gdy model wykryje szkodliwą zawartość w monicie wejściowym i włączono bezpieczeństwo zawartości.
Napiwek
Aby dowiedzieć się więcej na temat konfigurowania i kontrolowania ustawień bezpieczeństwa zawartości usługi Azure AI, zapoznaj się z dokumentacją dotyczącą bezpieczeństwa zawartości usługi Azure AI.
Używanie uzupełniania czatu z obrazami
Niektóre modele mogą powodować między tekstem i obrazami oraz generować uzupełnienia tekstu na podstawie obu rodzajów danych wejściowych. W tej sekcji zapoznasz się z możliwościami niektórych modeli przetwarzania obrazów w sposób czatu:
Ważne
Niektóre modele obsługują tylko jeden obraz dla każdego kolei w konwersacji czatu i tylko ostatni obraz jest zachowywany w kontekście. Jeśli dodasz wiele obrazów, spowoduje to wystąpienie błędu.
Aby wyświetlić tę możliwość, pobierz obraz i zakoduj informacje jako base64 ciąg. Wynikowe dane powinny znajdować się wewnątrz adresu URL danych:
Wizualizowanie obrazu:
Teraz utwórz żądanie ukończenia czatu z obrazem:
Odpowiedź jest następująca, gdzie można zobaczyć statystyki użycia modelu:
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: mistral-large-2407
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Ważne
Elementy oznaczone (wersja zapoznawcza) w tym artykule są obecnie dostępne w publicznej wersji zapoznawczej. Ta wersja zapoznawcza jest udostępniana bez umowy dotyczącej poziomu usług i nie zalecamy korzystania z niej w przypadku obciążeń produkcyjnych. Niektóre funkcje mogą być nieobsługiwane lub ograniczone. Aby uzyskać więcej informacji, zobacz Uzupełniające warunki korzystania z wersji zapoznawczych platformy Microsoft Azure.
W tym artykule wyjaśniono, jak używać interfejsu API uzupełniania czatów z modelami wdrożonym w wnioskowaniu modelu AI platformy Azure w usługach azure AI.
Wymagania wstępne
Aby używać modeli uzupełniania czatów w aplikacji, potrzebne są następujące elementy:
Subskrypcja Azure. Jeśli używasz modeli GitHub, możesz uaktualnić środowisko i utworzyć subskrypcję platformy Azure w tym procesie. Przeczytaj artykuł Upgrade from GitHub Models to Azure AI model inference if's your case (Uaktualnianie modeli Usługi GitHub do wnioskowania modelu AI platformy Azure), jeśli tak jest.
Zasób usług AI platformy Azure. Aby uzyskać więcej informacji, zobacz Create an Azure AI Services resource (Tworzenie zasobu usług Azure AI Services).
Adres URL i klucz punktu końcowego.
Wdrożenie modelu uzupełniania czatu. Jeśli nie masz jeszcze jednego artykułu Dodawanie i konfigurowanie modeli w usługach azure AI w celu dodania modelu uzupełniania czatów do zasobu.
Zainstaluj pakiet wnioskowania usługi Azure AI za pomocą następującego polecenia:
dotnet add package Azure.AI.Inference --prereleaseJeśli używasz identyfikatora Entra, potrzebujesz również następującego pakietu:
dotnet add package Azure.Identity
Korzystanie z uzupełniania czatu
Najpierw utwórz klienta, aby korzystać z modelu. Poniższy kod używa adresu URL punktu końcowego i klucza przechowywanego w zmiennych środowiskowych.
ChatCompletionsClient client = new ChatCompletionsClient(
new Uri(Environment.GetEnvironmentVariable("AZURE_INFERENCE_ENDPOINT")),
new AzureKeyCredential(Environment.GetEnvironmentVariable("AZURE_INFERENCE_CREDENTIAL")),
);
Jeśli zasób został skonfigurowany do obsługi identyfikatora Entra firmy Microsoft, możesz użyć następującego fragmentu kodu, aby utworzyć klienta.
TokenCredential credential = new DefaultAzureCredential(includeInteractiveCredentials: true);
AzureAIInferenceClientOptions clientOptions = new AzureAIInferenceClientOptions();
BearerTokenAuthenticationPolicy tokenPolicy = new BearerTokenAuthenticationPolicy(credential, new string[] { "https://cognitiveservices.azure.com/.default" });
clientOptions.AddPolicy(tokenPolicy, HttpPipelinePosition.PerRetry);
client = new ChatCompletionsClient(
new Uri(Environment.GetEnvironmentVariable("AZURE_INFERENCE_ENDPOINT")),
credential,
clientOptions,
);
Tworzenie żądania ukończenia czatu
W poniższym przykładzie pokazano, jak utworzyć podstawowe żądanie ukończenia czatu do modelu.
ChatCompletionsOptions requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are a helpful assistant."),
new ChatRequestUserMessage("How many languages are in the world?")
},
Model = "mistral-large-2407",
};
Response<ChatCompletions> response = client.Complete(requestOptions);
Uwaga
Niektóre modele nie obsługują komunikatów systemowych (role="system"). W przypadku korzystania z interfejsu API wnioskowania modelu AI platformy Azure komunikaty systemowe są tłumaczone na komunikaty użytkowników, co jest najbliższą dostępną funkcją. To tłumaczenie jest oferowane dla wygody, ale ważne jest, aby sprawdzić, czy model jest przestrzegany instrukcji w komunikacie systemowym z odpowiednim poziomem pewności.
Odpowiedź jest następująca, gdzie można zobaczyć statystyki użycia modelu:
Console.WriteLine($"Response: {response.Value.Content}");
Console.WriteLine($"Model: {response.Value.Model}");
Console.WriteLine("Usage:");
Console.WriteLine($"\tPrompt tokens: {response.Value.Usage.PromptTokens}");
Console.WriteLine($"\tTotal tokens: {response.Value.Usage.TotalTokens}");
Console.WriteLine($"\tCompletion tokens: {response.Value.Usage.CompletionTokens}");
Response: As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.
Model: mistral-large-2407
Usage:
Prompt tokens: 19
Total tokens: 91
Completion tokens: 72
Sprawdź sekcję usage w odpowiedzi, aby zobaczyć liczbę tokenów używanych dla monitu, łączną liczbę wygenerowanych tokenów oraz liczbę tokenów używanych do ukończenia.
Przesyłanie strumieniowe zawartości
Domyślnie interfejs API uzupełniania zwraca całą wygenerowaną zawartość w pojedynczej odpowiedzi. Jeśli generujesz długie zakończenia, oczekiwanie na odpowiedź może potrwać wiele sekund.
Możesz przesyłać strumieniowo zawartość, aby pobrać ją podczas jego generowania. Zawartość strumieniowa umożliwia rozpoczęcie przetwarzania ukończenia w miarę dostępności zawartości. Ten tryb zwraca obiekt, który przesyła strumieniowo odpowiedź jako zdarzenia wysyłane tylko do serwera. Wyodrębnij fragmenty z pola różnicowego, a nie z pola komunikatu.
Aby przesłać strumieniowo uzupełnienia, użyj CompleteStreamingAsync metody podczas wywoływania modelu. Zwróć uwagę, że w tym przykładzie wywołanie jest opakowane w metodę asynchroniczną.
static async Task StreamMessageAsync(ChatCompletionsClient client)
{
ChatCompletionsOptions requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are a helpful assistant."),
new ChatRequestUserMessage("How many languages are in the world? Write an essay about it.")
},
MaxTokens=4096,
Model = "mistral-large-2407",
};
StreamingResponse<StreamingChatCompletionsUpdate> streamResponse = await client.CompleteStreamingAsync(requestOptions);
await PrintStream(streamResponse);
}
Aby zwizualizować dane wyjściowe, zdefiniuj metodę asynchroniczną, aby wydrukować strumień w konsoli programu .
static async Task PrintStream(StreamingResponse<StreamingChatCompletionsUpdate> response)
{
await foreach (StreamingChatCompletionsUpdate chatUpdate in response)
{
if (chatUpdate.Role.HasValue)
{
Console.Write($"{chatUpdate.Role.Value.ToString().ToUpperInvariant()}: ");
}
if (!string.IsNullOrEmpty(chatUpdate.ContentUpdate))
{
Console.Write(chatUpdate.ContentUpdate);
}
}
}
Możesz zwizualizować sposób generowania zawartości przez przesyłanie strumieniowe:
StreamMessageAsync(client).GetAwaiter().GetResult();
Poznaj więcej parametrów obsługiwanych przez klienta wnioskowania
Zapoznaj się z innymi parametrami, które można określić w kliencie wnioskowania. Aby uzyskać pełną listę wszystkich obsługiwanych parametrów i odpowiedniej dokumentacji, zobacz Dokumentacja interfejsu API wnioskowania modelu AI platformy Azure.
requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are a helpful assistant."),
new ChatRequestUserMessage("How many languages are in the world?")
},
Model = "mistral-large-2407",
PresencePenalty = 0.1f,
FrequencyPenalty = 0.8f,
MaxTokens = 2048,
StopSequences = { "<|endoftext|>" },
Temperature = 0,
NucleusSamplingFactor = 1,
ResponseFormat = new ChatCompletionsResponseFormatText()
};
response = client.Complete(requestOptions);
Console.WriteLine($"Response: {response.Value.Content}");
Niektóre modele nie obsługują formatowania danych wyjściowych JSON. Zawsze możesz monitować model o wygenerowanie danych wyjściowych JSON. Jednak takie dane wyjściowe nie mają gwarancji, że są prawidłowe dane JSON.
Jeśli chcesz przekazać parametr, który nie znajduje się na liście obsługiwanych parametrów, możesz przekazać go do modelu bazowego przy użyciu dodatkowych parametrów. Zobacz Przekazywanie dodatkowych parametrów do modelu.
Tworzenie danych wyjściowych JSON
Niektóre modele mogą tworzyć dane wyjściowe JSON. Ustaw response_format wartość na wartość , aby json_object włączyć tryb JSON i zagwarantować, że komunikat generowany przez model jest prawidłowym kodem JSON. Należy również poinstruować model, aby samodzielnie wygenerował kod JSON za pośrednictwem komunikatu systemu lub użytkownika. Ponadto zawartość wiadomości może być częściowo odcięta, jeśli finish_reason="length", co wskazuje, że generacja przekroczyła max_tokens lub że konwersacja przekroczyła maksymalną długość kontekstu.
requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage(
"You are a helpful assistant that always generate responses in JSON format, " +
"using. the following format: { \"answer\": \"response\" }."
),
new ChatRequestUserMessage(
"How many languages are in the world?"
)
},
ResponseFormat = new ChatCompletionsResponseFormatJsonObject(),
Model = "mistral-large-2407",
};
response = client.Complete(requestOptions);
Console.WriteLine($"Response: {response.Value.Content}");
Przekazywanie dodatkowych parametrów do modelu
Interfejs API wnioskowania modelu AI platformy Azure umożliwia przekazywanie dodatkowych parametrów do modelu. Poniższy przykład kodu pokazuje, jak przekazać dodatkowy parametr logprobs do modelu.
requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are a helpful assistant."),
new ChatRequestUserMessage("How many languages are in the world?")
},
Model = "mistral-large-2407",
AdditionalProperties = { { "logprobs", BinaryData.FromString("true") } },
};
response = client.Complete(requestOptions, extraParams: ExtraParameters.PassThrough);
Console.WriteLine($"Response: {response.Value.Content}");
Przed przekazaniem dodatkowych parametrów do interfejsu API wnioskowania modelu AI platformy Azure upewnij się, że model obsługuje te dodatkowe parametry. Po wysłaniu żądania do modelu bazowego nagłówek extra-parameters jest przekazywany do modelu z wartością pass-through. Ta wartość informuje punkt końcowy o przekazaniu dodatkowych parametrów do modelu. Użycie dodatkowych parametrów z modelem nie gwarantuje, że model może je faktycznie obsłużyć. Przeczytaj dokumentację modelu, aby dowiedzieć się, które dodatkowe parametry są obsługiwane.
Używanie narzędzi
Niektóre modele obsługują korzystanie z narzędzi, które mogą być niezwykłym zasobem, gdy trzeba odciążyć określone zadania z modelu językowego, a zamiast tego polegać na bardziej deterministycznym systemie, a nawet innym modelu językowym. Interfejs API wnioskowania modelu AI platformy Azure umożliwia definiowanie narzędzi w następujący sposób.
Poniższy przykład kodu tworzy definicję narzędzia, która umożliwia wyszukiwanie informacji o locie z dwóch różnych miast.
FunctionDefinition flightInfoFunction = new FunctionDefinition("getFlightInfo")
{
Description = "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
Parameters = BinaryData.FromObjectAsJson(new
{
Type = "object",
Properties = new
{
origin_city = new
{
Type = "string",
Description = "The name of the city where the flight originates"
},
destination_city = new
{
Type = "string",
Description = "The flight destination city"
}
}
},
new JsonSerializerOptions() { PropertyNamingPolicy = JsonNamingPolicy.CamelCase }
)
};
ChatCompletionsFunctionToolDefinition getFlightTool = new ChatCompletionsFunctionToolDefinition(flightInfoFunction);
W tym przykładzie dane wyjściowe funkcji to brak dostępnych lotów dla wybranej trasy, ale użytkownik powinien rozważyć pociąg.
static string getFlightInfo(string loc_origin, string loc_destination)
{
return JsonSerializer.Serialize(new
{
info = $"There are no flights available from {loc_origin} to {loc_destination}. You " +
"should take a train, specially if it helps to reduce CO2 emissions."
});
}
Uwaga
Modele cohere wymagają, aby odpowiedzi narzędzia było prawidłową zawartością JSON sformatowaną jako ciąg. Podczas konstruowania komunikatów typu Tool upewnij się, że odpowiedź jest prawidłowym ciągiem JSON.
Monituj model o zarezerwowanie lotów przy użyciu tej funkcji:
var chatHistory = new List<ChatRequestMessage>(){
new ChatRequestSystemMessage(
"You are a helpful assistant that help users to find information about traveling, " +
"how to get to places and the different transportations options. You care about the" +
"environment and you always have that in mind when answering inqueries."
),
new ChatRequestUserMessage("When is the next flight from Miami to Seattle?")
};
requestOptions = new ChatCompletionsOptions(chatHistory, model: "mistral-large-2407");
requestOptions.Tools.Add(getFlightTool);
requestOptions.ToolChoice = ChatCompletionsToolChoice.Auto;
response = client.Complete(requestOptions);
Możesz sprawdzić odpowiedź, aby dowiedzieć się, czy należy wywołać narzędzie. Sprawdź przyczynę zakończenia, aby określić, czy narzędzie ma być wywoływane. Należy pamiętać, że można wskazać wiele typów narzędzi. W tym przykładzie pokazano narzędzie typu function.
var responseMessage = response.Value;
var toolsCall = responseMessage.ToolCalls;
Console.WriteLine($"Finish reason: {response.Value.Choices[0].FinishReason}");
Console.WriteLine($"Tool call: {toolsCall[0].Id}");
Aby kontynuować, dołącz tę wiadomość do historii czatów:
requestOptions.Messages.Add(new ChatRequestAssistantMessage(response.Value));
Teraz nadszedł czas, aby wywołać odpowiednią funkcję do obsługi wywołania narzędzia. Poniższy fragment kodu iteruje wszystkie wywołania narzędzia wskazane w odpowiedzi i wywołuje odpowiednią funkcję z odpowiednimi parametrami. Odpowiedź jest również dołączana do historii czatów.
foreach (ChatCompletionsToolCall tool in toolsCall)
{
if (tool is ChatCompletionsFunctionToolCall functionTool)
{
// Get the tool details:
string callId = functionTool.Id;
string toolName = functionTool.Name;
string toolArgumentsString = functionTool.Arguments;
Dictionary<string, object> toolArguments = JsonSerializer.Deserialize<Dictionary<string, object>>(toolArgumentsString);
// Here you have to call the function defined. In this particular example we use
// reflection to find the method we definied before in an static class called
// `ChatCompletionsExamples`. Using reflection allows us to call a function
// by string name. Notice that this is just done for demonstration purposes as a
// simple way to get the function callable from its string name. Then we can call
// it with the corresponding arguments.
var flags = BindingFlags.Instance | BindingFlags.Public | BindingFlags.NonPublic | BindingFlags.Static;
string toolResponse = (string)typeof(ChatCompletionsExamples).GetMethod(toolName, flags).Invoke(null, toolArguments.Values.Cast<object>().ToArray());
Console.WriteLine("->", toolResponse);
requestOptions.Messages.Add(new ChatRequestToolMessage(toolResponse, callId));
}
else
throw new Exception("Unsupported tool type");
}
Wyświetl odpowiedź z modelu:
response = client.Complete(requestOptions);
Stosowanie bezpieczeństwa zawartości
Interfejs API wnioskowania modelu AI platformy Azure obsługuje bezpieczeństwo zawartości usługi Azure AI. W przypadku korzystania z wdrożeń z włączonym bezpieczeństwem zawartości sztucznej inteligencji platformy Azure dane wejściowe i wyjściowe przechodzą przez zespół modeli klasyfikacji mających na celu wykrywanie i zapobieganie wystąpieniu szkodliwej zawartości. System filtrowania zawartości wykrywa i podejmuje działania na określonych kategoriach potencjalnie szkodliwej zawartości w monitach wejściowych i uzupełnianiu danych wyjściowych.
W poniższym przykładzie pokazano, jak obsługiwać zdarzenia, gdy model wykryje szkodliwą zawartość w monicie wejściowym i włączono bezpieczeństwo zawartości.
try
{
requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are an AI assistant that helps people find information."),
new ChatRequestUserMessage(
"Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills."
),
},
Model = "mistral-large-2407",
};
response = client.Complete(requestOptions);
Console.WriteLine(response.Value.Content);
}
catch (RequestFailedException ex)
{
if (ex.ErrorCode == "content_filter")
{
Console.WriteLine($"Your query has trigger Azure Content Safety: {ex.Message}");
}
else
{
throw;
}
}
Napiwek
Aby dowiedzieć się więcej na temat konfigurowania i kontrolowania ustawień bezpieczeństwa zawartości usługi Azure AI, zapoznaj się z dokumentacją dotyczącą bezpieczeństwa zawartości usługi Azure AI.
Używanie uzupełniania czatu z obrazami
Niektóre modele mogą powodować między tekstem i obrazami oraz generować uzupełnienia tekstu na podstawie obu rodzajów danych wejściowych. W tej sekcji zapoznasz się z możliwościami niektórych modeli przetwarzania obrazów w sposób czatu:
Ważne
Niektóre modele obsługują tylko jeden obraz dla każdego kolei w konwersacji czatu i tylko ostatni obraz jest zachowywany w kontekście. Jeśli dodasz wiele obrazów, spowoduje to wystąpienie błędu.
Aby wyświetlić tę możliwość, pobierz obraz i zakoduj informacje jako base64 ciąg. Wynikowe dane powinny znajdować się wewnątrz adresu URL danych:
string imageUrl = "https://news.microsoft.com/source/wp-content/uploads/2024/04/The-Phi-3-small-language-models-with-big-potential-1-1900x1069.jpg";
string imageFormat = "jpeg";
HttpClient httpClient = new HttpClient();
httpClient.DefaultRequestHeaders.Add("User-Agent", "Mozilla/5.0");
byte[] imageBytes = httpClient.GetByteArrayAsync(imageUrl).Result;
string imageBase64 = Convert.ToBase64String(imageBytes);
string dataUrl = $"data:image/{imageFormat};base64,{imageBase64}";
Wizualizowanie obrazu:
Teraz utwórz żądanie ukończenia czatu z obrazem:
ChatCompletionsOptions requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are an AI assistant that helps people find information."),
new ChatRequestUserMessage([
new ChatMessageTextContentItem("Which conclusion can be extracted from the following chart?"),
new ChatMessageImageContentItem(new Uri(dataUrl))
]),
},
MaxTokens=2048,
Model = "phi-3.5-vision-instruct",
};
var response = client.Complete(requestOptions);
Console.WriteLine(response.Value.Content);
Odpowiedź jest następująca, gdzie można zobaczyć statystyki użycia modelu:
Console.WriteLine($"{response.Value.Role}: {response.Value.Content}");
Console.WriteLine($"Model: {response.Value.Model}");
Console.WriteLine("Usage:");
Console.WriteLine($"\tPrompt tokens: {response.Value.Usage.PromptTokens}");
Console.WriteLine($"\tTotal tokens: {response.Value.Usage.TotalTokens}");
Console.WriteLine($"\tCompletion tokens: {response.Value.Usage.CompletionTokens}");
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: phi-3.5-vision-instruct
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Ważne
Elementy oznaczone (wersja zapoznawcza) w tym artykule są obecnie dostępne w publicznej wersji zapoznawczej. Ta wersja zapoznawcza jest udostępniana bez umowy dotyczącej poziomu usług i nie zalecamy korzystania z niej w przypadku obciążeń produkcyjnych. Niektóre funkcje mogą być nieobsługiwane lub ograniczone. Aby uzyskać więcej informacji, zobacz Uzupełniające warunki korzystania z wersji zapoznawczych platformy Microsoft Azure.
W tym artykule wyjaśniono, jak używać interfejsu API uzupełniania czatów z modelami wdrożonym w wnioskowaniu modelu AI platformy Azure w usługach azure AI.
Wymagania wstępne
Aby używać modeli uzupełniania czatów w aplikacji, potrzebne są następujące elementy:
Subskrypcja Azure. Jeśli używasz modeli GitHub, możesz uaktualnić środowisko i utworzyć subskrypcję platformy Azure w tym procesie. Przeczytaj artykuł Upgrade from GitHub Models to Azure AI model inference if's your case (Uaktualnianie modeli Usługi GitHub do wnioskowania modelu AI platformy Azure), jeśli tak jest.
Zasób usług AI platformy Azure. Aby uzyskać więcej informacji, zobacz Create an Azure AI Services resource (Tworzenie zasobu usług Azure AI Services).
Adres URL i klucz punktu końcowego.
- Wdrożenie modelu uzupełniania czatu. Jeśli nie masz jeszcze jednego artykułu Dodawanie i konfigurowanie modeli w usługach azure AI w celu dodania modelu uzupełniania czatów do zasobu.
Korzystanie z uzupełniania czatu
Aby użyć osadzania tekstu, użyj trasy /chat/completions dołączonej do podstawowego adresu URL wraz z poświadczeniami wskazanymi w pliku api-key.
Authorization nagłówek jest również obsługiwany w formacie Bearer <key>.
POST https://<resource>.services.ai.azure.com/models/chat/completions?api-version=2024-05-01-preview
Content-Type: application/json
api-key: <key>
Jeśli skonfigurowano zasób z obsługą identyfikatora Entra firmy Microsoft, przekaż token w nagłówkuAuthorization:
POST https://<resource>.services.ai.azure.com/models/chat/completions?api-version=2024-05-01-preview
Content-Type: application/json
Authorization: Bearer <token>
Tworzenie żądania ukończenia czatu
W poniższym przykładzie pokazano, jak utworzyć podstawowe żądanie ukończenia czatu do modelu.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many languages are in the world?"
}
]
}
Uwaga
Niektóre modele nie obsługują komunikatów systemowych (role="system"). W przypadku korzystania z interfejsu API wnioskowania modelu AI platformy Azure komunikaty systemowe są tłumaczone na komunikaty użytkowników, co jest najbliższą dostępną funkcją. To tłumaczenie jest oferowane dla wygody, ale ważne jest, aby sprawdzić, czy model jest przestrzegany instrukcji w komunikacie systemowym z odpowiednim poziomem pewności.
Odpowiedź jest następująca, gdzie można zobaczyć statystyki użycia modelu:
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726686,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 19,
"total_tokens": 91,
"completion_tokens": 72
}
}
Sprawdź sekcję usage w odpowiedzi, aby zobaczyć liczbę tokenów używanych dla monitu, łączną liczbę wygenerowanych tokenów oraz liczbę tokenów używanych do ukończenia.
Przesyłanie strumieniowe zawartości
Domyślnie interfejs API uzupełniania zwraca całą wygenerowaną zawartość w pojedynczej odpowiedzi. Jeśli generujesz długie zakończenia, oczekiwanie na odpowiedź może potrwać wiele sekund.
Możesz przesyłać strumieniowo zawartość, aby pobrać ją podczas jego generowania. Zawartość strumieniowa umożliwia rozpoczęcie przetwarzania ukończenia w miarę dostępności zawartości. Ten tryb zwraca obiekt, który przesyła strumieniowo odpowiedź jako zdarzenia wysyłane tylko do serwera. Wyodrębnij fragmenty z pola różnicowego, a nie z pola komunikatu.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many languages are in the world?"
}
],
"stream": true,
"temperature": 0,
"top_p": 1,
"max_tokens": 2048
}
Możesz zwizualizować sposób generowania zawartości przez przesyłanie strumieniowe:
{
"id": "23b54589eba14564ad8a2e6978775a39",
"object": "chat.completion.chunk",
"created": 1718726371,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"delta": {
"role": "assistant",
"content": ""
},
"finish_reason": null,
"logprobs": null
}
]
}
Ostatni komunikat w strumieniu został finish_reason ustawiony, wskazujący przyczynę zatrzymania procesu generowania.
{
"id": "23b54589eba14564ad8a2e6978775a39",
"object": "chat.completion.chunk",
"created": 1718726371,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"delta": {
"content": ""
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 19,
"total_tokens": 91,
"completion_tokens": 72
}
}
Poznaj więcej parametrów obsługiwanych przez klienta wnioskowania
Zapoznaj się z innymi parametrami, które można określić w kliencie wnioskowania. Aby uzyskać pełną listę wszystkich obsługiwanych parametrów i odpowiedniej dokumentacji, zobacz Dokumentacja interfejsu API wnioskowania modelu AI platformy Azure.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many languages are in the world?"
}
],
"presence_penalty": 0.1,
"frequency_penalty": 0.8,
"max_tokens": 2048,
"stop": ["<|endoftext|>"],
"temperature" :0,
"top_p": 1,
"response_format": { "type": "text" }
}
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726686,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 19,
"total_tokens": 91,
"completion_tokens": 72
}
}
Niektóre modele nie obsługują formatowania danych wyjściowych JSON. Zawsze możesz monitować model o wygenerowanie danych wyjściowych JSON. Jednak takie dane wyjściowe nie mają gwarancji, że są prawidłowe dane JSON.
Jeśli chcesz przekazać parametr, który nie znajduje się na liście obsługiwanych parametrów, możesz przekazać go do modelu bazowego przy użyciu dodatkowych parametrów. Zobacz Przekazywanie dodatkowych parametrów do modelu.
Tworzenie danych wyjściowych JSON
Niektóre modele mogą tworzyć dane wyjściowe JSON. Ustaw response_format wartość na wartość , aby json_object włączyć tryb JSON i zagwarantować, że komunikat generowany przez model jest prawidłowym kodem JSON. Należy również poinstruować model, aby samodzielnie wygenerował kod JSON za pośrednictwem komunikatu systemu lub użytkownika. Ponadto zawartość wiadomości może być częściowo odcięta, jeśli finish_reason="length", co wskazuje, że generacja przekroczyła max_tokens lub że konwersacja przekroczyła maksymalną długość kontekstu.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant that always generate responses in JSON format, using the following format: { \"answer\": \"response\" }"
},
{
"role": "user",
"content": "How many languages are in the world?"
}
],
"response_format": { "type": "json_object" }
}
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718727522,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "{\"answer\": \"There are approximately 7,117 living languages in the world today, according to the latest estimates. However, this number can vary as some languages become extinct and others are newly discovered or classified.\"}",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 39,
"total_tokens": 87,
"completion_tokens": 48
}
}
Przekazywanie dodatkowych parametrów do modelu
Interfejs API wnioskowania modelu AI platformy Azure umożliwia przekazywanie dodatkowych parametrów do modelu. Poniższy przykład kodu pokazuje, jak przekazać dodatkowy parametr logprobs do modelu.
POST https://<resource>.services.ai.azure.com/models/chat/completions?api-version=2024-05-01-preview
Authorization: Bearer <TOKEN>
Content-Type: application/json
extra-parameters: pass-through
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many languages are in the world?"
}
],
"logprobs": true
}
Przed przekazaniem dodatkowych parametrów do interfejsu API wnioskowania modelu AI platformy Azure upewnij się, że model obsługuje te dodatkowe parametry. Po wysłaniu żądania do modelu bazowego nagłówek extra-parameters jest przekazywany do modelu z wartością pass-through. Ta wartość informuje punkt końcowy o przekazaniu dodatkowych parametrów do modelu. Użycie dodatkowych parametrów z modelem nie gwarantuje, że model może je faktycznie obsłużyć. Przeczytaj dokumentację modelu, aby dowiedzieć się, które dodatkowe parametry są obsługiwane.
Używanie narzędzi
Niektóre modele obsługują korzystanie z narzędzi, które mogą być niezwykłym zasobem, gdy trzeba odciążyć określone zadania z modelu językowego, a zamiast tego polegać na bardziej deterministycznym systemie, a nawet innym modelu językowym. Interfejs API wnioskowania modelu AI platformy Azure umożliwia definiowanie narzędzi w następujący sposób.
Poniższy przykład kodu tworzy definicję narzędzia, która umożliwia wyszukiwanie informacji o locie z dwóch różnych miast.
{
"type": "function",
"function": {
"name": "get_flight_info",
"description": "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
"parameters": {
"type": "object",
"properties": {
"origin_city": {
"type": "string",
"description": "The name of the city where the flight originates"
},
"destination_city": {
"type": "string",
"description": "The flight destination city"
}
},
"required": [
"origin_city",
"destination_city"
]
}
}
}
W tym przykładzie dane wyjściowe funkcji to brak dostępnych lotów dla wybranej trasy, ale użytkownik powinien rozważyć pociąg.
Uwaga
Modele cohere wymagają, aby odpowiedzi narzędzia było prawidłową zawartością JSON sformatowaną jako ciąg. Podczas konstruowania komunikatów typu Tool upewnij się, że odpowiedź jest prawidłowym ciągiem JSON.
Monituj model o zarezerwowanie lotów przy użyciu tej funkcji:
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant that help users to find information about traveling, how to get to places and the different transportations options. You care about the environment and you always have that in mind when answering inqueries"
},
{
"role": "user",
"content": "When is the next flight from Miami to Seattle?"
}
],
"tool_choice": "auto",
"tools": [
{
"type": "function",
"function": {
"name": "get_flight_info",
"description": "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
"parameters": {
"type": "object",
"properties": {
"origin_city": {
"type": "string",
"description": "The name of the city where the flight originates"
},
"destination_city": {
"type": "string",
"description": "The flight destination city"
}
},
"required": [
"origin_city",
"destination_city"
]
}
}
}
]
}
Możesz sprawdzić odpowiedź, aby dowiedzieć się, czy należy wywołać narzędzie. Sprawdź przyczynę zakończenia, aby określić, czy narzędzie ma być wywoływane. Należy pamiętać, że można wskazać wiele typów narzędzi. W tym przykładzie pokazano narzędzie typu function.
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726007,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "",
"tool_calls": [
{
"id": "abc0dF1gh",
"type": "function",
"function": {
"name": "get_flight_info",
"arguments": "{\"origin_city\": \"Miami\", \"destination_city\": \"Seattle\"}",
"call_id": null
}
}
]
},
"finish_reason": "tool_calls",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 190,
"total_tokens": 226,
"completion_tokens": 36
}
}
Aby kontynuować, dołącz tę wiadomość do historii czatów:
Teraz nadszedł czas, aby wywołać odpowiednią funkcję do obsługi wywołania narzędzia. Poniższy fragment kodu iteruje wszystkie wywołania narzędzia wskazane w odpowiedzi i wywołuje odpowiednią funkcję z odpowiednimi parametrami. Odpowiedź jest również dołączana do historii czatów.
Wyświetl odpowiedź z modelu:
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant that help users to find information about traveling, how to get to places and the different transportations options. You care about the environment and you always have that in mind when answering inqueries"
},
{
"role": "user",
"content": "When is the next flight from Miami to Seattle?"
},
{
"role": "assistant",
"content": "",
"tool_calls": [
{
"id": "abc0DeFgH",
"type": "function",
"function": {
"name": "get_flight_info",
"arguments": "{\"origin_city\": \"Miami\", \"destination_city\": \"Seattle\"}",
"call_id": null
}
}
]
},
{
"role": "tool",
"content": "{ \"info\": \"There are no flights available from Miami to Seattle. You should take a train, specially if it helps to reduce CO2 emissions.\" }",
"tool_call_id": "abc0DeFgH"
}
],
"tool_choice": "auto",
"tools": [
{
"type": "function",
"function": {
"name": "get_flight_info",
"description": "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
"parameters":{
"type": "object",
"properties": {
"origin_city": {
"type": "string",
"description": "The name of the city where the flight originates"
},
"destination_city": {
"type": "string",
"description": "The flight destination city"
}
},
"required": ["origin_city", "destination_city"]
}
}
}
]
}
Stosowanie bezpieczeństwa zawartości
Interfejs API wnioskowania modelu AI platformy Azure obsługuje bezpieczeństwo zawartości usługi Azure AI. W przypadku korzystania z wdrożeń z włączonym bezpieczeństwem zawartości sztucznej inteligencji platformy Azure dane wejściowe i wyjściowe przechodzą przez zespół modeli klasyfikacji mających na celu wykrywanie i zapobieganie wystąpieniu szkodliwej zawartości. System filtrowania zawartości wykrywa i podejmuje działania na określonych kategoriach potencjalnie szkodliwej zawartości w monitach wejściowych i uzupełnianiu danych wyjściowych.
W poniższym przykładzie pokazano, jak obsługiwać zdarzenia, gdy model wykryje szkodliwą zawartość w monicie wejściowym i włączono bezpieczeństwo zawartości.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are an AI assistant that helps people find information."
},
{
"role": "user",
"content": "Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills."
}
]
}
{
"error": {
"message": "The response was filtered due to the prompt triggering Microsoft's content management policy. Please modify your prompt and retry.",
"type": null,
"param": "prompt",
"code": "content_filter",
"status": 400
}
}
Napiwek
Aby dowiedzieć się więcej na temat konfigurowania i kontrolowania ustawień bezpieczeństwa zawartości usługi Azure AI, zapoznaj się z dokumentacją dotyczącą bezpieczeństwa zawartości usługi Azure AI.
Używanie uzupełniania czatu z obrazami
Niektóre modele mogą powodować między tekstem i obrazami oraz generować uzupełnienia tekstu na podstawie obu rodzajów danych wejściowych. W tej sekcji zapoznasz się z możliwościami niektórych modeli przetwarzania obrazów w sposób czatu:
Ważne
Niektóre modele obsługują tylko jeden obraz dla każdego kolei w konwersacji czatu i tylko ostatni obraz jest zachowywany w kontekście. Jeśli dodasz wiele obrazów, spowoduje to wystąpienie błędu.
Aby wyświetlić tę możliwość, pobierz obraz i zakoduj informacje jako base64 ciąg. Wynikowe dane powinny znajdować się wewnątrz adresu URL danych:
Napiwek
Należy skonstruować adres URL danych przy użyciu skryptu lub języka programowania. W tym samouczku użyto tego przykładowego obrazu w formacie JPEG. Adres URL danych ma następujący format: data:image/jpg;base64,0xABCDFGHIJKLMNOPQRSTUVWXYZ....
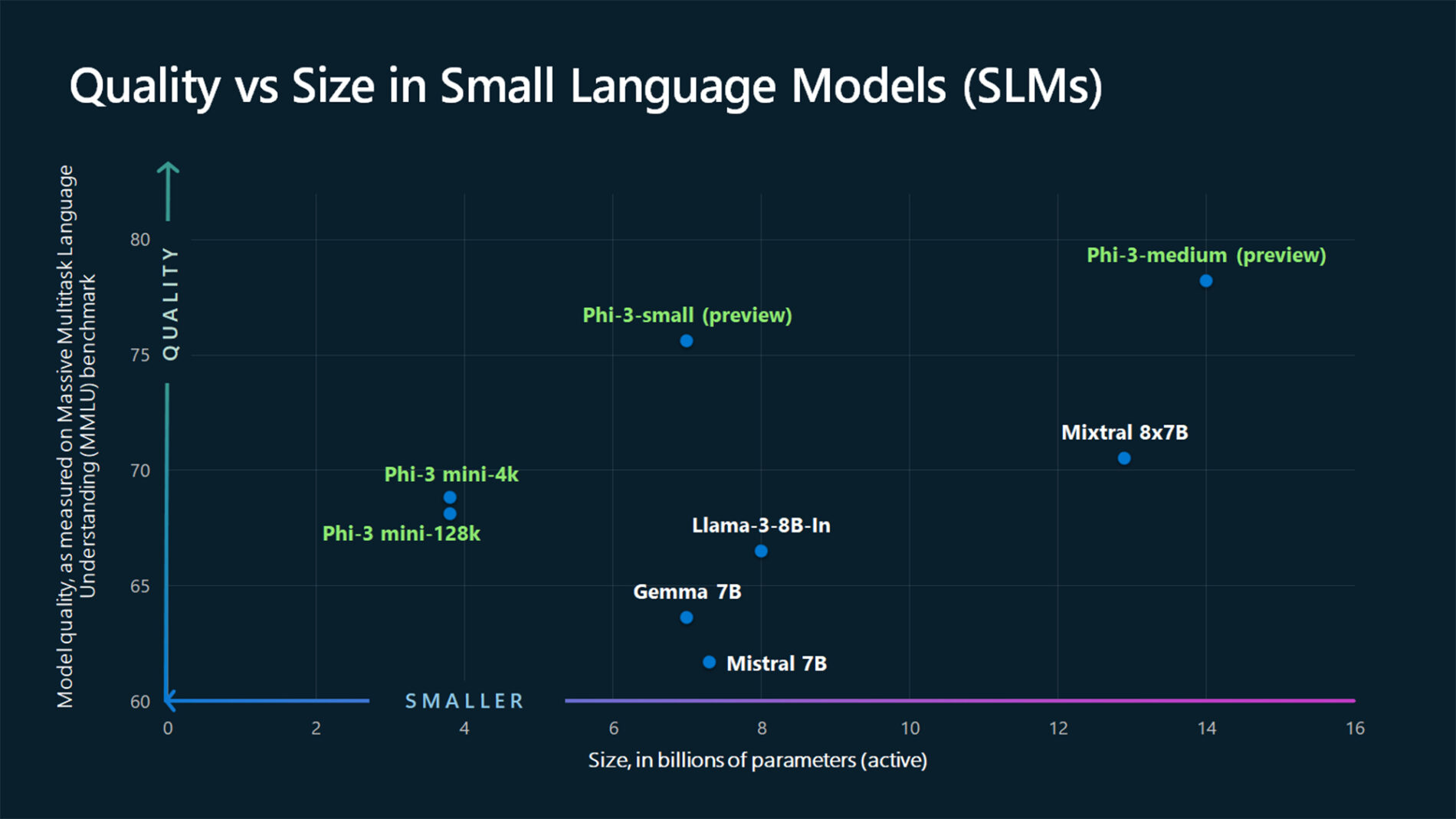{kind=link}
Wizualizowanie obrazu:
Teraz utwórz żądanie ukończenia czatu z obrazem:
{
"model": "phi-3.5-vision-instruct",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Which peculiar conclusion about LLMs and SLMs can be extracted from the following chart?"
},
{
"type": "image_url",
"image_url": {
"url": "data:image/jpg;base64,0xABCDFGHIJKLMNOPQRSTUVWXYZ..."
}
}
]
}
],
"temperature": 0,
"top_p": 1,
"max_tokens": 2048
}
Odpowiedź jest następująca, gdzie można zobaczyć statystyki użycia modelu:
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726686,
"model": "phi-3.5-vision-instruct",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 2380,
"completion_tokens": 126,
"total_tokens": 2506
}
}