Efektywne stronicowanie dużych ilości danych (C#)
Autor: Scott Mitchell
Domyślna opcja stronicowania kontrolki prezentacji danych jest nieodpowiednia podczas pracy z dużymi ilościami danych, ponieważ jego podstawowa kontrola źródła danych pobiera wszystkie rekordy, mimo że jest wyświetlany tylko podzestaw danych. W takich okolicznościach musimy zwrócić się do niestandardowego stronicowania.
Wprowadzenie
Jak omówiono w poprzednim samouczku, stronicowanie można zaimplementować na jeden z dwóch sposobów:
- Domyślne stronicowanie można zaimplementować, sprawdzając opcję Włącz stronicowanie w tagu inteligentnym kontrolki sieci Web danych. Jednak za każdym razem, gdy wyświetlasz stronę danych, źródło ObjectDataSource pobiera wszystkie rekordy, mimo że na stronie są wyświetlane tylko podzestawy.
- Niestandardowe stronicowanie zwiększa wydajność domyślnego stronicowania, pobierając tylko te rekordy z bazy danych, które muszą być wyświetlane dla konkretnej strony danych żądanych przez użytkownika; jednak niestandardowe stronicowanie wymaga nieco większego nakładu pracy na zaimplementowanie niż domyślne stronicowanie
Ze względu na łatwość implementacji wystarczy zaznaczyć pole wyboru i wszystko gotowe! domyślne stronicowanie to atrakcyjna opcja. Jego naiwne podejście w pobieraniu wszystkich rekordów, jednak sprawia, że jest to nieprawdopodobny wybór podczas stronicowania przez wystarczająco duże ilości danych lub witryn z wieloma współbieżnymi użytkownikami. W takich okolicznościach musimy zwrócić się do niestandardowego stronicowania w celu zapewnienia dynamicznego systemu.
Wyzwanie związane z niestandardowym stronicowaniem polega na możliwości zapisania zapytania zwracającego dokładny zestaw rekordów potrzebnych dla określonej strony danych. Na szczęście program Microsoft SQL Server 2005 udostępnia nowe słowo kluczowe do klasyfikowania wyników, co pozwala nam napisać zapytanie, które może efektywnie pobrać odpowiedni podzestaw rekordów. W tym samouczku zobaczymy, jak używać tego nowego słowa kluczowego programu SQL Server 2005 do implementowania niestandardowego stronicowania w kontrolce GridView. Interfejs użytkownika dla niestandardowego stronicowania jest taki sam jak w przypadku domyślnego stronicowania, ale przechodzenie z jednej strony do następnej przy użyciu niestandardowego stronicowania może być o kilka rzędów wielkości szybsze niż domyślne stronicowanie.
Uwaga
Dokładny wzrost wydajności wynikający z niestandardowego stronicowania zależy od całkowitej liczby stronicowanych rekordów oraz obciążenia umieszczanego na serwerze bazy danych. Na końcu tego samouczka przyjrzymy się niektórym szorstkim metryom, które przedstawiają korzyści wynikające z wydajności uzyskanej za pośrednictwem niestandardowego stronicowania.
Krok 1. Omówienie niestandardowego procesu stronicowania
Podczas stronicowania danych dokładne rekordy wyświetlane na stronie zależą od żądanej strony danych oraz liczby rekordów wyświetlanych na stronie. Załóżmy na przykład, że chcemy wyświetlić 81 produktów, wyświetlając 10 produktów na stronę. Podczas wyświetlania pierwszej strony chcemy, aby produkty od 1 do 10; podczas przeglądania drugiej strony bylibyśmy zainteresowani produktami od 11 do 20 itd.
Istnieją trzy zmienne, które określają, jakie rekordy należy pobrać, oraz sposób renderowania interfejsu stronicowania:
- Indeks wiersza początkowego indeks pierwszego wiersza na stronie danych do wyświetlenia. Ten indeks można obliczyć przez pomnożenie indeksu strony przez rekordy w celu wyświetlenia poszczególnych stron i dodanie go. Na przykład w przypadku stronicowania rekordów 10 naraz dla pierwszej strony (której indeks strony wynosi 0), indeks początkowy wiersza wynosi 0 * 10 + 1 lub 1; dla drugiej strony (której indeks strony to 1), indeks wiersza początkowego to 1 * 10 + 1 lub 11.
- Maksymalna liczba wierszy maksymalna liczba rekordów do wyświetlenia na stronę. Ta zmienna jest określana jako maksymalna liczba wierszy, ponieważ dla ostatniej strony może być mniej rekordów zwracanych niż rozmiar strony. Na przykład w przypadku stronicowania za pośrednictwem 81 produktów 10 rekordów na stronę dziewiąta i końcowa strona będzie zawierać tylko jeden rekord. Żadna strona nie będzie jednak wyświetlać większej liczby rekordów niż wartość Maksymalna liczba wierszy.
- Total Record Count the total number of records being paged through (Łączna liczba rekordów, przez które są stronicowane). Chociaż ta zmienna nie jest potrzebna do określenia, jakie rekordy mają być pobierane dla danej strony, określa interfejs stronicowania. Jeśli na przykład w interfejsie stronicowania jest wyświetlanych 81 produktów, interfejs stronicowania wie, że wyświetla dziewięć numerów stron w interfejsie użytkownika stronicowania.
W przypadku domyślnego stronicowania indeks wiersza początkowego jest obliczany jako produkt indeksu strony i rozmiar strony oraz jeden, natomiast maksymalny rozmiar wierszy jest po prostu rozmiarem strony. Ponieważ domyślne stronicowanie pobiera wszystkie rekordy z bazy danych podczas renderowania dowolnej strony danych, indeks dla każdego wiersza jest znany, co powoduje przejście do wiersza indeksu wierszy początkowych jako proste zadanie. Ponadto łączna liczba rekordów jest łatwo dostępna, ponieważ jest to po prostu liczba rekordów w tabeli DataTable (lub dowolny obiekt używany do przechowywania wyników bazy danych).
Biorąc pod uwagę zmienne Indeks wiersza początkowego i Maksymalna liczba wierszy, niestandardowa implementacja stronicowania musi zwracać tylko dokładny podzbiór rekordów rozpoczynających się od indeksu wiersza początkowego i maksymalnie maksymalną liczbę wierszy po tym. Stronicowanie niestandardowe zapewnia dwa wyzwania:
- Musimy być w stanie efektywnie skojarzyć indeks wiersza z każdym wierszem w całych danych, które są stronicowane, aby można było rozpocząć zwracanie rekordów w określonym indeksie wierszy początkowych
- Musimy podać łączną liczbę stronicowanych rekordów
W następnych dwóch krokach przeanalizujemy skrypt SQL potrzebny do reagowania na te dwa wyzwania. Oprócz skryptu SQL będziemy również musieli zaimplementować metody w dal i BLL.
Krok 2. Zwracanie całkowitej liczby stronicowanych rekordów
Zanim sprawdzimy, jak pobrać dokładny podzbiór rekordów dla wyświetlanej strony, najpierw przyjrzyjmy się, jak zwrócić łączną liczbę stronicowanych rekordów. Te informacje są potrzebne w celu prawidłowego skonfigurowania interfejsu użytkownika stronicowania. Łączna liczba rekordów zwracanych przez określone zapytanie SQL można uzyskać przy użyciu COUNT funkcji agregującej. Aby na przykład określić łączną liczbę rekordów w Products tabeli, możemy użyć następującego zapytania:
SELECT COUNT(*)
FROM Products
Dodajmy metodę do naszego dal, która zwraca te informacje. W szczególności utworzymy metodę DAL o nazwie TotalNumberOfProducts() , która wykonuje instrukcję pokazaną SELECT powyżej.
Rozpocznij od otwarcia Northwind.xsd pliku Typed DataSet w folderze App_Code/DAL . Następnie kliknij prawym przyciskiem myszy ikonę ProductsTableAdapter w Projektancie i wybierz polecenie Dodaj zapytanie. Jak widzieliśmy w poprzednich samouczkach, umożliwi to dodanie nowej metody do dal, która po wywołaniu wykona określoną instrukcję SQL lub procedurę składowaną. Podobnie jak w przypadku naszych metod TableAdapter w poprzednich samouczkach, w tym przypadku należy użyć instrukcji ad hoc JĘZYKA SQL.
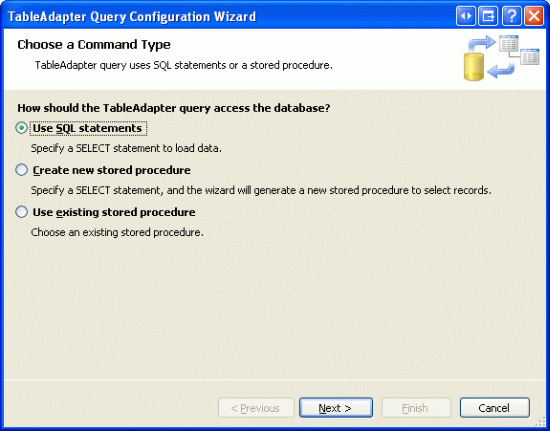
Rysunek 1. Używanie instrukcji SQL ad hoc
Na następnym ekranie możemy określić typ zapytania do utworzenia. Ponieważ to zapytanie zwróci pojedynczą wartość skalarną całkowitą liczbę rekordów w Products tabeli, wybierz SELECT opcję, która zwraca wartość singe.
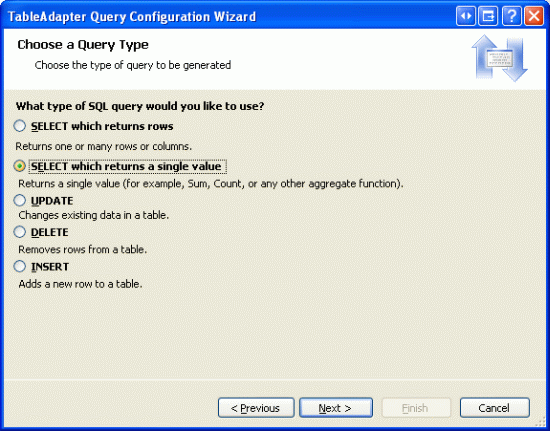
Rysunek 2. Konfigurowanie zapytania w celu używania instrukcji SELECT zwracającej pojedynczą wartość
Po wskazaniu typu zapytania do użycia musimy następnie określić zapytanie.
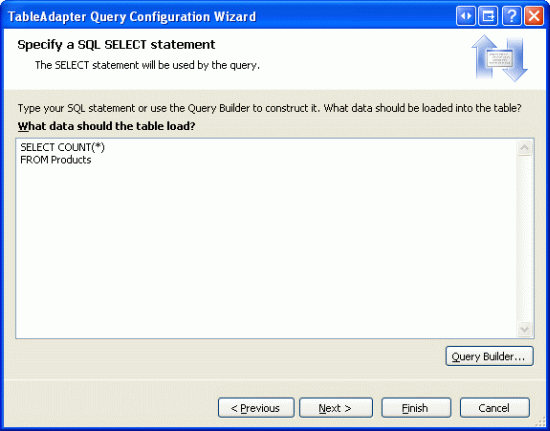
Rysunek 3. Używanie zapytania SELECT COUNT(*) FROM Products
Na koniec określ nazwę metody . Jak wspomniano powyżej, użyjmy polecenia TotalNumberOfProducts.
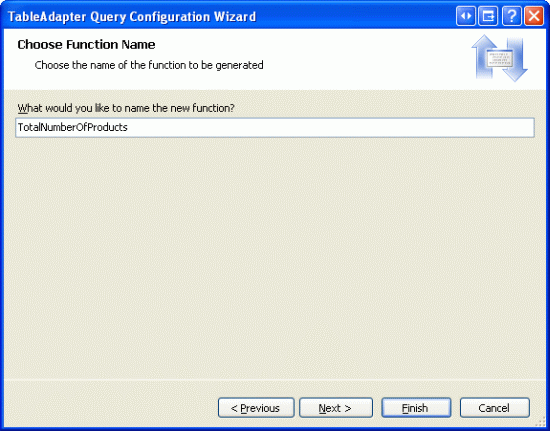
Rysunek 4. Nadaj metodzie DAL nazwę TotalNumberOfProducts
Po kliknięciu przycisku Zakończ kreator doda metodę TotalNumberOfProducts do dal. Metody zwracane przez skalarne w regionie DAL zwracają typy dopuszczające wartość null, jeśli wynikiem zapytania SQL jest NULL. Nasze COUNT zapytanie zawsze zwraca jednak wartość innąNULL niż wartość, niezależnie od tego, metoda DAL zwraca liczbę całkowitą dopuszczaną do wartości null.
Oprócz metody DAL potrzebujemy również metody w usłudze BLL. ProductsBLL Otwórz plik klasy i dodaj metodę, która po prostu wywołuje metodę TotalNumberOfProducts DAL TotalNumberOfProducts w dół:
public int TotalNumberOfProducts()
{
return Adapter.TotalNumberOfProducts().GetValueOrDefault();
}
Metoda dal s TotalNumberOfProducts zwraca liczbę całkowitą dopuszczającą wartość null, jednak utworzyliśmy ProductsBLL metodę s klasy, TotalNumberOfProducts aby zwracała standardową liczbę całkowitą. W związku z tym musimy mieć metodę ProductsBLL klasy s TotalNumberOfProducts zwracającą część wartości liczby całkowitej dopuszczanej do wartości null zwróconej przez metodę DAL.TotalNumberOfProducts Wywołanie metody zwraca GetValueOrDefault() wartość liczby całkowitej dopuszczalnej wartości null, jeśli istnieje. Jeśli liczba całkowita dopuszczana do wartości null to null, zwraca jednak domyślną wartość całkowitą, 0.
Krok 3. Zwracanie dokładnego podzestawu rekordów
Następnym zadaniem jest utworzenie metod w dal i BLL, które akceptują zmienne Indeks wiersza początkowego i Maksymalne wiersze omówione wcześniej i zwracają odpowiednie rekordy. Zanim to zrobimy, najpierw przyjrzyjmy się potrzebnego skryptu SQL. Wyzwaniem, przed którym stoimy, jest to, że musimy mieć możliwość efektywnego przypisania indeksu do każdego wiersza w całych wynikach, dzięki czemu możemy zwrócić tylko te rekordy rozpoczynające się od indeksu wierszy początkowych (i maksymalną liczbę rekordów).
Nie jest to wyzwanie, jeśli w tabeli bazy danych znajduje się już kolumna, która służy jako indeks wiersza. Na pierwszy rzut oka możemy pomyśleć, że Products pole tabeli ProductID wystarczy, ponieważ pierwszy produkt ma ProductID wartość 1, drugi 2 itd. Jednak usunięcie produktu pozostawia lukę w sekwencji, unieważniając to podejście.
Istnieją dwie ogólne techniki służące do efektywnego kojarzenia indeksu wierszy z danymi do stronicowania, dzięki czemu można pobrać dokładny podzbiór rekordów:
Korzystając z nowego słowa kluczowego programu SQL Server 2005 w programie SQL Server 2005
ROW_NUMBER(),ROW_NUMBER()słowo kluczowe kojarzy klasyfikację z każdym zwróconym rekordem w oparciu o kolejność. Tej klasyfikacji można użyć jako indeksu wierszy dla każdego wiersza.Za pomocą zmiennej tabeli i
SET ROWCOUNTinstrukcji programuSET ROWCOUNTSQL Server można określić, ile sum rekordów ma przetwarzać zapytanie przed zakończeniem; zmienne tabeli to lokalne zmienne języka T-SQL, które mogą przechowywać dane tabelaryczne, czyli tabele tymczasowe. Takie podejście działa równie dobrze zarówno w przypadku programów Microsoft SQL Server 2005, jak i SQL Server 2000 (natomiastROW_NUMBER()podejście działa tylko z programem SQL Server 2005).Chodzi o utworzenie zmiennej tabeli, która zawiera kolumnę
IDENTITYi kolumny dla kluczy podstawowych tabeli, których dane są stronicowane. Następnie zawartość tabeli, której dane są stronicowane, jest po cenach dumpingowych do zmiennej tabeli, co powoduje skojarzenie sekwencyjnego indeksu wierszy (za pośrednictwemIDENTITYkolumny) dla każdego rekordu w tabeli. Po wypełnieniu zmiennej tabeli można wykonać instrukcję w zmiennej tabeli połączonej z tabelą bazową, aby ściągnąćSELECTokreślone rekordy. InstrukcjaSET ROWCOUNTsłuży do inteligentnego ograniczania liczby rekordów, które muszą być po cenach dumpingowych do zmiennej tabeli.Ta wydajność podejścia jest oparta na żądanym numerze strony, ponieważ
SET ROWCOUNTwartość jest przypisana do wartości Indeksu wiersza początkowego oraz maksymalnej liczby wierszy. Podczas stronicowania za pośrednictwem stron z małą liczbą, takich jak pierwsze kilka stron danych, takie podejście jest bardzo wydajne. Jednak podczas pobierania strony w pobliżu końca występuje domyślna wydajność przypominająca stronicowanie.
Ten samouczek implementuje niestandardowe stronicowanie przy użyciu słowa kluczowego ROW_NUMBER() . Aby uzyskać więcej informacji na temat używania zmiennej tabeli i SET ROWCOUNT techniki, zobacz Efektywne stronicowanie za pośrednictwem dużych ilości danych.
Słowo ROW_NUMBER() kluczowe skojarzyło klasyfikację z każdym rekordem zwróconym w określonej kolejności przy użyciu następującej składni:
SELECT columnList,
ROW_NUMBER() OVER(orderByClause)
FROM TableName
ROW_NUMBER() Zwraca wartość liczbową określającą rangę dla każdego rekordu w odniesieniu do wskazanej kolejności. Aby na przykład zobaczyć rangę dla każdego produktu uporządkowanego od najdroższego do najmniejszego, możemy użyć następującego zapytania:
SELECT ProductName, UnitPrice,
ROW_NUMBER() OVER(ORDER BY UnitPrice DESC) AS PriceRank
FROM Products
Rysunek 5 przedstawia wyniki zapytania po uruchomieniu okna zapytania w programie Visual Studio. Należy pamiętać, że produkty są uporządkowane według ceny wraz z klasyfikacją cen dla każdego wiersza.
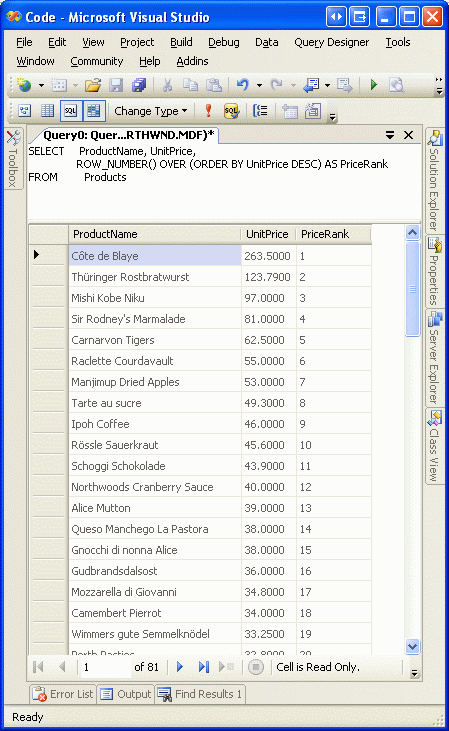
Rysunek 5. Pozycja ceny jest uwzględniona dla każdego zwróconego rekordu
Uwaga
ROW_NUMBER() jest tylko jedną z wielu nowych funkcji klasyfikacji dostępnych w programie SQL Server 2005. Aby zapoznać się z bardziej szczegółowym omówieniem funkcji ROW_NUMBER(), wraz z innymi funkcjami klasyfikacji, przeczytaj Artykuł Returning Ranked Results with Microsoft SQL Server 2005 (Zwracanie wyników rankingowych za pomocą programu Microsoft SQL Server 2005).
Podczas klasyfikowania wyników według określonej ORDER BY kolumny w OVER klauzuli (UnitPricew powyższym przykładzie) program SQL Server musi sortować wyniki. Jest to szybka operacja, jeśli istnieje indeks klastrowany w kolumnach, według których wyniki są uporządkowane, lub jeśli istnieje indeks obejmujący, ale może być bardziej kosztowny w przeciwnym razie. Aby zwiększyć wydajność dla wystarczająco dużych zapytań, rozważ dodanie indeksu nieklasowanego dla kolumny, według której wyniki są uporządkowane według. Zobacz Ranking Functions and Performance in SQL Server 2005 (Funkcje klasyfikowania i wydajność w programie SQL Server 2005 ), aby uzyskać bardziej szczegółowe informacje na temat zagadnień dotyczących wydajności.
Informacje o klasyfikacji zwracane przez ROW_NUMBER() program nie mogą być bezpośrednio używane w klauzuli WHERE . Można jednak użyć tabeli pochodnej ROW_NUMBER() , aby zwrócić wynik, który następnie może pojawić się w klauzuli WHERE . Na przykład następujące zapytanie używa tabeli pochodnej, aby zwrócić kolumny ProductName i UnitPrice wraz z ROW_NUMBER() wynikiem, a następnie używa WHERE klauzuli , aby zwrócić tylko te produkty, których ranga cenowa wynosi od 11 do 20:
SELECT PriceRank, ProductName, UnitPrice
FROM
(SELECT ProductName, UnitPrice,
ROW_NUMBER() OVER(ORDER BY UnitPrice DESC) AS PriceRank
FROM Products
) AS ProductsWithRowNumber
WHERE PriceRank BETWEEN 11 AND 20
Rozszerzenie tej koncepcji nieco dalej, możemy użyć tej metody, aby pobrać określoną stronę danych, biorąc pod uwagę żądane wartości Indeks wiersza początkowego i Maksymalna liczba wierszy:
SELECT PriceRank, ProductName, UnitPrice
FROM
(SELECT ProductName, UnitPrice,
ROW_NUMBER() OVER(ORDER BY UnitPrice DESC) AS PriceRank
FROM Products
) AS ProductsWithRowNumber
WHERE PriceRank > <i>StartRowIndex</i> AND
PriceRank <= (<i>StartRowIndex</i> + <i>MaximumRows</i>)
Uwaga
Jak zobaczymy w dalszej części tego samouczka, StartRowIndex indeks dostarczony przez obiekt ObjectDataSource jest indeksowany od zera, natomiast ROW_NUMBER() wartość zwracana przez program SQL Server 2005 jest indeksowana od 1. W związku z tym klauzula WHERE zwraca te rekordy, w których PriceRank wartość jest ściśle większa niż i mniejsza niż StartRowIndex lub równa StartRowIndex + MaximumRows.
Teraz, gdy już omówiliśmy, jak ROW_NUMBER() można użyć do pobrania określonej strony danych, biorąc pod uwagę wartości indeksu wierszy początkowych i maksymalnych wierszy, musimy teraz zaimplementować tę logikę jako metody w dal i BLL.
Podczas tworzenia tego zapytania musimy zdecydować o kolejności, według której będą klasyfikowane wyniki; posortujmy produkty według ich nazwy w kolejności alfabetycznej. Oznacza to, że w przypadku niestandardowej implementacji stronicowania w tym samouczku nie będzie można utworzyć niestandardowego raportu stronicowanego, niż można również sortować. W następnym samouczku zobaczymy jednak, jak można udostępnić takie funkcje.
W poprzedniej sekcji utworzyliśmy metodę DAL jako instrukcję ad hoc języka SQL. Niestety analizator języka T-SQL w programie Visual Studio używany przez kreatora TableAdapter nie lubi OVER składni używanej ROW_NUMBER() przez funkcję. W związku z tym musimy utworzyć tę metodę DAL jako procedurę składowaną. Wybierz Eksploratora serwera z menu Widok (lub naciśnij Ctrl+Alt+S) i rozwiń NORTHWND.MDF węzeł. Aby dodać nową procedurę składowaną, kliknij prawym przyciskiem myszy węzeł Procedury składowane i wybierz polecenie Dodaj nową procedurę składowaną (zobacz Rysunek 6).
Rysunek 6. Dodawanie nowej procedury składowanej na potrzeby stronicowania za pośrednictwem produktów
Ta procedura składowana powinna akceptować dwa parametry wejściowe liczby całkowitej — @startRowIndex i używać ROW_NUMBER() funkcji uporządkowanej ProductName przez pole, zwracając tylko te wiersze większe niż określone @startRowIndex i mniejsze lub równe @startRowIndex + @maximumRow s.@maximumRows Wprowadź następujący skrypt w nowej procedurze składowanej, a następnie kliknij ikonę Zapisz, aby dodać procedurę składowaną do bazy danych.
CREATE PROCEDURE dbo.GetProductsPaged
(
@startRowIndex int,
@maximumRows int
)
AS
SELECT ProductID, ProductName, SupplierID, CategoryID, QuantityPerUnit,
UnitPrice, UnitsInStock, UnitsOnOrder, ReorderLevel, Discontinued,
CategoryName, SupplierName
FROM
(
SELECT ProductID, ProductName, SupplierID, CategoryID, QuantityPerUnit,
UnitPrice, UnitsInStock, UnitsOnOrder, ReorderLevel, Discontinued,
(SELECT CategoryName
FROM Categories
WHERE Categories.CategoryID = Products.CategoryID) AS CategoryName,
(SELECT CompanyName
FROM Suppliers
WHERE Suppliers.SupplierID = Products.SupplierID) AS SupplierName,
ROW_NUMBER() OVER (ORDER BY ProductName) AS RowRank
FROM Products
) AS ProductsWithRowNumbers
WHERE RowRank > @startRowIndex AND RowRank <= (@startRowIndex + @maximumRows)
Po utworzeniu procedury składowanej pośmiń chwilę na jego przetestowanie. Kliknij prawym przyciskiem myszy GetProductsPaged nazwę procedury składowanej w Eksploratorze serwera i wybierz opcję Wykonaj. Program Visual Studio wyświetli monit o podanie parametrów @startRowIndex wejściowych i @maximumRow s (zobacz Rysunek 7). Spróbuj użyć różnych wartości i sprawdź wyniki.
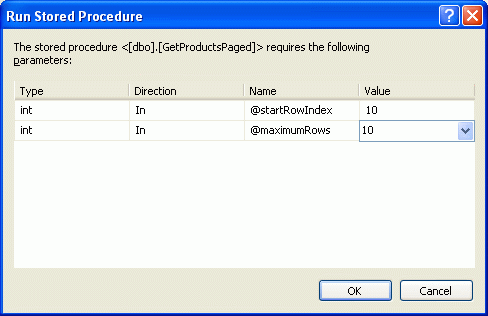 @startRowIndex i @maximumRows parametry" />
@startRowIndex i @maximumRows parametry" />
Rysunek 7. Wprowadź wartość parametrów @startRowIndex i @maximumRows
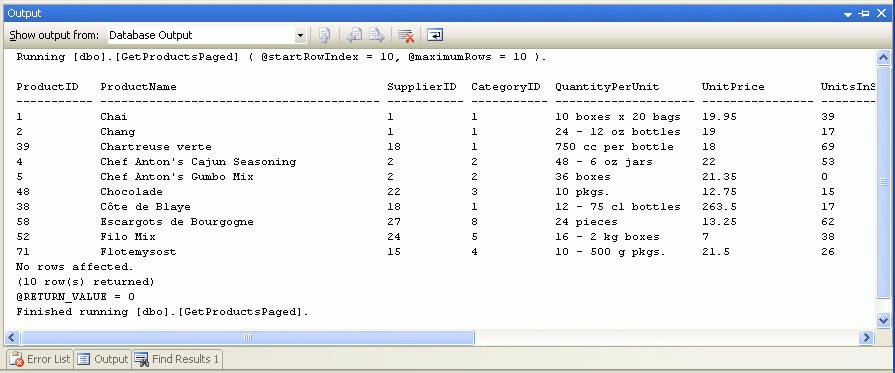
Po wybraniu tych wartości parametrów wejściowych w oknie Dane wyjściowe zostaną wyświetlone wyniki. Rysunek 8 przedstawia wyniki podczas przekazywania wartości 10 dla parametrów @startRowIndex i @maximumRows .
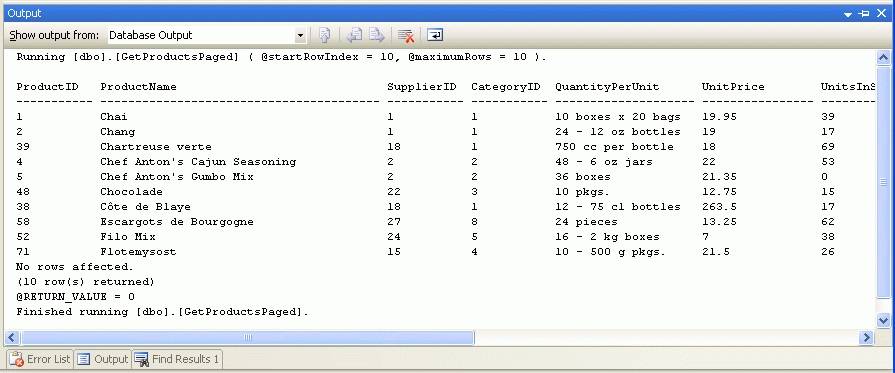
Rysunek 8. Zwracane są rekordy wyświetlane na drugiej stronie danych (kliknij, aby wyświetlić obraz pełnowymiarowy)
{kind=link}
Po utworzeniu tej procedury składowanej możemy utworzyć metodę ProductsTableAdapter . Otwórz typowy Northwind.xsd zestaw danych, kliknij prawym przyciskiem myszy ProductsTableAdapterelement , a następnie wybierz opcję Dodaj zapytanie. Zamiast tworzyć zapytanie przy użyciu instrukcji ad hoc SQL, utwórz ją przy użyciu istniejącej procedury składowanej.
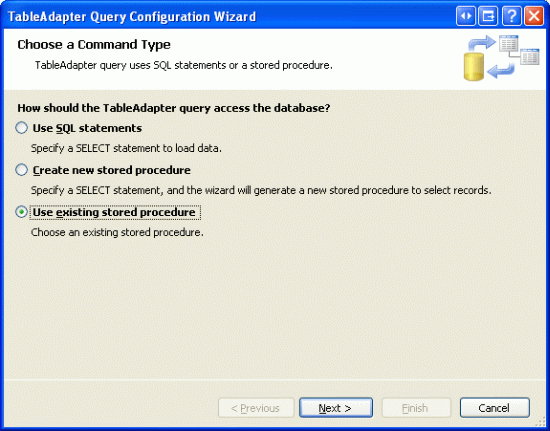
Rysunek 9. Tworzenie metody DAL przy użyciu istniejącej procedury składowanej
Następnie zostanie wyświetlony monit o wybranie procedury składowanej do wywołania. Wybierz procedurę GetProductsPaged składowaną z listy rozwijanej.
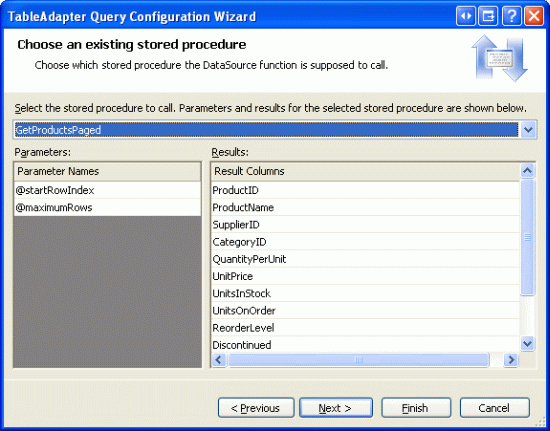
Rysunek 10. Wybierz procedurę składowaną GetProductsPaged z listy rozwijanej
Na następnym ekranie zostanie wyświetlony monit o rodzaj danych zwracanych przez procedurę składowaną: dane tabelaryczne, pojedynczą wartość lub brak wartości. GetProductsPaged Ponieważ procedura składowana może zwracać wiele rekordów, wskazuje, że zwraca dane tabelaryczne.
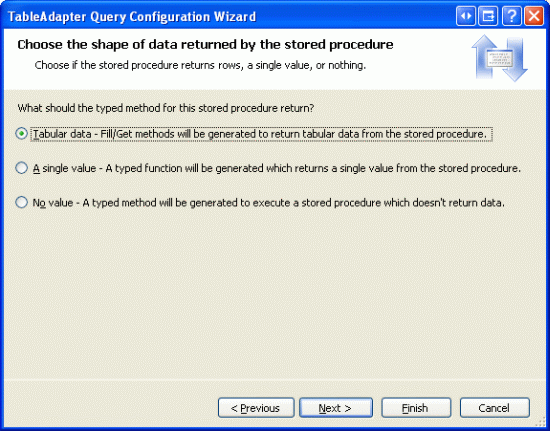
Rysunek 11. Wskazuje, że procedura składowana zwraca dane tabelaryczne
Na koniec wskaż nazwy metod, które chcesz utworzyć. Podobnie jak w przypadku naszych poprzednich samouczków, utwórz metody przy użyciu tabeli Fill a DataTable i Return a DataTable. Nadaj pierwszej metodzie FillPaged nazwę i drugą GetProductsPagedmetodę .
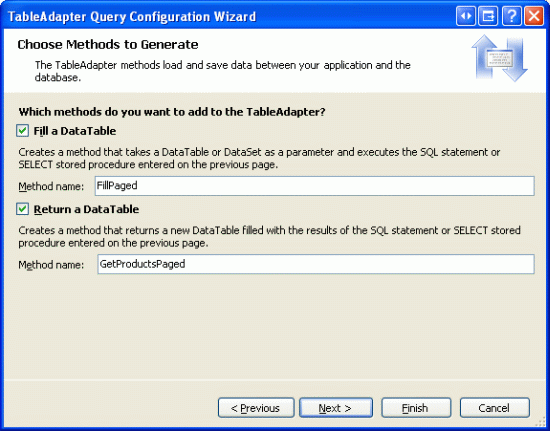
Rysunek 12. Nazwij metody FillPaged i GetProductsPaged
Oprócz utworzenia metody DAL, aby zwrócić określoną stronę produktów, musimy również zapewnić takie funkcje w usłudze BLL. Podobnie jak w przypadku metody DAL, metoda GetProductsPaged BLL musi akceptować dwa dane wejściowe liczb całkowitych do określania indeksu wiersza początkowego i maksymalne wiersze i muszą zwracać tylko te rekordy, które należą do określonego zakresu. Utwórz taką metodę BLL w klasie ProductsBLL, która wywołuje metodę DAL s GetProductsPaged w następujący sposób:
[System.ComponentModel.DataObjectMethodAttribute(
System.ComponentModel.DataObjectMethodType.Select, false)]
public Northwind.ProductsDataTable GetProductsPaged(int startRowIndex, int maximumRows)
{
return Adapter.GetProductsPaged(startRowIndex, maximumRows);
}
Możesz użyć dowolnej nazwy parametrów wejściowych metody BLL, ale jak wkrótce zobaczymy, wybierając opcję użycia startRowIndex i maximumRows zapisując nas z dodatkowego fragmentu pracy podczas konfigurowania obiektu ObjectDataSource do użycia tej metody.
Krok 4. Konfigurowanie obiektu ObjectDataSource do używania niestandardowego stronicowania
Korzystając z metod BLL i DAL na potrzeby uzyskiwania dostępu do określonego podzestawu rekordów, możemy utworzyć kontrolkę GridView, która umożliwia tworzenie kontrolki GridView na stronach za pomocą jego rekordów bazowych przy użyciu niestandardowego stronicowania. Zacznij od otwarcia EfficientPaging.aspx strony w folderze PagingAndSorting , dodania kontrolki GridView do strony i skonfigurowania jej tak, aby korzystała z nowej kontrolki ObjectDataSource. W poprzednich samouczkach często używaliśmy metody ObjectDataSource skonfigurowanej do używania ProductsBLL metody s GetProducts klasy. Tym razem jednak chcemy użyć GetProductsPaged metody , ponieważ GetProducts metoda zwraca wszystkie produkty w bazie danych, natomiast GetProductsPaged zwraca tylko określony podzestaw rekordów.
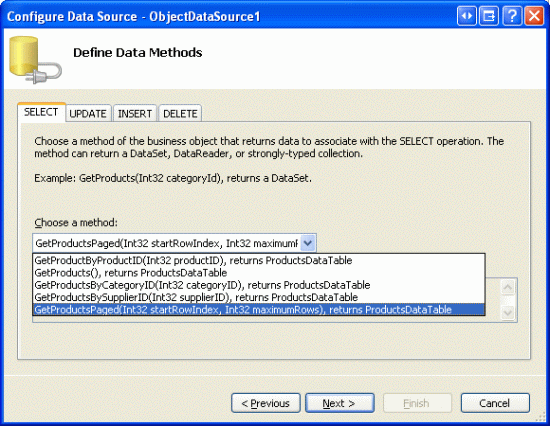
Rysunek 13. Konfigurowanie obiektu ObjectDataSource do używania metody GetProductsPaged klasy ProductsBLL
Ponieważ tworzysz obiekt GridView tylko do odczytu, pośmiń chwilę, aby ustawić listę rozwijaną metody na kartach INSERT, UPDATE i DELETE na wartość (Brak).
Następnie kreator ObjectDataSource wyświetli monit o podanie źródeł wartości parametrów wejściowych GetProductsPaged i maximumRows metodstartRowIndex. Te parametry wejściowe zostaną ustawione automatycznie przez kontrolkę GridView, więc po prostu pozostaw źródło ustawione na Wartość Brak i kliknij przycisk Zakończ.
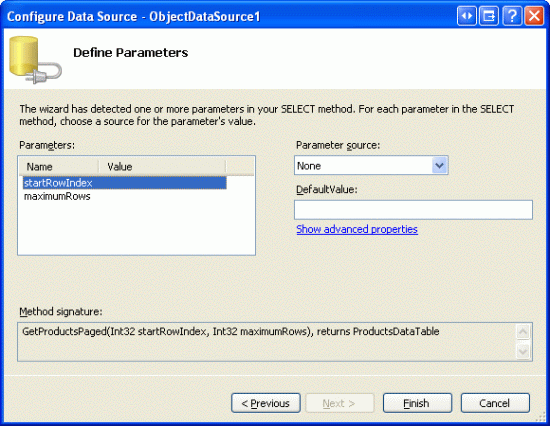
Rysunek 14. Pozostaw źródła parametrów wejściowych jako Brak
Po ukończeniu pracy kreatora ObjectDataSource kontrolka GridView będzie zawierać pole BoundField lub CheckBoxField dla każdego pola danych produktu. Możesz dostosować wygląd kontrolki GridView w miarę dopasowania. Zdecydowałem się wyświetlić tylko ProductName, , CategoryNameSupplierName, QuantityPerUnit, i UnitPrice BoundFields. Ponadto skonfiguruj kontrolkę GridView tak, aby obsługiwała stronicowanie, zaznaczając pole wyboru Włącz stronicowanie w tagu inteligentnym. Po tych zmianach znacznik deklaratywny GridView i ObjectDataSource powinien wyglądać podobnie do następującego:
<asp:GridView ID="GridView1" runat="server" AutoGenerateColumns="False"
DataKeyNames="ProductID" DataSourceID="ObjectDataSource1" AllowPaging="True">
<Columns>
<asp:BoundField DataField="ProductName" HeaderText="Product"
SortExpression="ProductName" />
<asp:BoundField DataField="CategoryName" HeaderText="Category"
ReadOnly="True" SortExpression="CategoryName" />
<asp:BoundField DataField="SupplierName" HeaderText="Supplier"
SortExpression="SupplierName" />
<asp:BoundField DataField="QuantityPerUnit" HeaderText="Qty/Unit"
SortExpression="QuantityPerUnit" />
<asp:BoundField DataField="UnitPrice" DataFormatString="{0:c}"
HeaderText="Price" HtmlEncode="False" SortExpression="UnitPrice" />
</Columns>
</asp:GridView>
<asp:ObjectDataSource ID="ObjectDataSource1" runat="server"
OldValuesParameterFormatString="original_{0}" SelectMethod="GetProductsPaged"
TypeName="ProductsBLL">
<SelectParameters>
<asp:Parameter Name="startRowIndex" Type="Int32" />
<asp:Parameter Name="maximumRows" Type="Int32" />
</SelectParameters>
</asp:ObjectDataSource>
Jeśli jednak odwiedzasz stronę za pośrednictwem przeglądarki, element GridView nie znajduje się tam, gdzie można go znaleźć.
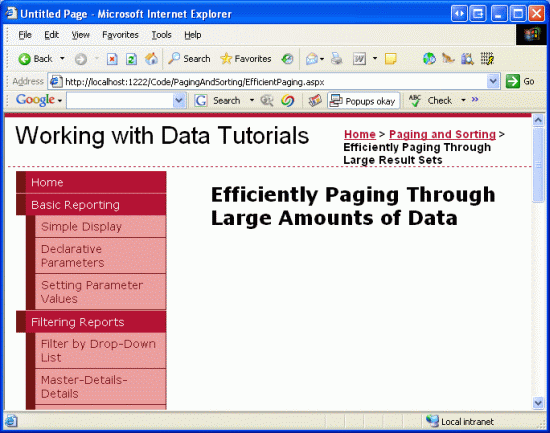
Rysunek 15. Kontrolka GridView nie jest wyświetlana
Brak kontrolki GridView, ponieważ element ObjectDataSource obecnie używa wartości 0 jako wartości parametrów wejściowych GetProductsPaged startRowIndex i .maximumRows W związku z tym wynikowe zapytanie SQL nie zwraca żadnych rekordów i dlatego kontrolka GridView nie jest wyświetlana.
Aby rozwiązać ten problem, należy skonfigurować obiekt ObjectDataSource do używania niestandardowego stronicowania. Można to zrobić w następujących krokach:
- Ustaw właściwość ObjectDataSource
EnablePagingnatruewartość wskazującą obiekt ObjectDataSource, który musi zostać przekazany doSelectMethoddwóch dodatkowych parametrów: jeden, aby określić indeks wiersza początkowego (StartRowIndexParameterName) i jeden, aby określić maksymalną liczbę wierszy (MaximumRowsParameterName). - Ustaw właściwości i ObjectDataSource odpowiednio
StartRowIndexParameterNamewłaściwości iMaximumRowsParameterNameStartRowIndexParameterNameMaximumRowsParameterNamewskazują nazwy parametrów wejściowych przekazanych doSelectMethodobiektu w celach niestandardowych stronicowania. Domyślnie te nazwy parametrów tostartIndexRowimaximumRows, dlatego podczas tworzeniaGetProductsPagedmetody w usłudze BLL użyto tych wartości dla parametrów wejściowych. Jeśli zdecydujesz się używać różnych nazw parametrów dla metody BLL,GetProductsPagedtakiej jakstartIndeximaxRows, na przykład należy ustawić właściwości ObjectDataSource iMaximumRowsParameterNameStartRowIndexParameterNameodpowiednio (na przykład startIndex dlaStartRowIndexParameterNamei maxRows dlaMaximumRowsParameterName). - Ustaw właściwość ObjectDataSource na nazwę metody, która zwraca łączną liczbę rekordów stronicowanych za pośrednictwem (
TotalNumberOfProducts), pamiętaj, żeProductsBLLmetoda klasySelectCountMethodTotalNumberOfProductszwraca całkowitą liczbę rekordów, które są stronicowane przy użyciu metody DAL, która wykonujeSELECT COUNT(*) FROM Productszapytanie. Te informacje są potrzebne przez obiekt ObjectDataSource w celu poprawnego renderowania interfejsu stronicowania. startRowIndexUsuń elementy imaximumRows<asp:Parameter>z znaczników deklaratywnego objectDataSource podczas konfigurowania obiektu ObjectDataSource za pomocą kreatora, program Visual Studio automatycznie dodał dwa<asp:Parameter>elementy dlaGetProductsPagedparametrów wejściowych metody. Po ustawieniu wartościEnablePagingtrueparametrów te zostaną przekazane automatycznie. Jeśli będą one również wyświetlane w składni deklaratywnej, obiekt ObjectDataSource podejmie próbę przekazania czterech parametrów doGetProductsPagedmetody i dwóch parametrów doTotalNumberOfProductsmetody. Jeśli zapomnisz usunąć te<asp:Parameter>elementy, podczas odwiedzania strony za pośrednictwem przeglądarki zostanie wyświetlony komunikat o błędzie, taki jak: ObjectDataSource 'ObjectDataSource1' nie może odnaleźć metody innej niż ogólna "TotalNumberOfProducts", która ma parametry: startRowIndex, maximumRows.
Po wprowadzeniu tych zmian składnia deklaratywna obiektu ObjectDataSource powinna wyglądać następująco:
<asp:ObjectDataSource ID="ObjectDataSource1" runat="server"
OldValuesParameterFormatString="original_{0}" TypeName="ProductsBLL"
SelectMethod="GetProductsPaged" EnablePaging="True"
SelectCountMethod="TotalNumberOfProducts">
</asp:ObjectDataSource>
Należy pamiętać, że EnablePaging właściwości i SelectCountMethod zostały ustawione, a <asp:Parameter> elementy zostały usunięte. Rysunek 16 przedstawia zrzut ekranu okno Właściwości po wprowadzeniu tych zmian.

Rysunek 16. Aby użyć niestandardowego stronicowania, skonfiguruj kontrolkę ObjectDataSource
Po wprowadzeniu tych zmian odwiedź tę stronę za pośrednictwem przeglądarki. Powinien zostać wyświetlonych 10 produktów uporządkowanych alfabetycznie. Pośmiń chwilę, aby przejść przez jedną stronę danych naraz. Chociaż nie ma żadnej różnicy wizualnej z perspektywy użytkownika końcowego między domyślnym stronicowaniem a niestandardowym stronicowaniem, niestandardowe stronicowanie stron jest wydajniejsze za pośrednictwem dużych ilości danych, ponieważ pobiera tylko te rekordy, które muszą być wyświetlane dla danej strony.
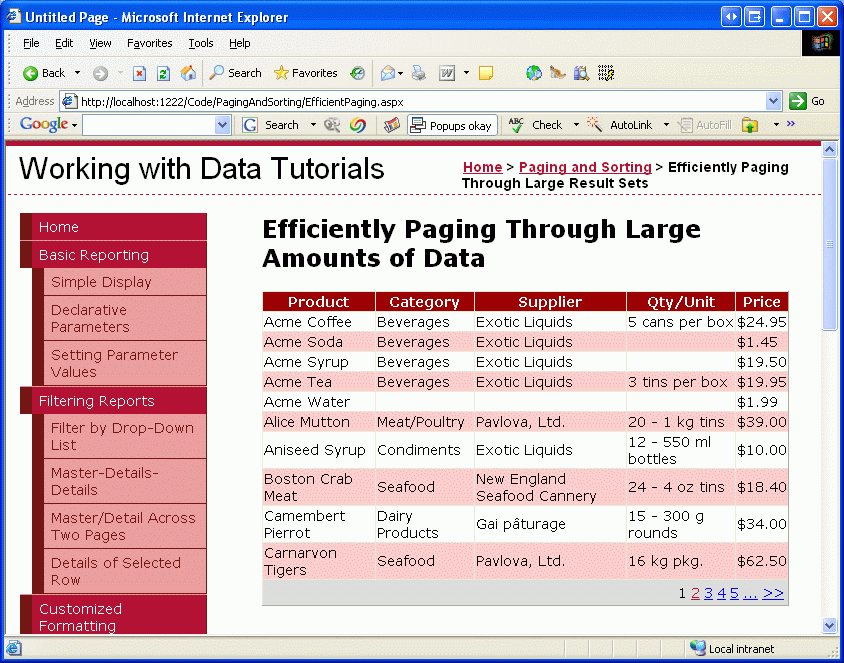
Rysunek 17. Dane uporządkowane według nazwy produktu są stronicowane przy użyciu niestandardowego stronicowania (kliknij, aby wyświetlić obraz pełnowymiarowy)
{kind=link}
Uwaga
W przypadku stronicowania niestandardowego wartość liczby stron zwracana przez obiekt ObjectDataSource SelectCountMethod jest przechowywana w stanie widoku gridView. Inne zmienne PageIndexGridView , EditIndex, DataKeys SelectedIndex, kolekcja itd. są przechowywane w stanie sterowania, który jest utrwalany niezależnie od wartości właściwości GridViewEnableViewState. PageCount Ponieważ wartość jest utrwalana w ramach ogłaszania zwrotnego przy użyciu stanu widoku, w przypadku korzystania z interfejsu stronicowania zawierającego link umożliwiający przejście do ostatniej strony, konieczne jest włączenie stanu widoku kontrolki GridView. (Jeśli interfejs stronicowania nie zawiera bezpośredniego linku do ostatniej strony, możesz wyłączyć stan wyświetlania).
Kliknięcie linku ostatniej strony powoduje powrót i powoduje, że kontrolka GridView zaktualizuje jej PageIndex właściwość. Jeśli ostatni link strony zostanie kliknięty, kontrolka GridView przypisze jej PageIndex właściwość do wartości mniejszą niż jej PageCount właściwość. Po wyłączeniu PageCount stanu widoku wartość jest tracona w przypadku ogłaszania zwrotnego, a PageIndex zamiast tego jest przypisana maksymalna wartość całkowita. Następnie kontrolka GridView próbuje określić indeks wiersza początkowego przez pomnożenie PageSize właściwości i PageCount . Powoduje to, OverflowException że produkt przekracza maksymalny dozwolony rozmiar liczby całkowitej.
Implementowanie niestandardowego stronicowania i sortowania
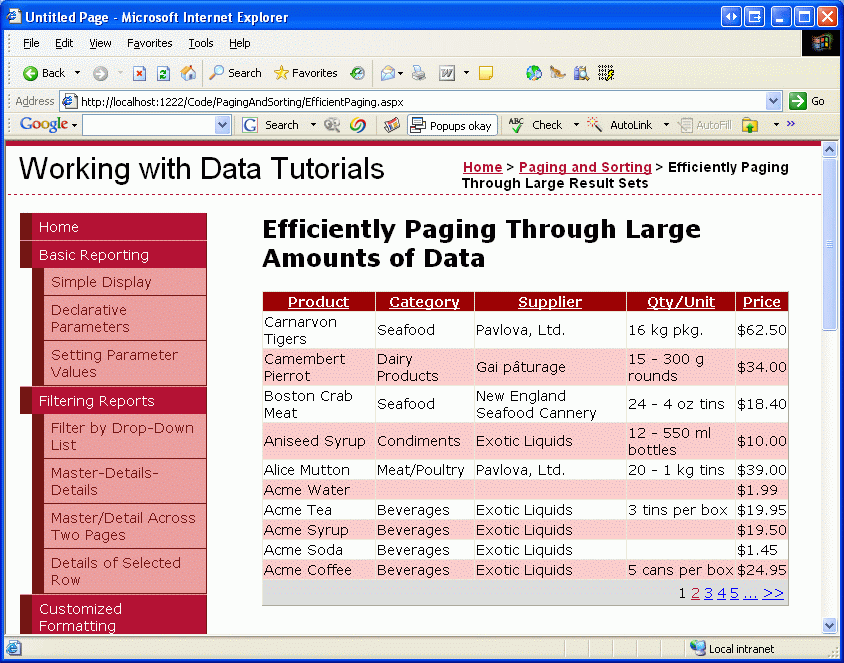
Nasza bieżąca niestandardowa implementacja stronicowania wymaga, aby kolejność, za pomocą której dane są stronicowane, można określić statycznie podczas tworzenia GetProductsPaged procedury składowanej. Można jednak zauważyć, że tag inteligentny GridView zawiera pole wyboru Włącz sortowanie oprócz opcji Włącz stronicowanie. Niestety dodanie obsługi sortowania do kontrolki GridView przy użyciu bieżącej niestandardowej implementacji stronicowania spowoduje sortowanie rekordów tylko na aktualnie wyświetlanej stronie danych. Jeśli na przykład skonfigurujesz kontrolkę GridView tak, aby obsługiwała stronicowanie, a następnie podczas wyświetlania pierwszej strony danych sortowanie według nazwy produktu w kolejności malejącej spowoduje odwrócenie kolejności produktów na stronie 1. Jak pokazano na rysunku 18, takie jak Carnarvon Tigers jako pierwszy produkt podczas sortowania w odwrotnej kolejności alfabetycznej, który ignoruje 71 innych produktów, które pochodzą po Carnarvon Tigers, alfabetycznie; tylko te rekordy na pierwszej stronie są brane pod uwagę w sortowaniu.
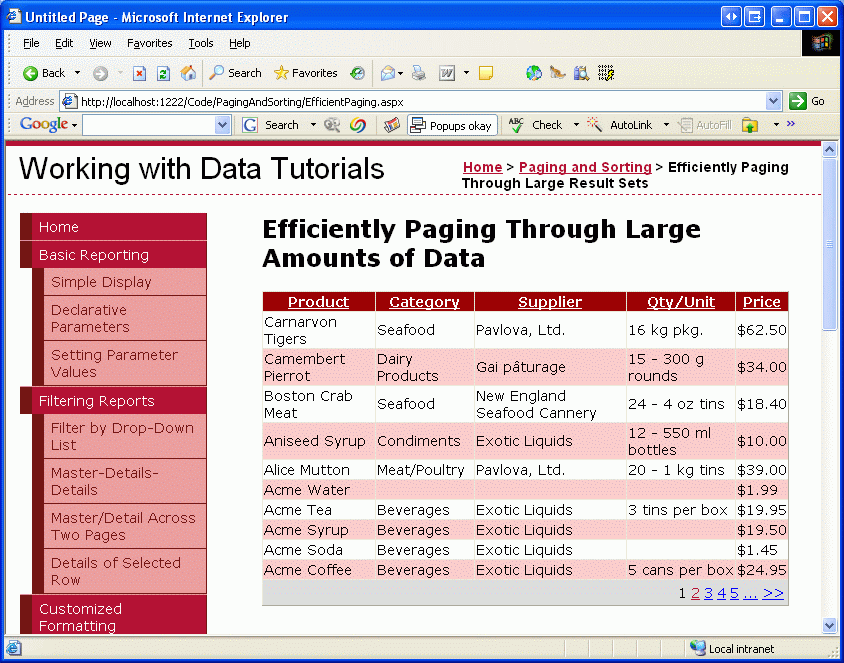
Rysunek 18. Posortowane są tylko dane wyświetlane na bieżącej stronie (kliknij, aby wyświetlić obraz pełnowymiarowy)
{kind=link}
Sortowanie dotyczy tylko bieżącej strony danych, ponieważ sortowanie odbywa się po pobraniu danych z metody BLL GetProductsPaged , a ta metoda zwraca tylko te rekordy dla określonej strony. Aby prawidłowo zaimplementować sortowanie, musimy przekazać wyrażenie sortowania do GetProductsPaged metody, aby dane mogły zostać odpowiednio sklasyfikowane przed zwróceniem określonej strony danych. Zobaczymy, jak to zrobić w następnym samouczku.
Implementowanie niestandardowego stronicowania i usuwanie
Jeśli włączasz usuwanie funkcji w siatceView, której dane są stronicowane przy użyciu niestandardowych technik stronicowania, okaże się, że podczas usuwania ostatniego rekordu z ostatniej strony funkcja GridView zniknie, a nie odpowiednio zdekrementuje element GridView s PageIndex. Aby odtworzyć tę usterkę, włącz usuwanie właśnie utworzonego samouczka. Przejdź do ostatniej strony (strona 9), gdzie powinien zostać wyświetlony pojedynczy produkt, ponieważ stronicujemy do 81 produktów, 10 produktów jednocześnie. Usuń ten produkt.
Po usunięciu ostatniego produktu element GridView powinien automatycznie przejść do ósmej strony, a takie funkcje są wyświetlane z domyślnym stronicowaniem. Jednak po usunięciu tego ostatniego produktu na ostatniej stronie funkcja GridView po prostu zniknie z ekranu. Dokładny powód , dla którego tak się dzieje, wykracza nieco poza zakres tego samouczka. Zobacz Usuwanie ostatniego rekordu na ostatniej stronie z kontrolki GridView z niestandardowym stronicowaniem , aby uzyskać szczegółowe informacje o niskim poziomie co do źródła tego problemu. Podsumowując, wynika to z następującej sekwencji kroków wykonywanych przez obiekt GridView po kliknięciu przycisku Usuń:
- Usuwanie rekordu
- Pobierz odpowiednie rekordy do wyświetlenia dla określonego
PageIndexelementu iPageSize - Sprawdź,
PageIndexczy obiekt nie przekracza liczby stron danych w źródle danych; jeśli tak, automatycznie dekrementuje właściwość GridViewPageIndex - Wiązanie odpowiedniej strony danych z kontrolką GridView przy użyciu rekordów uzyskanych w kroku 2
Problem wynika z faktu, że w kroku 2 PageIndex używany podczas chwytania rekordów do wyświetlenia jest nadal PageIndex z ostatniej strony, której jedyny rekord został właśnie usunięty. W związku z tym w kroku 2 żadne rekordy nie są zwracane od tej ostatniej strony danych, które nie zawierają już żadnych rekordów. Następnie, w kroku 3, GridView zdaje sobie sprawę, że jego PageIndex właściwość jest większa niż całkowita liczba stron w źródle danych (ponieważ usunęliśmy ostatni rekord na ostatniej stronie) i dlatego dekrementuje jego PageIndex właściwość. W kroku 4 kontrolka GridView próbuje powiązać się z danymi pobranymi w kroku 2; jednak w kroku 2 nie zostały zwrócone żadne rekordy, co powoduje, że element GridView jest pusty. W przypadku domyślnego stronicowania ten problem nie występuje, ponieważ w kroku 2 wszystkie rekordy są pobierane ze źródła danych.
Aby rozwiązać ten problem, mamy dwie opcje. Pierwszym z nich jest utworzenie procedury obsługi zdarzeń dla programu obsługi zdarzeń GridView RowDeleted , która określa, ile rekordów zostało wyświetlonych na stronie, która została właśnie usunięta. Jeśli był tylko jeden rekord, rekord właśnie usunięty musiał być ostatnim i musimy zdekrementować gridview s PageIndex. Oczywiście chcemy zaktualizować PageIndex tylko wtedy, gdy operacja usuwania zakończyła się pomyślnie, co można określić, upewniając się, że e.Exception właściwość ma wartość null.
To podejście działa, ponieważ aktualizuje po PageIndex kroku 1, ale przed krokiem 2. W związku z tym w kroku 2 zwracany jest odpowiedni zestaw rekordów. Aby to osiągnąć, użyj kodu podobnego do następującego:
protected void GridView1_RowDeleted(object sender, GridViewDeletedEventArgs e)
{
// If we just deleted the last row in the GridView, decrement the PageIndex
if (e.Exception == null && GridView1.Rows.Count == 1)
// we just deleted the last row
GridView1.PageIndex = Math.Max(0, GridView1.PageIndex - 1);
}
Alternatywnym obejściem jest utworzenie procedury obsługi zdarzeń dla zdarzenia ObjectDataSource i RowDeleted ustawienie AffectedRows właściwości na wartość 1. Po usunięciu rekordu w kroku 1 (ale przed ponownym pobraniem danych w kroku 2) kontrolka GridView aktualizuje jego PageIndex właściwość, jeśli operacja ma wpływ na co najmniej jeden wiersz. AffectedRows Jednak właściwość nie jest ustawiana przez obiekt ObjectDataSource i dlatego ten krok zostanie pominięty. Jednym ze sposobów wykonania tego kroku jest ręczne ustawienie AffectedRows właściwości, jeśli operacja usuwania zakończy się pomyślnie. Można to zrobić przy użyciu kodu, takiego jak następujące:
protected void ObjectDataSource1_Deleted(
object sender, ObjectDataSourceStatusEventArgs e)
{
// If we get back a Boolean value from the DeleteProduct method and it's true,
// then we successfully deleted the product. Set AffectedRows to 1
if (e.ReturnValue is bool && ((bool)e.ReturnValue) == true)
e.AffectedRows = 1;
}
Kod dla obu tych programów obsługi zdarzeń można znaleźć w klasie kodu w przykładzie EfficientPaging.aspx .
Porównanie wydajności domyślnej i niestandardowej stronicowania
Ponieważ niestandardowe stronicowanie pobiera tylko wymagane rekordy, natomiast domyślne stronicowanie zwraca wszystkie rekordy dla każdej wyświetlanej strony, jasne jest, że stronicowanie niestandardowe jest bardziej wydajne niż domyślne stronicowanie. Ale ile bardziej wydajne jest stronicowanie niestandardowe? Jakie korzyści z wydajności można zobaczyć, przechodząc z domyślnego stronicowania do niestandardowego stronicowania?
Niestety, nie ma jednego rozmiaru pasuje do wszystkich odpowiedzi tutaj. Wzrost wydajności zależy od wielu czynników, najwybitniejszych dwóch jest liczba stronicowanych rekordów oraz obciążenie umieszczone na serwerze bazy danych i kanałach komunikacyjnych między serwerem internetowym a serwerem bazy danych. W przypadku małych tabel z zaledwie kilkoma tuzinami rekordów różnica wydajności może być niewielka. W przypadku dużych tabel, z tysiącami do setek tysięcy wierszy, różnica wydajności jest jednak ostra.
Artykuł "Custom Paging in ASP.NET 2.0 with SQL Server 2005" (Niestandardowe stronicowanie w wersji 2.0 z programem SQL Server 2005) zawiera kilka testów wydajności, które przeprowadziłem, aby pokazać różnice w wydajności między tymi dwoma technikami stronicowania podczas stronicowania za pomocą tabeli bazy danych z 50 000 rekordów. W tych testach przeanalizowałem zarówno czas wykonywania zapytania na poziomie programu SQL Server (przy użyciu programu SQL Profiler), jak i na stronie ASP.NET przy użyciu funkcji śledzenia ASP.NET. Należy pamiętać, że te testy zostały uruchomione w moim polu programistycznym z jednym aktywnym użytkownikiem, dlatego nie są nienajętne i nie naśladują typowych wzorców ładowania witryn internetowych. Niezależnie od tego wyniki ilustrują względne różnice w czasie wykonywania dla domyślnego i niestandardowego stronicowania podczas pracy z wystarczająco dużą ilością danych.
| Średni czas trwania (s) | Odczytuje | |
|---|---|---|
| Domyślny profiler SQL stronicowania | 1.411 | 383 |
| Niestandardowy profiler SQL stronicowania | 0,002 | 29 |
| Domyślne śledzenie ASP.NET stronicowania | 2.379 | Nie dotyczy |
| Niestandardowe śledzenie ASP.NET stronicowania | 0.029 | Nie dotyczy |
Jak widać, pobieranie określonej strony danych wymaga średnio 354 mniej odczytów i ukończonych w ułamku czasu. Na stronie ASP.NET niestandardowa strona była w stanie renderować w pobliżu 1/100czasu , jaki zajęło użycie domyślnego stronicowania.
Podsumowanie
Domyślne stronicowanie to funkcja cinch umożliwiająca zaimplementowanie tylko zaznaczenia pola wyboru Włącz stronicowanie w tagu inteligentnym kontrolki sieci Web danych, ale taka prostota wiąże się z kosztem wydajności. W przypadku domyślnego stronicowania, gdy użytkownik zażąda dowolnej strony danych , zostaną zwrócone wszystkie rekordy, mimo że może być wyświetlana tylko niewielka część z nich. W celu zwalczania tego obciążenia związanego z wydajnością usługa ObjectDataSource oferuje alternatywną opcję stronicowania niestandardowego.
Podczas gdy niestandardowe stronicowanie poprawia się po domyślnych problemach z wydajnością stronicowania, pobierając tylko te rekordy, które muszą być wyświetlane, bardziej zaangażowane jest zaimplementowanie niestandardowego stronicowania. Najpierw należy napisać zapytanie, które poprawnie (i wydajnie) uzyskuje dostęp do określonego podzestawu żądanych rekordów. Można to osiągnąć na wiele sposobów; podczas badania w tym samouczku jest użycie nowej ROW_NUMBER() funkcji programu SQL Server 2005 do klasyfikowania wyników, a następnie zwracania tylko tych wyników, których klasyfikacja mieści się w określonym zakresie. Ponadto musimy dodać środki w celu określenia całkowitej liczby stronicowanych rekordów. Po utworzeniu tych metod DAL i BLL musimy również skonfigurować obiekt ObjectDataSource, aby określić, ile sum rekordów jest stronicowanych i może poprawnie przekazać wartości Indeks wiersza początkowego i Maksymalne wiersze do biblioteki BLL.
Chociaż implementowanie niestandardowego stronicowania wymaga wielu kroków i nie jest tak proste, jak domyślne stronicowanie, niestandardowe stronicowanie jest koniecznością podczas stronicowania wystarczająco dużych ilości danych. Jak pokazano w badaniu wyników, niestandardowe stronicowanie może rzucić sekundy poza czas renderowania strony ASP.NET i może rozjaśnić obciążenie serwera bazy danych o jedną kolejność wielkości.
Szczęśliwe programowanie!
Informacje o autorze
Scott Mitchell, autor siedmiu książek ASP/ASP.NET i założyciel 4GuysFromRolla.com, współpracuje z technologiami internetowymi firmy Microsoft od 1998 roku. Scott pracuje jako niezależny konsultant, trener i pisarz. Jego najnowsza książka to Sams Teach Yourself ASP.NET 2.0 w 24 godzinach. Można go uzyskać pod adresem mitchell@4GuysFromRolla.com. lub za pośrednictwem swojego bloga, który można znaleźć na stronie http://ScottOnWriting.NET.