Instrukcje: Modyfikowanie bazy danych typu lake
W tym artykule dowiesz się, jak zmodyfikować istniejącą bazę danych lake w Azure Synapse przy użyciu projektanta bazy danych. Projektant bazy danych umożliwia łatwe tworzenie i wdrażanie bazy danych bez konieczności pisania kodu.
Wymagania wstępne
- Uprawnienia administratora usługi Synapse lub współautora usługi Synapse są wymagane w obszarze roboczym usługi Synapse do tworzenia bazy danych lake.
- Uprawnienia współautora danych obiektu blob usługi Storage są wymagane w usłudze Data Lake podczas korzystania z opcji create table From data lake (Tworzenie tabeli z magazynu data lake ).
Modyfikowanie właściwości bazy danych
W centrum głównym obszaru roboczego usługi Azure Synapse Analytics wybierz kartę Dane po lewej stronie. Na karcie Dane zostanie wyświetlona lista baz danych, które już istnieją w obszarze roboczym.
Umieść kursor na sekcji Bazy danych i wybierz wielokropek ... obok bazy danych, którą chcesz zmodyfikować, a następnie wybierz pozycję Otwórz.
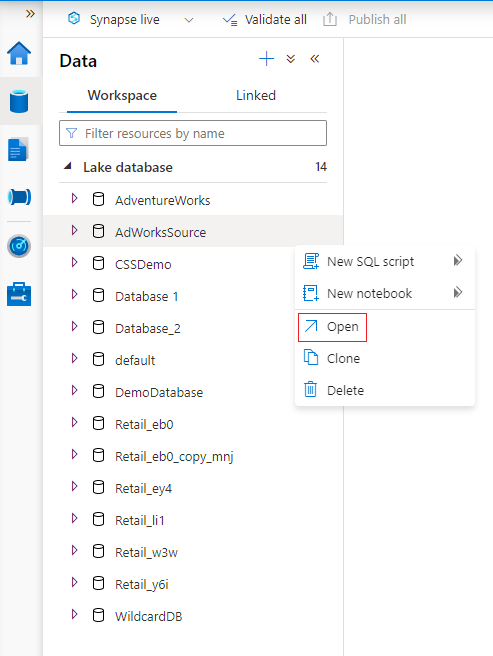
Karta projektanta bazy danych zostanie otwarta z wybraną bazą danych załadowaną na kanwie.
Projektant bazy danych ma okienko Właściwości , które można otworzyć, wybierając ikonę Właściwości w prawym górnym rogu karty.
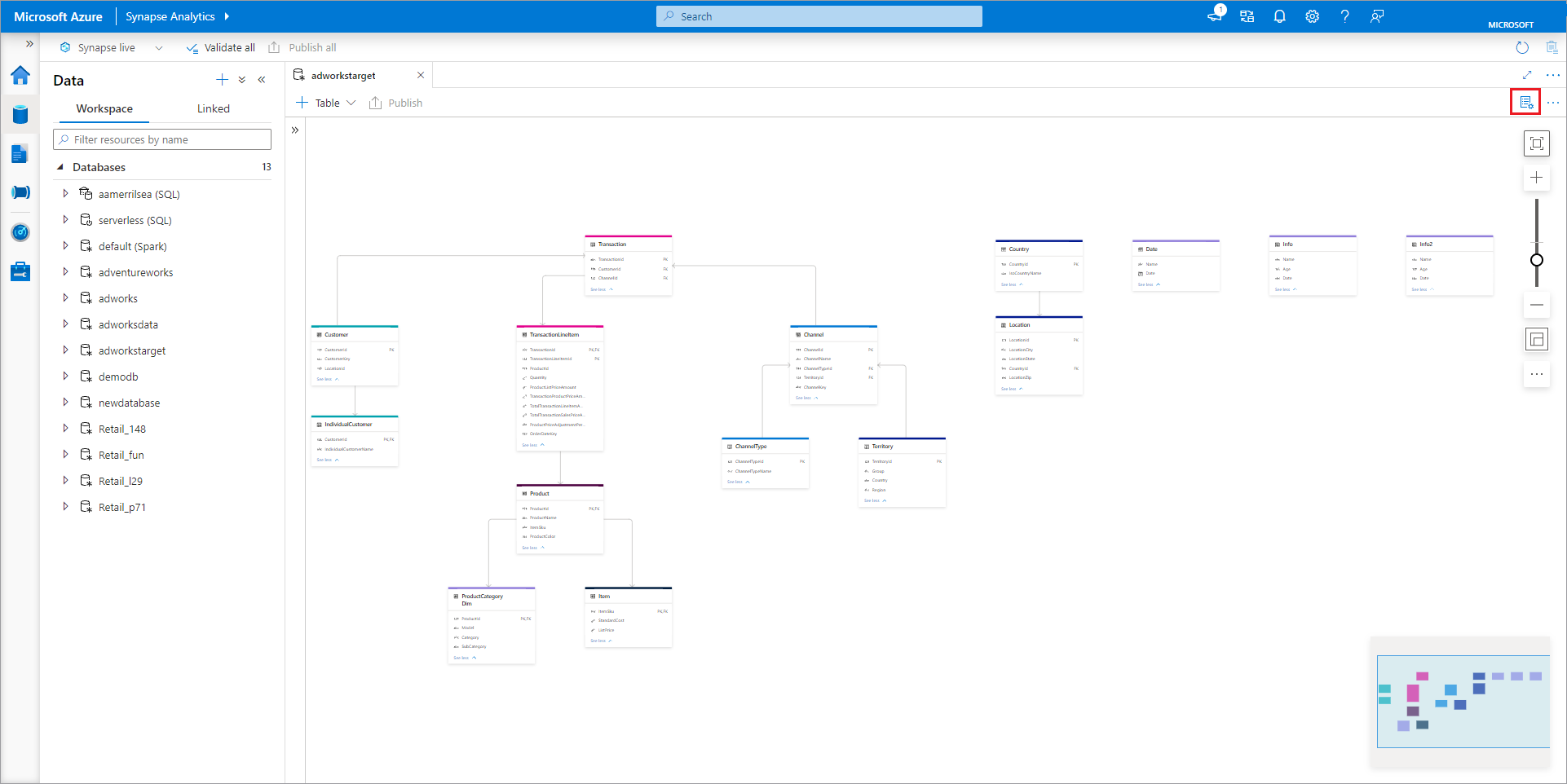
- Nazwa Nazwy nie mogą być edytowane po opublikowaniu bazy danych, dlatego upewnij się, że wybrana nazwa jest poprawna.
- Opis Nadanie bazie danych opisu jest opcjonalne, ale umożliwia użytkownikom zrozumienie przeznaczenia bazy danych.
- Ustawienia magazynu dla bazy danych to sekcja zawierająca domyślne informacje o magazynie dla tabel w bazie danych. Ustawienia domyślne są stosowane do każdej tabeli w bazie danych, chyba że zostaną one zastąpione w samej tabeli.
- Połączona usługa to domyślna połączona usługa używana do przechowywania danych w Azure Data Lake Storage. Zostanie wyświetlona domyślna połączona usługa skojarzona z obszarem roboczym usługi Synapse, ale możesz zmienić połączoną usługę na dowolne konto magazynu usługi ADLS.
- Folder input używany do ustawiania domyślnej ścieżki kontenera i folderu w tej połączonej usłudze przy użyciu przeglądarki plików lub ręcznej edycji ścieżki za pomocą ikony ołówka.
- Bazy danych data format lake w Azure Synapse obsługują formaty parquet i rozdzielany tekst jako formaty magazynu danych.
Aby dodać tabelę do bazy danych, wybierz przycisk + Tabela .
- Do kanwy zostanie dodana nowa tabela.
- W szablonie zostanie otwarta galeria i umożliwi wybranie szablonu bazy danych do użycia podczas dodawania nowej tabeli. Aby uzyskać więcej informacji, zobacz Tworzenie bazy danych lake na podstawie szablonu bazy danych.
- Usługa Data Lake umożliwia importowanie schematu tabeli przy użyciu danych już w usłudze Lake.
wybierz pozycję Niestandardowe. Na kanwie zostanie wyświetlona nowa tabela o nazwie Table_1.
Następnie można dostosować Table_1, w tym nazwę tabeli, opis, ustawienia magazynu, kolumny i relacje. Zobacz sekcję Dostosowywanie tabel w bazie danych poniżej.
Dodaj nową tabelę z magazynu data lake, wybierając pozycję + Tabela , a następnie pozycję Z usługi Data Lake.
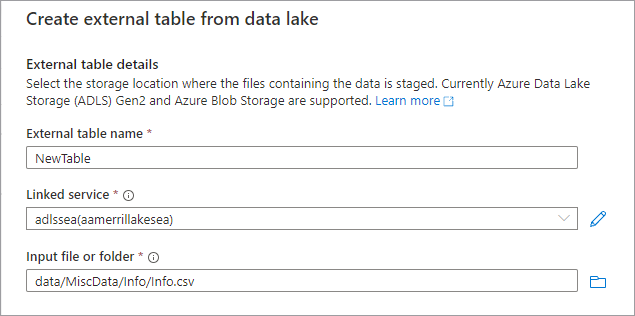
Zostanie wyświetlone okienko Tworzenie tabeli zewnętrznej z usługi Data Lake . Wypełnij okienko poniższymi szczegółami i wybierz pozycję Kontynuuj.
- Nazwa tabeli zewnętrznej, którą chcesz nadać tworzonej tabeli.
- Połączona usługa połączona zawierająca lokalizację Azure Data Lake Storage, w której znajduje się plik danych.
-
Plik wejściowy lub folder użyj przeglądarki plików, aby przejść do lokalizacji i wybrać plik w jeziorze, za pomocą którego chcesz utworzyć tabelę.
- Na następnym ekranie Azure Synapse wyświetli podgląd pliku i wykryje schemat.
- Nastąpi przekierowanie na stronę Nowa tabela zewnętrzna, na której można zaktualizować wszystkie ustawienia związane z formatem danych oraz dane podglądu, aby sprawdzić, czy Azure Synapse poprawnie zidentyfikował plik.
- Jeśli ustawienia są zadowolone, wybierz pozycję Utwórz.
- Nowa tabela o wybranej nazwie zostanie dodana do kanwy, a w sekcji Ustawienia magazynu dla tabeli zostanie wyświetlony określony plik.
Po dostosowaniu bazy danych nadszedł czas na jej opublikowanie. Jeśli używasz integracji usługi Git z obszarem roboczym usługi Synapse, musisz zatwierdzić zmiany i scalić je z gałęzią współpracy. Dowiedz się więcej o kontroli źródła w Azure Synapse. Jeśli używasz trybu Synapse Live, możesz wybrać pozycję "Publikuj".
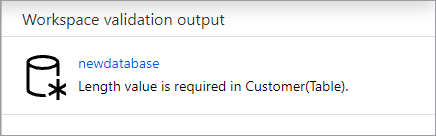
Baza danych zostanie zweryfikowana pod kątem błędów przed jej opublikowaniem. Wszystkie znalezione błędy będą wyświetlane na karcie powiadomień z instrukcjami dotyczącymi sposobu naprawienia błędu.
Publikowanie spowoduje utworzenie schematu bazy danych w magazynie metadanych Azure Synapse. Po opublikowaniu obiekty bazy danych i tabeli będą widoczne dla innych usług platformy Azure i umożliwiają przepływ metadanych z bazy danych do aplikacji, takich jak Power BI lub Microsoft Purview.
Dostosowywanie tabel w bazie danych
Projektant bazy danych umożliwia pełne dostosowanie dowolnej z tabel w bazie danych. Po wybraniu tabeli są dostępne trzy karty, z których każda zawiera ustawienia powiązane ze schematem lub metadanymi tabeli.
Ogólne
Karta Ogólne zawiera informacje specyficzne dla samej tabeli.
Nadaj nazwę tabeli. Nazwę tabeli można dostosować do dowolnej unikatowej wartości w bazie danych. Wiele tabel o tej samej nazwie jest niedozwolonych.
Dziedziczona z (opcjonalnie) ta wartość będzie obecna, jeśli tabela została utworzona na podstawie szablonu bazy danych. Nie można go edytować i informuje użytkownika, z której tabeli szablonu pochodzi.
Opis tabeli. Jeśli tabela została utworzona na podstawie szablonu bazy danych, będzie zawierać opis koncepcji reprezentowanej przez tę tabelę. To pole jest edytowalne i można je zmienić, aby dopasować je do opisu spełniającego wymagania biznesowe.
Folder wyświetlania zawiera nazwę folderu obszaru biznesowego, w ramach którego ta tabela została pogrupowana w ramach szablonu bazy danych. W przypadku tabel niestandardowych ta wartość będzie mieć wartość "Inne".
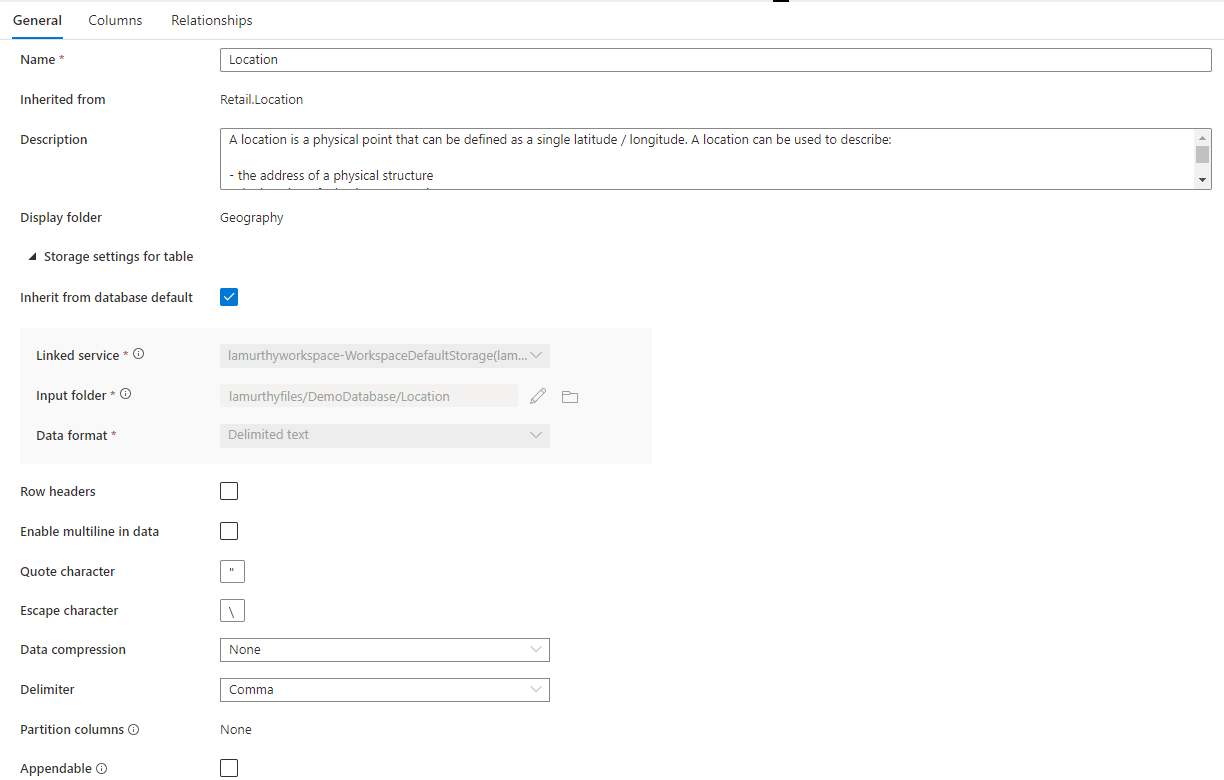
Ponadto istnieje zwijana sekcja o nazwie Ustawienia magazynu dla tabeli , która udostępnia ustawienia podstawowych informacji o magazynie używanych przez tabelę.
Dziedzicz po domyślnej bazie danych pole wyboru, które określa, czy poniższe ustawienia magazynu są dziedziczone z wartości ustawionych na karcie Właściwości bazy danych, czy są ustawiane indywidualnie. Jeśli chcesz dostosować wartości magazynu, usuń zaznaczenie tego pola.
- Połączona usługa to domyślna połączona usługa używana do przechowywania danych w Azure Data Lake Storage. Zmień to, aby wybrać inne konto usługi ADLS.
- Folder input folder w usłudze ADLS, w którym będą aktywne dane załadowane do tej tabeli. Możesz przeglądać lokalizację folderu lub edytować ją ręcznie przy użyciu ikony ołówka.
- Format danych format danych w bazach danych Input folder Lake w Azure Synapse obsługują formaty parquet i rozdzielane jako formaty przechowywania danych. Jeśli format danych nie jest zgodny z danymi w folderze, zapytania do tabeli zakończy się niepowodzeniem.
W przypadku formatu danych tekstu rozdzielanego istnieją dodatkowe ustawienia:
- Nagłówki wierszy zaznacz to pole wyboru, jeśli dane mają nagłówki wierszy.
- Włącz wielowierszowe pole wyboru danych , jeśli dane zawierają wiele wierszy w kolumnie ciągu.
- Znak cudzysłowu określa niestandardowy znak cudzysłowu dla rozdzielanego pliku tekstowego.
- Znak ucieczki określa niestandardowy znak ucieczki dla rozdzielanego pliku tekstowego.
- Kompresja danych — typ kompresji używany na danych.
- Ogranicz ogranicznik pola używany w plikach danych. Obsługiwane wartości to: Przecinek (,), tabulator (\t) i potok (|).
- W tym miejscu zostanie wyświetlona lista kolumn partycji.
- To pole wyboru można dodać, jeśli wysyłasz zapytania dotyczące danych usługi Dataverse z usługi SQL Serverless.
W przypadku danych Parquet dostępne jest następujące ustawienie:
- Kompresja danych — typ kompresji używany na danych.
Kolumny
Na karcie Kolumny znajdują się kolumny tabeli i można je modyfikować. Na tej karcie znajdują się dwie listy kolumn: Kolumny standardowe i Kolumny partycji.
Kolumny standardowe to dowolna kolumna, która przechowuje dane, jest kluczem podstawowym, a w przeciwnym razie nie jest używana do partycjonowania danych.
Partycjonowanie kolumn przechowuje również dane, ale są używane do partycjonowania danych bazowych na foldery na podstawie wartości zawartych w kolumnie. Każda kolumna ma następujące właściwości.
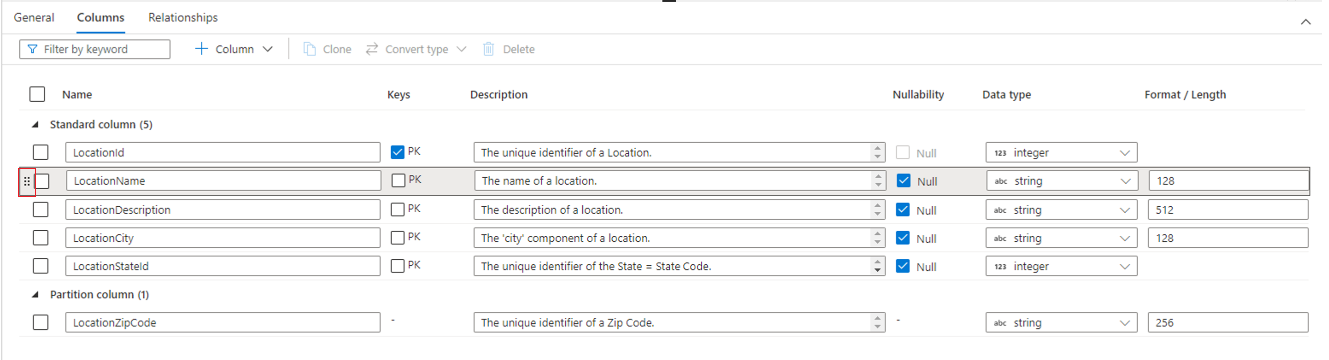
- Nazwij nazwę kolumny. Musi być unikatowa w tabeli.
- Klucze wskazują, czy kolumna jest kluczem podstawowym (PK) i/lub kluczem obcym (FK) dla tabeli. Nie dotyczy kolumn partycji.
- Opis kolumny. Jeśli kolumna została utworzona na podstawie szablonu bazy danych, zostanie przedstawiony opis koncepcji reprezentowanej przez tę kolumnę. To pole można edytować i można je zmienić tak, aby było zgodne z opisem zgodnym z wymaganiami biznesowymi.
- Wartość null wskazuje, czy w tej kolumnie mogą istnieć wartości null. Nie dotyczy kolumn partycji.
- Typ danych ustawia typ danych kolumny na podstawie dostępnej listy typów danych platformy Spark.
- Format/długość umożliwia dostosowanie formatu lub maksymalnej długości kolumny w zależności od typu danych. Typy danych daty i znacznika czasu mają listy rozwijane formatu, a inne typy, takie jak ciąg, mają pole maksymalnej długości. Nie wszystkie typy danych mają wartość, ponieważ niektóre typy mają stałą długość. W górnej części karty Kolumny znajduje się pasek poleceń, który może służyć do interakcji z kolumnami.
- Filtruj według słowa kluczowego filtruje listę kolumn do elementów pasujących do określonego słowa kluczowego.
-
+ Kolumna umożliwia dodanie nowej kolumny. Istnieją trzy możliwe opcje.
- Nowa kolumna tworzy nową niestandardową kolumnę standardową.
- W szablonie zostanie otwarte okienko eksploracji i pozwala zidentyfikować kolumny z szablonu bazy danych do uwzględnienia w tabeli. Jeśli baza danych nie została utworzona przy użyciu szablonu bazy danych, ta opcja nie zostanie wyświetlona.
- Kolumna partycji dodaje nową kolumnę partycji niestandardowej.
- Klonowanie duplikuje wybraną kolumnę. Sklonowane kolumny są zawsze tego samego typu co wybrana kolumna.
- Konwertowanie typu służy do zmieniania wybranej standardowej kolumny na kolumnę partycji i odwrotnie. Ta opcja będzie wyszarana, jeśli wybrano wiele kolumn różnych typów lub wybrana kolumna nie może zostać przekonwertowana z powodu flagi PK lub Nullability ustawionej na kolumnie.
- Usunięcie usuwa wybrane kolumny z tabeli. Ta akcja jest nieodwracalna.
Kolejność kolumn można również ponownie rozmieścić, przeciągając i upuszczając przy użyciu podwójnej pionowej wielokropka, która jest wyświetlana po lewej stronie nazwy kolumny po umieszczeniu kursora na kolumnie lub kliknięciu kolumny, jak pokazano na powyższej ilustracji.
Kolumny partycji
Kolumny partycji służą do partycjonowania danych fizycznych w bazie danych na podstawie wartości w tych kolumnach. Kolumny partycji umożliwiają łatwe dystrybuowanie danych na dysku do bardziej wydajnych fragmentów. Kolumny partycji w Azure Synapse są zawsze na końcu schematu tabeli. Ponadto są one używane od góry do dołu podczas tworzenia folderów partycji. Jeśli na przykład kolumny partycji to Rok i Miesiąc, w usłudze ADLS pojawi się struktura podobna do następującej:
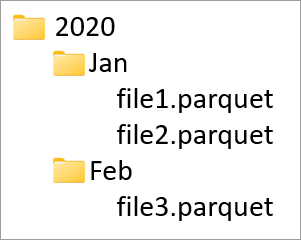
Gdzie file1 i file2 zawierały wszystkie wiersze, w których wartości rok i miesiąc były odpowiednio 2020 i Jan. W miarę dodawania większej liczby kolumn partycji do tabeli więcej plików jest dodawanych do tej hierarchii, dzięki czemu ogólny rozmiar plików partycji jest mniejszy.
Azure Synapse nie wymusza ani nie tworzy tej hierarchii przez dodanie kolumn partycji do tabeli. Dane muszą być ładowane do tabeli przy użyciu potoków usługi Synapse lub notesu Spark, aby można było utworzyć strukturę partycji.
Relacje
Karta Relacje umożliwia określenie relacji między tabelami w bazie danych. Relacje w projektancie baz danych są informacyjne i nie wymuszają żadnych ograniczeń dotyczących danych bazowych. Są one odczytywane przez inne aplikacje firmy Microsoft, aby przyspieszyć przekształcenia lub zapewnić użytkownikom biznesowym wgląd w sposób łączenia tabel. Okienko relacji zawiera następujące informacje.
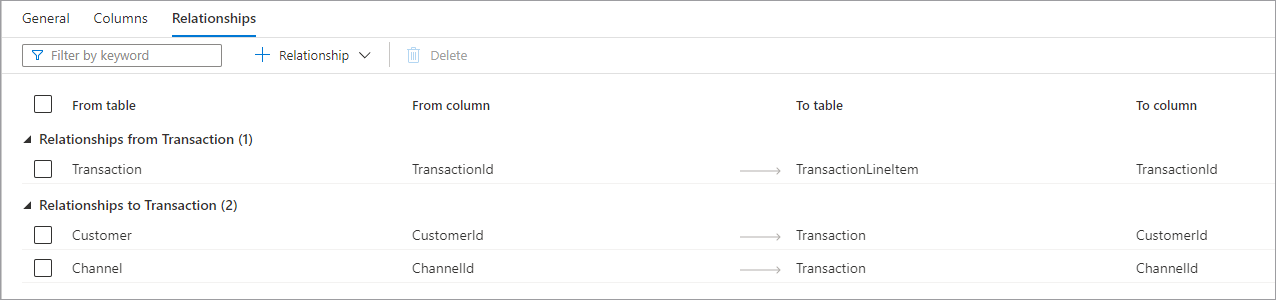
- Relacje z tabeli (Tabela) są wtedy, gdy co najmniej jedna tabela ma klucze obce połączone z tą tabelą. Jest to czasami nazywane relacją nadrzędną.
- Relacje z (tabelą) są wtedy, gdy tabela, która ma klucz obcy i jest połączona z inną tabelą. Jest to czasami nazywane relacją podrzędną.
- Oba typy relacji mają następujące właściwości.
- Z tabeli tabeli nadrzędnej w relacji lub po stronie "jednej".
- Z kolumny kolumny w tabeli nadrzędnej relacja jest oparta.
- Aby wylić tabelę podrzędną w relacji lub po stronie "wiele".
- Kolumna kolumny w tabeli podrzędnej jest oparta na relacji. W górnej części karty Relacje znajduje się pasek poleceń, który może służyć do interakcji z relacjami
- Filtruj według słowa kluczowego filtruje listę kolumn do elementów pasujących do określonego słowa kluczowego.
-
+ Relacja umożliwia dodanie nowej relacji. Dostępne są dwie opcje.
- Z tabeli tworzy nową relację z tabeli, nad którą pracujesz, do innej tabeli.
- Aby utworzyć nową relację z innej tabeli do tej, nad którą pracujesz.
- W szablonie zostanie otwarte okienko eksploracji i umożliwia wybranie relacji w szablonie bazy danych w celu uwzględnienia ich w bazie danych. Jeśli baza danych nie została utworzona przy użyciu szablonu bazy danych, ta opcja nie zostanie wyświetlona.
Następne kroki
Kontynuuj eksplorowanie możliwości projektanta bazy danych, korzystając z poniższych linków.