Planowanie pojemności i skalowania na potrzeby odzyskiwania po awarii programu VMware na platformę Azure
Skorzystaj z tego artykułu, aby zaplanować pojemność i skalowanie podczas replikowania lokalnych maszyn wirtualnych VMware i serwerów fizycznych na platformę Azure przy użyciu usługi Azure Site Recovery — wersja klasyczna.
W modernizacji należy utworzyć urządzenie replikacji/wiele urządzeń usługi Azure Site Recovery i używać ich do planowania pojemności.
Jak mogę rozpocząć planowanie pojemności?
Aby dowiedzieć się więcej o wymaganiach dotyczących infrastruktury usługi Azure Site Recovery, zbierz informacje o środowisku replikacji, uruchamiając Planista wdrażania usługi Azure Site Recovery na potrzeby replikacji programu VMware. Aby uzyskać więcej informacji, zobacz About Site Recovery Deployment Planner for VMware to Azure (Informacje o planistce wdrażania usługi Site Recovery dla oprogramowania VMware na platformie Azure).
Planista wdrażania usługi Site Recovery zawiera raport zawierający pełne informacje o zgodnych i niezgodnych maszynach wirtualnych, dyskach na maszynę wirtualną i współczynniku zmian danych na dysk. Narzędzie zawiera również podsumowanie wymagań dotyczących przepustowości sieci w celu spełnienia docelowego celu punktu odzyskiwania i infrastruktury platformy Azure wymaganej do pomyślnej replikacji i testowania pracy w trybie failover.
Zagadnienia dotyczące pojemności
| Składnik | Szczegóły |
|---|---|
| Replikacja | Maksymalna dzienna częstotliwość zmian: Maszyna chroniona może używać tylko jednego serwera przetwarzania. Pojedynczy serwer przetwarzania może obsłużyć dziennie do 2 TB zmian. Dlatego 2 TB to maksymalna dzienna szybkość zmiany danych obsługiwana dla chronionej maszyny. Maksymalna przepływność: replikowana maszyna może należeć do jednego konta magazynu na platformie Azure. Standardowe konto usługi Azure Storage może obsłużyć maksymalnie 20 000 żądań na sekundę. Zalecamy ograniczenie liczby operacji wejścia/wyjścia na sekundę (IOPS) na maszynie źródłowej do 20 000. Jeśli na przykład masz maszynę źródłową, która ma pięć dysków, a każdy dysk generuje 120 operacji we/wy na sekundę (rozmiar 8 K) na maszynie źródłowej, maszyna źródłowa mieści się w limicie liczby operacji we/wy na sekundę na dysk platformy Azure do 500. (Liczba wymaganych kont magazynu jest równa całkowitej liczbie operacji we/wy na sekundę maszyny źródłowej podzielonej przez 20 000). |
| Serwer konfiguracji | Serwer konfiguracji musi mieć możliwość obsługi dziennej pojemności współczynnika zmian we wszystkich obciążeniach uruchomionych na chronionych maszynach. Maszyna konfiguracji musi mieć wystarczającą przepustowość, aby stale replikować dane do usługi Azure Storage. Najlepszym rozwiązaniem jest umieszczenie serwera konfiguracji w tej samej sieci i segmencie sieci LAN co maszyny, które chcesz chronić. Serwer konfiguracji można umieścić w innej sieci, ale maszyny, które chcesz chronić, powinny mieć widoczność sieci warstwy 3. Zalecenia dotyczące rozmiaru serwera konfiguracji zostały podsumowane w tabeli w poniższej sekcji. |
| Serwer przetwarzania | Pierwszy serwer przetwarzania jest instalowany domyślnie na serwerze konfiguracji. W celu skalowania środowiska można wdrożyć dodatkowe serwery przetwarzania. Serwer przetwarzania odbiera dane replikacji z chronionych maszyn. Serwer przetwarzania optymalizuje dane przy użyciu buforowania, kompresji i szyfrowania. Następnie serwer przetwarzania wysyła dane na platformę Azure. Maszyna serwera przetwarzania musi mieć wystarczające zasoby do wykonania tych zadań. Serwer przetwarzania używa pamięci podręcznej opartej na dysku. Użyj oddzielnego dysku pamięci podręcznej o rozmiarze 600 GB lub więcej, aby obsłużyć zmiany danych przechowywane, jeśli wystąpi wąskie gardło sieci lub awaria. |
Zalecenia dotyczące rozmiaru serwera konfiguracji i wbudowanego serwera przetwarzania
Serwer konfiguracji używający wbudowanego serwera przetwarzania do ochrony obciążenia może obsługiwać maksymalnie 200 maszyn wirtualnych na podstawie następujących konfiguracji:
| Procesor CPU | Memory (Pamięć) | Rozmiar dysku pamięci podręcznej | Szybkość zmian danych | Chronione maszyny |
|---|---|---|---|---|
| 8 procesorów wirtualnych (2 gniazda * 4 rdzenie po 2,5 GHz) | 16 GB | 300 GB | 500 GB lub mniej | Użyj polecenia , aby replikować mniej niż 100 maszyn. |
| 12 procesorów wirtualnych (2 gniazda * 6 rdzeni po 2,5 GHz) | 18 GB | 600 GB | Od 501 GB do 1 TB | Służy do replikowania 100 do 150 maszyn. |
| 16 procesorów wirtualnych (2 gniazda * 8 rdzeni o 2,5 GHz) | 32 GB | 1 TB | >Od 1 TB do 2 TB | Służy do replikowania 151 do 200 maszyn. |
| Wdróż inny serwer konfiguracji przy użyciu szablonu OVF. | Wdróż nowy serwer konfiguracji, jeśli replikujesz więcej niż 200 maszyn. | |||
| Wdróż inny serwer przetwarzania. | >2 TB | Wdróż nowy serwer przetwarzania skalowalnego w poziomie, jeśli ogólna dzienna szybkość zmiany danych jest większa niż 2 TB. |
W tych konfiguracjach:
- Każda maszyna źródłowa ma trzy dyski o pojemności 100 GB.
- Użyliśmy testu porównawczego magazynu ośmiu dysków sygnatur dostępu współdzielonego o rozmiarze 10 K OBR/min z macierzą RAID 10 na potrzeby pomiarów dysku pamięci podręcznej.
Zalecenia dotyczące określania rozmiaru serwera przetwarzania
Serwer przetwarzania jest składnikiem obsługującym replikację danych w usłudze Azure Site Recovery. Jeśli dzienny współczynnik zmian jest większy niż 2 TB, należy dodać serwery przetwarzania skalowalnego w poziomie w celu obsługi obciążenia replikacji. Aby skalować w poziomie, możesz wykonać następujące czynności:
- Zwiększ liczbę serwerów konfiguracji, wdrażając przy użyciu szablonu OVF. Na przykład można chronić maksymalnie 400 maszyn przy użyciu dwóch serwerów konfiguracji.
- Dodaj serwery przetwarzania skalowalnego w poziomie. Serwery przetwarzania skalowalnego w poziomie umożliwiają obsługę ruchu replikacji zamiast (lub oprócz) serwera konfiguracji.
W poniższej tabeli opisano ten scenariusz:
- Serwer przetwarzania skalowalnego w poziomie jest konfigurowany.
- Skonfigurowano chronione maszyny wirtualne do używania serwera przetwarzania skalowalnego w poziomie.
- Każda chroniona maszyna źródłowa ma trzy dyski o pojemności 100 GB.
| Dodatkowy serwer przetwarzania | Rozmiar dysku pamięci podręcznej | Szybkość zmian danych | Chronione maszyny |
|---|---|---|---|
| 4 procesory wirtualne (2 gniazda * 2 rdzenie @ 2,5 GHz), 8 GB pamięci | 300 GB | 250 GB lub mniej | Użyj polecenia , aby replikować co najmniej 85 maszyn. |
| 8 procesorów wirtualnych (2 gniazda * 4 rdzenie @ 2,5 GHz), 12 GB pamięci | 600 GB | Od 251 GB do 1 TB | Służy do replikowania 86 do 150 maszyn. |
| 12 procesorów wirtualnych (2 gniazda * 6 rdzeni @ 2,5 GHz) 24 GB pamięci | 1 TB | >Od 1 TB do 2 TB | Służy do replikowania 151 do 225 maszyn. |
Sposób skalowania serwerów zależy od preferencji modelu skalowania w górę lub w poziomie. Aby przeprowadzić skalowanie w górę, wdróż kilka serwerów konfiguracji wysokiej klasy i serwerów przetwarzania. Aby skalować w poziomie, wdróż więcej serwerów, które mają mniej zasobów. Jeśli na przykład chcesz chronić 200 maszyn z ogólnym dziennym współczynnikiem zmian danych wynoszącym 1,5 TB, możesz wykonać jedną z następujących czynności:
- Skonfiguruj pojedynczy serwer przetwarzania (16 procesorów wirtualnych, 24 GB pamięci RAM).
- Skonfiguruj dwa serwery przetwarzania (2 x 8 procesorów wirtualnych, 2* 12 GB pamięci RAM).
Kontrolowanie przepustowości sieci
Gdy użyjesz planisty wdrażania usługi Site Recovery do obliczenia przepustowości wymaganej do replikacji (replikacji początkowej, a następnie różnicy), masz kilka opcji kontrolowania przepustowości używanej do replikacji:
- Przepustowość ograniczania: ruch VMware replikowany na platformę Azure przechodzi przez określony serwer przetwarzania. Możesz ograniczyć przepustowość na maszynach, które są uruchomione jako serwery przetwarzania.
- Wpływ na przepustowość: możesz wpłynąć na przepustowość używaną do replikacji przy użyciu kilku kluczy rejestru:
- Wartość rejestru HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows Azure Backup\Replication\UploadThreadsPerVM określa liczbę wątków używanych do transferu danych (replikacja początkowa lub różnicowa) dysku. Wyższa wartość zwiększa przepustowość sieciową używaną podczas replikacji.
- Wartość rejestru HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows Azure Backup\Replication\DownloadThreadsPerVM określa liczbę wątków używanych do transferu danych podczas powrotu po awarii.
Ograniczanie przepustowości
Otwórz przystawkę MMC usługi Azure Backup na maszynie, której używasz jako serwera przetwarzania. Domyślnie skrót do kopii zapasowej jest dostępny na pulpicie lub w następującym folderze: C:\Program Files\Microsoft Azure Recovery Services Agent\bin.
W przystawce wybierz pozycję Zmień właściwości.
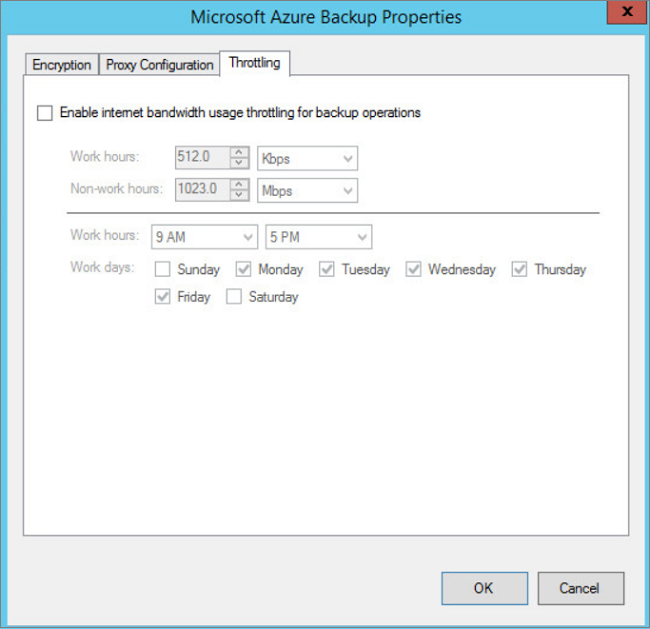
Na karcie Ograniczanie przepustowości wybierz pozycję Włącz ograniczanie użycia przepustowości internetowej dla operacji tworzenia kopii zapasowych. Ustaw limity w godzinach pracy i poza godzinami pracy. Prawidłowe zakresy wynoszą od 512 Kb/s do 1,023 Mb/s.
Możesz też użyć polecenia cmdlet Set-OBMachineSetting, aby ustawić ograniczanie przepływności. Oto przykład:
$mon = [System.DayOfWeek]::Monday
$tue = [System.DayOfWeek]::Tuesday
Set-OBMachineSetting -WorkDay $mon, $tue -StartWorkHour "9:00:00" -EndWorkHour "18:00:00" -WorkHourBandwidth (512*1024) -NonWorkHourBandwidth (2048*1024)
Set-OBMachineSetting -NoThrottle wskazuje, że ograniczanie przepływności nie jest wymagane.
Zmienianie przepustowości sieci dla maszyny wirtualnej
- W rejestrze maszyny wirtualnej przejdź do HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows Azure Backup\Replication.
- Aby zmienić ruch przepustowości na dysku replikowania, zmodyfikuj wartość UploadThreadsPerVM. Utwórz klucz, jeśli nie istnieje.
- Aby zmienić przepustowość ruchu powrotu po awarii z platformy Azure, zmodyfikuj wartość DownloadThreadsPerVM.
- Wartość domyślna dla każdego klucza to 4. W sieci „o nadmiarowych zasobach” należy zmienić wartości domyślne tych kluczy rejestru. Maksymalna wartość, której można użyć, to 32. Monitoruj ruch, aby zoptymalizować tę wartość.
Konfigurowanie infrastruktury usługi Site Recovery w celu ochrony ponad 500 maszyn wirtualnych
Przed skonfigurowaniem infrastruktury usługi Site Recovery uzyskaj dostęp do środowiska w celu mierzenia następujących czynników: zgodnych maszyn wirtualnych, dziennej szybkości zmiany danych, wymaganej przepustowości sieci dla celu punktu odzyskiwania, liczby wymaganych składników usługi Site Recovery i czasu potrzebnego do ukończenia replikacji początkowej. Wykonaj następujące kroki, aby zebrać wymagane informacje:
- Aby zmierzyć te parametry, uruchom planistę wdrażania usługi Site Recovery w środowisku. Aby uzyskać przydatne wskazówki, zobacz About Site Recovery Deployment Planner for VMware to Azure (Informacje o planistce wdrażania usługi Site Recovery dla oprogramowania VMware na platformie Azure).
- Wdróż serwer konfiguracji spełniający zalecenia dotyczące rozmiaru serwera konfiguracji. Jeśli obciążenie produkcyjne przekracza 650 maszyn wirtualnych, wdróż inny serwer konfiguracji.
- Na podstawie mierzonego dziennego współczynnika zmian danych należy wdrożyć serwery przetwarzania skalowalnego w poziomie przy użyciu wytycznych dotyczących rozmiaru.
- Jeśli oczekujesz, że współczynnik zmian danych dla maszyny wirtualnej dysku przekroczy 2 MB/s, upewnij się, że używasz dysków zarządzanych w warstwie Premium. Planista wdrażania usługi Site Recovery jest uruchamiany przez określony okres. Szczytowe wskaźniki zmian danych w innych momentach mogą nie być przechwytywane w raporcie.
- Ustaw przepustowość sieci na podstawie celu punktu odzyskiwania, który chcesz osiągnąć.
- Po skonfigurowaniu infrastruktury włącz odzyskiwanie po awarii dla obciążenia. Aby dowiedzieć się, jak to zrobić, zobacz Konfigurowanie środowiska źródłowego na potrzeby replikacji programu VMware na platformę Azure.
Wdrażanie dodatkowych serwerów przetwarzania
W przypadku skalowania wdrożenia poza 200 maszyn źródłowych lub całkowitego dziennego współczynnika zmian wynoszącym ponad 2 TB należy dodać serwery przetwarzania w celu obsługi woluminu ruchu. Ulepszyliśmy produkt w wersji 9.24, aby zapewnić alerty serwera przetwarzania w momencie konfigurowania serwera przetwarzania skalowalnego w poziomie. Skonfiguruj serwer przetwarzania, aby chronić nowe maszyny źródłowe lub równoważyć obciążenie.
Migrowanie maszyn do korzystania z nowego serwera przetwarzania
Wybierz pozycję Ustawienia>Serwery usługi Site Recovery. Wybierz serwer konfiguracji, a następnie rozwiń węzeł Serwery przetwarzania.
Kliknij prawym przyciskiem myszy aktualnie używany serwer przetwarzania, a następnie wybierz pozycję Przełącz.
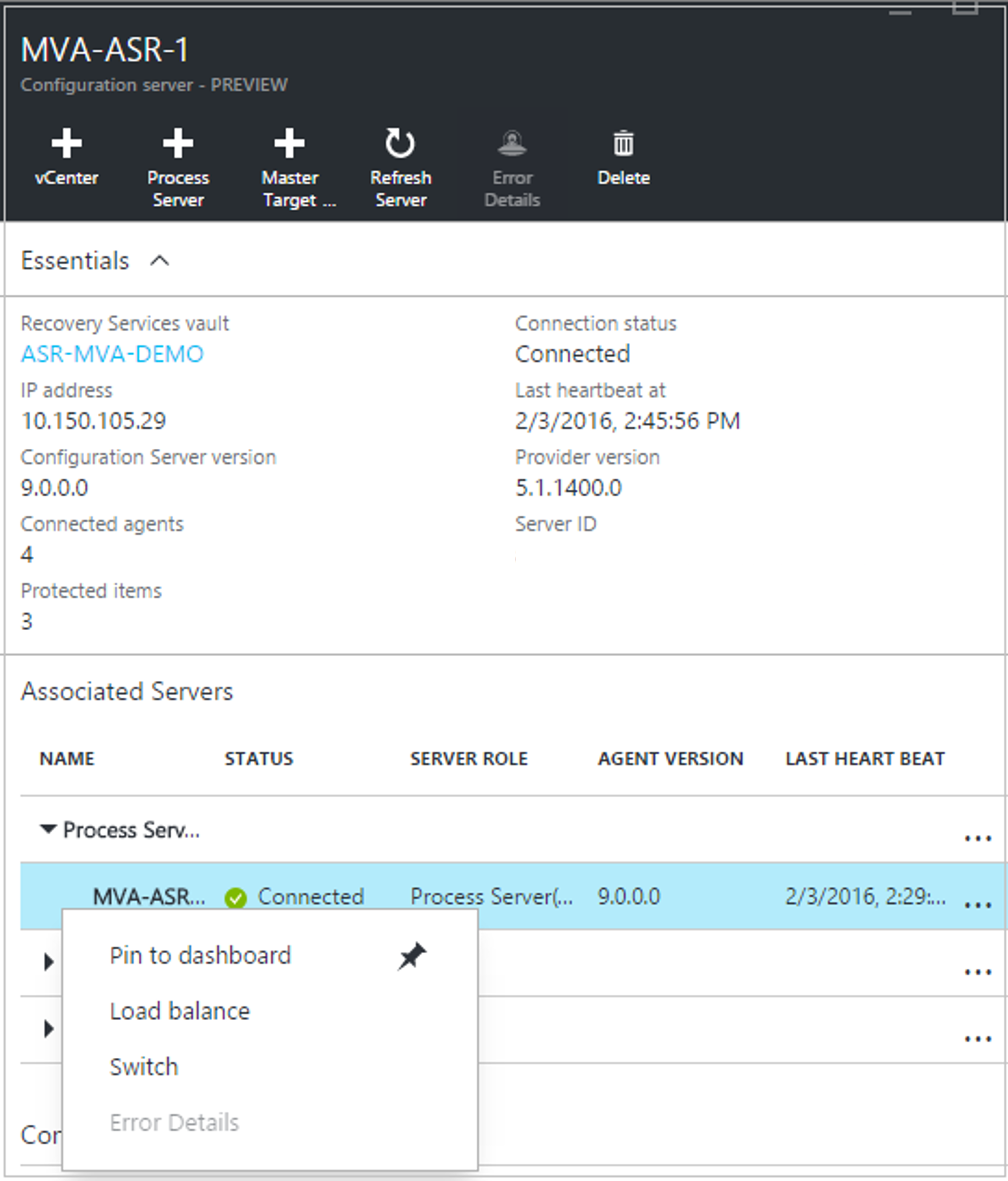
W obszarze Wybierz docelowy serwer przetwarzania wybierz nowy serwer przetwarzania, którego chcesz użyć. Następnie wybierz maszyny wirtualne, które będą obsługiwane przez serwer. Aby uzyskać informacje o serwerze, wybierz ikonę informacji. Aby ułatwić podejmowanie decyzji dotyczących obciążenia, jest wyświetlana średnia przestrzeń wymagana do replikowania każdej wybranej maszyny wirtualnej do nowego serwera przetwarzania. Wybierz znacznik wyboru, aby rozpocząć replikację do nowego serwera przetwarzania.
Wdrażanie dodatkowych głównych serwerów docelowych
W następujących scenariuszach wymagany jest więcej niż jeden główny serwer docelowy:
- Chcesz chronić maszynę wirtualną opartą na systemie Linux.
- Główny serwer docelowy dostępny na serwerze konfiguracji nie ma dostępu do magazynu danych maszyny wirtualnej.
- Całkowita liczba dysków na głównym serwerze docelowym (liczba dysków lokalnych na serwerze oraz liczba dysków do ochrony) jest większa niż 60 dysków.
Aby dowiedzieć się, jak dodać główny serwer docelowy dla maszyny wirtualnej opartej na systemie Linux, zobacz Instalowanie głównego serwera docelowego systemu Linux na potrzeby powrotu po awarii.
Aby dodać główny serwer docelowy dla maszyny wirtualnej opartej na systemie Windows:
Przejdź do pozycji Serwery konfiguracji infrastruktury>usługi Site Recovery magazynu>usługi Recovery.
Wybierz wymagany serwer konfiguracji, a następnie wybierz pozycję Główny serwer docelowy.
Pobierz ujednolicony plik instalacyjny, a następnie uruchom plik na maszynie wirtualnej, aby skonfigurować główny serwer docelowy.
Wybierz pozycję Zainstaluj główny element docelowy>Dalej.
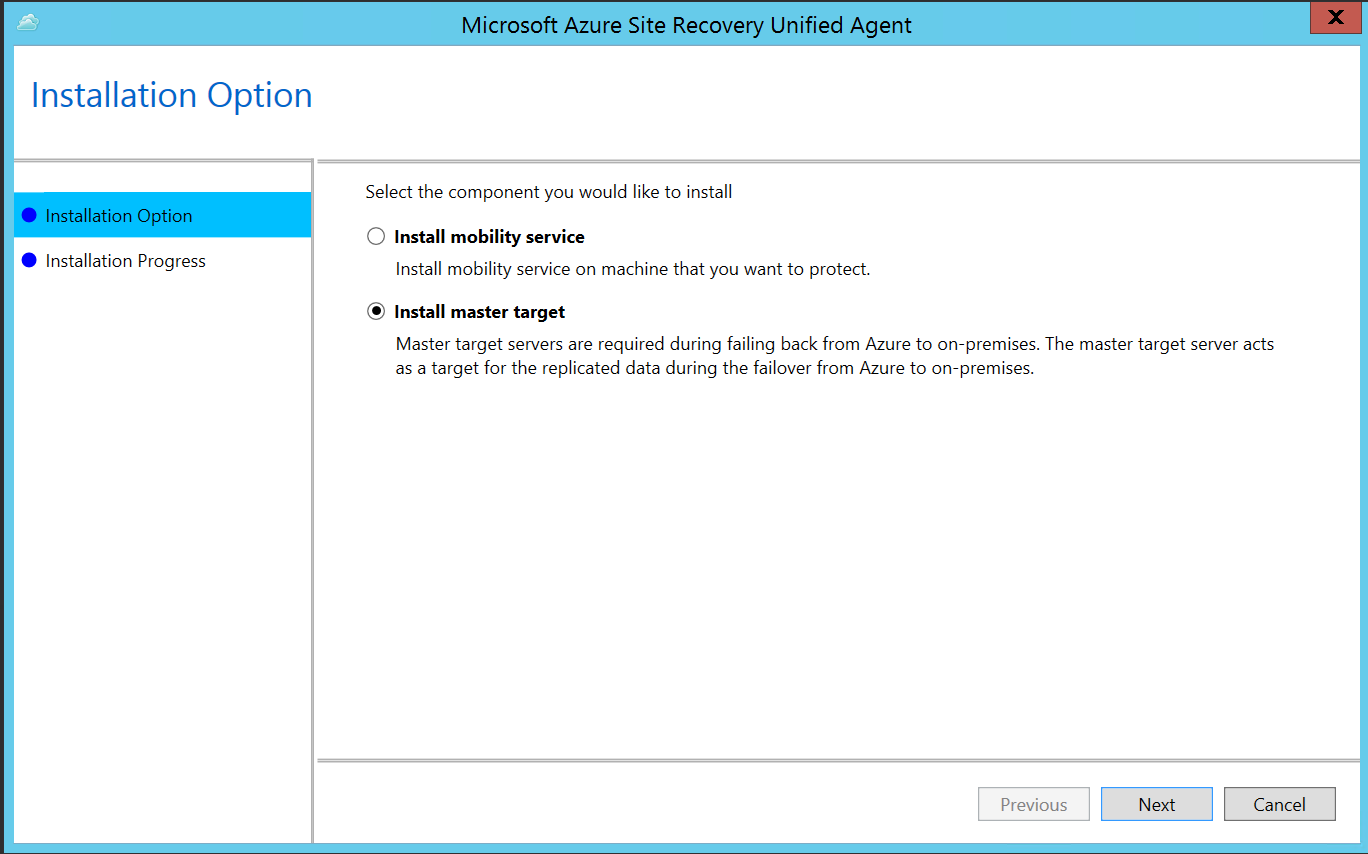
Wybierz domyślną lokalizację instalacji, a następnie wybierz pozycję Zainstaluj.
Aby zarejestrować główny obiekt docelowy na serwerze konfiguracji, wybierz pozycję Kontynuuj konfigurację.
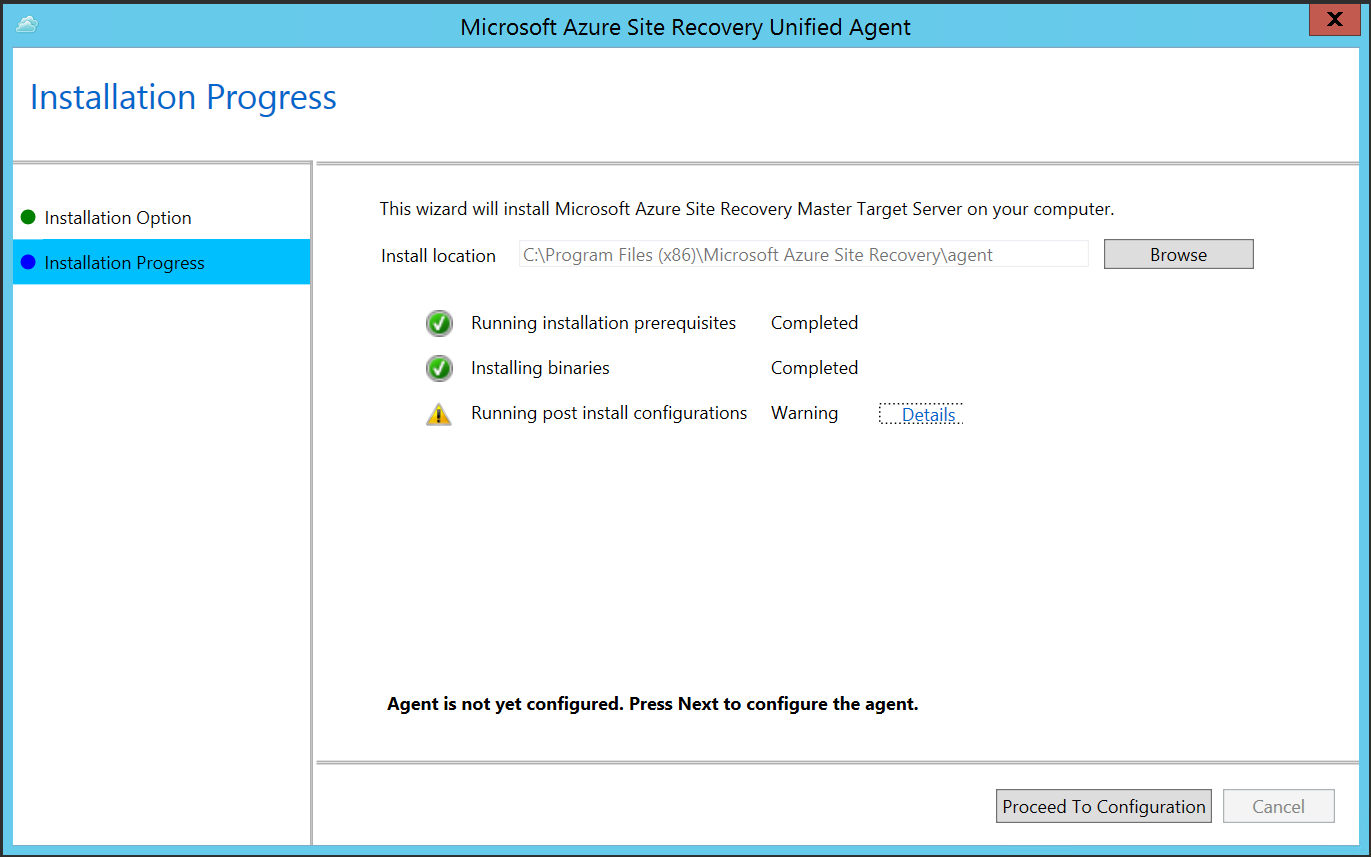
Wprowadź adres IP serwera konfiguracji, a następnie wprowadź hasło. Aby dowiedzieć się, jak wygenerować hasło, zobacz Generowanie hasła serwera konfiguracji.
Wybierz pozycję Zarejestruj. Po zakończeniu rejestracji wybierz pozycję Zakończ.
Po pomyślnym zakończeniu rejestracji serwer jest wymieniony w witrynie Azure Portal na serwerach konfiguracji infrastruktury>usługi Site Recovery magazynu>usługi Recovery w głównych serwerach docelowych serwera konfiguracji.
Uwaga
Pobierz najnowszą wersję głównego serwera docelowego ujednoliconego pliku instalacyjnego dla systemu Windows.
Następne kroki
Pobierz i uruchom planistę wdrażania usługi Site Recovery.