Używanie pakietów zewnętrznych z notesami Jupyter Notebook w klastrach Apache Spark w usłudze HDInsight
Dowiedz się, jak skonfigurować notes Jupyter w klastrze Apache Spark w usłudze HDInsight, aby używać zewnętrznych, współtworowanych przez społeczność pakietów apache maven , które nie są dołączone do gotowego rozwiązania w klastrze.
Możesz wyszukać pełną listę dostępnych pakietów w repozytorium Maven. Możesz również uzyskać listę dostępnych pakietów z innych źródeł. Na przykład pełna lista pakietów współtworzynych przez społeczność jest dostępna w temacie Pakiety Spark.
W tym artykule dowiesz się, jak używać pakietu spark-csv z notesem Jupyter Notebook.
Wymagania wstępne
Klaster Apache Spark w usłudze HDInsight. Aby uzyskać instrukcje, zobacz Tworzenie klastra platformy Apache Spark w usłudze Azure HDInsight.
Znajomość zagadnień dotyczących używania notesów Jupyter za pomocą platformy Spark w usłudze HDInsight. Aby uzyskać więcej informacji, zobacz Ładowanie danych i uruchamianie zapytań za pomocą platformy Apache Spark w usłudze HDInsight.
Schemat identyfikatora URI dla magazynu podstawowego klastrów. Dotyczy to
wasb://usługi Azure Storageabfs://dla usługi Azure Data Lake Storage Gen2. Jeśli bezpieczny transfer jest włączony dla usługi Azure Storage lub Data Lake Storage Gen2, identyfikator URI towasbs://lubabfss://, odpowiednio Zobacz, bezpieczny transfer.
Używanie pakietów zewnętrznych z notesami Jupyter Notebook
Przejdź do lokalizacji, w
https://CLUSTERNAME.azurehdinsight.net/jupyterktórejCLUSTERNAMEznajduje się nazwa klastra Spark.Utwórz nowy notes. Wybierz pozycję Nowy, a następnie wybierz pozycję Spark.
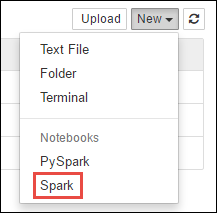
Zostanie utworzony i otwarty nowy notes o nazwie Untitled.pynb. Wybierz nazwę notesu u góry i wprowadź przyjazną nazwę.
Użyjesz
%%configuremagii, aby skonfigurować notes do korzystania z pakietu zewnętrznego. W notesach korzystających z pakietów zewnętrznych upewnij się, że wywołasz magię%%configurew pierwszej komórce kodu. Gwarantuje to, że jądro jest skonfigurowane do używania pakietu przed rozpoczęciem sesji.Ważne
Jeśli zapomnisz skonfigurować jądro w pierwszej komórce, możesz użyć
%%configureparametru z parametrem-f, ale spowoduje to ponowne uruchomienie sesji i cały postęp zostanie utracony.Wersja usługi HDInsight Polecenie W przypadku usług HDInsight 3.5 i HDInsight 3.6 %%configure{ "conf": {"spark.jars.packages": "com.databricks:spark-csv_2.11:1.5.0" }}W przypadku usług HDInsight 3.3 i HDInsight 3.4 %%configure{ "packages":["com.databricks:spark-csv_2.10:1.4.0"] }Powyższy fragment kodu oczekuje współrzędnych maven dla pakietu zewnętrznego w repozytorium centralnym maven. W tym fragmencie
com.databricks:spark-csv_2.11:1.5.0kodu jest współrzędną maven dla pakietu spark-csv . Poniżej przedstawiono sposób konstruowania współrzędnych dla pakietu.a. Znajdź pakiet w repozytorium Maven. W tym artykule użyjemy pliku spark-csv.
b. Z repozytorium zbierz wartości GroupId, ArtifactId i Version. Upewnij się, że zebrane wartości są zgodne z klastrem. W takim przypadku używamy pakietu Scala 2.11 i Spark 1.5.0, ale może być konieczne wybranie różnych wersji dla odpowiedniej wersji języka Scala lub Spark w klastrze. Wersję języka Scala w klastrze można znaleźć, uruchamiając jądro
scala.util.Properties.versionStringSpark Jupyter lub przesyłając na platformie Spark. Wersję platformy Spark w klastrze można znaleźć, uruchamiając poleceniesc.versionw notesach Jupyter Notebook.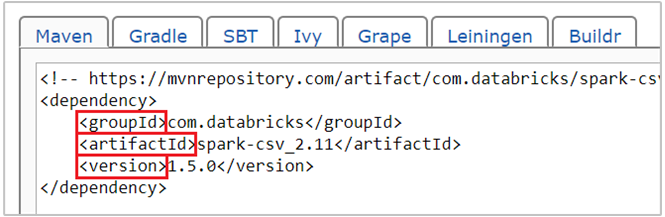
c. Połącz trzy wartości rozdzielone dwukropkiem (:).
com.databricks:spark-csv_2.11:1.5.0Uruchom komórkę kodu za pomocą magii
%%configure. Spowoduje to skonfigurowanie bazowej sesji usługi Livy do korzystania z podanego pakietu. W kolejnych komórkach w notesie można teraz użyć pakietu, jak pokazano poniżej.val df = spark.read.format("com.databricks.spark.csv"). option("header", "true"). option("inferSchema", "true"). load("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv")W przypadku usługi HDInsight 3.4 lub starszej należy użyć poniższego fragmentu kodu.
val df = sqlContext.read.format("com.databricks.spark.csv"). option("header", "true"). option("inferSchema", "true"). load("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv")Następnie możesz uruchomić fragmenty kodu, jak pokazano poniżej, aby wyświetlić dane z ramki danych utworzonej w poprzednim kroku.
df.show() df.select("Time").count()
Zobacz też
Scenariusze
- Platforma Apache Spark z usługą BI: wykonywanie interaktywnej analizy danych przy użyciu platformy Spark w usłudze HDInsight z narzędziami analizy biznesowej
- Platforma Apache Spark z usługą Machine Learning: używanie platformy Spark w usłudze HDInsight do analizowania temperatury budynku przy użyciu danych HVAC
- Platforma Apache Spark z usługą Machine Learning: przewidywanie wyników inspekcji żywności przy użyciu platformy Spark w usłudze HDInsight
- Analiza dzienników witryn internetowych przy użyciu platformy Apache Spark w usłudze HDInsight
Tworzenie i uruchamianie aplikacji
- Tworzenie autonomicznych aplikacji przy użyciu języka Scala
- Zdalne uruchamianie zadań w klastrze Apache Spark przy użyciu programu Apache Livy
Narzędzia i rozszerzenia
- Używanie zewnętrznych pakietów języka Python z notesami Jupyter Notebook w klastrach Apache Spark w usłudze HDInsight Linux
- Tworzenie i przesyłanie aplikacji Spark Scala przy użyciu dodatku HDInsight Tools Plugin for IntelliJ IDEA
- Zdalne debugowanie aplikacji Platformy Apache Spark za pomocą wtyczki HDInsight Tools dla środowiska IntelliJ IDEA
- Używanie notesów Apache Zeppelin z klastrem Apache Spark w usłudze HDInsight
- Jądra dostępne dla notesu Jupyter w klastrze Apache Spark dla usługi HDInsight
- Instalacja oprogramowania Jupyter na komputerze i nawiązywanie połączenia z klastrem Spark w usłudze HDInsight