Samouczek: tworzenie aplikacji Scala Maven dla platformy Apache Spark w usłudze HDInsight przy użyciu środowiska IntelliJ
W tym samouczku dowiesz się, jak utworzyć aplikację Apache Spark napisaną w języku Scala za pomocą narzędzia Apache Maven i środowiska IntelliJ IDEA. W tym artykule użyto narzędzia Apache Maven jako systemu kompilacji. Zaczyna się od istniejącego archetypu narzędzia Maven dla języka Scala dostarczonego przez środowisko IntelliJ IDEA. Tworzenie aplikacji Scala w środowisku IntelliJ IDEA obejmuje następujące kroki:
- Używanie narzędzia Maven jako systemu kompilacji.
- Aktualizowanie pliku POM (Project Object Model) umożliwiającego rozpoznawanie zależności modułu Spark.
- Pisanie aplikacji w języku Scala.
- Generowanie pliku jar, który można przesłać do klastrów HDInsight Spark.
- Uruchamianie aplikacji w klastrze Spark przy użyciu usługi Livy.
Z tego samouczka dowiesz się, jak wykonywać następujące czynności:
- Instalowanie wtyczki Scala dla środowiska IntelliJ IDEA
- Tworzenie aplikacji Scala Maven przy użyciu środowiska IntelliJ
- Tworzenie autonomicznego projektu Scala
Wymagania wstępne
Klaster Apache Spark w usłudze HDInsight. Aby uzyskać instrukcje, zobacz Tworzenie klastra platformy Apache Spark w usłudze Azure HDInsight.
Zestaw Oracle Java Development. W tym samouczku jest używany język Java w wersji 8.0.202.
Środowisko projektowe Java. W tym artykule użyto środowiska IntelliJ IDEA Community 2018.3.4.
Azure Toolkit for IntelliJ. Zobacz Installing the Azure Toolkit for IntelliJ (Instalowanie zestawu Azure Toolkit for IntelliJ).
Instalowanie wtyczki Scala dla środowiska IntelliJ IDEA
Wykonaj następujące kroki, aby zainstalować wtyczkę Scala:
Otwórz środowisko IntelliJ IDEA.
Na ekranie powitalnym przejdź do pozycji Configure (Konfiguruj)>Plugins (Wtyczki), aby otworzyć okno Plugins (Wtyczki).
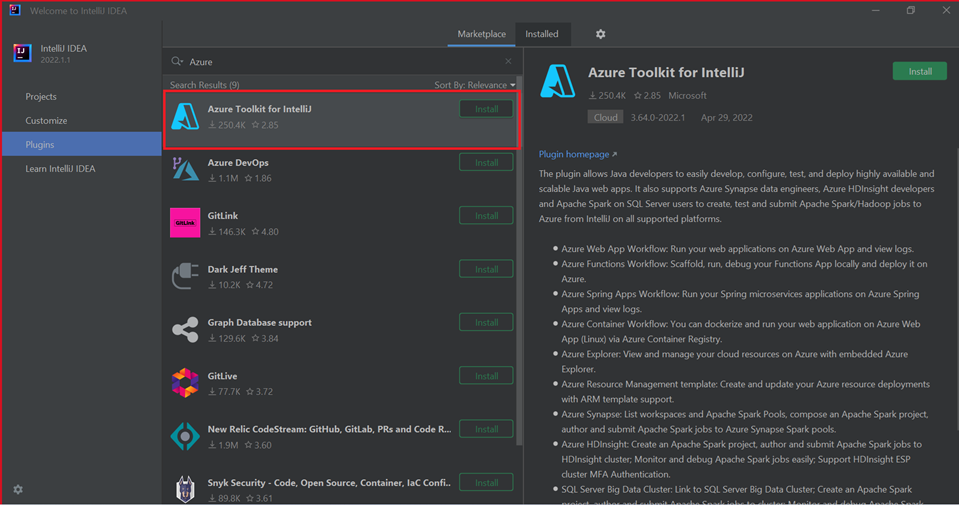
Wybierz pozycję Zainstaluj dla zestawu narzędzi Azure Toolkit for IntelliJ.
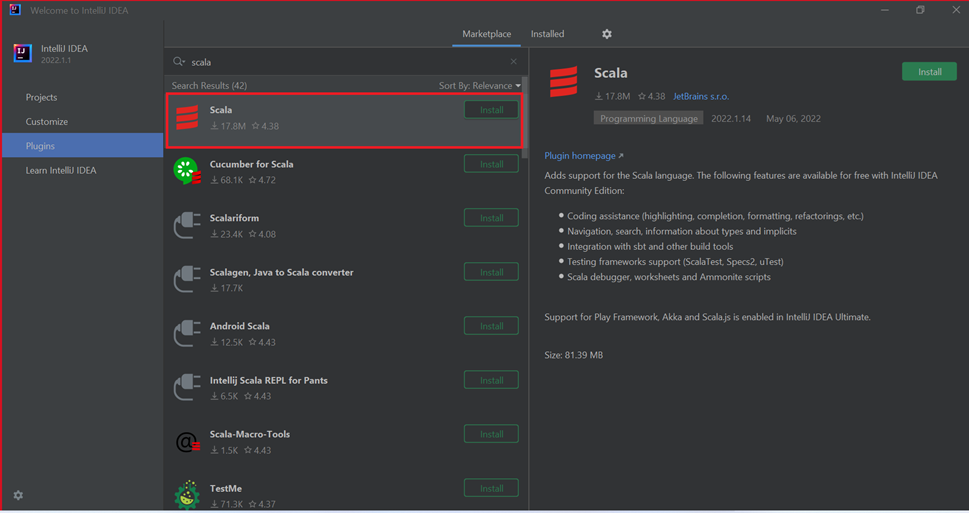
Wybierz pozycję Install (Instaluj) dla wtyczki Scala, która zostanie wyświetlona w nowym oknie.
Po pomyślnym zainstalowaniu wtyczki musisz ponownie uruchomić środowisko IDE.
Tworzenie aplikacji przy użyciu środowiska IntelliJ
Uruchom środowisko IntelliJ IDEA i wybierz pozycję Create New Project (Utwórz nowy projekt), aby otworzyć okno New Project (Nowy projekt).
Wybierz pozycję Apache Spark/HDInsight w okienku po lewej stronie.
Wybierz pozycję Spark Project (Scala) w głównym oknie.
Z listy rozwijanej Narzędzie kompilacji wybierz jedną z następujących wartości:
- Maven — w celu obsługi kreatora tworzenia projektu Scala.
- SBT — na potrzeby zarządzania zależnościami i kompilacji projektu Scala.
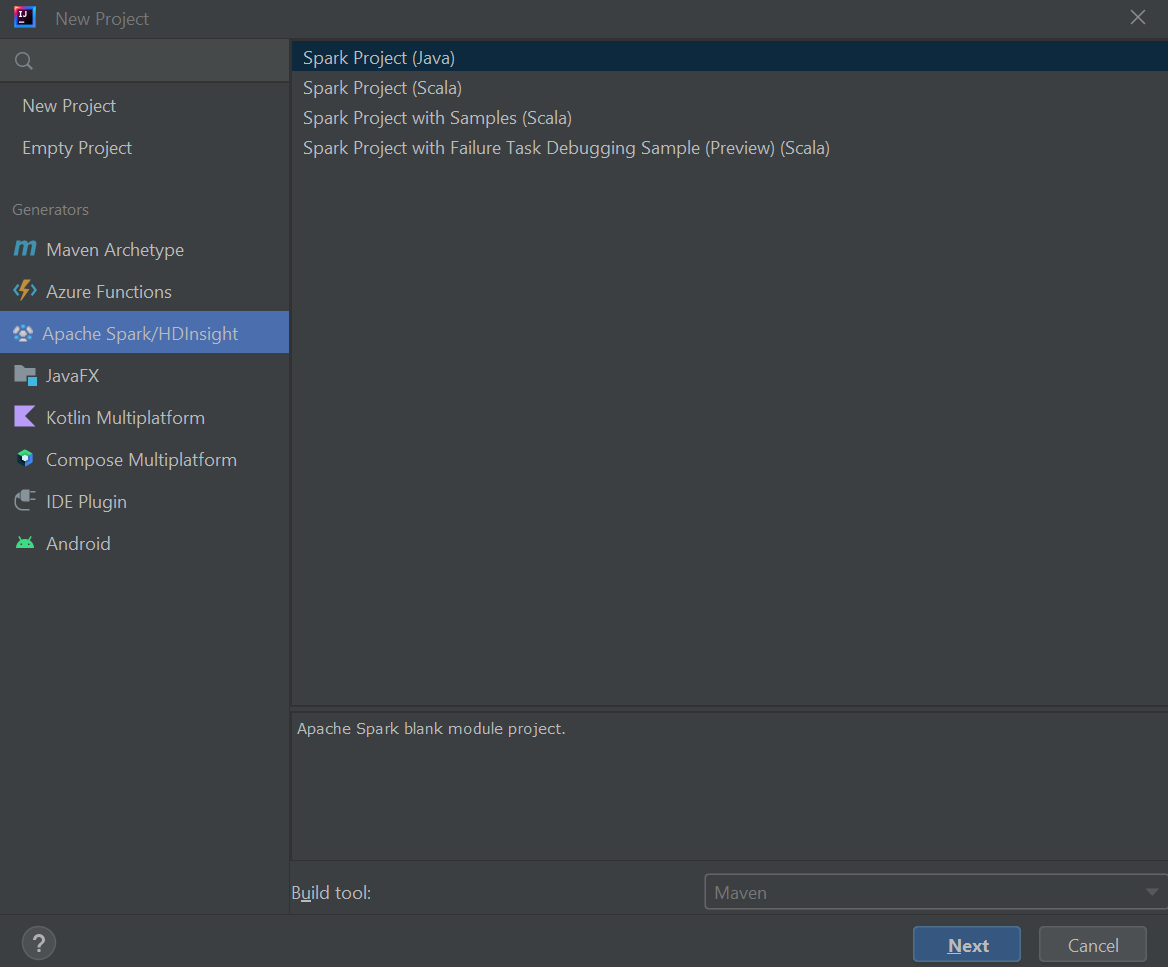
Wybierz Dalej.
W oknie New Project (Nowy projekt) podaj następujące informacje:
Właściwości opis Nazwa projektu Wprowadź nazwę. Lokalizacja projektu Wprowadź lokalizację do zapisania projektu. Zestaw SDK projektu To pole będzie puste podczas pierwszego użycia środowiska IDEA. Wybierz pozycję New... (Nowy...) i przejdź do swojego zestawu JDK. Wersja platformy Spark Kreator tworzenia integruje poprawną wersję dla zestawów Spark SDK i Scala SDK. Jeśli wersja klastra Spark jest starsza niż 2.0, wybierz wartość Spark 1.x. W przeciwnym razie wybierz Spark2.x. W tym przykładzie używana jest wersja Spark 2.3.0 (Scala 2.11.8). 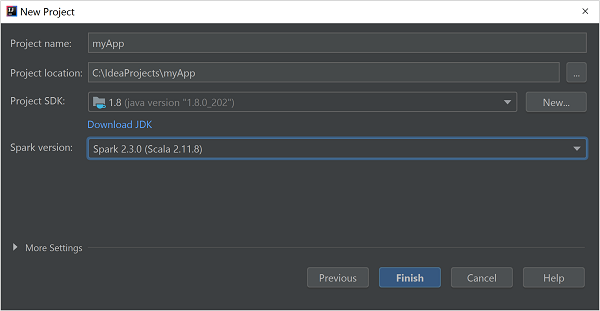
Wybierz Zakończ.
Tworzenie autonomicznego projektu Scala
Uruchom środowisko IntelliJ IDEA i wybierz pozycję Create New Project (Utwórz nowy projekt), aby otworzyć okno New Project (Nowy projekt).
Wybierz pozycję Maven w okienku po lewej stronie.
Wskaż zestaw SDK projektu. Jeśli jest pusty, wybierz pozycję New... (Nowy...) i przejdź do katalogu instalacyjnego Java.
Zaznacz pole wyboru Create from archetype (Utwórz z archetypu).
Z listy archetypów wybierz pozycję
org.scala-tools.archetypes:scala-archetype-simple. Ten archetyp pozwala utworzyć prawidłową strukturę katalogów i pobrać wymagane zależności domyślne, umożliwiające napisanie programu w języku Scala.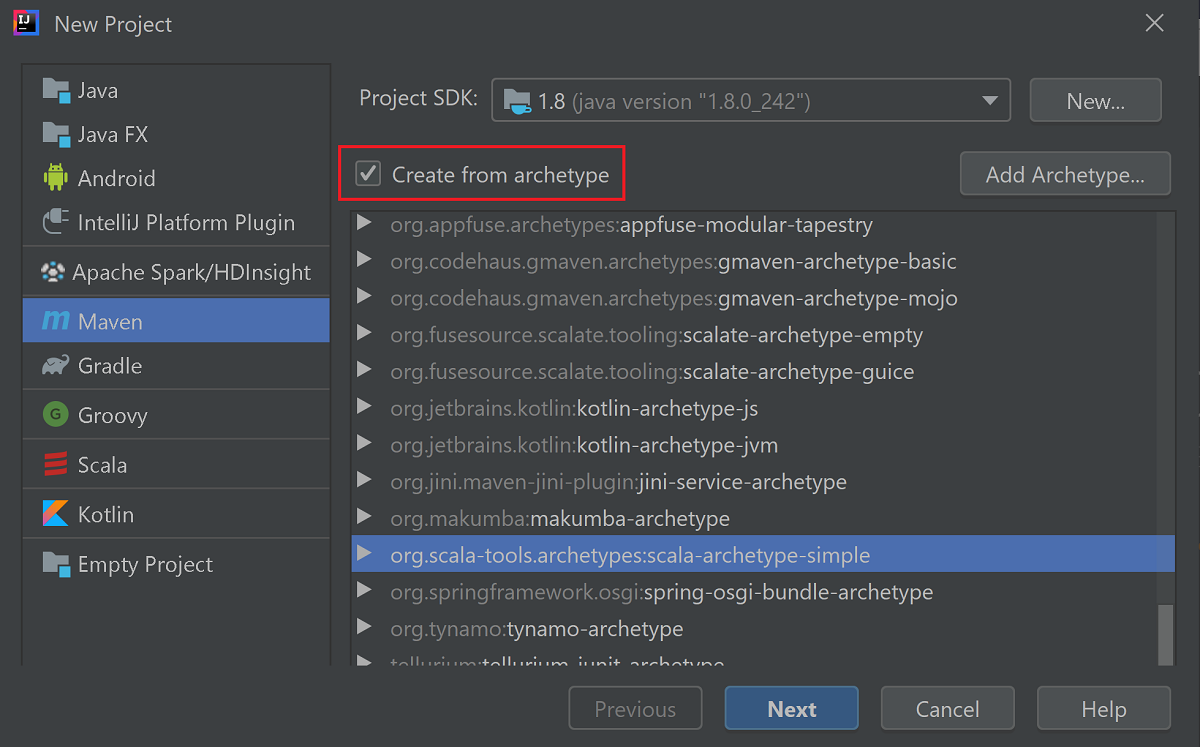
Wybierz Dalej.
Rozwiń węzeł Współrzędne artefaktu. Podaj odpowiednie wartości dla wartości GroupId i ArtifactId. Nazwa i Lokalizacja zostaną automatycznie wypełniane. W tym samouczku są one następujące:
- GroupId: com.microsoft.spark.example
- ArtifactId: SparkSimpleApp
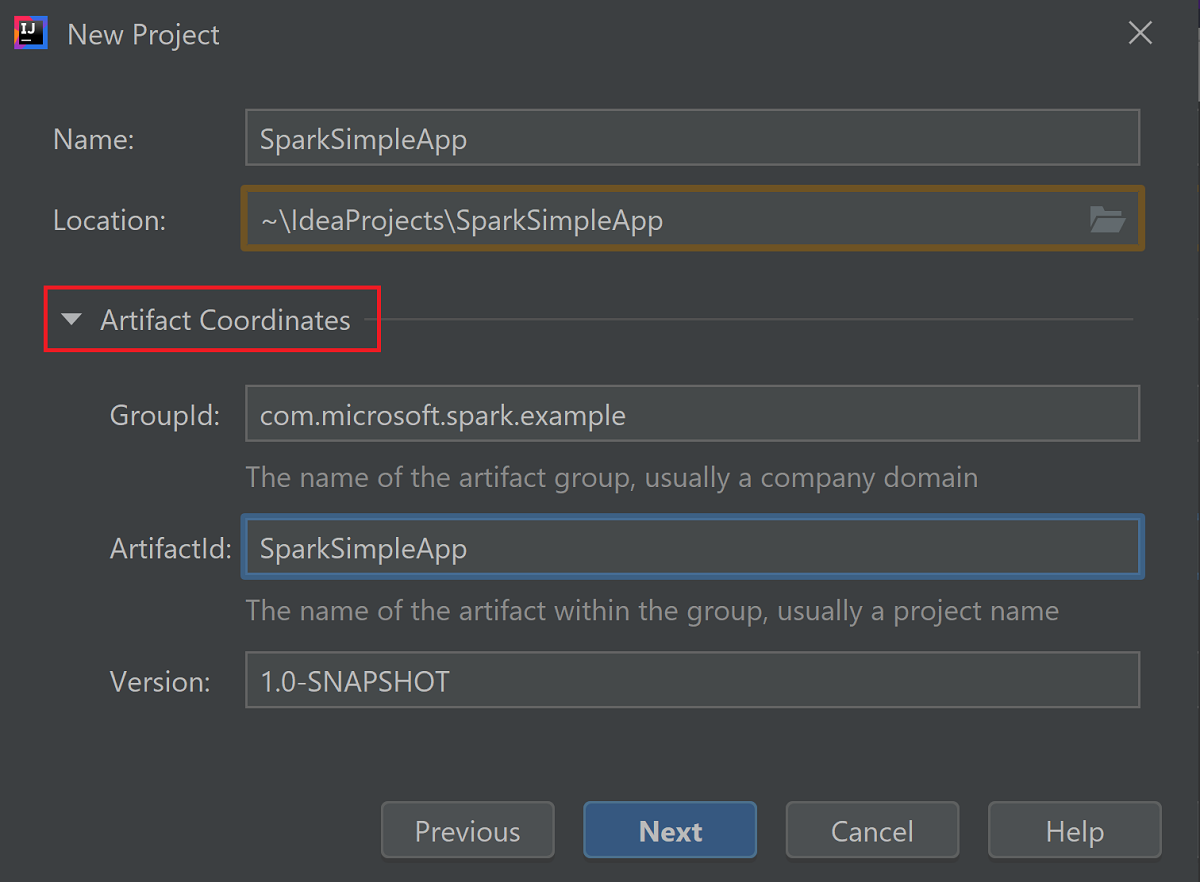
Wybierz Dalej.
Sprawdź ustawienia, a następnie wybierz pozycję Next (Dalej).
Sprawdź nazwę i lokalizację projektu, a następnie wybierz pozycję Finish (Zakończ). Zaimportowanie projektu potrwa kilka minut.
Po zaimportowaniu projektu w lewym okienku przejdź do pozycji SparkSimpleApp>src>test>scala>com>microsoft>spark>example. Kliknij prawym przyciskiem myszy pozycję MySpec, a następnie wybierz polecenie Usuń.... Nie potrzebujesz tego pliku dla aplikacji. Wybierz przycisk OK w oknie dialogowym.
W kolejnych krokach zaktualizujesz pom.xml , aby zdefiniować zależności aplikacji Spark Scala. Aby te zależności były pobierane i rozwiązywane automatycznie, należy skonfigurować narzędzie Maven.
W menu File (Plik) wybierz polecenie Settings (Ustawienia), aby otworzyć okno Settings (Ustawienia).
W oknie Settings (Ustawienia) wybierz pozycję Build, Execution, Deployment (Kompilacja, wykonywanie, wdrażanie)>Build Tools (Narzędzia kompilacji)>Maven>Importing (Importowanie).
Zaznacz pole wyboru Import Maven projects automatically (Importuj projekty Maven automatycznie).
Wybierz Zastosuj, a następnie wybierz OK. Następnie nastąpi powrót do okna projektu.
:::image type="content" source="./media/apache-spark-create-standalone-application/configure-maven-download.png" alt-text="Configure Maven for automatic downloads." border="true":::W okienku po lewej stronie przejdź do pozycji src>main>scala>com.microsoft.spark.example, a następnie kliknij dwukrotnie pozycję App, aby otworzyć plik App.scala.
Zastąp przykładowy kod następującym kodem i zapisz zmiany. Ten kod odczytuje dane z HVAC.csv (dostępne we wszystkich klastrach spark usługi HDInsight). Pobiera wiersze, które mają tylko jedną cyfrę w szóstej kolumnie. Następnie zapisuje dane wyjściowe do /HVACOut w domyślnym kontenerze magazynu dla klastra.
package com.microsoft.spark.example import org.apache.spark.SparkConf import org.apache.spark.SparkContext /** * Test IO to wasb */ object WasbIOTest { def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("WASBIOTest") val sc = new SparkContext(conf) val rdd = sc.textFile("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows which have only one digit in the 7th column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasb:///HVACout") } }W lewym okienku kliknij dwukrotnie plik pom.xml.
W sekcji
<project>\<properties>dodaj następujące segmenty:<scala.version>2.11.8</scala.version> <scala.compat.version>2.11.8</scala.compat.version> <scala.binary.version>2.11</scala.binary.version>W sekcji
<project>\<dependencies>dodaj następujące segmenty:<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_${scala.binary.version}</artifactId> <version>2.3.0</version> </dependency>Save changes to pom.xml.Utwórz plik jar. Środowisko IntelliJ IDEA umożliwia tworzenie plików JAR jako artefaktów projektu. Wykonaj poniższe kroki.
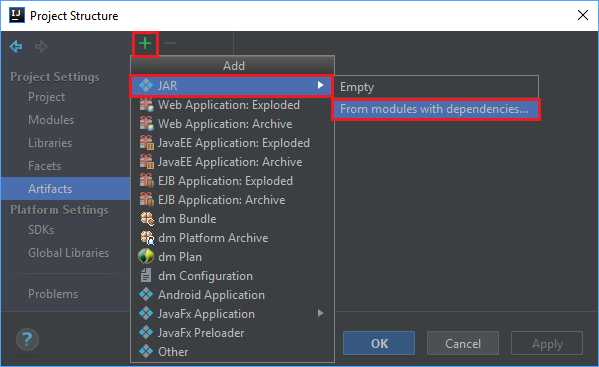
W menu File (Plik) wybierz pozycję Project Structure... (Struktura projektu...).
W oknie Project Structure (Struktura projektu) przejdź do pozycji Artifacts (Artefakty)>symbol znaku plus +>JAR>From modules with dependencies... (Z modułów z zależnościami).
W oknie Create JAR from Modules (Tworzenie pliku JAR z modułów) wybierz ikonę folderu w polu tekstowym Main Class (Klasa główna).
W oknie Select Main Class (Wybieranie klasy głównej) wybierz domyślną klasę, a następnie wybierz przycisk OK.
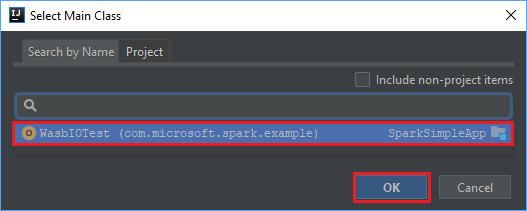
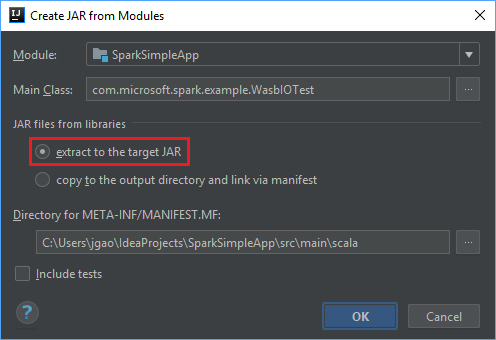
W oknie Create JAR from Modules (Tworzenie pliku JAR z modułów) sprawdź, czy jest wybrana opcja extract to the target JAR (Wyodrębnij do docelowego pliku JAR), a następnie wybierz przycisk OK. Wybranie tego ustawienia powoduje utworzenie pojedynczego pliku JAR zawierającego wszystkie zależności.
Karta Output Layout (Układ danych wyjściowych) zawiera listę wszystkich plików JAR, które są częścią projektu Maven. Możesz usunąć pliki, z którymi aplikacja Scala nie ma bezpośrednich zależności. W przypadku aplikacji, którą tworzysz tutaj, możesz usunąć wszystkie, ale ostatnie (dane wyjściowe kompilacji SparkSimpleApp). Wybierz pliki JAR do usunięcia, a następnie wybierz symbol znaku minus -.
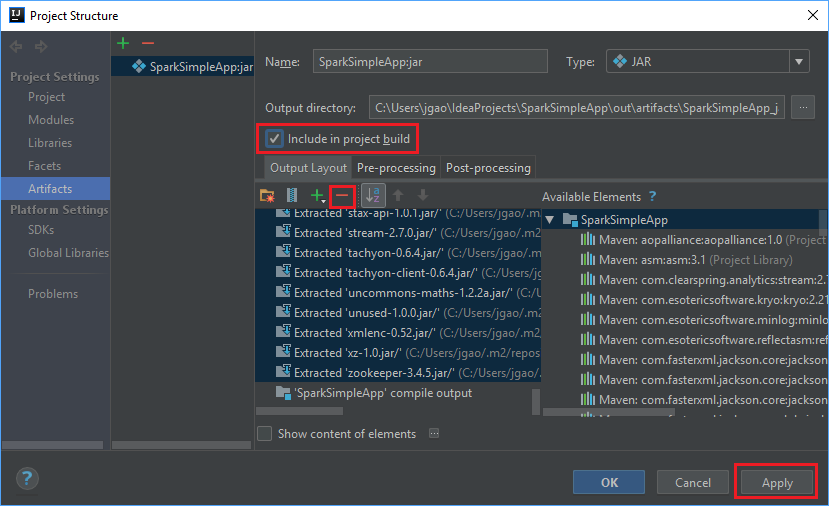
Upewnij się, że pole wyboru Uwzględnij w kompilacji projektu jest zaznaczone. Ta opcja gwarantuje, że plik jar jest tworzony za każdym razem, gdy projekt zostanie skompilowany lub zaktualizowany. Wybierz przycisk Apply (Zastosuj), a następnie przycisk OK.
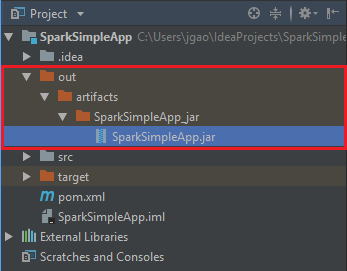
Aby utworzyć plik jar, przejdź do pozycji Build (Kompilacja)>Build Artifacts (Artefakty kompilacji)>Build (Kompilacja). Projekt zostanie skompilowany w ciągu około 30 sekund. Wyjściowy plik JAR jest tworzony w lokalizacji \out\artifacts.
Uruchamianie aplikacji w klastrze Apache Spark
Aplikację można uruchomić w klastrze przy użyciu następujących metod:
Skopiuj plik jar aplikacji do obiektu blob usługi Azure Storage skojarzonego z klastrem. Możesz to zrobić za pomocą narzędzia wiersza polecenia AzCopy. Dane możesz przesłać również przy użyciu wielu innych klientów. Więcej informacji na ten temat można znaleźć w artykule Przekazywanie danych dla zadań Apache Hadoop w usłudze HDInsight.
Użyj usługi Apache Livy, aby zdalnie przesłać zadanie aplikacji do klastra Spark. Klastry Spark w usłudze HDInsight zawierają usługę Livy, która udostępnia punkty końcowe REST umożliwiające zdalne przesyłanie zadań Spark. Aby uzyskać więcej informacji, zobacz Submit Apache Spark jobs remotely using Apache Livy with Spark clusters on HDInsight (Zdalne przesyłanie zadań Apache Spark przy użyciu usługi Apache Livy udostępnianej w klastrach Spark w usłudze HDInsight).
Czyszczenie zasobów
Jeśli nie zamierzasz nadal korzystać z tej aplikacji, usuń utworzony klaster, wykonując następujące czynności:
Zaloguj się w witrynie Azure Portal.
W polu Wyszukaj w górnej części wpisz HDInsight.
Wybierz pozycję Klastry usługi HDInsight w obszarze Usługi.
Na wyświetlonej liście klastrów usługi HDInsight wybierz pozycję ... obok klastra utworzonego na potrzeby tego samouczka.
Wybierz Usuń. Wybierz opcję Tak.
Następny krok
W tym artykule przedstawiono sposób tworzenia aplikacji Apache Spark Scala. Przejdź do następnego artykułu, aby dowiedzieć się, jak uruchomić tę aplikację w klastrze HDInsight Spark przy użyciu usługi Livy.