Przekształcanie danych przez uruchomienie notesu usługi Databricks
DOTYCZY:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
Działanie notesu usługi Azure Databricks w potoku uruchamia notes usługi Databricks w obszarze roboczym usługi Azure Databricks. Ten artykuł opiera się na artykule dotyczącym działań przekształcania danych, który zawiera ogólne omówienie transformacji danych i obsługiwanych działań przekształcania. Azure Databricks to zarządzana platforma do uruchamiania platformy Apache Spark.
Notes usługi Databricks można utworzyć przy użyciu szablonu usługi ARM przy użyciu formatu JSON lub bezpośrednio za pomocą interfejsu użytkownika usługi Azure Data Factory Studio. Aby zapoznać się z szczegółowym przewodnikiem dotyczącym tworzenia działania notesu usługi Databricks przy użyciu interfejsu użytkownika, zapoznaj się z samouczkiem Uruchamianie notesu usługi Databricks przy użyciu działania notesu notesu usługi Databricks w usłudze Azure Data Factory.
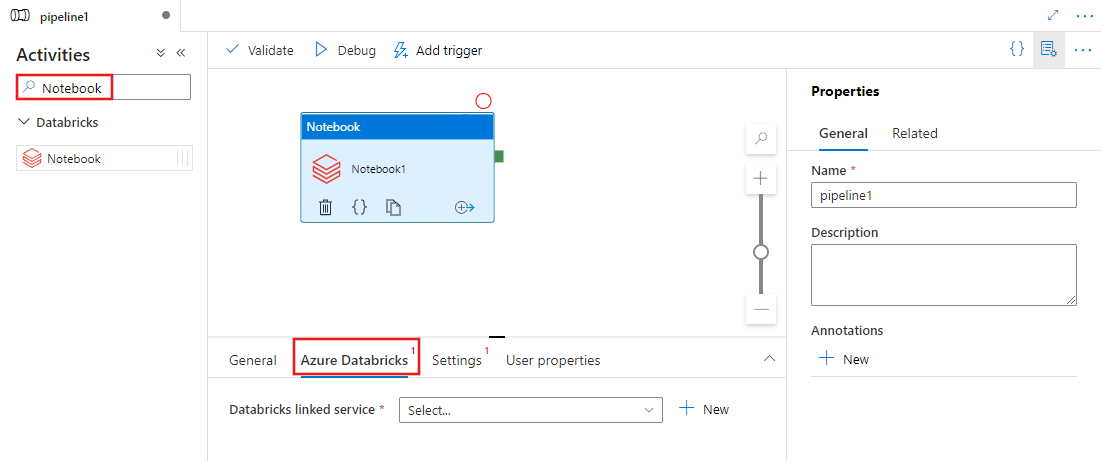
Dodawanie działania notesu dla usługi Azure Databricks do potoku za pomocą interfejsu użytkownika
Aby użyć działania notesu dla usługi Azure Databricks w potoku, wykonaj następujące kroki:
Wyszukaj pozycję Notes w okienku Działania potoku i przeciągnij działanie Notes na kanwę potoku.
Wybierz nowe działanie Notes na kanwie, jeśli nie zostało jeszcze wybrane.
Wybierz kartę Azure Databricks , aby wybrać lub utworzyć nową połączoną usługę Azure Databricks, która wykona działanie Notes.
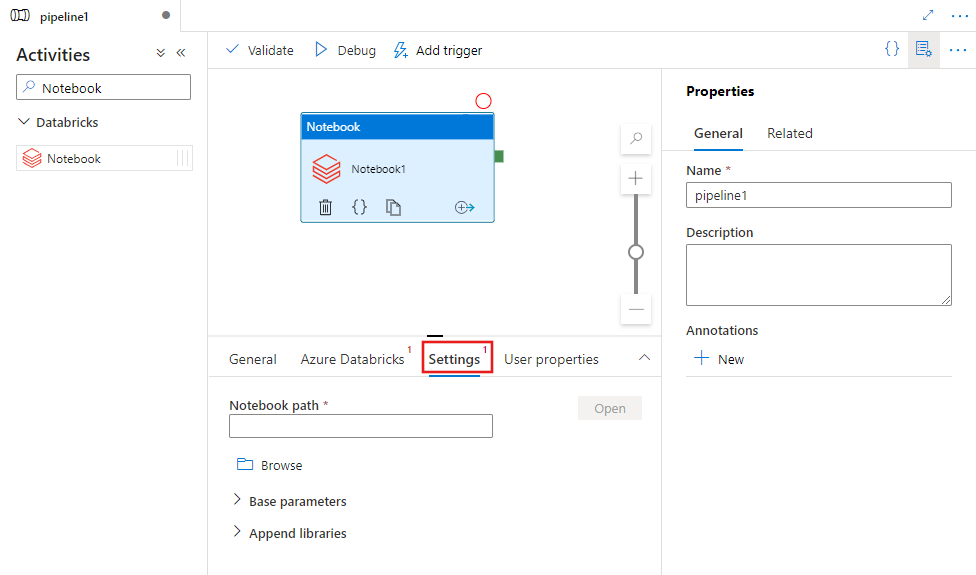
Wybierz kartę Ustawienia i określ ścieżkę notesu do wykonania w usłudze Azure Databricks, opcjonalne parametry podstawowe, które mają zostać przekazane do notesu, oraz wszystkie inne biblioteki, które mają zostać zainstalowane w klastrze w celu wykonania zadania.
Definicja działania notesu usługi Databricks
Oto przykładowa definicja JSON działania notesu usługi Databricks:
{
"activity": {
"name": "MyActivity",
"description": "MyActivity description",
"type": "DatabricksNotebook",
"linkedServiceName": {
"referenceName": "MyDatabricksLinkedservice",
"type": "LinkedServiceReference"
},
"typeProperties": {
"notebookPath": "/Users/user@example.com/ScalaExampleNotebook",
"baseParameters": {
"inputpath": "input/folder1/",
"outputpath": "output/"
},
"libraries": [
{
"jar": "dbfs:/docs/library.jar"
}
]
}
}
}
Właściwości działania notesu usługi Databricks
W poniższej tabeli opisano właściwości JSON używane w definicji JSON:
| Właściwości | Opis | Wymagania |
|---|---|---|
| name | Nazwa działania w potoku. | Tak |
| opis | Tekst opisujący działanie. | Nie. |
| type | W przypadku działania notesu usługi Databricks typ działania to DatabricksNotebook. | Tak |
| linkedServiceName | Nazwa połączonej usługi Databricks, na której działa notes usługi Databricks. Aby dowiedzieć się więcej o tej połączonej usłudze, zobacz artykuł Dotyczący połączonych usług obliczeniowych. | Tak |
| notebookPath | Ścieżka bezwzględna notesu do uruchomienia w obszarze roboczym usługi Databricks. Ta ścieżka musi zaczynać się od ukośnika. | Tak |
| baseParameters | Tablica par Klucz-Wartość. Parametry podstawowe mogą być używane dla każdego przebiegu działania. Jeśli notes przyjmuje parametr, który nie jest określony, zostanie użyta wartość domyślna z notesu. Więcej informacji na temat parametrów można znaleźć w notesach usługi Databricks. | Nie. |
| biblioteki | Lista bibliotek, które mają być zainstalowane w klastrze, które będą wykonywać zadanie. Może to być tablica ciągów <, obiektów>. | Nie. |
Obsługiwane biblioteki dla działań usługi Databricks
W powyższej definicji działania usługi Databricks należy określić następujące typy bibliotek: jar, egg, whl, maven, pypi, cran.
{
"libraries": [
{
"jar": "dbfs:/mnt/libraries/library.jar"
},
{
"egg": "dbfs:/mnt/libraries/library.egg"
},
{
"whl": "dbfs:/mnt/libraries/mlflow-0.0.1.dev0-py2-none-any.whl"
},
{
"whl": "dbfs:/mnt/libraries/wheel-libraries.wheelhouse.zip"
},
{
"maven": {
"coordinates": "org.jsoup:jsoup:1.7.2",
"exclusions": [ "slf4j:slf4j" ]
}
},
{
"pypi": {
"package": "simplejson",
"repo": "http://my-pypi-mirror.com"
}
},
{
"cran": {
"package": "ada",
"repo": "https://cran.us.r-project.org"
}
}
]
}
Aby uzyskać więcej informacji, zobacz dokumentację usługi Databricks dotyczącą typów bibliotek.
Przekazywanie parametrów między notesami i potokami
Parametry można przekazywać do notesów przy użyciu właściwości baseParameters w działaniu usługi databricks.
W niektórych przypadkach może być wymagane przekazanie niektórych wartości z notesu z powrotem do usługi, które mogą być używane do kontroli przepływu (kontrole warunkowe) w usłudze lub być używane przez działania podrzędne (limit rozmiaru to 2 MB).
W notesie możesz wywołać metodę dbutils.notebook.exit("returnValue"), a odpowiednie wyrażenie "returnValue" zostanie zwrócone do usługi.
Dane wyjściowe w usłudze można używać przy użyciu wyrażenia, takiego jak
@{activity('databricks notebook activity name').output.runOutput}.Ważne
Jeśli przekazujesz obiekt JSON, możesz pobrać wartości, dołączając nazwy właściwości. Przykład:
@{activity('databricks notebook activity name').output.runOutput.PropertyName}
Jak przekazać bibliotekę w usłudze Databricks
Możesz użyć interfejsu użytkownika obszaru roboczego:
Korzystanie z interfejsu użytkownika obszaru roboczego usługi Databricks
Aby uzyskać ścieżkę dbfs biblioteki dodanej przy użyciu interfejsu użytkownika, możesz użyć interfejsu wiersza polecenia usługi Databricks.
Zazwyczaj biblioteki Jar są przechowywane w obszarze dbfs:/FileStore/jars podczas korzystania z interfejsu użytkownika. Listę można wyświetlić za pośrednictwem interfejsu wiersza polecenia: databricks fs ls dbfs:/FileStore/job-jars
Możesz też użyć interfejsu wiersza polecenia usługi Databricks:
Postępuj zgodnie z instrukcjami kopiowania biblioteki przy użyciu interfejsu wiersza polecenia usługi Databricks
Korzystanie z interfejsu wiersza polecenia usługi Databricks (kroki instalacji)
Aby na przykład skopiować plik JAR do systemu dbfs:
dbfs cp SparkPi-assembly-0.1.jar dbfs:/docs/sparkpi.jar