Obsługiwane formaty plików i koderów koderów kompresji w usługach Azure Data Factory i Synapse Analytics (starsza wersja)
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
Ten artykuł dotyczy następujących łączników: Amazon S3, Azure Blob, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Azure Files, File System, FTP, Google Cloud Storage, HDFS, HTTP i SFTP.
Ważne
Usługa wprowadziła nowy model zestawu danych oparty na formacie, zobacz odpowiedni artykuł o formacie ze szczegółowymi informacjami:
-
Format Avro
-
Format binarny
-
Format tekstu rozdzielanego
-
Format JSON
-
Format ORC
-
Format Parquet
Pozostałe konfiguracje wymienione w tym artykule są nadal obsługiwane zgodnie ze zgodnością z poprzednimi wersjami. Zaleca się użycie nowego modelu w przyszłości.
Format tekstu (starsza wersja)
Uwaga
Zapoznaj się z nowym modelem z artykułu o formacie tekstu rozdzielanego. Następujące konfiguracje zestawu danych magazynu danych opartego na plikach są nadal obsługiwane zgodnie ze zgodnością z poprzednimi wersjami. Zaleca się użycie nowego modelu w przyszłości.
Jeśli chcesz odczytać plik tekstowy lub zapisać w pliku tekstowym, ustaw type właściwość w format sekcji zestawu danych na TextFormat. Ponadto możesz określić następujące opcjonalne właściwości w sekcji format. Aby uzyskać informacje na temat sposobu konfigurowania, zobacz sekcję Przykład formatu TextFormat.
| Właściwości | opis | Dozwolone wartości | Wymagania |
|---|---|---|---|
| columnDelimiter | Znak używany do rozdzielania kolumn w pliku. Możesz rozważyć użycie rzadkiego niedrukowalnego znaku, który może nie istnieć w danych. Na przykład określ wartość "\u0001", która reprezentuje początek nagłówka (SOH). | Dozwolony jest tylko jeden znak. Wartość domyślna to przecinek (,). Aby użyć znaku Unicode, zapoznaj się z znakami Unicode, aby uzyskać odpowiedni kod. |
Nie. |
| rowDelimiter | Znak używany do rozdzielania wierszy w pliku. | Dozwolony jest tylko jeden znak. Wartością domyślną jest dowolna z następujących wartości przy odczycie: [„\r\n”, „\r”, „\n”] oraz wartość „\r\n” przy zapisie. | Nie. |
| escapeChar | Znak specjalny służący do zmiany interpretacji ogranicznika kolumny w zawartości pliku wejściowego. W przypadku tabeli nie można określić zarówno właściwości escapeChar, jak i quoteChar. |
Dozwolony jest tylko jeden znak. Brak wartości domyślnej. Przykład: jeśli masz przecinek (',') jako ogranicznik kolumny, ale chcesz mieć znak przecinka w tekście (np. "Hello, world"), możesz zdefiniować znak "$" jako znak ucieczki i użyć ciągu "Hello$, world" w źródle. |
Nie. |
| quoteChar | Znak używany do umieszczania wartości ciągu w cudzysłowie. Ograniczniki kolumny i wiersza umieszczone w cudzysłowie są traktowane jako część wartości ciągu. Ta właściwość ma zastosowanie zarówno do wejściowych, jak i wyjściowych zestawów danych. W przypadku tabeli nie można określić zarówno właściwości escapeChar, jak i quoteChar. |
Dozwolony jest tylko jeden znak. Brak wartości domyślnej. Jeśli na przykład masz przecinek (',') jako ogranicznik kolumny, ale chcesz mieć znak przecinka w tekście (na przykład: <Hello, world), możesz zdefiniować znak " (podwójny cudzysłów) jako znak cudzysłowu i użyć ciągu "Hello, world>" w źródle. |
Nie. |
| nullValue | Co najmniej jeden znak służący do reprezentowania wartości null. | Co najmniej jeden znak. Wartości domyślne to „\N” i „NULL” przy odczycie oraz „\N” przy zapisie. | Nie. |
| encodingName | Określa nazwę kodowania. | Prawidłowa nazwa kodowania. Zobacz właściwość Encoding.EncodingName. Przykład: windows-1250 lub shift_jis. Wartość domyślna to UTF-8. | Nie. |
| firstRowAsHeader | Określa, czy pierwszy wiersz ma być traktowany jako nagłówek. W przypadku wejściowego zestawu danych usługa odczytuje pierwszy wiersz jako nagłówek. W przypadku wyjściowego zestawu danych usługa zapisuje pierwszy wiersz jako nagłówek. Aby uzyskać przykładowe scenariusze, zobacz sekcję Scenariusze użycia właściwości firstRowAsHeader oraz skipLineCount. |
Prawda False (domyślnie) |
Nie. |
| skipLineCount | Wskazuje liczbę niepustych wierszy do pominięcia podczas odczytywania danych z plików wejściowych. Jeśli określono zarówno właściwość skipLineCount, jak i firstRowAsHeader, najpierw zostaną pominięte wiersze, a następnie zostaną odczytane informacje nagłówka z pliku wejściowego. Aby uzyskać przykładowe scenariusze, zobacz sekcję Scenariusze użycia właściwości firstRowAsHeader oraz skipLineCount. |
Integer | Nie. |
| treatEmptyAsNull | Określa, czy ciąg pusty lub o wartości null ma być traktowany jako wartość null podczas odczytu danych z pliku wejściowego. |
True (domyślnie) Fałsz |
Nie. |
Przykład formatu TextFormat
W poniższej definicji JSON dla zestawu danych określono niektóre z opcjonalnych właściwości.
"typeProperties":
{
"folderPath": "mycontainer/myfolder",
"fileName": "myblobname",
"format":
{
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": ";",
"quoteChar": "\"",
"NullValue": "NaN",
"firstRowAsHeader": true,
"skipLineCount": 0,
"treatEmptyAsNull": true
}
},
Aby użyć właściwości escapeChar zamiast quoteChar, zastąp wiersz z właściwością quoteChar następującą właściwością escapeChar:
"escapeChar": "$",
Scenariusze użycia właściwości firstRowAsHeader oraz skipLineCount
- Kopiujesz dane ze źródła innego niż plik do pliku tekstowego i chcesz dodać wiersz nagłówka zawierający metadane schematu (na przykład: schemat SQL). Ustaw właściwość
firstRowAsHeaderna wartość true w zestawie danych wyjściowych dla tego scenariusza. - Kopiujesz dane z pliku tekstowego zawierającego wiersz nagłówka do ujścia innego niż plik i chcesz pominąć ten wiersz. Ustaw właściwość
firstRowAsHeaderna wartość true w zestawie danych wejściowych. - Kopiujesz dane z pliku tekstowego i chcesz pominąć kilka początkowych wierszy, które nie zawierają żadnych danych bądź informacji nagłówka. Określ właściwość
skipLineCount, aby wskazać liczbę wierszy do pominięcia. Jeśli pozostała część pliku zawiera wiersz nagłówka, możesz również określić właściwośćfirstRowAsHeader. Jeśli określono zarówno właściwośćskipLineCount, jak ifirstRowAsHeader, najpierw zostaną pominięte wiersze, a następnie zostaną odczytane informacje nagłówka z pliku wejściowego
Format JSON (starsza wersja)
Uwaga
Zapoznaj się z nowym modelem z artykułu o formacie JSON. Następujące konfiguracje zestawu danych magazynu danych opartego na plikach są nadal obsługiwane zgodnie ze zgodnością z poprzednimi wersjami. Zaleca się użycie nowego modelu w przyszłości.
Aby zaimportować/wyeksportować plik JSON zgodnie z rzeczywistym użyciem do/z usługi Azure Cosmos DB, zobacz sekcję Importowanie/eksportowanie dokumentów JSON w artykule Przenoszenie danych do/z usługi Azure Cosmos DB .
Jeśli chcesz przeanalizować pliki JSON lub zapisać dane w formacie JSON, ustaw type właściwość w format sekcji na wartość JsonFormat. Ponadto możesz określić następujące opcjonalne właściwości w sekcji format. Aby uzyskać informacje na temat sposobu konfigurowania, zobacz sekcję Przykład formatu JsonFormat.
| Właściwości | Opis | Wymagania |
|---|---|---|
| filePattern | Wskazuje wzorzec danych przechowywanych w każdym pliku JSON. Dozwolone wartości to: setOfObjects i arrayOfObjects. Wartością domyślną jest setOfObjects. Aby uzyskać szczegółowe informacje o tych wzorcach, zobacz sekcję Wzorce plików JSON. | Nie. |
| jsonNodeReference | Jeśli chcesz wykonać iterację i ekstrakcję danych z obiektów wewnątrz pola tablicy o tym samym wzorcu, określ ścieżkę JSON tej tablicy. Ta właściwość jest obsługiwana tylko podczas kopiowania danych z plików JSON. | Nie. |
| jsonPathDefinition | Określa wyrażenie ścieżki JSON dla każdego mapowania kolumny z niestandardową nazwą kolumny (musi zaczynać się małą literą). Ta właściwość jest obsługiwana tylko podczas kopiowania danych z plików JSON i można wyodrębnić dane z obiektu lub tablicy. W przypadku pól obiektu głównego na początku użyj elementu głównego $. W przypadku pól wewnątrz tablicy wybranej przez właściwość jsonNodeReference najpierw podaj element tablicy. Aby uzyskać informacje na temat sposobu konfigurowania, zobacz sekcję Przykład formatu JsonFormat. |
Nie. |
| encodingName | Określa nazwę kodowania. Aby uzyskać listę prawidłowych nazw kodowania, zobacz właściwość Encoding.EncodingName. Na przykład: windows-1250 lub shift_jis. Wartość domyślna to: UTF-8. | Nie. |
| nestingSeparator | Znak używany do rozdzielania poziomów zagnieżdżenia. Wartość domyślna to „.” (kropka). | Nie. |
Uwaga
W przypadku danych krzyżowych w tablicy do wielu wierszy (przypadek 1 —> przykład 2 w przykładach JsonFormat) można wybrać tylko rozwinięcie pojedynczej tablicy przy użyciu właściwości jsonNodeReference.
Wzorce plików JSON
działanie Kopiuj można przeanalizować następujące wzorce plików JSON:
Typ I: setOfObjects
Każdy plik zawiera pojedynczy obiekt lub wiele obiektów rozdzielonych wierszami bądź połączonych. W przypadku wybrania tej opcji w zestawie danych wyjściowych działanie kopiowania tworzy pojedynczy plik JSON z każdym obiektem w osobnym wierszu (rozdzielanie wierszami).
przykład kodu JSON z pojedynczym obiektem
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }przykład kodu JSON z obiektami rozdzielonymi wierszami
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"} {"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"} {"time":"2015-04-29T07:13:21.4370000Z","callingimsi":"466923101048691","callingnum1":"678901578","callingnum2":"345626404","switch1":"Germany","switch2":"UK"}przykład kodu JSON z obiektami połączonymi
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" } { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" } { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" }
Typ II: arrayOfObjects
Każdy plik zawiera tablicę obiektów.
[ { "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }, { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" }, { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" } ]
Przykład formatu JsonFormat
Przypadek 1. Kopiowanie danych z plików JSON
Przykład 1. Wyodrębnianie danych z obiektu i tablicy
W tym przykładzie oczekiwany jest jeden główny obiekt JSON mapowany na pojedynczy rekord w wyniku tabelarycznym. Jeśli masz plik JSON z następującą zawartością:
{
"id": "ed0e4960-d9c5-11e6-85dc-d7996816aad3",
"context": {
"device": {
"type": "PC"
},
"custom": {
"dimensions": [
{
"TargetResourceType": "Microsoft.Compute/virtualMachines"
},
{
"ResourceManagementProcessRunId": "827f8aaa-ab72-437c-ba48-d8917a7336a3"
},
{
"OccurrenceTime": "1/13/2017 11:24:37 AM"
}
]
}
}
}
i chcesz skopiować ją do tabeli usługi Azure SQL w następującym formacie przez wyodrębnienie danych z obiektu i tabeli:
| ID | deviceType | targetResourceType | resourceManagementProcessRunId | occurrenceTime |
|---|---|---|---|---|
| ed0e4960-d9c5-11e6-85dc-d7996816aad3 | PC | Microsoft.Compute/virtualMachines | 827f8aaa-ab72-437c-ba48-d8917a7336a3 | 1/13/2017 11:24:37 AM |
Zestaw danych wejściowych typu JsonFormat jest zdefiniowany następująco: (częściowa definicja zawierająca tylko stosowne fragmenty). W szczególności:
- Sekcja
structuredefiniuje niestandardowe nazwy kolumn i odpowiedni typ danych podczas konwersji na dane tabelaryczne. Ta sekcja jest opcjonalna, o ile nie trzeba wykonać mapowania kolumn. Aby uzyskać więcej informacji, zobacz Mapuj kolumny źródłowego zestawu danych na docelowe kolumny zestawu danych. - Właściwość
jsonPathDefinitionokreśla ścieżkę JSON dla każdej kolumny, wskazując, skąd mają zostać wyodrębnione dane. Aby skopiować dane z tablicy, możesz użyćarray[x].propertypolecenia , aby wyodrębnić wartość danej właściwości zxthobiektu lub użyćarray[*].propertypolecenia , aby znaleźć wartość z dowolnego obiektu zawierającego taką właściwość.
"properties": {
"structure": [
{
"name": "id",
"type": "String"
},
{
"name": "deviceType",
"type": "String"
},
{
"name": "targetResourceType",
"type": "String"
},
{
"name": "resourceManagementProcessRunId",
"type": "String"
},
{
"name": "occurrenceTime",
"type": "DateTime"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat",
"filePattern": "setOfObjects",
"jsonPathDefinition": {"id": "$.id", "deviceType": "$.context.device.type", "targetResourceType": "$.context.custom.dimensions[0].TargetResourceType", "resourceManagementProcessRunId": "$.context.custom.dimensions[1].ResourceManagementProcessRunId", "occurrenceTime": " $.context.custom.dimensions[2].OccurrenceTime"}
}
}
}
Przykład 2. Krzyżowe stosowanie tego samego wzorca z tabeli do wielu obiektów
W tym przykładzie oczekiwane jest przetransformowanie jednego głównego obiektu JSON na wiele rekordów w wyniku tabelarycznym. Jeśli masz plik JSON z następującą zawartością:
{
"ordernumber": "01",
"orderdate": "20170122",
"orderlines": [
{
"prod": "p1",
"price": 23
},
{
"prod": "p2",
"price": 13
},
{
"prod": "p3",
"price": 231
}
],
"city": [ { "sanmateo": "No 1" } ]
}
i chcesz ją skopiować do tabeli Azure SQL w następującym formacie, spłaszczając dane wewnątrz tablicy i łącząc je krzyżowo ze wspólnymi informacjami głównymi:
ordernumber |
orderdate |
order_pd |
order_price |
city |
|---|---|---|---|---|
| 01 | 20170122 | P1 | 23 | [{"sanmateo":"No 1"}] |
| 01 | 20170122 | P2 | 13 | [{"sanmateo":"No 1"}] |
| 01 | 20170122 | P3 | 231 | [{"sanmateo":"No 1"}] |
Zestaw danych wejściowych typu JsonFormat jest zdefiniowany następująco: (częściowa definicja zawierająca tylko stosowne fragmenty). W szczególności:
- Sekcja
structuredefiniuje niestandardowe nazwy kolumn i odpowiedni typ danych podczas konwersji na dane tabelaryczne. Ta sekcja jest opcjonalna, o ile nie trzeba wykonać mapowania kolumn. Aby uzyskać więcej informacji, zobacz Mapuj kolumny źródłowego zestawu danych na docelowe kolumny zestawu danych. -
jsonNodeReferencewskazuje, aby iterować i wyodrębniać dane z obiektów przy użyciu tego samego wzorca w tablicyorderlines. - Właściwość
jsonPathDefinitionokreśla ścieżkę JSON dla każdej kolumny, wskazując, skąd mają zostać wyodrębnione dane. W tym przykładzie ,ordernumberorderdate, icityznajdują się w obiekcie głównym ze ścieżką JSON rozpoczynającą się od$., podczas gdyorder_pdiorder_pricesą zdefiniowane ze ścieżką pochodzącą z elementu tablicy bez$..
"properties": {
"structure": [
{
"name": "ordernumber",
"type": "String"
},
{
"name": "orderdate",
"type": "String"
},
{
"name": "order_pd",
"type": "String"
},
{
"name": "order_price",
"type": "Int64"
},
{
"name": "city",
"type": "String"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat",
"filePattern": "setOfObjects",
"jsonNodeReference": "$.orderlines",
"jsonPathDefinition": {"ordernumber": "$.ordernumber", "orderdate": "$.orderdate", "order_pd": "prod", "order_price": "price", "city": " $.city"}
}
}
}
Pamiętaj o następujących kwestiach:
- Jeśli element
structureijsonPathDefinitionnie jest zdefiniowany w zestawie danych, działanie kopiowania wykrywa schemat z pierwszego obiektu i spłaszcza cały obiekt. - Jeśli dane wejściowe JSON zawierają tablicę, działanie kopiowania domyślnie konwertuje całą wartość tablicy na ciąg. Możesz wyodrębnić z niej dane przy użyciu właściwości
jsonNodeReferencei/lubjsonPathDefinitionbądź ją pominąć, nie określając jej we właściwościjsonPathDefinition. - Jeśli na tym samym poziomie występują zduplikowane nazwy, działanie kopiowania wybierze ostatnią z nich.
- W przypadku nazw właściwości wielkość liter ma znaczenie. Dwie właściwości o takiej samej nazwie, ale zapisanej przy użyciu różnej wielkości liter, są traktowane jako dwie osobne właściwości.
Przypadek 2. Zapisywanie danych do pliku JSON
Jeśli masz następującą tabelę w usłudze SQL Database:
| ID | order_date | order_price | order_by |
|---|---|---|---|
| 1 | 20170119 | 2000 | David |
| 2 | 20170120 | 3500 | Patrick |
| 3 | 20170121 | 4000 | Jason |
i dla każdego rekordu oczekuje się zapisu w obiekcie JSON w następującym formacie:
{
"id": "1",
"order": {
"date": "20170119",
"price": 2000,
"customer": "David"
}
}
Zestaw danych wyjściowych typu JsonFormat jest zdefiniowany następująco: (częściowa definicja zawierająca tylko stosowne fragmenty). W szczególności structure sekcja definiuje niestandardowe nazwy właściwości w pliku docelowym ( nestingSeparator wartość domyślna to ".") są używane do identyfikowania warstwy zagnieżdżenia z nazwy. Ta sekcja jest opcjonalna, o ile nie chcesz zmieniać nazwy właściwości na podstawie porównania z nazwą kolumny źródłowej ani zagnieżdżać właściwości.
"properties": {
"structure": [
{
"name": "id",
"type": "String"
},
{
"name": "order.date",
"type": "String"
},
{
"name": "order.price",
"type": "Int64"
},
{
"name": "order.customer",
"type": "String"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat"
}
}
}
Format Parquet (starsza wersja)
Uwaga
Zapoznaj się z nowym modelem z artykułu w formacie Parquet. Następujące konfiguracje zestawu danych magazynu danych opartego na plikach są nadal obsługiwane zgodnie ze zgodnością z poprzednimi wersjami. Zaleca się użycie nowego modelu w przyszłości.
Jeśli chcesz przeanalizować pliki Parquet lub zapisać dane w formacie Parquet, ustaw formattype właściwość na ParquetFormat. Nie musisz określać żadnych właściwości w sekcji Format należącej do sekcji typeProperties. Przykład:
"format":
{
"type": "ParquetFormat"
}
Należy uwzględnić następujące informacje:
- Złożone typy danych nie są obsługiwane (MAP, LIST).
- Białe znaki w nazwie kolumny nie są obsługiwane.
- Plik Parquet ma następujące opcje związane z kompresją: NONE, SNAPPY, GZIP oraz LZO. Usługa obsługuje odczytywanie danych z pliku Parquet w dowolnym z tych skompresowanych formatów z wyjątkiem LZO — używa kodera kompresji w metadanych do odczytywania danych. Jednak podczas zapisywania w pliku Parquet usługa wybiera przystawkę SNAPPY, która jest domyślna dla formatu Parquet. Obecnie nie ma możliwości zastąpienia tego zachowania.
Ważne
W przypadku kopiowania z uprawnieniami własnego środowiska Integration Runtime, np. między lokalnymi i w chmurze magazynami danych, jeśli nie kopiujesz plików Parquet w taki sposób, musisz zainstalować 64-bitowe środowisko JRE 8 (Środowisko uruchomieniowe Java) lub zestaw OpenJDK na maszynie IR. Zobacz następujący akapit, aby uzyskać więcej szczegółów.
W przypadku kopiowania działającego na własnym środowisku IR z serializacji/deserializacji plików Parquet usługa lokalizuje środowisko uruchomieniowe Języka Java, sprawdzając najpierw rejestr (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome) środowiska JRE, jeśli nie zostanie znaleziony, po drugie sprawdzając zmienną systemową JAVA_HOME dla zestawu OpenJDK.
- Aby użyć środowiska JRE: 64-bitowe środowisko IR wymaga 64-bitowego środowiska JRE. Możesz go znaleźć tutaj.
- Aby użyć zestawu OpenJDK: jest obsługiwany od czasu środowiska IR w wersji 3.13. Spakuj jvm.dll ze wszystkimi innymi wymaganymi zestawami zestawu OpenJDK na maszynę własnego środowiska IR i odpowiednio ustaw zmienną środowiskową systemu JAVA_HOME.
Napiwek
Jeśli skopiujesz dane do/z formatu Parquet przy użyciu własnego środowiska Integration Runtime i wystąpi błąd informujący o błędzie "Wystąpił błąd podczas wywoływania języka Java, komunikat: java.lang.OutOfMemoryError: Przestrzeń sterty Java", możesz dodać zmienną środowiskową _JAVA_OPTIONS na maszynie, która hostuje własne środowisko IR, aby dostosować minimalny/maksymalny rozmiar sterty dla maszyny JVM w celu wzmocnienia takiej możliwości kopiowania, a następnie ponownie uruchomić potok.
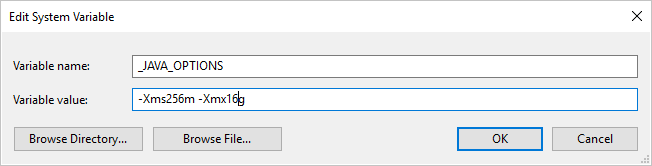
Przykład: ustaw zmienną _JAVA_OPTIONS z wartością -Xms256m -Xmx16g. Flaga Xms określa początkową pulę alokacji pamięci dla maszyny wirtualnej Java (JVM), podczas gdy Xmx określa maksymalną pulę alokacji pamięci. Oznacza to, że maszyny JVM zostaną uruchomione z ilością Xms pamięci i będą mogły korzystać z maksymalnej Xmx ilości pamięci. Domyślnie usługa używa min 64 MB i maksymalnej liczby 1G.
Mapowanie typu danych dla plików Parquet
| Typ danych usługi tymczasowej | Typ pierwotny Parquet | Typ oryginalny Parquet (Deserialize) | Typ oryginalny Parquet (serializowanie) |
|---|---|---|---|
| Wartość logiczna | Wartość logiczna | Brak | Brak |
| SByte | Int32 | Int8 | Int8 |
| Byte | Int32 | UInt8 | Int16 |
| Int16 | Int32 | Int16 | Int16 |
| UInt16 | Int32 | UInt16 | Int32 |
| Int32 | Int32 | Int32 | Int32 |
| UInt32 | Int64 | UInt32 | Int64 |
| Int64 | Int64 | Int64 | Int64 |
| UInt64 | Int64/Binary | UInt64 | Dziesiętne |
| Pojedynczy | Liczba zmiennoprzecinkowa | Brak | Brak |
| Liczba rzeczywista | Liczba rzeczywista | Brak | Brak |
| Dziesiętne | Plik binarny | Dziesiętne | Dziesiętne |
| String | Plik binarny | Utf8 | Utf8 |
| DateTime | Int96 | Brak | Brak |
| przedział_czasu | Int96 | Brak | Brak |
| DateTimeOffset | Int96 | Brak | Brak |
| ByteArray | Plik binarny | Brak | Brak |
| Identyfikator GUID | Plik binarny | Utf8 | Utf8 |
| Char | Plik binarny | Utf8 | Utf8 |
| CharArray | Nieobsługiwane | Brak | Brak |
Format ORC (starsza wersja)
Uwaga
Zapoznaj się z nowym modelem z artykułu o formacie ORC. Następujące konfiguracje zestawu danych magazynu danych opartego na plikach są nadal obsługiwane zgodnie ze zgodnością z poprzednimi wersjami. Zaleca się użycie nowego modelu w przyszłości.
Jeśli chcesz przeanalizować pliki ORC lub zapisać dane w formacie ORC, ustaw formattype właściwość na OrcFormat. Nie musisz określać żadnych właściwości w sekcji Format należącej do sekcji typeProperties. Przykład:
"format":
{
"type": "OrcFormat"
}
Należy uwzględnić następujące informacje:
- Złożone typy danych nie są obsługiwane (STRUKTURA, MAP, LIST, UNION).
- Białe znaki w nazwie kolumny nie są obsługiwane.
- Plik ORC ma trzy opcje związane z kompresją: NONE, ZLIB, SNAPPY. Usługa obsługuje odczytywanie danych z pliku ORC w dowolnym z tych skompresowanych formatów. Do odczytywania danych używa kodera-dekodera kompresji z metadanych. Jednak podczas zapisywania w pliku ORC usługa wybiera bibliotekę ZLIB, która jest domyślna dla ORC. Obecnie nie ma możliwości zastąpienia tego zachowania.
Ważne
W przypadku kopiowania z uprawnieniami własnego środowiska Integration Runtime, np. między lokalnymi i w chmurze magazynami danych, jeśli nie kopiujesz plików ORC w taki sposób, musisz zainstalować 64-bitowe środowisko JRE 8 (środowisko uruchomieniowe Java) lub zestaw OpenJDK na maszynie IR. Zobacz następujący akapit, aby uzyskać więcej szczegółów.
W przypadku kopiowania działającego na własnym środowisku IR z serializacji/deserializacji plików ORC usługa lokalizuje środowisko uruchomieniowe Języka Java, sprawdzając najpierw rejestr (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome) środowiska JRE, jeśli nie zostanie znaleziony, po drugie sprawdzając zmienną systemową JAVA_HOME dla zestawu OpenJDK.
- Aby użyć środowiska JRE: 64-bitowe środowisko IR wymaga 64-bitowego środowiska JRE. Możesz go znaleźć tutaj.
- Aby użyć zestawu OpenJDK: jest obsługiwany od czasu środowiska IR w wersji 3.13. Spakuj jvm.dll ze wszystkimi innymi wymaganymi zestawami zestawu OpenJDK na maszynę własnego środowiska IR i odpowiednio ustaw zmienną środowiskową systemu JAVA_HOME.
Mapowanie typów danych dla plików ORC
| Typ danych usługi tymczasowej | Typy ORC |
|---|---|
| Wartość logiczna | Wartość logiczna |
| SByte | Byte |
| Byte | Krótkie |
| Int16 | Krótkie |
| UInt16 | Int |
| Int32 | Int |
| UInt32 | Długi |
| Int64 | Długi |
| UInt64 | String |
| Pojedynczy | Liczba zmiennoprzecinkowa |
| Liczba rzeczywista | Liczba rzeczywista |
| Dziesiętne | Dziesiętne |
| String | String |
| DateTime | Sygnatura czasowa |
| DateTimeOffset | Sygnatura czasowa |
| przedział_czasu | Sygnatura czasowa |
| ByteArray | Plik binarny |
| Identyfikator GUID | String |
| Char | Char(1) |
Format AVRO (starsza wersja)
Uwaga
Zapoznaj się z nowym modelem z artykułu o formacie Avro. Następujące konfiguracje zestawu danych magazynu danych opartego na plikach są nadal obsługiwane zgodnie ze zgodnością z poprzednimi wersjami. Zaleca się użycie nowego modelu w przyszłości.
Jeśli chcesz przeanalizować pliki Avro lub zapisać dane w formacie Avro, ustaw formattype właściwość na AvroFormat. Nie musisz określać żadnych właściwości w sekcji Format należącej do sekcji typeProperties. Przykład:
"format":
{
"type": "AvroFormat",
}
Aby użyć formatu Avro w tabeli Hive, możesz zapoznać się z samouczkiem apache Hive.
Należy uwzględnić następujące informacje:
- Złożone typy danych nie są obsługiwane (rekordy, wyliczenia, tablice, mapy, związki i stałe).
Obsługa kompresji (starsza wersja)
Usługa obsługuje kompresowanie/dekompresowanie danych podczas kopiowania. Po określeniu compression właściwości w wejściowym zestawie danych działanie kopiowania odczytuje skompresowane dane ze źródła i dekompresuje je. Po określeniu właściwości w wyjściowym zestawie danych działanie kopiowania kompresuje następnie zapisuje dane w ujściu. Oto kilka przykładowych scenariuszy:
- Odczytywanie skompresowanych danych GZIP z obiektu blob platformy Azure, dekompresowanie ich i zapisywanie danych wynikowych w usłudze Azure SQL Database. Należy zdefiniować wejściowy zestaw danych obiektu blob platformy Azure z właściwością
compressiontypejako GZIP. - Odczytywanie danych z pliku zwykłego tekstu z lokalnego systemu plików, kompresowanie ich przy użyciu formatu GZip i zapisywanie skompresowanych danych do obiektu blob platformy Azure. Wyjściowy zestaw danych obiektów blob platformy Azure definiuje się za
compressiontypepomocą właściwości GZip. - Odczytaj plik .zip z serwera FTP, zdekompresuj go, aby pobrać pliki do wewnątrz i wylądować te pliki w usłudze Azure Data Lake Store. Należy zdefiniować wejściowy zestaw danych FTP z właściwością
compressiontypeZipDeflate. - Odczytywanie skompresowanych przez GZIP danych z obiektu blob platformy Azure, dekompresowanie ich, kompresowanie przy użyciu protokołu BZIP2 i zapisywanie danych wynikowych w obiekcie blob platformy Azure. Należy zdefiniować wejściowy zestaw danych obiektów blob platformy Azure z
compressiontypeustawionym na GZIP i wyjściowym zestawem danych ustawionymcompressiontypena BZIP2.
Aby określić kompresję dla zestawu danych, użyj właściwości kompresji w formacie JSON zestawu danych, jak w poniższym przykładzie:
{
"name": "AzureBlobDataSet",
"properties": {
"type": "AzureBlob",
"linkedServiceName": {
"referenceName": "StorageLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"fileName": "pagecounts.csv.gz",
"folderPath": "compression/file/",
"format": {
"type": "TextFormat"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
Sekcja kompresji ma dwie właściwości:
Typ: koder kompresji, który może być GZIP, Deflate, BZIP2 lub ZipDeflate. Uwaga podczas używania działania kopiowania do dekompresowania plików ZipDeflate i zapisu w magazynie danych ujścia opartego na plikach pliki pliki zostaną wyodrębnione do folderu:
<path specified in dataset>/<folder named as source zip file>/.Poziom: współczynnik kompresji, który może być optymalny lub najszybszy.
Najszybsza: operacja kompresji powinna zostać ukończona tak szybko, jak to możliwe, nawet jeśli wynikowy plik nie jest optymalnie skompresowany.
Optymalna: operacja kompresji powinna być optymalnie skompresowana, nawet jeśli operacja trwa dłużej.
Aby uzyskać więcej informacji, zobacz Temat Poziom kompresji.
Uwaga
Ustawienia kompresji nie są obsługiwane w przypadku danych w formatach AvroFormat, OrcFormat lub ParquetFormat. Podczas odczytywania plików w tych formatach usługa wykrywa koder-dekoder kompresji w metadanych i używa go. Podczas zapisywania w plikach w tych formatach usługa wybiera domyślny koder kodujący kompresji dla tego formatu. Na przykład ZLIB for OrcFormat i SNAPPY for ParquetFormat.
Nieobsługiwane typy plików i formaty kompresji
Za pomocą funkcji rozszerzalności można przekształcać pliki, które nie są obsługiwane. Dwie opcje obejmują usługę Azure Functions i zadania niestandardowe przy użyciu usługi Azure Batch.
Możesz zobaczyć przykład, który używa funkcji platformy Azure do wyodrębniania zawartości pliku tar. Aby uzyskać więcej informacji, zobacz Działanie usługi Azure Functions.
Tę funkcję można również utworzyć przy użyciu niestandardowego działania dotnet. Dalsze informacje są dostępne tutaj
Powiązana zawartość
Poznaj najnowsze obsługiwane formaty i kompresje plików z obsługiwanych formatów i kompresji plików.