Rozdzielany format tekstu w usługach Azure Data Factory i Azure Synapse Analytics
DOTYCZY:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
Postępuj zgodnie z tym artykułem, gdy chcesz przeanalizować rozdzielane pliki tekstowe lub zapisać dane w formacie tekstu rozdzielanego.
Format tekstu rozdzielanego jest obsługiwany w przypadku następujących łączników:
- Amazon S3
- Magazyn zgodny z usługą Amazon S3
- Azure Blob
- Usługa Azure Data Lake Storage 1. generacji
- Azure Data Lake Storage Gen2
- Azure Files
- System plików
- FTP
- Google Cloud Storage
- HDFS
- HTTP
- Oracle Cloud Storage
- SFTP
Właściwości zestawu danych
Aby uzyskać pełną listę sekcji i właściwości dostępnych do definiowania zestawów danych, zobacz artykuł Zestawy danych. Ta sekcja zawiera listę właściwości obsługiwanych przez rozdzielany zestaw danych tekstowych.
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type zestawu danych musi być ustawiona na wartość RozdzielanyTekst. | Tak |
| lokalizacja | Ustawienia lokalizacji plików. Każdy łącznik oparty na plikach ma własny typ lokalizacji i obsługiwane właściwości w obszarze location. |
Tak |
| columnDelimiter | Znaki używane do oddzielania kolumn w pliku. Wartość domyślna to przecinek ,. Gdy ogranicznik kolumny jest zdefiniowany jako pusty ciąg, co oznacza, że nie ma ogranicznika, cały wiersz jest traktowany jako pojedyncza kolumna.Obecnie ogranicznik kolumn jako pusty ciąg jest obsługiwany tylko w przypadku przepływu danych mapowania, ale nie działanie Kopiuj. |
Nie. |
| rowDelimiter | W przypadku działanie Kopiuj pojedynczy znak lub "\r\n" używany do oddzielania wierszy w pliku. Wartość domyślna to dowolna z następujących wartości podczas odczytu: ["\r\n", "\r", "\n"]; na zapis: "\r\n". Polecenie "\r\n" jest obsługiwane tylko w poleceniu kopiowania. W przypadku przepływu danych mapowania jeden lub dwa znaki używane do oddzielania wierszy w pliku. Wartość domyślna to dowolna z następujących wartości podczas odczytu: ["\r\n", "\r", "\n"]; na zapis: "\n". Gdy ogranicznik wiersza jest ustawiony na bez ogranicznika (pusty ciąg), ogranicznik kolumny musi być ustawiony jako żaden ogranicznik (pusty ciąg), co oznacza traktowanie całej zawartości jako pojedynczej wartości. Obecnie ogranicznik wierszy jako pusty ciąg jest obsługiwany tylko w przypadku przepływu danych mapowania, ale nie działanie Kopiuj. |
Nie. |
| quoteChar | Pojedynczy znak cudzysłowu wartości kolumn, jeśli zawiera ogranicznik kolumn. Wartość domyślna to podwójne cudzysłowy ". Jeśli quoteChar parametr jest zdefiniowany jako pusty ciąg, oznacza to, że nie ma cudzysłowu, a wartość kolumny nie jest cytowana i escapeChar jest używana do ucieczki ogranicznika kolumny i samego siebie. |
Nie. |
| escapeChar | Pojedynczy znak ucieczki cudzysłowów wewnątrz cytowanej wartości. Wartość domyślna to ukośnik \odwrotny. Jeśli escapeChar parametr jest zdefiniowany jako pusty ciąg, quoteChar należy również ustawić jako pusty ciąg, w którym przypadku upewnij się, że wszystkie wartości kolumn nie zawierają ograniczników. |
Nie. |
| firstRowAsHeader | Określa, czy należy traktować/tworzyć pierwszy wiersz jako wiersz nagłówka z nazwami kolumn. Dozwolone wartości to true i false (wartość domyślna). Gdy pierwszy wiersz jako nagłówek ma wartość false, zwróć uwagę, że podgląd danych interfejsu użytkownika i dane wyjściowe działania wyszukiwania automatycznie generują nazwy kolumn jako Prop_{n} (począwszy od 0), działanie kopiowania wymaga jawnego mapowania ze źródła na ujście i lokalizuje kolumny według porządkowych (począwszy od 1) oraz wyświetla listy przepływów danych mapowania i lokalizuje kolumny o nazwie jako Column_{n} (począwszy od 1). |
Nie. |
| nullValue | Określa ciąg reprezentujący wartość null. Wartość domyślna to pusty ciąg. |
Nie. |
| encodingName | Typ kodowania używany do odczytu/zapisu plików testowych. Dozwolone wartości są następujące: "UTF-8","UTF-8 bez BOM", "UTF-16", "UTF-16BE", "UTF-32", "UTF-32BE", "US-ASCII", "UTF-7", "BIG5", "EUC-JP", "EUC-KR", "GB2312", "GB18030", "JOHAB", "SHIFT-JIS", "CP875", "CP866", "IBM00858", "IBM037", "IBM273", "IBM437", "IBM500", "IBM737", "IBM737", "IBM775", "IBM850", "IBM852", "IBM855", "IBM857", "IBM860", "IBM861", "IBM863", "IBM864", "IBM865", "IBM865", "IBM869", "IBM870", "IBM01140", "IBM01141", "IBM01142", "IBM01143", "IBM01144", "IBM01145", "IBM01146", "IBM01147", "IBM01148", "IBM01149", "ISO-2022-JP", "ISO-2022-KR", "ISO-8859-1", "ISO-8859-2", "ISO-8859-3", "ISO-8859-4", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", "ISO-8859-9", "ISO-8859-13", "ISO-8859-15", "WINDOWS-874", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-1255"2", "WINDOWS-1253", "WINDOWS-1254", "WINDOWS-1255", "WINDOWS-1256", "WINDOWS-1257", "WINDOWS-1258". Przepływ mapowania danych nie obsługuje kodowania UTF-7. Przepływ danych mapowania notatek nie obsługuje kodowania UTF-8 za pomocą znacznika kolejności bajtów (BOM). |
Nie. |
| compressionCodec | Koder koder kompresji używany do odczytu/zapisu plików tekstowych. Dozwolone wartości to bzip2, gzip, deflate, ZipDeflate, TarGzip, Tar, Snappy lub lz4. Wartość domyślna nie jest kompresowana. Uwaga obecnie działanie Kopiuj nie obsługuje "snappy" i "lz4", a przepływ danych mapowania nie obsługuje "ZipDeflate", "TarGzip" i "Tar". Uwaga podczas używania działania kopiowania do dekompresowania plików TarDeflate/TarGzip/ i zapisu w magazynie danych ujścia opartego na plikach pliki domyślnie pliki są wyodrębniane do folderu: <path specified in dataset>/<folder named as source compressed file>/ użyj/preserveCompressionFileNameAsFolder preserveZipFileNameAsFolderźródła działania kopiowania, aby kontrolować, czy zachować nazwę skompresowanych plików jako struktury folderów. |
Nie. |
| compressionLevel | Współczynnik kompresji. Dozwolone wartości są optymalne lub najszybsze. - Najszybsza: operacja kompresji powinna zostać ukończona tak szybko, jak to możliwe, nawet jeśli wynikowy plik nie jest optymalnie skompresowany. - Optymalna: operacja kompresji powinna być optymalnie skompresowana, nawet jeśli operacja trwa dłużej. Aby uzyskać więcej informacji, zobacz Temat Poziom kompresji. |
Nie. |
Poniżej przedstawiono przykład rozdzielanego zestawu danych tekstowych w usłudze Azure Blob Storage:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"columnDelimiter": ",",
"quoteChar": "\"",
"escapeChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Właściwości działania kopiowania
Aby uzyskać pełną listę sekcji i właściwości dostępnych do definiowania działań, zobacz artykuł Pipelines (Potoki ). Ta sekcja zawiera listę właściwości obsługiwanych przez rozdzielane źródło tekstu i ujście.
Rozdzielany tekst jako źródło
Następujące właściwości są obsługiwane w sekcji działanie kopiowania *źródło* .
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type źródła działania kopiowania musi być ustawiona na wartość DelimitedTextSource. | Tak |
| formatUstawienia | Grupa właściwości. Zapoznaj się z tabelą ustawień odczytu tekstu rozdzielanego tekstem poniżej. | Nie. |
| storeSettings | Grupa właściwości dotyczących odczytywania danych z magazynu danych. Każdy łącznik oparty na plikach ma własne obsługiwane ustawienia odczytu w obszarze storeSettings. |
Nie. |
Obsługiwane ustawienia odczytu tekstu rozdzielanego w obszarze formatSettings:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Typ formatUstawienia musi być ustawiony na delimitedTextReadSettings. | Tak |
| skipLineCount | Wskazuje liczbę niepustych wierszy do pominięcia podczas odczytywania danych z plików wejściowych. Jeśli określono zarówno właściwość skipLineCount, jak i firstRowAsHeader, najpierw zostaną pominięte wiersze, a następnie zostaną odczytane informacje nagłówka z pliku wejściowego. |
Nie. |
| compressionProperties | Grupa właściwości dotyczących dekompresowania danych dla danego koder-dekodera kompresji. | Nie. |
| preserveZipFileNameAsFolder (pod compressionProperties->type jako ZipDeflateReadSettings) |
Dotyczy konfiguracji wejściowego zestawu danych z kompresją ZipDeflate . Wskazuje, czy podczas kopiowania zachować nazwę źródłowego pliku zip jako strukturę folderów. — W przypadku ustawienia wartości true (wartość domyślna) usługa zapisuje rozpakowane pliki na wartość <path specified in dataset>/<folder named as source zip file>/.— Po ustawieniu wartości false usługa zapisuje rozpakowane pliki bezpośrednio do . <path specified in dataset> Upewnij się, że nie masz zduplikowanych nazw plików w różnych źródłowych plikach zip, aby uniknąć wyścigów ani nieoczekiwanych zachowań. |
Nie. |
| preserveCompressionFileNameAsFolder (w obszarze compressionProperties->type jako TarGZipReadSettings lub TarReadSettings) |
Ma zastosowanie w przypadku skonfigurowania wejściowego zestawu danych z kompresją TarGzip/Tar. Wskazuje, czy podczas kopiowania zachować nazwę skompresowanego pliku źródłowego jako strukturę folderów. — W przypadku ustawienia wartości true (wartość domyślna) usługa zapisuje dekompresowane pliki na wartość <path specified in dataset>/<folder named as source compressed file>/. - W przypadku ustawienia wartości false usługa zapisuje dekompresowane pliki bezpośrednio do <path specified in dataset>. Upewnij się, że nie masz zduplikowanych nazw plików w różnych plikach źródłowych, aby uniknąć wyścigów ani nieoczekiwanych zachowań. |
Nie. |
"activities": [
{
"name": "CopyFromDelimitedText",
"type": "Copy",
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"storeSettings": {
"type": "AzureBlobStorageReadSettings",
"recursive": true
},
"formatSettings": {
"type": "DelimitedTextReadSettings",
"skipLineCount": 3,
"compressionProperties": {
"type": "ZipDeflateReadSettings",
"preserveZipFileNameAsFolder": false
}
}
},
...
}
...
}
]
Rozdzielany tekst jako ujście
Następujące właściwości są obsługiwane w sekcji działanie kopiowania *ujście*.
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type źródła działania kopiowania musi być ustawiona na wartość DelimitedTextSink. | Tak |
| formatUstawienia | Grupa właściwości. Zapoznaj się z poniższą tabelą ustawień zapisu tekstu rozdzielanego tekstem. | Nie. |
| storeSettings | Grupa właściwości dotyczących sposobu zapisywania danych w magazynie danych. Każdy łącznik oparty na plikach ma własne obsługiwane ustawienia zapisu w obszarze storeSettings. |
Nie. |
Obsługiwane ustawienia zapisu tekstu rozdzielanego w obszarze formatSettings:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Typ formatUstawienia musi być ustawiony na delimitedTextWriteSettings. | Tak |
| fileExtension | Rozszerzenie pliku używane do nazywania plików wyjściowych, na przykład .csv, .txt. Należy go określić, gdy fileName parametr nie jest określony w wyjściowym zestawie danych RozdzielanyTekst. Gdy nazwa pliku jest skonfigurowana w wyjściowym zestawie danych, będzie używana jako nazwa pliku ujścia, a ustawienie rozszerzenia pliku zostanie zignorowane. |
Tak, gdy nazwa pliku nie jest określona w wyjściowym zestawie danych |
| maxRowsPerFile | Podczas zapisywania danych w folderze można wybrać zapisywanie w wielu plikach i określić maksymalną liczbę wierszy na plik. | Nie. |
| fileNamePrefix | Dotyczy konfiguracji maxRowsPerFile .Określ prefiks nazwy pliku podczas zapisywania danych w wielu plikach, co spowodowało następujący wzorzec: <fileNamePrefix>_00000.<fileExtension>. Jeśli nie zostanie określony, prefiks nazwy pliku zostanie wygenerowany automatycznie. Ta właściwość nie ma zastosowania, gdy źródło jest magazynem opartym na plikach lub magazynem danych z włączoną opcją partycji. |
Nie. |
Właściwości przepływu mapowania danych
W przepływach danych mapowania można odczytywać i zapisywać w formacie tekstu rozdzielanego w następujących magazynach danych: Azure Blob Storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2 i SFTP, a format tekstu rozdzielanego w usłudze Amazon S3.
Wbudowany zestaw danych
Przepływy danych mapowania obsługują "wbudowane zestawy danych" jako opcję definiowania źródła i ujścia. Wbudowany rozdzielany zestaw danych jest definiowany bezpośrednio wewnątrz przekształceń źródła i ujścia i nie jest udostępniany poza zdefiniowanym przepływem danych. Jest to przydatne w przypadku parametryzacji właściwości zestawu danych bezpośrednio wewnątrz przepływu danych i może korzystać z lepszej wydajności udostępnionych zestawów danych usługi ADF.
Podczas odczytywania dużej liczby folderów źródłowych i plików można zwiększyć wydajność odnajdywania plików przepływu danych, ustawiając opcję "Projektowany schemat użytkownika" wewnątrz projekcji | Okno dialogowe Opcje schematu. Ta opcja powoduje wyłączenie domyślnego automatycznego odnajdywania schematu usługi ADF i znacznie poprawi wydajność odnajdywania plików. Przed ustawieniem tej opcji zaimportuj projekcję, aby usługa ADF ma istniejący schemat do projekcji. Ta opcja nie działa z dryfem schematu.
Właściwości źródła
W poniższej tabeli wymieniono właściwości obsługiwane przez rozdzielane źródło tekstu. Te właściwości można edytować na karcie Opcje źródła.
| Nazwa/nazwisko | opis | Wymagania | Dozwolone wartości | Właściwość skryptu przepływu danych |
|---|---|---|---|---|
| Ścieżki z symbolami wieloznacznymi | Wszystkie pliki pasujące do ścieżki wieloznacznej zostaną przetworzone. Zastępuje folder i ścieżkę pliku ustawioną w zestawie danych. | nie | Ciąg[] | symbole wieloznacznePaths |
| Ścieżka główna partycji | W przypadku danych plików podzielonych na partycje można wprowadzić ścieżkę katalogu głównego partycji, aby odczytywać foldery podzielone na partycje jako kolumny | nie | String | partitionRootPath |
| Lista plików | Czy źródło wskazuje plik tekstowy, który wyświetla listę plików do przetworzenia | nie | true lub false |
fileList |
| Wiersze wielowierszowe | Czy plik źródłowy zawiera wiersze obejmujące wiele wierszy. Wartości wielowierszowe muszą być w cudzysłowie. | nie true lub false |
multiLineRow | |
| Kolumna do przechowywania nazwy pliku | Utwórz nową kolumnę z nazwą pliku źródłowego i ścieżką | nie | String | rowUrlColumn |
| Po zakończeniu | Usuń lub przenieś pliki po przetworzeniu. Ścieżka pliku rozpoczyna się od katalogu głównego kontenera | nie | Usuń: true lub false Ruszać: ['<from>', '<to>'] |
przeczyszczanie plików moveFiles |
| Filtruj według ostatniej modyfikacji | Wybierz filtrowanie plików w oparciu o czas ich ostatniej zmiany | nie | Sygnatura czasowa | modifiedAfter modifiedBefore |
| Zezwalaj na brak znalezionych plików | Jeśli wartość true, błąd nie jest zgłaszany, jeśli nie znaleziono żadnych plików | nie | true lub false |
ignoreNoFilesFound |
| Maksymalna liczba kolumn | Wartość domyślna to 20480. Dostosuj tę wartość, gdy numer kolumny wynosi ponad 20480 | nie | Integer | maxColumns |
Uwaga
Obsługa źródeł przepływu danych dla listy plików jest ograniczona do 1024 wpisów w pliku. Aby dołączyć więcej plików, użyj symboli wieloznacznych na liście plików.
Przykład źródła
Na poniższej ilustracji przedstawiono przykład konfiguracji rozdzielanego źródła tekstu w przepływach danych mapowania.
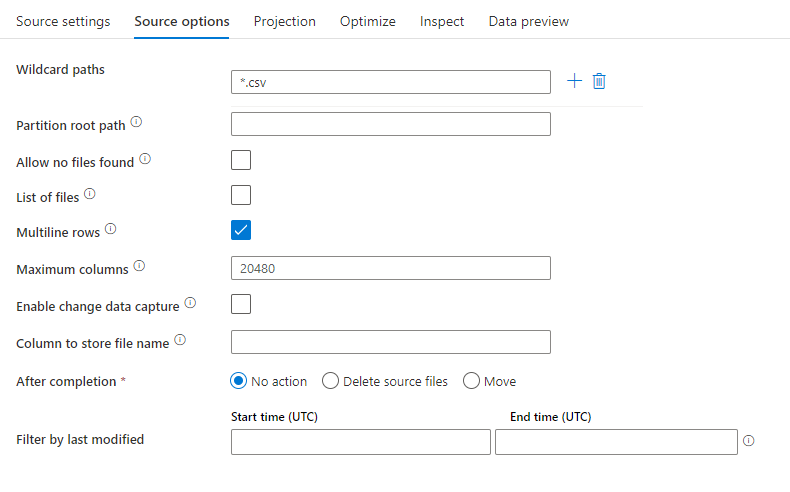
Skojarzony skrypt przepływu danych to:
source(
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false,
multiLineRow: true,
wildcardPaths:['*.csv']) ~> CSVSource
Uwaga
Źródła przepływu danych obsługują ograniczony zestaw globbing systemu Linux obsługiwany przez systemy plików Hadoop
Właściwości ujścia
W poniższej tabeli wymieniono właściwości obsługiwane przez rozdzielany ujście tekstu. Te właściwości można edytować na karcie Ustawienia .
| Nazwa/nazwisko | opis | Wymagania | Dozwolone wartości | Właściwość skryptu przepływu danych |
|---|---|---|---|---|
| Wyczyść folder | Jeśli folder docelowy zostanie wyczyszczone przed zapisem | nie | true lub false |
truncate |
| Opcja Nazwa pliku | Format nazewnictwa zapisanych danych. Domyślnie jeden plik na partycję w formacie part-#####-tid-<guid> |
nie | Wzorzec: ciąg Na partycję: Ciąg[] Nazwa pliku jako dane kolumny: Ciąg Dane wyjściowe do pojedynczego pliku: ['<fileName>'] Nazwa folderu jako dane kolumny: Ciąg |
filePattern partitionFileNames rowUrlColumn partitionFileNames rowFolderUrlColumn |
| Cudzysłowuj wszystko | Ujęć wszystkie wartości w cudzysłowie | nie | true lub false |
quoteAll |
| Nagłówek | Dodawanie nagłówków klienta do plików wyjściowych | nie | [<string array>] |
nagłówek |
Przykład ujścia
Na poniższej ilustracji przedstawiono przykład konfiguracji rozdzielanego ujścia tekstu w przepływach danych mapowania.
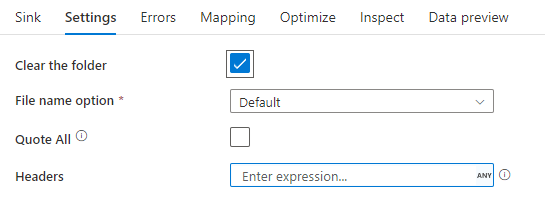
Skojarzony skrypt przepływu danych to:
CSVSource sink(allowSchemaDrift: true,
validateSchema: false,
truncate: true,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> CSVSink
Powiązane łączniki i formaty
Poniżej przedstawiono niektóre typowe łączniki i formaty związane z rozdzielonym formatem tekstu:
- Azure Blob Storage
- Format binarny
- Dataverse
- Format różnicowy
- Format programu Excel
- System plików
- FTP
- HTTP
- Format JSON
- Format Parquet