Rozwiązywanie problemów z wydajnością działania Kopiuj
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
W tym artykule opisano sposób rozwiązywania problemów z wydajnością działania kopiowania w usłudze Azure Data Factory.
Po uruchomieniu działania kopiowania można zebrać wyniki przebiegu i statystyki wydajności w widoku monitorowania działania kopiowania. Na poniższym obrazie przedstawiono przykład.
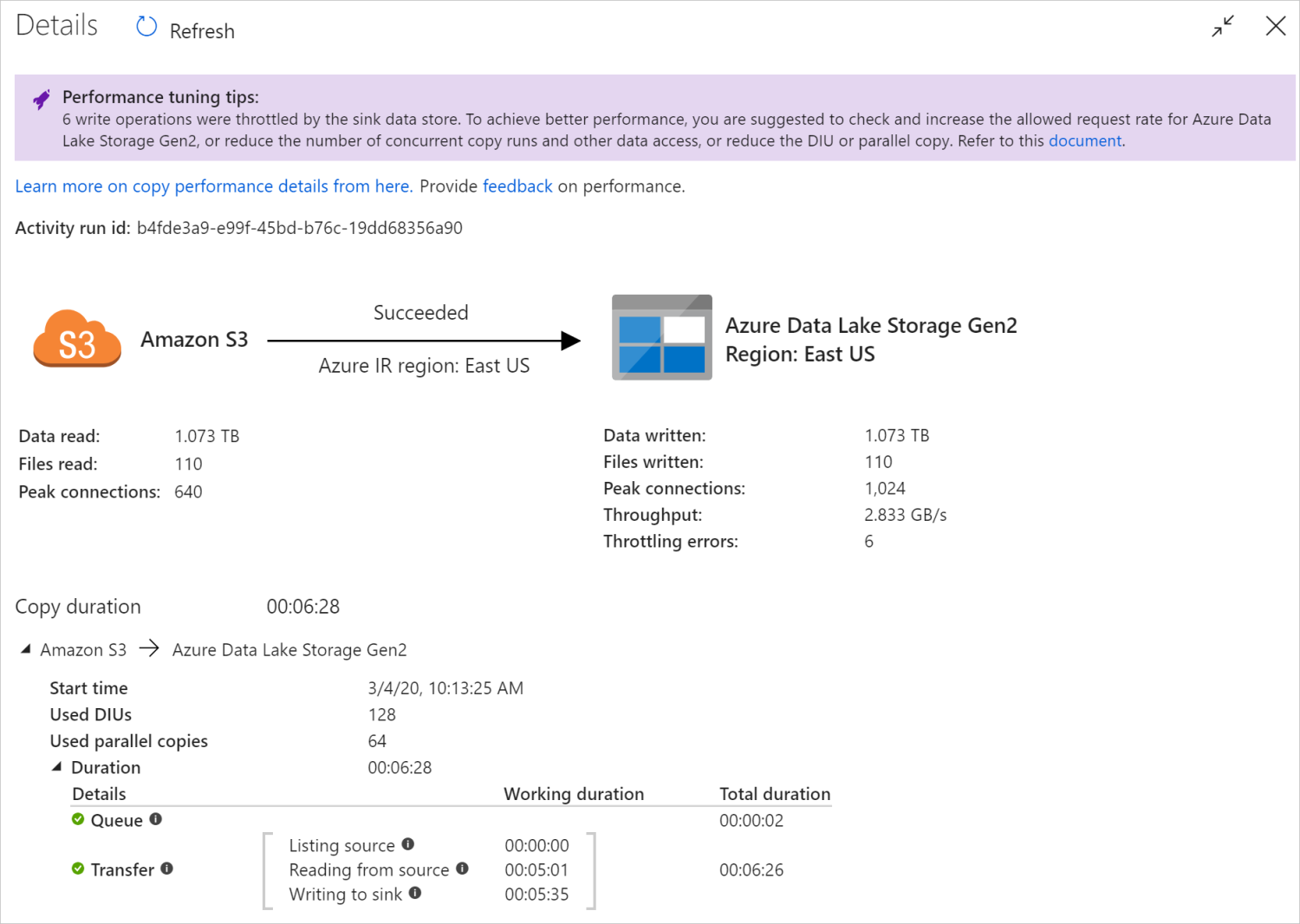
Porady dotyczące dostrajania wydajności
W niektórych scenariuszach po uruchomieniu działania kopiowania u góry zobaczysz "Porady dotyczące dostrajania wydajności" , jak pokazano na poprzedniej ilustracji. Porady informują o wąskim gardło zidentyfikowanym przez usługę dla tego konkretnego przebiegu kopiowania oraz sugestie dotyczące zwiększania przepływności kopiowania. Spróbuj dokonać zalecanej zmiany, a następnie ponownie uruchom kopię.
Obecnie porady dotyczące dostrajania wydajności zawierają sugestie dotyczące następujących przypadków:
| Kategoria | Porady dotyczące dostrajania wydajności |
|---|---|
| Specyficzny dla magazynu danych | Ładowanie danych do usługi Azure Synapse Analytics: sugeruje użycie instrukcji PolyBase lub COPY, jeśli nie są używane. |
| Kopiowanie danych z/do usługi Azure SQL Database: gdy jednostka DTU jest w wysokim wykorzystaniu, sugeruje uaktualnienie do wyższej warstwy. | |
| Kopiowanie danych z/do usługi Azure Cosmos DB: jeśli jednostka RU jest w wysokim wykorzystaniu, sugeruje uaktualnienie do większej jednostki RU. | |
| Kopiowanie danych z tabeli SAP: podczas kopiowania dużej ilości danych zalecamy użycie opcji partycji łącznika SAP w celu włączenia równoległego ładowania i zwiększenia maksymalnej liczby partycji. | |
| Pozyskiwanie danych z usługi Amazon Redshift: sugeruje użycie funkcji UNLOAD, jeśli nie są używane. | |
| Ograniczanie magazynu danych | Jeśli wiele operacji odczytu/zapisu jest ograniczanych przez magazyn danych podczas kopiowania, sugeruje sprawdzanie i zwiększanie dozwolonej liczby żądań dla magazynu danych lub zmniejszenie współbieżnego obciążenia. |
| Integration Runtime (Produkt Integration Runtime) | Jeśli używasz własnego środowiska Integration Runtime (IR) i działanie kopiowania czeka długo w kolejce, dopóki środowisko IR nie będzie dostępnego zasobu do wykonania, sugeruje skalowanie w poziomie/w górę środowiska IR. |
| Jeśli używasz środowiska Azure Integration Runtime , które znajduje się w nie optymalnym regionie, co powoduje spowolnienie odczytu/zapisu, sugeruje skonfigurowanie środowiska IR w innym regionie. | |
| Odporność na uszkodzenia | Jeśli skonfigurujesz odporność na uszkodzenia i pomijanie niezgodnych wierszy powoduje niską wydajność, sugeruje, aby zapewnić zgodność danych źródłowych i ujścia. |
| Kopia etapowa | Jeśli kopia etapowa jest skonfigurowana, ale nie jest pomocna dla pary źródła-ujścia, zaproponuj jego usunięcie. |
| Wznów | Gdy działanie kopiowania zostanie wznowione z ostatniego punktu awarii, ale nastąpi zmiana ustawienia jednostki DIU po oryginalnym uruchomieniu, zwróć uwagę, że nowe ustawienie jednostki DIU nie zostanie zastosowane. |
Omówienie szczegółów wykonywania działania kopiowania
Szczegóły wykonywania i czasy trwania w dolnej części widoku monitorowania działania kopiowania opisują kluczowe etapy działania kopiowania przechodzi (zobacz przykład na początku tego artykułu), co jest szczególnie przydatne do rozwiązywania problemów z wydajnością kopiowania. Wąskim gardłem przebiegu kopiowania jest ten z najdłuższym czasem trwania. Zapoznaj się z poniższą tabelą w definicji każdego etapu i dowiedz się, jak rozwiązywać problemy z działaniem kopiowania w środowisku Azure IR i Rozwiązywać problemy z działaniem kopiowania w środowisku IR hostowanych samodzielnie, z takimi informacjami.
| Etap | opis |
|---|---|
| Queue | Czas, który upłynął, dopóki działanie kopiowania rzeczywiście nie zostanie uruchomione w środowisku Integration Runtime. |
| Skrypt wstępny | Upłynął czas między działaniem kopiowania rozpoczynającym się od środowiska IR i kończeniem działania kopiowania wykonującego skrypt precopy w magazynie danych ujścia. Zastosuj podczas konfigurowania skryptu precopy dla ujść bazy danych, na przykład podczas zapisywania danych w usłudze Azure SQL Database przed skopiowanie nowych danych. |
| Przenoszenie | Upływający czas między końcem poprzedniego kroku a środowiskiem IR przesyłającym wszystkie dane ze źródła do ujścia. Zwróć uwagę, że podkroki w obszarze transferu są uruchamiane równolegle, a niektóre operacje nie są teraz wyświetlane, na przykład analizowanie/generowanie formatu pliku. - Czas pierwszego bajtu: czas, który upłynął między końcem poprzedniego kroku a czasem odebrania pierwszego bajtu przez środowisko IR z magazynu danych źródłowych. Dotyczy źródeł innych niż pliki. - Źródło listy: ilość czasu poświęcanego na wyliczanie plików źródłowych lub partycji danych. Ten ostatni dotyczy konfigurowania opcji partycji dla źródeł baz danych, na przykład podczas kopiowania danych z baz danych, takich jak Oracle/SAP HANA/Teradata/Netezza/etc. - Odczyt ze źródła: ilość czasu poświęcanego na pobieranie danych ze źródłowego magazynu danych. - Zapisywanie w ujściu: ilość czasu poświęcanego na zapisywanie danych w magazynie danych ujścia. Pamiętaj, że niektóre łączniki nie mają tej metryki w tej chwili, w tym usług Azure AI Search, Azure Data Explorer, Azure Table Storage, Oracle, SQL Server, Common Data Service, Dynamics 365, Dynamics CRM, Salesforce/Salesforce Service Cloud. |
Rozwiązywanie problemów z działaniem kopiowania w usłudze Azure IR
Wykonaj kroki dostrajania wydajności, aby zaplanować i przeprowadzić test wydajnościowy dla danego scenariusza.
Jeśli wydajność działania kopiowania nie spełnia Twoich oczekiwań, aby rozwiązać problemy z działaniem kopiowania pojedynczego uruchomionego w środowisku Azure Integration Runtime, jeśli w widoku monitorowania kopiowania są wyświetlane porady dotyczące dostrajania wydajności, zastosuj sugestię i spróbuj ponownie. W przeciwnym razie zapoznaj się ze szczegółami wykonywania działania kopiowania, sprawdź, który etap ma najdłuższy czas trwania, i zastosuj poniższe wskazówki, aby zwiększyć wydajność kopiowania:
Czas trwania skryptu wstępnego kopiowania: oznacza to, że wykonywanie skryptu precopy w bazie danych ujścia trwa długo. Dostosuj określoną logikę skryptu precopy, aby zwiększyć wydajność. Jeśli potrzebujesz dalszej pomocy dotyczącej ulepszania skryptu, skontaktuj się z zespołem bazy danych.
"Transfer — czas do pierwszego bajtu" — długotrwały czas trwania: oznacza to, że zapytanie źródłowe może długo zwracać dowolne dane. Sprawdź i zoptymalizuj zapytanie lub serwer. Jeśli potrzebujesz dalszej pomocy, skontaktuj się z zespołem magazynu danych.
"Transfer — wyświetlanie listy źródła" przez długi czas trwania: oznacza to, że wyliczanie plików źródłowych lub źródłowych partycji danych bazy danych działa wolno.
Podczas kopiowania danych ze źródła opartego na plikach, jeśli używasz filtru wieloznacznego na ścieżce folderu lub nazwie pliku ( lub
wildcardFileName), lub użyj filtru czasu ostatniej modyfikacji pliku (wildcardFolderPathmodifiedDatetimeStartlubmodifiedDatetimeEnd), zwróć uwagę, że taki filtr spowoduje wyświetlenie listy działań kopiowania wszystkich plików w określonym folderze po stronie klienta, a następnie zastosowanie filtru. Takie wyliczenie plików może stać się wąskim gardłem szczególnie wtedy, gdy reguła filtru spełnia tylko niewielki zestaw plików.Sprawdź, czy można kopiować pliki na podstawie ścieżki lub nazwy pliku partycjonowanego typu data/godzina. Taki sposób nie przynosi obciążenia po stronie źródła.
Sprawdź, czy zamiast tego możesz użyć natywnego filtru magazynu danych, w szczególności "prefiks" dla usług Amazon S3/Azure Blob Storage/Azure Files i "listAfter/listBefore" dla usługi ADLS Gen1. Te filtry są filtrem po stronie serwera magazynu danych i mają lepszą wydajność.
Rozważ podzielenie pojedynczego dużego zestawu danych na kilka mniejszych zestawów danych i pozwolić, aby te zadania kopiowania były uruchamiane współbieżnie, z których każda zajmuje się częścią danych. Możesz to zrobić za pomocą polecenia Lookup/GetMetadata + ForEach + Copy. Zapoznaj się z tematem Kopiowanie plików z wielu kontenerów lub Migrowanie danych z usługi Amazon S3 do szablonów rozwiązań usługi ADLS Gen2 w przykładzie ogólnym.
Sprawdź, czy usługa zgłasza błąd ograniczania przepustowości w źródle lub czy magazyn danych jest w stanie wysokiego wykorzystania. Jeśli tak, zmniejsz obciążenia w magazynie danych lub spróbuj skontaktować się z administratorem magazynu danych, aby zwiększyć limit przepustowości lub dostępny zasób.
Użyj środowiska Azure IR w tym samym lub bliskim regionie magazynu danych źródłowych.
"Transfer - odczyt ze źródła" doświadczył długiego czasu trwania pracy:
Zastosuj najlepsze rozwiązanie dotyczące ładowania danych specyficznych dla łącznika, jeśli ma zastosowanie. Na przykład podczas kopiowania danych z usługi Amazon Redshift skonfiguruj opcję używania redshift UNLOAD.
Sprawdź, czy usługa zgłasza błąd ograniczania przepustowości w źródle lub czy magazyn danych jest w wysokim wykorzystaniu. Jeśli tak, zmniejsz obciążenia w magazynie danych lub spróbuj skontaktować się z administratorem magazynu danych, aby zwiększyć limit przepustowości lub dostępny zasób.
Sprawdź wzorzec źródła i ujścia kopii:
Jeśli wzorzec kopiowania obsługuje więcej niż cztery jednostki Integracja danych (DIU) — zapoznaj się z tą sekcją na temat szczegółów, zazwyczaj możesz spróbować zwiększyć liczbę jednostek DIU, aby uzyskać lepszą wydajność.
W przeciwnym razie rozważ podzielenie pojedynczego dużego zestawu danych na kilka mniejszych zestawów danych. Następnie pozwól, aby te zadania kopiowania były uruchamiane współbieżnie — każde dla oddzielnego fragmentu danych. Możesz to zrobić za pomocą polecenia Lookup/GetMetadata + ForEach + Copy. Zapoznaj się z artykułem Kopiowanie plików z wielu kontenerów, Migrowanie danych z usługi Amazon S3 do usługi ADLS Gen2 lub Kopiowanie zbiorcze przy użyciu szablonów rozwiązań tabeli sterowania jako przykładu ogólnego.
Użyj środowiska Azure IR w tym samym lub bliskim regionie magazynu danych źródłowych.
"Transfer - zapisywanie do ujścia" doświadczył długiego czasu trwania pracy:
Zastosuj najlepsze rozwiązanie dotyczące ładowania danych specyficznych dla łącznika, jeśli ma zastosowanie. Na przykład podczas kopiowania danych do usługi Azure Synapse Analytics użyj instrukcji PolyBase lub COPY.
Sprawdź, czy usługa zgłasza błąd ograniczania przepustowości ujścia lub czy magazyn danych jest w wysokim wykorzystaniu. Jeśli tak, zmniejsz obciążenia w magazynie danych lub spróbuj skontaktować się z administratorem magazynu danych, aby zwiększyć limit przepustowości lub dostępny zasób.
Sprawdź wzorzec źródła i ujścia kopii:
Jeśli wzorzec kopiowania obsługuje więcej niż cztery jednostki Integracja danych (DIU) — zapoznaj się z tą sekcją na temat szczegółów, zazwyczaj możesz spróbować zwiększyć liczbę jednostek DIU, aby uzyskać lepszą wydajność.
W przeciwnym razie stopniowo dostrajaj kopie równoległe. Zbyt wiele równoległych kopii może nawet zaszkodzić wydajności.
Użyj środowiska Azure IR w tym samym lub bliskim regionie magazynu danych ujścia.
Rozwiązywanie problemów z działaniem kopiowania w własnym środowisku IR
Wykonaj kroki dostrajania wydajności, aby zaplanować i przeprowadzić test wydajnościowy dla danego scenariusza.
Jeśli wydajność kopiowania nie spełnia Twoich oczekiwań, aby rozwiązać problemy z działaniem kopiowania pojedynczego uruchomionego w środowisku Azure Integration Runtime, jeśli w widoku monitorowania kopiowania są wyświetlane porady dotyczące dostrajania wydajności, zastosuj sugestię i spróbuj ponownie. W przeciwnym razie zapoznaj się ze szczegółami wykonywania działania kopiowania, sprawdź, który etap ma najdłuższy czas trwania, i zastosuj poniższe wskazówki, aby zwiększyć wydajność kopiowania:
"Kolejka" doświadczyła długiego czasu trwania: oznacza to, że działanie kopiowania czeka długo w kolejce, dopóki własne środowisko IR nie będzie mieć zasobu do wykonania. Sprawdź pojemność i użycie środowiska IR oraz skaluj w górę lub w poziomie zgodnie z obciążeniem.
"Transfer — czas do pierwszego bajtu" — długotrwały czas trwania: oznacza to, że zapytanie źródłowe może długo zwracać dowolne dane. Sprawdź i zoptymalizuj zapytanie lub serwer. Jeśli potrzebujesz dalszej pomocy, skontaktuj się z zespołem magazynu danych.
"Transfer — wyświetlanie listy źródła" przez długi czas trwania: oznacza to, że wyliczanie plików źródłowych lub źródłowych partycji danych bazy danych działa wolno.
Sprawdź, czy maszyna własnego środowiska IR ma małe opóźnienia podczas nawiązywania połączenia ze źródłowym magazynem danych. Jeśli źródło znajduje się na platformie Azure, możesz użyć tego narzędzia , aby sprawdzić opóźnienie z maszyny własnego środowiska IR do regionu platformy Azure, tym lepiej.
Podczas kopiowania danych ze źródła opartego na plikach, jeśli używasz filtru wieloznacznego na ścieżce folderu lub nazwie pliku ( lub
wildcardFileName), lub użyj filtru czasu ostatniej modyfikacji pliku (wildcardFolderPathmodifiedDatetimeStartlubmodifiedDatetimeEnd), zwróć uwagę, że taki filtr spowoduje wyświetlenie listy działań kopiowania wszystkich plików w określonym folderze po stronie klienta, a następnie zastosowanie filtru. Takie wyliczenie plików może stać się wąskim gardłem szczególnie wtedy, gdy reguła filtru spełnia tylko niewielki zestaw plików.Sprawdź, czy można kopiować pliki na podstawie ścieżki lub nazwy pliku partycjonowanego typu data/godzina. Taki sposób nie przynosi obciążenia po stronie źródła.
Sprawdź, czy zamiast tego możesz użyć natywnego filtru magazynu danych, w szczególności "prefiks" dla usług Amazon S3/Azure Blob Storage/Azure Files i "listAfter/listBefore" dla usługi ADLS Gen1. Te filtry są filtrem po stronie serwera magazynu danych i mają lepszą wydajność.
Rozważ podzielenie pojedynczego dużego zestawu danych na kilka mniejszych zestawów danych i pozwolić, aby te zadania kopiowania były uruchamiane współbieżnie, z których każda zajmuje się częścią danych. Możesz to zrobić za pomocą polecenia Lookup/GetMetadata + ForEach + Copy. Zapoznaj się z tematem Kopiowanie plików z wielu kontenerów lub Migrowanie danych z usługi Amazon S3 do szablonów rozwiązań usługi ADLS Gen2 w przykładzie ogólnym.
Sprawdź, czy usługa zgłasza błąd ograniczania przepustowości w źródle lub czy magazyn danych jest w stanie wysokiego wykorzystania. Jeśli tak, zmniejsz obciążenia w magazynie danych lub spróbuj skontaktować się z administratorem magazynu danych, aby zwiększyć limit przepustowości lub dostępny zasób.
"Transfer - odczyt ze źródła" doświadczył długiego czasu trwania pracy:
Sprawdź, czy maszyna własnego środowiska IR ma małe opóźnienia podczas nawiązywania połączenia ze źródłowym magazynem danych. Jeśli źródło znajduje się na platformie Azure, możesz użyć tego narzędzia , aby sprawdzić opóźnienie z maszyny własnego środowiska IR do regionów platformy Azure, tym lepiej.
Sprawdź, czy maszyna własnego środowiska IR ma wystarczającą przepustowość ruchu przychodzącego, aby efektywnie odczytywać i przesyłać dane. Jeśli źródłowy magazyn danych znajduje się na platformie Azure, możesz użyć tego narzędzia , aby sprawdzić szybkość pobierania.
Sprawdź trend użycia procesora CPU i pamięci własnego środowiska IR w witrynie Azure Portal —> fabryka danych lub obszar roboczy usługi Synapse —> omówienie. Rozważ skalowanie środowiska IR w górę/w poziomie, jeśli użycie procesora CPU jest wysokie lub ilość dostępnej pamięci jest niska.
Zastosuj najlepsze rozwiązanie dotyczące ładowania danych specyficznych dla łącznika, jeśli ma to zastosowanie. Na przykład:
Podczas kopiowania danych z baz danych Oracle, Netezza, Teradata, SAP HANA, SAP Table i SAP Open Hub włącz opcje partycji danych w celu równoległego kopiowania danych.
Podczas kopiowania danych z systemu plików HDFS należy skonfigurować do używania narzędzia DistCp.
Podczas kopiowania danych z usługi Amazon Redshift skonfiguruj opcję używania redshift UNLOAD.
Sprawdź, czy usługa zgłasza błąd ograniczania przepustowości w źródle lub czy magazyn danych jest w wysokim wykorzystaniu. Jeśli tak, zmniejsz obciążenia w magazynie danych lub spróbuj skontaktować się z administratorem magazynu danych, aby zwiększyć limit przepustowości lub dostępny zasób.
Sprawdź wzorzec źródła i ujścia kopii:
Jeśli skopiujesz dane z magazynów danych z włączoną opcją partycji, rozważ stopniowe dostrojenie kopii równoległych. Zbyt wiele równoległych kopii może nawet zaszkodzić wydajności.
W przeciwnym razie rozważ podzielenie pojedynczego dużego zestawu danych na kilka mniejszych zestawów danych. Następnie pozwól, aby te zadania kopiowania były uruchamiane współbieżnie — każde dla oddzielnego fragmentu danych. Możesz to zrobić za pomocą polecenia Lookup/GetMetadata + ForEach + Copy. Zapoznaj się z artykułem Kopiowanie plików z wielu kontenerów, Migrowanie danych z usługi Amazon S3 do usługi ADLS Gen2 lub Kopiowanie zbiorcze przy użyciu szablonów rozwiązań tabeli sterowania jako przykładu ogólnego.
"Transfer - zapisywanie do ujścia" doświadczył długiego czasu trwania pracy:
Zastosuj najlepsze rozwiązanie dotyczące ładowania danych specyficznych dla łącznika, jeśli ma zastosowanie. Na przykład podczas kopiowania danych do usługi Azure Synapse Analytics użyj instrukcji PolyBase lub COPY.
Sprawdź, czy maszyna własnego środowiska IR ma małe opóźnienia podczas nawiązywania połączenia z magazynem danych ujścia. Jeśli ujście znajduje się na platformie Azure, możesz użyć tego narzędzia , aby sprawdzić opóźnienie z maszyny własnego środowiska IR do regionu platformy Azure, tym lepiej.
Sprawdź, czy maszyna własnego środowiska IR ma wystarczającą przepustowość ruchu wychodzącego, aby efektywnie przesyłać i zapisywać dane. Jeśli magazyn danych ujścia znajduje się na platformie Azure, możesz użyć tego narzędzia , aby sprawdzić szybkość przekazywania.
Sprawdź, czy trend użycia procesora CPU i pamięci własnego środowiska IR w witrynie Azure Portal —> fabryka danych lub obszar roboczy usługi Synapse —> strona przeglądu. Rozważ skalowanie środowiska IR w górę/w poziomie, jeśli użycie procesora CPU jest wysokie lub ilość dostępnej pamięci jest niska.
Sprawdź, czy usługa zgłasza błąd ograniczania przepustowości ujścia lub czy magazyn danych jest w wysokim wykorzystaniu. Jeśli tak, zmniejsz obciążenia w magazynie danych lub spróbuj skontaktować się z administratorem magazynu danych, aby zwiększyć limit przepustowości lub dostępny zasób.
Rozważ stopniowe dostrojenie kopii równoległych. Zbyt wiele równoległych kopii może nawet zaszkodzić wydajności.
Wydajność łącznika i środowiska IR
W tej sekcji poznać niektóre przewodniki rozwiązywania problemów z wydajnością dla określonego typu łącznika lub środowiska Integration Runtime.
Czas wykonywania działań różni się w zależności od środowiska Azure IR a środowiska IR sieci wirtualnej platformy Azure
Czas wykonywania działania różni się, gdy zestaw danych jest oparty na innym środowisku Integration Runtime.
Objawy: po prostu przełączenie listy rozwijanej Połączona usługa w zestawie danych wykonuje te same działania potoku, ale ma drastycznie różne czasy wykonywania. Gdy zestaw danych jest oparty na zarządzanym środowisku Virtual Network Integration Runtime, średnio trwa więcej czasu niż przebieg w oparciu o domyślne środowisko Integration Runtime.
Przyczyna: Sprawdź szczegóły przebiegów potoku, możesz zobaczyć, że powolny potok działa w środowisku IR zarządzanej sieci wirtualnej (Virtual Network), podczas gdy normalny działa w środowisku Azure IR. Zgodnie z projektem środowisko IR zarządzanej sieci wirtualnej trwa dłużej niż środowisko Azure IR, ponieważ nie rezerwujemy jednego węzła obliczeniowego na wystąpienie usługi, dlatego istnieje rozgrzewka dla każdego działania kopiowania do uruchomienia i występuje głównie w przypadku przyłączania do sieci wirtualnej, a nie środowiska Azure IR.
Niska wydajność podczas ładowania danych do usługi Azure SQL Database
Objawy: kopiowanie danych do usługi Azure SQL Database okazuje się powolne.
Przyczyna: Główna przyczyna problemu jest głównie wyzwalana przez wąskie gardło po stronie usługi Azure SQL Database. Poniżej przedstawiono niektóre możliwe przyczyny:
Warstwa usługi Azure SQL Database nie jest wystarczająco wysoka.
Użycie jednostek DTU usługi Azure SQL Database jest zbliżone do 100%. Możesz monitorować wydajność i rozważyć uaktualnienie warstwy usługi Azure SQL Database.
Indeksy nie są prawidłowo ustawiane. Usuń wszystkie indeksy przed załadowaniem danych i utwórz je ponownie po zakończeniu ładowania.
WriteBatchSize nie jest wystarczająco duży, aby dopasować rozmiar wiersza schematu. Spróbuj powiększyć właściwość problemu.
Zamiast wstawiania zbiorczego używana jest procedura składowana, która prawdopodobnie będzie miała gorzej wydajność.
Przekroczenie limitu czasu lub niska wydajność podczas analizowania dużego pliku programu Excel
Objawy:
Podczas tworzenia zestawu danych programu Excel i importowania schematu z połączenia/magazynu, danych podglądu, listy lub odświeżania arkuszy może wystąpić błąd przekroczenia limitu czasu, jeśli plik programu Excel jest duży.
W przypadku używania działania kopiowania do kopiowania danych z dużego pliku programu Excel (>= 100 MB) do innego magazynu danych może wystąpić niska wydajność lub problem z OOM.
Przyczyna:
W przypadku operacji, takich jak importowanie schematu, wyświetlanie podglądu danych i wyświetlanie listy arkuszy w zestawie danych programu Excel. Limit czasu wynosi 100 s i statyczny. W przypadku dużego pliku programu Excel te operacje mogą nie zostać zakończone w ramach wartości limitu czasu.
Działanie kopiowania odczytuje cały plik programu Excel do pamięci, a następnie lokalizuje określony arkusz i komórki do odczytywania danych. To zachowanie jest spowodowane podstawowym zestawem SDK używanym przez usługę.
Rozwiązanie:
W przypadku importowania schematu można wygenerować mniejszy przykładowy plik, który jest podzbiorem oryginalnego pliku, i wybrać opcję "importuj schemat z przykładowego pliku" zamiast "importuj schemat z połączenia/magazynu".
W przypadku wyświetlania listy arkuszy na liście rozwijanej arkusza możesz wybrać pozycję "Edytuj" i wprowadzić nazwę/indeks arkusza.
Aby skopiować duży plik programu Excel (>100 MB) do innego magazynu, możesz użyć Przepływ danych źródła programu Excel, które umożliwia odczytywanie strumieniowe i lepsze wykonywanie przesyłania strumieniowego.
Problem z funkcją OOM podczas odczytywania dużych plików JSON/Excel/XML
Objawy: podczas odczytywania dużych plików JSON/Excel/XML występuje problem z brakiem pamięci (OOM) podczas wykonywania działania.
Przyczyna:
- W przypadku dużych plików XML: Problem z systemem OOM podczas odczytywania dużych plików XML jest zgodnie z projektem. Przyczyną jest to, że cały plik XML musi być odczytywany do pamięci, ponieważ jest to pojedynczy obiekt, a następnie schemat jest wnioskowany, a dane są pobierane.
- W przypadku dużych plików programu Excel: OOM problem z odczytywaniem dużych plików programu Excel jest zgodnie z projektem. Przyczyną jest to, że używany zestaw SDK (POI/NPOI) musi odczytać cały plik programu Excel do pamięci, a następnie wywnioskować schemat i pobrać dane.
- W przypadku dużych plików JSON: Problem z odczytem dużych plików JSON jest projektowany, gdy plik JSON jest pojedynczym obiektem.
Zalecenie: Zastosuj jedną z następujących opcji, aby rozwiązać problem.
- Opcja 1: Zarejestruj własne środowisko Integration Runtime w trybie online przy użyciu zaawansowanego komputera (wysokiego użycia procesora CPU/pamięci), aby odczytywać dane z dużego pliku za pośrednictwem działania kopiowania.
- Opcja 2: użyj zoptymalizowanego klastra pamięci i dużego rozmiaru (na przykład 48 rdzeni), aby odczytywać dane z dużego pliku za pośrednictwem działania przepływu mapowania danych.
- Opcja-3: Podziel duży plik na małe, a następnie użyj działania kopiowania lub mapowania przepływu danych, aby odczytać folder.
- Opcja-4: Jeśli problem z OOM jest zablokowany lub występuje podczas kopiowania folderu XML/Excel/JSON, użyj działania foreach + kopiowania/mapowania przepływu danych w potoku, aby obsłużyć każdy plik lub podfolder.
-
Opcja-5: Inne:
- W przypadku formatu XML użyj działania notesu z klastrem zoptymalizowanym pod kątem pamięci, aby odczytywać dane z plików, jeśli każdy plik ma ten sam schemat. Obecnie platforma Spark ma różne implementacje do obsługi kodu XML.
- W przypadku formatu JSON użyj różnych formularzy dokumentów (na przykład Pojedynczy dokument, Dokument na wiersz i Tablica dokumentów) w ustawieniach JSON w obszarze mapowania źródła przepływu danych. Jeśli zawartość pliku JSON to Dokument na wiersz, zużywa mało pamięci.
Inne zasoby
Poniżej przedstawiono odwołania do monitorowania wydajności i dostrajania dla niektórych obsługiwanych magazynów danych:
- Azure Blob Storage: cele dotyczące skalowalności i wydajności dla magazynu obiektów blob oraz listy kontrolnej wydajności i skalowalności dla usługi Blob Storage.
- Azure Table Storage: cele dotyczące skalowalności i wydajności dla usługi Table Storage oraz listy kontrolnej wydajności i skalowalności dla usługi Table Storage.
- Azure SQL Database: możesz monitorować wydajność i sprawdzać wartość procentową jednostki transakcji bazy danych (DTU).
- Azure Synapse Analytics: jej możliwości są mierzone w jednostkach magazynu danych (DWU). Zobacz Zarządzanie mocą obliczeniową w usłudze Azure Synapse Analytics (omówienie).
- Azure Cosmos DB: poziomy wydajności w usłudze Azure Cosmos DB.
- SQL Server: monitoruj i dostrajaj wydajność.
- Lokalny serwer plików: dostrajanie wydajności dla serwerów plików.
Powiązana zawartość
Zobacz inne artykuły dotyczące działań kopiowania: