Przewodnik dotyczący wydajności i skalowalności działania kopiowania
DOTYCZY:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
Czasami chcesz przeprowadzić migrację danych na dużą skalę z magazynu danych typu data lake lub przedsiębiorstwa (EDW) do platformy Azure. Innym razem chcesz pozyskiwać duże ilości danych z różnych źródeł do platformy Azure na potrzeby analizy danych big data. W każdym przypadku kluczowe jest osiągnięcie optymalnej wydajności i skalowalności.
Potoki usług Azure Data Factory i Azure Synapse Analytics zapewniają mechanizm pozyskiwania danych z następującymi korzyściami:
- Obsługuje duże ilości danych
- Jest wysoce wydajny
- Jest opłacalne
Te zalety są doskonałe dla inżynierów danych, którzy chcą tworzyć skalowalne potoki pozyskiwania danych, które są wysoce wydajne.
Po przeczytaniu tego artykułu będziesz w stanie odpowiedzieć na następujące pytania:
- Jaki poziom wydajności i skalowalności można osiągnąć przy użyciu działania kopiowania na potrzeby scenariuszy migracji danych i pozyskiwania danych?
- Jakie kroki należy wykonać, aby dostosować wydajność działania kopiowania?
- Jakie optymalizacje wydajności można wykorzystać na potrzeby uruchomienia pojedynczego działania kopiowania?
- Jakie inne czynniki zewnętrzne należy wziąć pod uwagę podczas optymalizowania wydajności kopiowania?
Uwaga
Jeśli nie znasz ogólnie działania kopiowania, zapoznaj się z omówieniem działania kopiowania przed przeczytaniem tego artykułu.
Wydajność kopiowania i osiągalność skalowalności przy użyciu potoków usług Azure Data Factory i Synapse
Potoki usługi Azure Data Factory i Synapse oferują architekturę bezserwerową, która umożliwia równoległość na różnych poziomach.
Ta architektura umożliwia opracowywanie potoków, które maksymalizują przepływność przenoszenia danych dla środowiska. Te potoki w pełni wykorzystują następujące zasoby:
- Przepustowość sieci między źródłowymi i docelowymi magazynami danych
- Operacje wejściowe/wyjściowe magazynu danych źródłowych lub docelowych na sekundę (IOPS) i przepustowości
To pełne wykorzystanie oznacza, że można oszacować ogólną przepływność, mierząc minimalną przepływność dostępną przy użyciu następujących zasobów:
- Źródłowy magazyn danych
- Docelowy magazyn danych
- Przepustowość sieci między źródłowymi i docelowymi magazynami danych
W poniższej tabeli przedstawiono obliczenie czasu trwania przenoszenia danych. Czas trwania każdej komórki jest obliczany na podstawie danej sieci i przepustowości magazynu danych oraz danego rozmiaru ładunku danych.
Uwaga
Podany poniżej czas trwania jest przeznaczony do reprezentowania osiągalnej wydajności w rozwiązaniu do kompleksowej integracji danych przy użyciu co najmniej jednej techniki optymalizacji wydajności opisanej w temacie Kopiowanie funkcji optymalizacji wydajności, w tym przy użyciu narzędzia ForEach do partycjonowania i zduplikowania wielu współbieżnych działań kopiowania. Zalecamy wykonanie kroków opisanych w temacie Performance tuning steps (Kroki dostrajania wydajności), aby zoptymalizować wydajność kopiowania dla określonego zestawu danych i konfiguracji systemu. Należy użyć liczb uzyskanych w testach dostrajania wydajności na potrzeby planowania wdrożenia produkcyjnego, planowania pojemności i projekcji rozliczeń.
| Rozmiar danych / bandwidth |
50 Mb/s | 100 Mb/s | 500 Mb/s | 1 Gb/s | 5 Gb/s | 10 Gb/s | 50 Gb/s |
|---|---|---|---|---|---|---|---|
| 1 GB | 2,7 min | 1,4 min | 0,3 min | 0,1 min | 0,03 min | 0,01 min | 0,0 min |
| 10 GB | 27,3 min | 13,7 min | 2,7 min | 1,3 min | 0,3 min | 0,1 min | 0,03 min |
| 100 GB | 4.6 godz. | 2,3 godz. | 0,5 godz. | 0,2 godz. | 0,05 godz. | 0,02 godz. | 0,0 godz. |
| 1 TB | 46,6 godz. | 23,3 godz. | 4,7 godz. | 2,3 godz. | 0,5 godz. | 0,2 godz. | 0,05 godz. |
| 10 TB | 19,4 dni | 9,7 dni | 1,9 dni | 0,9 dni | 0,2 dni | 0,1 dni | 0,02 dni |
| 100 TB | 194,2 dni | 97,1 dni | 19,4 dni | 9,7 dni | 1,9 dni | 1 dzień | 0,2 dni |
| 1 PB | 64.7 mo | 32.4 mo | 6,5 mo | 3.2 mo | 0,6 mo | 0,3 mo | 0,06 mo |
| 10 PB | 647,3 mo | 323,6 mo | 64.7 mo | 31,6 mo | 6,5 mo | 3.2 mo | 0,6 mo |
Kopiowanie jest skalowalne na różnych poziomach:
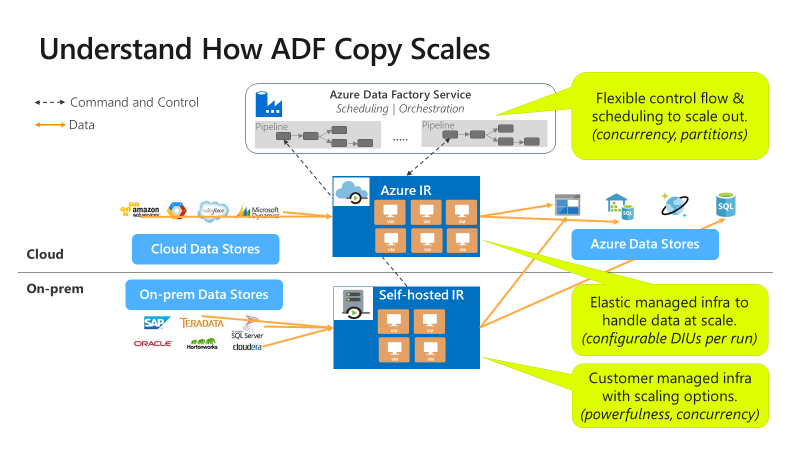
Przepływ sterowania może równolegle uruchamiać wiele działań kopiowania, na przykład za pomocą pętli For Each.
Jedno działanie kopiowania może korzystać ze skalowalnych zasobów obliczeniowych.
- W przypadku korzystania z środowiska Azure Integration Runtime (IR) można określić maksymalnie 256 jednostek integracji danych (DIU) dla każdego działania kopiowania w sposób bezserwerowy.
- W przypadku korzystania z własnego środowiska IR można wykonać jedną z następujących metod:
- Ręczne skalowanie maszyny w górę.
- Skalowanie w poziomie do wielu maszyn (do 4 węzłów), a jedno działanie kopiowania będzie partycjonować jego plik ustawiony na wszystkie węzły.
Jedno działanie kopiowania odczytuje dane i zapisuje je w magazynie danych przy użyciu wielu wątków równolegle.
Kroki dostrajania wydajności
Wykonaj następujące kroki, aby dostroić wydajność usługi za pomocą działania kopiowania:
Wybierz testowy zestaw danych i ustanów punkt odniesienia.
Podczas programowania przetestuj potok przy użyciu działania kopiowania względem reprezentatywnej próbki danych. Wybrany zestaw danych powinien reprezentować typowe wzorce danych wraz z następującymi atrybutami:
- Struktura folderów
- Wzorzec pliku
- Schemat danych
Zestaw danych powinien być wystarczająco duży, aby ocenić wydajność kopiowania. Ukończenie działania kopiowania trwa co najmniej 10 minut. Zbierz szczegóły wykonywania i charakterystykę wydajności po monitorowaniu działania kopiowania.
Jak zmaksymalizować wydajność pojedynczego działania kopiowania:
Zalecamy najpierw zmaksymalizowanie wydajności przy użyciu pojedynczego działania kopiowania.
Jeśli działanie kopiowania jest wykonywane w środowisku Azure Integration Runtime:
Zacznij od wartości domyślnych dla Integracja danych Units (DIU) i ustawień kopiowania równoległego.
Jeśli działanie kopiowania jest wykonywane w własnym środowisku Integration Runtime:
Zalecamy używanie dedykowanej maszyny do hostowania środowiska IR. Maszyna powinna być oddzielona od serwera hostowania magazynu danych. Zacznij od wartości domyślnych dla ustawienia kopiowania równoległego i użyj jednego węzła dla własnego środowiska IR.
Przeprowadź przebieg testu wydajnościowego. Zanotuj osiągniętą wydajność. Uwzględnij używane wartości rzeczywiste, takie jak jednostki DIU i kopie równoległe. Zapoznaj się z tematem copy activity monitoring ( Monitorowanie działania kopiowania), aby uzyskać informacje o sposobie zbierania używanych wyników uruchamiania i ustawień wydajności. Dowiedz się, jak rozwiązywać problemy z wydajnością działania kopiowania, aby zidentyfikować i rozwiązać wąskie gardło.
Iteracja w celu przeprowadzenia dodatkowych przebiegów testów wydajnościowych zgodnie ze wskazówkami dotyczącymi rozwiązywania problemów i dostrajania. Po uruchomieniu pojedynczego działania kopiowania nie można osiągnąć lepszej przepływności, rozważ, czy zmaksymalizować zagregowaną przepływność, uruchamiając wiele kopii jednocześnie. Ta opcja jest omówiona w następnym punktorze numerowanej.
Jak zmaksymalizować zagregowaną przepływność, uruchamiając wiele kopii jednocześnie:
Do tej pory zmaksymalizowano wydajność pojedynczego działania kopiowania. Jeśli nie udało Ci się jeszcze osiągnąć górne limity przepływności środowiska, możesz uruchomić wiele działań kopiowania równolegle. Można uruchomić równolegle przy użyciu konstrukcji przepływu sterowania. Jedną z takich konstrukcji jest pętla For Each. Aby uzyskać więcej informacji, zobacz następujące artykuły dotyczące szablonów rozwiązań:
Rozwiń konfigurację do całego zestawu danych.
Jeśli wyniki wykonywania i wydajność są zadowalające, możesz rozwinąć definicję i potok, aby pokryć cały zestaw danych.
Rozwiązywanie problemów z wydajnością działania Kopiuj
Wykonaj kroki dostrajania wydajności, aby zaplanować i przeprowadzić test wydajnościowy dla danego scenariusza. Dowiedz się również, jak rozwiązywać problemy z wydajnością każdego uruchomienia działania kopiowania, z tematu Rozwiązywanie problemów z wydajnością działania kopiowania.
Funkcje optymalizacji wydajności kopiowania
Usługa udostępnia następujące funkcje optymalizacji wydajności:
- Jednostki integracji danych
- Skalowalność własnego środowiska Integration Runtime
- Kopiowanie równoległe
- Kopia etapowa
Jednostki integracji danych
Jednostka Integracja danych (DIU) to miara reprezentująca moc pojedynczej jednostki w potokach usługi Azure Data Factory i Synapse. Moc to kombinacja alokacji zasobów procesora CPU, pamięci i sieci. DiU dotyczy tylko środowiska Azure Integration Runtime. DiU nie ma zastosowania do własnego środowiska Integration Runtime. Więcej informacji można znaleźć tutaj.
Skalowalność własnego środowiska Integration Runtime
Możesz chcieć hostować rosnące współbieżne obciążenie. Możesz też chcieć osiągnąć wyższą wydajność na obecnym poziomie obciążenia. Skalowanie przetwarzania można zwiększyć, wykonując następujące podejścia:
- Własne środowisko IR można skalować w górę , zwiększając liczbę współbieżnych zadań , które mogą być uruchamiane w węźle.
Skalowanie w górę działa tylko wtedy, gdy procesor i pamięć węzła są mniejsze niż w pełni wykorzystywane. - Własne środowisko IR można skalować w poziomie , dodając więcej węzłów (maszyn).
Aby uzyskać więcej informacji, zobacz:
- działanie Kopiuj funkcje optymalizacji wydajności: skalowalność własnego środowiska Integration Runtime
- Tworzenie i konfigurowanie własnego środowiska Integration Runtime: zagadnienia dotyczące skalowania
Kopiowanie równoległe
Właściwość można ustawić parallelCopies tak, aby wskazywała równoległość, której działanie kopiowania ma być używane. Ta właściwość jest uważana za maksymalną liczbę wątków w działaniu kopiowania. Wątki działają równolegle. Wątki odczytane ze źródła lub zapisu w magazynach danych ujścia. Dowiedz się więcej.
Kopia etapowa
Operacja kopiowania danych może wysyłać dane bezpośrednio do magazynu danych ujścia. Alternatywnie możesz użyć usługi Blob Storage jako tymczasowego magazynu przejściowego. Dowiedz się więcej.
Powiązana zawartość
Zobacz inne artykuły dotyczące działań kopiowania:
- omówienie działanie Kopiuj
- Rozwiązywanie problemów z wydajnością działania Kopiuj
- funkcje optymalizacji wydajności działanie Kopiuj
- Migrowanie danych z usługi Data Lake lub data warehouse na platformę Azure przy użyciu usługi Azure Data Factory
- Migrowanie danych z usługi Amazon S3 do usługi Azure Storage