Kopiowanie danych z platformy Spark przy użyciu usługi Azure Data Factory lub Synapse Analytics
DOTYCZY:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
W tym artykule opisano sposób używania działania kopiowania w potoku usługi Azure Data Factory lub Synapse Analytics do kopiowania danych z platformy Spark. Jest on oparty na artykule omówienie działania kopiowania, który przedstawia ogólne omówienie działania kopiowania.
Obsługiwane możliwości
Ten łącznik Platformy Spark jest obsługiwany w następujących funkcjach:
| Obsługiwane możliwości | IR |
|---|---|
| działanie Kopiuj (źródło/-) | (1) (2) |
| Działanie Lookup | (1) (2) |
(1) Środowisko Azure Integration Runtime (2) Self-hosted Integration Runtime
Aby uzyskać listę magazynów danych obsługiwanych jako źródła/ujścia przez działanie kopiowania, zobacz tabelę Obsługiwane magazyny danych.
Usługa udostępnia wbudowany sterownik umożliwiający łączność, dlatego nie trzeba ręcznie instalować żadnego sterownika przy użyciu tego łącznika.
Wymagania wstępne
Jeśli magazyn danych znajduje się wewnątrz sieci lokalnej, sieci wirtualnej platformy Azure lub chmury prywatnej Amazon Virtual, musisz skonfigurować własne środowisko Integration Runtime , aby się z nim połączyć.
Jeśli magazyn danych jest zarządzaną usługą danych w chmurze, możesz użyć środowiska Azure Integration Runtime. Jeśli dostęp jest ograniczony do adresów IP zatwierdzonych w regułach zapory, możesz dodać adresy IP środowiska Azure Integration Runtime do listy dozwolonych.
Możesz również użyć funkcji środowiska Integration Runtime zarządzanej sieci wirtualnej w usłudze Azure Data Factory, aby uzyskać dostęp do sieci lokalnej bez instalowania i konfigurowania własnego środowiska Integration Runtime.
Aby uzyskać więcej informacji na temat mechanizmów zabezpieczeń sieci i opcji obsługiwanych przez usługę Data Factory, zobacz Strategie dostępu do danych.
Wprowadzenie
Aby wykonać działanie Kopiuj za pomocą potoku, możesz użyć jednego z następujących narzędzi lub zestawów SDK:
- Narzędzie do kopiowania danych
- Witryna Azure Portal
- Zestaw SDK platformy .NET
- Zestaw SDK języka Python
- Azure PowerShell
- Interfejs API REST
- Szablon usługi Azure Resource Manager
Tworzenie połączonej usługi z platformą Spark przy użyciu interfejsu użytkownika
Wykonaj poniższe kroki, aby utworzyć połączoną usługę z platformą Spark w interfejsie użytkownika witryny Azure Portal.
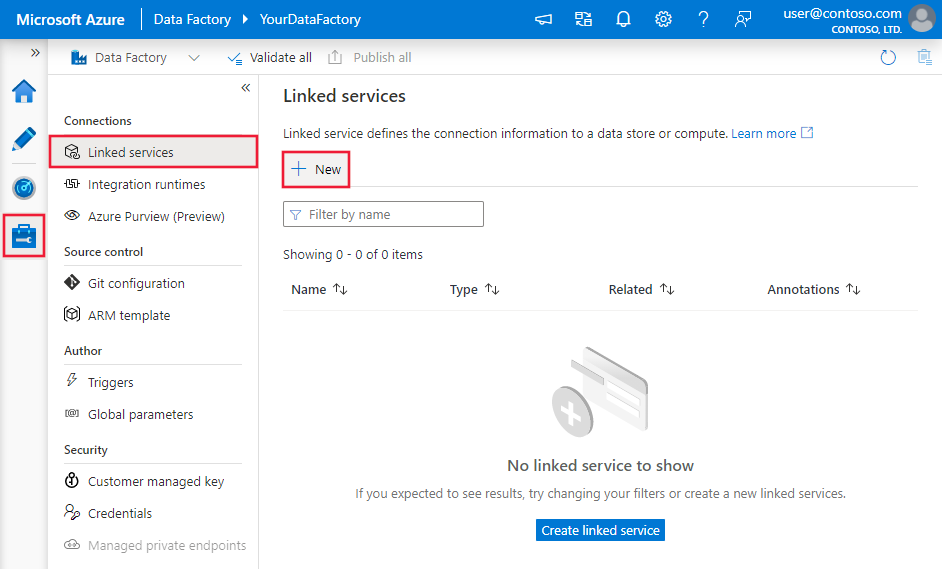
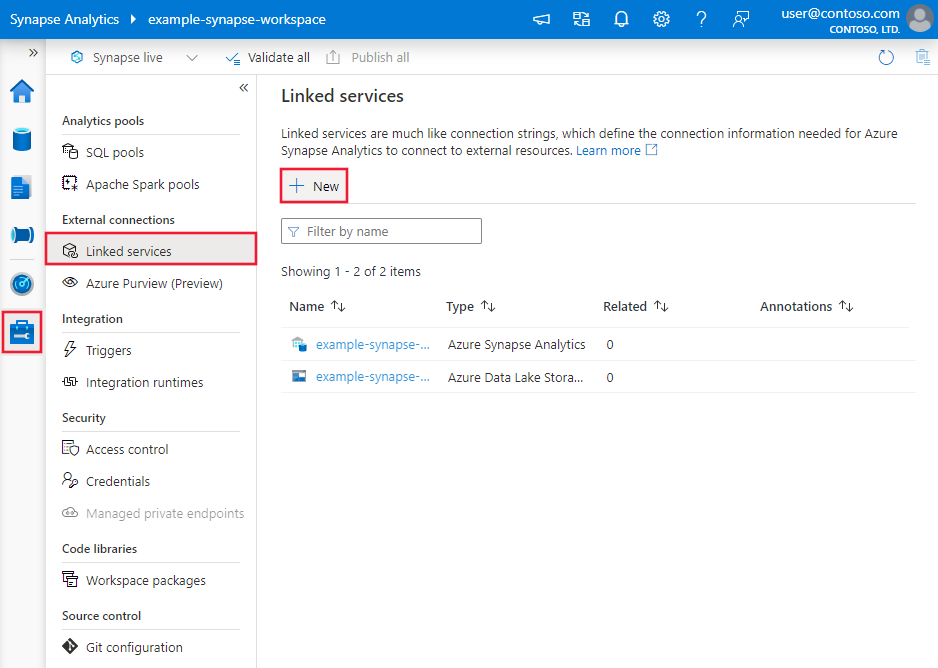
Przejdź do karty Zarządzanie w obszarze roboczym usługi Azure Data Factory lub Synapse i wybierz pozycję Połączone usługi, a następnie kliknij pozycję Nowy:
Wyszukaj ciąg Spark i wybierz łącznik Spark.

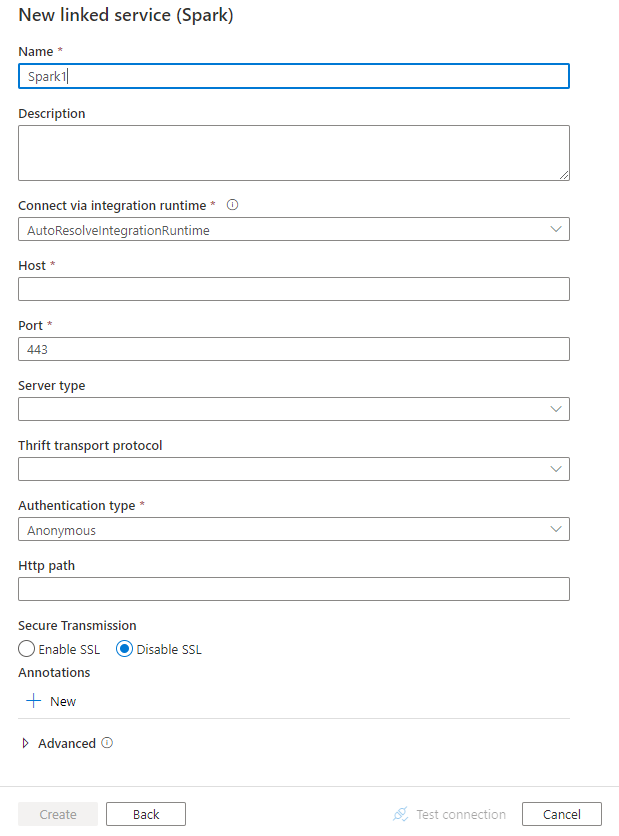
Skonfiguruj szczegóły usługi, przetestuj połączenie i utwórz nową połączoną usługę.
Szczegóły konfiguracji łącznika
Poniższe sekcje zawierają szczegółowe informacje o właściwościach używanych do definiowania jednostek usługi Data Factory specyficznych dla łącznika platformy Spark.
Właściwości połączonej usługi
Następujące właściwości są obsługiwane w przypadku połączonej usługi Spark:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type musi być ustawiona na: Spark | Tak |
| host | Adres IP lub nazwa hosta serwera Spark | Tak |
| port | Port TCP używany przez serwer Spark do nasłuchiwania połączeń klienckich. Jeśli łączysz się z usługą Azure HDInsights, określ port jako 443. | Tak |
| serverType | Typ serwera Spark. Dozwolone wartości to: SharkServer, SharkServer2, SparkThriftServer |
Nie. |
| thriftTransportProtocol | Protokół transportowy do użycia w warstwie Thrift. Dozwolone wartości to: Binary, SASL, HTTP |
Nie. |
| authenticationType | Metoda uwierzytelniania używana do uzyskiwania dostępu do serwera Spark. Dozwolone wartości to: Anonimowe, Nazwa użytkownika, Nazwa użytkownikaAndPassword, WindowsAzureHDInsightService |
Tak |
| nazwa użytkownika | Nazwa użytkownika używana do uzyskiwania dostępu do serwera Spark. | Nie. |
| hasło | Hasło odpowiadające użytkownikowi. Oznacz to pole jako element SecureString w celu bezpiecznego przechowywania go lub odwołuj się do wpisu tajnego przechowywanego w usłudze Azure Key Vault. | Nie. |
| httpPath | Częściowy adres URL odpowiadający serwerowi Spark. | Nie. |
| enableSsl | Określa, czy połączenia z serwerem są szyfrowane przy użyciu protokołu TLS. Wartość domyślna to false. | Nie. |
| trustedCertPath | Pełna ścieżka pliku pem zawierającego zaufane certyfikaty urzędu certyfikacji do weryfikowania serwera podczas nawiązywania połączenia za pośrednictwem protokołu TLS. Tę właściwość można ustawić tylko w przypadku korzystania z protokołu TLS na własnym środowisku IR. Wartość domyślna to plik cacerts.pem zainstalowany z środowiskiem IR. | Nie. |
| useSystemTrustStore | Określa, czy należy użyć certyfikatu urzędu certyfikacji z magazynu zaufania systemu, czy z określonego pliku PEM. Wartość domyślna to false. | Nie. |
| allowHostNameCNMismatch | Określa, czy podczas nawiązywania połączenia za pośrednictwem protokołu TLS/SSL należy wymagać, aby nazwa certyfikatu TLS/SSL wystawiona przez urząd certyfikacji odpowiadała nazwie hosta serwera. Wartość domyślna to false. | Nie. |
| allowSelfSignedServerCert | Określa, czy zezwalać na certyfikaty z podpisem własnym z serwera. Wartość domyślna to false. | Nie. |
| connectVia | Środowisko Integration Runtime do nawiązania połączenia z magazynem danych. Dowiedz się więcej w sekcji Wymagania wstępne . Jeśli nie zostanie określony, używa domyślnego środowiska Azure Integration Runtime. | Nie. |
Przykład:
{
"name": "SparkLinkedService",
"properties": {
"type": "Spark",
"typeProperties": {
"host" : "<cluster>.azurehdinsight.net",
"port" : "<port>",
"authenticationType" : "WindowsAzureHDInsightService",
"username" : "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
}
}
}
Właściwości zestawu danych
Pełna lista sekcji i właściwości dostępnych do definiowania zestawów danych znajduje się w artykule dotyczącym zestawów danych. Ta sekcja zawiera listę właściwości obsługiwanych przez zestaw danych platformy Spark.
Aby skopiować dane z platformy Spark, ustaw właściwość type zestawu danych na SparkObject. Obsługiwane są następujące właściwości:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type zestawu danych musi być ustawiona na: SparkObject | Tak |
| schema | Nazwa schematu. | Nie (jeśli określono "zapytanie" w źródle działania) |
| table | Nazwa tabeli. | Nie (jeśli określono "zapytanie" w źródle działania) |
| tableName | Nazwa tabeli ze schematem. Ta właściwość jest obsługiwana w celu zapewnienia zgodności z poprzednimi wersjami. Użyj polecenia schema i table dla nowego obciążenia. |
Nie (jeśli określono "zapytanie" w źródle działania) |
Przykład
{
"name": "SparkDataset",
"properties": {
"type": "SparkObject",
"typeProperties": {},
"schema": [],
"linkedServiceName": {
"referenceName": "<Spark linked service name>",
"type": "LinkedServiceReference"
}
}
}
Właściwości działania kopiowania
Aby uzyskać pełną listę sekcji i właściwości dostępnych do definiowania działań, zobacz artykuł Pipelines (Potoki ). Ta sekcja zawiera listę właściwości obsługiwanych przez źródło platformy Spark.
Spark jako źródło
Aby skopiować dane z platformy Spark, ustaw typ źródła w działaniu kopiowania na SparkSource. Następujące właściwości są obsługiwane w sekcji źródło działania kopiowania:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type źródła działania kopiowania musi być ustawiona na: SparkSource | Tak |
| zapytanie | Użyj niestandardowego zapytania SQL, aby odczytać dane. Na przykład: "SELECT * FROM MyTable". |
Nie (jeśli określono "tableName" w zestawie danych) |
Przykład:
"activities":[
{
"name": "CopyFromSpark",
"type": "Copy",
"inputs": [
{
"referenceName": "<Spark input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SparkSource",
"query": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Właściwości działania wyszukiwania
Aby dowiedzieć się więcej o właściwościach, sprawdź działanie Wyszukiwania.
Powiązana zawartość
Aby uzyskać listę magazynów danych obsługiwanych jako źródła i ujścia działania kopiowania, zobacz obsługiwane magazyny danych.