Kopiowanie danych do indeksu usługi Azure AI Search przy użyciu usługi Azure Data Factory lub Synapse Analytics
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
W tym artykule opisano sposób użycia działania kopiowania w potoku usługi Azure Data Factory lub Synapse Analytics w celu skopiowania danych do indeksu usługi Azure AI Search. Jest on oparty na artykule omówienie działania kopiowania, który przedstawia ogólne omówienie działania kopiowania.
Obsługiwane możliwości
Ten łącznik usługi Azure AI Search jest obsługiwany w przypadku następujących możliwości:
| Obsługiwane możliwości | IR | Zarządzany prywatny punkt końcowy |
|---|---|---|
| działanie Kopiuj (-/sink) | (1) (2) | ✓ |
(1) Środowisko Azure Integration Runtime (2) Self-hosted Integration Runtime
Dane z dowolnego obsługiwanego magazynu danych źródłowych można skopiować do indeksu wyszukiwania. Aby uzyskać listę magazynów danych obsługiwanych jako źródła/ujścia przez działanie kopiowania, zobacz tabelę Obsługiwane magazyny danych.
Wprowadzenie
Aby wykonać działanie Kopiuj za pomocą potoku, możesz użyć jednego z następujących narzędzi lub zestawów SDK:
- Narzędzie do kopiowania danych
- Witryna Azure Portal
- Zestaw SDK platformy .NET
- Zestaw SDK języka Python
- Azure PowerShell
- Interfejs API REST
- Szablon usługi Azure Resource Manager
Tworzenie połączonej usługi z usługą Azure Search przy użyciu interfejsu użytkownika
Wykonaj poniższe kroki, aby utworzyć połączoną usługę z usługą Azure Search w interfejsie użytkownika witryny Azure Portal.
Przejdź do karty Zarządzanie w obszarze roboczym usługi Azure Data Factory lub Synapse i wybierz pozycję Połączone usługi, a następnie kliknij pozycję Nowy:
Wyszukaj pozycję Wyszukaj i wybierz łącznik usługi Azure Search.
Skonfiguruj szczegóły usługi, przetestuj połączenie i utwórz nową połączoną usługę.
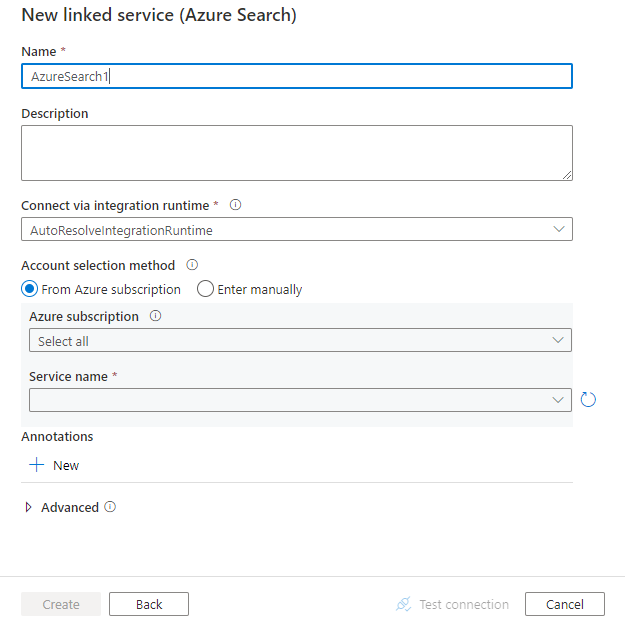
Szczegóły konfiguracji łącznika
Poniższe sekcje zawierają szczegółowe informacje o właściwościach używanych do definiowania jednostek usługi Data Factory specyficznych dla łącznika usługi Azure AI Search.
Właściwości połączonej usługi
Następujące właściwości są obsługiwane w przypadku połączonej usługi Azure AI Search:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type musi być ustawiona na: AzureSearch | Tak |
| Adres URL | Adres URL usługi wyszukiwania. | Tak |
| key | Klucz administratora usługi wyszukiwania. Oznacz to pole jako element SecureString w celu bezpiecznego przechowywania go lub odwołuj się do wpisu tajnego przechowywanego w usłudze Azure Key Vault. | Tak |
| connectVia | Środowisko Integration Runtime do nawiązania połączenia z magazynem danych. Możesz użyć środowiska Azure Integration Runtime lub własnego środowiska Integration Runtime (jeśli magazyn danych znajduje się w sieci prywatnej). Jeśli nie zostanie określony, używa domyślnego środowiska Azure Integration Runtime. | Nie. |
Ważne
Podczas kopiowania danych z magazynu danych w chmurze do indeksu wyszukiwania w połączonej usłudze Azure AI Search należy odwołać się do środowiska Azure Integration Runtime z jawnym regionem w witrynie connectVia. Ustaw region jako region, w którym znajduje się usługa wyszukiwania. Dowiedz się więcej z usługi Azure Integration Runtime.
Przykład:
{
"name": "AzureSearchLinkedService",
"properties": {
"type": "AzureSearch",
"typeProperties": {
"url": "https://<service>.search.windows.net",
"key": {
"type": "SecureString",
"value": "<AdminKey>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Właściwości zestawu danych
Pełna lista sekcji i właściwości dostępnych do definiowania zestawów danych znajduje się w artykule dotyczącym zestawów danych. Ta sekcja zawiera listę właściwości obsługiwanych przez zestaw danych usługi Azure AI Search.
Aby skopiować dane do usługi Azure AI Search, obsługiwane są następujące właściwości:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type zestawu danych musi być ustawiona na: AzureSearchIndex | Tak |
| indexName | Nazwa indeksu wyszukiwania. Usługa nie tworzy indeksu. Indeks musi istnieć w usłudze Azure AI Search. | Tak |
Przykład:
{
"name": "AzureSearchIndexDataset",
"properties": {
"type": "AzureSearchIndex",
"typeProperties" : {
"indexName": "products"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<Azure AI Search linked service name>",
"type": "LinkedServiceReference"
}
}
}
Właściwości działania kopiowania
Aby uzyskać pełną listę sekcji i właściwości dostępnych do definiowania działań, zobacz artykuł Pipelines (Potoki ). Ta sekcja zawiera listę właściwości obsługiwanych przez źródło usługi Azure AI Search.
Usługa Azure AI Search jako ujście
Aby skopiować dane do usługi Azure AI Search, ustaw typ źródła w działaniu kopiowania na wartość AzureSearchIndexSink. Następujące właściwości są obsługiwane w sekcji ujścia działania kopiowania:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type źródła działania kopiowania musi być ustawiona na: AzureSearchIndexSink | Tak |
| writeBehavior | Określa, czy scalić, czy zastąpić, gdy dokument już istnieje w indeksie.
Zobacz właściwość WriteBehavior. Dozwolone wartości to: Scal (wartość domyślna) i Przekaż. |
Nie. |
| writeBatchSize | Przekazuje dane do indeksu wyszukiwania, gdy rozmiar buforu osiągnie wartość writeBatchSize.
Aby uzyskać szczegółowe informacje, zobacz właściwość WriteBatchSize. Dozwolone wartości to: liczba całkowita od 1 do 1000; wartość domyślna to 1000. |
Nie. |
| maxConcurrentConnections | Górny limit połączeń współbieżnych ustanowionych z magazynem danych podczas uruchamiania działania. Określ wartość tylko wtedy, gdy chcesz ograniczyć połączenia współbieżne. | Nie. |
Właściwość WriteBehavior
Usługa AzureSearchSink upserts podczas zapisywania danych. Innymi słowy, podczas pisania dokumentu, jeśli klucz dokumentu już istnieje w indeksie wyszukiwania, usługa Azure AI Search aktualizuje istniejący dokument, a nie zgłasza wyjątek powodujący konflikt.
Usługa AzureSearchSink udostępnia następujące dwa zachowania upsert (przy użyciu zestawu AzureSearch SDK):
- Scal: połącz wszystkie kolumny w nowym dokumencie z istniejącym. W przypadku kolumn z wartością null w nowym dokumencie wartość w istniejącym dokumencie jest zachowywana.
- Przekaż: nowy dokument zastępuje istniejący. W przypadku kolumn, które nie zostały określone w nowym dokumencie, wartość jest ustawiona na wartość null, niezależnie od tego, czy w istniejącym dokumencie znajduje się wartość inna niż null.
Domyślne zachowanie to Scalanie.
WriteBatchSize, właściwość
Usługa Azure AI usługa wyszukiwania obsługuje pisanie dokumentów jako partii. Partia może zawierać od 1 do 1000 akcji. Akcja obsługuje jeden dokument w celu wykonania operacji przekazywania/scalania.
Przykład:
"activities":[
{
"name": "CopyToAzureSearch",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure AI Search output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureSearchIndexSink",
"writeBehavior": "Merge"
}
}
}
]
Obsługa typów danych
W poniższej tabeli określono, czy typ danych usługi Azure AI Search jest obsługiwany, czy nie.
| Typ danych usługi Azure AI Search | Obsługiwane w ujściu usługi Azure AI Search |
|---|---|
| String | Y |
| Int32 | Y |
| Int64 | Y |
| Liczba rzeczywista | Y |
| Wartość logiczna | Y |
| DataTimeOffset | Y |
| Tablica ciągów | N |
| GeographyPoint | N |
Obecnie inne typy danych, np. ComplexType, nie są obsługiwane. Aby uzyskać pełną listę obsługiwanych typów danych usługi Azure AI Search, zobacz Obsługiwane typy danych (Azure AI Search).
Powiązana zawartość
Aby uzyskać listę magazynów danych obsługiwanych jako źródła i ujścia działania kopiowania, zobacz obsługiwane magazyny danych.