Kopiowanie i przekształcanie danych w usłudze Azure Database for MySQL przy użyciu usługi Azure Data Factory lub Synapse Analytics
DOTYCZY:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
W tym artykule opisano sposób używania działania kopiowania w potokach usługi Azure Data Factory lub Synapse Analytics do kopiowania danych z i do usługi Azure Database for MySQL oraz używania Przepływ danych do przekształcania danych w usłudze Azure Database for MySQL. Aby dowiedzieć się więcej, przeczytaj artykuły wprowadzające dotyczące usług Azure Data Factory i Synapse Analytics.
Ten łącznik jest przeznaczony dla
- Usługa Azure Database for MySQL — pojedynczy serwer
- Usługa Azure Database for MySQL — serwer elastyczny
Aby skopiować dane z ogólnej bazy danych MySQL znajdującej się lokalnie lub w chmurze, użyj łącznika MySQL.
Wymagania wstępne
Ten przewodnik Szybki start wymaga następujących zasobów i konfiguracji wymienionych poniżej jako punktu wyjścia:
- Istniejąca usługa Azure Database for MySQL — pojedynczy serwer lub serwer elastyczny MySQL z dostępem publicznym lub prywatnym punktem końcowym.
- Włącz opcję Zezwalaj na dostęp publiczny z dowolnej usługi platformy Azure na tym serwerze na stronie sieci serwera MySQL. Umożliwi to korzystanie z programu Data Factory Studio.
Obsługiwane możliwości
Ten łącznik usługi Azure Database for MySQL jest obsługiwany w przypadku następujących możliwości:
| Obsługiwane możliwości | IR | Zarządzany prywatny punkt końcowy |
|---|---|---|
| działanie Kopiuj (źródło/ujście) | (1) (2) | ✓ |
| Przepływ danych mapowania (źródło/ujście) | (1) | ✓ |
| Działanie Lookup | (1) (2) | ✓ |
(1) Środowisko Azure Integration Runtime (2) Self-hosted Integration Runtime
Wprowadzenie
Aby wykonać działanie Kopiuj za pomocą potoku, możesz użyć jednego z następujących narzędzi lub zestawów SDK:
- Narzędzie do kopiowania danych
- Witryna Azure Portal
- Zestaw SDK platformy .NET
- Zestaw SDK języka Python
- Azure PowerShell
- Interfejs API REST
- Szablon usługi Azure Resource Manager
Tworzenie połączonej usługi z usługą Azure Database for MySQL przy użyciu interfejsu użytkownika
Wykonaj poniższe kroki, aby utworzyć połączoną usługę z usługą Azure Database for MySQL w interfejsie użytkownika witryny Azure Portal.
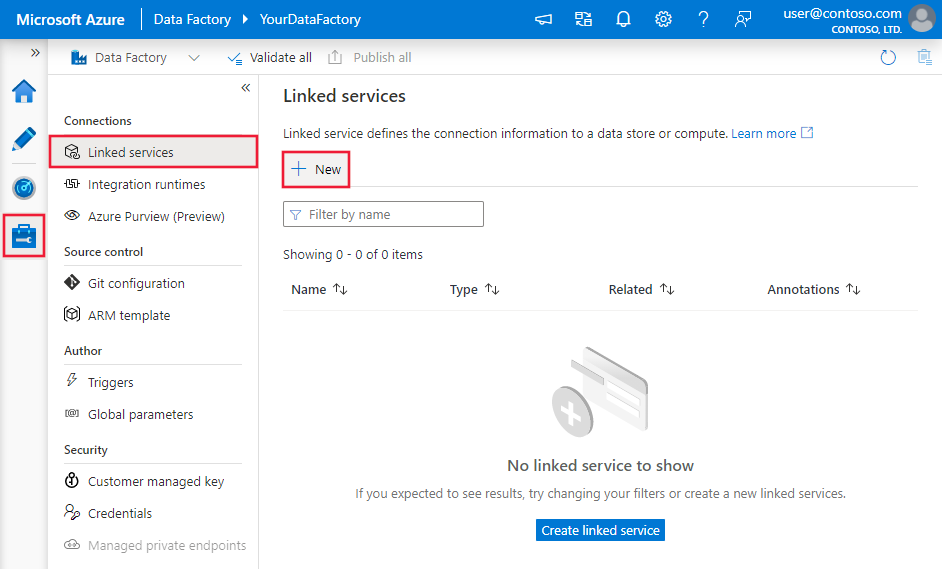
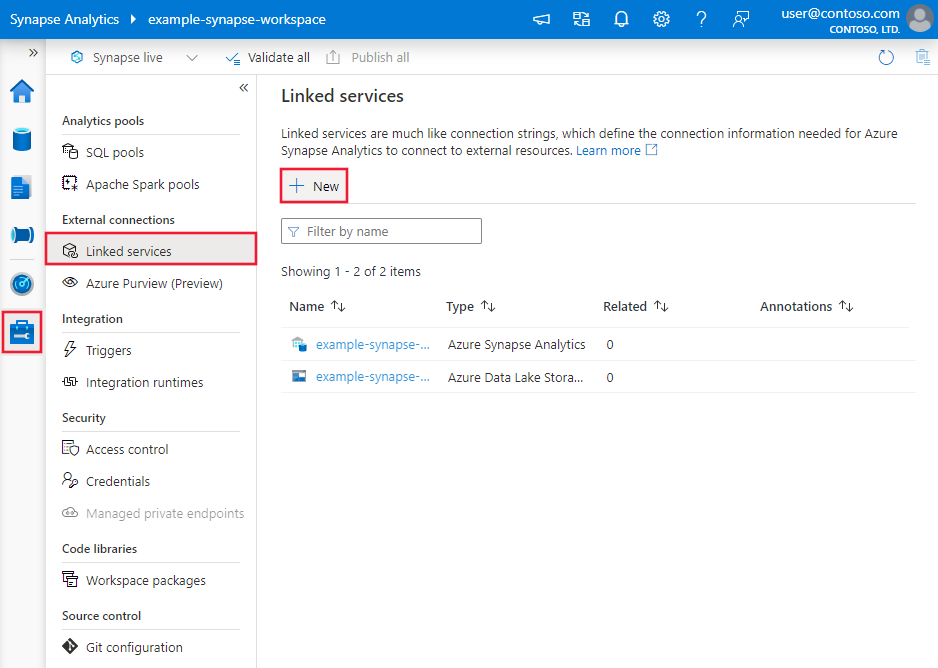
Przejdź do karty Zarządzanie w obszarze roboczym usługi Azure Data Factory lub Synapse i wybierz pozycję Połączone usługi, a następnie kliknij pozycję Nowy:
Wyszukaj ciąg MySQL i wybierz łącznik usługi Azure Database for MySQL.

Skonfiguruj szczegóły usługi, przetestuj połączenie i utwórz nową połączoną usługę.
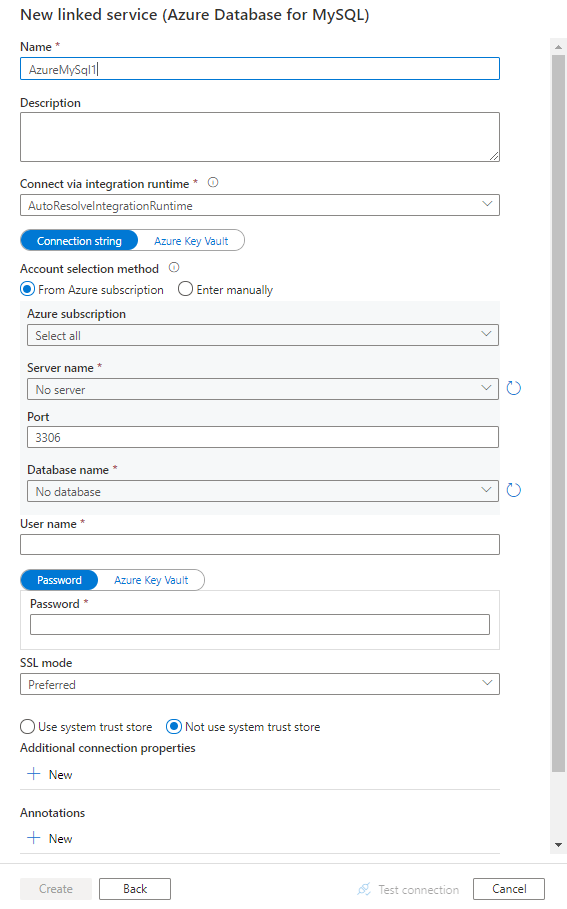
Szczegóły konfiguracji łącznika
Poniższe sekcje zawierają szczegółowe informacje o właściwościach używanych do definiowania jednostek usługi Data Factory specyficznych dla łącznika usługi Azure Database for MySQL.
Właściwości połączonej usługi
Następujące właściwości są obsługiwane w przypadku połączonej usługi Azure Database for MySQL:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type musi być ustawiona na: AzureMySql | Tak |
| Parametry połączenia | Określ informacje potrzebne do nawiązania połączenia z wystąpieniem usługi Azure Database for MySQL. Możesz również umieścić hasło w usłudze Azure Key Vault i ściągnąć konfigurację password z parametry połączenia. Zapoznaj się z poniższymi przykładami i artykułem Store credentials in Azure Key Vault (Przechowywanie poświadczeń w usłudze Azure Key Vault ), aby uzyskać więcej szczegółów. |
Tak |
| connectVia | Środowisko Integration Runtime do nawiązania połączenia z magazynem danych. Możesz użyć środowiska Azure Integration Runtime lub własnego środowiska Integration Runtime (jeśli magazyn danych znajduje się w sieci prywatnej). Jeśli nie zostanie określony, używa domyślnego środowiska Azure Integration Runtime. | Nie. |
Typowy parametry połączenia to Server=<server>.mysql.database.azure.com;Port=<port>;Database=<database>;UID=<username>;PWD=<password>. Więcej właściwości, które można ustawić w danym przypadku:
| Właściwości | opis | Opcje | Wymagania |
|---|---|---|---|
| Tryb SSL | Ta opcja określa, czy sterownik używa szyfrowania TLS i weryfikacji podczas nawiązywania połączenia z bazą danych MySQL. Np. SSLMode=<0/1/2/3/4> |
WYŁĄCZONE (0) / PREFEROWANE (1) (ustawienie domyślne) / WYMAGANE (2) / VERIFY_CA (3) / VERIFY_IDENTITY (4) | Nie. |
| UseSystemTrustStore | Ta opcja określa, czy używać certyfikatu urzędu certyfikacji z magazynu zaufania systemu, czy z określonego pliku PEM. Np. UseSystemTrustStore=<0/1>; |
Włączone (1) / Wyłączone (0) (ustawienie domyślne) | Nie. |
Przykład:
{
"name": "AzureDatabaseForMySQLLinkedService",
"properties": {
"type": "AzureMySql",
"typeProperties": {
"connectionString": "Server=<server>.mysql.database.azure.com;Port=<port>;Database=<database>;UID=<username>;PWD=<password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Przykład: przechowywanie hasła w usłudze Azure Key Vault
{
"name": "AzureDatabaseForMySQLLinkedService",
"properties": {
"type": "AzureMySql",
"typeProperties": {
"connectionString": "Server=<server>.mysql.database.azure.com;Port=<port>;Database=<database>;UID=<username>;",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Właściwości zestawu danych
Pełna lista sekcji i właściwości dostępnych do definiowania zestawów danych znajduje się w artykule dotyczącym zestawów danych. Ta sekcja zawiera listę właściwości obsługiwanych przez zestaw danych usługi Azure Database for MySQL.
Aby skopiować dane z usługi Azure Database for MySQL, ustaw właściwość type zestawu danych na wartość AzureMySqlTable. Obsługiwane są następujące właściwości:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type zestawu danych musi być ustawiona na: AzureMySqlTable | Tak |
| tableName | Nazwa tabeli w bazie danych MySQL. | Nie (jeśli określono "zapytanie" w źródle działania) |
Przykład
{
"name": "AzureMySQLDataset",
"properties": {
"type": "AzureMySqlTable",
"linkedServiceName": {
"referenceName": "<Azure MySQL linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"tableName": "<table name>"
}
}
}
Właściwości działania kopiowania
Aby uzyskać pełną listę sekcji i właściwości dostępnych do definiowania działań, zobacz artykuł Pipelines (Potoki ). Ta sekcja zawiera listę właściwości obsługiwanych przez źródło i ujście usługi Azure Database for MySQL.
Usługa Azure Database for MySQL jako źródło
Aby skopiować dane z usługi Azure Database for MySQL, w sekcji źródła działania kopiowania są obsługiwane następujące właściwości:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type źródła działania kopiowania musi być ustawiona na: AzureMySqlSource | Tak |
| zapytanie | Użyj niestandardowego zapytania SQL, aby odczytać dane. Na przykład: "SELECT * FROM MyTable". |
Nie (jeśli określono "tableName" w zestawie danych) |
| queryCommandTimeout | Czas oczekiwania przed przekroczeniem limitu czasu żądania zapytania. Wartość domyślna to 120 minut (02:00:00) | Nie. |
Przykład:
"activities":[
{
"name": "CopyFromAzureDatabaseForMySQL",
"type": "Copy",
"inputs": [
{
"referenceName": "<Azure MySQL input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureMySqlSource",
"query": "<custom query e.g. SELECT * FROM MyTable>"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Usługa Azure Database for MySQL jako ujście
Aby skopiować dane do usługi Azure Database for MySQL, w sekcji ujścia działania kopiowania są obsługiwane następujące właściwości:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type ujścia działania kopiowania musi być ustawiona na: AzureMySqlSink | Tak |
| preCopyScript | Określ zapytanie SQL dla działania kopiowania do wykonania przed zapisaniem danych w usłudze Azure Database for MySQL w każdym uruchomieniu. Za pomocą tej właściwości można wyczyścić wstępnie załadowane dane. | Nie. |
| writeBatchSize | Wstawia dane do tabeli usługi Azure Database for MySQL, gdy rozmiar buforu osiągnie wartość writeBatchSize. Dozwolona wartość to liczba całkowita reprezentująca liczbę wierszy. |
Nie (wartość domyślna to 10 000) |
| writeBatchTimeout | Czas oczekiwania na ukończenie operacji wstawiania wsadowego przed przekroczeniem limitu czasu. Dozwolone wartości to Przedział czasu. Przykładem jest 00:30:00 (30 minut). |
Nie (wartość domyślna to 00:00:30) |
Przykład:
"activities":[
{
"name": "CopyToAzureDatabaseForMySQL",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure MySQL output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureMySqlSink",
"preCopyScript": "<custom SQL script>",
"writeBatchSize": 100000
}
}
}
]
Właściwości przepływu mapowania danych
Podczas przekształcania danych w przepływie mapowania danych można odczytywać i zapisywać w tabelach z usługi Azure Database for MySQL. Aby uzyskać więcej informacji, zobacz przekształcanie źródła i przekształcanie ujścia w przepływach danych mapowania. Możesz użyć zestawu danych usługi Azure Database for MySQL lub wbudowanego zestawu danych jako typu źródła i ujścia.
Przekształcanie źródła
W poniższej tabeli wymieniono właściwości obsługiwane przez źródło usługi Azure Database for MySQL. Te właściwości można edytować na karcie Opcje źródła.
| Nazwa/nazwisko | opis | Wymagania | Dozwolone wartości | Właściwość skryptu przepływu danych |
|---|---|---|---|---|
| Table | W przypadku wybrania pozycji Tabela jako danych wejściowych przepływ danych pobiera wszystkie dane z tabeli określonej w zestawie danych. | Nie. | - | (tylko w przypadku wbudowanego zestawu danych) tableName |
| Query | Jeśli wybierzesz pozycję Zapytanie jako dane wejściowe, określ zapytanie SQL, aby pobrać dane ze źródła, które zastępuje dowolną tabelę, którą określisz w zestawie danych. Korzystanie z zapytań to doskonały sposób na zmniejszenie liczby wierszy na potrzeby testowania lub wyszukiwania. Klauzula Order By nie jest obsługiwana, ale można ustawić pełną instrukcję SELECT FROM. Można również użyć funkcji tabeli zdefiniowanych przez użytkownika. select * from udfGetData() is a UDF in SQL that zwraca tabelę, której można użyć w przepływie danych. Przykład zapytania: select * from mytable where customerId > 1000 and customerId < 2000 lub select * from "MyTable". |
Nie. | String | zapytanie |
| Procedura składowana | Jeśli wybierzesz procedurę składowaną jako dane wejściowe, określ nazwę procedury składowanej do odczytu danych z tabeli źródłowej lub wybierz pozycję Odśwież, aby poprosić usługę o odnalezienie nazw procedur. | Tak (jeśli wybierzesz procedurę składowaną jako dane wejściowe) | String | procedureName |
| Parametry procedury | Jeśli wybierzesz procedurę składowaną jako dane wejściowe, określ parametry wejściowe procedury składowanej w kolejności ustawionej w procedurze lub wybierz pozycję Importuj, aby zaimportować wszystkie parametry procedury przy użyciu formularza @paraName. |
Nie. | Tablica | Wejścia |
| Rozmiar partii | Określ rozmiar partii, aby podzielić duże dane na partie. | Nie. | Integer | batchSize |
| Poziom izolacji | Wybierz jeden z następujących poziomów izolacji: - Odczyt zatwierdzony - Odczyt niezatwierdzony (ustawienie domyślne) - Powtarzalny odczyt -Serializacji - Brak (ignoruj poziom izolacji) |
Nie. | READ_COMMITTED READ_UNCOMMITTED REPEATABLE_READ SERIALIZACJI BRAK |
isolationLevel |
Przykładowy skrypt źródłowy usługi Azure Database for MySQL
Jeśli używasz usługi Azure Database for MySQL jako typu źródła, skojarzony skrypt przepływu danych to:
source(allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
query: 'select * from mytable',
format: 'query') ~> AzureMySQLSource
Przekształcenie ujścia
W poniższej tabeli wymieniono właściwości obsługiwane przez ujście usługi Azure Database for MySQL. Te właściwości można edytować na karcie Opcje ujścia.
| Nazwa/nazwisko | opis | Wymagania | Dozwolone wartości | Właściwość skryptu przepływu danych |
|---|---|---|---|---|
| Metoda aktualizacji | Określ, jakie operacje są dozwolone w miejscu docelowym bazy danych. Ustawieniem domyślnym jest zezwalanie tylko na wstawianie. Aby zaktualizować, upsert lub usunąć wiersze, do tagowania wierszy dla tych akcji jest wymagane przekształcenie alter wiersza. |
Tak | true lub false |
możliwe do usunięcia możliwość wstawienia możliwe do aktualizacji upsertable |
| Kolumny kluczy | W przypadku aktualizacji, operacji upserts i delete należy ustawić kolumny kluczy, aby określić, który wiersz ma zostać zmieniony. Nazwa kolumny wybranej jako klucz będzie używana w ramach kolejnej aktualizacji, upsert, delete. W związku z tym należy wybrać kolumnę, która istnieje w mapowaniu ujścia. |
Nie. | Tablica | keys |
| Pomijanie zapisywania kolumn kluczy | Jeśli nie chcesz zapisywać wartości w kolumnie klucza, wybierz pozycję "Pomiń pisanie kolumn kluczy". | Nie. | true lub false |
skipKeyWrites |
| Akcja tabeli | Określa, czy należy ponownie utworzyć lub usunąć wszystkie wiersze z tabeli docelowej przed zapisem. - Brak: żadna akcja nie zostanie wykonana w tabeli. - Utwórz ponownie: tabela zostanie porzucona i utworzona ponownie. Wymagane w przypadku dynamicznego tworzenia nowej tabeli. - Obcinanie: wszystkie wiersze z tabeli docelowej zostaną usunięte. |
Nie. | true lub false |
odtworzyć truncate |
| Rozmiar partii | Określ liczbę wierszy zapisywanych w każdej partii. Większe rozmiary partii zwiększają kompresję i optymalizację pamięci, ale ryzykuj z wyjątków pamięci podczas buforowania danych. | Nie. | Integer | batchSize |
| Skrypty pre-sql i post | Określ wielowierszowe skrypty SQL, które będą wykonywane przed (wstępne przetwarzanie) i po (przetwarzaniu po przetwarzaniu) dane są zapisywane w bazie danych ujścia. | Nie. | String | preSQLs postSQLs |
Napiwek
- Zaleca się podzielenie pojedynczych skryptów wsadowych z wieloma poleceniami na wiele partii.
- W ramach partii można uruchamiać tylko instrukcje języka DDL (Data Definition Language) i Języka manipulowania danymi (DML), które zwracają prostą liczbę aktualizacji. Dowiedz się więcej na temat wykonywania operacji wsadowych
Włącz wyodrębnianie przyrostowe: użyj tej opcji, aby poinformować usługę ADF o przetwarzaniu tylko wierszy, które uległy zmianie od czasu ostatniego wykonania potoku.
Kolumna przyrostowa: w przypadku korzystania z funkcji wyodrębniania przyrostowego należy wybrać kolumnę daty/godziny lub liczbową, która ma być używana jako znak wodny w tabeli źródłowej.
Rozpocznij odczytywanie od początku: ustawienie tej opcji przy użyciu wyodrębniania przyrostowego spowoduje, że usługa ADF odczytuje wszystkie wiersze podczas pierwszego wykonywania potoku z włączonym wyodrębnieniem przyrostowym.
Przykładowy skrypt ujścia usługi Azure Database for MySQL
Jeśli używasz usługi Azure Database for MySQL jako typu ujścia, skojarzony skrypt przepływu danych to:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:true,
updateable:true,
upsertable:true,
keys:['keyColumn'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> AzureMySQLSink
Właściwości działania wyszukiwania
Aby dowiedzieć się więcej o właściwościach, sprawdź działanie Wyszukiwania.
Mapowanie typów danych dla usługi Azure Database for MySQL
Podczas kopiowania danych z usługi Azure Database for MySQL następujące mapowania są używane z typów danych MySQL do tymczasowych typów danych używanych wewnętrznie w usłudze. Zobacz Mapowania schematu i typu danych, aby dowiedzieć się, jak działanie kopiowania mapuje schemat źródłowy i typ danych na ujście.
| Typ danych usługi Azure Database for MySQL | Typ danych usługi tymczasowej |
|---|---|
bigint |
Int64 |
bigint unsigned |
Decimal |
bit |
Boolean |
bit(M), M>1 |
Byte[] |
blob |
Byte[] |
bool |
Int16 |
char |
String |
date |
Datetime |
datetime |
Datetime |
decimal |
Decimal, String |
double |
Double |
double precision |
Double |
enum |
String |
float |
Single |
int |
Int32 |
int unsigned |
Int64 |
integer |
Int32 |
integer unsigned |
Int64 |
long varbinary |
Byte[] |
long varchar |
String |
longblob |
Byte[] |
longtext |
String |
mediumblob |
Byte[] |
mediumint |
Int32 |
mediumint unsigned |
Int64 |
mediumtext |
String |
numeric |
Decimal |
real |
Double |
set |
String |
smallint |
Int16 |
smallint unsigned |
Int32 |
text |
String |
time |
TimeSpan |
timestamp |
Datetime |
tinyblob |
Byte[] |
tinyint |
Int16 |
tinyint unsigned |
Int16 |
tinytext |
String |
varchar |
String |
year |
Int32 |
Powiązana zawartość
Aby uzyskać listę magazynów danych obsługiwanych jako źródła i ujścia działania kopiowania, zobacz obsługiwane magazyny danych.