Waarschijnlijkheidsfunctie evalueren
Belangrijk
De ondersteuning voor Azure Machine Learning-studio (klassiek) eindigt op 31 augustus 2024. U wordt aangeraden om vóór die datum over te stappen naar Azure Machine Learning.
Vanaf 1 december 2021 kunt u geen nieuwe resources voor Azure Machine Learning-studio (klassiek) meer maken. Tot en met 31 augustus 2024 kunt u de bestaande resources van Azure Machine Learning-studio (klassiek) blijven gebruiken.
- Zie informatie over het verplaatsen van machine learning-projecten van ML Studio (klassiek) naar Azure Machine Learning.
- Meer informatie over Azure Machine Learning.
De documentatie van ML-studio (klassiek) wordt buiten gebruik gesteld en wordt in de toekomst mogelijk niet meer bijgewerkt.
Past bij een opgegeven waarschijnlijkheidsverdelingsfunctie voor een gegevensset
Categorie: Statistische functies
Notitie
Van toepassing op: alleen Machine Learning Studio (klassiek)
Vergelijkbare modules voor slepen en neerzetten zijn beschikbaar in Azure Machine Learning designer.
Moduleoverzicht
In dit artikel wordt beschreven hoe u de module Waarschijnlijkheidsfunctie evalueren in Machine Learning Studio (klassiek) gebruikt om statistische metingen te berekenen die de verdeling van een kolom beschrijven, zoals de Bernoulli-, Pareto- of Poisson-verdelingen.
Als u dit model wilt gebruiken, verbindt u een gegevensset die ten minste één kolom met numerieke waarden bevat en kiest u een waarschijnlijkheidsverdeling die u wilt testen. De module retourneert een gegevenstabel met waarden uit de opgegeven waarschijnlijkheidsfunctie.
U kunt een van deze waarden berekenen voor de gekozen waarschijnlijkheidsverdeling:
- cumulatieve verdelingsfunctie (cdf)
- inverse cumulatieve verdelingsfunctie (InverseCdf)
- kansdichtheidsfunctie (Pdf)
Waarom is de waarschijnlijkheidsverdeling nuttig?
Wanneer u uw gegevens evalueert op basis van een waarschijnlijkheidsverdeling, worden kolomwaarden toegewezen aan een set waarden met bekende eigenschappen. Door te weten of uw gegevens overeenkomen met een van deze bekende distributies, kunt u mogelijk andere eigenschappen van uw gegevens afleiden. Over het algemeen krijgt u betere voorspellingen van een model wanneer u de distributie kunt identificeren die het beste bij de gegevens past.
De vraag welke waarschijnlijkheidsverdelingsfunctie moet worden gebruikt, is afhankelijk van de gegevens en de variabelen die worden gemeten. Sommige distributies zijn bijvoorbeeld ontworpen om de waarschijnlijkheid van discrete waarden te beschrijven; andere zijn alleen bedoeld voor gebruik met doorlopende numerieke variabelen. Voor sommige distributies moet u ook van tevoren een verwacht gemiddelde, vrijheidsgraden, enzovoort weten. Zie Ondersteunde kansverdelingen voor meer informatie
De kansfunctie evalueren configureren
Alle opties veranderen afhankelijk van het type waarschijnlijkheidsverdeling dat u wilt berekenen. Als u de kansverdelingsmethode wijzigt, worden andere selecties die u mogelijk hebt gemaakt, opnieuw ingesteld.
Zorg er daarom voor dat u eerst de optie Distributie kiest.
De gegevensset die als invoer wordt gebruikt, moet numerieke gegevens bevatten. Andere typen gegevens worden genegeerd.
Voor elke analyse kunt u één kansverdelingsmethode toepassen. Als u een andere waarschijnlijkheidsverdeling wilt berekenen, voegt u een afzonderlijk exemplaar van de module toe voor elke distributie die u wilt testen.
Voeg de module Kansfunctie evalueren toe aan uw experiment. U vindt deze module in de categorie Statistische functies in Machine Learning Studio (klassiek).
Verbinding maken een gegevensset die ten minste één kolom met getallen bevat.
Gebruik de optie Distributie om het soort waarschijnlijkheidsverdeling te selecteren dat u wilt berekenen. Zie Ondersteunde kansverdelingen voor een lijst met opties en de vereiste argumenten.
Stel parameters in die vereist zijn voor de distributie.
Kies een van de drie statistieken die u wilt maken: de cumulatieve verdelingsfunctie (cdf), de inverse cumulatieve verdelingsfunctie (InverseCdf) of de kansdichtheidsfunctie (pdf).
Zie de sectie Technische opmerkingen voor definities.
Gebruik de kolomkiezer om de kolommen te kiezen waarvoor de geselecteerde waarschijnlijkheidsverdeling moet worden berekend.
Alle kolommen die u selecteert, moeten een numeriek gegevenstype hebben.
Het gegevensbereik in de kolom moet ook geldig zijn, gezien de geselecteerde waarschijnlijkheidsfunctie. Anders kan er een fout of NaN-resultaat optreden.
Voor parseringskolommen worden waarden die overeenkomen met achtergrondnullen niet verwerkt.
Gebruik de optie Resultaatmodus om op te geven hoe de resultaten moeten worden uitgevoerd. U kunt kolomwaarden vervangen door de waarschijnlijkheidsdistributiewaarden, de nieuwe waarden toevoegen aan de gegevensset of alleen de waarschijnlijkheidsverdelingswaarden retourneren.
Voer het experiment uit of klik met de rechtermuisknop op de module Waarschijnlijkheidsfunctie evalueren en klik op Uitvoeren geselecteerd.
Resultaten
De volgende tabel bevat een voorbeeld van resultaten, met behulp van de optie Toevoegen , op één temperatuurkolom uit de voorbeeldgegevensset Forest Fires .
| temp | StandardNormal.Cdf(temp) | StandardNormal.Pdf(temp) | FFisher.cdf(temp | FFisher.cdf(temp |
|---|---|---|---|---|
| 8.2 | 1 | 1 | 0.984774 | 0.004349 |
| 18 | 1 | 1 | 0.997896 | 0.000311 |
| 14.6 | 1 | 1 | 0.996352 | 0.000648 |
| 8.3 | 1 | 1 | 0.985201 | 0.004187 |
| 11,4 | 1 | 1 | 0.993147 | 0.001502 |
De koppen van de gegenereerde kolommen bevatten de waarschijnlijkheidsverdeling die is gebruikt.
Als u niet zeker weet welke waarschijnlijkheidsverdeling waarschijnlijk past bij uw gegevens, kunt u een snel diagram maken van cumulatieve verdeling en kansdichtheid voor elke numerieke kolom.
- Klik met de rechtermuisknop op de uitvoer van de gegevensset of module en selecteer Visualiseren.
- Selecteer de interessekolom en selecteer in het deelvenster Histogramde cumulatieve verdeling of kansdichtheid.
- Een grafiek van de distributie, zoals het volgende, wordt vervangen door het histogram dat de gegevens vertegenwoordigt.
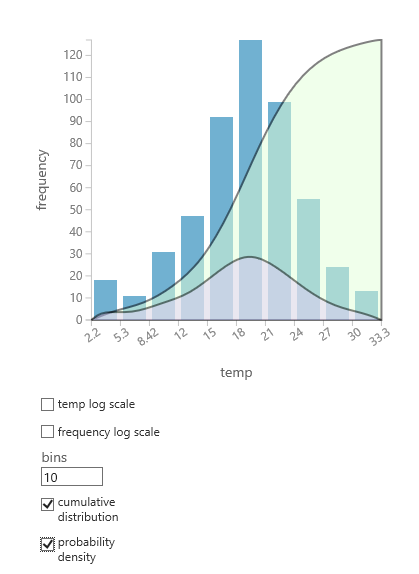
Ondersteunde kansverdelingen
De module Evaluate Probability Function ondersteunt de volgende verdelingen:
Bernoulli
De Bernoulli-verdeling is een verdeling over binaire waarden: met andere woorden, het modelleert de verwachte verdeling wanneer slechts twee waarden mogelijk zijn.
Als u wilt berekenen, selecteert u Bernoulli en stelt u de volgende opties in:
- Kans op succes
De parameter p geeft de kans op dat een 1 wordt gegenereerd. Typ een getal (float) tussen 0,0 en 1,0 dat de kans op succes aangeeft. De standaardwaarde is .5.
Bèta
De bèta-verdeling is een continue univariate verdeling.
Als u wilt berekenen, selecteert u Bèta en stelt u de volgende opties in:
Vorm
Typ een waarde om de vorm van de verdeling te wijzigen.Een shapeparameter is een parameter van een waarschijnlijkheidsverdeling die de locatie of schaal niet definieert. Wanneer u daarom een waarde voor een shape invoert, verandert de parameter de vorm van de verdeling in plaats van deze te verplaatsen, uit te rekken of te verkleinen.
De waarde moet een getal (
double) zijn. De standaardwaarde is 1.0.Schalen
Typ een getal dat u wilt gebruiken voor het schalen van de distributie.Door een schaalwaarde toe te passen op de distributie, kunt u deze verkleinen of uitrekken.
De standaardwaarde is 1,0. Waarden moeten positieve getallen zijn.
Bovengrens
Typ een getal (double) dat de bovengrens van de verdeling vertegenwoordigt. De standaardwaarde is 1.0.Ondergrens
Typ een getal (double) dat de ondergrens van de verdeling vertegenwoordigt. De standaardwaarde is 0.0.
Binomiale
De binomiale verdeling is een discrete univariate-verdeling. De binomiale verdeling wordt gebruikt om het aantal gunstige uitkomsten in een steekproef te modelleren. Vervanging wordt gebruikt bij het nemen van steekproeven. Gebruik de Hypergeometrische verdeling voor steekproeven zonder vervanging.
Als u wilt berekenen, selecteert u Binomiaal en stelt u de volgende opties in:
Kans op succes
Typ een getal (float) tussen 0,0 en 1,0 dat de kans op succes aangeeft. De standaardwaarde is .5.Aantal proefversies
Geef het aantal proefversies op.Gebruik een
integer, met een minimumwaarde van 1. De standaardwaarde is 3.
Cauchy
De Cauchy-verdeling is een symmetrische continue waarschijnlijkheidsverdeling.
Als u wilt berekenen, selecteert u Cauchy en stelt u de volgende opties in:
Locatie
Typ een getal (double) dat de locatie van het0e element aangeeft.Door een waarde voor de parameter Locatie op te geven, kunt u de waarschijnlijkheidsverdeling omhoog of omlaag verplaatsen naar een numerieke schaal.
De standaardwaarde is 0.0.
ChiSquare
De chi-kwadratische verdeling is een som van de kwadraten van k onafhankelijke, standaard, normale, willekeurige variabelen.
Als u wilt berekenen, selecteert u ChiSquare en stelt u de volgende opties in:
- Aantal vrijheidsgraden Typ een getal (
double) om de vrijheidsgraden op te geven. De standaardwaarde is 1.0.
ChiSquareRightTailed
Deze optie biedt een rechtszijdige chi-kwadraatverdeling.
Als u wilt berekenen, selecteert u ChiSquareRightTailed en stelt u de volgende opties in:
- Aantal vrijheidsgraden
Typ een getal (double) om de vrijheidsgraden op te geven. De standaardwaarde is 1.0.
Exponentieel
De exponentiële verdeling is een verdeling over de reële getallen die worden geparameteriseerd door één niet-negatieve parameter.
Als u wilt berekenen, selecteert u Exponentieel en stelt u de volgende opties in:
- Lambda
Typ een getal (double) dat moet worden gebruikt als de lambda-parameter. De standaardwaarde is 1.0.
FFisher
Genereert de waarschijnlijkheid van de Fisher-statistiek voor een steekproef, ook wel bekend als de Fisher F-verdeling. Deze verdeling is tweezijdig.
Als u wilt berekenen, selecteert u FFisher en stelt u de volgende opties in:
Vrijheidsgraden van teller
Typ een getal (double) om de vrijheidsgraden op te geven die in de teller worden gebruikt. De standaardwaarde is 3.0.Noemergraden van vrijheid
Typ een getal (double) om de vrijheidsgraden op te geven die in de noemer worden gebruikt. De standaardwaarde is 6.0.
FFisherRightTailed
Hiermee maakt u een rechtszijdige Fisher-distributie. De Fisher-distributie wordt ook wel de Fisher F-distributie, Snedecor-distributie of Fisher-Snedecor distributie genoemd. Deze specifieke vorm van de verdeling is rechtszijdig.
Als u wilt berekenen, selecteert u FFisherRightTailed en stelt u de volgende opties in:
Vrijheidsgraden van teller
Typ een getal (double) om de vrijheidsgraden op te geven die in de teller worden gebruikt. De standaardwaarde is 3.0.Noemergraden van vrijheid
Typ een getal (double) om de vrijheidsgraden op te geven die in de noemer worden gebruikt. De standaardwaarde is 6.0.
Gamma
De gamma-verdeling is een familie van continue waarschijnlijkheidsverdelingen met twee parameters. Chi-kwadraat is bijvoorbeeld een speciaal geval van de gamma-verdeling.
Als u wilt berekenen, selecteert u Gamma en stelt u de volgende opties in:
Schalen
Typ een waarde die u wilt gebruiken voor het schalen van de distributie.Door een schaalwaarde toe te passen op de distributie, kunt u deze verkleinen of uitrekken.
De standaardwaarde is 1,0. Waarden moeten positieve getallen zijn.
Locatie
Typ een getal (double) dat de locatie van het0e element aangeeft.Door een waarde voor de parameter Locatie op te geven, kunt u de waarschijnlijkheidsverdeling omhoog of omlaag verplaatsen naar een numerieke schaal.
De standaardwaarde is 0.0.
GeneralizedValues
Hiermee maakt u een distributie die is ontwikkeld om extreme waarden te verwerken. De gegeneraliseerde extreme waardeverdeling (GEV) is eigenlijk een groep continue waarschijnlijkheidsverdelingen waarin de Gumbel-, Fréchet- en Weibull-verdelingen (ook wel type I, II en III extreme waardeverdelingen genoemd) worden gecombineerd.
Zie dit artikel in Wikipedia: Fisher-Tippet-Gnedenko theorema voor meer informatie over extreme waardetheorie.
Als u wilt berekenen, selecteert u GeneralizedValues en stelt u de volgende opties in:
Vorm
Typ een waarde om de vorm van de verdeling te wijzigen.Een shapeparameter is een parameter van een waarschijnlijkheidsverdeling die de locatie of schaal niet definieert. Wanneer u daarom een waarde voor een shape invoert, verandert de parameter de vorm van de verdeling in plaats van deze te verplaatsen, uit te rekken of te verkleinen.
De waarde moet een getal (
double) zijn. De standaardwaarde is 1.0.Schalen
Typ een waarde die u wilt gebruiken voor het schalen van de distributie.Door een schaalwaarde toe te passen op de distributie, kunt u deze verkleinen of uitrekken.
De standaardwaarde is 1,0. Waarden moeten positieve getallen zijn.
Locatie
Typ een getal (double) dat de locatie van het0e element aangeeft.Door een waarde voor de parameter Locatie te typen, kunt u de waarschijnlijkheidsverdeling omhoog of omlaag verplaatsen naar een numerieke schaal.
De standaardwaarde is 0.0.
Geometrische
De geometrische verdeling is een verdeling over positieve gehele getallen die worden geparameteriseerd door één positief reëel getal.
Als u wilt berekenen, selecteert u Geometrisch en stelt u de volgende opties in:
- Kans op succes
Typ een getal (float) tussen 0,0 en 1,0 dat de kans op succes aangeeft. De standaardwaarde is .5.
Notitie
Deze implementatie van de geometrische verdeling genereert geen nullen.
GumbelMax
De Gumbel-verdeling is een van de verschillende extreme waardeverdelingen. Met de optie GumbelMax wordt de maximale extreme waardetype 1-verdeling geïmplementeerd.
Als u wilt berekenen, selecteert u GumbelMax en stelt u de volgende opties in:
Schalen
Typ een waarde die u wilt gebruiken voor het schalen van de distributie.Door een schaalwaarde toe te passen op de distributie, kunt u deze verkleinen of uitrekken.
De standaardwaarde is 1,0. Waarden moeten positieve getallen zijn.
Locatie
Typ een getal (double) dat de locatie van het0e element aangeeft.Door een waarde voor de parameter Locatie te typen, kunt u de waarschijnlijkheidsverdeling omhoog of omlaag verplaatsen naar een numerieke schaal.
De standaardwaarde is 0.0.
GumbelMin
De Gumbel-verdeling is een van de verschillende extreme waardeverdelingen. De Gumbel-verdeling wordt ook wel de kleinste extreme waardeverdeling (SEV) of de kleinste extreme waardeverdeling (Type I) genoemd. Met de optie GumbelMin wordt de minimale extreme waardetype 1-verdeling geïmplementeerd.
Als u wilt berekenen, selecteert u GumbelMin en moet u de volgende opties instellen:
Schalen
Typ een waarde die u wilt gebruiken voor het schalen van de distributie.Door een schaalwaarde toe te passen op de distributie, kunt u deze verkleinen of uitrekken.
De standaardwaarde is 1,0. Waarden moeten positieve getallen zijn.
Locatie
Typ een getal (double) dat de locatie van het0e element aangeeft.Door een waarde voor de parameter Locatie te typen, kunt u de waarschijnlijkheidsverdeling omhoog of omlaag verplaatsen naar een numerieke schaal.
De standaardwaarde is 0.0.
Hypergeometrische
De hypergeometrische verdeling is een discrete waarschijnlijkheidsverdeling die het aantal gunstige uitkomsten in een reeks n tekent van een eindige populatie zonder vervanging, net zoals in de binomiale verdeling het aantal gunstige uitkomsten voor tekenen met vervanging wordt beschreven.
Als u wilt berekenen, selecteert u Hypergeometrisch en stelt u de volgende opties in:
Aantal monsters
Typ een geheel getal dat het aantal te gebruiken voorbeelden aangeeft. De standaardwaarde is 9.Aantal geslaagde bewerkingen
Typ een geheel getal dat de waarde voor succes definieert. De standaardwaarde is 24.Grootte van populatie
Geef de populatiegrootte op die moet worden gebruikt bij het schatten van de hypergeometrische verdeling.
Laplace
De Laplace-distributie is een verdeling over de reële getallen, geparameteriseerd met een gemiddelde en met een schaalparameter.
Als u wilt berekenen, selecteert u Laplace-distributie en stelt u de volgende opties in:
Schalen
Typ een waarde die u wilt gebruiken voor het schalen van de distributie.Door een schaalwaarde toe te passen op de distributie, kunt u deze verkleinen of uitrekken.
De standaardwaarde is 1,0. Waarden moeten positieve getallen zijn.
Locatie
Typ een getal (double) dat de locatie van het0e element aangeeft.Door een waarde voor de parameter Locatie te typen, kunt u de waarschijnlijkheidsverdeling omhoog of omlaag verplaatsen naar een numerieke schaal.
De standaardwaarde is 0.0.
Logistieke
De logistieke distributie is vergelijkbaar met de normale distributie, maar heeft geen limiet aan de linkerkant van de distributie. De logistieke distributie wordt gebruikt in logistieke regressie- en neurale netwerkmodellen en voor het modelleren van life sciences-gegevens.
Als u wilt berekenen, selecteert u Logistiek en stelt u de volgende opties in:
Schalen
Typ een waarde die u wilt gebruiken voor het schalen van de distributie.Door een schaalwaarde toe te passen op de distributie, kunt u deze verkleinen of uitrekken.
De standaardwaarde is 1,0. Waarden moeten positieve getallen zijn.
Bedoel
Typ een getal (double)dat de geschatte gemiddelde waarde van de verdeling aangeeft. De standaardwaarde is 0.0.
Logaritmische
De logaritmische verdeling is een continue univariate-verdeling.
Als u wilt berekenen, selecteert u Logarial en stelt u de volgende opties in:
Bedoel
Typ een getal (double) dat de geschatte gemiddelde waarde van de verdeling aangeeft. De standaardwaarde is 0.0.Standaarddeviatie
Typ een positief getal (double) dat de geschatte standaarddeviatie van de verdeling aangeeft. De standaardwaarde is 1.0.
NegativeBinomial
De negatieve binomiale verdeling is een verdeling over de natuurlijke getallen met twee parameters (r, p). In het speciale geval dat r een geheel getal is, kunt u de verdeling interpreteren als het aantal zijden vóór hetrth-hoofd wanneer de waarschijnlijkheid van het hoofd p is.
Als u wilt berekenen, selecteert u NegativeBinomial en stelt u de volgende opties in:
Kans op succes
Typ een getal (float) tussen 0,0 en 1,0 dat de kans op succes aangeeft. De standaardwaarde is .5.Aantal geslaagde bewerkingen
Typ een geheel getal dat de waarde voor succes aangeeft. De standaardwaarde is 24.
Normaal
De normale verdeling wordt ook wel de Gaussiaanse verdeling genoemd.
Als u wilt berekenen, selecteert u Normaal en stelt u de volgende opties in:
Bedoel
Typ een getal (double) dat de geschatte gemiddelde waarde van de verdeling aangeeft. De standaardwaarde is 0.0.Standaarddeviatie
Typ een positief getal (double) dat de geschatte standaarddeviatie van de verdeling aangeeft. De standaardwaarde is 1.0.
Pareto
De Pareto-verdeling is een machtswetsverdeling die samenvalt met sociale, wetenschappelijke, geofysische, actuariele en vele andere soorten waarneembare verschijnselen.
Als u wilt berekenen, selecteert u Pareto en stelt u de volgende opties in:
Vorm
Typ een waarde (optioneel) om de vorm van de verdeling te wijzigen.Een shapeparameter is een parameter van een waarschijnlijkheidsverdeling die de locatie of schaal niet definieert. Als u daarom een waarde voor de shape invoert, wordt de vorm van de verdeling gewijzigd in plaats van de shape te verplaatsen, uit te rekken of te verkleinen.
De waarde moet een getal (
double) zijn. De standaardwaarde is 1.0.Schalen
Typ een waarde (optioneel) om de schaal van de distributie te wijzigen. Door een schaalwaarde toe te passen op de verdeling, kunt u deze verkleinen of uitrekken.De waarde moet een getal (
double) zijn. De standaardwaarde is 1.0.
Poisson
In deze implementatie wordt de methode van Knuth gebruikt om gedistribueerde Willekeurige Variabelen van Poisson te genereren. Zie Poisson-regressie voor meer informatie over de Poisson-verdeling.
Als u wilt berekenen, selecteert u Poisson en stelt u de volgende opties in:
- Bedoel
Typ een getal (double) dat de geschatte gemiddelde waarde van de verdeling aangeeft. De standaardwaarde is 0.0.
Rayleigh
De Rayleigh-verdeling is een continue waarschijnlijkheidsverdeling. Als voorbeeld van hoe het ontstaat, heeft de windsnelheid een Rayleigh-verdeling als de onderdelen van de tweedimensionale windsnelheidsvector niet-gerelateerd zijn en normaal verdeeld zijn met gelijke variantie.
Als u wilt berekenen, selecteert u Rayleigh en stelt u de volgende opties in:
- Ondergrens
Typ een getal (double) dat de ondergrens van de verdeling vertegenwoordigt. De standaardwaarde is 0.0.
Standaardnormaal
Deze optie biedt de standaard normale verdeling, zonder andere parameters.
Als u wilt berekenen, selecteert u StandardNormal en selecteert u de kolommen.
TStudent
Met deze optie wordt de univariate student t-distributie geïmplementeerd.
Als u wilt berekenen, selecteert u TStudent en stelt u de volgende opties in:
- Aantal vrijheidsgraden
Typ een getal (double) om de vrijheidsgraden op te geven. De standaardwaarde is 1.0.
TStudentRightTailed
Implementeert de univariate student t-verdeling met behulp van één rechterstaart.
Als u wilt berekenen, selecteert u TStudentRightTailed en stelt u de volgende opties in:
- Aantal vrijheidsgraden
Typ een getal (double) om de vrijheidsgraden op te geven. De standaardwaarde is 1.0.
TStudentTwoTailed
Implementeert een tweezijdige t-verdeling van studenten.
Als u wilt berekenen, selecteert u TStudentTwoTailed en stelt u de volgende opties in:
- Aantal vrijheidsgraden
Typ een getal (double) om de vrijheidsgraden op te geven. De standaardwaarde is 1.0.
Uniforme
De uniforme verdeling wordt ook wel de rechthoekige verdeling genoemd.
Als u wilt berekenen, selecteert u Uniform en stelt u de volgende opties in:
Ondergrens
Typ een getal (double) dat de ondergrens van de verdeling aangeeft. De standaardwaarde is 0.0.Bovengrens
Typ een getal (double) dat de bovengrens van de verdeling aangeeft. De standaardwaarde is 1.0.
Weibull
De Weibull-distributie wordt veel gebruikt in betrouwbaarheidstechniek. U kunt de parameter Shape gebruiken om veel andere distributies te modelleren.
Als u wilt berekenen, selecteert u Weibull en stelt u de volgende opties in:
Vorm
Typ een waarde (optioneel) om de vorm van de verdeling te wijzigen.Een shapeparameter is een parameter van een waarschijnlijkheidsverdeling die de locatie of schaal niet definieert. Als u daarom een waarde voor de shape invoert, wordt de vorm van de verdeling gewijzigd in plaats van de shape te verplaatsen, uit te rekken of te verkleinen.
De waarde moet een getal (
double) zijn. De standaardwaarde is 1.0.Schalen
Typ een waarde (optioneel) om de schaal van de distributie te wijzigen. Door een schaalwaarde toe te passen op de verdeling, kunt u deze verkleinen of uitrekken.De waarde moet een getal (
double) zijn. De standaardwaarde is 1.0.
Technische opmerkingen
Deze sectie bevat implementatiedetails, tips en antwoorden op veelgestelde vragen.
Implementatiegegevens
Deze module ondersteunt alle distributies die worden geleverd in de bibliotheek open source MATH.NET Numerieke gegevens. Zie de documentatie voor de bibliotheek Math.Net.Numerics.Distribution voor meer informatie.
Rechtszijdige en tweezijdige distributies worden weergegeven als afzonderlijke distributies, niet als geparameteriseerde versies van basisdistributies. Het huidige gedrag is het behouden van compatibiliteit met Excel.
Definities
Deze module ondersteunt het berekenen van een van deze waarden voor de opgegeven distributie:
cdf of de cumulatieve verdelingsfunctie
Retourneert de kans voor een samengestelde gebeurtenis, gedefinieerd als de som van currences wanneer de willekeurige variabele een waarde kleiner dan een bepaalde waarde x neemt.
Met andere woorden, het beantwoordt de vraag: 'Hoe vaak zijn steekproeven die kleiner zijn dan of gelijk zijn aan deze waarde?'
Deze functie kan worden gebruikt met zowel continue als discrete numerieke variabelen.
InverseCdf of de inverse cumulatieve verdelingsfunctie
Retourneert de waarde die is gekoppeld aan een specifieke cumulatieve waarschijnlijkheidswaarde (cdf).
Met andere woorden, het beantwoordt de vraag: "Wat is de waarde van x waarmee de cdf-functie de cumulatieve kans y retourneert?"
pdf of de kansdichtheidsfunctie
Beschrijft de relatieve kans dat een willekeurige variabele een specifieke waarde is.
Met andere woorden, het beantwoordt de vraag: "Hoe vaak zijn steekproeven precies op deze waarde?"
Verwachte invoer
| Naam | Type | Beschrijving |
|---|---|---|
| Gegevensset | Gegevenstabel | Invoergegevensset |
Moduleparameters
| Name | Bereik | Type | Standaard | Beschrijving |
|---|---|---|---|---|
| Distributie | Alle | Kansdistributie | Standaardnormaal | Selecteer het soort waarschijnlijkheidsverdeling dat u wilt genereren. |
| Methode | Alle | ProbabilityDistributionMethod | Cdf | Selecteer de methode die u wilt gebruiken bij het berekenen van de geselecteerde waarschijnlijkheidsverdeling. Opties zijn de cumulatieve verdelingsfunctie (cdf), de inverse cumulatieve verdelingsfunctie (InverseCdf) en de kansdichtheidsfunctie of massafunctie (pdf). |
| Negatieve binomiale distributiemethode | Alle | KansDistributionMethodForNegativeBinomial | Cdf | Als u de negatieve binomiale verdeling selecteert, geeft u de methode op die wordt gebruikt voor het evalueren van de distributie. |
| Kans op succes | [0.0;1.0] | Float | 0,5 | Typ een waarde die moet worden gebruikt als de kans op succes. |
| Vorm | Alle | Float | 1.0 | Typ een waarde die de vorm van de verdeling wijzigt. |
| Schalen | >=0,0 | Float | 1.0 | Typ een waarde die de schaal van de distributie wijzigt om deze groter of kleiner te maken. |
| Aantal experimenten | >=1 | Geheel getal | 3 | Geef het aantal experimenten op. |
| Ondergrens | Alle | Float | 0,0 | Typ een getal dat moet worden gebruikt als de ondergrens van de distributie |
| Bovengrens | Alle | Float | 1.0 | Typ een getal dat moet worden gebruikt als de bovengrens van de distributie |
| Locatie | Alle | Float | 0,0 | Typ de locatie van het nulelement in de verdeling. |
| Aantal vrijheidsgraden | Alle | Float | 1.0 | Geef het aantal vrijheidsgraden op. |
| Vrijheidsgraden van teller | Alle | Float | 3,0 | Geef het aantal vrijheidsgraden in de teller op. |
| Noemer vrijheidsgraden | Alle | Float | 6.0 | Geef het aantal vrijheidsgraden in de noemer op. |
| Lambda | >=0,0 | Float | 1.0 | Geef een waarde op voor de lambda-parameter. |
| Aantal monsters | Alle | Geheel getal | 9 | Geef het aantal steekproeven op. |
| Aantal geslaagde | Alle | Geheel getal | 24 | Typ een waarde die u wilt gebruiken als het aantal geslaagde waarden. |
| Grootte van populatie | Alle | Geheel getal | 52 | Geef de grootte van de populatie op. |
| Gemiddeld | Alle | Float | 0,0 | Typ de geschatte gemiddelde waarde. |
| Standaarddeviatie | >=0,0 | Float | 1.0 | Typ de geschatte standaarddeviatie. |
| Kolomset | Alle | ColumnSelection | Kies de kolommen waarover u de waarschijnlijkheidsverdeling wilt berekenen. | |
| Resultaatmodus | Alle | Outputto | ResultOnly | Geef op hoe de resultaten moeten worden opgeslagen in de uitvoergegevensset. De opties zijn om nieuwe kolommen toe te voegen, bestaande kolommen te vervangen of alleen de resultaten uit te voeren. |
Uitvoer
| Naam | Type | Beschrijving |
|---|---|---|
| Resultatengegevensset | Gegevenstabel | Uitvoergegevensset |
Uitzondering
Zie Modulefoutcodes voor een volledige lijst met foutberichten.
| Uitzondering | Beschrijving |
|---|---|
| Fout 0017 | Uitzondering treedt op als een of meer opgegeven kolommen een type hebben dat niet wordt ondersteund door de huidige module. |
Zie Machine Learning Foutcodes voor een lijst met fouten die specifiek zijn voor Studio-modules (klassiek).
Zie Machine Learning REST API-foutcodes voor een lijst met API-uitzonderingen.