Caching configureren
Belangrijk
Azure HDInsight op AKS is op 31 januari 2025 buiten gebruik gesteld. Kom meer te weten via deze aankondiging.
U moet uw workloads migreren naar Microsoft Fabric- of een gelijkwaardig Azure-product om plotselinge beëindiging van uw workloads te voorkomen.
Belangrijk
Deze functie is momenteel beschikbaar als preview-versie. De aanvullende gebruiksvoorwaarden voor Microsoft Azure Previews meer juridische voorwaarden bevatten die van toepassing zijn op Azure-functies die bèta, in preview of anderszins nog niet in algemene beschikbaarheid zijn vrijgegeven. Voor informatie over deze specifieke preview, zie Azure HDInsight on AKS preview-informatie. Voor vragen of suggesties voor functies dient u een aanvraag in op AskHDInsight- met de details en volgt u ons voor meer updates over Azure HDInsight Community-.
Het opvragen van objectopslag met behulp van de Hive-connector is een veelvoorkomend gebruiksvoorbeeld voor Trino. Dit proces omvat vaak het verzenden van grote hoeveelheden gegevens. Objecten worden opgehaald uit HDFS of een ander ondersteund objectarchief door meerdere werkrollen en verwerkt door deze werknemers. Herhaalde query's met verschillende parameters of zelfs verschillende query's van verschillende gebruikers, hebben vaak toegang tot en overdracht van dezelfde objecten.
HDInsight in AKS heeft uiteindelijke resultaatcache toegevoegd mogelijkheid voor Trino, wat de volgende voordelen biedt:
- Verminder de belasting van objectopslag.
- Verbeter de queryprestaties.
- Verlaag de querykosten.
Cacheopties
Verschillende opties voor opslaan in cache:
- Eindresultaatcaching: Wanneer dit is ingeschakeld (in de configuratiesectie van de coördinatorcomponenten), wordt het resultaat van elke query voor elke catalogus opgeslagen in de cache op een coördinator-VM.
- Hive/Iceberg/Delta Lake-catalogus cache-instellingen: wanneer ingeschakeld (voor een specifieke catalogus van het bijbehorende type), wordt de gesplitste data voor elke query binnen het cluster in de cache opgeslagen op werkende virtuele machines.
Eindresultaat opslaan in cache
Het opslaan van uiteindelijke resultaten kan op twee manieren worden geconfigureerd:
Beschikbare configuratieparameters zijn:
| Eigenschap | Verstek | Beschrijving |
|---|---|---|
query.cache.enabled |
vals | Biedt de mogelijkheid om het opslaan van eindresultaten in te schakelen als het waar is. |
query.cache.ttl |
- | Definieert een tijd totdat cachegegevens worden bewaard vóór verwijdering. Bijvoorbeeld: "10m","1h" |
query.cache.disk-usage-percentage |
80 | Percentage schijfruimte dat wordt gebruikt voor gegevens in de cache. |
query.cache.max-result-data-size |
0 | Maximale gegevensgrootte voor een resultaat. Als deze waarde is overschreden, wordt het resultaat niet in de cache opgeslagen. |
Notitie
Het opslaan van uiteindelijke resultaten maakt gebruik van een queryplan en ttl als cachesleutel.
Het opslaan van uiteindelijke resultaten kan ook worden beheerd via de volgende sessieparameters:
| Sessieparameter | Verstek | Beschrijving |
|---|---|---|
query_cache_enabled |
Oorspronkelijke configuratiewaarde | Hiermee schakelt u het opslaan van eindresultaten voor een query/sessie in of uit. |
query_cache_ttl |
Oorspronkelijke configuratiewaarde | Definieert een tijd totdat cachegegevens worden bewaard vóór verwijdering. |
query_cache_max_result_data_size |
Oorspronkelijke configuratiewaarde | Maximale gegevensgrootte voor een resultaat. Als deze waarde is overschreden, wordt het resultaat niet in de cache opgeslagen. |
query_cache_forced_refresh |
vals | Als deze optie is ingesteld op true, wordt het resultaat van de uitvoering van query's in de cache opgeslagen. Het resultaat vervangt bestaande gegevens in de cache als deze bestaat). |
Notitie
Sessieparameters kunnen worden ingesteld voor een sessie (bijvoorbeeld als Trino CLI wordt gebruikt) of kunnen worden ingesteld in meerdere instructies voordat querytekst wordt uitgevoerd. Bijvoorbeeld
set session query_cache_enabled=true;
select cust.name, *
from tpch.tiny.orders
join tpch.tiny.customer as cust on cust.custkey = orders.custkey
order by cust.name
limit 10;
Caching van het eindresultaat produceert JMX-metrische gegevens , die met behulp van Managed Prometheus en Grafana bekeken kunnen worden. De volgende metrische gegevens zijn beschikbaar:
| Metrisch | Beschrijving |
|---|---|
trino_cache_cachestats_requestcount |
Het totale aantal query's dat via de cachelaag gaat. Dit nummer bevat geen query's die worden uitgevoerd met cache uitgeschakeld. |
trino_cache_cachestats_hitcount |
Het aantal cachetreffers, d.w.z. het aantal query's wanneer gegevens beschikbaar zijn en worden geretourneerd vanuit de cache. |
trino_cache_cachestats_misscount |
Aantal cachemissers, bijvoorbeeld het aantal query's wanneer gegevens niet beschikbaar waren en in de cache moesten worden opgeslagen. |
trino_cache_cachestats_hitrate |
Percentageweergave van cachetreffers ten opzichte van het totale aantal query's. |
trino_cache_cachestats_totalevictedcount |
Het aantal in de cache opgeslagen query's dat uit de cache is verwijderd. |
trino_cache_cachestats_totalbytesfromsource |
Het aantal bytes dat uit de bron is gelezen. |
trino_cache_cachestats_totalbytesfromcache |
Het aantal bytes dat uit de cache is gelezen. |
trino_cache_cachestats_totalcachedbytes |
Totaal aantal bytes dat in de cache is opgeslagen. |
trino_cache_cachestats_totalevictedbytes |
Totaal aantal verwijderde bytes. |
trino_cache_cachestats_spaceused |
Huidige grootte van de cache. |
trino_cache_cachestats_cachereadfailures |
Aantal keren dat gegevens niet uit de cache kunnen worden gelezen vanwege een fout. |
trino_cache_cachestats_cachewritefailures |
Aantal keren dat gegevens niet in de cache kunnen worden geschreven vanwege een fout. |
Azure Portal gebruiken
Meld u aan bij Azure Portal.
Typ 'HDInsight in AKS-cluster' in de zoekbalk van Azure Portal en selecteer 'Azure HDInsight op AKS-clusters' in de vervolgkeuzelijst.

Selecteer de clusternaam op de lijstpagina.
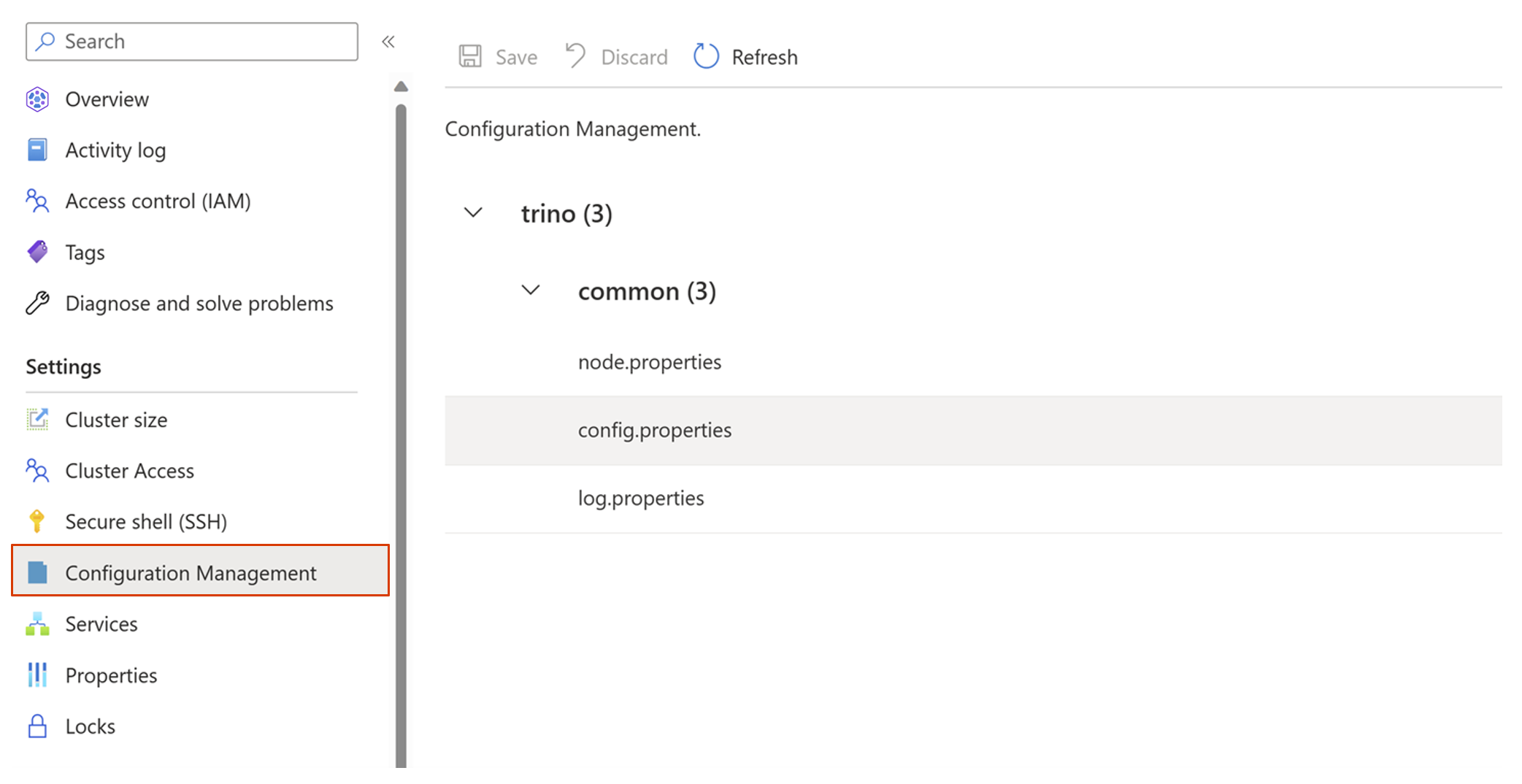
Navigeer naar Configuratiebeheer-blade.
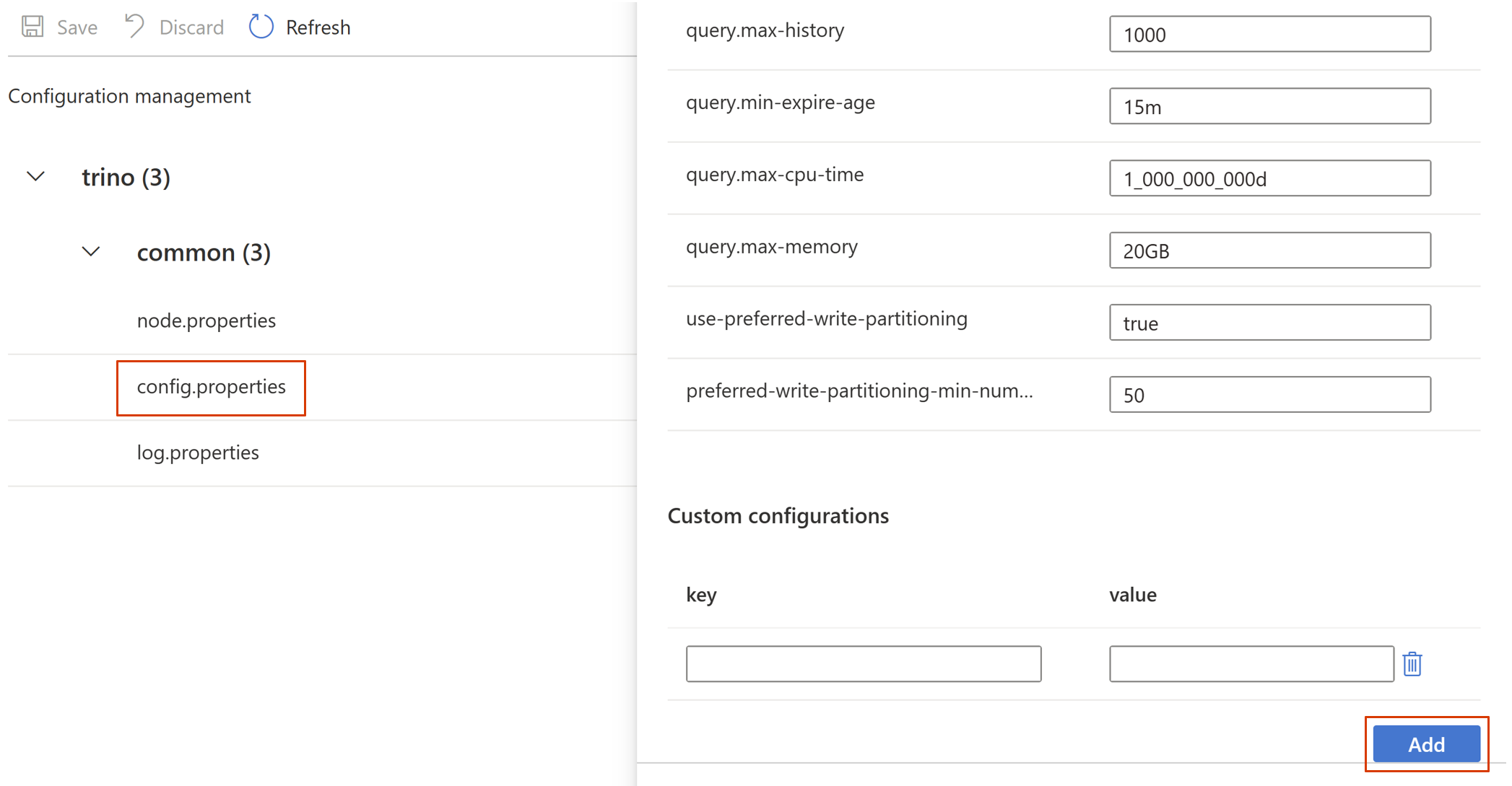
Ga naar config.properties -> Aangepaste configuraties en klik vervolgens op toevoegen.
Stel de vereiste eigenschappen in en klik op OK.
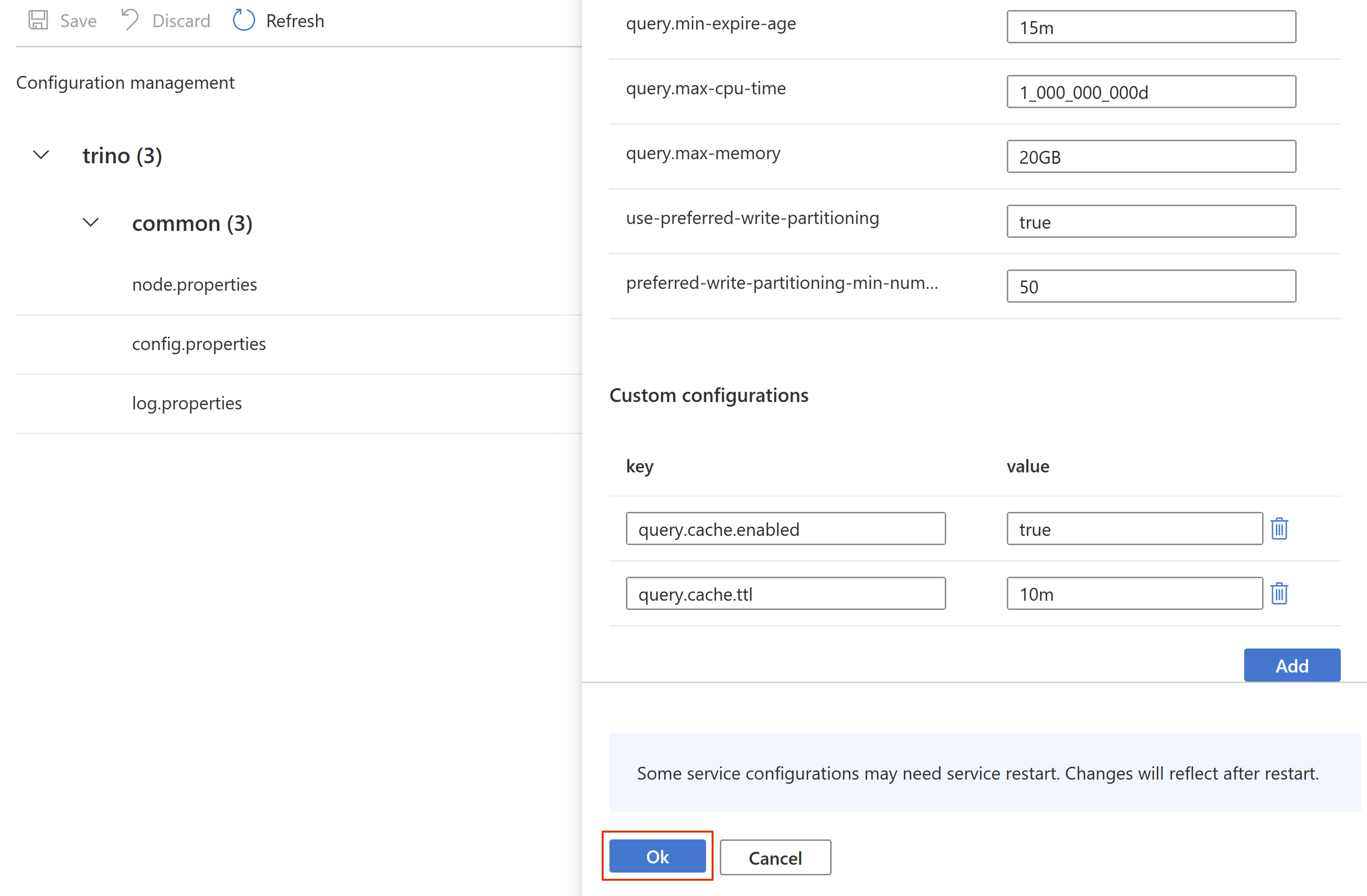
de configuratie opslaan.
ARM-sjabloon gebruiken
Voorwaarden
- Een operationeel Trino-cluster met HDInsight in AKS.
- Maak ARM-sjabloon voor uw cluster.
- Bekijk het volledige cluster ARM-sjabloon voorbeeld.
- Bekendheid met ontwerpen en implementeren van ARM-sjablonen.
U moet de eigenschappen in het coördinatoronderdeel definiëren in properties.clusterProfile.serviceConfigsProfiles sectie in de ARM-sjabloon.
In het volgende voorbeeld ziet u waar u de eigenschappen kunt toevoegen.
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {},
"resources": [
{
"type": "microsoft.hdinsight/clusterpools/clusters",
"apiVersion": "<api-version>",
"name": "<cluster-pool-name>/<cluster-name>",
"location": "<region, e.g. westeurope>",
"tags": {},
"properties": {
"clusterType": "Trino",
"clusterProfile": {
"serviceConfigsProfiles": [
{
"serviceName": "trino",
"configs": [
{
"component": "coordinator",
"files": [
{
"fileName": "config.properties",
"values": {
"query.cache.enabled": "true",
"query.cache.ttl": "10m"
}
}
]
}
]
}
]
}
}
}
]
}
Hive/Iceberg/Delta Lake caching
Alle drie de connectors delen dezelfde set van parameters zoals die beschreven in Hive caching.
Notitie
Bepaalde parameters kunnen niet worden geconfigureerd en worden altijd ingesteld op de standaardwaarden:
hive.cache.data-transfer-port=8898,
hive.cache.bookkeeper-port=8899,
hive.cache.location=/etc/trino/cache,
hive.cache.disk-gebruik-percentage=80
In het volgende voorbeeld ziet u waar u de eigenschappen kunt toevoegen om Hive-caching in te schakelen met behulp van een ARM-sjabloon.
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {},
"resources": [
{
"type": "microsoft.hdinsight/clusterpools/clusters",
"apiVersion": "<api-version>",
"name": "<cluster-pool-name>/<cluster-name>",
"location": "<region, e.g. westeurope>",
"tags": {},
"properties": {
"clusterType": "Trino",
"clusterProfile": {
"serviceConfigsProfiles": [
{
"serviceName": "trino",
"configs": [
{
"component": "catalogs",
"files": [
{
"fileName": "hive1.properties",
"values": {
"connector.name": "hive"
"hive.cache.enabled": "true",
"hive.cache.ttl": "5d"
}
}
]
}
]
}
]
}
}
}
]
}
Implementeer de bijgewerkte ARM-sjabloon om de wijzigingen in uw cluster weer te geven. Meer informatie over het implementeren van een ARM-sjabloon.