Hive-metastore gebruiken met Apache Spark-cluster™
Belangrijk
Azure HDInsight op AKS is op 31 januari 2025 buiten gebruik gesteld. Kom meer te weten via deze aankondiging.
U moet uw workloads migreren naar Microsoft Fabric- of een gelijkwaardig Azure-product om plotselinge beëindiging van uw workloads te voorkomen.
Belangrijk
Deze functie is momenteel beschikbaar als preview-versie. De aanvullende gebruiksvoorwaarden voor Microsoft Azure Previews meer juridische voorwaarden bevatten die van toepassing zijn op Azure-functies die bèta, in preview of anderszins nog niet in algemene beschikbaarheid zijn vrijgegeven. Zie Azure HDInsight op AKS preview-informatievoor meer informatie over deze specifieke preview. Voor vragen of suggesties voor functies dient u een aanvraag in op AskHDInsight- met de details en volgt u ons voor meer updates over Azure HDInsight Community-.
Het is essentieel om de gegevens en metastore te delen over meerdere services. Een van de veelgebruikte metastores binnen de HIVE-metastore. Met HDInsight in AKS kunnen gebruikers verbinding maken met externe metastore. Met deze stap kunnen de HDInsight-gebruikers naadloos verbinding maken met andere services in het ecosysteem.
Azure HDInsight in AKS ondersteunt aangepaste metaarchieven, die worden aanbevolen voor productieclusters. De belangrijkste stappen die erbij komen kijken, zijn
- Een Azure SQL-database maken
- Een sleutelkluis maken voor het opslaan van de inloggegevens
- Metastore configureren tijdens het maken van een HDInsight op AKS-cluster met Apache Spark™
- Gebruikmaken van externe metastore (hiermee kunt u databases weergeven en een SELECT LIMIT 1 uitvoeren).
Terwijl u het cluster maakt, moet de HDInsight-service verbinding maken met de externe metastore en uw referenties verifiëren.
Een Azure SQL-database maken
Maak of heb een bestaande Azure SQL Database voordat u een aangepaste Hive-metastore instelt voor een HDInsight-cluster.
Notitie
Momenteel ondersteunen we alleen Azure SQL Database for HIVE-metastore. Vanwege hive-beperking wordt het teken '-' (afbreekstreepje) in de naam van de metastore-database niet ondersteund.
Een sleutelkluis aanmaken voor het opslaan van de inloggegevens
Maak een Azure Key Vault.
Het doel van de Key Vault is om u in staat te stellen het wachtwoord van de SQL Server-beheerder op te slaan dat is ingesteld tijdens het maken van de SQL-database. HDInsight op het AKS-platform gaat niet direct om met de inloggegevens. Daarom is het nodig om uw belangrijke referenties op te slaan in Azure Key Vault. Leer de stappen om een Azure Key Vaultte maken.
De volgende rollen toewijzen na het maken van Azure Key Vault
Object Rol Opmerkingen Door de gebruiker toegewezen beheerde identiteit (dezelfde UAMI als die wordt gebruikt door het HDInsight-cluster) Key Vault-geheimengebruiker Leer hoe je een rol toewijst aan UAMI Gebruiker (die een geheim maakt in Azure Key Vault) Key Vault-beheerder Leer hoe je rol aan gebruikertoewijst. Notitie
Zonder deze rol kan de gebruiker geen geheim maken.
-
Met deze stap kunt u het beheerderswachtwoord van uw SQL-server als geheim bewaren in Azure Key Vault. Voeg uw wachtwoord (hetzelfde wachtwoord toe als opgegeven in de SQL DB voor beheerder) in het veld Waarde tijdens het toevoegen van een geheim.

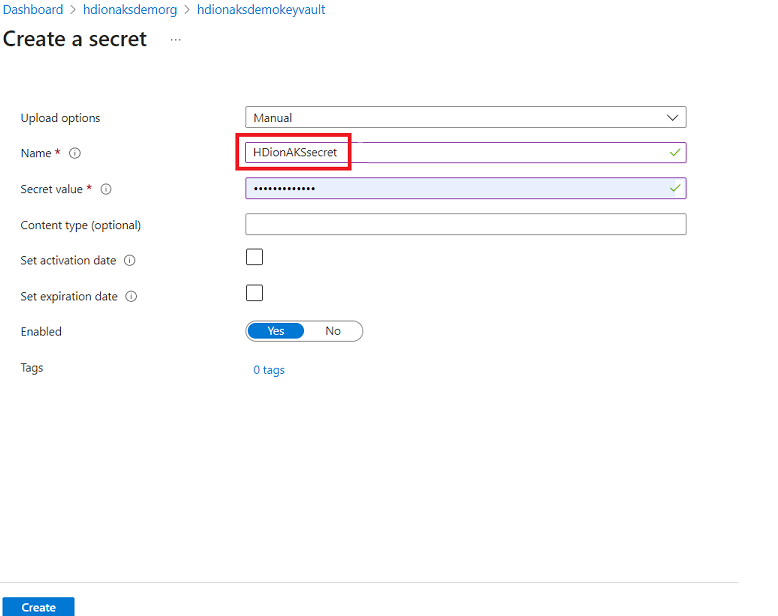
Notitie
Noteer de geheime naam, omdat u dit nodig hebt tijdens het maken van het cluster.


Metastore configureren terwijl u een HDInsight Spark-cluster maakt
Navigeer naar HDInsight in AKS-clustergroep om clusters te maken.
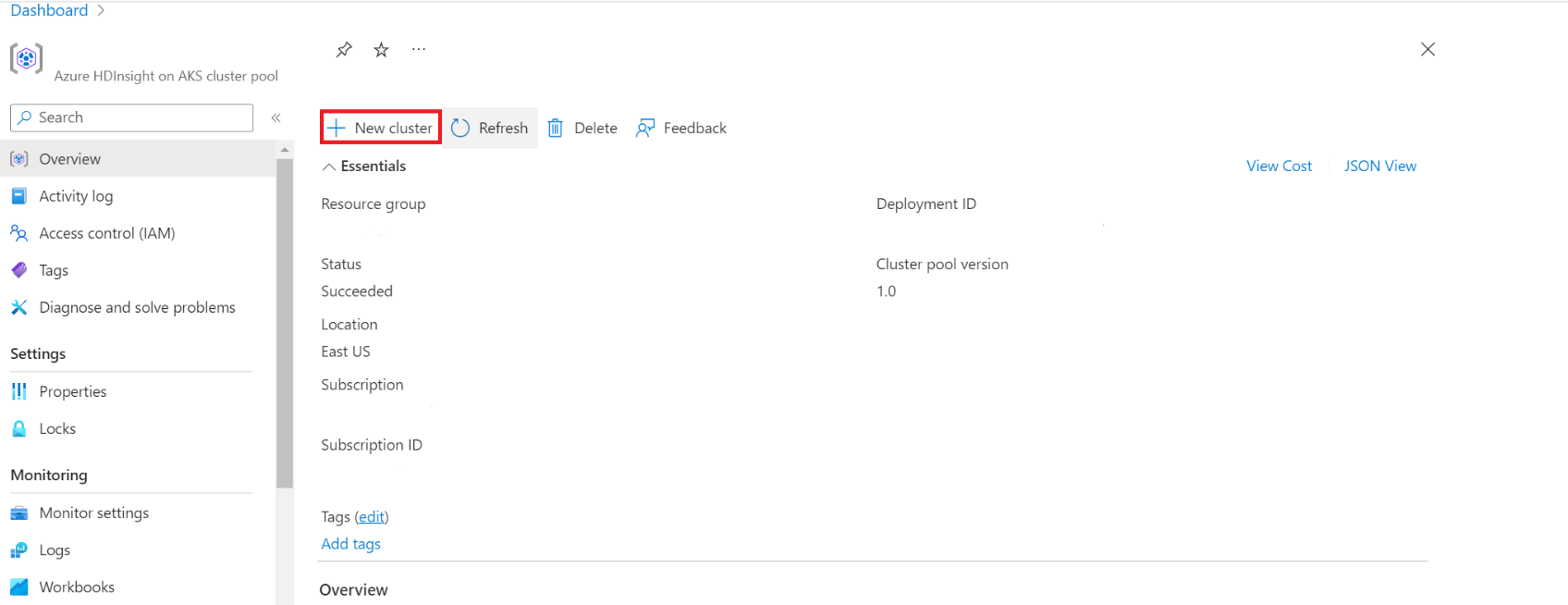
Schakel de wisselknop in om externe Hive-metastore toe te voegen en vul de volgende details in.
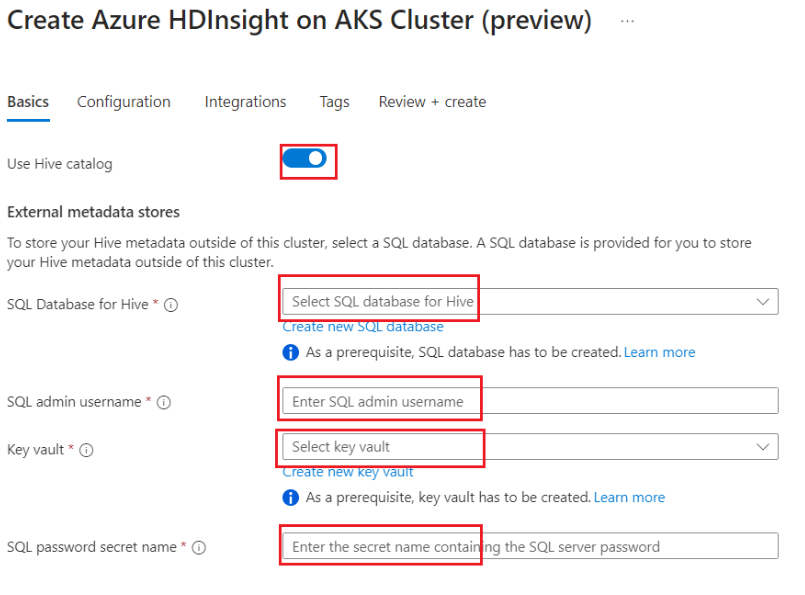
De rest van de details moeten worden ingevuld volgens de regels voor het maken van clusters voor Apache Spark-cluster in HDInsight op AKS.
Klik op Controleren en maken.
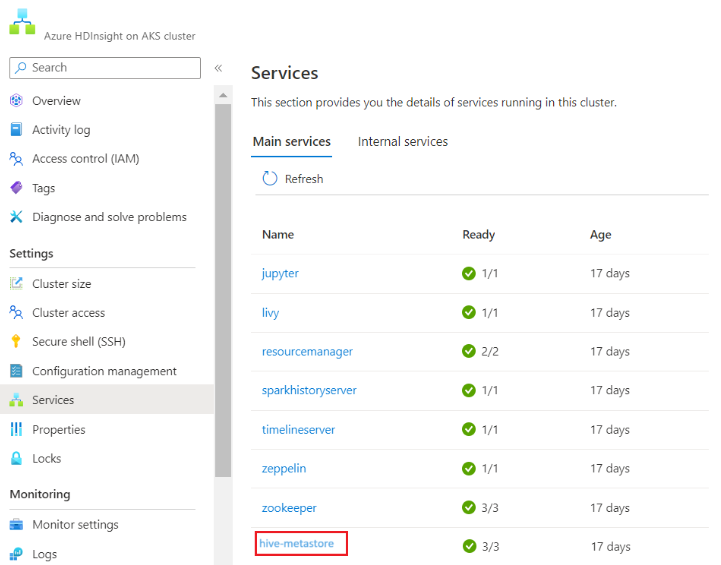
Notitie
- De levenscyclus van de metastore is niet gekoppeld aan de levenscyclus van clusters, zodat u clusters kunt maken en verwijderen zonder metagegevens te verliezen. Metagegevens zoals uw Hive-schema's blijven behouden, zelfs nadat u het HDInsight-cluster hebt verwijderd en opnieuw hebt gemaakt.
- Met een aangepaste metastore kunt u meerdere clusters en clustertypen koppelen aan die metastore.



De externe metastore bedienen
Een tabel maken
>> spark.sql("CREATE TABLE sampleTable (number Int, word String)")
Gegevens toevoegen aan de tabel
>> spark.sql("INSERT INTO sampleTable VALUES (123, \"HDIonAKS\")");\
De tabel lezen
>> spark.sql("select * from sampleTable").show()



Referentie
- Apache, Apache Spark, Spark en bijbehorende opensource-projectnamen zijn handelsmerken van de Apache Software Foundation (ASF).