Delta Lake gebruiken in Azure HDInsight in AKS met Apache Spark-cluster™ (preview)
Belangrijk
Azure HDInsight op AKS is op 31 januari 2025 buiten gebruik gesteld. Meer informatie met deze aankondiging.
U moet uw workloads migreren naar Microsoft Fabric- of een gelijkwaardig Azure-product om plotselinge beëindiging van uw workloads te voorkomen.
Belangrijk
Deze functie is momenteel beschikbaar als preview-versie. De aanvullende gebruiksvoorwaarden voor Microsoft Azure Previews meer juridische voorwaarden bevatten die van toepassing zijn op Azure-functies die bèta, in preview of anderszins nog niet in algemene beschikbaarheid zijn vrijgegeven. Zie Azure HDInsight in AKS preview-informatievoor meer informatie over deze specifieke preview. Voor vragen of suggesties voor functies dient u een aanvraag in op AskHDInsight- met de details en volgt u ons voor meer updates over Azure HDInsight Community-.
Azure HDInsight op AKS is een beheerde cloudservice voor big data-analyses waarmee organisaties grote hoeveelheden gegevens kunnen verwerken. In deze zelfstudie ziet u hoe u Delta Lake gebruikt in Azure HDInsight in AKS met een Apache Spark-cluster™.
Voorwaarde
Een Apache Spark-cluster™ maken in Azure HDInsight in AKS-
Delta Lake-scenario uitvoeren in Jupyter Notebook. Maak een Jupyter-notebook en selecteer Spark tijdens het maken van een notebook, omdat het volgende voorbeeld zich in Scala bevindt.
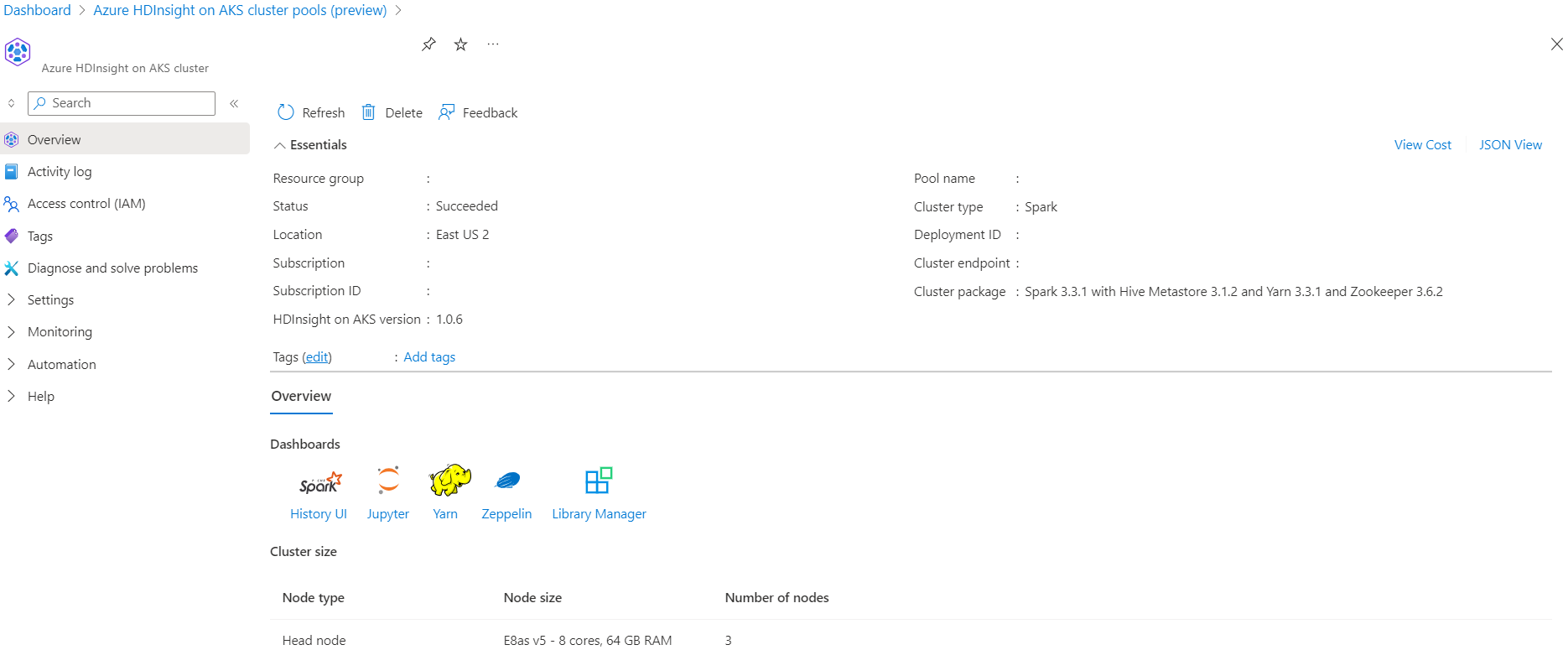


Scenario
- Lees het NYC Taxi Parquet-gegevenformaat - Een lijst met URL's van Parquet-bestanden wordt verstrekt door NYC Taxi & Limousine Commission.
- Voor elke URL (bestand) voert u een transformatie uit en slaat u deze op in Delta-indeling.
- Bereken de gemiddelde afstand, de gemiddelde kosten per mijl en de gemiddelde kosten van Delta Table met behulp van incrementele belasting.
- Sla de berekende waarde op uit stap 3 in Delta-indeling in de KPI-uitvoermap.
- Maak deltatabel in de uitvoermap Delta-indeling (automatisch vernieuwen).
- De KPI-uitvoermap heeft meerdere versies van de gemiddelde afstand en de gemiddelde kosten per mijl voor een reis.
Benodigde configuraties voor het Delta Lake opgeven
Delta Lake met Apache Spark-compatibiliteitsmatrix- Delta Lake, wijzig de Delta Lake-versie op basis van Apache Spark-versie.
%%configure -f
{ "conf": {"spark.jars.packages": "io.delta:delta-core_2.12:1.0.1,net.andreinc:mockneat:0.4.8",
"spark.sql.extensions":"io.delta.sql.DeltaSparkSessionExtension",
"spark.sql.catalog.spark_catalog":"org.apache.spark.sql.delta.catalog.DeltaCatalog"
}
}

Het gegevensbestand weergeven
Notitie
Deze bestands-URL's zijn afkomstig van NYC Taxi & Limousine Commission.
import java.io.File
import java.net.URL
import org.apache.commons.io.FileUtils
import org.apache.hadoop.fs._
// data file object is being used for future reference in order to read parquet files from HDFS
case class DataFile(name:String, downloadURL:String, hdfsPath:String)
// get Hadoop file system
val fs:FileSystem = FileSystem.get(spark.sparkContext.hadoopConfiguration)
val fileUrls= List(
"https://d37ci6vzurychx.cloudfront.net/trip-data/fhvhv_tripdata_2022-01.parquet"
)
// Add a file to be downloaded with this Spark job on every node.
val listOfDataFile = fileUrls.map(url=>{
val urlPath=url.split("/")
val fileName = urlPath(urlPath.size-1)
val urlSaveFilePath = s"/tmp/${fileName}"
val hdfsSaveFilePath = s"/tmp/${fileName}"
val file = new File(urlSaveFilePath)
FileUtils.copyURLToFile(new URL(url), file)
// copy local file to HDFS /tmp/${fileName}
// use FileSystem.copyFromLocalFile(boolean delSrc, boolean overwrite, Path src, Path dst)
fs.copyFromLocalFile(true,true,new org.apache.hadoop.fs.Path(urlSaveFilePath),new org.apache.hadoop.fs.Path(hdfsSaveFilePath))
DataFile(urlPath(urlPath.size-1),url, hdfsSaveFilePath)
})

Maak een uitvoermap aan
De locatie waar u uitvoer van de delta-indeling wilt maken, wijzig indien nodig de transformDeltaOutputPath en avgDeltaOutputKPIPath variabele,
-
avgDeltaOutputKPIPath: om de gemiddelde KPI op te slaan in delta-indeling -
transformDeltaOutputPath: getransformeerde uitvoer opslaan in delta-indeling
import org.apache.hadoop.fs._
// this is used to store source data being transformed and stored delta format
val transformDeltaOutputPath = "/nyctaxideltadata/transform"
// this is used to store Average KPI data in delta format
val avgDeltaOutputKPIPath = "/nyctaxideltadata/avgkpi"
// this is used for POWER BI reporting to show Month on Month change in KPI (not in delta format)
val avgMoMKPIChangePath = "/nyctaxideltadata/avgMoMKPIChangePath"
// create directory/folder if not exist
def createDirectory(dataSourcePath: String) = {
val fs:FileSystem = FileSystem.get(spark.sparkContext.hadoopConfiguration)
val path = new Path(dataSourcePath)
if(!fs.exists(path) && !fs.isDirectory(path)) {
fs.mkdirs(path)
}
}
createDirectory(transformDeltaOutputPath)
createDirectory(avgDeltaOutputKPIPath)
createDirectory(avgMoMKPIChangePath)

Delta-indelingsgegevens maken vanuit Parquet-indeling
Invoergegevens zijn afkomstig uit
listOfDataFile, waar gegevens worden gedownload uit https://www.nyc.gov/site/tlc/about/tlc-trip-record-data.pageLaad de gegevens afzonderlijk om de tijdreizen en -versie te demonstreren
Voer transformatie uit en bereken de volgende zakelijke KPI bij incrementele belasting:
- De gemiddelde afstand
- De gemiddelde kosten per mijl
- De gemiddelde kosten
Getransformeerde en KPI-gegevens opslaan in delta-indeling
import org.apache.spark.sql.functions.udf import org.apache.spark.sql.DataFrame // UDF to compute sum of value paid by customer def totalCustPaid = udf((basePassengerFare:Double, tolls:Double,bcf:Double,salesTax:Double,congSurcharge:Double,airportFee:Double, tips:Double) => { val total = basePassengerFare + tolls + bcf + salesTax + congSurcharge + airportFee + tips total }) // read parquet file from spark conf with given file input // transform data to compute total amount // compute kpi for the given file/batch data def readTransformWriteDelta(fileName:String, oldData:Option[DataFrame], format:String="parquet"):DataFrame = { val df = spark.read.format(format).load(fileName) val dfNewLoad= df.withColumn("total_amount",totalCustPaid($"base_passenger_fare",$"tolls",$"bcf",$"sales_tax",$"congestion_surcharge",$"airport_fee",$"tips")) // union with old data to compute KPI val dfFullLoad= oldData match { case Some(odf)=> dfNewLoad.union(odf) case _ => dfNewLoad } dfFullLoad.createOrReplaceTempView("tempFullLoadCompute") val dfKpiCompute = spark.sql("SELECT round(avg(trip_miles),2) AS avgDist,round(avg(total_amount/trip_miles),2) AS avgCostPerMile,round(avg(total_amount),2) avgCost FROM tempFullLoadCompute") // save only new transformed data dfNewLoad.write.mode("overwrite").format("delta").save(transformDeltaOutputPath) //save compute KPI dfKpiCompute.write.mode("overwrite").format("delta").save(avgDeltaOutputKPIPath) // return incremental dataframe for next set of load dfFullLoad } // load data for each data file, use last dataframe for KPI compute with the current load def loadData(dataFile: List[DataFile], oldDF:Option[DataFrame]):Boolean = { if(dataFile.isEmpty) { true } else { val nextDataFile = dataFile.head val newFullDF = readTransformWriteDelta(nextDataFile.hdfsPath,oldDF) loadData(dataFile.tail,Some(newFullDF)) } } val starTime=System.currentTimeMillis() loadData(listOfDataFile,None) println(s"Time taken in Seconds: ${(System.currentTimeMillis()-starTime)/1000}")
Delta-indeling lezen met deltatabel
- getransformeerde gegevens lezen
- KPI-gegevens lezen
import io.delta.tables._ val dtTransformed: io.delta.tables.DeltaTable = DeltaTable.forPath(transformDeltaOutputPath) val dtAvgKpi: io.delta.tables.DeltaTable = DeltaTable.forPath(avgDeltaOutputKPIPath)
Schema afdrukken
- Delta-tabelschema afdrukken voor getransformeerde en gemiddelde KPI-gegevens1.
// transform data schema dtTransformed.toDF.printSchema // Average KPI Data Schema dtAvgKpi.toDF.printSchema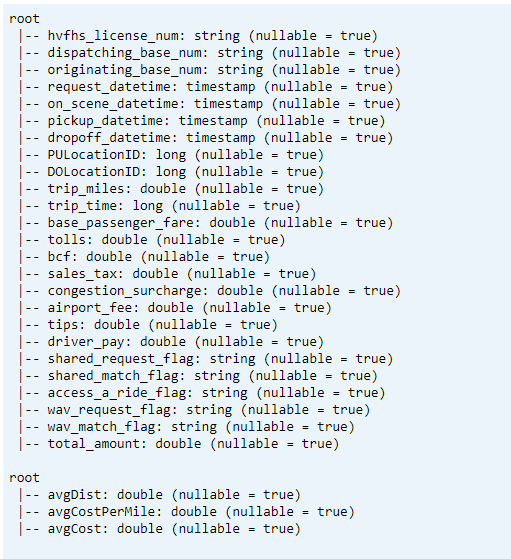
Laatst berekende KPI uit gegevenstabel weergeven
dtAvgKpi.toDF.show(false)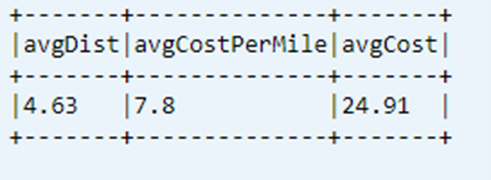


Berekende KPI-geschiedenis weergeven
In deze stap wordt de geschiedenis van de KPI-transactietabel uit _delta_log weergegeven
dtAvgKpi.history().show(false)

KPI-gegevens weergeven na elke gegevensbelasting
- Door tijdreizen kunt u KPI-wijzigingen na elke lading bekijken
- U kunt alle versiewijzigingen opslaan in CSV-formaat op
avgMoMKPIChangePath, zodat Power BI deze wijzigingen kan lezen.
val dfTxLog = spark.read.json(s"${transformDeltaOutputPath}/_delta_log/*.json")
dfTxLog.select(col("add")("path").alias("file_path")).withColumn("version",substring(input_file_name(),-6,1)).filter("file_path is not NULL").show(false)

Referentie
- Apache, Apache Spark, Spark en bijbehorende opensource-projectnamen zijn handelsmerken van de Apache Software Foundation (ASF).