Apache Flink Application Mode-cluster op HDInsight op AKS
Belangrijk
Azure HDInsight op AKS is op 31 januari 2025 buiten gebruik gesteld. Meer informatie over in deze aankondiging.
U moet uw workloads migreren naar Microsoft Fabric- of een gelijkwaardig Azure-product om plotselinge beëindiging van uw workloads te voorkomen.
Belangrijk
Deze functie is momenteel beschikbaar als preview-versie. De aanvullende gebruiksvoorwaarden voor Microsoft Azure Previews meer juridische voorwaarden bevatten die van toepassing zijn op Azure-functies die bèta, in preview of anderszins nog niet in algemene beschikbaarheid zijn vrijgegeven. Zie Azure HDInsight op AKS preview-informatievoor meer informatie over deze specifieke preview. Voor vragen of suggesties voor functies dient u een aanvraag in op AskHDInsight- met de details en volgt u ons voor meer updates over Azure HDInsight Community-.
HDInsight op AKS biedt nu een Flink Application Mode-cluster. Met dit cluster kunt u de levenscyclus van de Flink-toepassingsmodus van het cluster beheren via de Azure-portal. Het biedt een gebruiksvriendelijke interface en de Rest API's van Azure Resource Management. Clusters in de toepassingsmodus zijn ontworpen ter ondersteuning van grote en langlopende taken met toegewezen resources en verwerken resource-intensieve of uitgebreide gegevensverwerkingstaken.
Met deze implementatiemodus kunt u toegewezen resources toewijzen voor specifieke Flink-toepassingen, zodat ze voldoende rekenkracht en geheugen hebben om grote workloads efficiënt te verwerken.

Voordelen
Vereenvoudigde clusterimplementatie met Job-JAR.
Gebruiksvriendelijke REST API: HDInsight in AKS biedt gebruiksvriendelijke ARM REST API's voor het beheren van app-modustaakbewerkingen, zoals Bijwerken, Opslaan, Annuleren, Verwijderen.
Eenvoudig te beheren taakupdates en statusbeheer: de integratie met de Azure-portal biedt een probleemloze ervaring voor het bijwerken van taken en het herstellen naar hun laatst opgeslagen status (savepoint). Deze functionaliteit zorgt voor continuïteit en gegevensintegriteit gedurende de levenscyclus van de taak.
Automatiseer Flink Job(s) met behulp van Azure Pipelines of andere CI/CD-hulpprogramma's: Met HDInsight op AKS hebben Flink-gebruikers toegang tot gebruiksvriendelijke ARM Rest API, kunt u Flink-taakbewerkingen naadloos integreren in uw Azure Pipeline of andere CI/CD-hulpprogramma's.
Belangrijke functies
Taken stoppen en starten met Savepoints: Gebruikers kunnen hun Flink AppMode-taken zonder problemen stoppen en starten vanaf hun vorige status (Savepoint). Savepoints zorgen ervoor dat de voortgang van taken behouden blijft, waardoor naadloze hervatting mogelijk is.
Job-Updates: De gebruiker kan de actieve AppMode-taak bijwerken na het bijwerken van het jar-bestand in het opslagaccount. Deze update maakt automatisch gebruik van het savepoint en start de AppMode-taak met een nieuw JAR-bestand.
Stateless Updates: Het uitvoeren van een herstart voor een AppMode-taak wordt vereenvoudigd door Stateless Updates. Met deze functie kunnen gebruikers een schone herstart starten met behulp van bijgewerkte taak-JAR.
Savepoint Management: op elk gewenst moment kunnen gebruikers savepoints maken voor hun actieve taken. Deze opslagpunten kunnen indien nodig worden weergegeven en gebruikt om de taak opnieuw op te starten vanaf een specifiek controlepunt.
Annuleren: de taak wordt definitief geannuleerd.
verwijderen: AppMode-cluster verwijderen.
Een Flink Application-cluster maken
Voorwaarden
voltooi de vereisten in de volgende secties:
Voeg een taak-JAR toe in het opslagaccount.
Voordat u een Flink App Mode-cluster instelt, zijn er verschillende voorbereidende stappen vereist. Een van deze stappen is het plaatsen van de App Mode job JAR in het opslagaccount van het cluster.
Een map aanmaken voor de JAR-taak in app-modus:
Maak binnen de specifieke containers een map waarin u het JAR-bestand van de taak in app-modus uploadt. Deze map fungeert als de locatie voor het opslaan van JAR-bestanden die u wilt opnemen in het klassepad van het Flink-cluster of -taak.
Savepoints Directory (optioneel):
Als gebruikers opslagpunten willen maken tijdens het uitvoeren van de taak, maakt u een afzonderlijke map in het opslagaccount voor het opslaan van deze opslagpunten. Deze directory werd gebruikt voor het opslaan van controlepuntgegevens en metagegevens voor savepoints.
Voorbeeld van een mapstructuur:
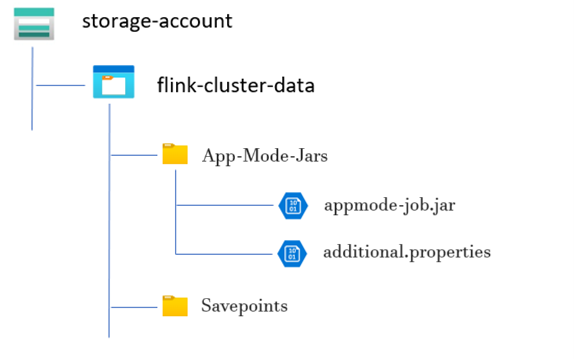

Een Flink App Mode-cluster maken
Flink AppMode-clusters kunnen worden gemaakt zodra de implementatie van de clustergroep is voltooid, laten we de stappen doorlopen voor het geval u aan de slag gaat met een bestaande clustergroep.
Typ in de Azure Portal HDInsight-clustergroepen/HDInsight/HDInsight op AKS en selecteer Azure HDInsight op AKS-clustergroepen om naar de clustergroepspagina te gaan. Selecteer op de pagina HDInsight op AKS-clustergroepen de clustergroep waarin u een nieuw Flink-cluster wilt maken.

Klik op de pagina specifieke clustergroep op + Nieuw cluster en geef de volgende informatie op:
Eigenschap Beschrijving Abonnement Dit veld wordt automatisch ingevuld met het Azure-abonnement dat is geregistreerd voor de clustergroep. Resourcegroep Dit veld wordt automatisch ingevuld en toont de resourcegroep in de cluster pool. Regio Dit veld wordt automatisch ingevuld en toont de regio die is geselecteerd in de clustergroep. Clustergroep Dit veld wordt automatisch ingevuld en toont de naam van de clustergroep waarop het cluster nu wordt gemaakt. Als u een cluster in een andere pool wilt maken, zoekt u de clustergroep in de portal en klikt u op + Nieuw cluster. HDInsight in AKS-poolversie Dit veld wordt automatisch ingevuld en toont de versie van de clustergroep waarop het cluster nu wordt gemaakt. HDInsight op AKS Versie Selecteer de minor- of patchversie van HDInsight in AKS van het nieuwe cluster. Clustertype Selecteer Flink in de vervolgkeuzelijst. Clusternaam Voer de naam van het nieuwe cluster in. Door de gebruiker toegewezen beheerde identiteit Selecteer in de vervolgkeuzelijst de beheerde identiteit die u wilt gebruiken met het cluster. Als u de eigenaar bent van de Managed Service Identity (MSI) en de MSI heeft niet de rol van Managed Identity Operator op het cluster, klik dan op de koppeling onder het vak om de nodige toestemming vanaf de AKS-agentgroep MSI toe te wijzen. Als de MSI al over de juiste machtigingen beschikt, wordt er geen koppeling weergegeven. Zie de vereisten voor andere roltoewijzingen die vereist zijn voor de MSI. Opslagaccount Selecteer in de vervolgkeuzelijst het opslagaccount dat u wilt koppelen aan het Flink-cluster en geef de containernaam op. De beheerde identiteit krijgt verder toegang tot het opgegeven opslagaccount met de rol 'Storage Blob Data Owner' tijdens het creëren van de cluster. Virtueel netwerk Het virtuele netwerk voor het cluster. Subnetwerk Het virtuele subnet voor het cluster. Hive-catalogus inschakelen voor Flink SQL:
Eigendom Beschrijving Hive-catalogus gebruiken Schakel deze optie in om een externe Hive-metastore te gebruiken. SQL Database voor Hive Selecteer in de vervolgkeuzelijst de SQL Database waarin u hive-metastore-tabellen wilt toevoegen. Gebruikersnaam van SQL-beheerder Voer de gebruikersnaam van de SQL-serverbeheerder in. Dit account wordt door metastore gebruikt om te communiceren met sql-database. Sleutelkluis Selecteer in de vervolgkeuzelijst de Sleutelkluis, die een geheim met wachtwoord bevat voor de gebruikersnaam van de SQL Server-beheerder. U moet een toegangsbeleid instellen met alle vereiste machtigingen, zoals sleutelmachtigingen, geheime machtigingen en certificaatmachtigingen voor de MSI, die wordt gebruikt voor het maken van het cluster. De MSI heeft de rol Key Vault-beheerder nodig. Voeg de vereiste machtigingen toe met behulp van IAM. Sql-wachtwoordgeheimnaam Voer de geheime naam in uit de Sleutelkluis waarin het wachtwoord van de SQL-database is opgeslagen. 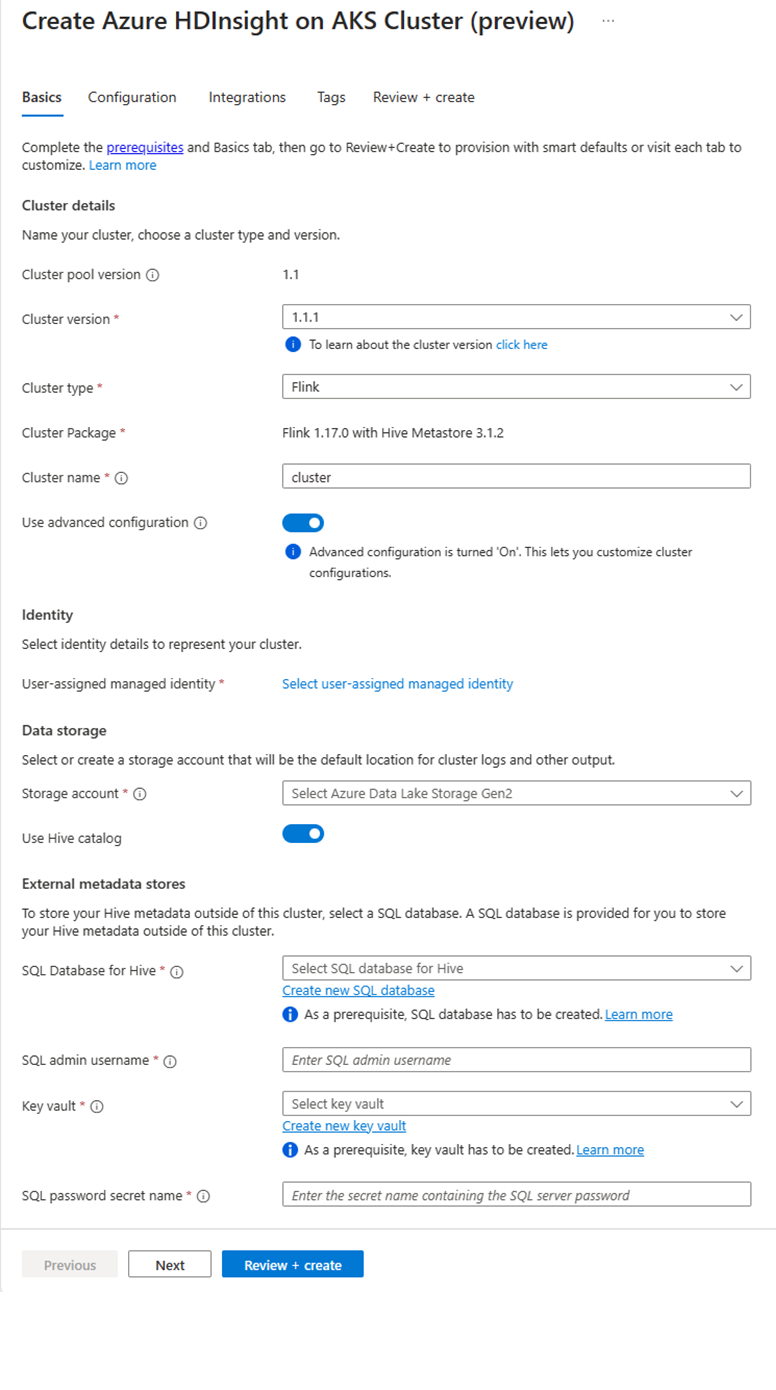
Notitie
Standaard gebruiken we het opslagaccount voor hive-catalogus hetzelfde als het opslagaccount en de container die tijdens het maken van het cluster wordt gebruikt.
Selecteer Volgende: Configuratie om door te gaan.
Geef op de pagina Configuratie de volgende informatie op:
Eigendom Beschrijving Grootte van knooppunt Selecteer de knooppuntgrootte die moet worden gebruikt voor de Flink-knooppunten, zowel hoofd- als werkknooppunten. Aantal knooppunten Selecteer het aantal knooppunten voor Flink-cluster; standaard zijn er twee hoofdknooppunten. De grootte van werkknooppunten helpt bij het bepalen van de configuraties van taakbeheer voor de Flink. De jobbeheer- en geschiedenisservers bevinden zich op hoofdknooppunten. Kies in de sectie Implementatie het implementatietype als toepassingsmodus geef de volgende informatie op:
Eigenschap Beschrijving Jar-bestandspad Vul het ABFS-pad (Opslag) in voor uw JAR-bestand voor taak. Bijvoorbeeld abfs://flink@teststorage.dfs.core.windows.net/appmode/job.jarInvoerklasse (optioneel) Hoofdklasse voor uw toepassingsmoduscluster. Bijvoorbeeld: com.microsoft.testjob Argumenten (optioneel) Argument voor de hoofdklasse van uw job. Naam van het opslagpunt De naam van het oude opslagpunt dat u wilt gebruiken voor het starten van de taak Upgrademodus Selecteer de standaardoptie Upgrade. Deze optie wordt gebruikt wanneer de upgrade van de hoofdversie plaatsvindt voor een cluster. Er zijn drie opties beschikbaar. UPDATE: Gebruikt wanneer een gebruiker wil herstellen vanaf het laatste opslagpunt na de upgrade. STATELESS_UPDATE: Gebruikt wanneer een gebruiker na de upgrade een frisse herstart voor de taak wil. LAST_STATE_UPDATE: Gebruikt wanneer een gebruiker na de upgrade een taak wil herstellen vanaf het laatste controlepunt. Flink-taakconfiguratie Voeg meer configuratie toe die vereist is voor de Flink-taak. Selecteer Aggregatie van taaklogboeken. Schakel het selectievakje in als u uw taaklogboek wilt uploaden naar externe opslag. Het helpt bij het opsporen van fouten in de taakproblemen. De standaardlocatie voor taaklogboek is 'StorageAccount/Container/DeploymentId/logs'. U kunt de standaardlogboekmap wijzigen door 'pipeline.remote.log.dir' te configureren. Het standaardinterval voor logboekverzameling is 600 sec. De gebruiker kan wijzigen door 'pipeline.log.aggregation.interval' te configureren.
Geef in de sectie Serviceconfiguratie de volgende informatie op:
Eigenschap Beschrijving CPU van taakbeheer Geheel getal. Voer de grootte in van de CPU's van Taakbeheer (in kernen). Geheugen van taakbeheer in MB Voer de geheugengrootte van Taakbeheer in MB in. Min van 1800 MB. CPU van jobmanager Geheel getal. Voer het aantal CPU's in voor de jobmanager (in kernen). Jobmanagergeheugen in MB Voer de geheugengrootte in MB in. Minimaal 1800 MB. CPU van geschiedenisserver Geheel getal. Voer het aantal CPU's in voor de jobmanager (in kernen). Geheugen van geschiedenisserver in MB Voer de geheugengrootte in MB in. Minimaal 1800 MB. 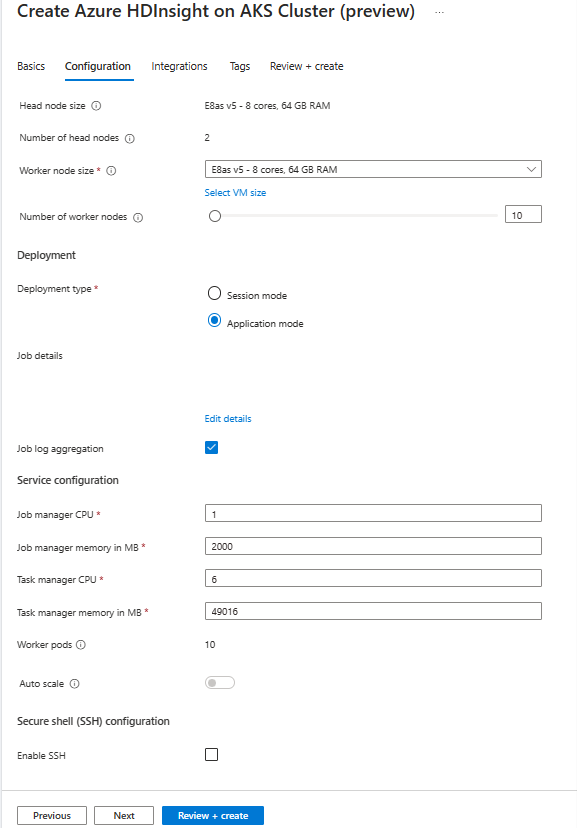
Klik op Volgende: integratieknop om door te gaan naar de volgende pagina.
Geef op de pagina Integratie de volgende informatie op:
Onroerend goed Beschrijving Loganalyse Deze functie is alleen beschikbaar als de gekoppelde log analytics-werkruimte van de clustergroep, nadat de logboeken zijn ingeschakeld die moeten worden verzameld, kunnen worden geselecteerd. Azure Prometheus Met deze functie kunt u inzichten en logboeken rechtstreeks in uw cluster weergeven door metrische gegevens en logboeken naar de Azure Monitor-werkruimte te verzenden. nl-NL:
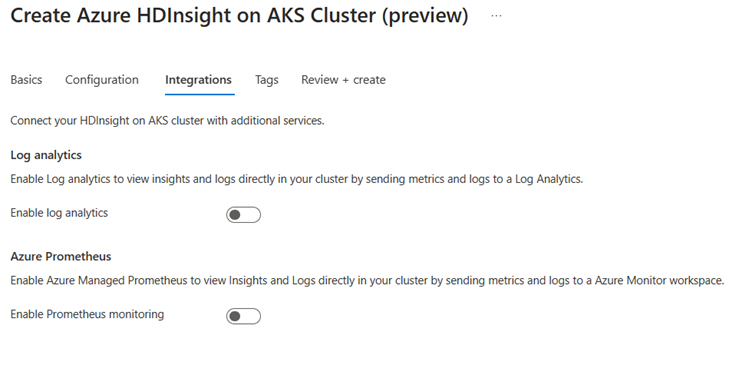
Klik op de knop Volgende: Tags om door te gaan naar de volgende pagina.
Geef op de pagina Tags de volgende informatie op:
Eigenschap Beschrijving Naam Facultatief. Voer een naam in zoals HDInsight in AKS om eenvoudig alle resources te identificeren die zijn gekoppeld aan uw clusterbronnen. Waarde U kunt dit leeg laten. Hulpbron Selecteer Alles geselecteerde resources. Klik op Volgende: Beoordelen en maken om door te gaan.
Zoek op de pagina Controleren en maken naar het Validatie geslaagd bericht boven aan de pagina en klik vervolgens op Maken.




Op de pagina Implementatie in proces wordt weergegeven welke het cluster wordt gemaakt. Het duurt 5-10 minuten om het cluster te maken. Zodra het cluster is gemaakt, wordt het bericht 'Uw implementatie is voltooid' weergegeven. Als u van de pagina weg navigeert, kunt u uw meldingen controleren op de huidige status.
Toepassingstaak beheren vanuit de portal
HDInsight AKS biedt manieren om Flink-taken te beheren. U kunt een mislukte taak opnieuw starten. Start de taak opnieuw vanuit de portal.
Als u de Flink-taak vanuit de portal wilt uitvoeren, gaat u naar:
Portal > HDInsight op AKS-clustergroep > Flink Cluster > Settings > Flink Jobs.

Stop: Stoptaak vereist geen parameters. De gebruiker kan de taak stoppen door de actie te selecteren. Zodra de taak is gestopt, wordt de taakstatus in de portal gestopt.
Start: Hiermee start u de taak vanuit het opslagpunt. Als u de taak wilt starten, selecteert u de gestopte taak en start u deze.
Update: Update helpt bij het herstarten van taken met geüpdatete taakcode. Gebruikers moeten de meest recente taak-JAR bijwerken in de opslaglocatie en de taak bijwerken vanuit de portal. Met deze actie stopt u de taak met savepoint en begint u opnieuw met de meest recente JAR.
Stateless Update: Stateless is net als een update, maar het omvat een nieuwe herstart van de taak met de nieuwste code. Zodra de taak is bijgewerkt, wordt de taakstatus op de portal weergegeven als Wordt uitgevoerd.
Savepoint: Neem het savepoint voor de Flink Job.
Annuleren: Beëindig de taak.
Verwijderen: AppMode-cluster verwijderen.
Taakdetails weergeven: Om de taakdetails te bekijken, kan de gebruiker op de taaknaam klikken. Dit geeft de details van de taak en het laatste actieresultaat weer.
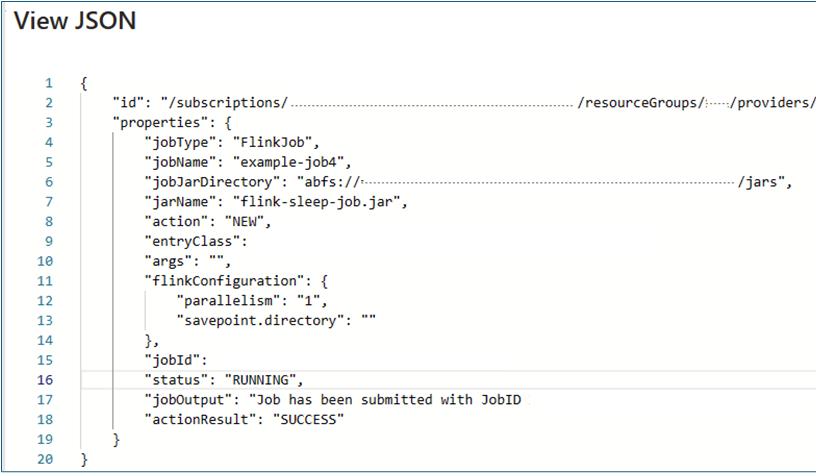

Voor een mislukte actie geeft deze json-weergave gedetailleerde uitzonderingen en redenen voor de fout.