Voorbeelden van het vouwen van query's
Dit artikel bevat enkele voorbeeldscenario's voor elk van de drie mogelijke resultaten voor het vouwen van query's. Het bevat ook enkele suggesties voor het optimaal profiteren van het query folding-mechanisme en het effect dat het kan hebben in uw query's.
Het scenario
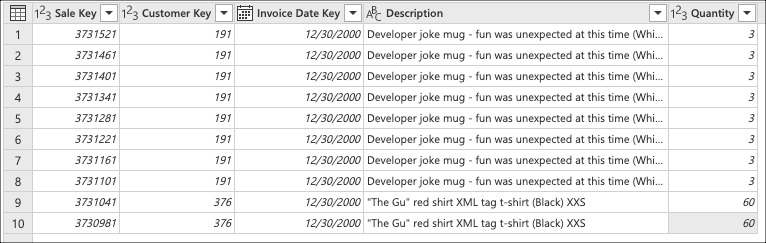
Stel dat u een scenario hebt waarin u, met behulp van de Wide World Importers-database voor Azure Synapse Analytics SQL-database, een query maakt in Power Query die verbinding maakt met de fact_Sale tabel en de laatste 10 verkopen met alleen de volgende velden ophaalt:
- Verkoopsleutel
- Klantsleutel
- Factuurdatumsleutel
- Beschrijving
- Hoeveelheid
Notitie
Voor demonstratiedoeleinden gebruikt dit artikel de database die wordt beschreven in de zelfstudie over het laden van de Wide World Importers-database in Azure Synapse Analytics. Het belangrijkste verschil in dit artikel is dat de fact_Sale tabel alleen gegevens bevat voor het jaar 2000, met in totaal 3.644.356 rijen.
Hoewel de resultaten mogelijk niet exact overeenkomen met de resultaten die u krijgt door de zelfstudie uit de Documentatie van Azure Synapse Analytics te volgen, is het doel van dit artikel om de belangrijkste concepten en impact te laten zien die query's in uw query's kunnen hebben.
In dit artikel worden drie manieren beschreven om dezelfde uitvoer te bereiken met verschillende niveaus van query folding:
- Geen query folding
- Gedeeltelijke query folding
- Volledige query folding
Geen voorbeeld van het vouwen van query's
Belangrijk
Query's die alleen afhankelijk zijn van niet-gestructureerde gegevensbronnen of die geen rekenengine hebben, zoals CSV- of Excel-bestanden, hebben geen mogelijkheden voor het vouwen van query's. Dit betekent dat Power Query alle vereiste gegevenstransformaties evalueert met behulp van de Power Query-engine.
Nadat u verbinding hebt gemaakt met uw database en naar de fact_Sale tabel navigeert, selecteert u de transformatie Onderste rijen behouden in de groep Rijen verminderen van het tabblad Start .
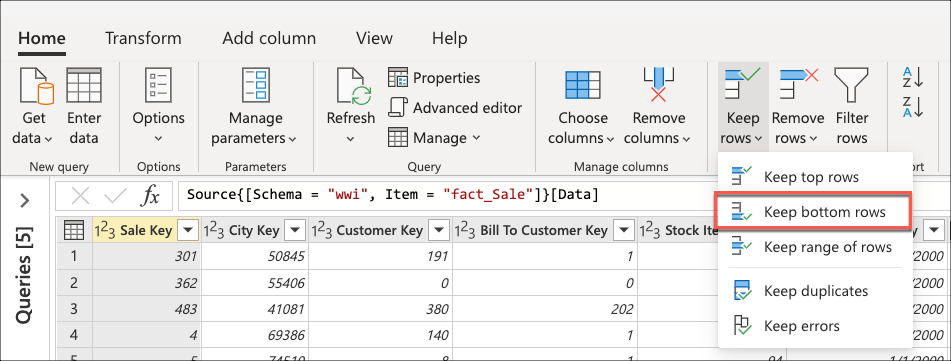
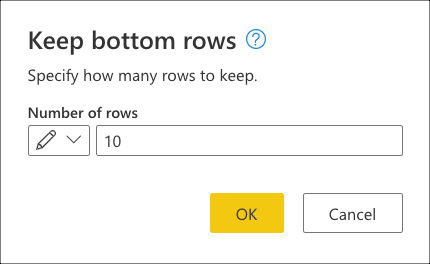
Nadat u deze transformatie hebt geselecteerd, wordt er een nieuw dialoogvenster weergegeven. In dit nieuwe dialoogvenster kunt u het aantal rijen invoeren dat u wilt behouden. Voer voor dit geval de waarde 10 in en selecteer VERVOLGENS OK.
Tip
Voor dit geval levert het uitvoeren van deze bewerking het resultaat van de laatste tien verkopen op. In de meeste scenario's wordt u aangeraden een explicietere logica op te geven waarmee wordt gedefinieerd welke rijen als laatste worden beschouwd door een sorteerbewerking toe te passen op de tabel.
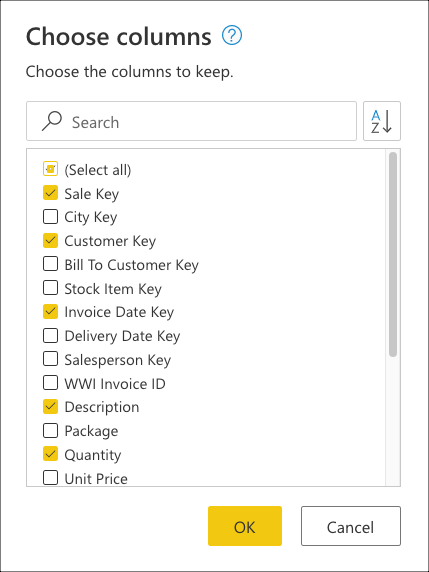
Selecteer vervolgens de transformatie Kolommen kiezen in de groep Kolommen beheren van het tabblad Start . Vervolgens kunt u de kolommen selecteren die u uit de tabel wilt bewaren en de rest verwijderen.
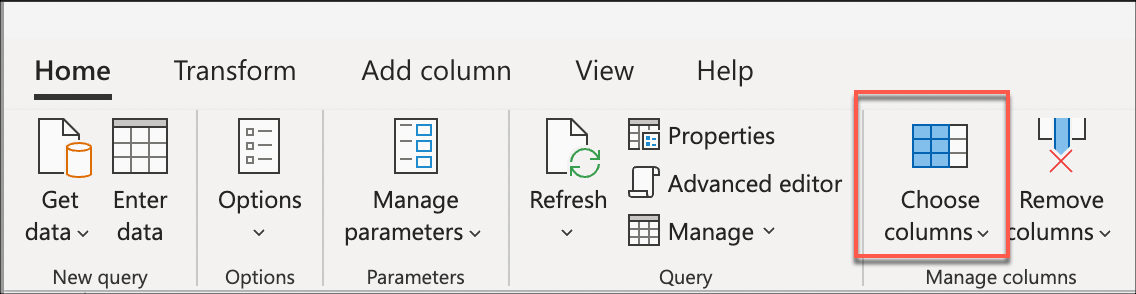
Tot slot selecteert u in het dialoogvenster Kolommen kiezen het Sale Key, Customer Key, Invoice Date Keyen DescriptionQuantity de kolommen en selecteert u OK.
Het volgende codevoorbeeld is het volledige M-script voor de query die u hebt gemaakt:
let
Source = Sql.Database(ServerName, DatabaseName),
Navigation = Source{[Schema = "wwi", Item = "fact_Sale"]}[Data],
#"Kept bottom rows" = Table.LastN(Navigation, 10),
#"Choose columns" = Table.SelectColumns(#"Kept bottom rows", {"Sale Key", "Customer Key", "Invoice Date Key", "Description", "Quantity"})
in
#"Choose columns""
Geen query folding: Inzicht in de query-evaluatie
Onder Toegepaste stappen in de Power Query-editor ziet u dat de queryvouwen-indicatoren voor onderste rijen behouden en Kolommen kiezen zijn gemarkeerd als stappen die buiten de gegevensbron worden geëvalueerd of, met andere woorden, door de Power Query-engine.
U kunt met de rechtermuisknop op de laatste stap van uw query klikken, de query kiezen met de naam Kolommen kiezen en de optie selecteren waarmee het queryplan weergeven wordt gelezen. Het doel van het queryplan is om u een gedetailleerd overzicht te geven van hoe uw query wordt uitgevoerd. Ga naar Het queryplan voor meer informatie over deze functie.
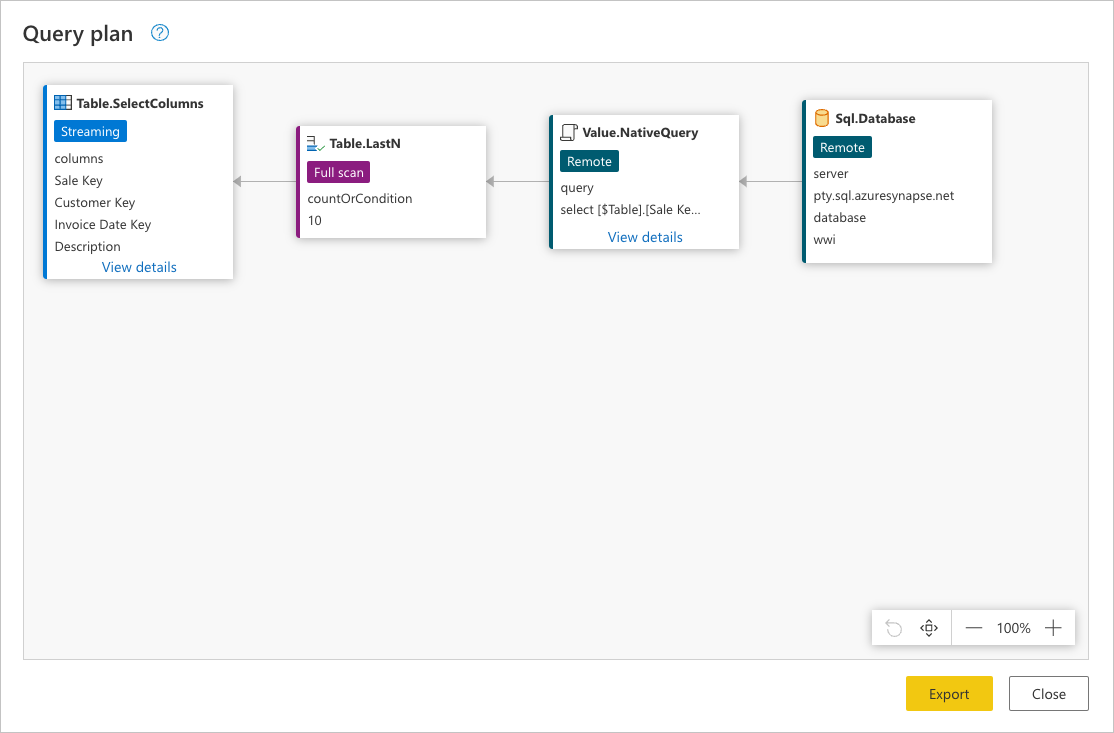
Elk vak in de vorige afbeelding wordt een knooppunt genoemd. Een knooppunt vertegenwoordigt de uitsplitsing van de bewerking om aan deze query te voldoen. Knooppunten die gegevensbronnen vertegenwoordigen, zoals SQL Server in het bovenstaande voorbeeld en het Value.NativeQuery knooppunt, vertegenwoordigen welk deel van de query wordt offloaden naar de gegevensbron. De rest van de knooppunten, in dit geval Table.LastN en Table.SelectColumns gemarkeerd in de rechthoek in de vorige afbeelding, worden geëvalueerd door de Power Query-engine. Deze twee knooppunten vertegenwoordigen de twee transformaties die u hebt toegevoegd, Onderste rijen behouden en Kolommen kiezen. De rest van de knooppunten vertegenwoordigen bewerkingen die plaatsvinden op gegevensbronniveau.
Als u de exacte aanvraag wilt zien die naar uw gegevensbron wordt verzonden, selecteert u Details weergeven in het Value.NativeQuery knooppunt.
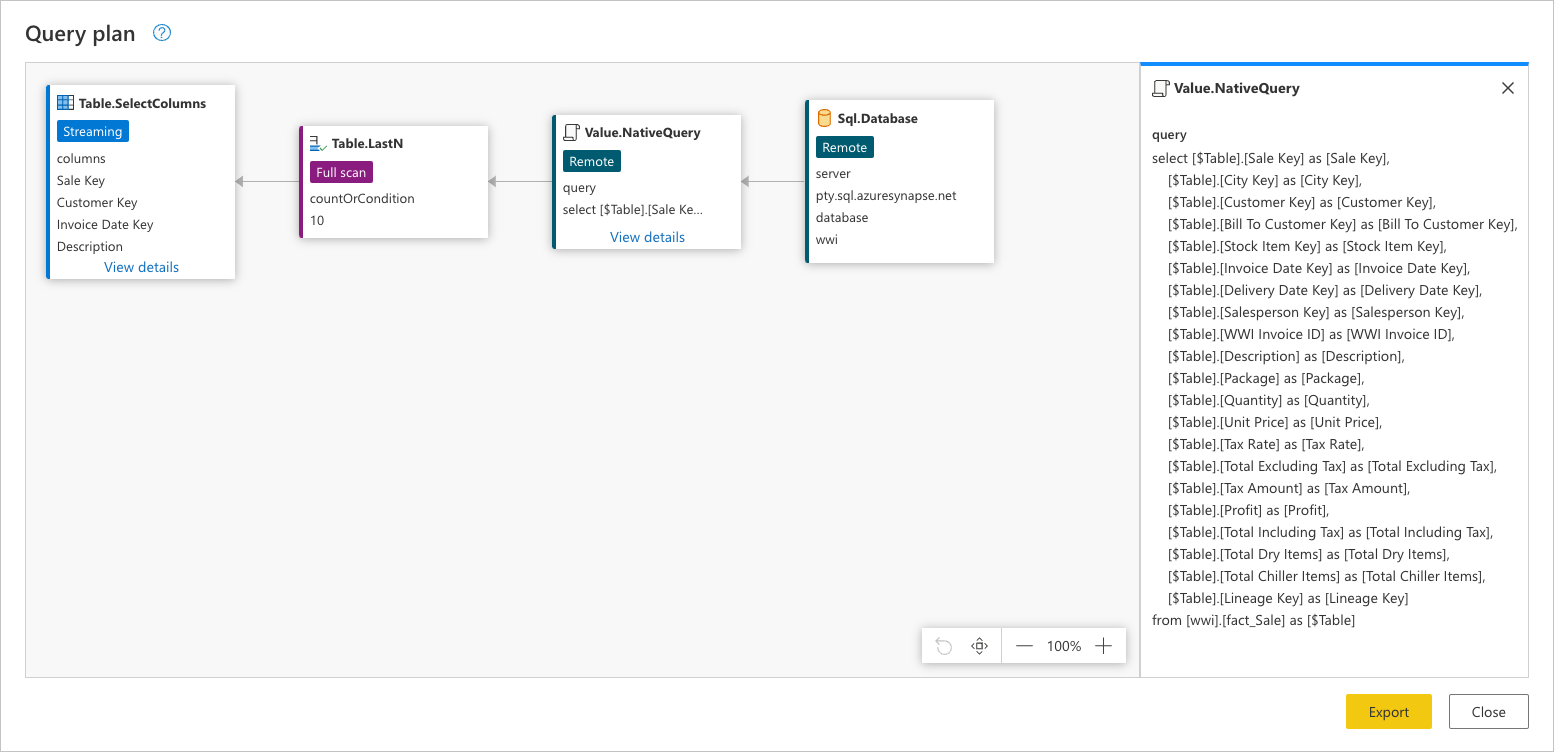
Deze gegevensbronaanvraag bevindt zich in de systeemeigen taal van uw gegevensbron. In dit geval is deze taal SQL en deze instructie vertegenwoordigt een aanvraag voor alle rijen en velden uit de fact_Sale tabel.
Door deze gegevensbronaanvraag te raadplegen, krijgt u meer inzicht in het verhaal dat het queryplan probeert over te brengen:
Sql.Database: Dit knooppunt vertegenwoordigt de toegang tot de gegevensbron. Verbinding maken s naar de database en verzendt metagegevensaanvragen om inzicht te hebben in de mogelijkheden ervan.Value.NativeQuery: Vertegenwoordigt de aanvraag die is gegenereerd door Power Query om aan de query te voldoen. Power Query verzendt de gegevensaanvragen in een systeemeigen SQL-instructie naar de gegevensbron. In dit geval vertegenwoordigt dit alle records en velden (kolommen) uit defact_Saletabel. Voor dit scenario is dit niet wenselijk, omdat de tabel miljoenen rijen bevat en de interesse alleen in de laatste 10 valt.Table.LastN: Zodra Power Query alle records uit defact_Saletabel ontvangt, wordt de Power Query-engine gebruikt om de tabel te filteren en alleen de laatste tien rijen te bewaren.Table.SelectColumns: Power Query gebruikt de uitvoer van hetTable.LastNknooppunt en past een nieuwe transformatie toe die wordt aangeroepenTable.SelectColumns, waarmee de specifieke kolommen worden geselecteerd die u uit een tabel wilt bewaren.
Voor de evaluatie moest deze query alle rijen en velden uit de fact_Sale tabel downloaden. Deze query duurde gemiddeld 6 minuten en 1 seconde om te worden verwerkt in een standaardexemplaren van Power BI-gegevensstromen (die rekening hield met de evaluatie en het laden van gegevens naar gegevensstromen).
Voorbeeld van gedeeltelijk vouwen van query's
Nadat u verbinding hebt gemaakt met de database en naar de fact_Sale tabel navigeert, selecteert u eerst de kolommen die u uit de tabel wilt bewaren. Selecteer de transformatie Kolommen kiezen in de groep Kolommen beheren op het tabblad Start . Met deze transformatie kunt u expliciet de kolommen selecteren die u uit de tabel wilt bewaren en de rest verwijderen.
Selecteer in het dialoogvenster Kolommen kiezen de Sale Keykolommen , , Customer Keyen DescriptionInvoice Date KeyQuantity kolommen en selecteer vervolgens OK.
U maakt nu logica waarmee de tabel wordt gesorteerd op de laatste verkoop onder aan de tabel. Selecteer de Sale Key kolom, de primaire sleutel en incrementele reeks of index van de tabel. Sorteer de tabel met alleen dit veld in oplopende volgorde vanuit het contextmenu voor de kolom.
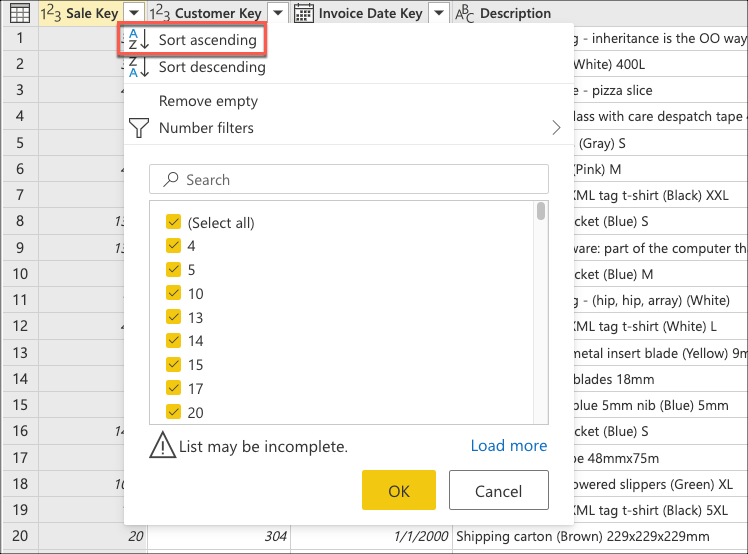
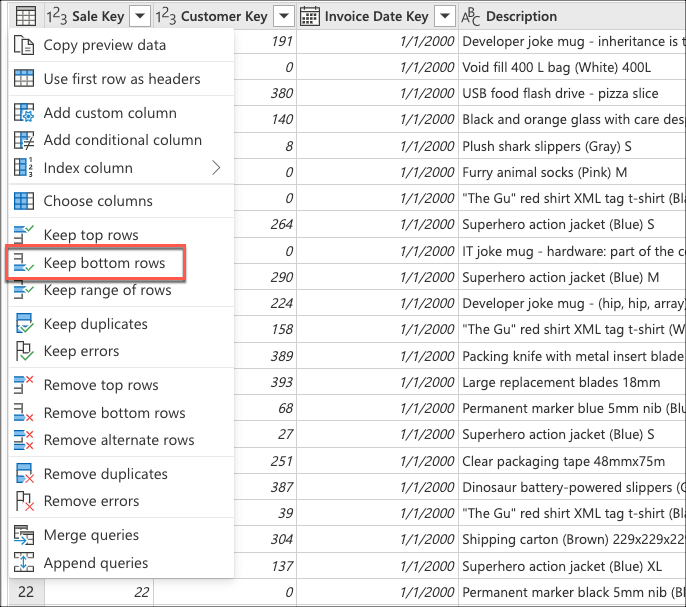
Selecteer vervolgens het contextmenu van de tabel en kies de transformatie onderste rijen behouden.
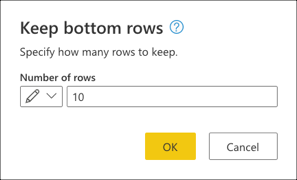
Voer in Onderste rijen behouden de waarde 10 in en selecteer VERVOLGENS OK.
Het volgende codevoorbeeld is het volledige M-script voor de query die u hebt gemaakt:
let
Source = Sql.Database(ServerName, DatabaseName),
Navigation = Source{[Schema = "wwi", Item = "fact_Sale"]}[Data],
#"Choose columns" = Table.SelectColumns(Navigation, {"Sale Key", "Customer Key", "Invoice Date Key", "Description", "Quantity"}),
#"Sorted rows" = Table.Sort(#"Choose columns", {{"Sale Key", Order.Ascending}}),
#"Kept bottom rows" = Table.LastN(#"Sorted rows", 10)
in
#"Kept bottom rows"
Voorbeeld van gedeeltelijk vouwen van query's: Inzicht in de query-evaluatie
Als u het deelvenster toegepaste stappen controleert, ziet u dat de queryvouwindicatoren laten zien dat de laatste transformatie die u hebt toegevoegd, Kept bottom rowsis gemarkeerd als een stap die buiten de gegevensbron wordt geëvalueerd of, met andere woorden, door de Power Query-engine.
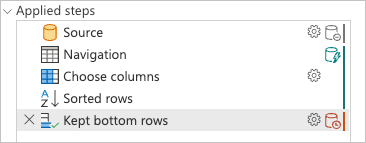
U kunt met de rechtermuisknop klikken op de laatste stap van uw query, de naam Kept bottom rowsen de optie Queryplan selecteren om beter te begrijpen hoe uw query kan worden geëvalueerd.
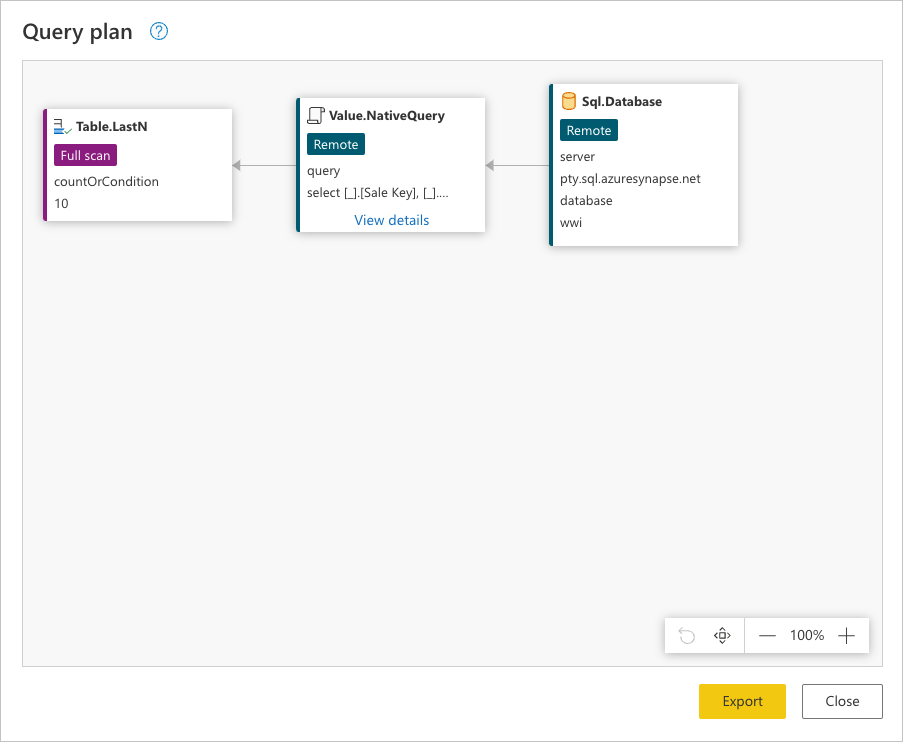
Elk vak in de vorige afbeelding wordt een knooppunt genoemd. Een knooppunt vertegenwoordigt elk proces dat moet worden uitgevoerd (van links naar rechts) om uw query te kunnen evalueren. Sommige van deze knooppunten kunnen worden geëvalueerd in uw gegevensbron, terwijl andere, zoals het knooppunt, Table.LastNvertegenwoordigd door de stap Onderste rijen behouden, worden geëvalueerd met behulp van de Power Query-engine.
Als u de exacte aanvraag wilt zien die naar uw gegevensbron wordt verzonden, selecteert u Details weergeven in het Value.NativeQuery knooppunt.
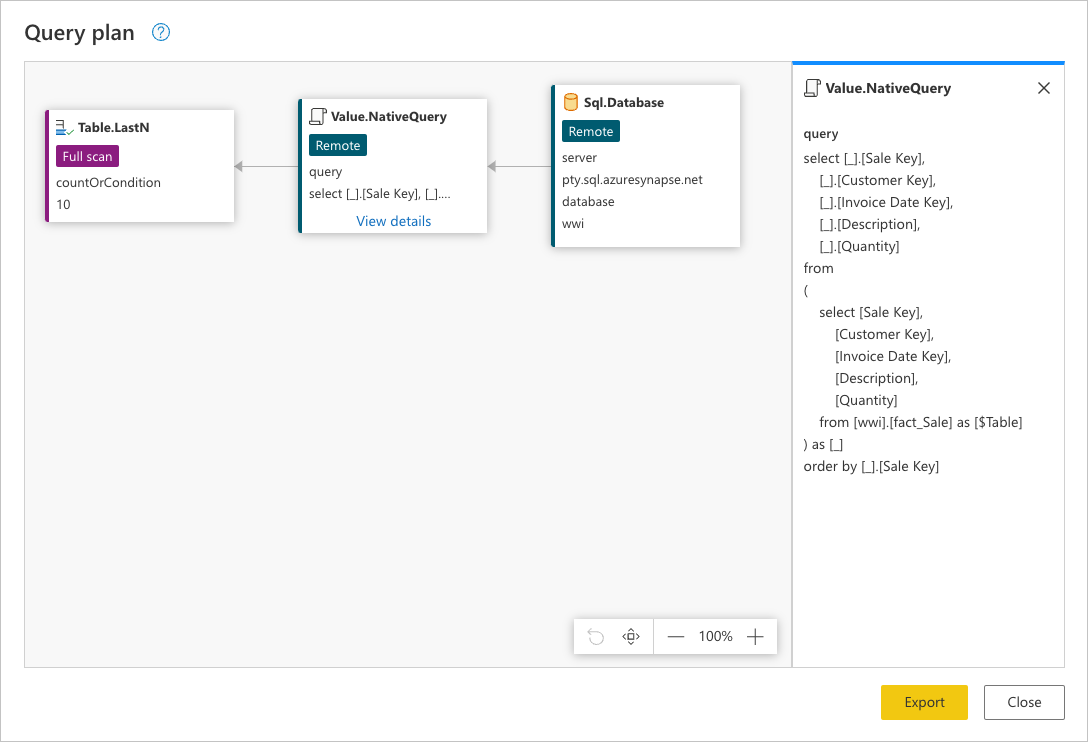
Deze aanvraag bevindt zich in de systeemeigen taal van uw gegevensbron. In dit geval is die taal SQL en deze instructie vertegenwoordigt een aanvraag voor alle rijen, met alleen de aangevraagde velden uit de fact_Sale tabel die door het Sale Key veld zijn besteld.
Door deze gegevensbronaanvraag te raadplegen, krijgt u meer inzicht in het verhaal dat het volledige queryplan probeert over te brengen. De volgorde van de knooppunten is een opeenvolgend proces dat begint met het aanvragen van de gegevens uit uw gegevensbron:
Sql.Database: Verbinding maken s naar de database en verzendt metagegevensaanvragen om inzicht te hebben in de mogelijkheden ervan.Value.NativeQuery: Vertegenwoordigt de aanvraag die is gegenereerd door Power Query om aan de query te voldoen. Power Query verzendt de gegevensaanvragen in een systeemeigen SQL-instructie naar de gegevensbron. In dit geval vertegenwoordigt dit alle records, waarbij alleen de aangevraagde velden uit defact_Saletabel in de database in oplopende volgorde worden gesorteerd op hetSales Keyveld.Table.LastN: Zodra Power Query alle records uit defact_Saletabel ontvangt, wordt de Power Query-engine gebruikt om de tabel te filteren en alleen de laatste tien rijen te bewaren.
Voor de evaluatie moest deze query alle rijen en alleen de vereiste velden uit de fact_Sale tabel downloaden. Het duurde gemiddeld 3 minuten en 4 seconden om te worden verwerkt in een standaardexemplaren van Power BI-gegevensstromen (die rekening hield met de evaluatie en het laden van gegevens naar gegevensstromen).
Voorbeeld van het vouwen van volledige query's
Nadat u verbinding hebt gemaakt met de database en naar de fact_Sale tabel navigeert, selecteert u eerst de kolommen die u uit de tabel wilt bewaren. Selecteer de transformatie Kolommen kiezen in de groep Kolommen beheren op het tabblad Start . Met deze transformatie kunt u expliciet de kolommen selecteren die u uit de tabel wilt bewaren en de rest verwijderen.
Selecteer in Kolommen kiezen de Sale Key, Customer Key, , Invoice Date Keyen DescriptionQuantity kolommen en selecteer vervolgens OK.
U maakt nu logica waarmee de tabel wordt gesorteerd op de laatste verkoop boven aan de tabel. Selecteer de Sale Key kolom, de primaire sleutel en incrementele reeks of index van de tabel. Sorteer de tabel alleen met behulp van dit veld in aflopende volgorde vanuit het contextmenu voor de kolom.
Selecteer vervolgens het contextmenu van de tabel en kies de transformatie van bovenste rijen behouden.
Voer in Bovenste rijen behouden de waarde 10 in en selecteer VERVOLGENS OK.
Het volgende codevoorbeeld is het volledige M-script voor de query die u hebt gemaakt:
let
Source = Sql.Database(ServerName, DatabaseName),
Navigation = Source{[Schema = "wwi", Item = "fact_Sale"]}[Data],
#"Choose columns" = Table.SelectColumns(Navigation, {"Sale Key", "Customer Key", "Invoice Date Key", "Description", "Quantity"}),
#"Sorted rows" = Table.Sort(#"Choose columns", {{"Sale Key", Order.Descending}}),
#"Kept top rows" = Table.FirstN(#"Sorted rows", 10)
in
#"Kept top rows"
Volledig voorbeeld van het vouwen van query's: Inzicht in de query-evaluatie
Wanneer u het deelvenster toegepaste stappen controleert, ziet u dat de queryvouwindicatoren laten zien dat de transformaties die u hebt toegevoegd, Kolommen kiezen, Gesorteerde rijen en Bovenste rijen behouden, worden gemarkeerd als stappen die worden geëvalueerd in de gegevensbron.

U kunt met de rechtermuisknop op de laatste stap van uw query klikken, de laatste met de naam Bewaarde bovenste rijen en de optie selecteren die het queryplan leest.
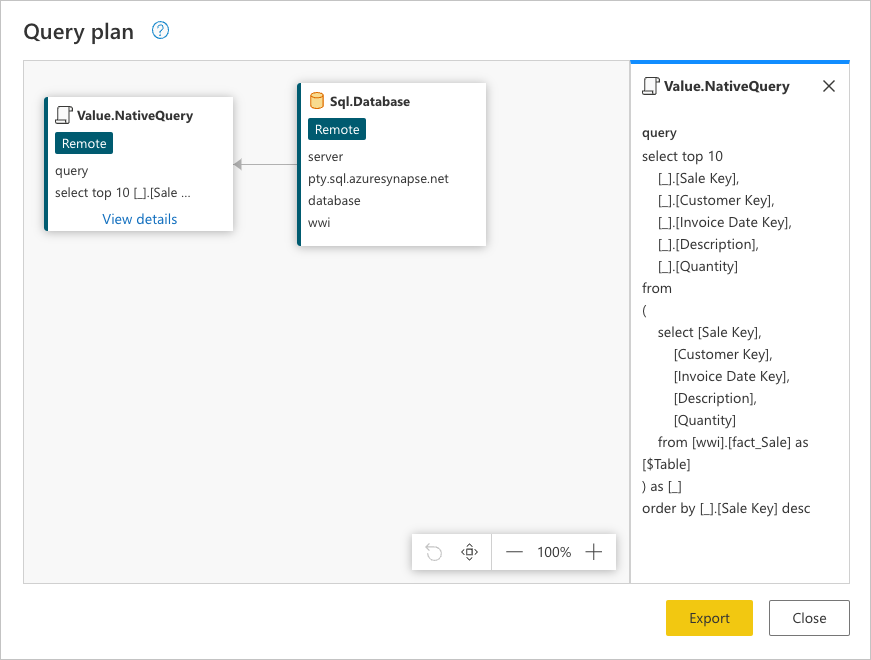
Deze aanvraag bevindt zich in de systeemeigen taal van uw gegevensbron. In dit geval is deze taal SQL en deze instructie vertegenwoordigt een aanvraag voor alle rijen en velden uit de fact_Sale tabel.
Door deze gegevensbronquery te raadplegen, krijgt u meer inzicht in het verhaal dat het volledige queryplan probeert over te brengen:
Sql.Database: Verbinding maken s naar de database en verzendt metagegevensaanvragen om inzicht te hebben in de mogelijkheden ervan.Value.NativeQuery: Vertegenwoordigt de aanvraag die is gegenereerd door Power Query om aan de query te voldoen. Power Query verzendt de gegevensaanvragen in een systeemeigen SQL-instructie naar de gegevensbron. In dit geval vertegenwoordigt dit een aanvraag voor alleen de tien bovenste records van defact_Saletabel, met alleen de vereiste velden nadat ze in aflopende volgorde zijn gesorteerd met behulp van hetSale Keyveld.
Notitie
Er is geen component die kan worden gebruikt om de onderste rijen van een tabel in de T-SQL-taal te SELECTEREN, maar er is een TOP-component waarmee de bovenste rijen van een tabel worden opgehaald.
Voor de evaluatie downloadt deze query slechts 10 rijen, met alleen de velden die u in de fact_Sale tabel hebt aangevraagd. Deze query duurde gemiddeld 31 seconden om te worden verwerkt in een standaardexemplaren van Power BI-gegevensstromen (die rekening hield met de evaluatie en het laden van gegevens naar gegevensstromen).
Prestatievergelijking
Om beter inzicht te krijgen in de invloed die query's in deze query's hebben, kunt u uw query's vernieuwen, de tijd vastleggen die nodig is om elke query volledig te vernieuwen en deze te vergelijken. Ter vereenvoudiging biedt dit artikel de gemiddelde tijdsinstellingen voor vernieuwingen die zijn vastgelegd met behulp van de monteur voor vernieuwen van Power BI-gegevensstromen, terwijl u verbinding maakt met een toegewezen Azure Synapse Analytics-omgeving met DW2000c als serviceniveau.
De vernieuwingstijd voor elke query is als volgt:
| Opmerking | Label | Tijd in seconden |
|---|---|---|
| Geen query folding | Geen | 361 |
| Gedeeltelijke query folding | Gedeeltelijk | 184 |
| Volledige query folding | Volledig | 31 |
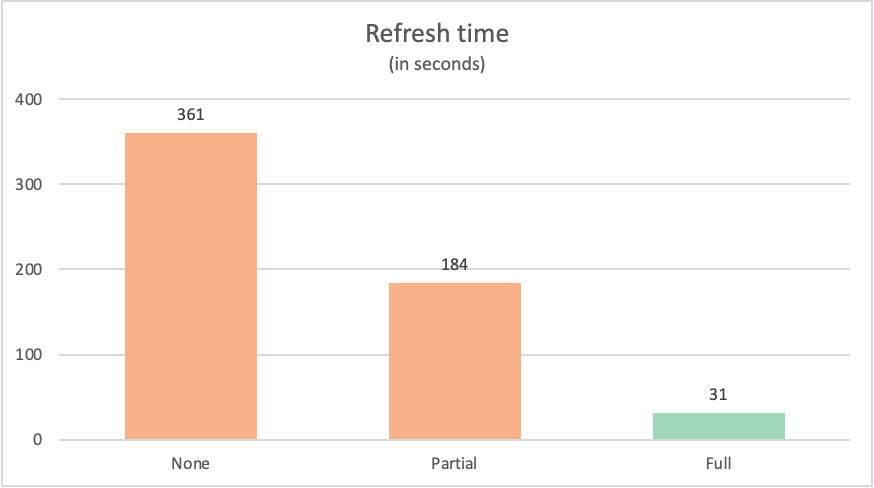
Het is vaak zo dat een query die volledig terugvouwt naar de gegevensbron, presteert beter dan vergelijkbare query's die niet volledig naar de gegevensbron worden teruggevouwen. Er kunnen veel redenen zijn waarom dit het geval is. Deze redenen variëren van de complexiteit van de transformaties die uw query uitvoert, tot de queryoptimalisaties die zijn geïmplementeerd in uw gegevensbron, zoals indexen en toegewezen computing en netwerkresources. Er zijn nog steeds twee specifieke belangrijke processen die query folding probeert te gebruiken om de invloed die beide processen hebben met Power Query te minimaliseren:
- Actieve gegevens
- Transformaties die worden uitgevoerd door de Power Query-engine
In de volgende secties wordt uitgelegd wat de invloed is van deze twee processen in de eerder genoemde query's.
Actieve gegevens
Wanneer een query wordt uitgevoerd, wordt geprobeerd de gegevens uit de gegevensbron op te halen als een van de eerste stappen. Welke gegevens worden opgehaald uit de gegevensbron, wordt gedefinieerd door het query folding-mechanisme. Dit mechanisme identificeert de stappen van de query die kunnen worden offload naar de gegevensbron.
De volgende tabel bevat het aantal rijen dat is aangevraagd in de fact_Sale tabel van de database. De tabel bevat ook een korte beschrijving van de SQL-instructie die is verzonden om dergelijke gegevens op te vragen uit de gegevensbron.
| Opmerking | Label | Aangevraagde rijen | Beschrijving |
|---|---|---|---|
| Geen query folding | Geen | 3644356 | Aanvraag voor alle velden en alle records uit de fact_Sale tabel |
| Gedeeltelijke query folding | Gedeeltelijk | 3644356 | Aanvraag voor alle records, maar alleen vereiste velden uit de fact_Sale tabel nadat deze zijn gesorteerd op het Sale Key veld |
| Volledige query folding | Volledig | 10 | Alleen de vereiste velden en de TOP 10 records van de tabel aanvragen nadat ze fact_Sale in aflopende volgorde zijn gesorteerd op het Sale Key veld |
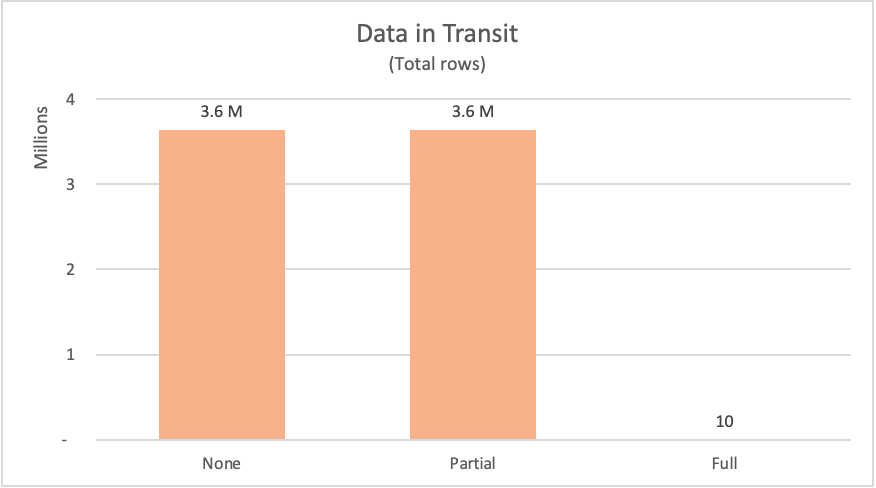
Bij het aanvragen van gegevens uit een gegevensbron moet de gegevensbron de resultaten voor de aanvraag berekenen en vervolgens de gegevens naar de aanvrager verzenden. Hoewel de computerresources al zijn vermeld, kunnen de netwerkresources van de gegevens van de gegevensbron naar Power Query de gegevens effectief ontvangen en voorbereiden op de transformaties die lokaal plaatsvinden, afhankelijk van de grootte van de gegevens.
Voor de voorbeeldvoorbeelden moest Power Query meer dan 3,6 miljoen rijen uit de gegevensbron aanvragen voor de geen voorbeelden van het vouwen van query's en gedeeltelijke query's. Voor het volledige voorbeeld van het vouwen van query's heeft deze slechts 10 rijen aangevraagd. Voor de aangevraagde velden heeft het voorbeeld voor het vouwen van query's niet alle beschikbare velden uit de tabel aangevraagd. Zowel de gedeeltelijke query folding als de volledige query folding-voorbeelden hebben alleen een aanvraag ingediend voor precies de velden die ze nodig hebben.
Let op
U wordt aangeraden incrementele vernieuwingsoplossingen te implementeren die gebruikmaken van query's of tabellen met grote hoeveelheden gegevens. Verschillende productintegraties van Power Query implementeren time-outs om langlopende query's te beëindigen. Sommige gegevensbronnen implementeren ook time-outs voor langlopende sessies en proberen dure query's uit te voeren op hun servers. Meer informatie: Incrementeel vernieuwen gebruiken met gegevensstromen en incrementeel vernieuwen voor semantische modellen
Transformaties die worden uitgevoerd door de Power Query-engine
In dit artikel wordt uitgelegd hoe u het queryplan kunt gebruiken om beter te begrijpen hoe uw query kan worden geëvalueerd. In het queryplan ziet u de exacte knooppunten van de transformatiebewerkingen die door de Power Query-engine worden uitgevoerd.
In de volgende tabel ziet u de knooppunten uit de queryplannen van de vorige query's die door de Power Query-engine zouden zijn geëvalueerd.
| Opmerking | Label | Transformatieknooppunten van Power Query-engine |
|---|---|---|
| Geen query folding | Geen | Table.LastN, Table.SelectColumns |
| Gedeeltelijke query folding | Gedeeltelijk | Table.LastN |
| Volledige query folding | Volledig | — |
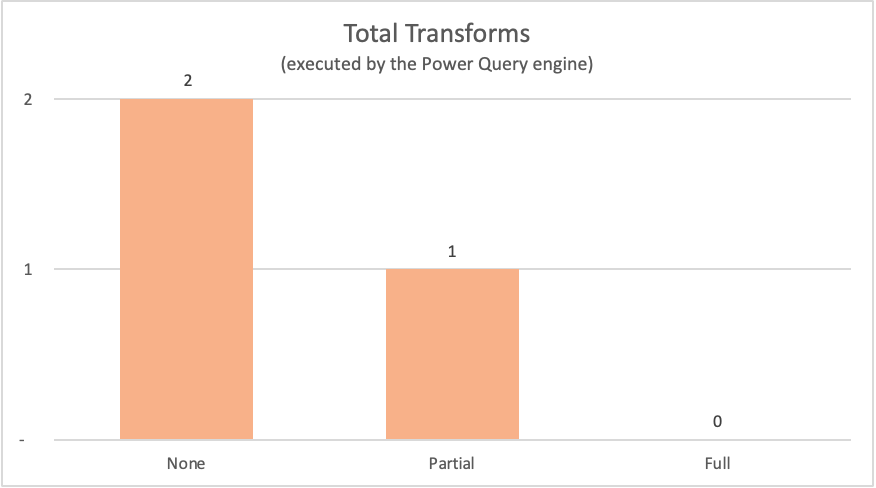
Voor de voorbeelden die in dit artikel worden weergegeven, zijn voor het volledige voorbeeld van het vouwen van query's geen transformaties in de Power Query-engine vereist, omdat de vereiste uitvoertabel rechtstreeks afkomstig is van de gegevensbron. De andere twee query's hebben daarentegen enige berekeningen nodig bij de Power Query-engine. Vanwege de hoeveelheid gegevens die door deze twee query's moet worden verwerkt, duurt het proces voor deze voorbeelden langer dan het volledige voorbeeld van het vouwen van query's.
Transformaties kunnen worden gegroepeerd in de volgende categorieën:
| Type of Operator | Beschrijving |
|---|---|
| Extern | Operators die gegevensbronknooppunten zijn. De evaluatie van deze operators vindt plaats buiten Power Query. |
| Streaming | Operators zijn passthrough-operators. Met een eenvoudig filter kunnen de Table.SelectRows resultaten meestal worden gefilterd terwijl ze de operator passeren en hoeven niet alle rijen te worden verzameld voordat de gegevens worden verplaatst. Table.SelectColumns en Table.ReorderColumns zijn andere voorbeelden van dit soort operators. |
| Volledige scan | Operators die alle rijen moeten verzamelen voordat de gegevens naar de volgende operator in de keten kunnen gaan. Als u bijvoorbeeld gegevens wilt sorteren, moet Power Query alle gegevens verzamelen. Andere voorbeelden van volledige scanoperators zijn Table.Group, Table.NestedJoinen Table.Pivot. |
Tip
Hoewel niet elke transformatie hetzelfde is vanuit het oogpunt van prestaties, is het meestal beter om minder transformaties te hebben.
Overwegingen en suggesties
- Volg de aanbevolen procedures bij het maken van een nieuwe query, zoals aangegeven in best practices in Power Query.
- Gebruik de indicatoren voor het vouwen van query's om te controleren welke stappen ervoor zorgen dat uw query niet kan worden gevouwen. Rangschik ze indien nodig om het vouwen te vergroten.
- Gebruik het queryplan om te bepalen welke transformaties plaatsvinden in de Power Query-engine voor een bepaalde stap. Overweeg om uw bestaande query te wijzigen door de stappen opnieuw te rangschikken. Controleer vervolgens het queryplan van de laatste stap van uw query opnieuw en kijk of het queryplan er beter uitziet dan de vorige. Het nieuwe queryplan heeft bijvoorbeeld minder knooppunten dan de vorige en de meeste knooppunten zijn 'Streaming'-knooppunten en niet 'volledige scan'. Voor gegevensbronnen die ondersteuning bieden voor vouwen, vertegenwoordigen alle knooppunten in het queryplan anders dan
Value.NativeQueryen gegevensbrontoegangsknooppunten transformaties die niet zijn gevouwen. - Indien beschikbaar, kunt u de optie Systeemeigen query weergeven (of Gegevensbronquery weergeven) gebruiken om ervoor te zorgen dat uw query kan worden teruggevouwen naar de gegevensbron. Als deze optie is uitgeschakeld voor uw stap en u een bron gebruikt die deze normaal gesproken inschakelt, hebt u een stap gemaakt die het vouwen van query's stopt. Als u een bron gebruikt die deze optie niet ondersteunt, kunt u vertrouwen op de indicatoren en het queryplan voor het vouwen van query's.
- Gebruik de hulpprogramma's voor querydiagnose om meer inzicht te krijgen in de aanvragen die naar uw gegevensbron worden verzonden wanneer de mogelijkheden voor het vouwen van query's beschikbaar zijn voor de connector.
- Wanneer u gegevens uit het gebruik van meerdere connectors combineert, probeert Power Query zoveel mogelijk werk naar beide gegevensbronnen te pushen terwijl wordt voldaan aan de privacyniveaus die zijn gedefinieerd voor elke gegevensbron.
- Lees het artikel over privacyniveaus om uw query's te beschermen tegen het uitvoeren van een Data Privacy Firewall-fout.
- Gebruik andere hulpprogramma's om query folding te controleren vanuit het perspectief van de aanvraag die door de gegevensbron wordt ontvangen. Op basis van het voorbeeld in dit artikel kunt u de Microsoft SQL Server Profiler gebruiken om de aanvragen te controleren die worden verzonden door Power Query en ontvangen door de Microsoft SQL Server.
- Als u een nieuwe stap toevoegt aan een volledig gevouwen query en de nieuwe stap ook wordt gevouwen, kan Power Query een nieuwe aanvraag verzenden naar de gegevensbron in plaats van een in de cache opgeslagen versie van het vorige resultaat te gebruiken. In de praktijk kan dit proces leiden tot schijnbaar eenvoudige bewerkingen voor een kleine hoeveelheid gegevens die langer duurt om te worden vernieuwd in de preview dan verwacht. Deze langere vernieuwing is het gevolg van het opnieuw opvragen van de gegevensbron in Power Query in plaats van een lokale kopie van de gegevens te bewerken.