Incrementeel vernieuwen gebruiken met gegevensstromen
Met gegevensstromen kunt u grote hoeveelheden gegevens overbrengen naar Power BI of de opgegeven opslag van uw organisatie. In sommige gevallen is het echter niet praktisch om een volledige kopie van brongegevens bij te werken bij elke vernieuwing. Een goed alternatief is incrementeel vernieuwen, wat de volgende voordelen biedt voor gegevensstromen:
- Vernieuwen gaat sneller: alleen gegevens die zijn gewijzigd, moeten worden vernieuwd. Vernieuw bijvoorbeeld alleen de laatste vijf dagen van een gegevensstroom van tien jaar.
- Vernieuwen is betrouwbaarder: het is bijvoorbeeld niet nodig om langdurige verbindingen met vluchtige bronsystemen te onderhouden.
- Resourceverbruik wordt verminderd: minder gegevens om te vernieuwen vermindert het totale geheugenverbruik en andere resources.
Incrementeel vernieuwen is beschikbaar in gegevensstromen die zijn gemaakt in Power BI en gegevensstromen die zijn gemaakt in Power Apps. In dit artikel worden schermen van Power BI weergegeven, maar deze instructies zijn van toepassing op gegevensstromen die zijn gemaakt in Power BI of in Power Apps.
Notitie
Wanneer het schema voor een tabel in een analytische gegevensstroom wordt gewijzigd, wordt een volledige vernieuwing uitgevoerd om ervoor te zorgen dat alle resulterende gegevens overeenkomen met het nieuwe schema. Als gevolg hiervan worden gegevens die incrementeel worden opgeslagen, vernieuwd en gaan in sommige gevallen verloren als het bronsysteem geen historische gegevens bewaart.
Als u incrementeel vernieuwen gebruikt in gegevensstromen die zijn gemaakt in Power BI, moet de gegevensstroom zich in een werkruimte in Premium-capaciteit bevinden. Incrementeel vernieuwen in Power Apps vereist Power Apps-abonnementen per app of per gebruiker en is alleen beschikbaar voor gegevensstromen met Azure Data Lake Storage als doel.
Voor het gebruik van incrementeel vernieuwen in Power BI of Power Apps is vereist dat brongegevens die zijn opgenomen in de gegevensstroom een datum/tijd-veld hebben waarop incrementeel vernieuwen kan worden gefilterd.
Incrementeel vernieuwen configureren voor gegevensstromen
Een gegevensstroom kan veel tabellen bevatten. Incrementeel vernieuwen wordt ingesteld op tabelniveau, zodat één gegevensstroom zowel volledig vernieuwde tabellen als incrementele vernieuwingstabellen kan bevatten.
Als u een tabel met incrementeel vernieuwen wilt instellen, configureert u eerst de tabel zoals u dat zou doen.
Nadat de gegevensstroom is gemaakt en opgeslagen, selecteert u Incrementeel vernieuwen ![]() in de tabelweergave, zoals wordt weergegeven in de volgende afbeelding.
in de tabelweergave, zoals wordt weergegeven in de volgende afbeelding.
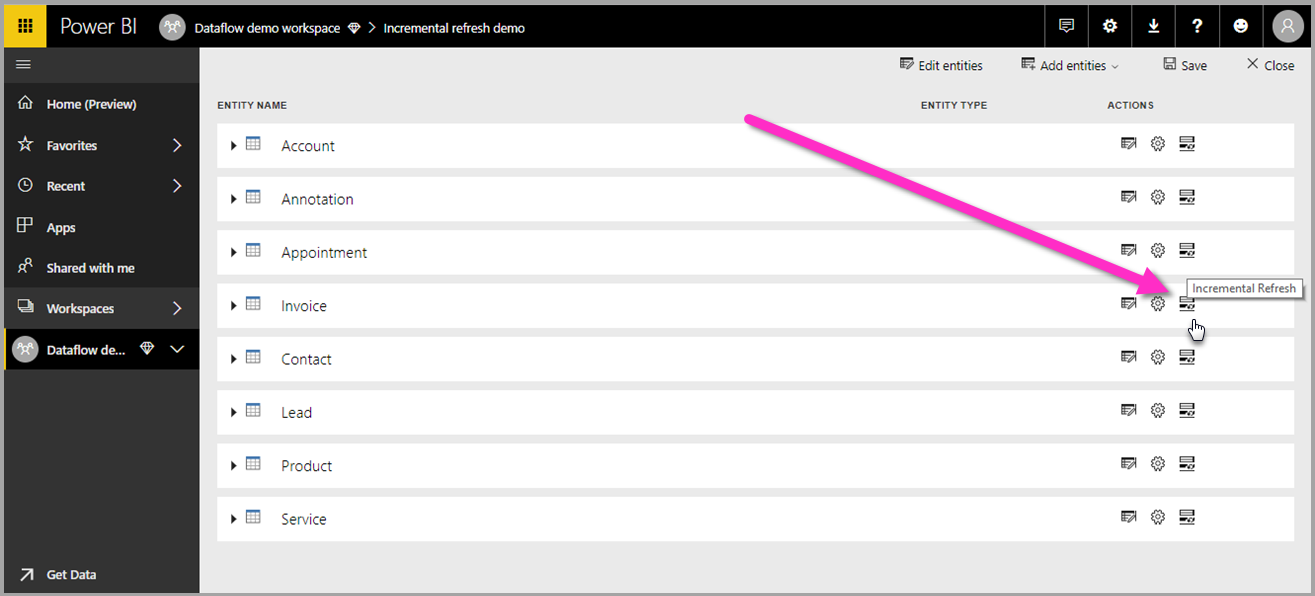
Wanneer u het pictogram selecteert, wordt het venster Instellingen voor incrementeel vernieuwen weergegeven. Schakel incrementeel vernieuwen in.
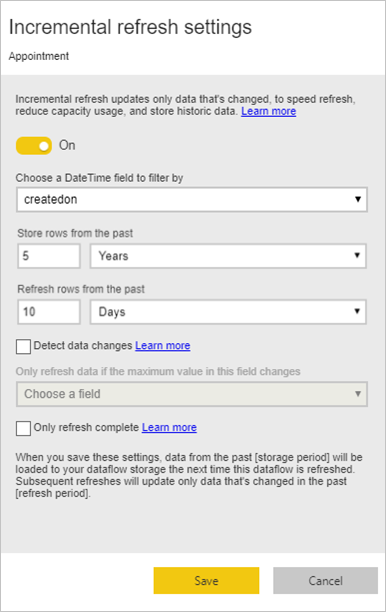
In de volgende lijst worden de instellingen in het venster Instellingen voor incrementeel vernieuwen uitgelegd.
Wisselknop Incrementeel vernieuwen in-/uitschakelen: hiermee schakelt u het beleid voor incrementeel vernieuwen in of uit voor de tabel.
Vervolgkeuzelijst Filterveld: Hiermee selecteert u het queryveld waarop de tabel moet worden gefilterd voor stappen. Dit veld bevat alleen Datum/tijd-velden. U kunt incrementeel vernieuwen niet gebruiken als uw tabel geen datum/tijd-veld bevat.
Belangrijk
Kies een onveranderlijk datumveld voor het incrementele vernieuwingsfilter. Als de veldwaarde verandert (bijvoorbeeld met een gewijzigd veld met datum), kan dit leiden tot vernieuwingsfouten vanwege dubbele waarden in de gegevens.
Rijen uit het verleden opslaan/vernieuwen: in het voorbeeld in de vorige afbeelding ziet u de volgende instellingen.
In dit voorbeeld definiëren we een vernieuwingsbeleid voor het opslaan van vijf jaar aan gegevens in totaal en incrementeel vernieuwen van 10 dagen aan gegevens. Ervan uitgaande dat de tabel dagelijks wordt vernieuwd, worden de volgende acties uitgevoerd voor elke vernieuwingsbewerking:
Voeg een nieuwe dag met gegevens toe.
Vernieuw 10 dagen tot aan de huidige datum.
Kalenderjaren verwijderen die ouder zijn dan vijf jaar vóór de huidige datum. Als de huidige datum bijvoorbeeld 1 januari 2019 is, wordt het jaar 2013 verwijderd.
Het vernieuwen van de eerste gegevensstroom kan enige tijd in beslag nemen om alle vijf jaar te importeren, maar latere vernieuwingen zijn waarschijnlijk veel sneller voltooid.
Gegevenswijzigingen detecteren: een incrementele vernieuwing van 10 dagen is veel efficiënter dan een volledige vernieuwing van vijf jaar, maar u kunt dit mogelijk nog beter doen. Wanneer u het selectievakje Gegevenswijzigingen detecteren inschakelt, kunt u een datum/tijd-kolom selecteren om alleen de dagen te identificeren waarop de gegevens zijn gewijzigd en vernieuwd. Hierbij wordt ervan uitgegaan dat een dergelijke kolom bestaat in het bronsysteem, wat doorgaans voor controledoeleinden geldt. De maximumwaarde van deze kolom wordt geëvalueerd voor elk van de perioden in het incrementele bereik. Als deze gegevens niet zijn gewijzigd sinds de laatste vernieuwing, hoeft u de periode niet te vernieuwen. In het voorbeeld kan dit de dagen die incrementeel worden vernieuwd, verder verminderen van 10 tot misschien 2.
Tip
Voor het huidige ontwerp moet de kolom die wordt gebruikt voor het detecteren van gegevenswijzigingen, worden bewaard en in het cachegeheugen opgeslagen. U kunt een van de volgende technieken overwegen om kardinaliteit en geheugenverbruik te verminderen:
- Behoud alleen de maximumwaarde van deze kolom op het moment van vernieuwen, mogelijk met behulp van een Power Query-functie.
- Beperk de precisie tot een niveau dat acceptabel is gezien de vereisten voor de vernieuwingsfrequentie.
Alleen volledige vernieuwingsperioden: Stel dat de vernieuwing elke dag om 4:00 uur is gepland. Als gegevens in het bronsysteem worden weergegeven tijdens die eerste vier uur van die dag, wilt u er mogelijk geen rekening mee houden. Sommige zakelijke metrische gegevens, zoals vaten per dag in de olie- en gasindustrie, zijn niet praktisch of verstandig om rekening mee te houden op basis van gedeeltelijke dagen.
Een ander voorbeeld waarbij alleen volledige perioden worden vernieuwd, is het vernieuwen van gegevens uit een financieel systeem. Stel dat er een financieel systeem is waarin gegevens voor de vorige maand worden goedgekeurd op de 12e kalenderdag van de maand. U kunt het incrementele bereik instellen op één maand en de vernieuwing plannen op de 12e dag van de maand. Als deze optie is geselecteerd, worden de gegevens van januari (de meest recente volledige maandelijkse periode) op 12 februari vernieuwd.
Notitie
Incrementeel vernieuwen van gegevensstromen bepaalt datums volgens de volgende logica: als een vernieuwing is gepland, gebruikt incrementele vernieuwing voor gegevensstromen de tijdzone die is gedefinieerd in het vernieuwingsbeleid. Als er geen planning voor vernieuwen bestaat, gebruikt incrementeel vernieuwen de tijd van de computer waarop de vernieuwing wordt uitgevoerd.
Nadat incrementeel vernieuwen is geconfigureerd, verandert de gegevensstroom uw query automatisch zodat deze filtert op datum. Als de gegevensstroom is gemaakt in Power BI, kunt u de automatisch gegenereerde query ook bewerken met behulp van de geavanceerde editor in Power Query om uw vernieuwing te verfijnen of aan te passen. Lees meer over incrementeel vernieuwen en hoe het werkt in de volgende secties.
Notitie
Wanneer u de gegevensstroom bewerkt, maakt de Power Query-editor rechtstreeks verbinding met de gegevensbron en worden de gegevens die in de cache zijn opgeslagen/gefilterd, niet weergegeven in de gegevensstroom nadat deze door het incrementele vernieuwingsbeleid zijn verwerkt. Als u de gegevens in de cache in de gegevensstroom wilt controleren, maakt u vanuit Power BI Desktop verbinding met de gegevensstroom nadat u het beleid voor incrementeel vernieuwen hebt geconfigureerd en de gegevensstroom hebt vernieuwd.
Incrementeel vernieuwen en gekoppelde tabellen versus berekende tabellen
Voor gekoppelde tabellen werkt incrementeel vernieuwen de brontabel bij. Omdat gekoppelde tabellen gewoon een aanwijzer naar de oorspronkelijke tabel zijn, heeft incrementeel vernieuwen geen invloed op de gekoppelde tabel. Wanneer de brontabel wordt vernieuwd volgens het gedefinieerde vernieuwingsbeleid, moet elke gekoppelde tabel ervan uitgaan dat de gegevens in de bron worden vernieuwd.
Berekende tabellen zijn gebaseerd op query's die worden uitgevoerd via een gegevensarchief. Dit kan een andere gegevensstroom zijn. Daarom gedragen berekende tabellen zich op dezelfde manier als gekoppelde tabellen.
Omdat berekende tabellen en gekoppelde tabellen zich op dezelfde manier gedragen, zijn de vereisten en configuratiestappen voor beide hetzelfde. Een verschil is dat incrementeel vernieuwen voor berekende tabellen in bepaalde configuraties niet op een geoptimaliseerde manier kan worden uitgevoerd vanwege de manier waarop partities worden gebouwd.
Schakelen tussen incrementeel en volledig vernieuwen
Gegevensstromen ondersteunen het wijzigen van het vernieuwingsbeleid tussen incrementeel en volledig vernieuwen. Wanneer een wijziging in beide richtingen plaatsvindt (volledig naar incrementeel of incrementeel naar volledig), is de wijziging van invloed op de gegevensstroom na de volgende vernieuwing.
Wanneer u een gegevensstroom verplaatst van volledig vernieuwen naar incrementeel, wordt de gegevensstroom bijgewerkt door de gegevensstroom aan het vernieuwingsvenster te koppelen en te verhogen zoals gedefinieerd in de instellingen voor incrementeel vernieuwen.
Wanneer u een gegevensstroom verplaatst van incrementeel naar volledig vernieuwen, worden alle gegevens die in de incrementele vernieuwing zijn verzameld, overschreven door het beleid dat is gedefinieerd in de volledige vernieuwing. U moet deze actie goedkeuren.
Ondersteuning voor tijdzones bij incrementeel vernieuwen
Incrementeel vernieuwen van gegevensstromen is afhankelijk van het tijdstip waarop deze wordt uitgevoerd. Het filteren van de query is afhankelijk van de dag waarop deze wordt uitgevoerd.
Ter ondersteuning van deze afhankelijkheden en om gegevensconsistentie te garanderen, implementeert incrementeel vernieuwen voor gegevensstromen de volgende heuristiek voor het vernieuwen van nu scenario's:
In het geval dat een geplande vernieuwing in het systeem is gedefinieerd, worden de tijdzone-instellingen uit de sectie Geplande vernieuwing gebruikt voor incrementele vernieuwing. Dit zorgt ervoor dat de tijdzone waarin de persoon die de gegevensstroom vernieuwt, altijd consistent is met de definitie van het systeem.
Als er geen geplande vernieuwing is gedefinieerd, gebruiken gegevensstromen de tijdzone van de computer van de gebruiker die de vernieuwing uitvoert.
Incrementeel vernieuwen kan ook worden aangeroepen met behulp van API's. In dit geval kan de API-aanroep een tijdzone-instelling bevatten die wordt gebruikt bij het vernieuwen. Het gebruik van API's kan handig zijn voor test- en validatiedoeleinden.
Details van de implementatie van incrementeel vernieuwen
Gegevensstromen maken gebruik van partitionering voor incrementeel vernieuwen. Incrementeel vernieuwen in gegevensstromen zorgt ervoor dat het minimale aantal partities voldoet aan de beleidsvereisten voor vernieuwen. Oude partities die buiten het bereik vallen, worden verwijderd, waardoor een doorlopend venster behouden blijft. Partities worden opportunistisch samengevoegd, waardoor het totale aantal vereiste partities wordt verminderd. Dit verbetert de compressie en kan in sommige gevallen de prestaties van query's verbeteren.
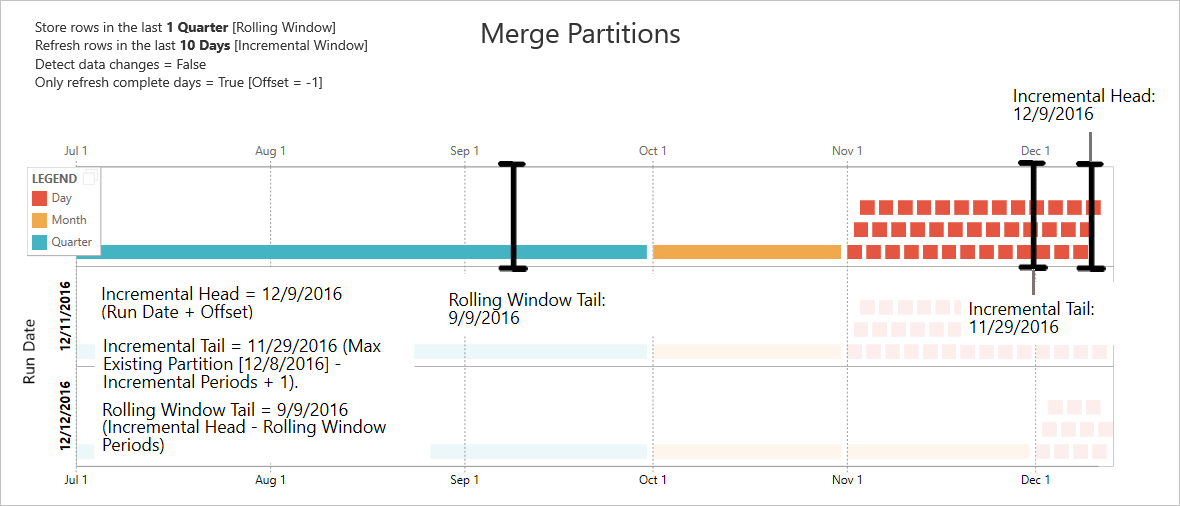
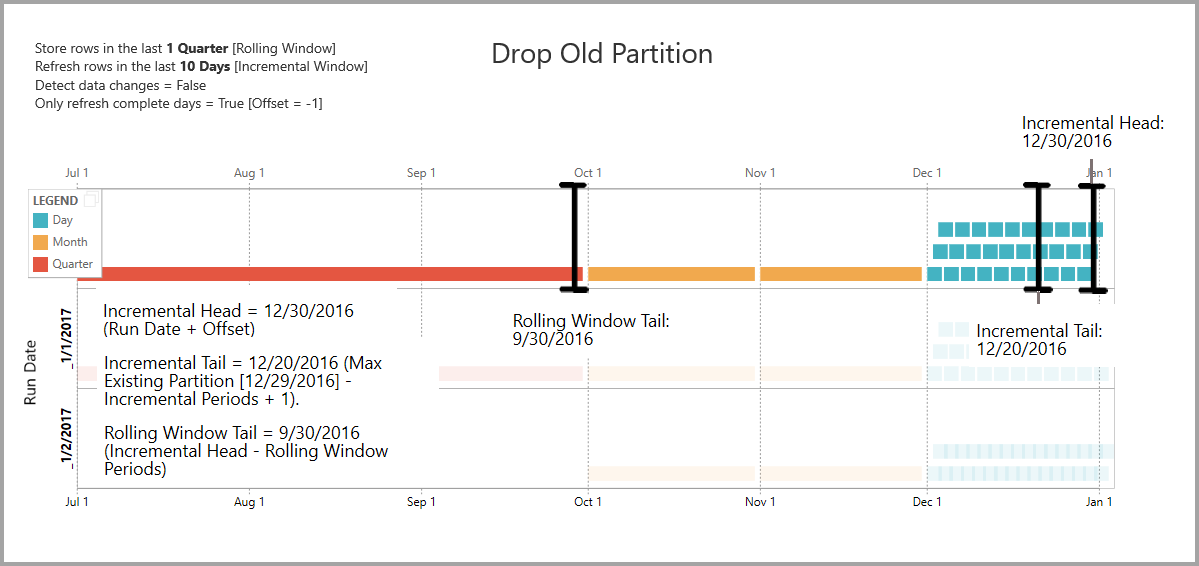
De voorbeelden in deze sectie delen het volgende vernieuwingsbeleid:
- Rijen opslaan in het laatste kwartaal
- Rijen vernieuwen in de afgelopen 10 dagen
- Gegevenswijzigingen detecteren = Onwaar
- Alleen volledige dagen vernieuwen = True
Partities samenvoegen
In dit voorbeeld worden dagpartities automatisch samengevoegd met het maandniveau nadat ze buiten het incrementele bereik vallen. Partities in het incrementele bereik moeten dagelijks worden onderhouden, zodat alleen die dagen kunnen worden vernieuwd. Met de vernieuwingsbewerking met uitvoeringsdatum 11-11-2016 worden de dagen in november samengevoegd, omdat ze buiten het incrementele bereik vallen.
Oude partities verwijderen
Oude partities die buiten het totale bereik vallen, worden verwijderd. De vernieuwingsbewerking met Uitvoeringsdatum 1-2-2017 verlaagt de partitie voor Q3 van 2016 omdat deze buiten het totale bereik valt.
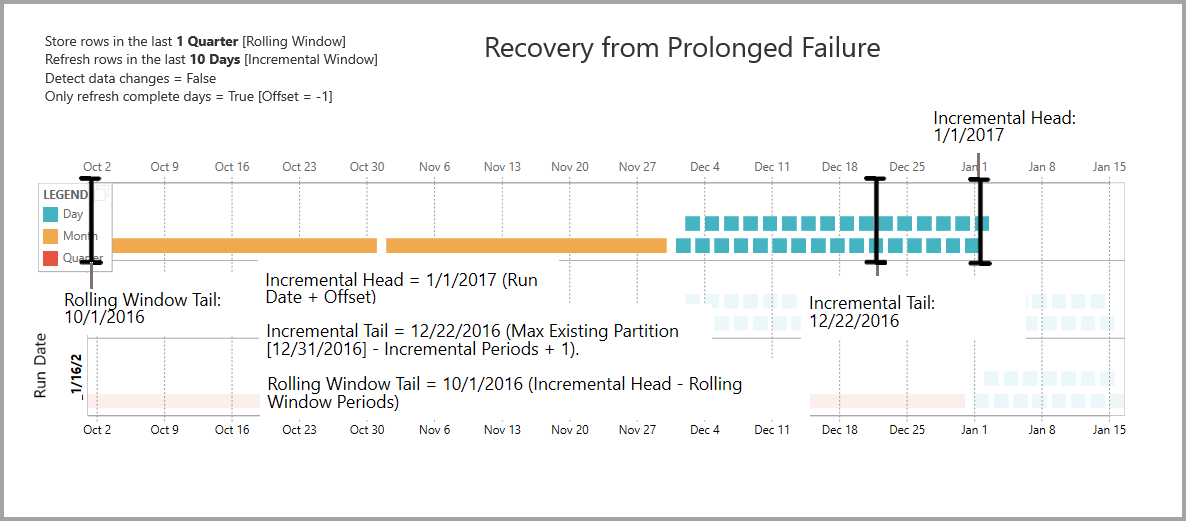
Herstel na langdurige storing
In dit voorbeeld wordt gesimuleerd hoe het systeem probleemloos herstelt na langdurige fouten. Stel dat vernieuwen niet is uitgevoerd omdat de referenties van de gegevensbron zijn verlopen en dat het 13 dagen duurt om het probleem op te lossen. Het incrementele bereik is slechts 10 dagen.
De volgende geslaagde vernieuwingsbewerking, met Run Date 1-15-2017, moet de ontbrekende 13 dagen opnieuw invullen en vernieuwen. De vorige negen dagen moeten ook worden vernieuwd omdat ze niet volgens de normale planning zijn vernieuwd. Met andere woorden, het incrementele bereik wordt verhoogd van 10 tot 22 dagen.
De volgende vernieuwingsbewerking, met Uitvoeringsdatum 16-2017, maakt gebruik van de mogelijkheid om de dagen in december en de maanden in Q4 van 2016 samen te voegen.
Incrementeel vernieuwen van gegevensstromen en gegevenssets
Incrementeel vernieuwen van gegevensstromen en incrementele vernieuwing van gegevenssets zijn ontworpen om samen te werken. Het is acceptabel en wordt ondersteund om een tabel incrementeel te vernieuwen in een gegevensstroom, volledig geladen in een gegevensset of een volledig geladen tabel in een gegevensstroom die incrementeel wordt geladen in een gegevensset.
Beide benaderingen werken volgens uw opgegeven definities in de vernieuwingsinstellingen. Meer informatie: Incrementeel vernieuwen in Power BI Premium
Zie ook
In dit artikel wordt incrementeel vernieuwen beschreven voor gegevensstromen. Hier volgen nog enkele artikelen die nuttig kunnen zijn:
- Selfservice voor gegevensvoorbereiding in Power BI
- Berekende tabellen maken in gegevensstromen
- Verbinding maken met gegevensbronnen voor gegevensstromen
- Tabellen koppelen tussen gegevensstromen
- Gegevensstromen maken en gebruiken in Power BI
- Gegevensstromen gebruiken met on-premises gegevensbronnen
- Resources voor ontwikkelaars voor Power BI-gegevensstromen
Voor meer informatie over Power Query en geplande vernieuwing kunt u deze artikelen lezen:
Lees het overzichtsartikel voor meer informatie over Common Data Model: